
LREC 2008, Marrakech, Morocco1 Automatic phone segmentation of expressive speech L. Charonnat, G....
13
LREC 2008, Marrakech, Morocco 1 Automatic phone segmentation of expressive speech L. Charonnat, G. Vidal, O. Boëffard IRISA/Cordial, Université de Rennes 1, Lannion, France. VIVOS project, funded by the French National Agency for Research (ANR)
-
Upload
frederick-stokes -
Category
Documents
-
view
212 -
download
0
Transcript of LREC 2008, Marrakech, Morocco1 Automatic phone segmentation of expressive speech L. Charonnat, G....

LREC 2008, Marrakech, Morocco 1
Automatic phone segmentation of expressive speech
L. Charonnat, G. Vidal, O. Boëffard
IRISA/Cordial,
Université de Rennes 1, Lannion, France.
VIVOS project, funded by the French National Agency for Research (ANR)

LREC 2008, Marrakech, Morocco 2
OUTLINE
►Introduction►Corpus description►Experimentation
■ text verification■ phonetisation■ HMM modeling
►A new mixed model►Results►Conclusion and perspectives

LREC 2008, Marrakech, Morocco 3
Introduction
►Objectives■ To develop an automatic segmentation system adapted to
expressive speech taken from movie dubbing.■ To investigate a new modelling methodology using mixed
HMM models based on both Context Dependent and Context Independent Models.
►Motivations■ Voices for TTS applications are created from constrained
recordings whereas unconstrained recordings are available, notably in the post-production industry.
■ Context-independent phoneme models are usually used to perform label alignment, but, in some cases, context-dependent phoneme models can improve the alignment precision for co-articulated sounds.
LREC 2008, Marrakech, Morocco 4
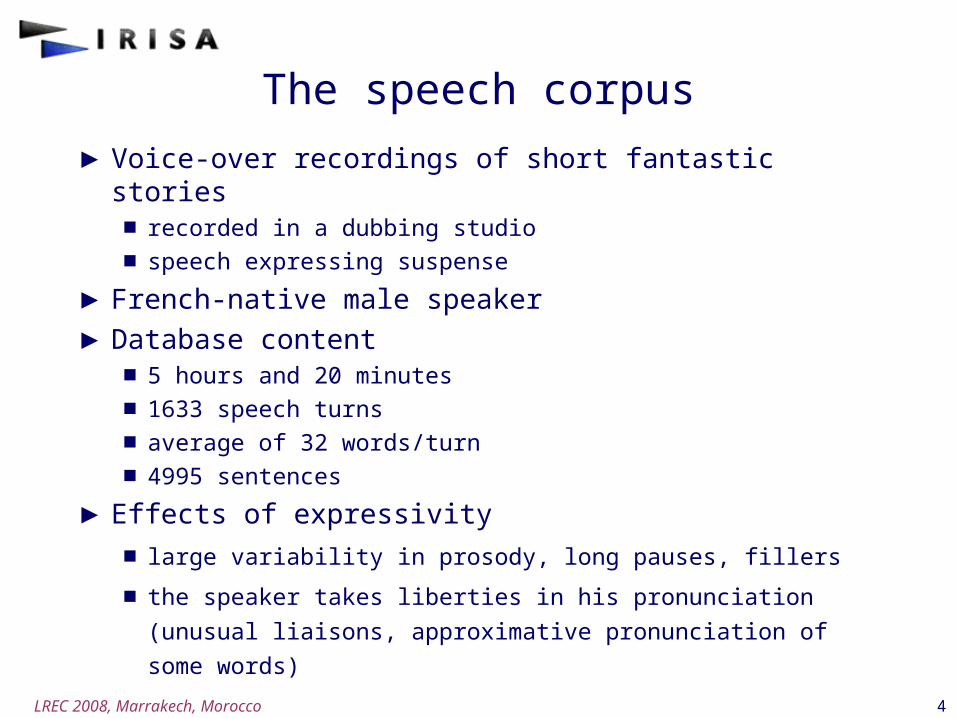
The speech corpus
►Voice-over recordings of short fantastic stories■ recorded in a dubbing studio■ speech expressing suspense
►French-native male speaker►Database content
■ 5 hours and 20 minutes■ 1633 speech turns■ average of 32 words/turn■ 4995 sentences
►Effects of expressivity
■ large variability in prosody, long pauses, fillers
■ the speaker takes liberties in his pronunciation (unusual
liaisons, approximative pronunciation of some words)

LREC 2008, Marrakech, Morocco 5
Experimentation
►3 corpora
■ learning : 70% of the corpus -> to train the models
■ validation : 12% of the corpus -> to set modeling parameters
■ test : 18% of the corpus -> to evaluate the overall performance

LREC 2008, Marrakech, Morocco 6
Text verification
►Manual checking
■ spelling
■ pronunciation
►Insertions of tags in the text
■ indicating deep breathing and long pauses
■ not synchronized with the signal
►Exception dictionary for
■ some acronyms
■ foreign words
■ ~600 words
►speech turns synchronization

LREC 2008, Marrakech, Morocco 7
Phonetisation
►Rules-based grapheme-phoneme conversion
►Variants : liaisons, schwas, pauses
►Production of a graph including optional variants
►HTK phonological words
ils sont amenés => i l / s õ / a m ø n e

LREC 2008, Marrakech, Morocco 8
HMM methodology
►1 phoneme ↔1 hmm model
►12 MFCC + Energy + derivatives (39 coefficents)
►3 emitting states
►Context Independent models :
■ initialised on the learning corpus (70% of the corpus)
■ 3 gaussian components mixture
►Context Dependent models :
■ initialised on Context Independent models
■ 4 gaussian components mixture
■ estimation of missing contextual models using a classification tree
►Mixed models

LREC 2008, Marrakech, Morocco 9
Mixed models►Mixing context-dependant models and context-
independant models according to their performance on
a validation set

LREC 2008, Marrakech, Morocco 10
Comparing CD vs CI models
Pauses Voiced
Plosives
Unvoiced
Plosives
Voiced
Fricatives
Unvoiced
Fricatives
Nasal
Cons.
Liquids Semi-
Vowels
Open Oral
V.
Closed
Oral V.
Open
Nasal V.
Closed
Nasal V.
Pauses 7.25 4.24 10.78 14.69 0.43 18.18 2.95 20.00 -0.23 0.36 5.57 3.17
Voiced Plosives - -12.74 -12.02 0.93 0 0 -1.10 -0.94 1.04 -0.83 1.15 0.43
Unvoiced Plos. 33.76 3.78 -9.84 0 -2.94 -4.49 -2.84 -2.68 -1.59 0.41 -0.34 -0.51
Voiced Fric. -6.00 -3.82 -1.34 13.69 9.47 -0.09 -2.23 -1.42 -3.18 -1.90 0.20 -1.90
Unvoiced Fric. -4.42 3.68 -0.74 -16.67 1.19 0 -3.17 0.11 -0.95 -1.66 -0.84 -0.15
Nasal Cons. 15.39 -14.44 -5.37 0.87 1.75 -12.21 -2.66 -2.03 -2.30 -2.72 -2.02 -1.51
Liquids 41.80 -2.42 -4.57 1.33 6.96 0.09 -4.19 -5.15 -0.82 -0.72 -0.86 0.64
Semi-Vowels -0.87 0 -3.63 0 5.88 8.34 16.67 - -10.11 -11.97 1.92 2.11
Open Oral V. 30.42 -0.41 0.61 -2.67 3.19 -0.26 -1.20 -1.77 -5.63 2.30 -3.55 -8.44
Closed Oral V. 17.87 -0.86 -0.45 -0.50 2.65 -0.34 -3.63 -2.13 -12.69 -2.27 -7.67 4.94
Open Nasal V. 14.42 -1.71 -6.73 1.19 2.10 -1.96 -3.22 0 -13.10 1.18 0 3.58
Closed Nasal V. 28.02 -1.95 -2.24 -3.78 1.35 -1.76 -1.96 0 13.80 -5.22 16.66 8.70
►Difference of %age of correct alignments (<20 ms) between
Context-Dependent models and Context-Independent
models

LREC 2008, Marrakech, Morocco 11
Results : phonetic decoding
►Disagreement (Elisions+Insertions+Substitutions)
between 5.11% and 5.55%
►Good labelling of liaisons, elisions and insertions of
pauses and schwas
►Substitutions : inversion between open and closed
vowels
Elis io ns Insertio ns substitutio n
HMM- p h o n e 0 .3 2 %[±0 .0 6 %]
1 .0 1 %[±0.11 %]
3 .9 2 %[±0.2 1 %]
HMM- tr ip h o n e 0 .2 2 %[±0.0 5 %]
0 .9 0 %[±0.1 0 %]
3 .9 9 %[±0.2 1 %]
HMM- m ixed 0 .2 6 %[±0.0 6 %]
1 .3 0 %[±0.1 2 %]
3 .9 9 %[±0.2 1 %]
LREC 2008, Marrakech, Morocco 12
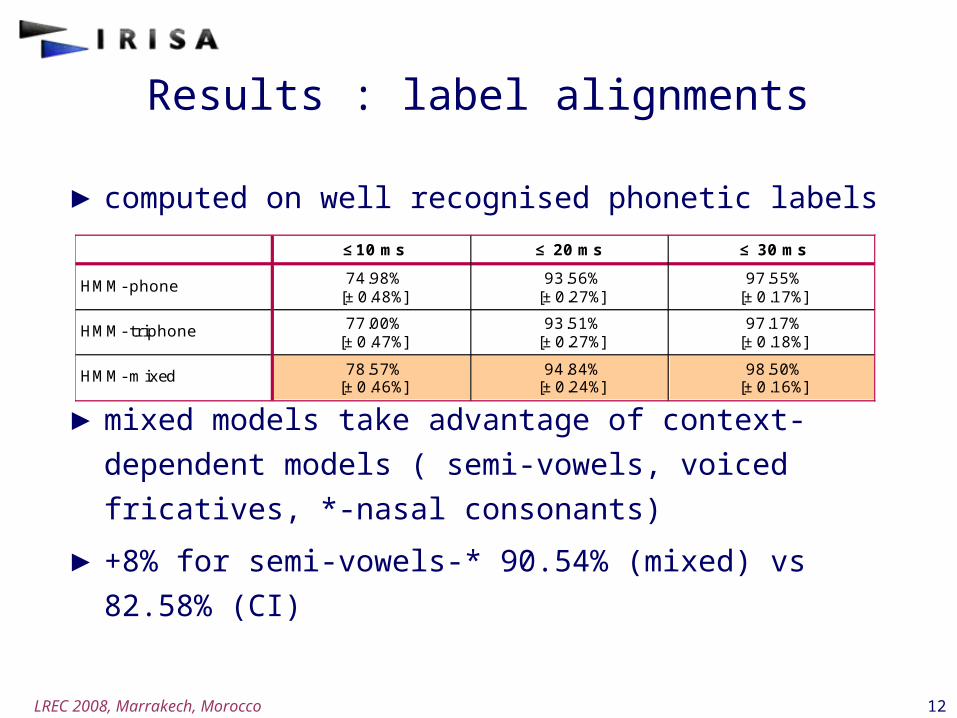
Results : label alignments
►computed on well recognised phonetic labels
►mixed models take advantage of context-dependent
models ( semi-vowels, voiced fricatives, *-nasal
consonants)
►+8% for semi-vowels-* 90.54% (mixed) vs 82.58% (CI)
≤ 1 0 ms ≤ 2 0 ms ≤ 3 0 ms
HMM- p h o n e 7 4 .9 8 %[±0 .4 8 %]
9 3 .5 6 %[±0.2 7 %]
9 7 .5 5 %[±0.1 7 %]
HMM- tr ip h o n e 7 7 .0 0 %[±0.4 7 %]
9 3 .5 1 %[±0.2 7 %]
9 7 .1 7 %[±0.1 8 %]
HMM- m ixed 7 8 .5 7 %[±0.4 6 %]
9 4 .8 4 %[±0.2 4 %]
9 8 .5 0 %[±0.1 6 %]

LREC 2008, Marrakech, Morocco 13
Conclusion and perspectives
►Good segmentation scores of expressive speech are due to
■ an accurate text verification (...but only at a text level)
■ an automatically generated graph of phonemesa including variants
■ an automatic hmm segmentation
►Experimentation of a new segmentation methodology by
mixing CI and CD models
►Perspectives
■ to improve automatic grapheme to phoneme conversion of
acronyms and proper names
■ to apply post-processings for open/closed vowels and pauses
■ to include new filler models


















