

Low-complexity and Repetitive Regions n OraLee Branch n John Wootton n NCBI n...
18
-
Upload
eustace-walker -
Category
Documents
-
view
218 -
download
0
Transcript of Low-complexity and Repetitive Regions n OraLee Branch n John Wootton n NCBI n...

DNA Sequences–What would be the expected number of occurrences
of a particular sequence in a genome? • Size: human genome 6*109 considering both strands• Base frequency: equal• Sequence length: 20 nucleotides
–Bernouli Model: = 0.005
–But:• (GT)n with n>10 = 105
Sequence Composition
20
9
410*6

Low-complexity Regions
Simple Sequence Regions (SSR)– MICRO- or MINISATELLITES– Regions that have significant biases in AA or nucleotide composition :
repeats of simple motifs
– (GT)n
(AAC)n (P)
n (NANP)
n
Low-Complexity Regions/Segments– Complexity can be measured by Shannon’s Entropy
• Regarding an amino acid sequence
– For each composition of a complexity state, there exists a large number of possible sequences
20
1
)ln(i
ii ff

Low-Complexity Regions Locally abundant residues may be
– continuous or loosely clustered irregular or aperiodic
>25% of AA in currently sequenced genome is in LC regions– non-globular domains SSR
Examples: myosins, pilins, segments in antigens, short subsequences of 10-50 residues with unknown function– Beta-pleated sheets– Alpha helices– Coiled-coils

Low-Complexity Regions Locally abundant residues may be
– continuous or loosely clustered irregular or aperiodic
>25% of AA in currently sequenced genome is in LC regions– non-globular domains SSR
Examples: myosins, pilins, segments in antigens, short subsequences of 10-50 residues with unknown function– Beta-pleated sheets– Alpha helices– Coiled-coils

Detecting Low-Complexity
SEG and PSEG/NSEG algorithms–Wootton and Federhen
• Methods in Enzymology 266:33 (1996)• Computers and Chemistry 17:149 (1993)
SEG–UNIX Executable available on ncbi servers
• seg FASTAfile Window TriggerComplexity Extension K2(1) K2(2)
• Longer Window lengths define more sustained regions, but overlook short biased subsequences
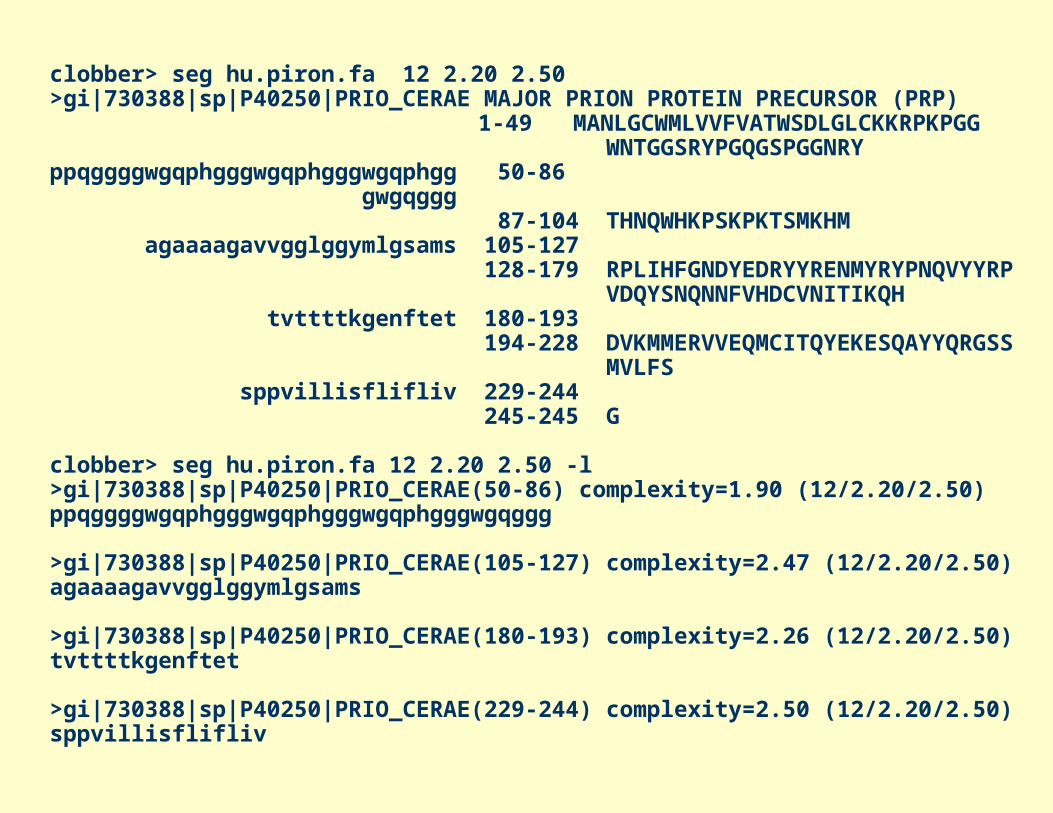
clobber> seg hu.piron.fa 12 2.20 2.50>gi|730388|sp|P40250|PRIO_CERAE MAJOR PRION PROTEIN PRECURSOR (PRP)
1-49 MANLGCWMLVVFVATWSDLGLCKKRPKPGG WNTGGSRYPGQGSPGGNRYppqggggwgqphgggwgqphgggwgqphgg 50-86 gwgqggg 87-104 THNQWHKPSKPKTSMKHM agaaaagavvgglggymlgsams 105-127 128-179 RPLIHFGNDYEDRYYRENMYRYPNQVYYRP VDQYSNQNNFVHDCVNITIKQH tvttttkgenftet 180-193 194-228 DVKMMERVVEQMCITQYEKESQAYYQRGSS MVLFS sppvillisflifliv 229-244 245-245 G
clobber> seg hu.piron.fa 12 2.20 2.50 -l>gi|730388|sp|P40250|PRIO_CERAE(50-86) complexity=1.90 (12/2.20/2.50)ppqggggwgqphgggwgqphgggwgqphgggwgqggg
>gi|730388|sp|P40250|PRIO_CERAE(105-127) complexity=2.47 (12/2.20/2.50)agaaaagavvgglggymlgsams
>gi|730388|sp|P40250|PRIO_CERAE(180-193) complexity=2.26 (12/2.20/2.50)tvttttkgenftet
>gi|730388|sp|P40250|PRIO_CERAE(229-244) complexity=2.50 (12/2.20/2.50)sppvillisflifliv

SEG piron with different window lengthsquestion-based – exploratory tool – optimization step

– Intuitive explanation• Take a 20-residue long sequence
– (20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0)– ( 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 )– ( 3 3 3 3 3 2 2 2 2 1 1 0 0 0 0 0 0 0 0 0)
– Complexity can be described by Shannon’s Entropy (K2)• Regarding an amino acid sequence
– For each composition of a complexity state, there exists a large number of possible sequences (K1)
Detecting Low-Complexity
N
iii ffK
12 )ln(
N
iin
L
LK
1
1
!
!ln
1

How SEG works seg FASTAfile Window TriggerComplexity Extension
K2(1) K2(2)
Looks within window length: if complexity < K2(1) then extends until complexity < K2(2)
Uniform prior probabilities
– Protein sequence data base is a heterogeneous statistical mixture such that the initially-unknown AA frequencies in Low-complexity subsets need have no similarity to frequencies in total data base
– Unbiased view of low-complexity regions
– Gives equiprobable compositions for any complexity state

How SEG works, continued
How do you correct for the background AA/nuc composition bias?
– After randomly shuffling all the residues, determine the trigger complexity that results in 4% of the data base being within Low-complexity regions
– Then use this trigger complexity and subtract 4% from %AA in Low-complexity regions

Detecting Low-complexity with repetitive motif: SSR
PSEG or NSEG Repetition of residue types or k-grams Period 3
(n V E n K N n V D n K D n V N n K S n K)(n m i n m i n m i n m i n m i n m i n m)
(n m E n m N n m D n m D n m N n m S n m)
Sliding window along sequence in single residue steps

Evolutionary Mechanisms Evolution of sequences in general
– Evolution rate of 10-5 – 10-9
• Base pair substitution (10-9 )• Insertion/deletions• Recombination
In SSR, Low-complexity regions, mutations are in length – with steps typically +/- one repeat unit– Evolution rate 10-3
• Biased nucleotide substitution due to increased recombination in repetitive regions
• Unequal crossing over (recombination)• Replication slippage
Alignment of repeats does not imply relationships/ancestory

Low-Complexity and BLAST searches
Low-complexity regions results in BLAST searches being dominated by Low-complexity regions – biased AA/nuc composition
BLAST added “mask low-complexity” by default– Seg parameters: 12 2.2 2.5
BLAST now also uses a compositional bias filter on the whole database– Masks if composition bias using seg 10 1.8 2.1
YOU MAY WANT TO TURN THESE OPTIONS OFF and use your own organism-specific seg paramenters when doing protein homology searching
YOU WILL NEED TO TURN THESE OPTIONS OFF if you are interested in looking at sequence similarities of repetitive/low complexity regions.

Example: Plasmodium falciparum
Using whole genome sequences is important to limit pcr sequencing bias for antigens: hydrophilic proteins
Considering GC-content / AA bias–P. falciparum is approximately 28 % GC
Visualization of individual proteins

A helpful tool here and in general
SEALS: A system for Easy Analysis of Lots of Sequences, R. Walker and E. Koonin, NCBI
www.ncbi.nlm.nih.gov/ CBBresearch/Walker/SEALS/index.html
Demonstrate getting an appropriate data set– Taxnode2gi, gi2fasta– Daffy– Purge– Gref– Fanot
Use cleaned data set of P. falciparum proteins

Protein Analysis
Setting the trigger complexity:– Dbcomp– Shuffledb– Seg
Run SEG on P. falciparum MSP1, PfEMP2, Cg2– Options
• –p (tree form output) • -l (only report Low-C segs)• -h (don’t report Low-C segs)• -x (substitute Low-C with x)
Run PSEG on P. falciparum MSP1, PfEMP2, Cg2 with different –z (periodicity)

Usefulness of studying Low-Complexity
Within a proteinsecondary structure, homology searchers, protein locationgenetic disorders
Within taxamicrosatellite markerspolymorphism comparisons between proteins
Between taxaSynteny , orthologsdifferent selection pressures upon different organismsparasites: immunogenicity, rapid evolution of
antigens, recombination




![Letterhead Template.docx · Web viewThe Royal Canadian Legion [Branch Name] [Branch Address] [Branch Address] [Branch Telephone Number] [Branch Fax Number] [Branch Email Address]](https://static.fdocuments.in/doc/165x107/5e8c06ee97d20636b84df16c/letterhead-web-view-the-royal-canadian-legion-branch-name-branch-address.jpg)













