
Long Text Keystroke Biometrics Study Gary Bartolacci, Mary Curtin, Marc Katzenberg, Ngozi Nwana...
22
Long Text Keystroke Biometrics Study Gary Bartolacci, Mary Curtin, Marc Katzenberg, Ngozi Nwana Sung-Hyuk Cha, Charles Tappert (Software Engineering Project Team + DPS Student)
-
date post
19-Dec-2015 -
Category
Documents
-
view
213 -
download
1
Transcript of Long Text Keystroke Biometrics Study Gary Bartolacci, Mary Curtin, Marc Katzenberg, Ngozi Nwana...

Long Text Keystroke Biometrics Study
Gary Bartolacci, Mary Curtin, Marc Katzenberg, Ngozi Nwana
Sung-Hyuk Cha, Charles Tappert
(Software Engineering Project Team + DPS Student)

2
Keystroke Biometric
Biometrics important for security apps Advantage - inexpensive and easy to
implement, the only hardware needed is a keyboard
Disadvantage - behavioral rather than physiological biometric, easy to disguise
One of the least studied biometrics, thus good for dissertation studies

3
Focus of Study Previous studies mostly
concerned with short character string input Password hardening Short name strings
We focus on large text input 200 or more characters per sample

4
Focus of Study (cont)
Applications of interest Identification
1-of-n classification problem e.g., sender of inappropriate e-mail in a
business environment with a limited number of employees
Verification Binary classification problem, yes/no e.g., student taking online exam

5
Software Components
Raw Keystroke Data Capture over the Internet (Java applet)
Feature Extraction (SAS software) Classification (SAS software)
Training Testing

6
Keystroke Data Capture
(Java Applet)
Raw data recorded for each entry Key’s character Key’s code text equivalent Key’s location on keyboard
1 = standard, 2 = left, 3 = right Time key was pressed (msec) Time key was released (msec) Number of left, right, double mouse
clicks

7
Keystroke Data Capture(Java Applet)

8
Aligned Raw Data File(Hello World!)

9
Feature Extraction
10 Mean and 10 Std of key press durations 8 most frequent alphabet letters (e, a, r, i, o, t, n,
s) Space & shift keys
10 Mean and 10 Std of key transitions 8 most common digrams (in, th, ti, on, an, he, al,
er) Space-to-any-letter & any-letter-to-space
18 Total number of keypresses for Space, backspace, delete, insert, home, end,
enter, ctrl, 4 arrow keys, shift (left), shift (right), total entry time, left, right, & double mouse clicks

10
Feature Extraction Preprocessing
Outlier removal Remove samples > 2 std from mean Prevents skewing of feature
measurements caused by pausing of the keystroker
Standardization x’ = (x - xmin) / (xmax - xmin) Scales to range 0-1 to give roughly equal
weight to each feature
11
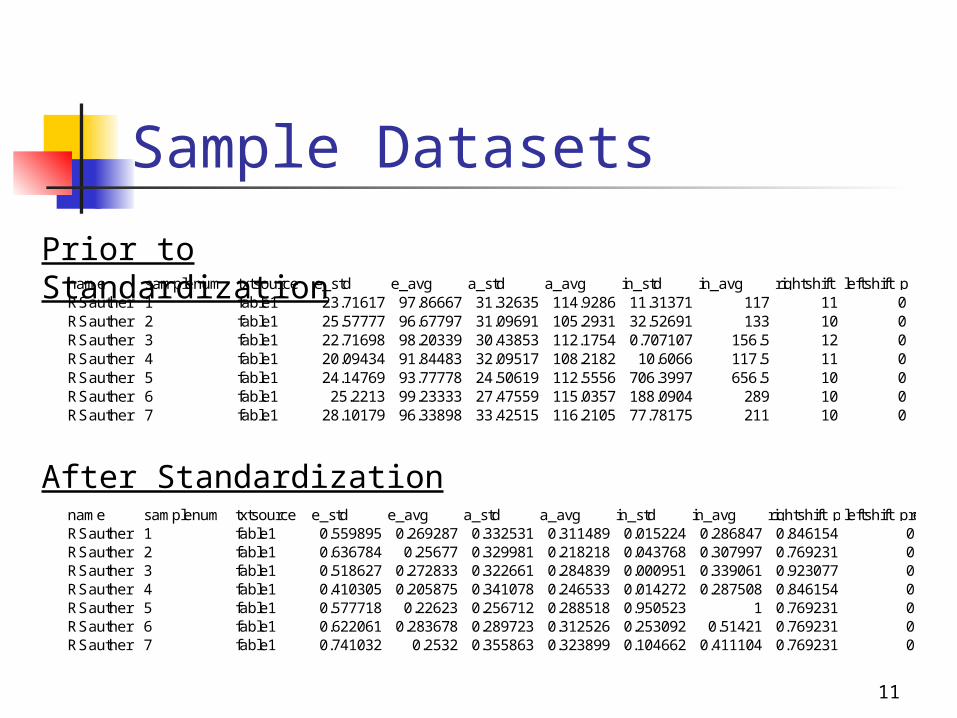
Sample Datasets
name samplenum txtsource e_std e_avg a_std a_avg in_std in_avg rightshift_pressesleftshift_pressesRSauther 1 fable1 23.71617 97.86667 31.32635 114.9286 11.31371 117 11 0RSauther 2 fable1 25.57777 96.67797 31.09691 105.2931 32.52691 133 10 0RSauther 3 fable1 22.71698 98.20339 30.43853 112.1754 0.707107 156.5 12 0RSauther 4 fable1 20.09434 91.84483 32.09517 108.2182 10.6066 117.5 11 0RSauther 5 fable1 24.14769 93.77778 24.50619 112.5556 706.3997 656.5 10 0RSauther 6 fable1 25.2213 99.23333 27.47559 115.0357 188.0904 289 10 0RSauther 7 fable1 28.10179 96.33898 33.42515 116.2105 77.78175 211 10 0
Prior to Standardization
name samplenum txtsource e_std e_avg a_std a_avg in_std in_avg rightshift_pressesleftshift_pressesRSauther 1 fable1 0.559895 0.269287 0.332531 0.311489 0.015224 0.286847 0.846154 0RSauther 2 fable1 0.636784 0.25677 0.329981 0.218218 0.043768 0.307997 0.769231 0RSauther 3 fable1 0.518627 0.272833 0.322661 0.284839 0.000951 0.339061 0.923077 0RSauther 4 fable1 0.410305 0.205875 0.341078 0.246533 0.014272 0.287508 0.846154 0RSauther 5 fable1 0.577718 0.22623 0.256712 0.288518 0.950523 1 0.769231 0RSauther 6 fable1 0.622061 0.283678 0.289723 0.312526 0.253092 0.51421 0.769231 0RSauther 7 fable1 0.741032 0.2532 0.355863 0.323899 0.104662 0.411104 0.769231 0
After Standardization

12
Classification Identification
Nearest neighbor classifier using Euclidean distance
Input sample compared to every training sample

13
Experimental Design:Identification Experiment
8 subjects that know the purpose of exp. Training – 10 reps of text a (approx. 600
char) Testing
10 reps of text a 10 reps of text b (same length as text a) 10 reps of text c (half length of text a)

14
Experimental Design: Instructions for Subjects
Subjects were told to input the data using their normal keystroke dynamics
Subjects were asked leave at least a day between entering samples

15
Experimental Design:Text a – about 600
characters This is an Aesop fable about the bat and the
weasels. A bat who fell upon the ground and was caught by a weasel pleaded to be spared his life. The weasel refused, saying that he was by nature the enemy of all birds. The bat assured him that he was not a bird, but a mouse, and thus was set free. Shortly afterwards the bat again fell to the ground and was caught by another weasel, whom he likewise entreated not to eat him. The weasel said that he had a special hostility to mice. The bat assured him that he was not a mouse, but a bat, and thus a second time escaped. The moral of the story: it is wise to turn circumstances to good account.

16
Expected Outcomes: Recognition Accuracy
Accuracy on text a > that on text b text a is the training text
Accuracy on text b > that on text c
text b is longer than text c Accuracy on texts a, b, c > arbitrary
text texts a, b, & c are similar, all Aesop
fables

17
Preliminary Results – Reduced Experiment
Reduced identification experiment Smaller text input
“The quick brown fox jumps over the lazy dog.”
Fewer subjects Three project team members
Fewer feature measurements Mean and std for “e” and “o” key press
durations Accuracy of 80%, which is promising
18
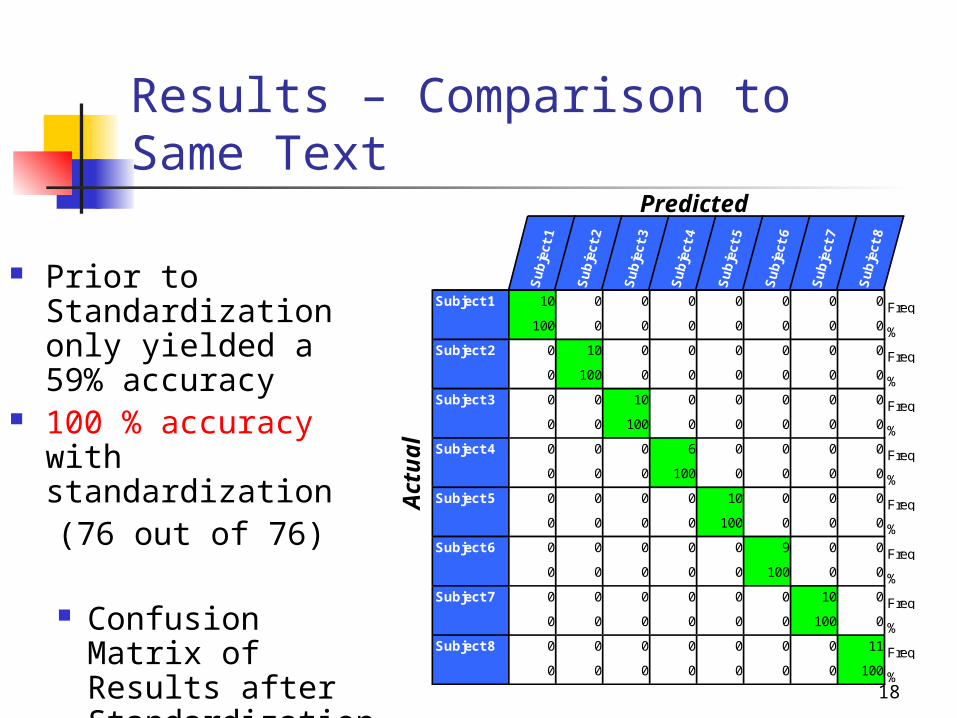
Results – Comparison to Same Text
Predicted
Actual
Prior to Standardization only yielded a 59% accuracy
100 % accuracy with standardization (76 out of 76)
Confusion Matrix of Results after Standardization
Su
bje
ct 1
Su
bje
ct 2
Su
bje
ct 3
Su
bje
ct 4
Su
bje
ct 5
Su
bje
ct 6
Su
bje
ct 7
Su
bje
ct 8
Subject 1 10 0 0 0 0 0 0 0 Freq100 0 0 0 0 0 0 0 %0 10 0 0 0 0 0 0 Freq0 100 0 0 0 0 0 0 %0 0 10 0 0 0 0 0 Freq0 0 100 0 0 0 0 0 %0 0 0 6 0 0 0 0 Freq0 0 0 100 0 0 0 0 %0 0 0 0 10 0 0 0 Freq0 0 0 0 100 0 0 0 %0 0 0 0 0 9 0 0 Freq0 0 0 0 0 100 0 0 %0 0 0 0 0 0 10 0 Freq0 0 0 0 0 0 100 0 %0 0 0 0 0 0 0 11 Freq0 0 0 0 0 0 0 100 %
Subject 3
Subject 4
Subject 1
Subject 2
Subject 7
Subject 8
Subject 5
Subject 6

19
Results – Comparison to Different Text of ~Equal Length
Predicted
Actual
Prior to Standardization only yielded a 38% accuracy
98.5 % accuracy with standardization (65 out of 66)
Confusion Matrix of Results after Standardization
Su
bje
ct 1
Su
bje
ct 2
Su
bje
ct 3
Su
bje
ct 4
Su
bje
ct 5
Su
bje
ct 7
Su
bje
ct 8
Subject 1 10 0 0 0 0 0 0 Freq100 0 0 0 0 0 0 %0 9 0 0 0 1 0 Freq0 90 0 0 0 10 0 %0 0 10 0 0 0 0 Freq0 0 100 0 0 0 0 %0 0 0 6 0 0 0 Freq0 0 0 100 0 0 0 %0 0 0 0 10 0 0 Freq0 0 0 0 100 0 0 %0 0 0 0 0 10 0 Freq0 0 0 0 0 100 0 %0 0 0 0 0 0 10 Freq0 0 0 0 0 0 100 %
Subject 7
Subject 8
Subject 5
Subject 3
Subject 4
Subject 1
Subject 2

20
Results – Comparison to Different Text of Shorter Length
Predicted
Actual
Prior to Standardization only yielded a 14% accuracy
97% accuracy with standardization (74 out of 76)
Confusion Matrix of Results after Standardization
Su
bje
ct 1
Su
bje
ct 2
Su
bje
ct 3
Su
bje
ct 4
Su
bje
ct 5
Su
bje
ct 6
Su
bje
ct 7
Su
bje
ct 8
Subject 1 10 0 0 0 0 0 0 0 Freq100 0 0 0 0 0 0 0 %0 9 0 0 0 0 1 0 Freq0 90 0 0 0 0 10 0 %0 0 10 0 0 0 0 0 Freq0 0 100 0 0 0 0 0 %0 0 0 5 0 0 1 0 Freq0 0 0 83.33 0 0 16.67 0 %0 0 0 0 10 0 0 0 Freq0 0 0 0 100 0 0 0 %0 0 0 0 0 10 0 0 Freq0 0 0 0 0 100 0 0 %0 0 0 0 0 0 10 0 Freq0 0 0 0 0 0 100 0 %0 0 0 0 0 0 0 10 Freq0 0 0 0 0 0 0 100 %
Subject 7
Subject 8
Subject 5
Subject 6
Subject 3
Subject 4
Subject 1
Subject 2

21
Conclusions
System is a viable means of differentiating between individuals based on typing patterns
Standardization is crucial to the accuracy of the system
It is likely that the shorter the text used for verification, the lower the accuracy
Decreasing # measurements used also decreases accuracy

22
Questions/Comments?
Focus or applications? Software implementation? Experimental design? Expected experimental outcomes?
![Pontificia Universidad Católica de Valparaísoopac.pucv.cl/pucv_txt/txt-2500/UCH2887_01.pdf · Una clasificación interesante de agentes, propuesta en [Nwana, 1996], se observa en](https://static.fdocuments.in/doc/165x107/5ea939756f1513497b5180cf/pontificia-universidad-catlica-de-valpara-una-clasificacin-interesante-de.jpg)

















