
Linear Models for Classification - University of Nebraska...
71
university-logo The Classification Problem Discriminant Functions Probabilististic Discriminative Models Probabilististic Generative Models Linear Models for Classification Catherine Lee Anderson figures courtesy of Christopher M. Bishop Department of Computer Science University of Nebraska at Lincoln CSCE 970: Pattern Recognition and Machine Learning Cate Anderson Linear Models for Classification
Transcript of Linear Models for Classification - University of Nebraska...

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Linear Models for Classification
Catherine Lee Andersonfigures courtesy of Christopher M. Bishop
Department of Computer ScienceUniversity of Nebraska at Lincoln
CSCE 970: Pattern Recognition and Machine Learning
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Congradulations!!!!
You have just inherited an old house from your great grandaunt on your mothers side twice removed by marriage (andonce by divorce).
There is an amazing collection of books in the old library(and in almost every other room in the house) containingevery thing from old leather bounded tomes and crinkly oldparchments to the newer dust jacket bound best sellersand academic text books along with a sizable collection ofpaper back pulp fiction and DC comic books.
Yep, old Aunt Lacee was a collector and you have to cleanout the old house before you can sell it.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Your Mission
Being the over worked (and underpaid) student that youare, you have limited time to spend on this task ...........
but because you spend your leasuire time listening to NPR(“the Book Guys”) you know that there is money to bemade in old books.
In other words, you need to quickly determine which booksto throw out (or better still recycle), which to sell, and whichto hang onto as an investment.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
The Task
From listening to “The Book Guys” you know thqt there aremany aspects of a book that determine its present valuewhich will help you determine if you wish to toss, sell orkeep it. These aspects include:
date publishedauthortopicconditiongenrepresence of dust jacketnumber of volume know to be publishedetc......
And to your advantage, you have just completed a coursein machine learning so you recognize that what you have isa straight forward classification problem.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Outline
1 The Classification ProblemDefining the problemApproaches in modeling
2 Discriminant Functionssimple model for two classesFisher Linear DiscriminantPerceptron
3 Probabilististic Discriminative ModelsLogistic Regression
4 Probabilististic Generative ModelsModeling conditional class probabilitiesBayes TheoremDiscrete Features
Cate Anderson Linear Models for Classification
university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Defining the problemApproaches in modeling
Outline
1 The Classification ProblemDefining the problemApproaches in modeling
2 Discriminant Functionssimple model for two classesFisher Linear DiscriminantPerceptron
3 Probabilististic Discriminative ModelsLogistic Regression
4 Probabilististic Generative ModelsModeling conditional class probabilitiesBayes TheoremDiscrete Features
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Defining the problemApproaches in modeling
Classification
Problem Components
- A group, X , of items, x with common characteristics withspecific values assigned to these characterisitcs: valuescan be nominal, numeric, discrete or continuous.
- A set of disjoint classes, into which we wish to place eachof the above items.
- A function that assigns each item to one and only one ofthese disjoint classes.
Classification: Assigning each item to one discrete classusing a function devised specifically for this purpose.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Defining the problemApproaches in modeling
Structure of items
Each item can be represented as a D-dimensional vector,x = {x1, x2, . . . , xD}, where D is the number of aspects,attributes or value fields used to described the item.
Aunt Lacee’s Collection - Items to be classified are books,comics and parchments, each of which has a set of valuesattached to it (type, title, publish date, genre, conditions,. . .)
Sample items from Aunt Lace’s Collection:x = {“book”, “Origin of Species”, 1872, “biology,” “mint”, . . .}
x = {“parchment”, “Magna Carta”, 1210, “history,” “brittle”, . . .}
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Defining the problemApproaches in modeling
Structure of Classes
A set of K classes, C = {c1, c2, . . . , cK}, where each x canbelong to only one class
Input space is divided into K decision areas, each areacorresponding to a class
Boundries of decision areas are decision boundaries ordecision surfaces
In linear classification models these surfaces are linearfunction of x
In other words, these surfaces are defined by(D − 1)-dimensional hyperplanes within the D-dimensionalinput space.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Defining the problemApproaches in modeling
Example: two dimensions, two classes
x2
x1
wx
y(x)‖w‖
x⊥
−w0‖w‖
y = 0y < 0
y > 0
R2
R1
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Defining the problemApproaches in modeling
Structure of Classes
For Aunt Lacee’s book collection, K =3
c1 = “no value” - books with no value which will be recycledc2 = “sell immediately” - books with immediate cash valuesuch as current text books and best sellers which will besold quickly.c3 = “keep” - these books (or parchments or comics ) havemuseum quality price tags and require time in order toplace properly (for maximum profit).
Each item of the collection will be assigned one and onlyone class. By their very nature, they are mutually exclusive.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Defining the problemApproaches in modeling
Representation of a K Class Label
Let t be a vector of length K , used to represent a classlabel.
Each element tk of t is 0 except for element i when x ∈ ci
For Aunt Lacee’s collection, the values of t are as follows:
ti = {1, 0, 0} indicates xi ∈ c1 and should be recycled.ti = {0, 1, 0} indicates xi ∈ c2 and should be sold.ti = {0, 0, 1} indicates xi ∈ c3 and should be kept.
A binary class is a special case, needing only a singledimension vector.
t = {0} indicates xi ∈ c0
t = {1} indicates xi ∈ c1
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Defining the problemApproaches in modeling
Outline
1 The Classification ProblemDefining the problemApproaches in modeling
2 Discriminant Functionssimple model for two classesFisher Linear DiscriminantPerceptron
3 Probabilististic Discriminative ModelsLogistic Regression
4 Probabilististic Generative ModelsModeling conditional class probabilitiesBayes TheoremDiscrete Features
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Defining the problemApproaches in modeling
Approaches to the problem
Three approaches to finding the “function” for our classificationproblem
Discriminant Functions- The simplest approach is a function which directly assigns
each x to one ci ∈ C
Probabilistic Discriminant Functions- Separates the inference stage from the decision stage.
- In the inference stage, the conditional probability distribution,p(Ck | x) , is modeled directly.
- In decision stage, class is assigned based on thesedistributions.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Defining the problemApproaches in modeling
Approaches to the problem
Probabilistic Generative Functions
- Both the class conditional probability distribution, p(x | Ck ) aswell as the prior probabilities p(Ck ), are modeled and usedto compute posterior probabilites using bayes theorem.
p(Ck | x) =p(x | Ck ) p(Ck )
p(x)
- This model develops the probability densities of the inputspace such that new examples can accurately begenerated.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Outline
1 The Classification ProblemDefining the problemApproaches in modeling
2 Discriminant Functionssimple model for two classesFisher Linear DiscriminantPerceptron
3 Probabilististic Discriminative ModelsLogistic Regression
4 Probabilististic Generative ModelsModeling conditional class probabilitiesBayes TheoremDiscrete Features
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Two class problem
y(x) = wT x + w0
where w is a weight vector of same dimension D as x.w0 is the bias or threshold (-w0).An input vector x is assigned to one of the two classes asfollows:
x →{
c0 if y(x) < 0c1 if y(x) ≥ 0
Decision boundary will be a hyperplane in D − 1dimensions
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Matrix notation
As a reminder of the convention: vectors are columnmatrices where
w =
w1w2...
wD
so wT =[
w1 w2 · · · wD]
and
wT x =[
w1 w2 · · · wD]
x1x2...
xD
= w1x1+w2x2+· · ·+wDxD
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Example: two dimensions, two classes
x2
x1
wx
y(x)‖w‖
x⊥
−w0‖w‖
y = 0y < 0
y > 0
R2
R1
y(x) = wT x + w0
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Multi-class (K > 2)
K-class discriminant comprised of K functions of the formyk (x) = wT
k + wk0Assign input vector as follows
x → ck where k = argmaxk∈{1,2.....}
yk (x)
Ri
Rj
Rk
xA
xB
x̂Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Learning parameter w
Three techniques for learning the parameter of the discriminantfunction, w.
Least Squares
Fisher’s linear discriminant
Perceptron
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Least Squares
Once again, each class, Ck , has it’s own linear model :yk (x) = wT
k x + wk0.
As a reminder of the convention: vectors are columnmatrices
w =
w1w2...
wD
so wT =[
w1 w2 · · · wD]
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Least Squares, compact notation
Let W̃ be a D + 1× K matrix whose columns represent thecolumn vector w̃ :
w̃ =
w0w1...
wD
Let x̃ be a D + 1× 1 column matrix (1, xT )T : x̃ =
1x1...
xD
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Least Squares, compact notation
The individual class discriminant functionsyk (x) = wT
k x + wk0
can be writteny(x) = W̃T x̃
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Least Squares, determining W̃
W̃ is determined by minimizing a sum-of-squares errorfunction whose form is given as:
E(w) =12
N∑n=1
{y(xn, w)− tn}2
Let X̃ be a n × (D + 1) matrix representing a training set ofn examples.
Let T be a n × k matrix representing the targets for the ntraining examples
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Least Squares, determining W̃
This yields the expression
ED(W̃) =12
Tr{
(X̃W̃− T)T (X̃W̃− T)}
To minimize, take the derivative with respect to W and setto zero to obtain
W̃ = (X̃T X̃)−1X̃T T = X̃†T
and finally the discriminant function
y(x) = W̃T x̃ = TT(
X̃†)T
x̃
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Least Squares, considerations
Under certain conditions, this model will have the propertythat the elements of y(x)will sum to 1 for any value of x.
However, since they are not constraint to lay on the interval(0, 1), meaning that negative numbers and numbers largerthan 1 might occur, then the elements cannot be treated asprobabilities.
Among other disadvantages, this approach has an“inappropriate” response to outliers.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Least Squares - Response to outliers
−4 −2 0 2 4 6 8
−8
−6
−4
−2
0
2
4
−4 −2 0 2 4 6 8
−8
−6
−4
−2
0
2
4
a) Well separated b) In the presence of outliersseveral misclassified examples
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Outline
1 The Classification ProblemDefining the problemApproaches in modeling
2 Discriminant Functionssimple model for two classesFisher Linear DiscriminantPerceptron
3 Probabilististic Discriminative ModelsLogistic Regression
4 Probabilististic Generative ModelsModeling conditional class probabilitiesBayes TheoremDiscrete Features
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Fisher’s Linear Discriminant in concept
An approach that reduces the dimensionality of the modelby projecting the input vector to a reduced dimensionspace.
Simple example, two dimensional input vectors, projecteddown to one
−2 2 6
−2
0
2
4
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Fisher’s Linear Discriminant
Start with a two class problem: y = wT x whose classmean vectors are given as.
m1 =1
N1
∑n∈C1
xn and m2 =1
N2
∑n∈C2
xn
Choose w to maximizem2 −m1 = wT (m2 −m1)
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Fisher’s Linear Discriminant
Maximizing the separation of the mean for each class
−2 2 6
−2
0
2
4
However, classes still overlap
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Fisher’s Linear Discriminant
Add the condition of minimizing the within-class variance,which is given as
s2k =
∑n∈Ck
(yn −mk )2
Fishers criterion is based on the maximization ofseparation of class mean with minimized within-classvariance.These two conditioned are captured in the ratio betweenthe variance of the class means and the within-classvariance, given by
J(w) =(m2 −m1)
2
s21 + S2
2
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Fisher’s Linear Discriminant
Casting this ratio back into terms of the original frame ofreference,
J(w) =wT SBwwT SBw
where SB = (m2 −m1)(m2 −m1)T and
Sw =∑n∈C1
(xn −m1)(xn −m1)T +
∑n∈C2
(xn −m2)(xn −m2)T
Take derivative with respect to w and set to zero to findminimum.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Fisher’s Linear Discriminant
derivative : (wT SBw)Sww = (wT Sww)SBw
Only direction of w is importantw ∝ S−1
w (m2 −m1)
To make this a discriminant function, y0 is chosen so that
x ∈{C1 if y(x) ≥ y0C2 if y(x) < y0
Cate Anderson Linear Models for Classification
university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
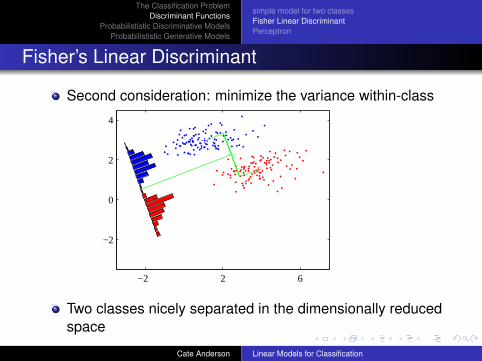
Fisher’s Linear Discriminant
Second consideration: minimize the variance within-class
−2 2 6
−2
0
2
4
Two classes nicely separated in the dimensionally reducedspace
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Outline
1 The Classification ProblemDefining the problemApproaches in modeling
2 Discriminant Functionssimple model for two classesFisher Linear DiscriminantPerceptron
3 Probabilististic Discriminative ModelsLogistic Regression
4 Probabilististic Generative ModelsModeling conditional class probabilitiesBayes TheoremDiscrete Features
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Perceptron
This model takes the form y(x) = f (wT Φ(x))
- where Φ is a transformation function that creates thefeature vector from the input vector.We will use the indentity transformation function tobegin our discussion.
- where f (·) is given by
f (a) =
{+1, a ≥ 0−1, a < 0.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Perceptron - The binary problem
There is a change in target coding: t is now a scaler, takingthe values or either 1 or -1.This value is interpreted as the input vector belonging toC1 if t = 1, else C2 when t = −1.In considering w, we want
xn ∈ C1 ⇒ wT Φ(xn) > 0 and
xn ∈ C2 ⇒ wT Φ(xn) ≤ 0
which means we want
∀xn ∈ X , wT Φ(xn)tn > 0
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Perceptron - weight update
The perceptron error
Ep(w) = −∑
n∈MwT Φntn
The perceptron update rule if x is misclassified
w(τ+1) = w(τ) − η 5 Ep(w) = w(τ) + ηΦntn
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Perceptron - example
−1 −0.5 0 0.5 1−1
−0.5
0
0.5
1
−1 −0.5 0 0.5 1−1
−0.5
0
0.5
1
a) Misclassified example b) w after update
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Perceptron - example
−1 −0.5 0 0.5 1−1
−0.5
0
0.5
1
−1 −0.5 0 0.5 1−1
−0.5
0
0.5
1
a) Next misclassified example b) w after update
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
Perceptron - consideration
The update rule is guaranteed to reduce the error from thatspecific example
It does not guarantee to reduce the error contribution fromthe other misclassified examples.
Could change previously correctly classified example tomisclassified.
However, the perceptron convergence theorem doesguarantee to find an exact solution if one exists
It will find this exact solution in a finite number of steps.
Cate Anderson Linear Models for Classification
university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
simple model for two classesFisher Linear DiscriminantPerceptron
review
We have seen
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
Outline
1 The Classification ProblemDefining the problemApproaches in modeling
2 Discriminant Functionssimple model for two classesFisher Linear DiscriminantPerceptron
3 Probabilististic Discriminative ModelsLogistic Regression
4 Probabilististic Generative ModelsModeling conditional class probabilitiesBayes TheoremDiscrete Features
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
A Logit - What is it when it’s at home
A logit is simply the natural log of the odds
Odds are simply the ratio of two probabilites
In a binary classification problem, the sum of the twoposterior probabilities sum to 1
If p(C1 | x) is the probability that x belongs to c1, thenp(C2 | x) = 1− p(C1 | x).
So the odds are
odds =p(C1 | x)
1− p(C1 | x)
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
A Logit - What benefits
Example: if an individual is 6 foot tall, then according tocensus data that probability that the individual is male is0.9.
This makes the probability of being female 1− 0.9 = 0.1
The odds on being male are 0.9/0.1 = 9.
However, the odds of being female are 0.1/0.9 = .11
The lack of symmetry is unappealing. Intuition wouldappreciate the odds on being female being the opposite ofthe odds on being male.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
A Logit - linear model
The natural log supplies this symmetry:ln(9.0) = 2.197ln(0.1) = −2.197
Now, if we assume that the logit is linear with respect to xwe have
logit(P) = ln(
P1− P
)= a + Bx
where a and B are parameters.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
from logit to sigmoid
From
logit(P) = ln(
P1− P
)= a + Bx
Exponentiate both sides
P = (1− P)e(a+Bx) = e(a+Bx) − Pe(a+Bx)
P + Pe(a+Bx) = e(a+Bx)
P(1 + e(a+Bx)) = e(a+Bx)
P =e(a+Bx)
1 + e(a+Bx)=
11 + e−(a+Bx)
where a is the probability when x is zero and B adjusts therate that the probability changes with x .
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
The sigmoid
Sigmoid mean S-shapedAlso called a “squashing function” because it maps a verylarge domain into the relatively small interval (0, 1).
−5 0 50
0.5
1
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
The model
The posterior probability of C1 can be written
p(C1 | Φ) = y(Φ) = σ(wT Φ) =1
1 + e−(wT Φ)
w must be learned by adjusting its M components ( inputvector has length M)
weight update:
w(τ+1) = w(τ) − η 5 En
where
5E(w) =N∑
n=1
(yn − tn)Φn and 5 En = (yn − tn)Φn
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
Maximum Likelihood
Maximum likelihood: the probability p(t | w), which readthe probability of the observed data set given theparameter vector w.This can be calculated by taking the product of individualprobabilities of the class assigned to each xn ∈ D agreeingwith tn.
p(t | w) =N∏
n=1
p(cn = tn | x)
where tn = {0, 1} and
p(cn = tn | x) =
{p(c1 | Φn) if cn = 1
1− p(c1 | Φn) if cn = 0
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
Maximum Likelihood
Since the target is either 1 or 0, this allows for amathematically convenient expression for this product
p(t | w) =N∏
n=1
(p(c1 | Φn))tn(1− p(c1 | Φn))
(1−tn)
From p(C1 | Φ) = y(Φ) = σ(wT Φ)
p(t | w) =N∏
n=1
(y(Φ))tn(1− y(Φ))(1−tn)
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
Maximum Likelihood and error
The negative log of the maximum likelihood function is
E(w) = − ln p(t | w) = −N∑
n=1
(tn ln yn + (1− tn) ln(1− yn))
The gradient of this is
∆E(w) =d
dw(− ln p(t | w))
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
Maximum Likelihood and error
∆E(w) = −N∑
n=1
ddw
(tn ln yn + (1− tn) ln(1− yn))
= −N∑
n=1
tnyn
dyn
dw+
(1− tn)(1− yn)
d(1− yn)
dw
= −N∑
n−1
(tnyn
Φnyn(1− yn) +(1− tn)(1− yn)
(−Φnyn(1− yn))
)
= −N∑
n=1
(tn − tnyn − yn + tnyn)Φn =N∑
n=1
(yn − tn)Φn
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
Logistic regression model
The model based on maximum likelihood
p(C1 | Φ) = y(Φ) = σ(wT Φ) =1
1 + e−(wT Φ)
weight update based on gradient of maximum likelihood:
w(τ+1) = w(τ) − η 5 En = w(τ) + η((yn − tn)Φn)
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Logistic Regression
A new model
The model based on literative reweighted least squares
p(C1 | Φ) = y(Φ) = σ(wT Φ) =1
1 + e−(wT Φ)
weight update based on a Newton-Raphson iterativeoptimization scheme:
wnew = wold − H−1 5 E(w)
The Hessian H, is a matrix whose elements are are thesecond derivatives of E(w) with respect to w.This is an Numerical analysis technique which is analternative to the first one covered.Faster convergence at the cost of more computationalyexpense steps is the trade off.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Outline
1 The Classification ProblemDefining the problemApproaches in modeling
2 Discriminant Functionssimple model for two classesFisher Linear DiscriminantPerceptron
3 Probabilististic Discriminative ModelsLogistic Regression
4 Probabilististic Generative ModelsModeling conditional class probabilitiesBayes TheoremDiscrete Features
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Probabilistic Generative Models: The approach
This approach tends to be more computationallyexpensive.The training data and any information on the distribution ofthe training data within input space is used to model theclass conditional probabilities.Then using Bayes Theorem, the posterior probability iscalculated.The descision of label is made by choosing the maximumposterior probability.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Modeling class conditional probabilities with priorprobabilities
The class conditional probability is given by p(x | ck ) and isread the probability of x given the class ck .
The prior probability p(ck ) which is the probability of ckindependent of any other variable.
The probability p(xn, c1) = p(c1)p(xn | c1)
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Specific case of Binary label
Let tn = 1 → c1 and tn = 0 → c2
Let p(c1) = π so p(c2) = 1− π
Let each class have a Gaussian class-conditional densitywith shared covariance matrix.
N (x | µ, Σ) =1
(2π)D/21
|Σ|1/2 exp{−1
2(x− µ)T Σ−1(x− µ)
}where µ is a D-dimensional mean vector,
Σ is a D × D covariance matrix,and |Σ| is the determinant of Σ.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Specific case of Binary label
The conditional probabilities for each class are
p(c1)p(xn | c1) = πN (x | µ1, Σ)
p(c2)p(xn | c2) = (1− π)N (x | µ2, Σ)
The likelihood function is given by
p(t | π,µ1,µ2,Σ) =N∏
n=1
[πN (xn | µ1, Σ)]tn [(1−π)N (xn | µ2, Σ)]1−tn
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Specific case of Binary label
The error for this is the negative log of the likelihood
−N∑
n=1
(tn ln π + (1− tn) ln(1− π))
We minimize this by setting the derviative with respect to πto zero and solve for π.
π =1N
N∑n=1
tn =N1
N=
N1
N1 + N2
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Outline
1 The Classification ProblemDefining the problemApproaches in modeling
2 Discriminant Functionssimple model for two classesFisher Linear DiscriminantPerceptron
3 Probabilististic Discriminative ModelsLogistic Regression
4 Probabilististic Generative ModelsModeling conditional class probabilitiesBayes TheoremDiscrete Features
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Review of Bayes Theorem
P(ck | x) =P(x | ck )P(ck )
P(x)
P(x) is the prior probability that x will be observed,meaning the probability of x given no knowledge aboutwhich ck is observed.It can be seen that as P(x) increases,P(ck | x) decreases,indicating that the higher a probability of an incidentindependent of any other factor, the lower the probability ofthat incident dependent on another condition.
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Review of Bayes Theorem
P(x | ck ) is the class conditional probability that x will beobserved once class ck is observed.Both P(x | ck ) and P(ck ) have been modeledNow P(ck | x), A posterior probability, can be calculatedThe label is assigned as the class that generates theMaximum A Posterior (MAP) probability for the input vector
cMAP ≡ argmaxck∈C
P(ck | x) = argmaxck∈C
P(x | ck )P(ck )
P(x)
cMAP ≡ argmaxck∈C
P(x | ck )P(ck )
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Review of Bayes Theorem
P(x | ck ) is the class conditional probability that x will beobserved once class ck is observed.Both P(x | ck ) and P(ck ) have been modeledNow P(ck | x), A posterior probability, can be calculatedThe label is assigned as the class that generates theMaximum A Posterior (MAP) probability for the input vector
cMAP ≡ argmaxck∈C
P(ck | x) = argmaxck∈C
P(x | ck )P(ck )
P(x)
cMAP ≡ argmaxck∈C
P(x | ck )P(ck )
Cate Anderson Linear Models for Classification
university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Outline
1 The Classification ProblemDefining the problemApproaches in modeling
2 Discriminant Functionssimple model for two classesFisher Linear DiscriminantPerceptron
3 Probabilististic Discriminative ModelsLogistic Regression
4 Probabilististic Generative ModelsModeling conditional class probabilitiesBayes TheoremDiscrete Features
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Discrete feature Values
Each x is made up of an ordered set of feature values:x = {a1, a2, . . . , ai) where i = number of attributes.
Sample problem: Aunt Lacee’s Libraryx = {“book”, “Origin of Species”, 1500-1900, “biology,” “mint”, . . .}
Each attribute has as set of allowed valuesa1 ∈ {book, paperback, parchment, comic}.a3 ∈ {<1200, 1200-1500, 1500-1900, 1900-1930,
1930-1960, 1960-current}
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Naïve Bayes assumption
Assume that the attributes are conditionally independent.P(x | ck ) = P(a1, a2, . . . , ai | ck ) =
∏i P(ai | ck )
where any given P(ai | ck ) = number of instances intraining set with same ai value and target value ck dividedby number of instances with target ck .P(ck ) is the number of instances with target = ck dividedby total number of instances.
Final label is determined by naïve Bayes
cNB = argmaxck∈{c1,c2}
P(ck )∏
i
P(ai | ck )
Cate Anderson Linear Models for Classification

university-logo
The Classification ProblemDiscriminant Functions
Probabilististic Discriminative ModelsProbabilististic Generative Models
Modeling conditional class probabilitiesBayes TheoremDiscrete Features
Review
Discriminant functionsLeast SquaresPerceptron
Probabilistic Discriminant FunctionsLogistic Regression
- With maximum likelihood error approximation- With Newton-Raphson approach to error
approximationProbabilistic Generative Functions
Gaussian class conditional probabilitesDiscrete Attribute values with the Naïve Bayes Classifier
Cate Anderson Linear Models for Classification


















