
Lessons learned from Large Scale Real World Recommender Systems
22
Lessons Learned from Large Scale Real World Recommender Systems Chris Alvino March 8, 2017 Director of Personalization, ipsy
-
Upload
chrisalvino -
Category
Engineering
-
view
79 -
download
1
Transcript of Lessons learned from Large Scale Real World Recommender Systems

Lessons Learned from Large Scale Real World Recommender
SystemsChris Alvino
March 8, 2017
Director of Personalization, ipsy

Page RecommendationsProblem: Form hundreds of millions of daily
refreshed personalized home pages
It’s not a grid, it’s LoLoMo*
Challenges:
- Fast (< 5 ms) response but with large amounts
of computation (> 2s) per page
- Balancing relevance and diversity
- Balancing different use cases, e.g. discovering,
continue watching, rewatching, etc.
Source: http://techblog.netflix.com/2015/04/learning-personalized-homepage.htmlLoLoMo = Lists of Lists of Movies

Glam Bag PersonalizationWhat is a Glam Bag? ipsy’s monthly subscription offering,
featuring 5 beauty products in themed make-up bag
Inspires individuals around world to express their inner beauty
2.5+ million monthly Glam Bag subscribers
YouTube-style content creators promoting products and
building sense of community
eCommerce app, “ipsy Shopper” often featuring cash back
Significant use of NLP in the Shopper application
~ 230 employees in San Mateo, New York, Santa Monica

Glam Bag Personalization2.5+ million monthly Glam Bags shipped
40-50 different products per month
Products rarely repeat (“item cold start” every month)
Members “get what they get” (no returns)
A/B testing challenging (subscriber experiences not
independent)
Heavy use of ML and two stages combinatorial optimization

What is this talk?/Feel Good Moment
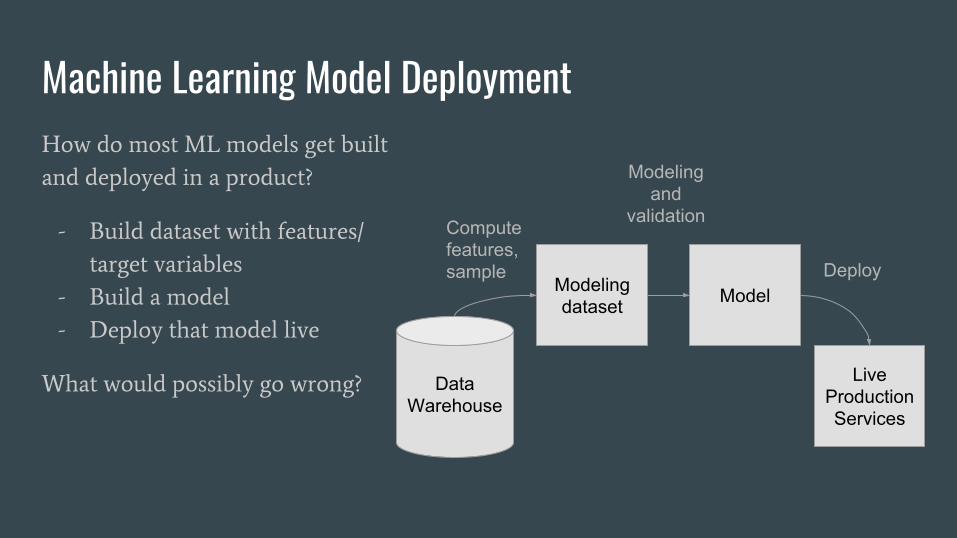
Machine Learning Model DeploymentHow do most ML models get built
and deployed in a product?
- Build dataset with features/
target variables
- Build a model
- Deploy that model live
What would possibly go wrong? DataWarehouse
Modeling dataset Model
Live Production Services
Compute features, sample Deploy
Modeling and
validation
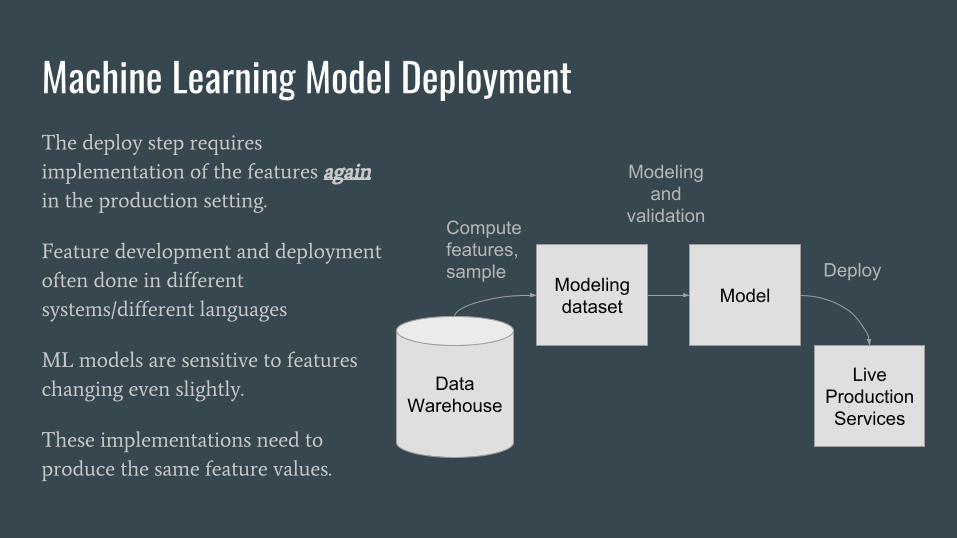
Machine Learning Model DeploymentThe deploy step requires
implementation of the features again
in the production setting.
Feature development and deployment
often done in different
systems/different languages
ML models are sensitive to features
changing even slightly.
These implementations need to
produce the same feature values.
DataWarehouse
Modeling dataset Model
Live Production Services
Compute features, sample Deploy
Modeling and
validation
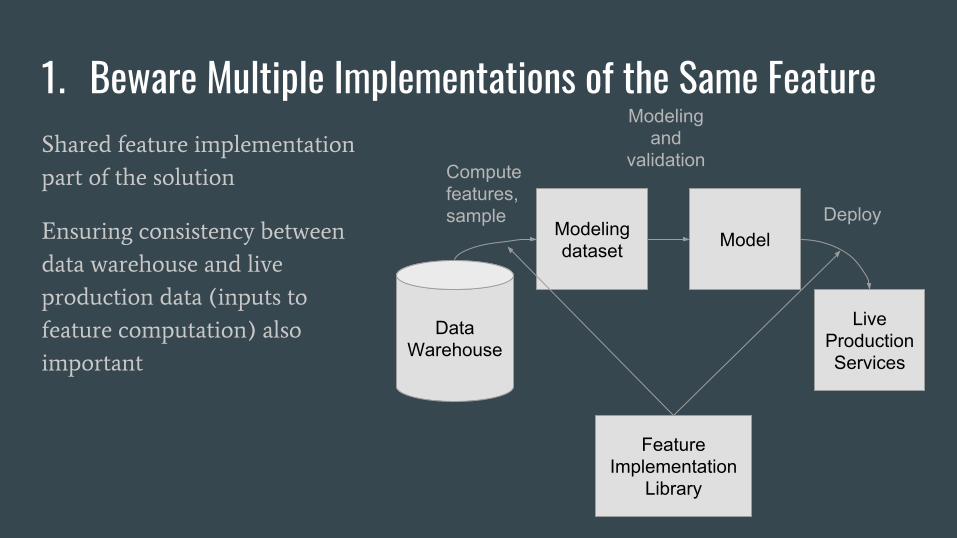
1. Beware Multiple Implementations of the Same FeatureShared feature implementation
part of the solution
Ensuring consistency between
data warehouse and live
production data (inputs to
feature computation) also
important
DataWarehouse
Modeling dataset Model
Live Production Services
Compute features, sample Deploy
Modeling and
validation
Feature Implementation
Library

2. Use Appropriate “Mathematical Interfaces” For RobustnessSample Recommender System:
- Build subsystem that for every
(user,product) tuple, returns
relevance score (possibly
separate team)
- Use that relevance score for
building X part of product (e.g.
building a personalized page)
- Home page component makes
many calls to relevance model
Relevance model
Build personalized home page
(user, product)Classifier output (e.g. probability of play)
(user)Personalized home page
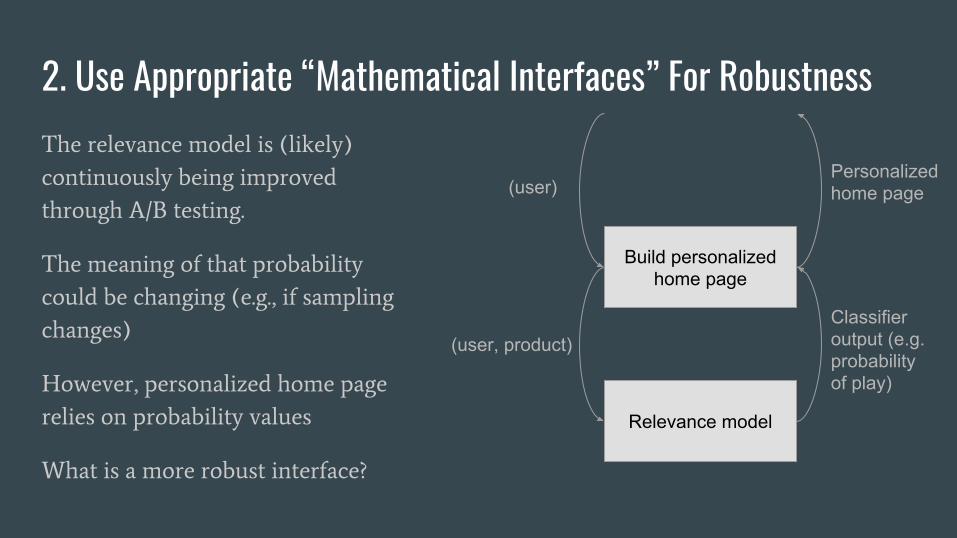
The relevance model is (likely)
continuously being improved
through A/B testing.
The meaning of that probability
could be changing (e.g., if sampling
changes)
However, personalized home page
relies on probability values
What is a more robust interface?
2. Use Appropriate “Mathematical Interfaces” For Robustness
Relevance model
Build personalized home page
(user, product)Classifier output (e.g. probability of play)
(user)Personalized home page
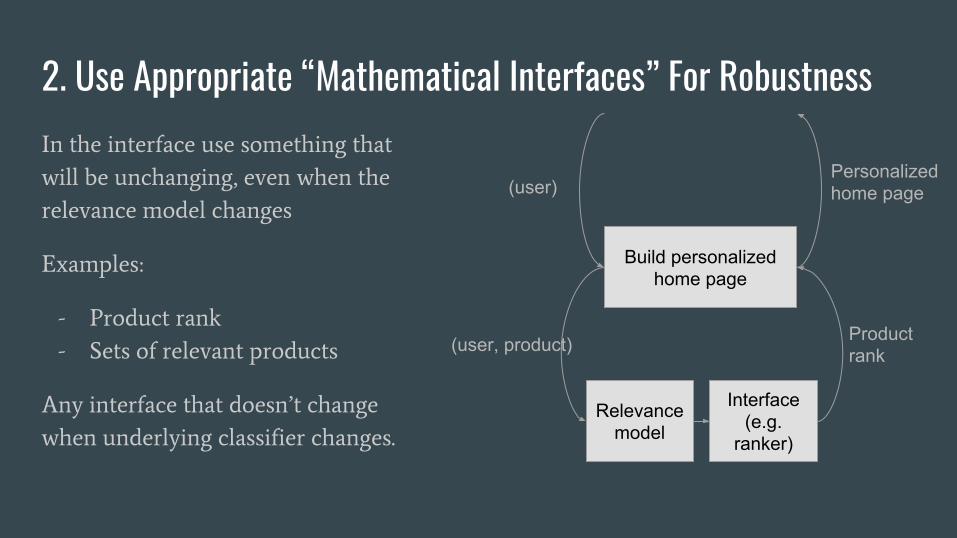
In the interface use something that
will be unchanging, even when the
relevance model changes
Examples:
- Product rank
- Sets of relevant products
Any interface that doesn’t change
when underlying classifier changes.
2. Use Appropriate “Mathematical Interfaces” For Robustness
Relevance model
Build personalized home page
(user, product) Product rank
(user)Personalized home page
Interface (e.g.
ranker)

3. Be Religious about A/B testing

3. Be Religious about A/B testingWe use A/B tests to assess causality, i.e.
determine whether a change actually
improves product/metrics/KPIs (in
probability)
In theory it’s a solid way to improve
your product
In practice there’s many ways it can be
done incorrectly...
Non-test users (current production model) All users
(test model rolled out)
Control users
Test users
time
users
roll out decision

3a. Be Religious about A/B testing: Early StoppingDangers of early rollouts / early stopping:
● Type I error (false positive rate) goes up!!!
● Early stopped tests might not capture weekend/weekday
variability, day of month variability (e.g., when people get
payed)
Solutions:
● Even if you roll out, finish the test with original cohorts
● Can also use sequential testing
● Analytics teams should not allow peeking at tests unless there is
discipline within company to not roll out early
Non-test users (current
production model)
Non-test users
(test model rolled out)
Control users
Test users
time
users
roll out decision

3b. Be Religious about A/B testing: Non-Inferiority TestingReferring to standard comparative A/B test:
“We’ll roll it out even if it’s flat” -- Aggressive PM
Control Test
Retention

3b. Be Religious about A/B testing: Non-Inferiority TestingReferring to standard comparative A/B test:
“We’ll roll it out even if it’s flat” -- Aggressive PM
Often happens when there are side benefits to
rolling out a test, e.g., when a test results in:
- Reduced costs/operational benefits
- Reduced engineering complexity
- Placing the product in a better position for
future ideas
- Advancing someone’s career
Retention
Control Test

3b. Be Religious about A/B testing: Non-Inferiority TestingYou can make this type of testing arbitrarily easy
to achieve (and arbitrarily bad for your product)
by simply undersampling/making error-bars large.
Retention
Control Test

3b. Be Religious about A/B testing: Non-Inferiority TestingRight thing to do is a
non-inferiority test
Set a threshold, , for
how much metric
harm you are willing
to accept
Measure probability
of being bad or
worse
Source: Walker and Nowacki: Understanding Equivalence and Non-inferiority testinghttps://www.ncbi.nlm.nih.gov/pmc/articles/PMC3019319/

Do not: Place different types of users in different cohorts.
A/B test designs with users cohorted based on:
- time of day of signup
- based on availability of customer service chat agents
- based on geographic location
- many more
… caused/would have caused a false result and a failed A/B
test.
3c. Avoid A/B Test Biases
Random decision
Test (B)Control (A)
Users or Sessions
Do: Cohort users at random.

4. Don’t Understimate the Value of Diversity (vs. Relevance)In all recommender systems
I’ve worked on, diversity has
helped a lot…
… even hacked diversity.
Optimizing jointly for
relevance and diversity hard
Greedy techniques based on
submodular objective
functions* work well/have
optimality guarantees
Item 1 Item 2 Item 3 Item 4
P(Item1 Selected)
P(Item2 Selected | Item1 Not Selected)
P(Item3 Selected | Item1 nor
Item2 Selected)
etc.
*Ahmed et al. Fair and Balanced: Learning to Present News Stories: http://dl.acm.org/citation.cfm?id=2124337&dl=ACM&coll=DL&CFID=736745878&CFTOKEN=68130463

5. (Very) Simple Ideas Often Result in Most of the GainOften you don’t need deep learning.
Often you don’t need matrix factorization.
Sometimes you don’t even need a trained
model.
In large scale real world RecSys favor ideas
with least moving parts that get the job
done
Story about VSARO - Video Score
Adaptive Row Ordering or …

QuestionsHappy International Women’s Day!
We are hiring! http://careers.ipsy.com
Roles available:
- Senior Mobile Engineers
- Senior Software Engineers
- Senior Data Engineers


















