
Lecture5: Lossless Compression Techniqueseee.guc.edu.eg/Courses/Communications/COMM901... ·...
30
SOURCE CODING PROF. A.M.ALLAM LECTURES 10/15/2016 1 Lecture5: Lossless Compression Techniques Fixed to variable mapping: we encoded source symbols of fixed length into variable length code sequences Source Symbol s k Symbol Probability P k Code I Code II Symbol Code , Word c k Code Word Length l k Symbol Code Word c k Code Word Length l k s 0 1/2 00 2 0 1 s 1 1/4 01 2 10 2 s 2 1/8 10 2 110 3 s 3 1/8 11 2 1111 4 Variable to fixed mapping encode variable length source sequences into a fixed length code words Variable to variable mapping encode variable length source sequences into a variable length code words Fixed to fixed mapping: we encoded source symbols of fixed length into fixed length code sequences
Transcript of Lecture5: Lossless Compression Techniqueseee.guc.edu.eg/Courses/Communications/COMM901... ·...

SOURCE CODING PROF. A.M.ALLAM
LECTURES 10/15/2016 1
Lecture5: Lossless Compression Techniques
Fixed to variable mapping: we encoded source symbols of fixed length into variable length code
sequences
Source Symbol sk Symbol
Probability
Pk
Code I Code II
Symbol Code ,
Word ck
Code Word
Length lk
Symbol Code
Word ck
Code Word
Length lk
s0 1/2 00 2 0 1
s1 1/4 01 2 10 2
s2 1/8 10 2 110 3
s3 1/8 11 2 1111 4
Variable to fixed mapping encode variable length source sequences into a fixed length code
words
Variable to variable mapping encode variable length source sequences into a variable length code
words
Fixed to fixed mapping: we encoded source symbols of fixed length into fixed length code sequences

SOURCE CODING PROF. A.M.ALLAM
LECTURES 10/15/2016
Shannon Fano Code
It is a technique for constructing a prefix code based on a set of symbols and their probabilities (estimated or measured)
1-Source symbols are listed in order of decreasing probability from left to right
4-Recursively apply the steps 2 and 3 to each of the two halves, subdividing groups and adding bits to the codes until each symbol has become a corresponding code leaf on the tree
2-Divide the list into two parts, with the total probability (or frequency of occurrence) of the left
part being as close to the total of the right as possible
3-The left part of the list is assigned the binary digit 0, and the right part is assigned the digit 1
This means that the codes for the symbols in the first part will all start with 0, and the codes in the
second part will all start with 1
Algorithm
It is suboptimal in the sense that it does not achieve the lowest
possible expected code word length
The technique was proposed by Claude Shannon and was
attributed to Robert Fano
Lecture5: Lossless Compression Techniques
2

SOURCE CODING PROF. A.M.ALLAM
Ex: Assume a sequence of alphabet A={ a , b , c , d , e , f } with the following occurrence
weights, {9, 8, 6, 5, 4, 2} respectively. Apply Shannon Fano coding and discuss the
suboptimality
LECTURES 10/15/2016
Shannon Fano Code Lecture5: Lossless Compression Techniques
3

SOURCE CODING PROF. A.M.ALLAM
LECTURES 10/15/2016
Shannon Fano Code Lecture5: Lossless Compression Techniques
4
17 17

SOURCE CODING PROF. A.M.ALLAM
Shannon Fano Code Lecture5: Lossless Compression Techniques
5

SOURCE CODING PROF. A.M.ALLAM
LECTURES 10/15/2016
Shannon Fano Code Shannon Fano Code Lecture5: Lossless Compression Techniques
6

SOURCE CODING PROF. A.M.ALLAM
LECTURES 10/15/2016
Shannon Fano Code Lecture5: Lossless Compression Techniques
7

SOURCE CODING PROF. A.M.ALLAM
4
0 1
2
0 1
e f
LECTURES 10/15/2016
Shannon Fano Code Lecture5: Lossless Compression Techniques
8

SOURCE CODING PROF. A.M.ALLAM
LECTURES 10/15/2016
K
k
kk lPL1
symbolbitsxxL /5.2)058.0118.0147.0176.0(3)265.0235.0(2
Symbol Frequency P CODE
a 9 0.265 00
b 8 0.235 01
c 6 0.176 100
d 5 0.147 101
e 4 0.118 110
f 2 0.059 111
Shannon Fano Code Lecture5: Lossless Compression Techniques
9

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code
In general, Huffman coding is a form of statistical coding as not
all characters occur with the same frequency (Probability)
Huffman code is a prefix, variable length code that can achieve the shortest average code length for a given input alphabet with pmf
The process of finding the optimal code was algorithmized by Huffman
It is commonly used for lossless compressions
A code is an optimal prefix code if it has the same average codeword
length as a Huffman code for the given pmf
Lecture5: Lossless Compression Techniques
Huffman procedure is based on two observations regarding optimum prefix codes:
1- Symbols that occur more frequently (have a higher probability of occurrence) will have
shorter codewords than symbols that occur less frequently
2-The two symbols that occur least frequently will have the same length
10

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
Consider the following short text Ex:
Eerie eyes seen near lake
Build Huffman tree to encode the text
-Get the count of each letter
- Sort from lowest to highest count
11

SOURCE CODING PROF. A.M.ALLAM
Huffman Code Lecture5: Lossless Compression Techniques
- Create a new node as the sum of the lowest two count
12

SOURCE CODING PROF. A.M.ALLAM
Huffman Code Lecture5: Lossless Compression Techniques
- Create a new node as the sum of the lowest two count
13
- Locate the node at its precedence and create a new one

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
- Locate the node at its precedence and create a new one
14

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
15

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
16

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
17

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
18

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
19

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
20

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
21

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
22

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
23

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
The frequency of the root node should equal to the number of characters in the text
0 1
0 1
0 1
0 1 0 1
0 1
0 1
0 1
0 1
0 1 0 1
24
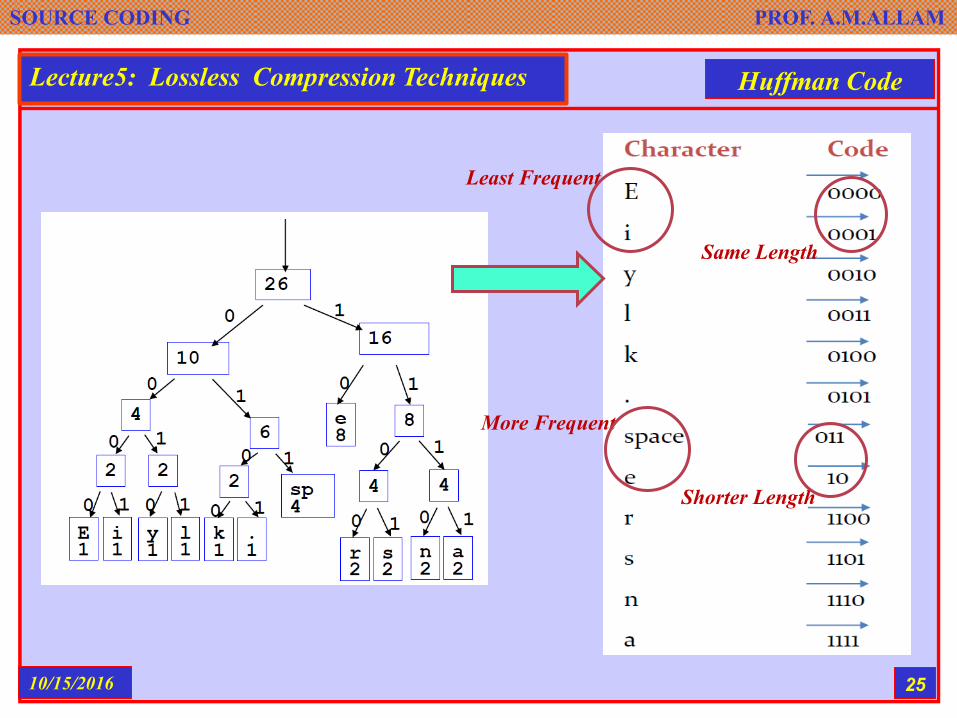
SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
Shorter Length
More Frequent
Same Length
Least Frequent
25

SOURCE CODING PROF. A.M.ALLAM
10/15/2016
Huffman Code
1-Source symbols are listed in order of decreasing probability (frequency)
4-The probability of the new symbol is placed in the list in accordance with its value
The steps are repeated until we are left with a final list of source statistics of only two for which a 0 and a 1 are assigned
2-The two source symbols of lowest probability are assigned a 0 and 1(splitting stage )
3-These two source symbols are combined into a new source symbol with probability
equal to the sum of the two original probabilities (The list of source symbols and
therefore source statistics is thereby reduced in size by one)
Huffman Algorithm
Lecture5: Lossless Compression Techniques
26

SOURCE CODING PROF. A.M.ALLAM
LECTURES 10/15/2016
Huffman Code Lecture5: Lossless Compression Techniques
Ex: Find the Huffman code for the following source given the corresponding probabilities; marginal pmf
S2 0.4
S1 0.2
S3 0.2
So 0.1
S4 0.1
0
1
0.2
0.2
0.2
0.4
0.2
0
1
0.4
0.4
0.4
0.2 1
0.6
0.6
0.4 0
0
1
36.1)(1
22
K
k
kk LlP
So 0.1
S1 0.2
S2 0.4
S3 0.2
S4 0.1
1
01
000
0010
0011
364.12.2
3CR
27
12193.2)1.0
1(log)1.0(2)
2.0
1(log)2.0(2)
4.0
1(log)4.0()( 222 xxxsH
)(2.241.041.032.032.014.0 sHxxxxxL

SOURCE CODING PROF. A.M.ALLAM
LECTURES 10/15/2016
Alternative solution
Hence, to obtain a minimum variance Huffman code, we always
put the combined symbol as high in the list as possible
Huffman Code Lecture5: Lossless Compression Techniques
So 0.1
S1 0.2
S2 0.4
S3 0.2
S4 0.1
S2 0.4
S1 0.2
S3 0.2
So 0.1
S4 0.1
0
1
0.2
0.2
0.2
0.4
0.2
0
1
0.4
0.4
0.4
0.2 1
0.6
0.6
0.4 0
0
1
00
10
11
010
011
364.12.2
3CR
16.0)(1
22
K
k
kk LlP
28
12193.2)1.0
1(log)1.0(2)
2.0
1(log)2.0(2)
4.0
1(log)4.0()( 222 xxxsH
)(2.231.031.022.022.024.0 sHxxxxxL

SOURCE CODING PROF. A.M.ALLAM
LECTURES 10/15/2016
Huffman encoding process (Huffman tree) is not unique Conclusions
The code with the lowest code length variance is the best because it ensure
the least amount of variability in the encoded stream
Huffman code process is optimal if:
1)()( SHLSH
In fact (from literatures), it can be shown that if Pmax is the largest
probability in the probability model,
then for Pmax ≥ 0.5,
while for Pmax < 0.5
max)()( PSHLSH
086.0)()( max PSHLSH
Tighter bound
Looser bound
An encoding scheme that minimizes the average length is called optimal coding
Huffman Code Lecture5: Lossless Compression Techniques
The average codeword length is equal to the marginal entropy if all
marginal probabilities are integer powers of 2
29

SOURCE CODING PROF. A.M.ALLAM
LECTURES 10/15/2016
Huffman vs. Shannon
K
k
kk lPL1 symbolbits
xxxL
/470.2704.0441.0352.1
)058.0118.0(4147.03)176.0265.0235.0(2
Symbol Frequency P
a 9 0.265
b 8 0.235
c 6 0.176
d 5 0.147
e 4 0.118
f 2 0.059
01
0
1
0.176
0.176
0.235
0.147
0
1
0.321
0.265
0.235
0.176 1
0.321
0.265 0
0.265 0.411
1
0
0
1
10
11
001
0000
0000
The average code length is less than that of Shannon Fano code,
Hence Huffman is optimum, but Shannon is suboptimal
Lecture5: Lossless Compression Techniques
30


















