
Lecture 1 CSE 260 – Parallel Computation (Fall 2015) Scott ...
34
Lecture 1 CSE 260 – Parallel Computation (Fall 2015) Scott B. Baden Introduction
Transcript of Lecture 1 CSE 260 – Parallel Computation (Fall 2015) Scott ...

Lecture 1 CSE 260 – Parallel Computation
(Fall 2015) Scott B. Baden
Introduction

2
Welcome to CSE 260! • Your instructor is Scott Baden
u [email protected] u Office hours in EBU3B Room 3244
• Today at 3.30, next week TBA (or make appointment)
• Your TA is Siddhant Arya u [email protected]
• The class home page is
http://www.cse.ucsd.edu/classes/fa15/cse260-a
• Course Resources u Piazza (Moodle for grades) u Stampede @ TACC
Create an XSEDE portal account if you don’t have one u Bang @ UCSD
Scott B. Baden / CSE 260, UCSD / Fall '15

• How to solve computationally intensive problems on parallel computers effectively: multicore processors, GPUs, clusters u Parallel programming: multithreading, message passing,
vectorization, accelerator programming (OpenMP, CUDA, SIMD)
u Parallel algorithms: discretization, sorting, linear algebra, sorting; communication avoiding algorithms (CA); irregular problems
u Performance programming: latency hiding, managing locality within complicated memory hierarchies, load balancing, efficient data motion
What you’ll learn in this class
Scott B. Baden / CSE 260, UCSD / Fall '15 3

4
Background • CSE 260 will build on your existing background,
generalizing programming techniques, algorithm design and analysis
• Background u Graduate standing u Recommended undergrad background: Computer
Architecture & Operating Systems, C/C++ programming u I will level the playing field for non-CSE students; see
me if you are unsure about your background • Your background
u CSME? u Parallel computation? u Numerical analysis?
Scott B. Baden / CSE 260, UCSD / Fall '15

5
Background Markers • C/C++ Java Fortran? • TLB misses • MPI • RPC • Multithreading • CUDA, GPUs • Abstract base class • Navier Stokes Equations • Sparse factorization €
∇ • u = 0DρDt
+ ρ ∇ •v( ) = 0
€
f (a) +" f (a)1!
(x − a) +" " f (a)2!
(x − a)2 + ...
Scott B. Baden / CSE 260, UCSD / Fall '15

6
Course Requirements • 5 assignments
u Pre-survey and Registration: due Sunday @ 9pm
u 3 Programming labs • Teams of 2, option to switch teams• Find a partner using the
“looking for a partner” Moodle forum• Includes a lab report, greater emphasis (grading)
with each labu 1 in class test toward the end of the course
Scott B. Baden / CSE 260, UCSD / Fall '15

7
Text and readings • Required texts
u Programming Massively Parallel Processors: A Hands-on Approach, 2nd Ed., by David Kirk and Wen-mei Hwu, Morgan Kaufmann Publishers (201w)
u An Introduction to Parallel Programming, by Peter Pacheco, Morgan Kaufmann (2011)
• Assigned class readings will also include on-line materials
• Lecture slides www.cse.ucsd.edu/classes/fa15/cse260-a/Lectures
Scott B. Baden / CSE 260, UCSD / Fall '15

8
Policies • Academic Integrity
u Do you own work u Plagiarism and cheating will not be tolerated
• By taking this course, you implicitly agree to abide by the following the course polices: www.cse.ucsd.edu/classes/fa15/cse260-a/Policies.html
Scott B. Baden / CSE 260, UCSD / Fall '15

• Class participation is important to keep the lecture active
• Consider the slides as talking points, class discussions driven by your interest
• Complete the assigned readings before lecture and be prepared to discuss in class
• Different lecture modalities u The 2 minute pause u In class problem solving
Classroom participation
Scott B. Baden / CSE 260, UCSD / Fall '15 9

• Opportunity in class to develop your understanding, of lecture u By trying to explain to someone else u Getting your brain actively working on it
• What will happen u I pose a question u You discuss with 1-2 people around you
• Most important is your understanding of why the answer is correct
u After most people seem to be done • I’ll ask for quiet • A few will share what their group talked about
– Good answers are those where you were wrong, then realized…
The 2 minute pause
Scott B. Baden / CSE 260, UCSD / Fall '15 10

• Principles • Technological disruption and its impact • Motivation – applications
An Introduction to Parallel Computation
Scott B. Baden / CSE 260, UCSD / Fall '15 11

12
What is parallel processing? • We decompose a workload onto simultaneously
executing physical processing resources to improve some aspect of performance u Speedup: 100 processors run ×100 faster than one u Capability: Tackle a larger problem, more accurately u Algorithmic, e.g. search u Locality: more cache memory and bandwidth
• Multiple processors co-operate to process a related set of tasks – tightly coupled
• Generally requires some form of communication and/or synchronization to manage the workload distribution
Scott B. Baden / CSE 260, UCSD / Fall '15

Have you written a parallel program? • Threads • MPI • RPC • C++11 Async • CUDA
Scott B. Baden / CSE 260, UCSD / Fall '15 13

The difference between Parallel Processing, Concurrency & Distributed Computing
• Parallel processing u Performance (and capacity) is the main goal u More tightly coupled than distributed computation
• Concurrency u Concurrency control: serialize certain computations to ensure
correctness, e.g. database transactions u Performance need not be the main goal
• Distributed computation u Geographically distributed u Multiple resources computing & communicating unreliably u “Cloud” computing, large amounts of storage, different from
clusters in the cloud u Looser, coarser grained communication and synchronization
• May or may not involve separate physical resources, e.g. multitasking “Virtual Parallelism”
Scott B. Baden / CSE 260, UCSD / Fall '15 14

Granularity
• A measure of how often a computation communicates, and what scale u Distributed computer: a whole program u Multicomputer: function, a loop nest u Multiprocessor: + memory reference u Multicore: a single socket implementation of a
multiprocessor u GPU: kernel thread u Instruction level parallelism: instruction,
register
15 Scott B. Baden / CSE 260, UCSD / Fall '15

• Principles • Technological disruption and its impact • Motivation – applications
An Introduction to Parallel Computation
Scott B. Baden / CSE 260, UCSD / Fall '15 16

Why is parallelism inevitable? • Physical limitations on heat dissipation impede
processor clock speed increases • To make the processor faster, we replicate the
computational elements
Scott B. Baden / CSE 260, UCSD / Fall '15 18
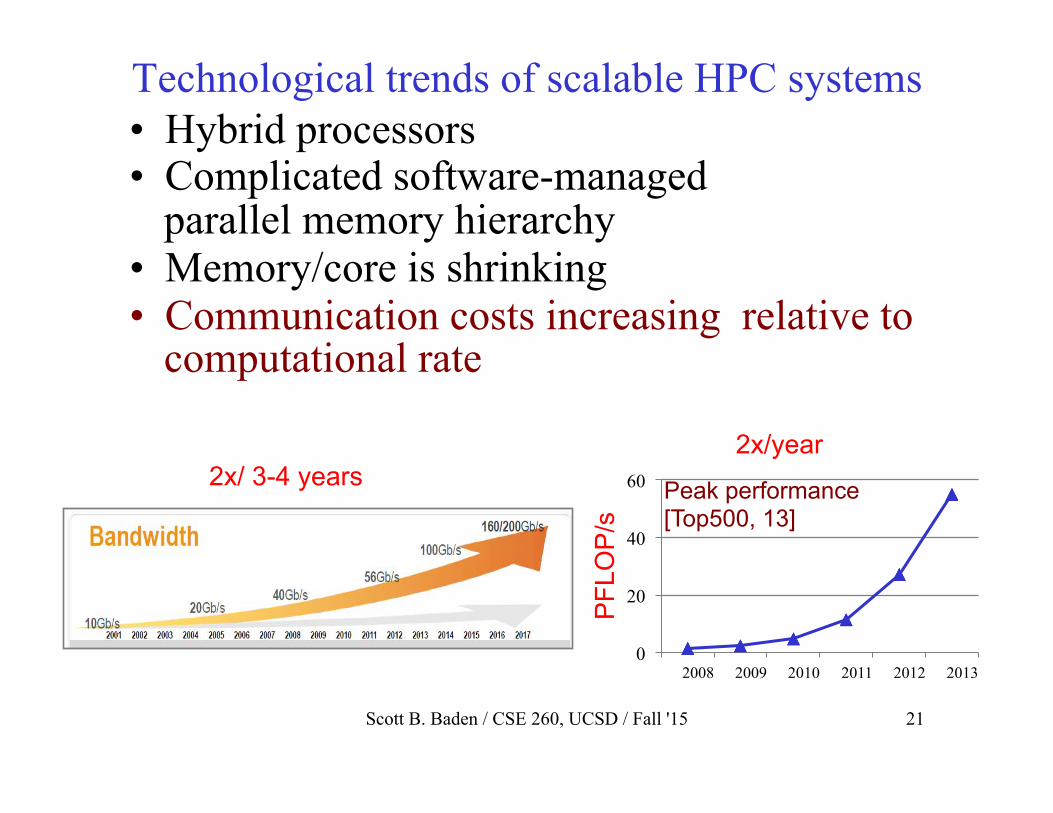
Technological trends of scalable HPC systems • Hybrid processors • Complicated software-managed
parallel memory hierarchy • Memory/core is shrinking • Communication costs increasing relative to
computational rate
Peak performance [Top500, 13]
0
20
40
60
2008 2009 2010 2011 2012 2013
2x/year
PFL
OP
/s
2x/ 3-4 years
PFL
OP
/s
Scott B. Baden / CSE 260, UCSD / Fall '15 21

23 9/25/15 23
The age of the multi-core processor • On-chip parallel computer • IBM Power4 (2001), many others follow
(Intel, AMD, Tilera, Cell Broadband Engine) • First dual core laptops (2005-6) • GPUs (nVidia, ATI): desktop supercomputer • In smart phones, behind the dashboard
blog.laptopmag.com/nvidia-tegrak1-unveiled • Everyone has a parallel computer at their
fingertips • If we don’t use parallelism, we lose it! realworldtech.com
Scott B. Baden / CSE 260, UCSD / Fall '15
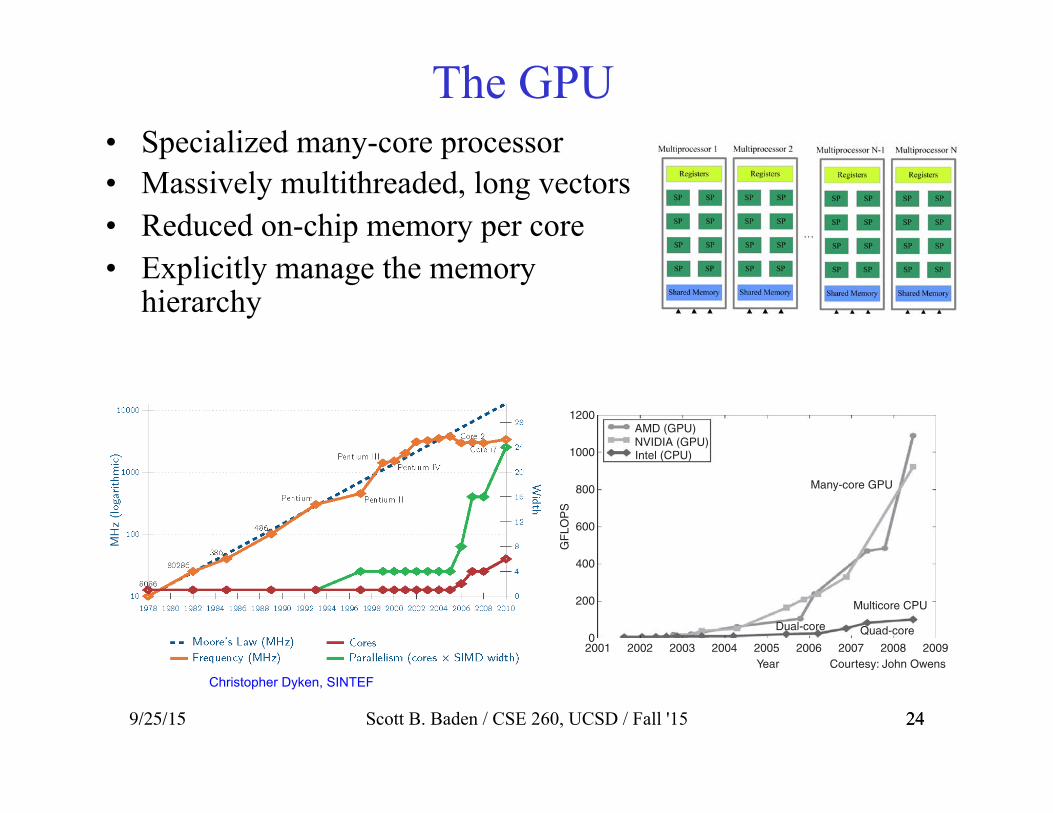
24 9/25/15 24
The GPU • Specialized many-core processor • Massively multithreaded, long vectors • Reduced on-chip memory per core • Explicitly manage the memory
hierarchy
Scott B. Baden / CSE 260, UCSD / Fall '15
Christopher Dyken, SINTEF
1200
1000
800
600
GF
LOP
S
AMD (GPU)NVIDIA (GPU)Intel (CPU)
400
200
02001 2002 2003 2004 2005
Year2006 2007
Quad-coreDual-core
Many-core GPU
Multicore CPU
Courtesy: John Owens2008 2009

Performance and Implementation Issues
9/25/15 25
• To cope with growing data motion costs (relative to computation) ! Conserve locality ! Hide latency
• Little’s Law [1961]
# threads = performance × latency
T = p × λ
! p and λ increasing with time p =1 - 8 flops/cycle λ = 500 cycles/word
Memory (DRAM)
Processor
Year
Perf
orm
ance
fotosearch.comfotosearch.com
λp-1
Scott B. Baden / CSE 260, UCSD / Fall '15 25

Consequences of evolutionary disruption • Transformational: new capabilities for
predictive modelling, healthcare… benefits to society
• Changes the common wisdom for solving a problem including the implementation
• Simplified processor design, but more user control over the hardware resources
Scott B. Baden / CSE 260, UCSD / Fall '15 26

Today’s mobile computer would have been yesterday’s supercomputer
• Cray-1 Supercomputer
• 80 MHz processor • 240 Mflops/sec peak • 3.4 Mflops Linpack • 8 Megabytes memory
• Water cooled • 1.8m H x 2.2m W • 4 tons • Over $10M in 1976
www.anandtech.com/show/8716/apple-a8xs-gpu-gxa6850-even-better-than-i-thought
Scott B. Baden / CSE 260, UCSD / Fall '15 27

Exascale computing
• What is an exaflop? 1M Gigaflops! 1018 flops • The first Exascale computer ~ 2020
u 20+ MWatts : 50+ GFlops/Watt • Top 500 #1, Tianhe-2: 1.9 GF/W (17.6MW)
u Exascale extrapolation: 521 MW #49 Green500 [Does not include 6.2 MW extra]
u #1 on the green list delivers 4.4 GF/W GSIC Center Tokyo Inst Tech, TSUBAME-KFC Xeon E5 and NVIDIA K20x
• Exascale adds a significant power barrier • Per capita power consumption in the EU (IEA)
in 2009: 0.77kW [Tianhe-2 ~ 20K]
Scott B. Baden / CSE 260, UCSD / Fall '15 28

• Principles • Technological disruption and its impact • Motivation – applications
An Introduction to Parallel Computation
Scott B. Baden / CSE 260, UCSD / Fall '15 29

Simulates a 7.7 earthquake along the southern San Andreas fault near LA using seismic, geophysical, and other data from the Southern California Earthquake Center
Scott B. Baden / CSE 260, UCSD / Fall '15 30
epicenter.usc.edu/cmeportal/TeraShake.html
A Motivating Application - TeraShake

• Divide up Southern California into blocks
• For each block, get all the data about geological structures, fault information, …
• Map the blocks onto processors of the supercomputer
• Run the simulation using current information on fault activity and on the physics of earthquakes
Scott B. Baden / CSE 260, UCSD / Fall '15 31
SDSC Machine Room
DataCentral@SDSC
How TeraShake Works

Scott B. Baden / CSE 260, UCSD / Fall '15 32
Animation

Face detection with Viola-Jones algorithm • Searches images for features of a human face
• GPU performance competitive with FPGAs, but far lower development cost
• Jason Oberg, Daniel Hefenbrock, Tan Nguyen [CSE 260, fa’09 →fccm’10]
Window Feature Image
Scott B. Baden / CSE 260, UCSD / Fall '15 33
Sonia Sotomayor

• Capability u We solved a problem that we couldn’t solve
before, or under conditions that were not possible previously
• Performance u Solve the same problem in less time than before u This can provide a capability if we are solving
many problem instances • The result achieved must justify the effort
u Enable new scientific discovery u Software costs must be reasonable
The Payoff
Scott B. Baden / CSE 260, UCSD / Fall '15 34

I increased performance – so what’s the catch? • A well behaved single processor algorithm may
behave poorly on a parallel computer, and may need to be reformulated numerically
• There currently exists no tool that can convert a serial program into an efficient parallel program … for all applications … all of the time… on all
hardware
• Many Performance programming issues ! The new code may look dramatically different
from the original
Scott B. Baden / CSE 260, UCSD / Fall '15 35

Application-specific knowledge is important • The more we know about the application…
… specific problem … math/physics ... initial data … … context for analyzing the output… … the more we can improve performance
• Particularly challenging for irregular problems • Parallelism introduces many new tradeoffs
u Redesign the software u Rethink the problem solving technique
Scott B. Baden / CSE 260, UCSD / Fall '15 36

Next time • Parallel processors • Optimizing the memory hierarchy for high
performance
Scott B. Baden / CSE 260, UCSD / Fall '15 37

FIN
Scott B. Baden / CSE 260, UCSD / Fall '15 38


















