
Learning The Lexicon - Department of Computer …cs.jhu.edu/~lorland1/miniws12-zr-sp/McGraw.pdf ·...
29
Ian McGraw ([email protected] ) Computer Science and Artificial Intelligence Lab Massachusetts Institute of Technology Cambridge, MA, USA Learning The Lexicon A Pronunciation Mixture Model Ibrahim Badr Jim Glass
Transcript of Learning The Lexicon - Department of Computer …cs.jhu.edu/~lorland1/miniws12-zr-sp/McGraw.pdf ·...

Ian McGraw!([email protected])!
Computer Science and Artificial Intelligence Lab!Massachusetts Institute of Technology!
Cambridge, MA, USA!
Learning The Lexicon!A Pronunciation Mixture Model!
Ibrahim Badr Jim Glass!

Automatic Speech Recognition!
Technical Difficulty (more learning)!
Hum
an E
xper
tise!
Speech!
Parallel Speech/Text!
Phonetic Units, Lexicon,!Parallel Speech/Text!
Speech, Text!
~98% of the worldʼs languages have not been addressed by resource and expert intensive supervised speech recognition training methods.!
MIT Computer Science and Artificial Intelligence Laboratory!
A Perspective on Resources!
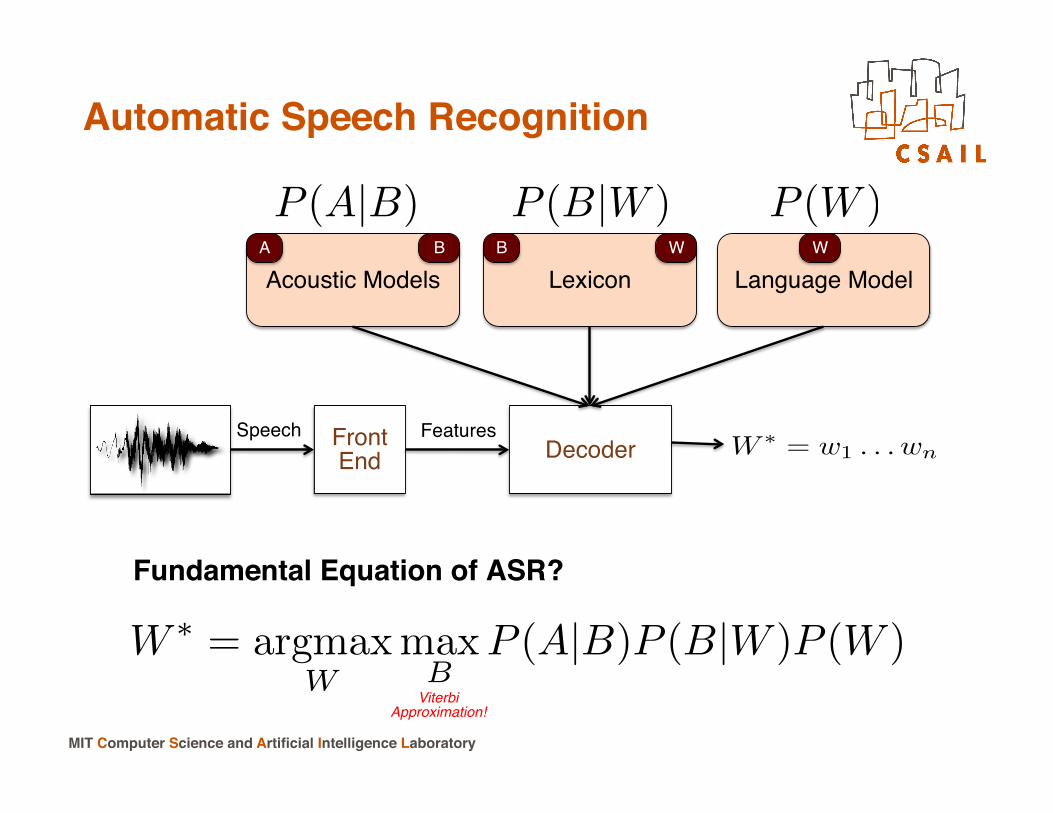
Automatic Speech Recognition!
MIT Computer Science and Artificial Intelligence Laboratory!
Decoder!Front!End! W ∗ = w1 . . . wn
Speech! Features!
Acoustic Models! Lexicon! Language Model!
Fundamental Equation of ASR?!
A! B! B! W! W!
P (W )P (A|B) P (B|W )
W ∗ = argmaxW
maxB
P (A|B)P (B|W )P (W )Viterbi !
Approximation!!

Stochastic Lexicon!
MIT Computer Science and Artificial Intelligence Laboratory!
P (B|W ) =�
j=1
P (bj |wj)
P (hh ax w ay iy | hawaii)e.g.!

Stochastic Lexicon: A Single Entry!
MIT Computer Science and Artificial Intelligence Laboratory!
P (b|w)
1 1
|{bw}|θb|w
Learned Parameters!

MIT Computer Science and Artificial Intelligence Laboratory!
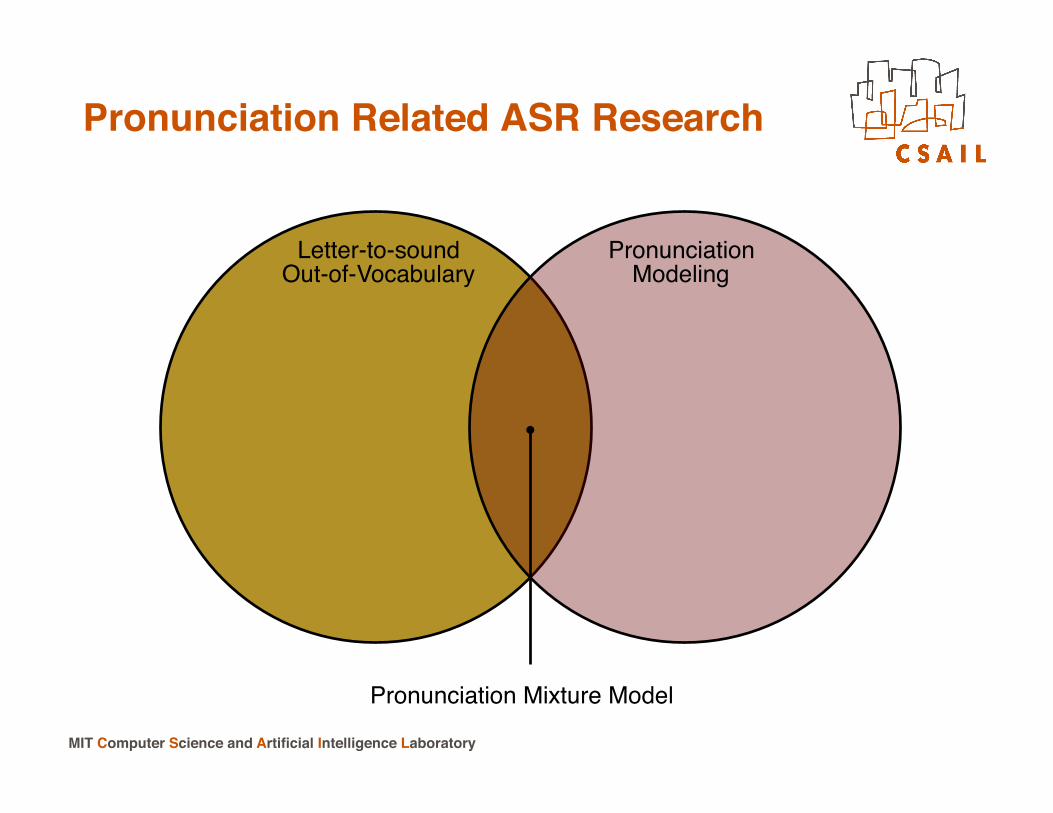
Pronunciation Related ASR Research!
Pronunciation !Modeling!
Letter-to-sound!Out-of-Vocabulary!
Pronunciation Mixture Model!

Modeling Pronunciation Variation!
MIT Computer Science and Artificial Intelligence Laboratory!
Model! Domain! Impact on WER%!Rule learning from manual transcriptions [Riley et al. 1999]!
Broadcast news! 12.7 10.0 !Conversational! 44.7 43.8 !
Decision trees + dynamic lexicon [Fosler-Lussier 1999]!
Broadcast news! 21.4 20.4 !
Knowledge-based rules + FST weight learning [Hazen et al. 2002]!
Weather queries! 12.1 11.0 !

Example:!nearest tornado !
Phoneme: n ih r ax s td # t ao r n ey df ow!
Phone: n ih r ax s # tcl t er n ey dx ow!n ih r ax s tcl t # tcl t ao r n ey dcl d ow!
… !
A set of generic rewrite rules convert a baseform from phonemes to its possible variants at the phone level.!
Phonological Rules!
Expanding the lexicon!

Recognition using!
“Gyllenhaal”!
“Gyllenhaal”!
“Gyllenhaal”!
1
2
M
jh ih l ax n hh aa l
jh ih l eh n hh aa ao l
jh ih l eh n hh aa l! 0.76
0.23
0.05 �
=
�=
�=
or directly in a stochastic lexicon!!is used in a subsequent iteration,!θ
Pronunciation Mixture Model!
θb|w
Candidate Pronunciations!{b}
wi Ai

Pronunciation Mixture Model!
E-step:!
M-step:!
is expected number of times that pronunciation is used for word . !
is the normalized across all pronunciations for a given word .!
Mθ[w,p] wp
Mθ[w,p] wθ∗p|w

Continuous Speech PMM Example!
MIT Computer Science and Artificial Intelligence Laboratory!
0.5584 # w ah tcl # dcl d uw # y uw # n ow # 0.2250 # w ah tcl # dcl d # y uw # n ow # 0.0645 # w ah tcl # dcl d uw # y ax # n ow # 0.0434 # w ah tcl t # dcl d uw # y uw # n ow # 0.0376 # w ah tcl # dcl d ow # y uw # n ow # 0.0244 # w ah tcl # dcl d ax # y uw # n ow # 0.0219 # w ah tcl # dcl d iy # y uw # n ow # 0.0097 # w ah tcl # dcl d # y ax # n ow # 0.0083 # w ah tcl t # dcl d uw # y ax # n ow # 0.0063 # w ah tcl # dcl jh # y uw # n ow #
0.4954 # th ae ng kcl k # y ax # 0.4891 # th ae ng kcl k # y uw # 0.0068 # th ae ng kcl k # y ah # 0.0035 # th ae ng kcl k # y axr # 0.0010 # th ae ng kcl # y ax # 0.0010 # th ae ng kcl # y uw # 0.0010 # th ae ng kcl k # y ow # 0.0007 # th ae ng kcl k # y el # 0.0004 # th ae ng kcl k # y aa uw # 0.0004 # th ae ng kcl k # y aw #
# what # do # you # know #
# thank # you # θy ax|you
θy uw|you
θy ah|you
Normalize!!
MIT Computer Science and Artificial Intelligence Laboratory!
Pronunciation Related ASR Research!
Pronunciation !Modeling!
Letter-to-sound!Out-of-Vocabulary!
Pronunciation Mixture Model!

• Expert Pronunciations
– The SLS dictionary is based on PronLex!* Contains around 150,000 words!* Has an average of 1.2 pronunciations per word.!* Supplementary phonological rules expand pronunciations.!* Expanded lexicon has an average of 4.0 pronunciations per word.!
• Letter-to-sound L2S System
– Joint sequence models [Bisani and Ney, 2008]!* Graphonemes: Train on expert lexicon.!* Graphones: Train on expanded expert lexicon. !
Initializing a PMM: Choosing the Support!
MIT Computer Science and Artificial Intelligence Laboratory!

Joint-sequence Models for L2S!
w! =! c! o! u! p! l! e!b! =! k! ah! p! ax! l!
=! k! ah! p! ax! l!g1! =! c/k! o/ah! u/! p/p! /ax! l/l! e/!g2! =! c/k! o/! u/ah! p/p! /ax! l/l! e/!
EM used to infer alignments and build an M-gram over multigrams.!
b∗ = argmaxb
P (w,b)
P (w,b) =�
g∈S(w,b)
P (g) ≈ maxg∈S(w,b)
P (g)
S(w,b)!
MIT Computer Science and Artificial Intelligence Laboratory!

Non-singular Graphones!
MIT Computer Science and Artificial Intelligence Laboratory!
w! =! c! o! u! p! l! e!b! =! kcl_k! ah! pcl_p! ax! l!
=! kcl_k! ah! pcl_p! ax! l!g1! =! c/kcl_k! o/ah! u/! p/pcl_p! /ax! l/l! e/!g2! =! c/kcl_k! o/! u/ah! p/pcl_p! /ax! l/l! e/!
Parameters:
L = the number of graphemes!R = the number of phonetic units!M = language model context size!

Weighted Finite State Transducers!
MIT Computer Science and Artificial Intelligence Laboratory!
Jw � P (w,b)
P (w,b)J �
�
L
C
P
G
Context Dependent Labels!
�
��
Language Model!
Stochastic Lexicon!
Phonological Rules!
R = C ◦ P ◦ L ◦GStandard Recognition!
PMM Training!
SW i = Jwi1#Jwi
2# . . .#Jwi
|W|
Ri = C ◦ SW i
Ri = C ◦ P ◦ SW i

Recognition Output During Training!
MIT Computer Science and Artificial Intelligence Laboratory!
0.5584 # w ah tcl # dcl d uw # y uw # n ow # 0.2250 # w ah tcl # dcl d # y uw # n ow # 0.0645 # w ah tcl # dcl d uw # y ax # n ow # 0.0434 # w ah tcl t # dcl d uw # y uw # n ow # 0.0376 # w ah tcl # dcl d ow # y uw # n ow # 0.0244 # w ah tcl # dcl d ax # y uw # n ow # 0.0219 # w ah tcl # dcl d iy # y uw # n ow # 0.0097 # w ah tcl # dcl d # y ax # n ow # 0.0083 # w ah tcl t # dcl d uw # y ax # n ow # 0.0063 # w ah tcl # dcl jh # y uw # n ow #
0.4954 # th ae ng kcl k # y ax # 0.4891 # th ae ng kcl k # y uw # 0.0068 # th ae ng kcl k # y axr # 0.0035 # th ae ng kcl k # y el # 0.0010 # th ae ng kcl # y ax # 0.0010 # th ae ng kcl # y uw # 0.0010 # th ae ng kcl k # y ow # 0.0007 # th ae ng kcl k # y ah # 0.0004 # th ae ng kcl k # y aa uw # 0.0004 # th ae ng kcl k # y aw #
# what # do # you # know #
# thank # you #
(Effectively)!

SUMMIT Recognizer Setup!
MIT Computer Science and Artificial Intelligence Laboratory!
• Landmark-based speech recognizer!• MFCC averages are taken at varying durations around hypothesized boundaries!• 112-dimensional feature vectors are whitened with a PCA rotation!• 50 principal components are kept!
• Context dependent acoustic models!• Up to 75 diagonal gaussian mixture components each!• Maximum-likelihood back-off models are trained on a corpus of telephone speech!
• Lexicon!• Expert dictionary based on PronLex!• ~150,000 words for training graphones/graphonemes!• All lexicons limited to training set words for testing!

Isolated Words: Experimental Setup!• Phonebook Corpus!
– Isolated words spoken over the telephone by Americans!– 2,000 words chosen randomly from the set that had at leas 13 speakers!– For each word, 1 male and 1 female utterance was held out for testing!– The remaining 22,000 utterances were used for training!
• Lexicon!– The 2,000 test words were removed from the lexicon!– A simple edit distance criterion was used to prune similar words!– A 5-gram graphoneme language model was trained !
• Testing!– We test lexicons trained using varying amounts of acoustic data!– We compare with two baselines:!
* Expert Baseline WER: 12.4%!* Graphoneme L2S WER: 16.7% !
MIT Computer Science and Artificial Intelligence Laboratory!

Isolated Word: Experimental Results!
MIT Computer Science and Artificial Intelligence Laboratory!
0 2 4 6 8 1010
11
12
13
14
15
16
17
Number of utterances used to learn baseforms (M)
WER
on
Test
Set
(%)
Lexicon Adaptation using Acoustic Examples
Unweighted Top PMM pronunciation
Weighted PMM pronunciations
Expert Lexicon
Graphoneme Lexicon
Collect 10 pronunciations!for each word.!
Train a PMM just on these pronunciations.!

Analysis!
MIT Computer Science and Artificial Intelligence Laboratory!
83% of the top pronunciations are identical!
Word Dictionary Baseform Top PMM Pronunciationparishoners [sic] p AE r ih sh ax n er z p AX r ih sh ax n er ztraumatic tr r AO m ae tf ax kd tr r AX m ae tf ax kdwinnifred w ih n ax f r AX dd w ih n ax f r EH ddcrosby k r ao Z b iy k r aa S b iymelrose m eh l r ow Z m eh l r ow Sarenas ER iy n ax z AX R iy n ax zbillowy b ih l OW iy b ih l AX W iywhitener w ay TF AX n er w ay TD n erairsickness eh r SH ih kd n EH s eh r S ih kd n AX sIsabel AX S AA b eh l IH Z AX b eh l

MIT Computer Science and Artificial Intelligence Laboratory!
• Jupiter: Weather Query Corpus!– Short queries (average of ~6 words in length)!– We prune utterances with non-speech artifacts out of the corpus!– We use a training set containing 76.68 hours of speech!– We use a test set containing 3.18 hours and a dev set of .84 hours!– The acoustic models are well matched to the training set!
• Lexicon & LM!– The lexicons in these experiments contain only training set words!– A trigram was trained on the training set transcripts !
• Testing!– We provide a baseline based only on the letter-to-sound pronunciations!– We decode using the expert dictionary to give us a baseline!– We weight the expert lexicon using the PMM training!– We train a 5-gram graphone and graphoneme-based PMM!
Continuous Speech: Experimental Setup!

MIT Computer Science and Artificial Intelligence Laboratory!
Continuous Speech: Experimental Results!
WERGraphoneme L2S 11.2Expert 9.5Expert PMM 9.2Phoneme PMM 8.3Phone PMM 8.2

Analysis!
MIT Computer Science and Artificial Intelligence Laboratory!
Word Dictionary Baseform Top PMM Pronunciationalready ao L r eh df iy aa r eh df iyantarctica ae nt aa r KD t ax k ax ae nt aa r tf ax k axasked ae s KD t ae s tdbarbara b aa r b AX r ah b aa r b r axbratislava b r AA tf ax s l aa v ax b r tf ax z l aa v axclothes k l ow DH z k l ow z

Lexicon Sizes!
MIT Computer Science and Artificial Intelligence Laboratory!
Weather Lexicon Avg # Prons # States # Arcs SizeExpert 1.2 32K 152K 3.5 MBPhoneme PMM 3.15 51K 350K 7.5 MBPhone PMM 4.0 47K 231K 5.2 MB

Varying Initialization Parameters!
MIT Computer Science and Artificial Intelligence Laboratory!
Singular Graphones and variable MM=1 M=2 M=3 M=4 M=5
LM FST Size 28K 64K 624K 3.1M 9.4M
WER Using Graphones Alone (T=.01)PPW 3.9 14.2 11.4 7.5 5.9WER Dev. 71.4 20.5 14.3 13.1 12.5WER Test 74.9 17.6 11.7 10.9 10.2
WER Using Graphone-based PMM (T=.01)PPW 6.08 4.0 3.5 3.1 3.0WER Dev. 17.7 10.6 10.6 10.5 10.7WER Test 15.6 8.4 8.2 8.1 8.2

Varying Initialization Parameters!
MIT Computer Science and Artificial Intelligence Laboratory!
Graphones with M = 5 and variable L-to-R1-to-1 1-to-2 1-to-3 2-to-2 3-to-3
LM FST Size 9.4M 12M 12M 25M 21M
WER Using Graphones Alone (T=.01)PPW 5.9 5.7 5.7 5.4 5.5WER Dev. 12.5 12.2 12.4 12.2 12.3WER Test 10.2 10.2 10.3 10.4 10.1
WER Using Graphone-based PMM (T=.01)PPW 3.0 3.0 2.9 2.9 2.9WER Dev. 10.7 10.6 10.5 10.4 10.6WER Test 8.2 8.2 8.2 8.2 8.2

Conclusions!
MIT Computer Science and Artificial Intelligence Laboratory!
• PMM: Maximum-likelihood lexicon learning!
• Flexible initialization from experts or L2S!
• Requires no additional resources!
• Produces better-than-expert pronunciations!

Future Directions!
MIT Computer Science and Artificial Intelligence Laboratory!
• Apply to other languages!
• Train in tandem with acoustic models (no phonological rules)!
• Learn the lexicon from scratch?!


















