
Learning Bayesian Networks. Dimensions of Learning ModelBayes netMarkov net DataCompleteIncomplete...
31
Learning Bayesian Networks
-
date post
20-Dec-2015 -
Category
Documents
-
view
217 -
download
0
Transcript of Learning Bayesian Networks. Dimensions of Learning ModelBayes netMarkov net DataCompleteIncomplete...

Learning Bayesian Networks

Dimensions of Learning
Model Bayes net Markov net
Data Complete Incomplete
Structure Known Unknown
Objective Generative Discriminative

Bayes net(s)data
X1 truefalsefalsetrue
X2 1532
X3 0.7-1.65.96.3
...
.
.
....
Learning Bayes netsfrom data
X1
X4
X9
X3
X2
X5
X6
X7
X8
Bayes-netlearner
+prior/expert information
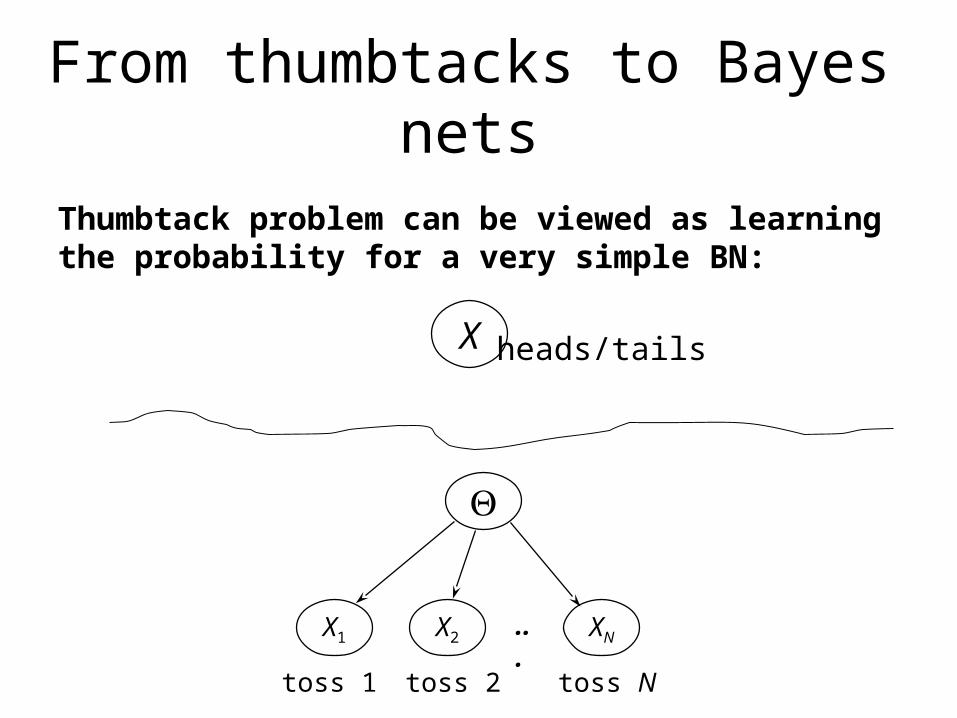
From thumbtacks to Bayes nets
Thumbtack problem can be viewed as learningthe probability for a very simple BN:
X heads/tails
X1 X2 XN...
toss 1 toss 2 toss N
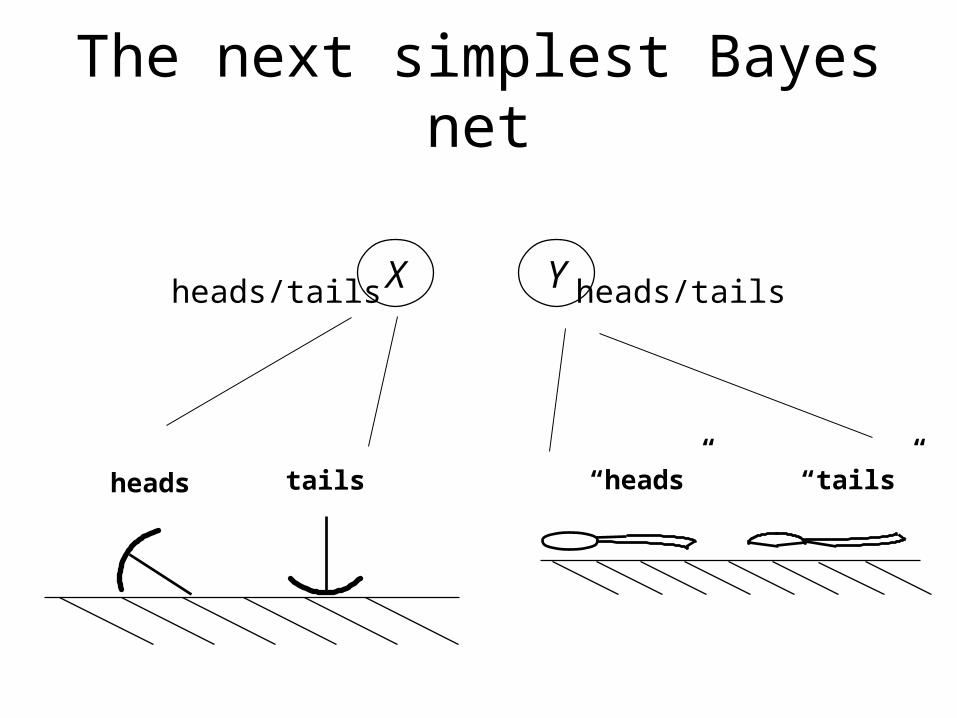
The next simplest Bayes net
Xheads/tails Y heads/tails
tailsheads “heads” “tails”
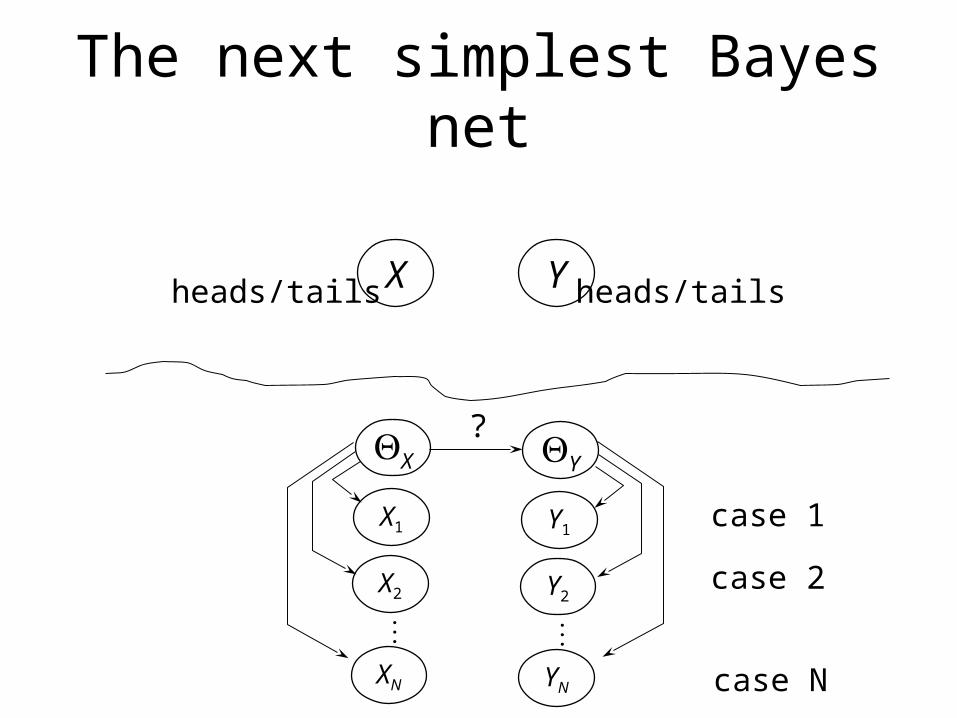
The next simplest Bayes net
Xheads/tails Y heads/tails
X
X1
X2
XN
Y
Y1
Y2
YN
case 1
case 2
case N
?

The next simplest Bayes net
Xheads/tails Y heads/tails
X
X1
X2
XN
Y
Y1
Y2
YN
case 1
case 2
case N
"parameterindependence"
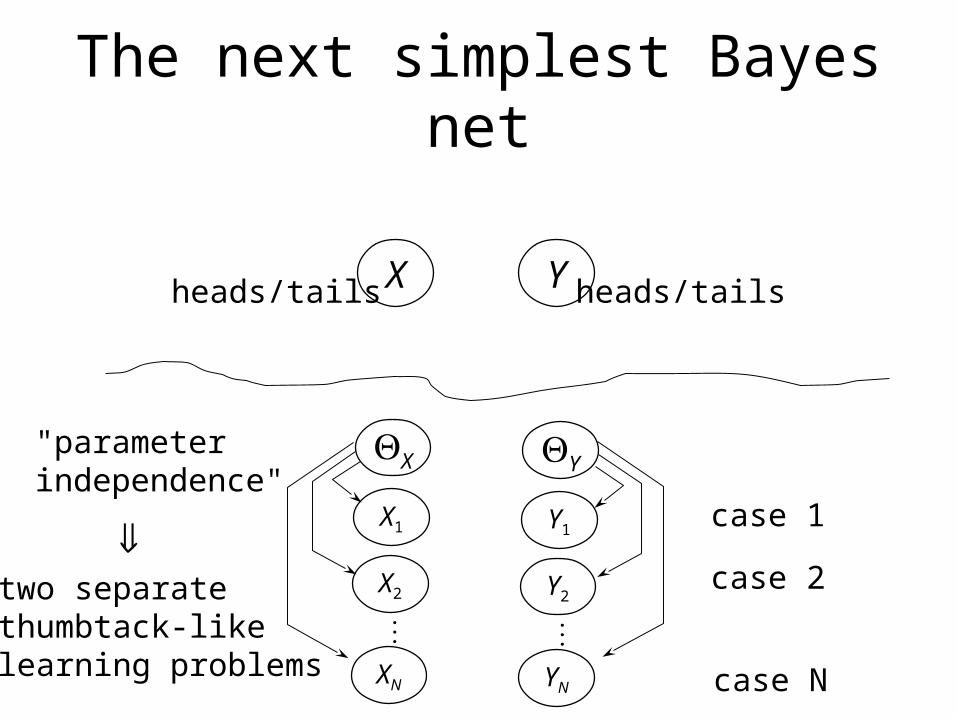
The next simplest Bayes net
Xheads/tails Y heads/tails
X
X1
X2
XN
Y
Y1
Y2
YN
case 1
case 2
case N
"parameterindependence"
two separatethumbtack-likelearning problems

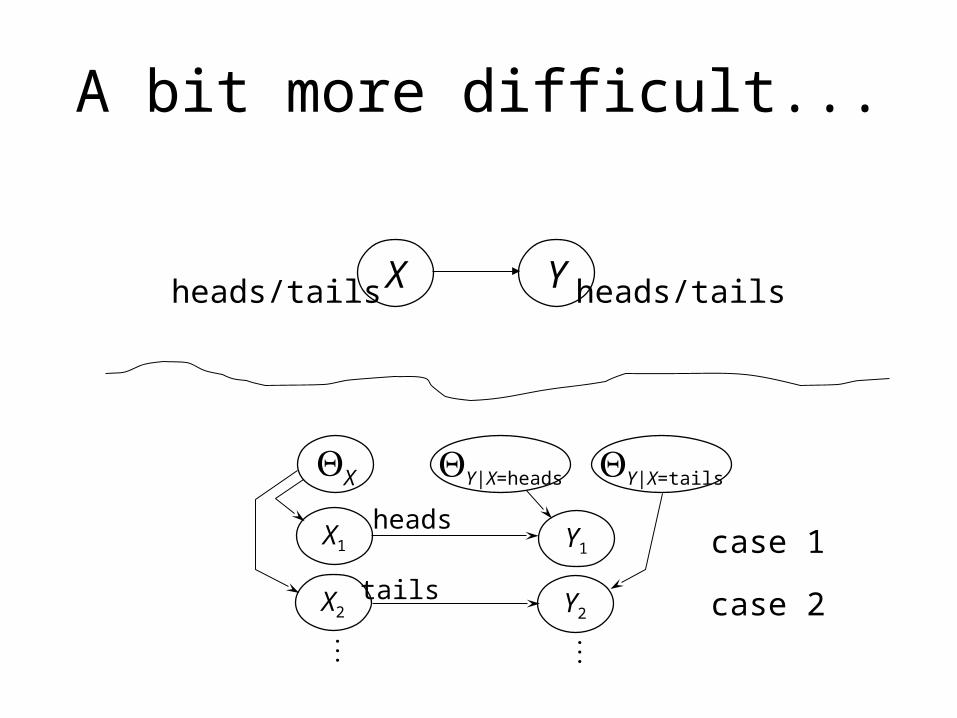
A bit more difficult...
Xheads/tails Y heads/tails
Three probabilities to learn:X=heads
Y=heads|X=heads
Y=heads|X=tails
A bit more difficult...
Xheads/tails Y heads/tails
X
X1
X2
Y|X=heads
Y1
Y2
case 1
case 2
Y|X=tails
heads
tails

A bit more difficult...
Xheads/tails Y heads/tails
X
X1
X2
Y|X=heads
Y1
Y2
case 1
case 2
Y|X=tails
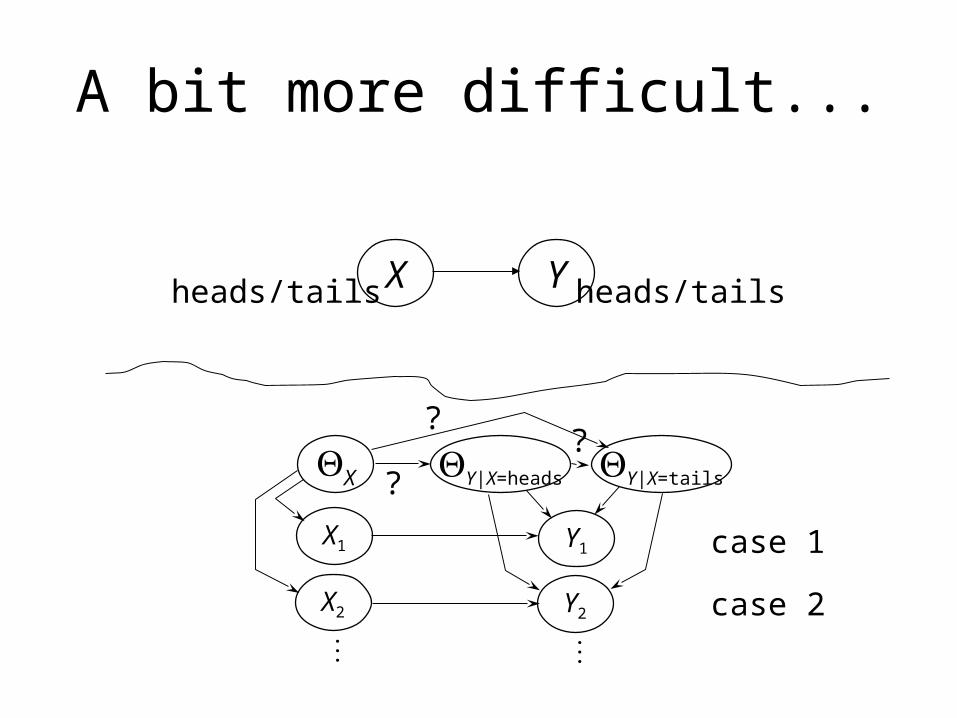
A bit more difficult...
Xheads/tails Y heads/tails
X
X1
X2
Y|X=heads
Y1
Y2
case 1
case 2
Y|X=tails
??
?

A bit more difficult...
Xheads/tails Y heads/tails
X
X1
X2
Y|X=heads
Y1
Y2
case 1
case 2
Y|X=tails
3 separate thumbtack-like problems

In general …
Learning probabilities in a Bayes netis straightforward if
• Complete data
• Local distributions from the exponential family (binomial, Poisson, gamma, ...)
• Parameter independence
• Conjugate priors
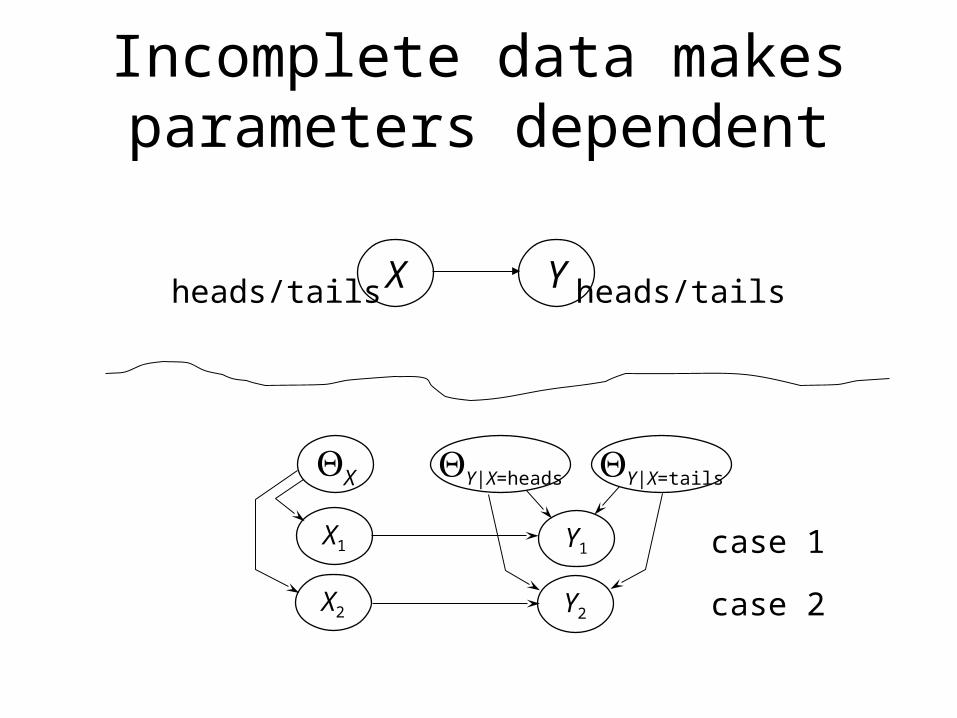
Incomplete data makes parameters dependent
Xheads/tails Y heads/tails
X
X1
X2
Y|X=heads
Y1
Y2
case 1
case 2
Y|X=tails

Solution: Use EM
• Initialize parameters ignoring missing data
• E step: Infer missing values usingcurrent parameters
• M step: Estimate parameters using completed data
• Can also use gradient descent
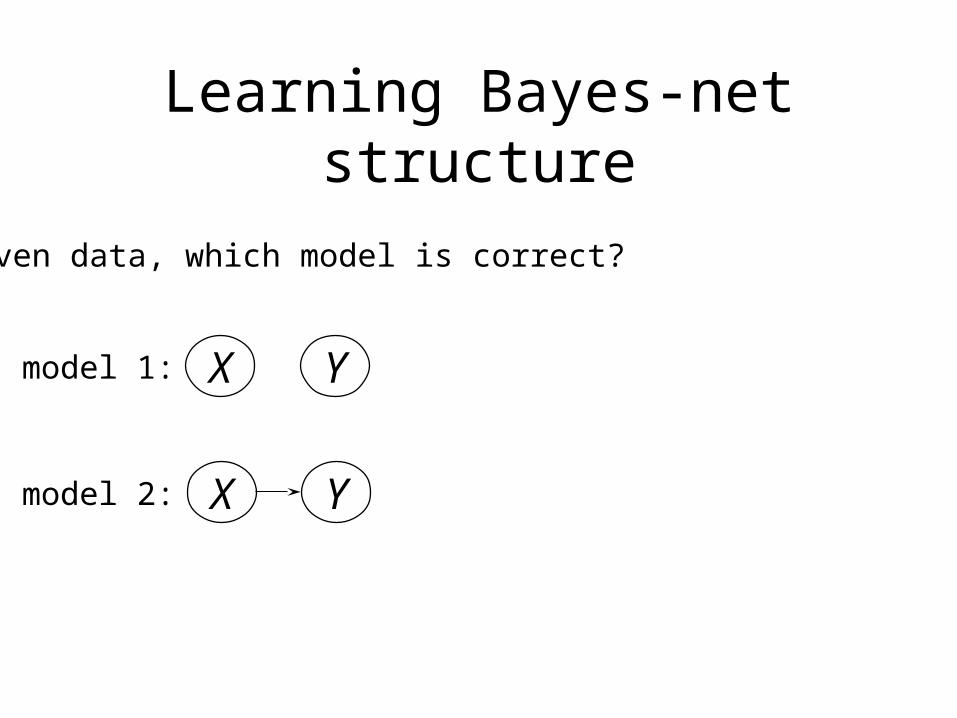
Learning Bayes-net structure
Given data, which model is correct?
X Ymodel 1:
X Ymodel 2:

Bayesian approach
Given data, which model is correct? more likely?
X Ymodel 1:
X Ymodel 2:
7.0)( 1 mp
3.0)( 2 mp
Data d
1.0)|( 1 dmp
9.0)|( 2 dmp

Bayesian approach:Model averaging
Given data, which model is correct? more likely?
X Ymodel 1:
X Ymodel 2:
7.0)( 1 mp
3.0)( 2 mp
Data d
1.0)|( 1 dmp
9.0)|( 2 dmp
averagepredictions
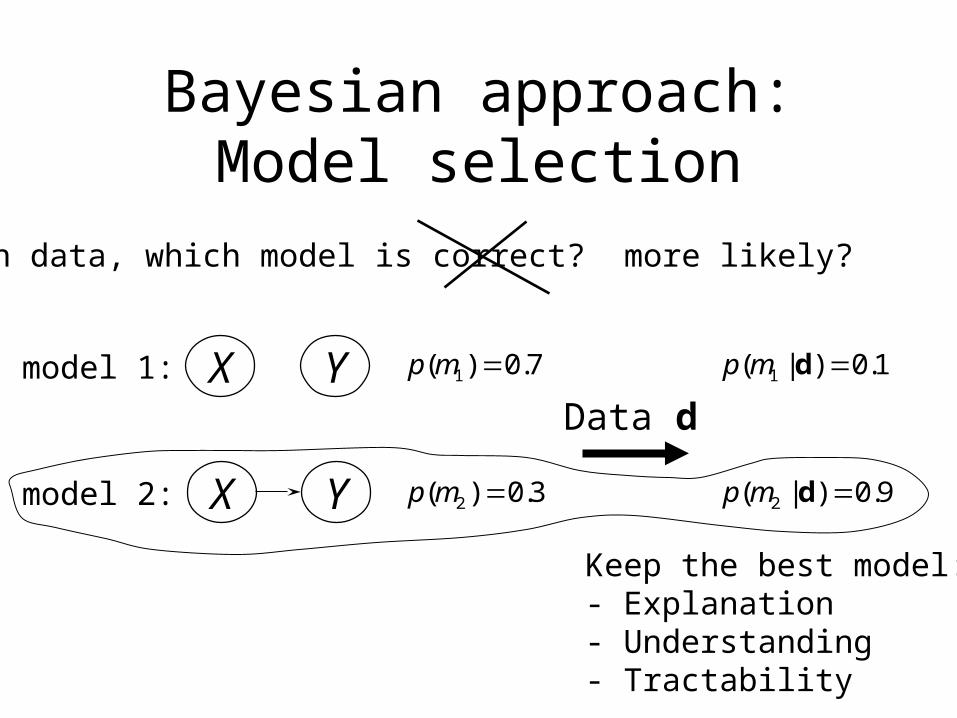
Bayesian approach:Model selection
Given data, which model is correct? more likely?
X Ymodel 1:
X Ymodel 2:
7.0)( 1 mp
3.0)( 2 mp
Data d
1.0)|( 1 dmp
9.0)|( 2 dmp
Keep the best model:- Explanation- Understanding- Tractability

To score a model,use Bayes’ theorem
Given data d:
)|()()|( mpmpmp dd
dmpmpmp )|(),|()|( dd
"marginallikelihood"
modelscore
likelihood

Thumbtack example
)(
)#(
)(
)#(
)##(
)(
)1(
)|()1()|(
1#1#
##
t
t
h
h
th
th
th
th
th
th
d
dmpmp
th
d
conjugateprior
X heads/tails

More complicated graphs
Xheads/tails Y heads/tails
3 separate thumbtack-like learning problems
)(
)#(
)(
)#(
)##(
)(
)(
)#(
)(
)#(
)##(
)(
)(
)#(
)(
)#(
)##(
)()|(
t
t
h
h
th
th
t
t
h
h
th
th
t
t
h
h
th
th
th
th
th
th
th
thmp
d X
Y|X=heads
Y|X=tails

Model score for adiscrete Bayes net
ii r
k ijk
ijkijkn
i
q
j ijij
ij N
Nmp
11 1 )(
)(
)(
)()|(
d
N X x
r X
q X
N N
ijk i i ij
i i
i i
ij ijkk
r
ij ijkk
ri i
:
:
:
# cases where = and =
number of states of
number of instances of parents of
ik Pa pa
1 1

Computation ofmarginal likelihood
Efficient closed form if
• Local distributions from the exponential family (binomial, poisson, gamma, ...)
• Parameter independence
• Conjugate priors
• No missing data (including no hidden variables)
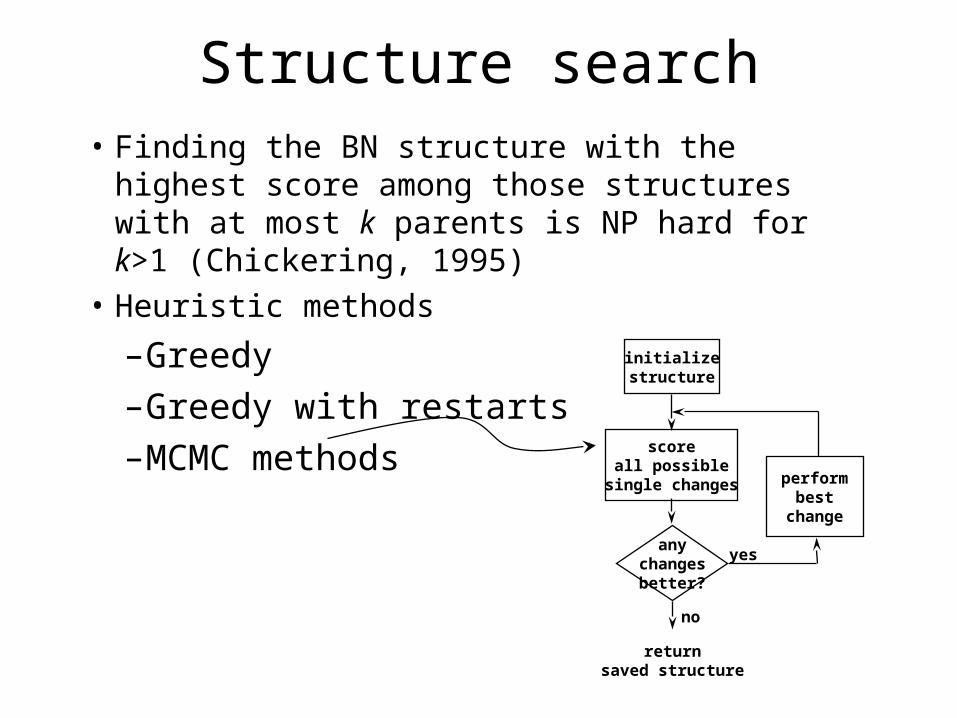
Structure search• Finding the BN structure with the highest
score among those structures with at most k parents is NP hard for k>1 (Chickering, 1995)
• Heuristic methods
–Greedy–Greedy with restarts–MCMC methods score
all possiblesingle changes
anychangesbetter?
performbest
change
yes
no
returnsaved structure
initializestructure

Structure priors
1. All possible structures equally likely
2. Partial ordering, required / prohibited arcs
3. Prior(m) Similarity(m, prior BN)

Parameter priors
• All uniform: Beta(1,1)
• Use a prior Bayes net

Parameter priors
Recall the intuition behind the Beta prior for the
thumbtack:
• The hyperparameters h and t can be thought
of as imaginary counts from our prior
experience, starting from "pure ignorance"
• Equivalent sample size = h + t
• The larger the equivalent sample size, the more
confident we are about the long-run fraction
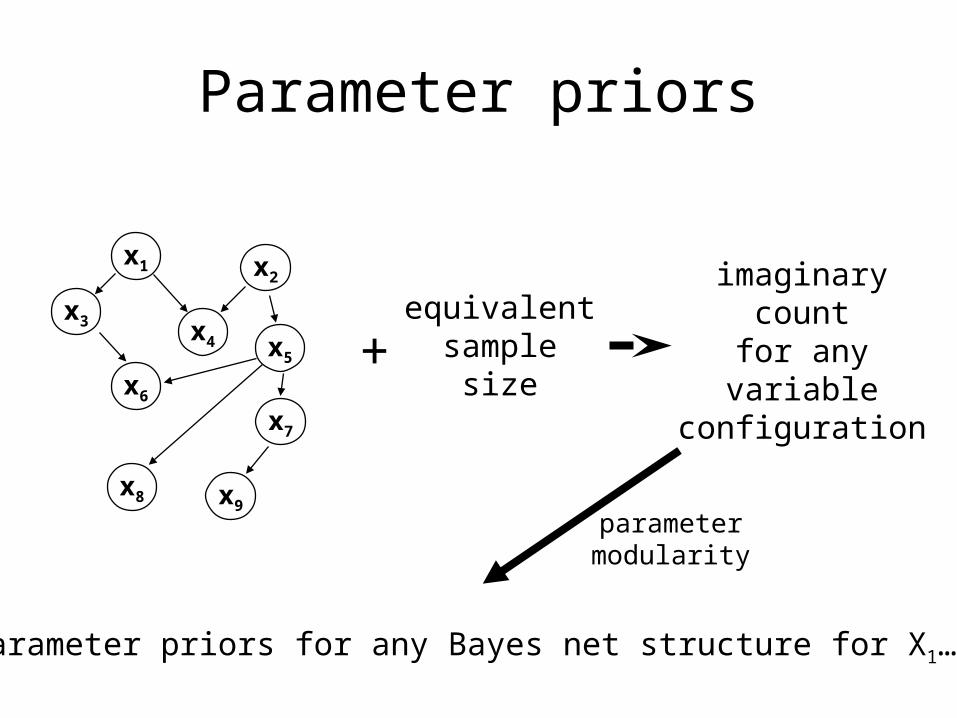
Parameter priors
x1
x4
x9
x3
x2
x5
x6
x7
x8
+equivalent
samplesize
imaginarycount
for anyvariable
configuration
parameter priors for any Bayes net structure for X1…Xn
parametermodularity
x1
x4
x9
x3
x2
x5
x6
x7
x8
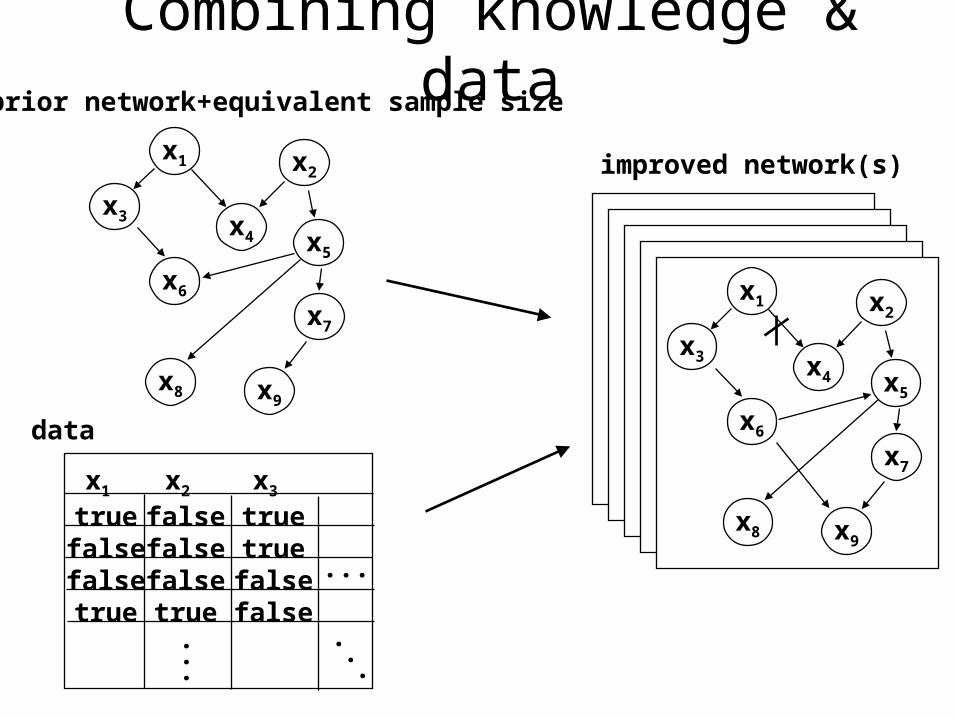
prior network+equivalent sample size
data
improved network(s)
x1 truefalsefalsetrue
x2 falsefalsefalsetrue
x3 truetruefalsefalse
...
.
.
....
Combining knowledge & data
x1
x4
x9
x3
x2
x5
x6
x7
x8


















