
Latent Dirichlet Allocation - · PDF fileLatent Dirichlet Allocation David M. Blei, ......
32
Latent Dirichlet Allocation David M. Blei, Andrew Y. Ng, Michael I. Jordan Presenter: Suin Kim, UILAB, KAIST March 08, 2011
-
Upload
truongngoc -
Category
Documents
-
view
225 -
download
0
Transcript of Latent Dirichlet Allocation - · PDF fileLatent Dirichlet Allocation David M. Blei, ......

Latent Dirichlet Allocation
David M. Blei, Andrew Y. Ng, Michael I. Jordan
Presenter: Suin Kim, UILAB, KAISTMarch 08, 2011

CS774, March 08, 2011 Suin Kim, KAIST
Today I’ll talk about...
• Mathematical background• Variational Bayesian method• Parameter estimation• Examples, applications and empirical results
• Preliminary parts are omitted.• Now you’re familiar to basic LDA model.
• Please interrupt me if you have any question.
2

CS774, March 08, 2011 Suin Kim, KAIST
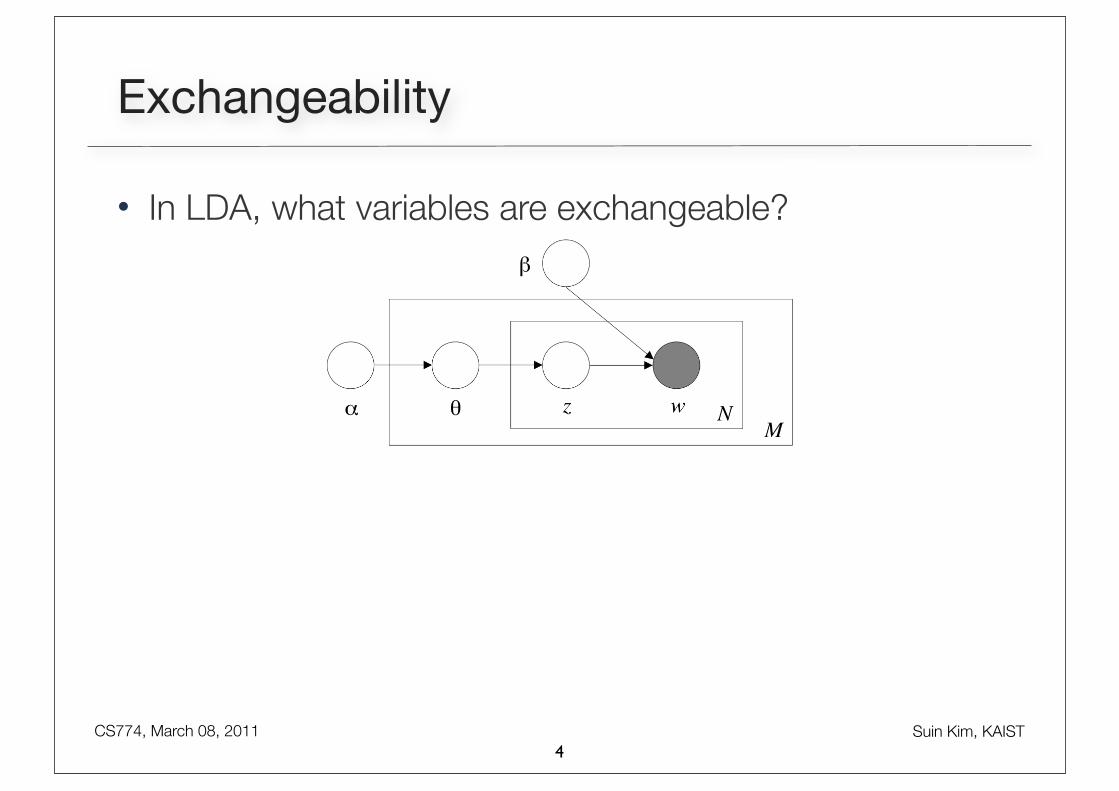
Exchangeability
• Let {z1, z2, ... zn} is a finite set of random variables.
• {z1, z2, ... zn} is exchangeable if the joint distribution is invariant to permutation.
• “Future samples behave like earlier samples.”
• “The future being predictable on the basis of past experience.”
• Exchangeable: conditionally independent and identically distributed. i.i.d ⇒ exchangeable
• Assumption of exchangeability is a major simplifying assumption.
3
CS774, March 08, 2011 Suin Kim, KAIST
Exchangeability
• In LDA, what variables are exchangeable?
4

CS774, March 08, 2011 Suin Kim, KAIST
Exchangeability
• In LDA, what variables are exchangeable?
• Words are generated by topics
• Those topics are infinitely exchangeable within a document
5

CS774, March 08, 2011 Suin Kim, KAIST
Perplexity
• Perplexity is a measurement in information theory.
• For unknown probability model p, how is the proposed model q well predicts the data x?
• The perplexity of model q is .
• Better q will assign higher probabilities q(xi),resulting lower perplexity.
6
2−�N
i=11N log2 q(xi)

CS774, March 08, 2011 Suin Kim, KAIST
Approximate Inference
• Model contains latent variables Z and observable X
• Sometimes posterior distribution p(Z|X) is intractable because
• Dimensionality of the latent space is too high
• Posterior distribution has a highly complex form
• Stochastic approximations
• MCMC
• Deterministic approximations
• Variational Inference(Bayes)
7

CS774, March 08, 2011 Suin Kim, KAIST
Variational Bayesian methods
• Also called ensemble learning
• A family of techniques for approximating intractable integrals
• VB methods can
• provide an analytical approximation to the posterior probability of the unobserved variables
• derive a lower bound to the marginal likelihood
• Alternative to Monte Carlo sampling methods
8

CS774, March 08, 2011 Suin Kim, KAIST
Variational optimization on a Bayesian model
• Set of all latent variables and variables Z
• Set of all observed variables X
• Our model specifies joint distribution P(X, Z)
• We want to find an approximation for P(Z|X) and P(X)
•
• In LDA, is intractable since is intractable.
9
p(Z|X) =p(Z,X)
p(X)p(θ, z|w,α,β) =
p(θ, z,w|α,β)p(w|α,β)
p(w|α,β)

CS774, March 08, 2011 Suin Kim, KAIST
Variational optimization on a Bayesian model
• We can decompose log marginal probability using
• , where
• L(q) is lower bound of ln p(X).
• KL(q||p) is divergence between q and p.
• Less divergence, better approximation.
10
ln p(X) = L(q) + KL(q||p)
L(q) =�
q(Z) ln(p(X,Z)
q(Z))dZ
KL(q||p) = −�
q(Z) ln(p(Z|X)
q(Z))dZ

CS774, March 08, 2011 Suin Kim, KAIST
Variational optimization on a Bayesian model
•
• We want to minimize KL divergence
• By optimization w.r.t q(Z)
• Equivalent to maximizing lower bound L(q)
• We choose tractable distribution q(Z) and seek the member of this family to minimize KL divergence
• No overfitting!
• Why?
11
ln p(X) = L(q) + KL(q||p)

CS774, March 08, 2011 Suin Kim, KAIST
Variational optimization on a Bayesian model
• How can we choose approximating distribution?
1. Use a distribution q(Z|ω) governed by ω• L(q) becomes a function of ω
2. Choose q from factorized distributions.
• Example) Variational distribution is Gaussian, optimized with respect to μ and σ.
12μ

CS774, March 08, 2011 Suin Kim, KAIST
Parameter estimation on LDA
• is intractable
• We define as a surrogate of p.
• We approximate α,β,γ,ϕ from variational EM algorithm
• E-step: Minimize the KL divergence regarding to
• M-step: Find the α and β that maximizes resulting lower bound on the likelihood
13
p(θ, z|w,α,β) =p(θ, z,w|α,β)p(w|α,β)
q(θ, z|γ,φ) = q(θ|γ)N�
n=1
q(zn|φn)
γ∗d ,φ
∗d

CS774, March 08, 2011 Suin Kim, KAIST
Parameter estimation on LDA
• E-step
• We compute for all n and i.
• Setting derivatives as 0 minimizes KL divergence.
•
•
• In E-step, we have inferred ϕ and γ with respect to α and β.
14
φni ∝ βiwn exp(Eq[log(θi)|γ])
γi = αi +�N
n=1 φni
∂
∂γiKL(q||p), ∂
∂φniKL(q||p)

CS774, March 08, 2011 Suin Kim, KAIST
Parameter estimation on LDA
• M-step
• We wish to find parameters that maximize the log likelihood
•
• To find α, we must use an iterative method.
• We use linear-time Newton-Raphson algorithm
• Hessian is in the form .
15
l(α,β) =�M
d=1 log p(wd|α,β)βij ∝
�Md=1
�Nd
n=1 φdniwjdn
∂L
∂αiαj= δ(i, j)MΨ�(αi)−Ψ(
�kj=1 αj)

CS774, March 08, 2011 Suin Kim, KAIST
Parameter estimation on LDA
• Detailed derivation
• Please refer to appendix A.1, A.3 and A.4.
16

CS774, March 08, 2011 Suin Kim, KAIST
Smoothing
• New document is likely to contain word which didn’t appear in a training corpus.
• P(new word) = 0
• P(document contains new word) = ∏P(wordi) = 0
• “Smooth” the multinomial parameters
• Always assign positive probability
17

CS774, March 08, 2011 Suin Kim, KAIST
Experiment
• TREC AP corpus, 16K documents
• 100-topic LDA model
• Using variational inference, authors computed
• Dirichlet parameters γ for the article
• Multinomial parameters ϕn for each word in the article
• Listed topics which have large number of expected number of words in the article.
• Since , significant topics have large .
18
γi = αi +N�
n=1
φni γi − αi
E[Number of words generated by topic i]

4 most significant topics, with words which have large .p(w|z)

CS774, March 08, 2011 Suin Kim, KAIST
Experiment
• What is the problem of the “bag-of-words” model?
20

CS774, March 08, 2011 Suin Kim, KAIST
Experiment
• What is the problem of the “bag-of-words” model?
• Words are separated into different topics.
• How can we extend basic LDA model to overcome this?
21

CS774, March 08, 2011 Suin Kim, KAIST
Applications
• Document modeling
• Generalization performance of models
• Achieve high likelihood on a held-out test set
• Document classification
• Classify a document into ≥2 mutex classes
• Collaborative filtering
• Train a model on a fully observed set of users
• Predict movie that user prefers
22

CS774, March 08, 2011 Suin Kim, KAIST
Document modeling
• For a test set of M documents,
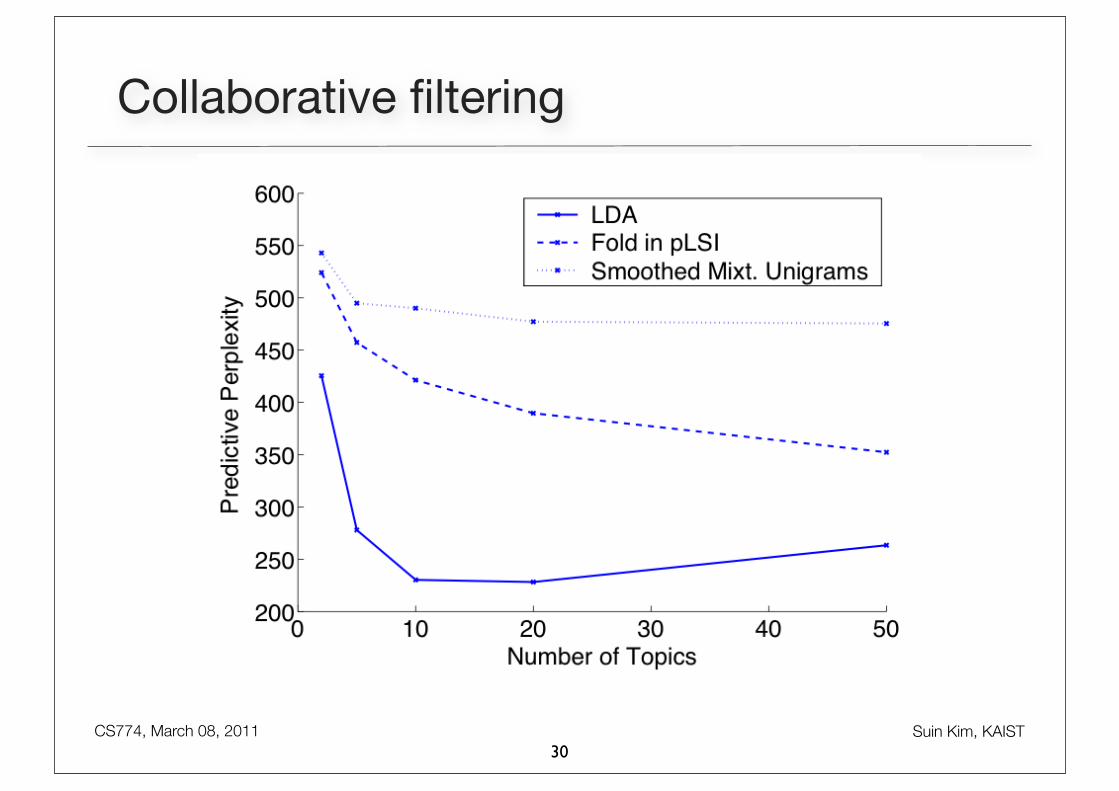
• Compared LDA, Unigram, pLSI and Mixt. Unigrams.
• pLSI and Mixture of Unigrams suffered from overfitting.
• Why LDA is free from overfitting?
23
perplexity(Dtest) = exp(−�M
d=1 log p(wd)�Md=1 Nd
)

CS774, March 08, 2011 Suin Kim, KAIST
pLSI vs LDA
• What is the key difference of pLSI and LDA?
24
Diagram from Yohan Jo’s slide

CS774, March 08, 2011 Suin Kim, KAIST
pLSI vs LDA
• If θ and φ are not constrained to α and β, the model is pLSI.
• Since θ and φ is permittedas well as it explains the corpus well,it overfits to the training data.
25
φ
w
z
θ
α
D
T Nd
β
Diagram from Yohan Jo’s slide

CS774, March 08, 2011 Suin Kim, KAIST
Document modeling
26

CS774, March 08, 2011 Suin Kim, KAIST
Document classification
• Generative model for classification
• Use one LDA module per class
• Choice of features
• Use LDA to reduce feature set into fixed set of real values
• Posterior Dirichlet parameters
• Document classifier using LDA
1. Estimated parameters of LDA on all documents
2. Trained SVM on the result of LDA
27
γ∗(w)

CS774, March 08, 2011 Suin Kim, KAIST
Document classification
28
CS774, March 08, 2011 Suin Kim, KAIST
Collaborative filtering
• Uses EachMovie collaborative filtering data
• A collection of user’s indication of preferred movie choices
• User : DocumentMovie: Word
29
Unseen Document Show Predict
CS774, March 08, 2011 Suin Kim, KAIST
Collaborative filtering
30

CS774, March 08, 2011 Suin Kim, KAIST
Conclusion
• LDA is based on a simple exchangeability assumption for the words and topics in a document
• LDA as a dimensionality reduction technique
• Exact inference is intractable for LDA
• We can use various approximate inference algorithms
• LDA has high modularity and extensibility
• A variety of extensions of LDA can be considered
31
Q & A


















