
Large Scale Data Clustering: an overview
40
Large Scale Data Clustering Algorithms Vahid Mirjalili Data Scientist Feb 11 th 2016
-
Upload
vahid-mirjalili -
Category
Data & Analytics
-
view
1.293 -
download
0
Transcript of Large Scale Data Clustering: an overview

Large Scale Data Clustering Algorithms
Vahid Mirjalili Data Scientist
Feb 11th 2016

Outline
1. Overview of clustering algorithms and validation
2. Fast and accurate k-means clustering for large datasets
3. Clustering based on landmark points
4. Spectral relaxation for k-means clustering
5. Proposed methods for microbial community detection
2

Part 1:
Overview of Data Clustering Algorithms
Jain, Anil K. "Data clustering: 50 years beyond K-means." Pattern recognition letters 31.8 (2010): 651-666. 3

Data clustering
Goal: discover natural groupings among given data points
Unsupervised learning (unlabeled data)Exploratory analysis (without any pre-specified model/hypothesis)
UsagesGain insight from the underlying structure of data (salient features, anomaly detection, etc)
Identify degree of similarity between points (infer phylogenetic relationships)
Data Compression (summarizing data by cluster prototypes, removing redundant patterns)
4

Applications
Wide range of applications: computer vision, document clustering, gene clustering, customer/product groups
An example application for Computer Visions: image segmentation and separating the background
5

Different clustering algorithms
Literature contains 1000 clustering algorithms
Different criteria to divide clustering algorithms
Soft vs. Hard Clustering
Prototype vs. Density based
Partitional vs.Hierarchical Clustering
6

Partitional vs. Hierarchical
1. Partitional algorithms (k-means)Partition the data spaceFinds all clusters simultaneously
2. Hierarchical algorithmsGenerate nested cluster hierarchy Agglomerative (bottom-up) Divisive (top-down)
Distance between clusters:Single-linkage, complete linkage, average-linkage
7

K-means clustering
Objective function:
1. Select K initial cluster centroids
2. Assign data points to the nearest cluster centroid
3. Update the new cluster centroids
Figure curtesy: Data clustering: 50 years beyond k-means, Anil Jain 8

K-means pros and cons
+ Simple/easy to implement
+ Order of linear complexity O(N × Iterations)
- Results highly dependent on initialization
- Prone to local minima
- Sensitive to outliers, and clusters sizes
- Globular shaped clusters
- Requiring multiple passes
- Not applicable to categorical data
Local minima
Non-globular clusters
Outliers
9

K-means extensions
K-means++ To improve the initialization process
X-means To find the optimal number of clusters without prior knowledge
Kernel K-means To form arbitrary/non-globular shaped clusters
Fuzzy c-means Multiple cluster assignment (membership degree)
K-medians More robust to outliers (median of each feature)
K-medoids More robust to outliers, different distance metrics, categorical data
Bisecting K-means and many more ...10
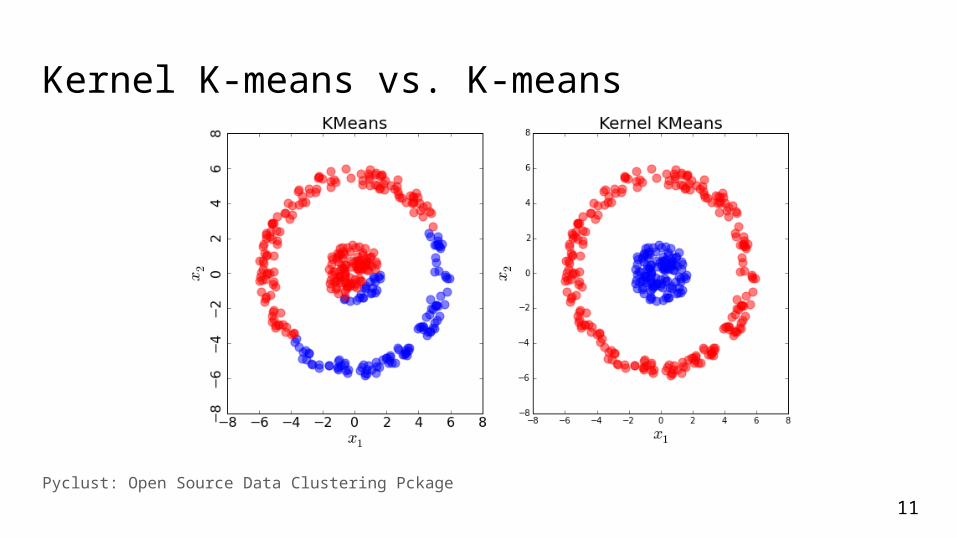
Kernel K-means vs. K-means
Pyclust: Open Source Data Clustering Pckage
11

Bisecting K-means
12Pyclust: Open Source Data Clustering Pckage

Other approaches in data clustering
Prototype-based methods• Clusters are formed based on similarity to a prototype• K-means, k-medians, k-medoids, …
Density based methods (clusters are high density regions separated by low density regions)• Jarvis-Patrick Algorithm: similairty between patterns defined
as the number of common neighbors• DBSCAN (MinPts, ε-neighborhood)Identify types noise points/border points/core points
13

DBSCAN pros and cons
+ No need to know number of clusters apriori+ Identify arbitrary shaped clusters+ Robust to noise and outliers- Sensitivity to the parameters- Problem with high dimensional data (subspace clustering)
14

Clustering Validation
1. Internal Validity Indexes• Assessing clustering quality based on how the data itself fit in the clustering
structure
• Silhouette
• Stability and Admissibility analyses Test the sensitivity of an algorithm to changes in data while keeping the structures intact
Convext admissiblity, cluster prportion, omission, and monotone admissibility
15
clustersother allwithofitydissimilaraveragesmallest:)(clustersamethewithinofitydissimilaraverage:)(
)()(max)()()(
iibiia
ibiaiaibiS

Clustering Validation
2. Relative IndexesAssessing how similar two clustering solutions are
3. External IndexesComparing a clustering solution with ground-truth labels/clustersPurity, Rand Index (RI), Normalized Mutual Information, Fβ-score, MCC, …
16
RePr
Re.Pr1
Re
Pr2
2
F
FNTPTP
FPTPTP
k
kjc
Njmax1C,Purity
Purity is not a reliable measure by itself

Part 2:
Fast and Accurate K-means for Large Datasets
Shindler, Michael, Alex Wong, and Adam W. Meyerson. "Fast and accurate k-means for large datasets." Advances in neural information processing systems. 2011
17

Motivation
Goal: Clustering Large Datasets Data cannot be stored in main memoryStreaming model (sequential access)
Facility Location problem: desired facility cost is given without prior knowledge of k
• Original K-means requires multiple passes through data not suitable for big data / streaming data
18

Well Clusterable Data
An instance of k-means is called σ-separable if reducing the number of clusters increases the cost of optimal k-means clustering by 1/σ2
K=3Jk=3(C)
K=2Jk=2(C))(
)(
3
22
CJCJ
k
k
20

K-means++ Seeding Procedure (non-streaming)
Let S be the set of already selected seeds
1. Initially choose a point uniformly at random
2. Select a new point randomly with probability according to
3. Repeat until
• An improved version allows more than k centers
Advantage: avoiding local minima traps
K-means++: The advantages of careful seeding, N. Ailon et al.
j
jSpSpd
),(),(2
min
kS ||
kS ||
22

Proposed AlgorithmInitializeGuess a small facility cost
Find the closest facility pointDecide whether to create a new facility
point, or assign it to the closest cluster facility (add the weight=contribution to facility cost)
Number of facility points overflow:increase fMerge (wegihted) facility points
23

Approximate Nearest Neighbor
Finding nearest facility point is the most time consuming part
1. Construct a random vector
2. Store the facility points in order of
3. For a new point , find the two facilities
such that
4. Compute the distances to and
This approximation can increase the approximation ratio by a constant factor
w
iyw.iy
x
)(log... 1 Oywxwyw ii
iy 1iy
iyw.1. iyww
24

Algorithm Analysis
Determine better facility cost
Better approximation ratio (17) much less than previous work by Braverman
Running time
Running time with approximate nearest neighbor
25
)log( nnk
))loglog(log( nkn

Part 3:
Active Clustering of Biological Sequences
Voevodski, Konstantin, et al. "Active clustering of biological sequences." The Journal of Machine Learning Research 13.1 (2012): 203-225.
26

Motivation
BLAST Sequence Query• Create a hash table of all the words• Pairwise alignment of subsequences in the same bucketNo need to calculate the distances of a new query sequence to all the database sequences
Previous clustering algorithm for gene sequences require all pair-wise calculations
Goal: develop a clustering algorithm without computing all pair distances
Query sequence
Hash Table
27

Landmark Clustering Algorithm
Input:Dataset SDesired number of clusters kProbability of performance guaranteeObjective function
propertystability ),1(
1
Main Procedures:1. Landmark Selection2. Expanding Landmarks3. Cluster Assignment
k
i Cxi
i
cxdC1
),()(
28
...},,{ 21 llL nnLO log||:TimeRunning

Landmark Selection
Distance Calculations
L
|)|.|(| LSO29

Expand-Landmarks
Landmark l is working if
}),(|{ rlsdSsBrl
Ball B around landmark l
minsBl
30

Cluster Assignment
Construct graph using working landmark, • Nodes represent (working) landmarks • Edges represent the overlapping balls
Find the connected components of graph
Clustered points are the set of points in these balls
The number of clusters is
BG
}Comp,...,Comp{)(Components 1 mBG
)(Components BG
31

Performance AnalysisNumber of required landmarks
Active landmark selectionUniform selection (degrading performance)
Good points:
Landmark spread property: any set of good points must have a landmark closer than
With high probability (1-δ), landmark spread property is satisfied
Based on landmark spread property, Expand-Landmarks correctly cluster most of the points in a cluster core- Assumption of large clusters, doesn’t capture smaller clusters 32
critcrit dxwxwdxw 17)()(and)( 2
)(xw
)(2 xw
critd
/1lnkO /ln kkO

Part 4:
Spectral Relaxation of K-means Clustering
Zha, Hongyuan, et al. "Spectral relaxation for k-means clustering." Advances in neural information processing systems. 2001.
33

Motivation
K-means is prone to local minima
Reformulate k-means objective function as a trace maximization problem
Different approaches to tackle this local minima issue:
• Improving the initialization process (K-means++)
• Relaxing constraints in the objective function (spectral relaxation method)
34

Derivation
Data matrix D Cost of a partitioning
Cost for an single cluster
Maximizing minimizing
k
i
s
si
is
i
mdss1 1
2)()(
22
1
2)( /Fi
TsiF
Tii
s
si
isi seeIDemDmdss
i
i
k
i ii
Ti
i
T
iTi
k
ii s
eDDs
eDDssss )(trace)(1
)(trace)(trace)( XDDXDDss TTT matrixindicator lorthonormak n is where X
)(trace DXDX TT )(ss
1...1......1...1
e
35

Theorem
For a symmetric matrix with eigenvalues n ...21nnH
)(tracemax...21 YHY T
IYYn
kT
36

Cluster Assignment
Global Gram matrix
Gram matrix for cluster i:
Eigenvalue decomposition largest eigenvalue
Err
DD
DDDD
DD
kTk
T
T
T
...00............0...00...0
22
11
iTi DD
ii yiiiiTi yyDD ˆ
n
njjjT
yyy
yyDD
21
21 ...
DDT
37

Cluster Assignment
Method1: apply k-means to the matrix of k largest eigenvectors of global gram matrix (pivoted k-means)
Method2: (pivoted QR decomposition of )
Davis-Khan sin(θ) Theorem: matrix orthogonal iswhere)(ˆ kkVErrOVYY kk
38
kcluster1cluster
ˆ,...,ˆ....ˆ,...,ˆ 111111 1 kkskksT
k vyvyvyvyYk
TkY

Part 5:
Application for Microbial Community Detection
39

Large genetic sequence datasets
Goal: cluster in streaming model / limited passes
Landmark selection algorithm (one pass)
Expand landmarks and assigning sequences to the nearest landmark
Finding the nearest landmark: A hashing scheme to find the nearest landmark
Require choice of hyper-parameters
Assumption of σ-separability, and large clusters
40

Hashing Scheme for nearest neighbor search
Shindler’s approximate nearest neighbor numeric random vector
Create random sequences
Hash function: Levenshtein (edit) distance between sequence x, and random sequences
41
New sequencex
Hash Table
xww .
Closest landmark
mrrr ...,,, 21
),( ii rxEdith

Acknowledgements
Department of Computer Science and Engineering,Michigan State University
My friend Sebastian Raschka, Data Scientist and author of “Python Machine Learning”
Please visit http://vahidmirjalili.com
42


















