

Large data with Scikit-learn - Boston Data Mining Meetup - Alex Perrier
30
LARGE DATA WITH SCIKIT-LEARN Alex Perrier - Data & Software - - Day Data Science contributor - - Night @alexip @BerkleeOnline @ODSC
-
Upload
alex-perrier-ph-d -
Category
Data & Analytics
-
view
351 -
download
1
Transcript of Large data with Scikit-learn - Boston Data Mining Meetup - Alex Perrier

LARGE DATA WITH SCIKIT-LEARN
Alex Perrier -
Data & Software - - Day
Data Science contributor - - Night
@alexip
@BerkleeOnline
@ODSC

PLAN1) What is large data?
out-of-core, streaming, online, batch?
2) Algorithms
3) Implementation
4) Examples

WHAT IS LARGE DATA?Cannot �t in the main memory (RAM)
2-10Gb makes the computer swap toomuch. Slow!
From in-memory to on-disk
Being able to work with data that �ts on disk on asingle machine with no cluster

MANY GREAT ALTERNATIVESDato:
memory optimized
Text: [py]R:
GraphLab createH20.ai
AWS instancespySpark MLlib
GensimSGD streaming package

TERMINOLOGYOut-of-core / External memory
Data does not �t in main memory => access data storedin slow data store (disk, ...), slower (10x, 100x)
O�ine: all the data is available from the start
Online: Serialized. Same results as o�ine. Act on newdata right away
Streaming Serialized. limited number of passes overthe data, can postpone processing. "old" data is of lessimportance.
Minibatch, Serialized in blocks
Incremental = online + minibatch

http://stats.stackexchange.com/questions/22439/incremental-or-online-or-single-pass-or-data-stream-clustering-refers-to-the-sam

clf = Some Model or Transformation
Train on training data X_train, y_train
Predict on test data: X_test => y_test
Assess model performance on test: y_truth, vs y_test
Predict on new data:
clf.�t(X_train,y_train)
y_test = clf.predict(X_test)
clf.score(y_truth, y_test, metric = ...)
= clf . predict( )y ̂ Xnew

SCIKIT-LEARN: OUT-OF-CORE
Split the training data in blocks: mini-batch (sequential,random, ...)
Load each block in sequence
Train the model adaptively on each block
Convergence!

SCIKIT-LEARN MINIBATCH LEARNINGBatch size nsplit the data in N blocks.partial_�t instead of .�t
clf.partial_�t(X_train(i),y(i), all_classes)
All possible classes given to partial_�t on �rst calli = 1..N number of blocks

SCIKIT: IMPLEMENTATIONImplementation with generators
Generator code
better example

II ALGORITHMS

ALGORITHMSRegression Classi�cation
Stochastic Gradient (1) X X
Naive Bayes (2) X
(1) SG + PassiveAggressive + Perceptron (clf only)
(2) NB: MultinomialNB, BernoulliNB
Clustering Decomposition
MiniBatchKMeans X X
DictionaryLearning, PCA X

with
Stochastic Gradient - Wiener �ltering
Gradient Descent solves
= ( X Yw0 XT )+1XT
= + μ [( + ) ]wn+1 wn ∑i
wTn xi yi xi
Deterministic!

Deterministic!
SGD / LMS:
Approximate the gradient one sample at a time ,xi yi
= + μ( + )wn+1 wn wTn xi yi xi
Slow convergencePoor approximation of Gradient => oscillations
Mini-batch SGD / Block-LMS
N sample at a time to estimate the gradient
= + [( + ) ]wn+1 wnμN ∑
i
N
wTn xi yi xi
Less gradient noise, better convergence than SGD, stillvery optimizable

very optimizable
OTHER LOSS FUNCTIONS
GD: loss = MSEPassive Aggressive: Hinge lossPerceptron: loss = +/- 1

MINI BATCH K-MEANS
D. Sculley @Google, 2010, Web Scale K-Means Clustering
Each mini-batchEach sample in the batch
Find closes center (min dist)Each sample in the batch
Update with
xCx
xCx
= (1 + ) + μxCxμ
| |CxCx

Not same partition as K-Means, but much faster
Same convergence level

Classi�cation: Mini-batches need to be balanced forclasses
Perceptron, PA and SGD put di�erent emphasis onsamples over time.
Batch size in�uences?

BATCH SIZEThe bigger the better? until you run out of memory?
time e�ciency of training (small batch) VS noisinessof gradient estimate (large batch)
Adding some noise (small batch) can be interesting to getout of local minimas
In practice
small to moderate mini-batch sizes (10-500)decaying learning rate
https://www.quora.com/Intuitively-how-does-mini-batch-size-a�ect-the-performance-of-gradient-descent

III EXAMPLES
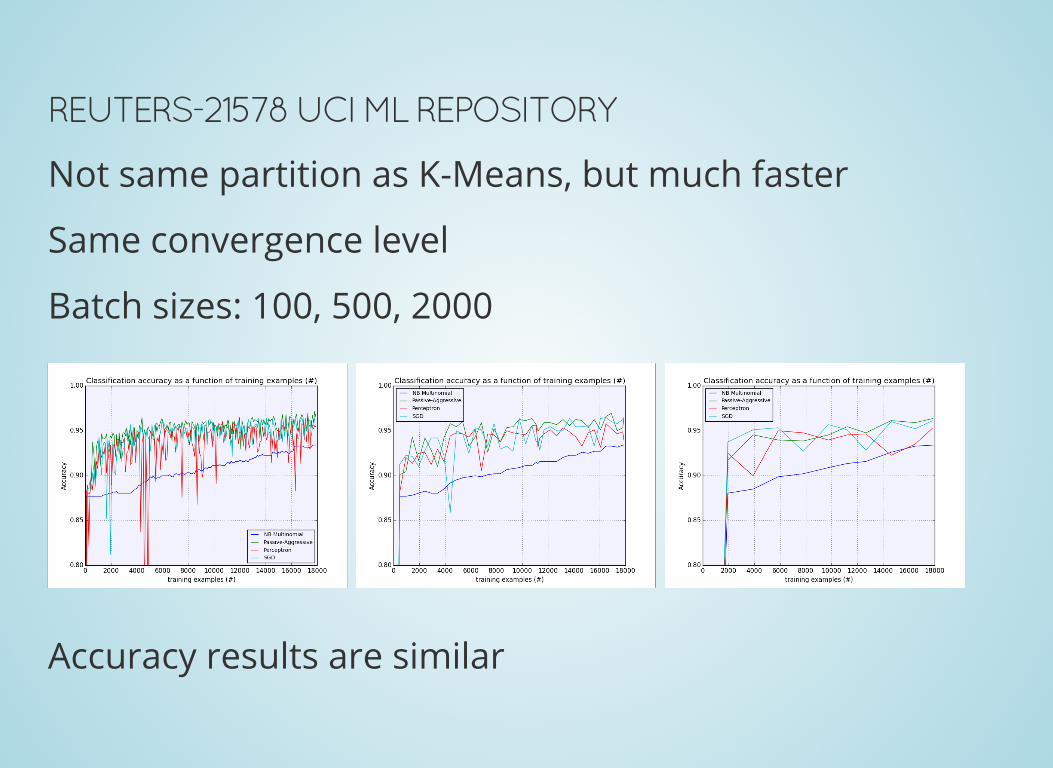
REUTERS-21578 UCI ML REPOSITORY
Not same partition as K-Means, but much faster
Same convergence level
Batch sizes: 100, 500, 2000
Accuracy results are similar
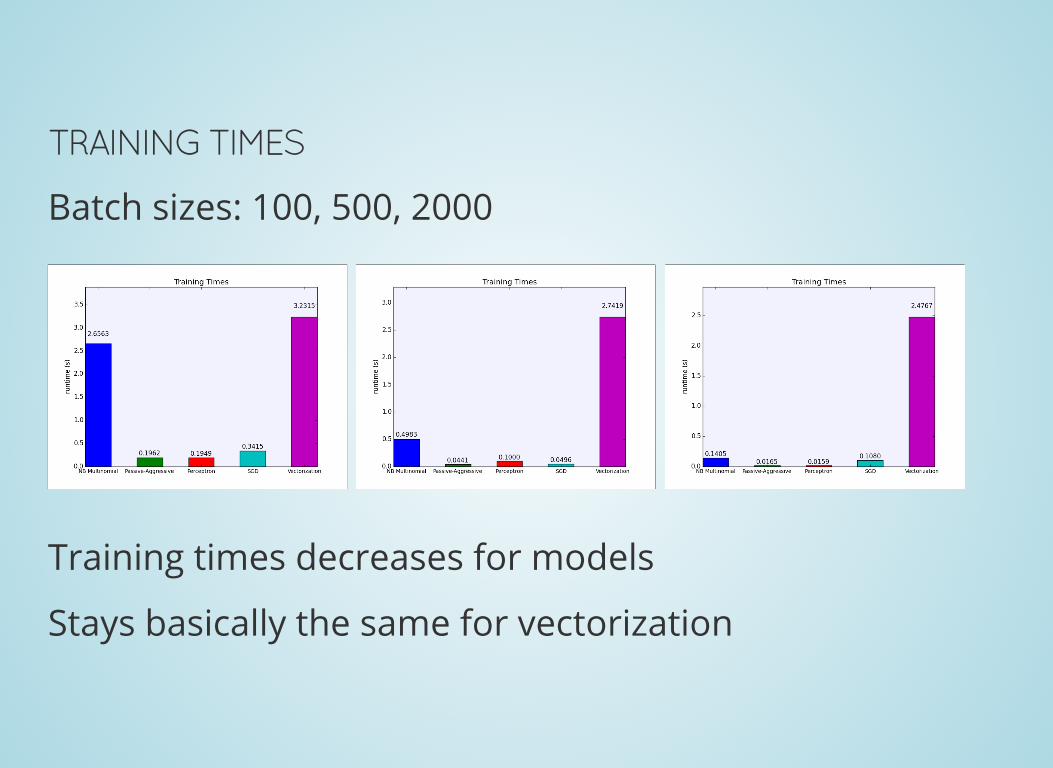
Training times decreases for models
TRAINING TIMES
Batch sizes: 100, 500, 2000
Stays basically the same for vectorization

Large training dataset, 30k HTML pages, 36Gb
feature extraction, vectorization: TfIdf / Hashing Trick
10k training 4k test

MODEL COMPARISON
10k pages, 500 batch size, 100 iterations
NB steadily converges,
SGD, PA, Perceptron: unstable

BATCH SIZE
Naive Bayes, Batch size: 10, 100 and 500

PART II DATA MUNGING (NEXT TIME)Loading csv �lesParsing, segmenting,word counts, TfIdF, hashing vectorizer
=> time consuming

DASKContinuum IO (same people who brought you Conda)Easy install pip or conda (no JVM like spark)Blocked algorithmCopies the numpy interfaceVery little code changesMatthew Rocklin - PyData 2015

LINKS
Memory imprint of Python Dict
Dask
scikit learn
http://scikit-learn.org/stable/modules/scaling_strategies.htmlhttp://scikit-learn.org/stable/auto_examples/applications/plot_out_of_core_classi�cation.html#example-applications-plot-out-of-core-classi�cation-py
https://blog.scrapinghub.com/2014/03/26/optimizing-memory-usage-of-scikit-learn-models-using-succinct-tries/
https://github.com/dask/dask-examples/blob/master/nyctaxi-2013.ipynb
http://fa.bianp.net/talks/she�eld_april_2014/#/step-19
http://scikit-learn.org/stable/auto_examples/applications/plot_out_of_core_classi�cation.html#example-applications-plot-out-of-core-classi�cation-py
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassi�er.html
https://github.com/scikit-learn/scikit-learn/issues/4834

https://github.com/scikit-learn/scikit-learn/issues/4834https://github.com/szilard/benchm-ml/blob/master/0-init/1-install.txthttp://cs229.stanford.edu/materials.htmlhttp://stackover�ow.com/questions/15036630/batch-gradient-descent-with-scikit-learn-sklearnhttp://sebastianruder.com/optimizing-gradient-descent/Passive Aggresssive


















