
Lapack / ScaLAPACK / Multi-core and more Julie Langou @ UCSB - April 16 th 2007.
59
Lapack / ScaLAPACK / Multi-core and more Julie Langou @ UCSB - April 16 th 2007
-
Upload
emery-preston -
Category
Documents
-
view
223 -
download
0
Transcript of Lapack / ScaLAPACK / Multi-core and more Julie Langou @ UCSB - April 16 th 2007.

Lapack / ScaLAPACK / Multi-core and more
Julie Langou @ UCSB - April 16th 2007

04/18/23 17:58 2
My background
» Education» Bachelor degree in Applied Mathematics, Toulouse France» Master degree in Computer Science related to Space and
Aircraft industries, Toulouse, France.» Work
» Software Engineer for CDC, the French leader in insurance and financial services (I.e AIG, ING Direct, etc…), Paris, France.
» Principal Software Engineer on HMIS (Homeless shelters) in Knoxville,TN
» Research Associate at ICL - Innovative Computing Laboratory, Knoxville TN since 2004.
» Julien (CERFACS / ICL / CU Denver): Research Interests: Numerical Linear Algebra
* Iterative methods for finding eigenvalues of Hermitian matrices with application in nanotechnology,
* Iterative methods for multiple right-hand sides * LAPACK, ScaLAPACK: working on the new release, due for 2007 * FTLA: Fault Tolerant Linear Algebra * Stability of numerical schemes in particular numerical stability of
orthogonalization methods * Allreduce Algorithms - QR factorization of a tall and skinny matrix

04/18/23 17:58 3
Plan
» My occupation at ICL» Software Engineering LAPACK» Single-double Iterative Refinement Routines for LAPACK
» Windows support for LAPACK/ScaLAPACK/ATLAS
» Multicore» PLASMA (Parallel Linear Algebra for Scalable Multi-core Architectures)
» Benchmarking of Neumann
» Surprise…

04/18/23 17:58 4
Plan
» My occupation at ICL» Software Engineering LAPACK» Single-double Iterative Refinement Routines for LAPACK
» Windows support for LAPACK/ScaLAPACK/ATLAS
» Multicore» PLASMA (Parallel Linear Algebra for Scalable Multi-core Architectures)
» Benchmarking of Neumann

04/18/23 17:58 5
LAPACK – 3.1 (released for SC06)
============================= == LAPACK 3.1: What's new == ============================= 1) Hessenberg QR algorithm with the small bulge multi-shift QR algorithm together with
aggressive early deflation. This is an implementation of the 2003 SIAM SIAG LA Prize winning algorithm of Braman, Byers and Mathias, that significantly speeds up the nonsymmetric eigenproblem.
2) Improvements of the Hessenberg reduction subroutines. These accelerate the first phase of the nonsymmetric eigenvalue problem. See the reference by G. Quintana-Orti and van de Geijn below. 3) New MRRR eigenvalue algorithms that also support subset computations. These implementations of the 2006 SIAM SIAG LA Prize winning algorithm of Dhillon and Parlett are also significantly more accurate than the version in LAPACK 3.0.
4) Mixed precision iterative refinement subroutines for exploiting fast single precision hardware. On platforms like the Cell processor that do single precision much faster than double, linear systems can be solved many times faster. Even on commodity processors there is a factor of 2 in speed between single and double precision. These are prototype routines in the sense that their interfaces might changed based on user feedback.
5) New partial column norm updating strategy for QR factorization with column pivoting. This fixes a subtle numerical bug dating back to LINPACK that can give completely wrong results. See the reference by Drmac and Bujanovic below.
6) Thread safety: Removed all the SAVE and DATA statements (or provided alternate routines without those statements), increasing reliability on SMPs.
7) Additional support for matrices with NaN/subnormal elements, optimization of the balancing subroutines, improving reliability.
8) Several bug fixes.

04/18/23 17:58 6
LAPACK-3.1: faster
» xGEHRD (reduction to Hessenberg form)contributor: Daniel Kressnerref: Gregorio Quintana-Orti and Robert van de Geijn, Improving the Performance of Reduction to Hessenberg Form. ACM Transactions on Mathematical Software, 32(2):180-194, June 2006.
» xHSEQR (QR algorithm for Hessenberg matrix)contributor: Karen Braman and Ralph Byersref: K. Braman, R. Byers and R. Mathias, The Multi-Shift QR Algorithm Part I : Maintaining Well Focused Shifts, and Level 3 Performance, SIAM Journal of Matrix Analysis, volume 23, pages 929-947, 2002.ref: K. Braman, R. Byers and R. Mathias, The Multi-Shift QR Algorithm Part II: Aggressive Early Deflation, SIAM Journal of Matrix Analysis, volume 23, pages 948--973, 2002.

04/18/23 17:58 7
Some results for the full nonsymmetric eigenvalue problem
ZGEEV [n=1500, jobvl=V, jobvr=N, random matrix, uniform [-1.1] entries dist]
LAPACK 3.0 LAPACK 3.1 (3.0)/(3.1)
checks 0.00s (0.00%) 0.00s (0.00%)
scaling 0.13s (0.05%) 0.12s (0.20%)
balancing 0.08s (0.04%) 0.08s (0.13%)
Hessenberg reduction 13.39s (5.81%) 12.17s (19.31%) 1.10x
zunghr 3.93s (1.70%) 3.91s (6.20%)
Hessenberg QR algorithm 203.16s (88.10%) 36.81s (58.42%) 5.51x
compute eigenvectors 9.82s (4.26%) 9.83s (15.59%)
undo balancing 0.09s (0.04%) 0.09s (0.15%)
undo scaling 0.00s (0.00%) 0.00s (0.00%)
total 230.60s (100.00%) 63.02s (100.00%) 3.65x
ARCH: Intel Pentium 4 ( 3.4 GHz )F77 : GNU Fortran (GCC) 3.4.4BLAS: libgoto_prescott32p-r1.00.so (one thread)
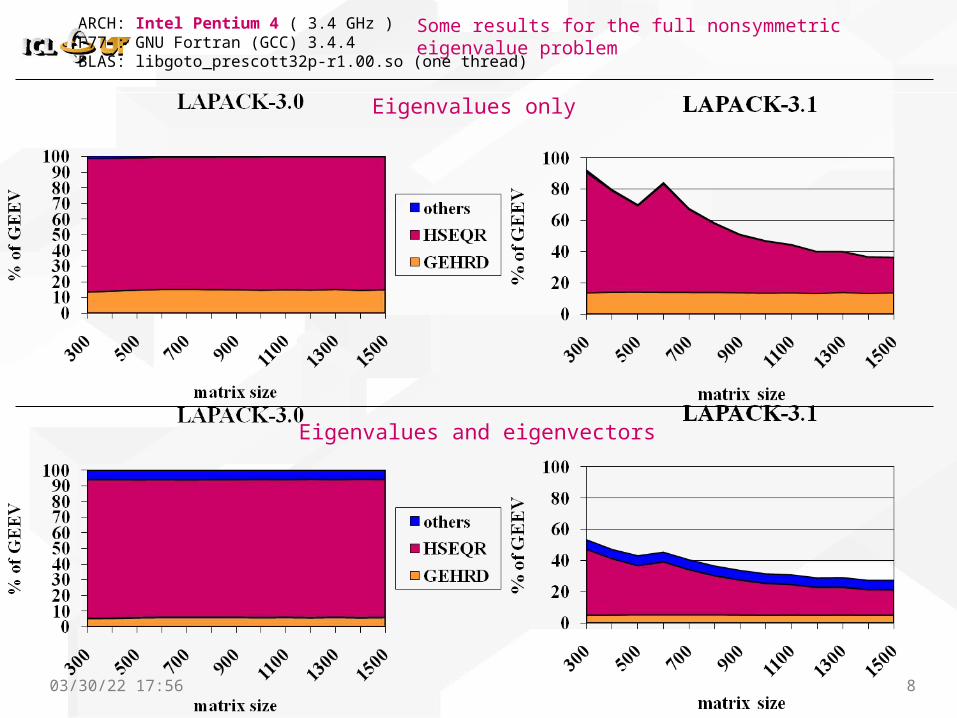
04/18/23 17:58 8
Some results for the full nonsymmetric eigenvalue problem
ARCH: Intel Pentium 4 ( 3.4 GHz )F77 : GNU Fortran (GCC) 3.4.4BLAS: libgoto_prescott32p-r1.00.so (one thread)
Eigenvalues and eigenvectors
Eigenvalues only
04/18/23 17:58 9
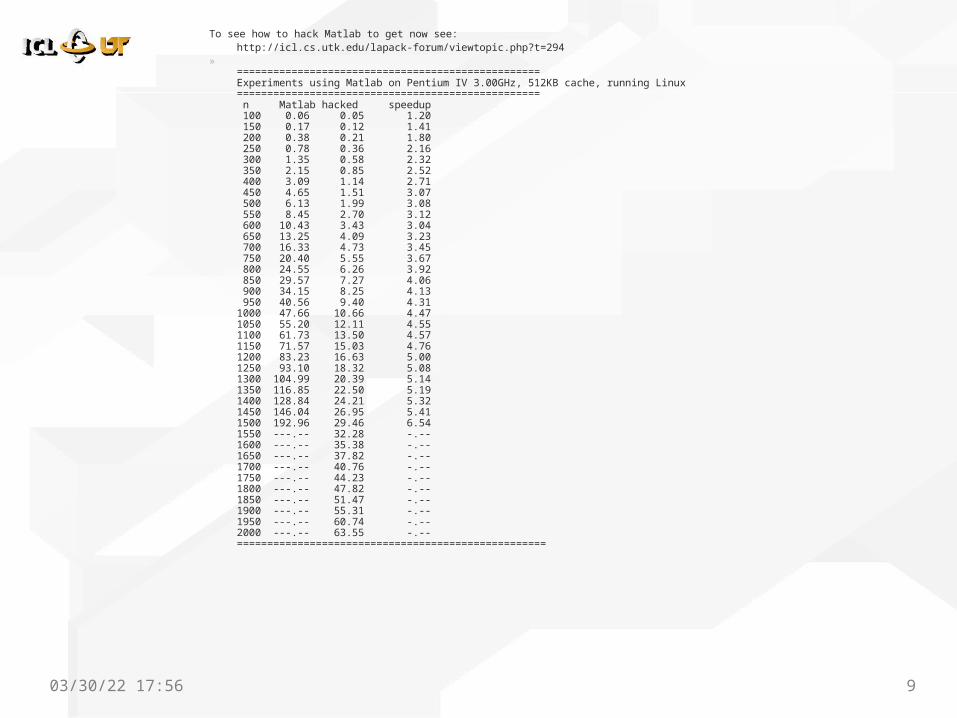
To see how to hack Matlab to get now see:http://icl.cs.utk.edu/lapack-forum/viewtopic.php?t=294
»==================================================Experiments using Matlab on Pentium IV 3.00GHz, 512KB cache, running Linux ================================================== n Matlab hacked speedup 100 0.06 0.05 1.20 150 0.17 0.12 1.41 200 0.38 0.21 1.80 250 0.78 0.36 2.16 300 1.35 0.58 2.32 350 2.15 0.85 2.52 400 3.09 1.14 2.71 450 4.65 1.51 3.07 500 6.13 1.99 3.08 550 8.45 2.70 3.12 600 10.43 3.43 3.04 650 13.25 4.09 3.23 700 16.33 4.73 3.45 750 20.40 5.55 3.67 800 24.55 6.26 3.92 850 29.57 7.27 4.06 900 34.15 8.25 4.13 950 40.56 9.40 4.31 1000 47.66 10.66 4.47 1050 55.20 12.11 4.55 1100 61.73 13.50 4.57 1150 71.57 15.03 4.76 1200 83.23 16.63 5.00 1250 93.10 18.32 5.08 1300 104.99 20.39 5.14 1350 116.85 22.50 5.19 1400 128.84 24.21 5.32 1450 146.04 26.95 5.41 1500 192.96 29.46 6.54 1550 ---.-- 32.28 -.-- 1600 ---.-- 35.38 -.-- 1650 ---.-- 37.82 -.-- 1700 ---.-- 40.76 -.-- 1750 ---.-- 44.23 -.-- 1800 ---.-- 47.82 -.-- 1850 ---.-- 51.47 -.-- 1900 ---.-- 55.31 -.-- 1950 ---.-- 60.74 -.-- 2000 ---.-- 63.55 -.-- ===================================================

04/18/23 17:58 10
Promises made
» Goal 1 – Better Numerics• MRRR algorithm for SEP • Up to 5x faster HQR• Up to 10x faster HQZ• Recursive• Jacobi for SVD and SEP• Iterative refinement for Ax=b, least squares
» Goal 2 – Expanded Content
• Make content of ScaLAPACK mirror LAPACK as much as possible: driver for complex SVD (Du), driver for NEP.
• Add new functions (examples)– Updating / downdating of factorizations– More generalized SVDs– More generalized Sylvester/Lyapunov eqns–
Structured eigenproblems• O(n2) version of roots(p)• Selected matrix polynomials• Arbitrary precision, quads
» New (not in the proposal)» single-double iterative
refinement routines» Drmac: QR column pivoting» Gustavson: RFP (Rectangular
Full Packed) format
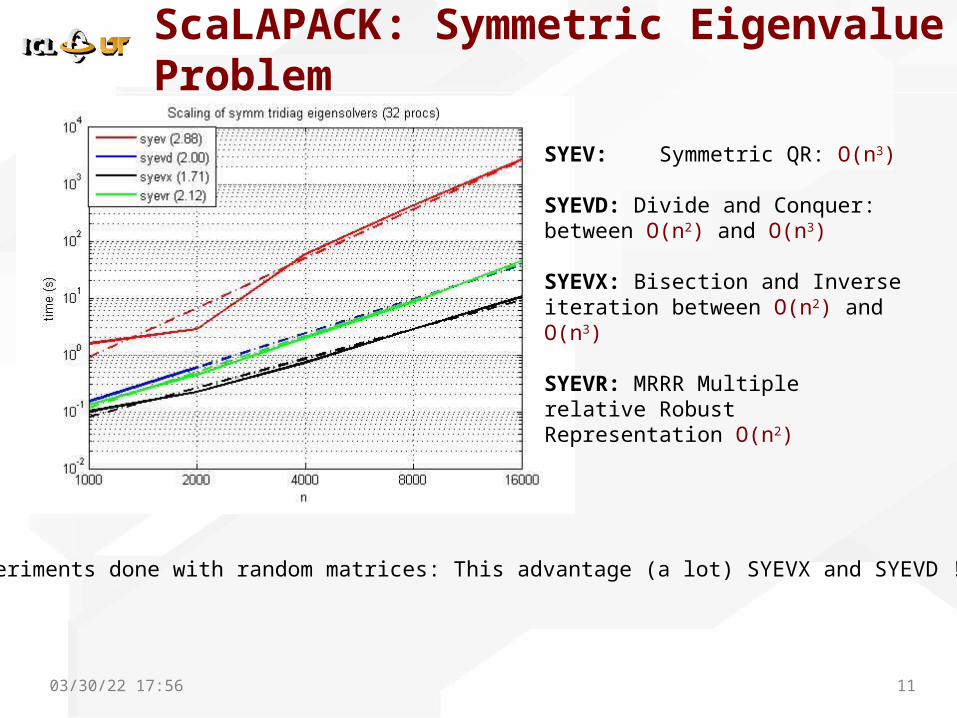
ScaLAPACK: Symmetric Eigenvalue Problem
04/18/23 17:58 11
SYEV: Symmetric QR: O(n3)
SYEVD: Divide and Conquer: between O(n2) and O(n3)
SYEVX: Bisection and Inverse iteration between O(n2) and O(n3)
SYEVR: MRRR Multiple relative Robust Representation O(n2)
Experiments done with random matrices: This advantage (a lot) SYEVX and SYEVD !

04/18/23 17:58 12
LAPACK / ScaLAPACK release » Release
» [November 11, 2006] LAPACK 3.1.0» [February 26, 2007] LAPACK-3.1.1» LAPACK 4.0 …September 2007?
» [Feb 01, 2006] scalapack-1.7.1 » [Feb 23, 2006] scalapack-1.7.2 » [March 22, 2006] scalapack-1.7.3» [May 26, 2006] scalapack-1.7.4» [January 16, 2007] scalapack-1.7.5 » [April 5, 2007] scalapack-1.8.0
» Software Engineering» Sca/LAPACK Program Style
» Trac website: web-based software project management. » Automate testing system: buildbot. » LAPACK forum : working better than expected.» Still lots of email also on the [email protected]» New search engine

04/18/23 17:58 13
Plan
» My occupation at ICL» Software Engineering LAPACK» Single-double Iterative Refinement Routines for LAPACK
» Windows support for LAPACK/ScaLAPACK/ATLAS
» Multicore» PLASMA (Parallel Linear Algebra for Scalable Multi-core Architectures)
» Benchmarking of Neumann

Exploiting the Performance of 32 bit Floating Point Arithmetic in Obtaining 64
bit Accuracy
(Revisiting Iterative Refinement for Linear Systems)
Julie Langou Piotr Luszczek Alfredo Buttari
Julien Langou Jakub Kurzak Jack Dongarra

15
Architecture of the Cell
single-instruction multiple-data (SIMD) architecture : Synergistic Processor Unit
(SPU) Vector:128 bits
Fused add-multiplyLatency for double
operations: 6 cycles
IBM 64-bit Power Architecture™ core
AltiVec/VMX Vector Unit4 multiply-add /cycle for
single1 multiply-add/cycle for
double
http://domino.research.ibm.com/comm/research.nsf/pages/r.arch.innovation.htmlhttp://www.research.ibm.com/cell/cell_chip.html http://www-128.ibm.com/developerworks/power/library/pa-cellperf/
Cell is a heterogeneous chip multiprocessor that consists of an IBM 64-bit Power Architecture™ core, augmented with eight specialized co-processors based on a novel single-instruction multiple-data (SIMD) architecture. Clock: 3.2Ghz

16
Performance of the cell
This is how single precision performance breaks down for the CBE by “Jakub”» The vector unit of one SPE can do one vector operation each cycle.
A vector is 128 bits and can hold 4 floats. So, with fused add-multiply, you can have 8 single-precision floating point operation per cycle. The target clock is 3.2 GHz (our cell is 2.1), so you get 3.2 * 8 = 25.6 GFLOPS on a single SPU. You have 8 SPUs, so in total you can get 8 * 25.6 = 204.8 GFLOPS from the 8 SPUs. However the PPU has an Altivec/VMX vector unit which can also do 4 multiply-add operations per cycle. So if you add it all together, the total single-precision performance of the whole CBE is 230.4 GFLOPS.
» Double precision can also be processed in a vectorized fashion on an SPE, but a vector can store only 2 64-bit doubles, so performance is cut by 2. Additionally, the double precision operations are not fully pipelined, so one operation has a latency of 6 cycles, so you are 6 times slower. So in total you are 6*2=12 times slower for a double precision operation. And also the Altivec/VMX on the PPU cannot process doubles in a vectorized fashion, so on the PPU you rely on the standard floating point unit which should still do a single multiply-add in one cycle.
» To sum up, for double precision on a 3.2 GHz chip, you have 2.13 GFLOPS on a single SPU, so 2.13 * 8 = 17 in total, plus 6.4 on the PPU = 23.47 total. So, around 230 GFLOPS single precision and around 23 GFLOPS double precision
» Peak performance for single precision: ~230 GFlops
» Peak performance for double precision: ~24 GFlops

17
Problematic on the cell
» Single are 10 times faster than double!
» But single are 2 times less accurate than double
Can we get double accuracy results with a performance not too far from the peak of single
precision?

18
use iterative refinement!
» Factorize the matrix in single precision, O(n3) FLOP
» Then use this factorization as a preconditioner in a double precision iterative method, O(n2) FLOP
» The single LU factorization is a POOR double LU factorizationbut an EXCELLENT preconditioner
Typically the iterative methods will converge in few steps
» O(n3) FLOP vs O(n2): single computations dominate the # of FLOP:» Speed of Single precision
» Convergence in a double precision iterative solver:» Accuracy in Double precision

19
Introduction to Iterative Refinement
Algorithm
L U = lu(A) %LU factorization (SINGLE) O(n3) x = L\(U\b) % Solve (SINGLE) O(n2) r = b – Ax % Residual (DOUBLE) O(n2) (DOUBLE) O(n2) while ( || r || not small enough ), %stopping criteria
z = L\(U\r) %LU factorization on the residual (SINGLE) O(n2)
x = x + z % new solution (DOUBLE) O(n2) r = b - Ax % new residual (DOUBLE) O(n2)
End
COST: (SINGLE) O(n3) + #ITER * (DOUBLE) O(n2)

20
limitation
c(n). s . (A) < 1

21
limitation
c(n). s . (A) < 1
the condition number of A cannot be too large
(typically (A) < 108 for this scheme as opposed to
(A) < 1016 for regular double LU)
Limitation also with the range of the numbers used (overflow quicker in single)

22
Number of steps
» Approximately …
» double precision: d = 10-16 -> td = -log10(d) = 16
» single precision: s = 10-8 -> ts = -log10(s) = 8
» condition number: (A) = 104 -> tk = log10( (A) ) = 4
» Max # of steps = td/(ts-tk) = 16/(8-4) = 4

23
Single vs Double
Architectures (BLAS/LAPACK) nDGEMM/SGEMM
DGETRF/SGETRF
Cell - 10 10
Intel Pentium III Coppermine (Goto) 3500 2.10 2.24
Intel Pentium III Katmai (Goto) 3000 2.12 2.11
Sun UltraSPARC IIe (Sunperf) 3000 1.45 1.79
Intel Pentium IV Prescott (Goto) 4000 2.00 1.86
Intel Pentium IV-M Northwood (Goto) 4000 2.02 1.98
AMD Opteron (Goto) 4000 1.98 1.93
Cray X1 (libsci) 4000 1.68 1.54
IBM Power PC G5 (2.7 GHz) (VecLib) 5000 2.29 2.05
Compaq Alpha EV6 (CXML) 3000 0.99 1.08
IBM SP Power3 (ESSL) 3000 1.03 1.13
SGI Octane (ATLAS) 2000 1.08 1.13
Intel Itanium 2 (Goto and ATLAS) 1500 0.71

24
OPERATION PER CYCLE TIME
ProcessorSingle Double
x87 SSE 3DNOW! x87 SSE2
Pentium 1 0 0 1 0
Pentium II 1 0 0 1 0
Pentium III 1 4 0 1 0
Pentium 4 1 4 0 1 2
Athlon 2 0 4 2 0
Enhanced Athlon 2 0 4 2 0
Athlon4 2 4 4 2 0
AthlonMP 2 4 4 2 0
MMX : Set of "MultiMedia eXtensions" to the x86 ISA. Mainly new instructions for integer performance, and maybe some prefetch. For Intel, all chips starting with the PentiumMMX processor possess these extensions. For AMD, all chips starting with the K6 possess these extensions. SSE : Streaming SIMD (Single Instruction Multiple Data) Extensions. SSE is a superset of MMX.These instructions are used to speed up single precision (32 bit) floating point arithmetic. For Intel, all chips listed starting with the Pentium III possess SSE extensions. For AMD, all chips starting from Athlon4 possess SSE. 3DNow! :AMD's extension to MMX that does almost the exact same thing SSE does, except the single precision arithmetic is not IEEE compliant . It is also a superset of MMX (but not of SSE; 3DNow! was released before SSE). It is supported only on AMD, starting with the K6-2 chip. SSE2 :Additional instructions that perform double precision floating arithmetic. Allows for 2 double precision FLOPs every cycle. For Intel, supported on the Pentium 4 and for AMD, supported on the Opteron.
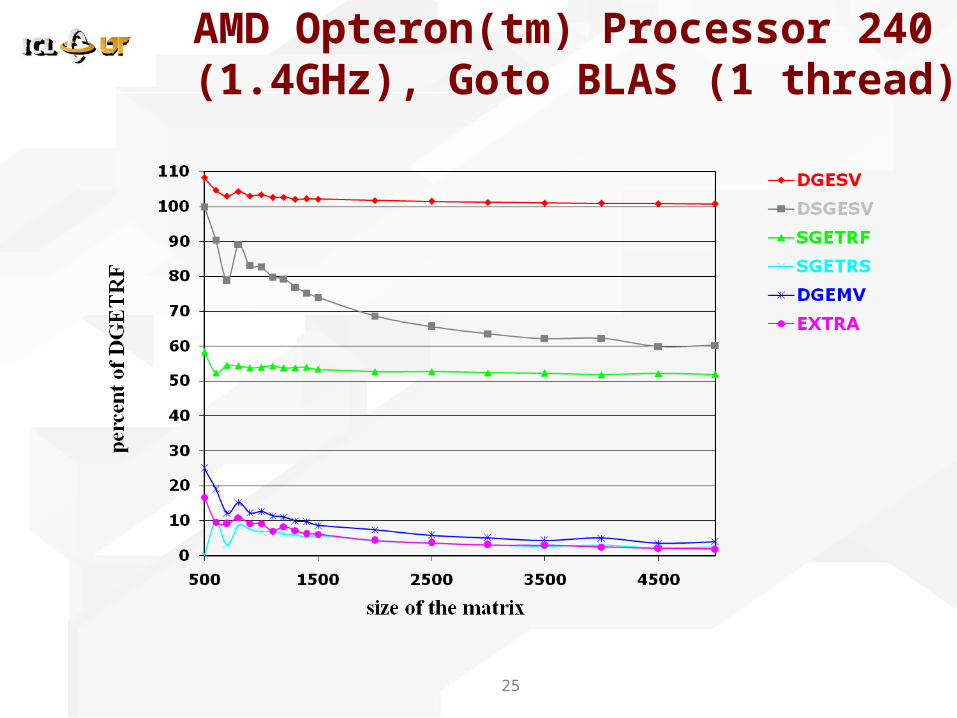
25
AMD Opteron(tm) Processor 240 (1.4GHz), Goto BLAS (1 thread)
26
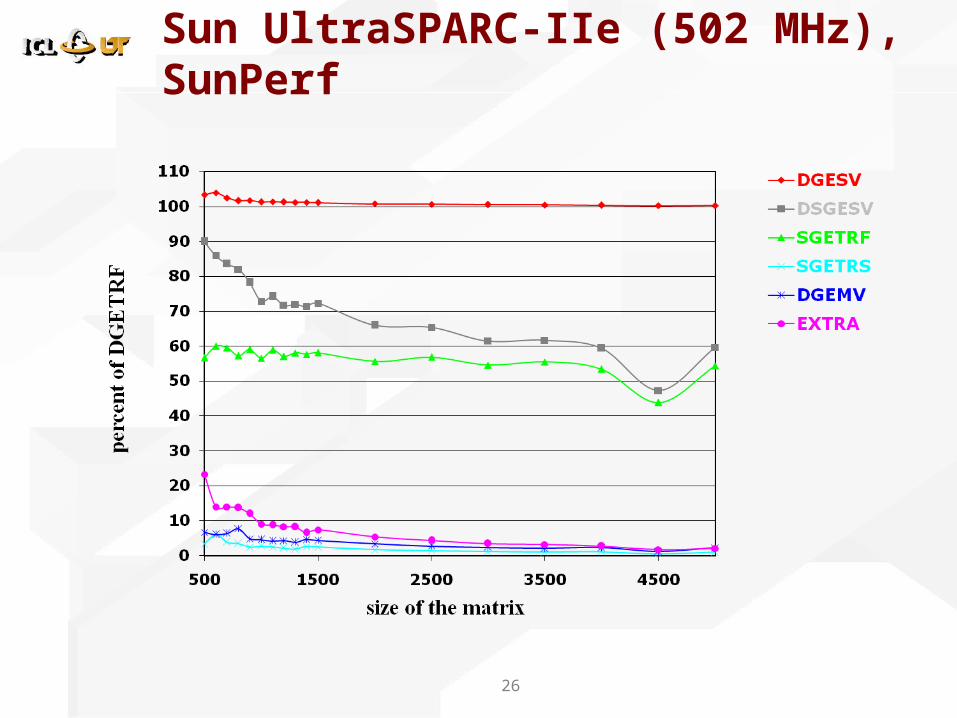
Sun UltraSPARC-IIe (502 MHz), SunPerf

27
Intel Pentium III CopperMine (0.9GHz), Goto BLAS

28
Intel Pentium Xeon Northwood (2.4GHz), Goto BLAS (1 thread)

29
Intel Pentium IV Prescott (3.4GHz), Goto BLAS (1 thread)
30
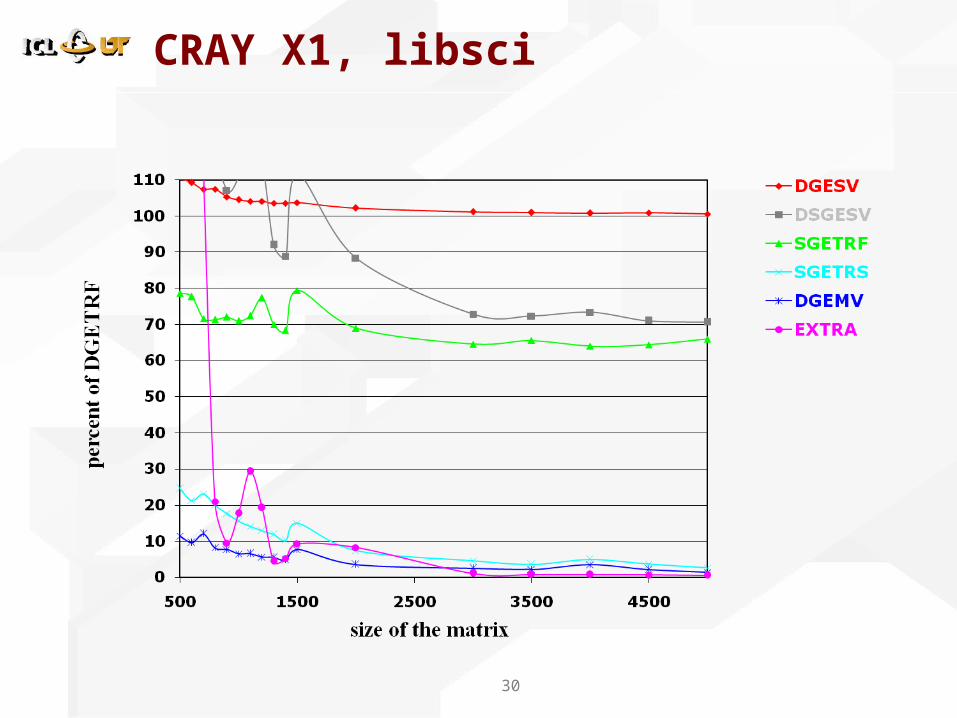
CRAY X1, libsci
31
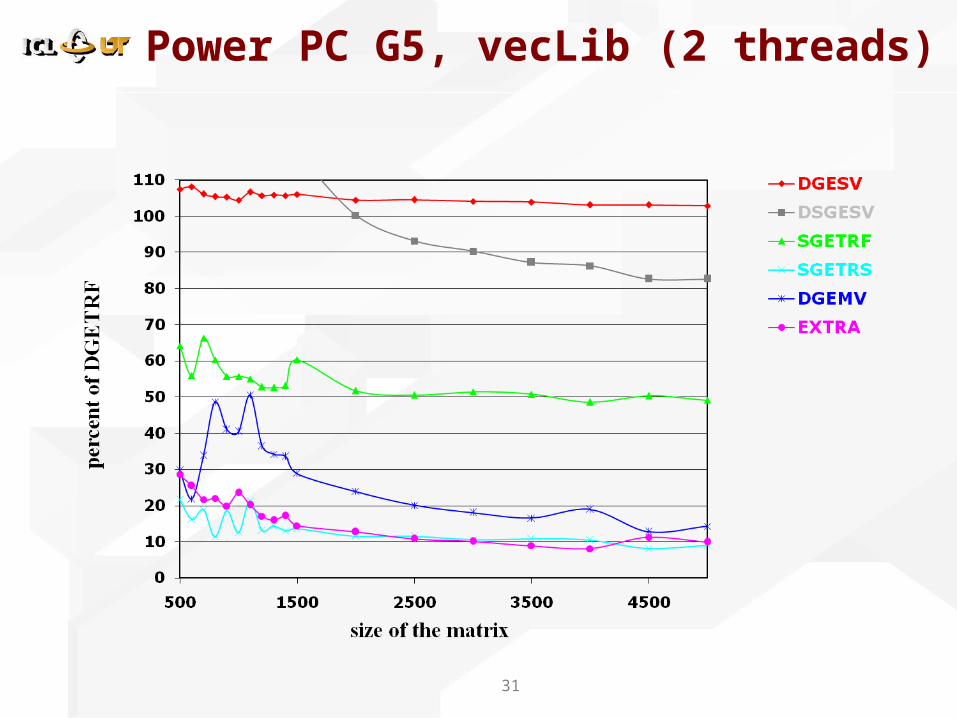
Power PC G5, vecLib (2 threads)
32
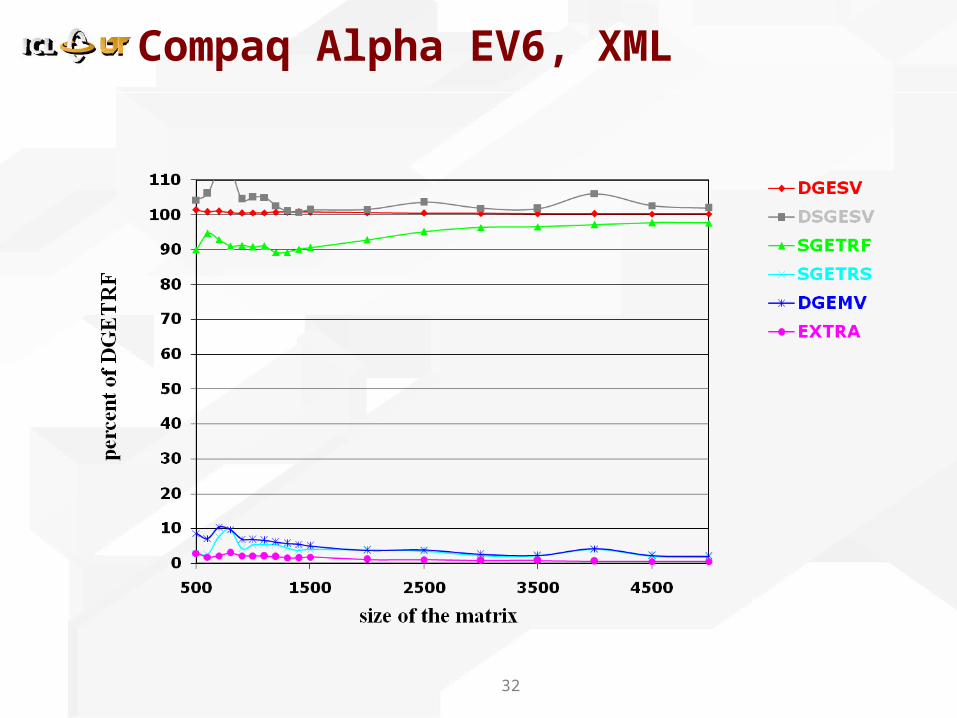
Compaq Alpha EV6, XML

33
SGI Octane (270 MHz), ATLAS 3.6 (1 thread)

34
IBM SP RS/6000, Power 3, (1.5 GHz), ESSL

35
Final Results
Architectures (BLAS/LAPACK) n DGEMM/SGEMM
DGETRF/SGETRF
DGESV/DSGESV
# iter
Intel Pentium III Coppermine (Goto) 3500 2.10 2.24 1.92 4
Intel Pentium III Katmai (Goto) 3000 2.12 2.11 1.79 4
Sun UltraSPARC IIe (Sunperf) 3000 1.45 1.79 1.58 4
Intel Pentium IV Prescott (Goto) 4000 2.00 1.86 1.57 5
Intel Pentium IV-M Northwood (Goto) 4000 2.02 1.98 1.84 5
AMD Opteron (Goto) 4000 1.98 1.93 1.53 5
Cray X1 (libsci) 4000 1.68 1.54 1.38 7
IBM Power PC G5 (2.7 GHz) (VecLib) 5000 2.29 2.05 1.24 5
Compaq Alpha EV6 (CXML) 3000 0.99 1.08 1.01 4
IBM SP Power3 (ESSL) 3000 1.03 1.13 1.00 3
SGI Octane (ATLAS) 2000 1.08 1.13 0.91 4
Intel Itanium 2 (Goto and ATLAS) 1500 0.71
very effective on a number but not for all the architectures.
36
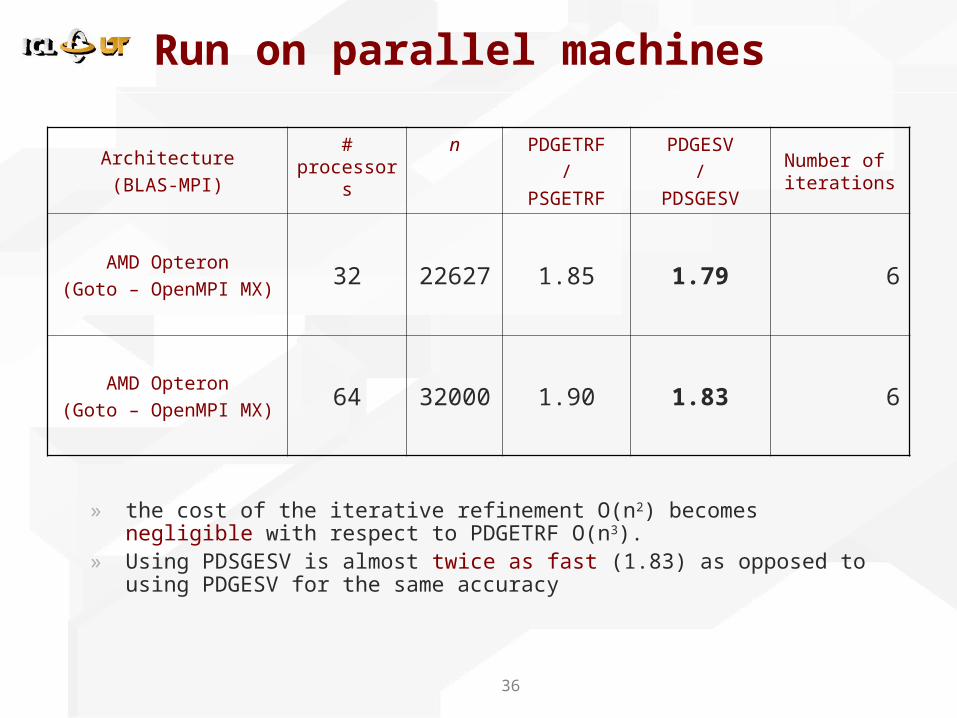
Run on parallel machines
Architecture(BLAS-MPI)
# processor
s
n PDGETRF/
PSGETRF
PDGESV/
PDSGESV
Number of iterations
AMD Opteron(Goto – OpenMPI MX)
32 22627 1.85 1.79 6
AMD Opteron(Goto – OpenMPI MX)
64 32000 1.90 1.83 6
» the cost of the iterative refinement O(n2) becomes negligible with respect to PDGETRF O(n3).
» Using PDSGESV is almost twice as fast (1.83) as opposed to using PDGESV for the same accuracy

37
Quad / double
» Expected Accuracy: 10-32
» No more than 3 steps of iterative refinement are needed. » The speedup goes from 10 (n=100) to close to 100 (n=1000).
nQGESV QDGESV
speedup time (s) time (s)
100 0.29 0.03 9.5
200 2.27 0.10 20.9
300 7.61 0.24 30.5
400 17.81 0.44 40.4
500 34.71 0.69 49.7
600 60.11 1.01 59.0
700 94.95 1.38 68.7
800 141.75 1.83 77.3
900 201.81 2.33 86.3
1000 276.94 2.92 94.8
» Intel Xeon 3.2Ghz
» ifort –O3» Reference Blas

38
Implementation and Testing
DSGESV computes the solution to a real system of linear equations A * X = B, where A is an N-by-N matrix and X and B are N-by-NRHS matrices. DSGESV first tries to factorize the matrix in SINGLE PRECISION and use this factorization within an iterative refinement procedure to produce a solution with DOUBLE PRECISION normwise backward error quality.If the approach fails the method switch to a DOUBLE PRECISION factorization and solve. The iterative refinement process is stopped if
ITER < ITERMAX = 30 or
Backward error = RNRM / ( XNRM * ANRM ) < MIN(4,SQRT(N/6) * EPS where
» ITER is the number of iteration in the iterative refinement process » RNRM is the 2-norm of the residual» XNRM is the 2-norm of the solution» ANRM is the Frobenius-norm of the matrix A» EPS is the relative machine precision returned by DLAMCH

39
Related work / Originality
» Iterative refinement is not a new subject. Lots of literature.
» Never been done for speed before, only for accuracy» Iterative refinement was used to
» Cope with not stable LU factorization (SuperLU, pivot growth)
» Improve forward error (cf. Berkeley guys)
» Most of the theorems on mixed-precision iter-ref are: “what is the SINGLE accuracy I can get with iterative
refinement single/double?”» Our problem is :
“what is the DOUBLE accuracy I can get using iterative refinement single/double?”
» See theoretical analysis at the end of technical report:http://www.cs.utk.edu/~library/TechReports/2006/ut-cs-06-574.pdf

40
extensions
» More Algorithms:» Cholesky / QR / eigenvalue / singular value
» More data format» GB : General band matrix, GE : General matrix (already in Lapack
3.1.0), GT : General tridiagonal matrix , PB : Positive Definite Symmetric Band Matrix, PO : Positive Definite Symmetric Matrix, PP : Packed Storage Definite Symmetric Matrix, PT : Packed Storage, SP : Symmetric Matrix Packed Storage, SY :Symmetric Matrix
» Various precisions» Quad/double
» Change the outer iterative methods» Richardson -> GCR, GMRES
» Change the inner solve (SPARSE)» Instead of backward/forward solve in LU single, any solver
(iterative methods) will do. See Alfredo Buttari, Jack Dongarra, Jakub Kurzak, Piotr Luszczek, and Stanimire Tomov. Computations to Enhance the Performance while Achieving the 64-bit Accuracy. UT-CS-06-584, November 2006.

04/18/23 17:58 41
IBM Cell 3.2 Ghz AX=b Performance

04/18/23 17:58 42
Plan
» My occupation at ICL» Software Engineering LAPACK» Single-double Iterative Refinement Routines for LAPACK
» Windows support for LAPACK/ScaLAPACK/ATLAS
» Multicore» PLASMA (Parallel Linear Algebra for Scalable Multi-core Architectures)
» Benchmarking of Neumann

04/18/23 17:58 43
Windows support – 100% MS Native
» ATLAS Automatically Tuned Linear Algebra Software (ATLAS) Portable BLAS
» LAPACK Linear Algebra PACKage
» ScaLAPACK Dense linear algebra package like LAPACK but for clusters
» SUA» Powershell» Microsoft Visual Studio

04/18/23 17:58 44
Plan
» My occupation at ICL» Software Engineering LAPACK» Single-double Iterative Refinement Routines for LAPACK
» Windows support for LAPACK/ScaLAPACK/ATLAS
» Multicore» PLASMA (Parallel Linear Algebra for Scalable Multi-core Architectures)
» Benchmarking of Neumann

04/18/23 17:58 45
Future Scaling without Innovation
Slide adapted from Rick Stevens, ANL
If we scale current peak performance numbers for various architectures and allowing system peak doubling every 18 months. Trouble ahead
Projected Year
BlueGene/LEarth
SimulatorCommodity Based
250 TF 2005 1.0 MWatt 100 MWatt 5 MWatt
1 PF 2008 2.5 MWatt 200 MWatt 15 MWatt
10 PF 2013 25 MWatt 2000 MWatt 150 MWatt
100 PF 2020 250 MWatt20,000 MWatt
1500 MWatt

04/18/23 17:58 46
Power is an Industry Wide Problem
“Hiding in Plain Sight, Google Seeks More Power”, by John Markoff, June 14, 2006
New Google Plant in The Dulles, Oregon, from NYT, June 14, 2006
» Google facilities» leveraging hydroelectric
power» old aluminum plants
» >500,000 servers worldwide

04/18/23 17:58 47
Free lunch is over
» Problem» physical barriers to further increases in clock speeds:
too much heat, too much power consumption, and too much leaking voltage
» heat dissipation» physical limits on the number of pins and bandwidth on a
single chip: gap between processor performance and memory performance, which was already bad, will get increasingly worse.
» the design trade-offs being made to address the previous two factors will render commodity processors, absent any further augmentation, inadequate for the purposes of tera- and petascale systems for advanced applications.
» Solution» reduce clock and increase execution units = Multicore
» Result» Non-parallel software won't run any faster. A new
approach to programming is required.» Programmers will not be able to consider these cores
independently (i.e., multi-core is not “the new SMP") because they share on-chip resources in ways that separate processors do not.

04/18/23 17:58 48
Power Cost of Frequency
» Power ∝ Voltage2 x Frequency (V2F)
» Frequency ∝ Voltage
» Power ∝Frequency3
04/18/23 17:58 49
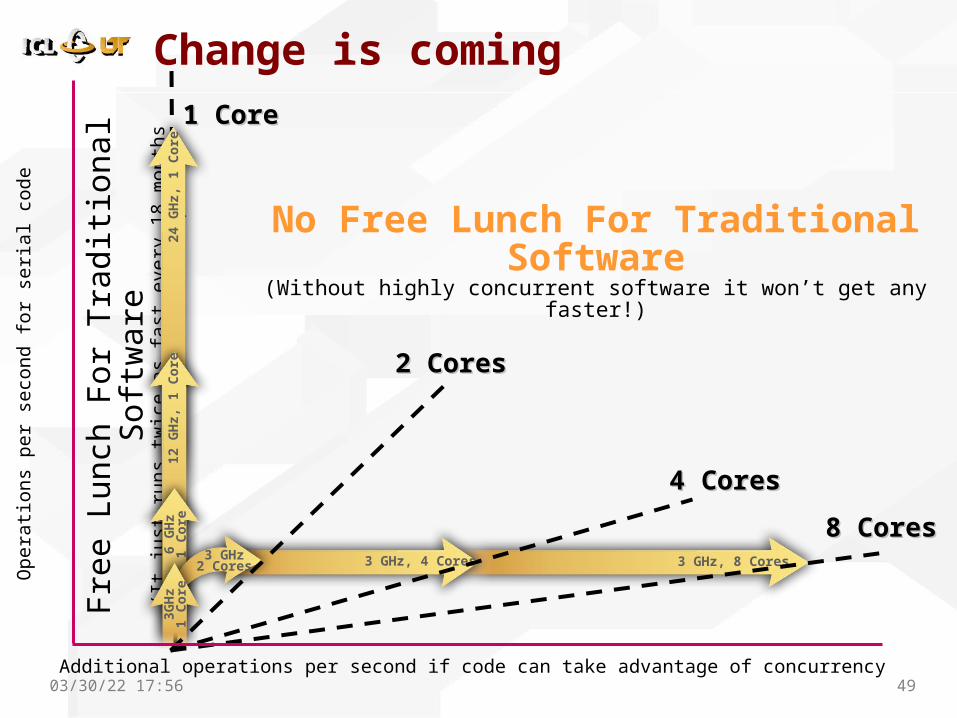
Change is coming
3 GHz, 8 Cores3 GHz, 4 Cores
2 Cores2 Cores
4 Cores4 Cores
8 Cores8 Cores
1 Core1 CoreFr
ee L
unch
For
Tra
dit
ion
al S
oft
ware
(It
just
run
s tw
ice a
s fa
st e
very
18 m
on
ths
wit
h n
o c
han
ge t
o t
he c
ode!)
Op
era
tions
per
seco
nd f
or
seri
al co
de
No Free Lunch For Traditional Software
(Without highly concurrent software it won’t get any faster!)
Additional operations per second if code can take advantage of concurrency
24 G
Hz,
1 C
ore
12 G
Hz,
1 C
ore
6 G
Hz
1 C
ore
3 GHz2 Cores
3G
Hz
1 C
ore

What is a Multicore processor, BTW?
» “a processor that combines two or more independent processors into a single package” (wikipedia) Single chip Multiple distinct processing engine Multiple, independent threads of control (or program counters MIMD)
» What about:» types of core?
» homogeneous (AMD Opteron, Intel Woodcrest...)» heterogeneous (STI Cell, Sun Niagara...)
» memory?» how is it arranged?
» bus?» is it going to be fast enough?
» cache?» shared? (Intel/AMD)» non present at all? (STI Cell)
» Communications?

04/18/23 17:58 51
2004 2005 2006 2007 2008 2009 2010 2011
Cores Per Processor Chip
0
100
200
300
400
500
600
Cores Per Processor Chip Hardware Threads Per Chip
CPU Desktop Trends 2004-2011
» Relative processing power will continue to double every 18 months» 5 years from now: 128 cores/chip w/512 logical processes per chip

04/18/23 17:58 52
Future Large Systems, Say in 5 Years
» 128 cores per socket
» 32 sockets per node
» 128 nodes per system
» System = 128*32*128 = 524,288 Cores!
» And by the way, its 4 threads of exec per core
» That’s about 2M threads to manage

04/18/23 17:58 53
Plan
» My occupation at ICL» Software Engineering LAPACK» Single-double Iterative Refinement Routines for LAPACK
» Windows support for LAPACK/ScaLAPACK/ATLAS
» Multicore» PLASMA (Parallel Linear Algebra for Scalable Multi-core Architectures)
» Benchmarking of Neumann

neumann.cs.ucsb.edu
» What is neumman?» Theoretical peak expected:» As for the peaks. For the Clovetown/woodcrest is easy. The SSE can do
2» fp per clock cycle plus there's one multiply and one add unit so, is» multiply and adds are well mixed you can do up to 4 ops per cycle. » The woodcrest peak is thus:
» ncores*clock*4 = 4*3.0*4 = 48
» for the Opteron is a bit more complex and I didn't really get it. Anyway
» at the end, there is a factor of two difference with intels (apart from
» the frequency). The opteron peak is thus:
» ncores*clock*2 = 16*2.2*2 = 70.4
» Goto GEMM peak
04/18/23 17:58 54

Perf DGEMM - AMD opteron 16 cores (8X2)
0
10
20
30
40
50
60
70
80
50010001500200025003000350040004500500055006000650070007500800085009000950010000
Dimension N
GFLOPS
ACML
GOTO
ATLAS
PDGEMM-p16-t1
PDGEMM-p8-t2
PEAK
Comparison of BLAS libraries
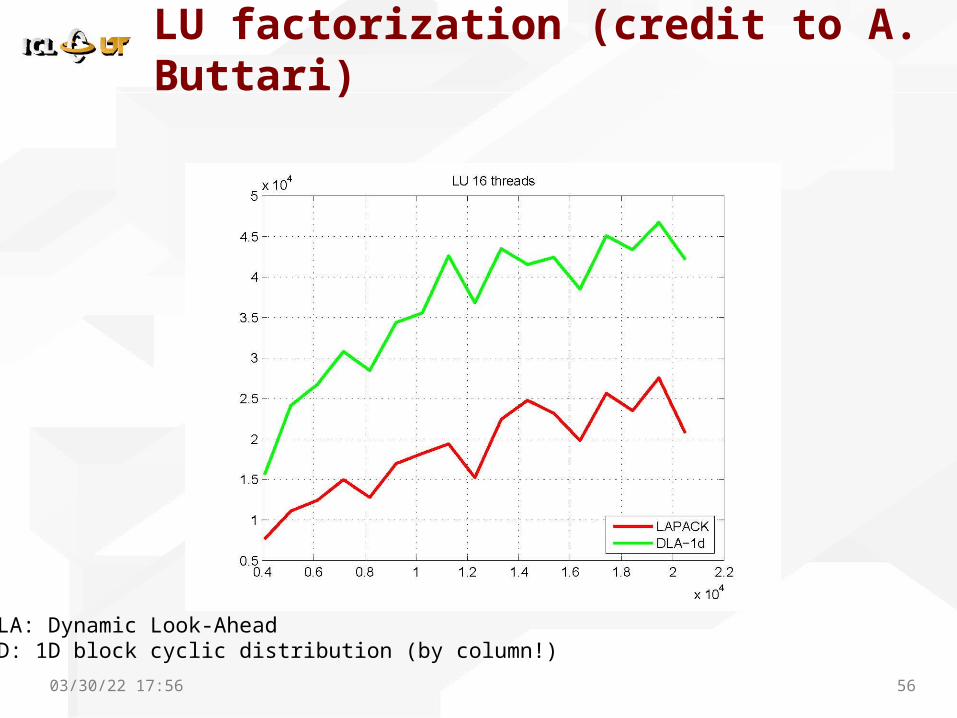
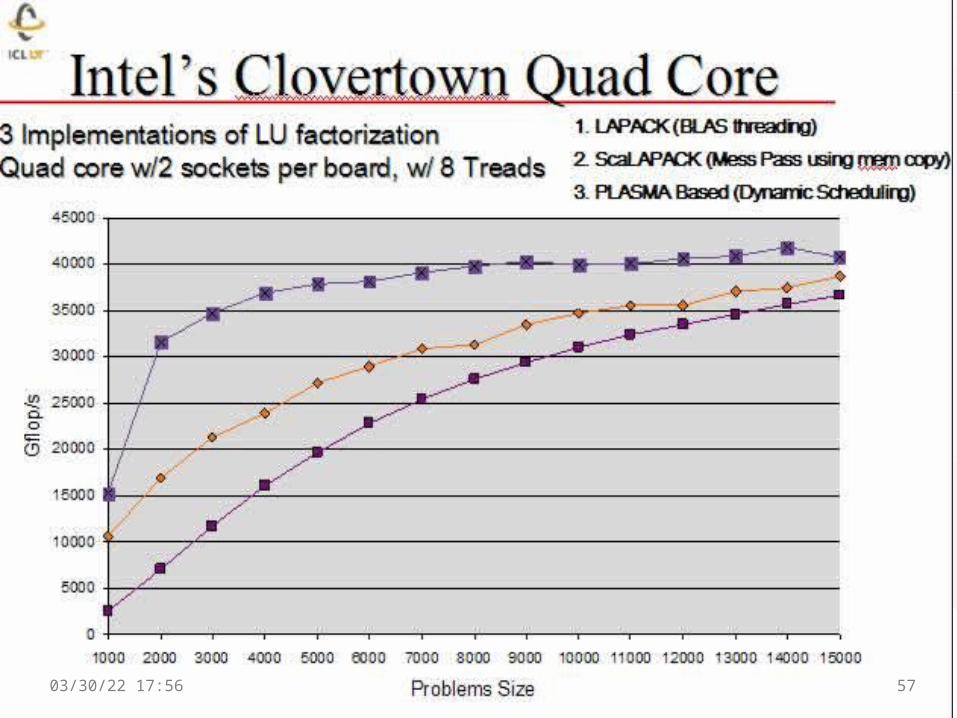
LU factorization (credit to A. Buttari)
04/18/23 17:58 56
DLA: Dynamic Look-Ahead1D: 1D block cyclic distribution (by column!)
7
04/18/23 17:58 57

Cholesky factorization (credit to A. Buttari)
04/18/23 17:58 58
DLA: Dynamic Look-Ahead1D: 1D block cyclic distribution (by column!)2D: 1D block cyclic distribution (2x8)
DLA: Dynamic Look-Ahead1D: 1D block cyclic distribution (by column!)2D: 1D block cyclic distribution (2x8)

Jim DemmelMark HoemmenJason ReidyLaura Grigori (INRIA - France)
All reduce algorithms(or Tall Skinny Algorithms if you are from Berkeley)


















