
Kristof Beyls, Erik D’Hollander, Frederik Vandeputte ICCS 2005 – May 23 RDVIS: A Tool That...
20
Kristof Beyls, Erik D’Hollander, Frederik Vandeputte ICCS 2005 – May 23 RDVIS: A Tool That Visualizes th Causes of Low Locality and Hints Program Optimizations
-
Upload
eloise-caryl -
Category
Documents
-
view
217 -
download
1
Transcript of Kristof Beyls, Erik D’Hollander, Frederik Vandeputte ICCS 2005 – May 23 RDVIS: A Tool That...

Kristof Beyls,Erik D’Hollander,
Frederik Vandeputte
ICCS 2005 – May 23
RDVIS: A Tool That Visualizes theCauses of Low Locality and Hints
Program Optimizations

Overview
1. Motivation: cache bottleneck
2. Some theoretical background: reuses
3. View 1: cache-missing reuses
4. View 2: reuse pair clusters corresponding to program optimizations
5. Experimental results
6. Implementation details
7. Conclusion

1. Motivation
• Many programs incur large cache bottlenecks.
• Mainly caused by poor locality (temporal or spatial)
• Temporal locality is hard to optimize automatically in a compiler
• Therefore: need to help programmer to pin-point sources of low temporal locality.

2. Theoretical background
• Stream of memory accesses:accesses:a b c a a breferences: r1 r1 r2 r1 r1 r1basic block: bb1 bb1 bb2 bb1 bb1 bb1
• Reuses / Reuse Distance• Reference pair / Reference pair histogram• Basic Block Vector of Intermediately
executed code.
20
2
Cache miss
reuse distance ≥ cache size

2. Theoretical background
• Stream of memory accesses:accesses:a b c a a breferences: r1 r1 r2 r1 r1 r1basic block: bb1 bb1 bb2 bb1 bb1 bb1
• Reuses / Reuse Distance• Reference pair / Reference pair histogram• Basic Block Vector of Intermediately
executed code.
Reference pair r1-r1
Reuse distance
1
2
10 2
20
2

3. RDVIS by example:matrix multiplication
Reuses between a[i*N+k] at distance 2^9 Reuses between b[k*N+j] at distance 2^17
How to bring reuses of b[k*N+j] closer together?
What separates reuses?
What code is executed between reuses?

3. RDVIS by example:matrix multiplication
Reuses occur betweeniterations of i-loop
Solution: bring iterationsof i-loop inwards
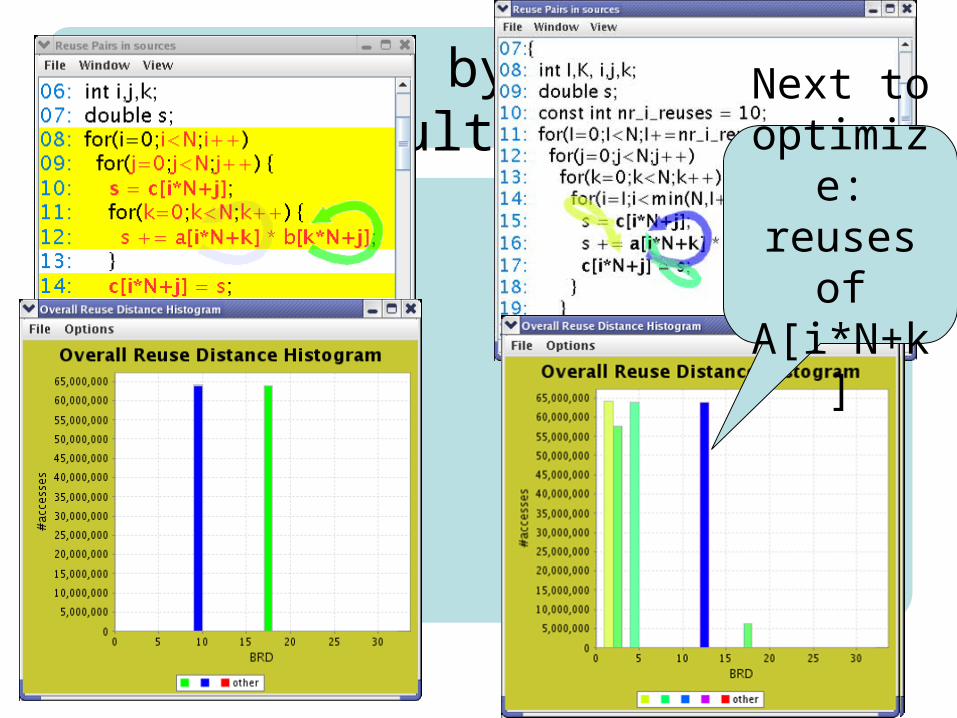
3. RDVIS by example:matrix multiplication
Next to optimize: reuses of A[i*N+k]

3. Matrix multiplication:final resultL1 cache
L2 cacheMain memory
Exec. Time on P4:
Orig: 0.740s
Opt.: 0.223s
Speedup: 3.3

4. Cluster Analysis
• In more complex programs, there can be many arrows.
• Many arrows can often by optimized by the same program transformation.
• Key idea: “When the same code is executed between use and reuse, probably the same program transformation is needed.”

4. Cluster Analysisby example: equake
Many different arrows
contribute to long-distance
reuse

2(bis). Theoretical background
• Stream of memory accesses:accesses:a b c a a breferences: r1 r1 r2 r1 r1 r1basic block: bb1 bb1 bb2 bb1 bb1 bb1
• Reuses / Reuse Distance• Reference pair / Reference pair histogram• Basic Block Vector of Intermediately
executed code of a reference pair.
BBV(Reference pair r1-r1)
.66.66% exec. betw. reuses
bb2bb1Basic block

4. Cluster Analysisby example: equake
LOOP FUSION!

5. Experimental Results
0123456789
101112
athlonXP Alpha Itanium average
Speedup
mcf
art
equake

6. Some Implementation Details
• Instrumentation added to GCC 4:– Exact source location info added to all abstract syntax
tree nodes.– Source location info is added in language-specific
front-end (currently only C, Fortran is being added).– Instrumentation occurs in language-independent
middle-end.• Inserts function call for each memory reference• Inserts function call at begin of each basic block• Writes out source location info for memory references and
basic blocks

7. Conclusion
• Visualization indicates reuses at a long distance, and the code that is executed between those reuses.
• Clustering of intermediately executed code leads to reference pairs that are optimizable with the same program transformation.
• Give RDVIS a try: http://www.elis.UGent.be/~kbeyls/rdvis

QUESTIONS?

MCF
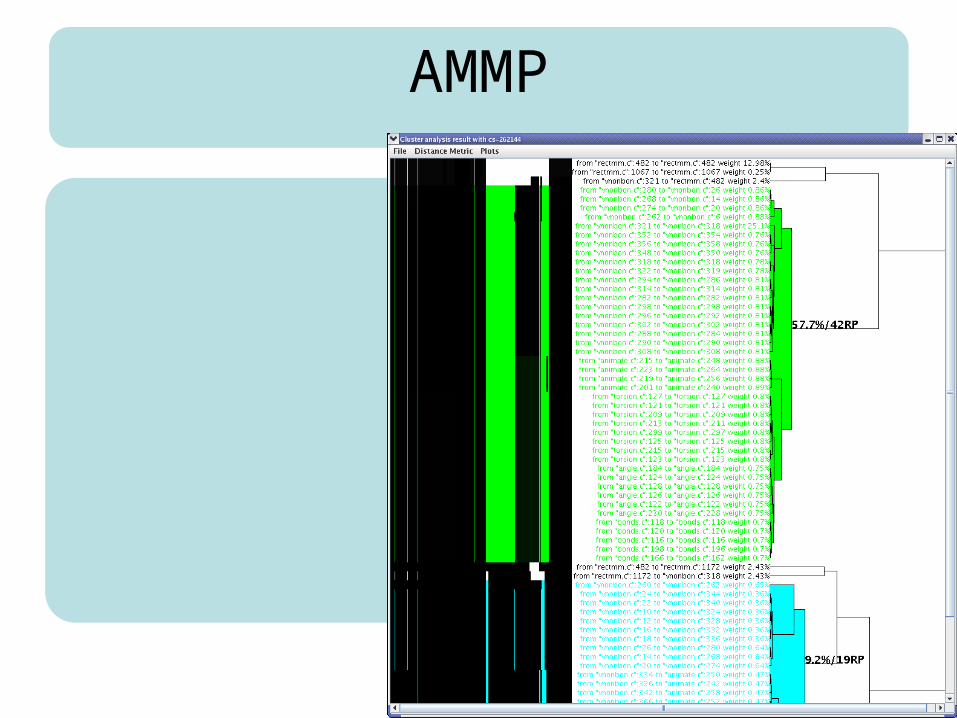
AMMP

AMMP


















