
Knowledge Mining and Big Data - TUTavisa/lec1.pdf · Knowledge Mining and Big Data Ari Visa 2015 ....
42
Knowledge Mining and Big Data Ari Visa 2015
Transcript of Knowledge Mining and Big Data - TUTavisa/lec1.pdf · Knowledge Mining and Big Data Ari Visa 2015 ....

Knowledge Mining and Big Data
Ari Visa 2015

Outline
• Definitions
• Backgrounds
• What is data mining?
• Data Mining: On what kind of data?
• Data mining functionality
• Are all the patterns interesting?
• Classification of data mining systems
• Major issues in data mining

Definitions
• Data: Facts and things certainly known. Data are any facts, numbers, or text that can be processed by a computer.
• Information: News and knowledge given. The patterns, associations, or relationships among all this data can provide information.
• Knowledge: Understanding, range of information, familiarity gained by experience. Information can be converted into knowledge about historical patterns and future trends.
• Experience: Process of gaining knowledge or skill by doing and seeing things

Definitions
• Big data include data sets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process the data within a tolerable elapsed time [1].
• Limits on the size of data sets are a constantly moving target, as of 2012 ranging from a few dozen terabytes to many petabytes of data in a single data set.
• Doug Laney defined data growth challenges and opportunities as being three-dimensional, i.e. increasing volume (amount of data), velocity (speed of data in and out), and variety (range of data types and sources).[Douglas, Laney. "3D Data Management: Controlling Data Volume, Velocity and Variety". Gartner. Retrieved 6 February 2001]

Definitions
• Databases <-> On-line processing
• Data mining:
– Extraction of interesting (non-trivial, implicit, previously unknown and potentially useful) information or patterns from data in large databases
– Organizations integrate their various databases into data warehouses. Data warehousing is defined as a process of centralized data management and retrieval (data capture, processing power, data transmission, and storage capabilities ).
• Knowledge mining (knowledge discovery in databases): – Extraction of interesting (previously unknown and potentially useful)
models from data in large databases

Definitions
• Data stream: A sequence of digitally encoded signals used to represent information in transmission [Federal Standard 1037C data stream].
• Data Stream Mining is the process of extracting knowledge structures from continuous, rapid data records.
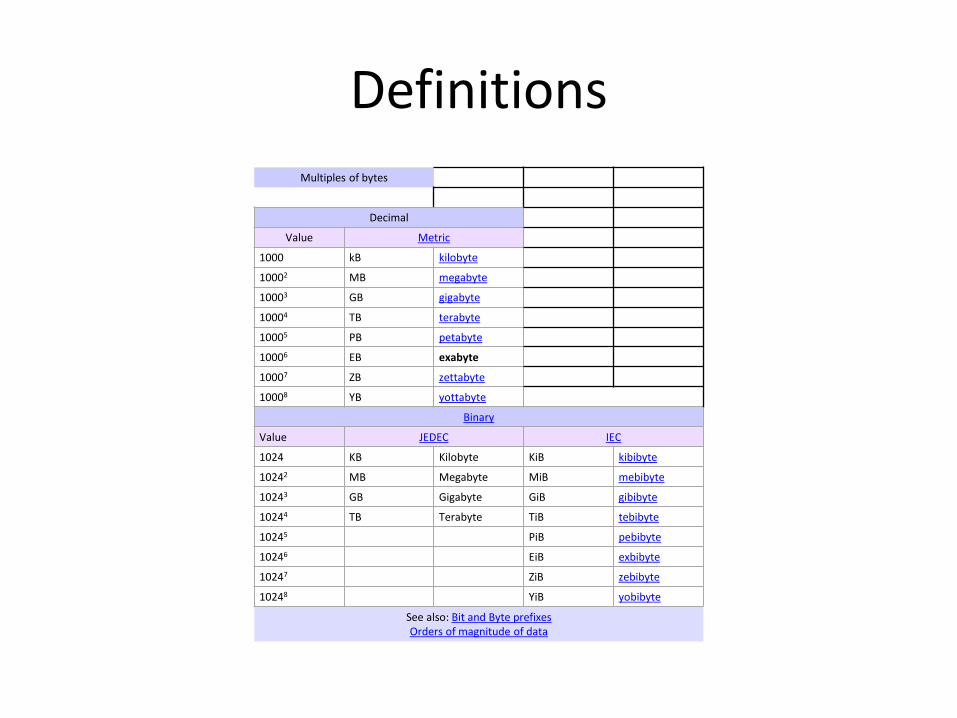
Definitions
Multiples of bytes
Decimal
Value Metric
1000 kB kilobyte
10002 MB megabyte
10003 GB gigabyte
10004 TB terabyte
10005 PB petabyte
10006 EB exabyte
10007 ZB zettabyte
10008 YB yottabyte
Binary
Value JEDEC IEC
1024 KB Kilobyte KiB kibibyte
10242 MB Megabyte MiB mebibyte
10243 GB Gigabyte GiB gibibyte
10244 TB Terabyte TiB tebibyte
10245 PiB pebibyte
10246 EiB exbibyte
10247 ZiB zebibyte
10248 YiB yobibyte
See also: Bit and Byte prefixes Orders of magnitude of data

Background
• Big data are difficult to work with using most relational database management systems and desktop statistics and visualization packages, requiring instead "massively parallel software running on tens, hundreds, or even thousands of servers“
• The trend to larger data sets is due to the additional information derivable from analysis of a single large set of related data, as compared to separate smaller sets with the same total amount of data, allowing correlations to be found to "spot business trends, determine quality of research, prevent diseases, link legal citations, combat crime, and determine real-time roadway traffic conditions."

Background- Evolution of Database Technology
• 1960s: Data collection, database creation, IMS and network DBMS
• 1970s: Relational data model, relational DBMS implementation
• 1980s: RDBMS, advanced data models (extended-relational, OO, deductive, etc.) and application-oriented DBMS (spatial, scientific, engineering, etc.)
• 1990s—2000s: Data mining and data warehousing, multimedia databases, and Web databases
• 2000s – 2020s: Cloud based distributed databases, HaDoop

Background
• Business Intelligence uses descriptive statistics with data with high information density to measure things, detect trends etc.;
• Big Data uses inductive statistics with data [4] with low information density whose huge volume allow to infer laws (regressions…) and thus giving (with the limits of inference reasoning) to Big Data some predictive capabilities

Background
• Big data requires exceptional technologies to efficiently process large quantities of data within tolerable elapsed times.
• Real or near-real time information delivery is one of the defining characteristics of big data analytics.

Background
• In 2000, Seisint Inc. develops C++ based distributed file sharing framework for data storage and querying. Structured, semi-structured and/or unstructured data is stored and distributed across multiple servers. Querying of data is done by modified C++ called ECL which uses apply scheme on read method to create structure of stored data during time of query.
• In 2004 LexisNexis acquired Seisint Inc. and 2008 acquired ChoicePoint, Inc. and their high speed parallel processing platform. The two platforms were merged into HPCC Systems and in 2011 was open sourced under Apache v2.0 License. Currently HPCC and Quantcast File System are the only publicly available platforms to exceed multiple exabytes of data.
• In 2004, Google published a paper on a process called MapReduce that used such an architecture. The MapReduce framework provides a parallel processing model and associated implementation to process huge amount of data. With MapReduce, queries are split and distributed across parallel nodes and processed in parallel (the Map step). The results are then gathered and delivered (the Reduce step). The framework was very successful,[51] so others wanted to replicate the algorithm. Therefore, an implementation of the MapReduce framework was adopted by an Apache open source project named Hadoop.
• MIKE2.0 is an open approach to information management that acknowledges the need for revisions due to big data implications in an article titled "Big Data Solution Offering".The methodology addresses handling big data in terms of useful permutations of data sources, complexity in interrelationships, and difficulty in deleting (or modifying) individual records.
• Recent studies show that the use of a multiple layer architecture is an option for dealing with big data. The Distributed Parallel architecture distributes data across multiple processing units and parallel processing units provide data much faster, by improving processing speeds. This type of architecture inserts data into a parallel DBMS, which implements the use of MapReduce and Hadoop frameworks. This type of framework looks to make the processing power transparent to the end user by using a front end application server.

Definitions
• The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
• Hadoop is a rapidly evolving ecosystem of components for implementing the Google MapReduce algorithms [3] in a scalable fashion on commodity hardware. Hadoop enables users to store and process large volumes of data and analyze it in ways not previously possible with less scalable solutions or standard SQL-based approaches.

Definitions
• Hadoop is a highly scalable compute and storage platform. While most users will not initially deploy servers numbered in the hundreds or thousands, Dell recommends following the design principles that drive large, hyper-scale deployments. This ensures that as you start with a small Hadoop environment, you can easily scale that environment without rework to existing servers, software, deployment strategies, and network connectivity [2].

Definitions
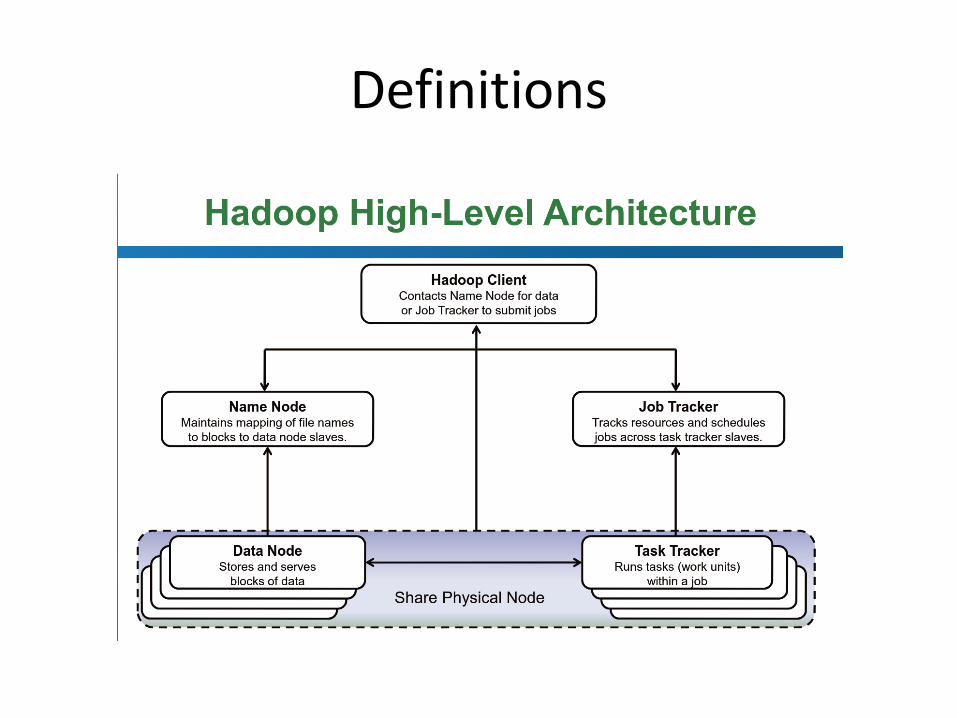
• NameNode -The NameNode is the central location for information about the file system deployed in a Hadoop environment. An environment can have one or two NameNodes, configured to provide minimal redundancy between the NameNodes. The NameNode is contacted by clients of the Hadoop Distributed File System (HDFS) to locate information within the file system and provide updates for data they have added, moved, manipulated, or deleted.
• DataNode – DataNodes make up the majority of the servers contained in a Hadoop environment. Common Hadoop environments will have more than one DataNode, and oftentimes they will number in the hundreds based on capacity and performance needs. The DataNode serves two functions: It contains a portion of the data in the HDFS and it acts as a compute platform for running jobs, some of which will utilize the local data within the HDFS.
• EdgeNode – The EdgeNode is the access point for the external applications, tools, and users that need to utilize the Hadoop environment. The EdgeNode sits between the Hadoop cluster and the corporate network to provide access control, policy enforcement, logging, and gateway services to the Hadoop environment. A typical Hadoop environment will have a minimum of one EdgeNode and more based on performance needs.

Definitions

Definitions
Definitions

Definitions
Definitions

Definitions
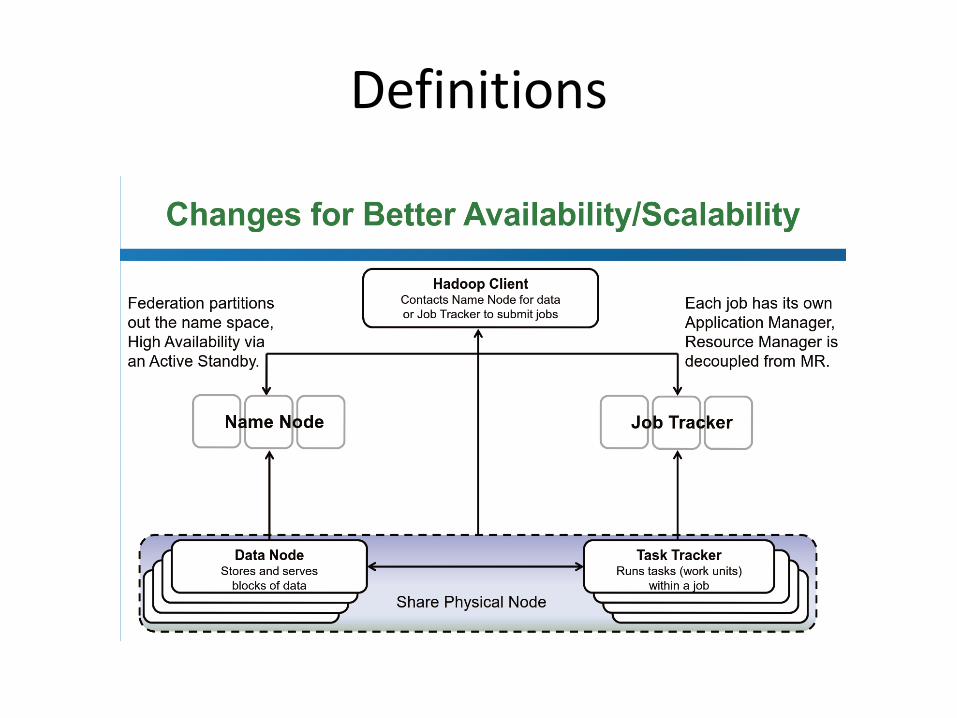
• A MapReduce program is composed of a Map() procedure that performs filtering and sorting and a Reduce() procedure that performs a summary operation.The "MapReduce System" orchestrates the processing by marshalling the distributed servers, running the various tasks in parallel, managing all communications and data transfers between the various parts of the system, and providing for redundancy and fault tolerance.
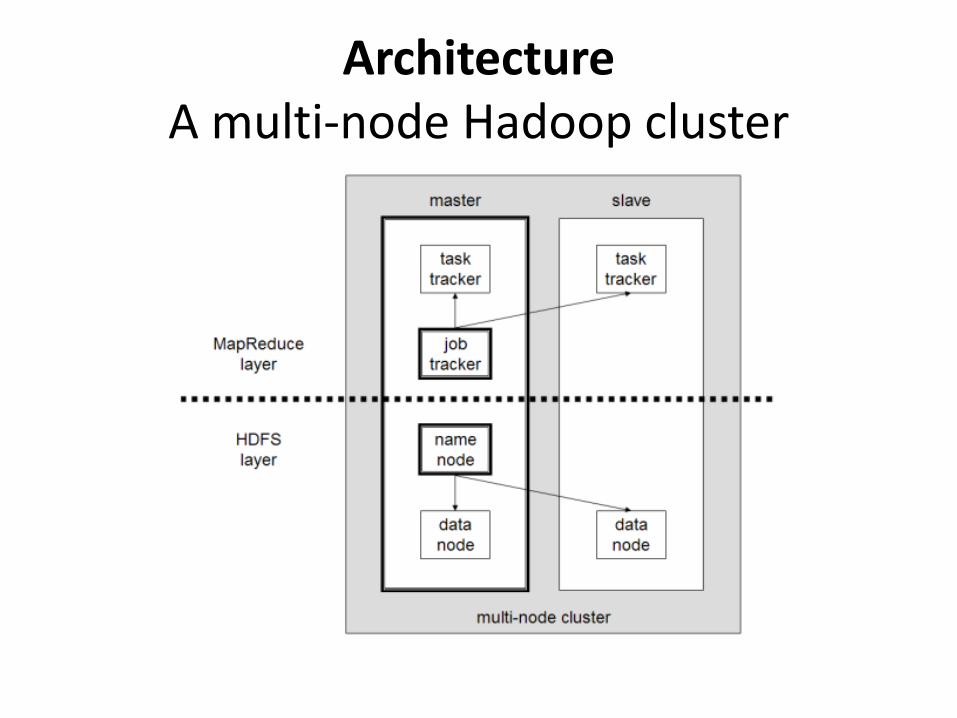
Architecture A multi-node Hadoop cluster

Technologies
• The challenges include capture, curation, storage, search, sharing, transfer, analysis, and visualization.
• Big data require exceptional technologies to efficiently process large quantities of data within tolerable elapsed times. A 2011 McKinsey report
suggests suitable technologies include A/B testing, association rule learning, classification, cluster analysis, crowdsourcing, data fusion and integration, ensemble learning, genetic algorithms, machine learning, natural language processing, neural networks, pattern recognition, anomaly detection, predictive modelling, regression, sentiment analysis, signal processing, supervised and unsupervised learning, simulation, time series analysis and visualisation. Multidimensional big data can also be represented as tensors, which can be more efficiently handled by tensor-based computation, such as multilinear subspace learning. Additional technologies being applied to big data include massively parallel-processing (MPP) databases, search-based applications, data-mining grids, distributed file systems, distributed databases, cloud based infrastructure (applications, storage and computing resources) and the Internet.

A Knowledge Discovery Process
– Data mining: the core of
knowledge discovery process.
Data Cleaning
Data Integration
Data Warehouse
Task-relevant Data
Selection
Data Mining
Pattern Evaluation

Steps of a KDD Process
• Learning the application domain: – relevant prior knowledge and goals of application
• Creating a target data set: data selection
• Data cleaning and preprocessing: (may take 60% of effort!)
• Data reduction and transformation: – Find useful features, dimensionality/variable reduction, invariant
representation.
• Choosing functions of data mining – summarization, classification, regression, association, clustering.
• Choosing the mining algorithm(s)
• Data mining: search for patterns of interest
• Pattern evaluation and knowledge presentation – visualization, transformation, removing redundant patterns, etc.
• Use of discovered knowledge
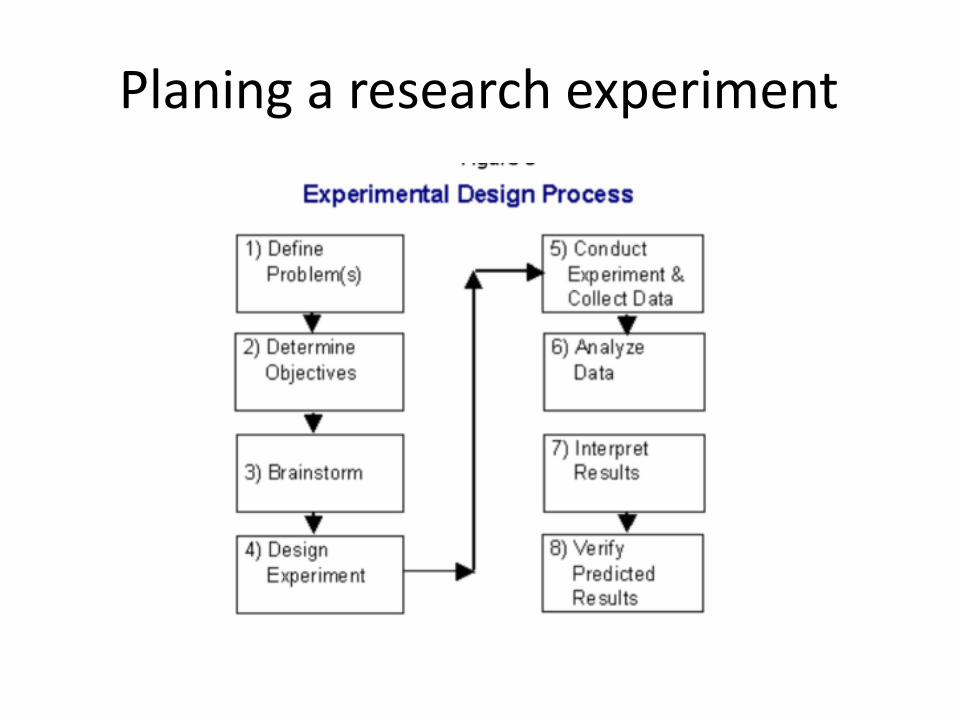
Planing a research experiment

Data Mining: On What Kind of Data?
• Relational databases • Data warehouses • Transactional databases • Advanced DB and information repositories
– Object-oriented and object-relational databases – Spatial databases – Time-series data and temporal data – Text databases and multimedia databases – Heterogeneous and legacy databases – WWW

Data Mining Functionalities (1)
• Concept description: Characterization and discrimination – Generalize, summarize, and contrast data
characteristics, e.g., dry vs. wet regions
• Association (correlation and causality) – Multi-dimensional vs. single-dimensional association
– age(X, “20..29”) ^ income(X, “20..29K”) buys(X, “PC”) [support = 2%, confidence = 60%]
– contains(T, “computer”) contains(x, “software”) [1%, 75%]

Association Analysis – An Example

Data Mining Functionalities (2)
• Classification and Prediction
– Finding models (functions) that describe and distinguish classes or concepts for future prediction
– E.g., classify countries based on climate, or classify cars based on gas mileage
– Presentation: decision-tree, classification rule, neural network
– Prediction: Predict some unknown or missing numerical values
• Cluster analysis – Class label is unknown: Group data to form new classes, e.g., cluster
houses to find distribution patterns
– Clustering based on the principle: maximizing the intra-class similarity and minimizing the interclass similarity


Data Mining Functionalities (3)
• Outlier analysis
– Outlier: a data object that does not comply with the general behavior of the
data
– It can be considered as noise or exception but is quite useful in fraud
detection, rare events analysis
• Trend and evolution analysis
– Trend and deviation: regression analysis
– Sequential pattern mining, periodicity analysis
– Similarity-based analysis
• Other pattern-directed or statistical analyses

Can We Find All and Only Interesting Patterns?
• Find all the interesting patterns: Completeness
– Can a data mining system find all the interesting patterns?
– Association vs. classification vs. clustering
• Search for only interesting patterns: Optimization
– Can a data mining system find only the interesting patterns?
– Approaches
• First general all the patterns and then filter out the uninteresting
ones.
• Generate only the interesting patterns—mining query optimization

Are All the “Discovered” Patterns Interesting?
• A data mining system/query may generate thousands of patterns, not all of
them are interesting.
– Suggested approach: Human-centered, query-based, focused mining
• Interestingness measures: A pattern is interesting if it is easily understood by
humans, valid on new or test data with some degree of certainty, potentially
useful, novel, or validates some hypothesis that a user seeks to confirm
• Objective vs. subjective interestingness measures:
– Objective: based on statistics and structures of patterns, e.g., support, confidence,
etc.
– Subjective: based on user’s belief in the data, e.g., unexpectedness, novelty,
actionability, etc.

A Multi-Dimensional View of Data Mining Classification
• Databases to be mined
– Relational, transactional, object-oriented, object-relational, active, spatial, time-series, text, multi-media, heterogeneous, legacy, WWW, etc.
• Knowledge to be mined
– Characterization, discrimination, association, classification, clustering, trend, deviation and outlier analysis, etc.
– Multiple/integrated functions and mining at multiple levels
• Techniques utilized
– Database-oriented, data warehouse (OLAP), machine learning, statistics, visualization, neural network, etc.
• Applications adapted – Retail, telecommunication, banking, fraud analysis, DNA mining, stock market
analysis, Web mining, Weblog analysis, etc.

A Multi-Dimensional View of Data Mining Classification
• Databases to be mined
– Relational, transactional, object-oriented, object-relational, active, spatial, time-series, text, multi-media, heterogeneous, legacy, WWW, etc.
• Knowledge to be mined
– Characterization, discrimination, association, classification, clustering, trend, deviation and outlier analysis, etc.
– Multiple/integrated functions and mining at multiple levels
• Techniques utilized
– Database-oriented, data warehouse (OLAP), machine learning, statistics, visualization, neural network, etc.
• Applications adapted – Retail, telecommunication, banking, fraud analysis, DNA mining, stock market
analysis, Web mining, Weblog analysis, etc.

Big Data: Confluence of Multiple Disciplines
Big Data Mining
Database Technology
Statistics
Other Disciplines
Information Science
Machine Learning
Visualization

Major Issues in Data Mining (1)
• Mining methodology and user interaction – Mining different kinds of knowledge in databases
– Interactive mining of knowledge at multiple levels of abstraction
– Incorporation of background knowledge
– Data mining query languages and ad-hoc data mining
– Expression and visualization of data mining results
– Handling noise and incomplete data
– Pattern evaluation: the interestingness problem
• Performance and scalability – Efficiency and scalability of data mining algorithms
– Parallel, distributed and incremental mining methods

Major Issues in Data Mining (2)
• Issues relating to the diversity of data types – Handling relational and complex types of data
– Mining information from heterogeneous databases and global information systems (WWW)
• Issues related to applications and social impacts – Application of discovered knowledge
• Domain-specific data mining tools
• Intelligent query answering
• Process control and decision making
– Integration of the discovered knowledge with existing knowledge: A knowledge fusion problem
– Protection of data security, integrity, and privacy

Summary
• Data mining: discovering interesting patterns from large amounts of data
• A natural evolution of database technology, in great demand, with wide applications
• A KDD process includes data cleaning, data integration, data selection, transformation, data mining, pattern evaluation, and knowledge presentation
• Mining can be performed in a variety of information repositories
• Data mining functionalities: characterization, discrimination, association, classification, clustering, outlier and trend analysis, etc.
• Classification of data mining systems
• Major issues in data mining

More Information
• [1] Activities in Finland: Digile (formerly known as TIVIT SHOK) http://www.digile.fi/frontpage
• [2]Google MapReduce: http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/en//archive/mapreduce-osdi04.pdf
• [3] Hadoop: http://i.dell.com/sites/content/business/solutions/whitepapers/en/Documents/hadoop-introduction.pdf
• [4] Big Data: http://ww2.lavastorm.com/The-Top-Challenges-of-Big-Data-and-Analytics-Google.html?gclid=CP7F2bCYmbkCFXJ6cAodoC0Apw

References
• U. M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy. Advances
in Knowledge Discovery and Data Mining. AAAI/MIT Press, 1996.
• J. Han and M. Kamber. Data Mining: Concepts and Techniques. Morgan
Kaufmann, 2000.
• T. Imielinski and H. Mannila. A database perspective on knowledge
discovery. Communications of ACM, 39:58-64, 1996.
• G. Piatetsky-Shapiro, U. Fayyad, and P. Smith. From data mining to
knowledge discovery: An overview. In U.M. Fayyad, et al. (eds.), Advances
in Knowledge Discovery and Data Mining, 1-35. AAAI/MIT Press, 1996.
• G. Piatetsky-Shapiro and W. J. Frawley. Knowledge Discovery in Databases.
AAAI/MIT Press, 1991.


















