
Knowledge Discovery in Databases - vse.czberka/docs/4iz451/sl01-kdd-en.pdfKnowledge Discovery in...
22
Knowledge Discovery in Databases T1: introduction P. Berka, 2019 1/22 Knowledge Discovery in Databases (Information Harvesting, Data Archeology, Data Mining, Knowledge Destilery, ....) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns from data (Fayyad a kol., 1996) Data mining involves the use of sophisticated data analysis tools to discover previously unknown, valid patterns and relationships in large data sets (Adriaans, Zantinge, 1999) Analysis of observational data sets to find unsuspected relationships and summarize data in novel ways that are both understandable and useful to the data owner (Hand, Manilla, Smyth, 2001) Data mining is the process of analyzing hidden patterns of data from different perspectives and categorizing them into useful information (techopedia.org, 2011) Three sources: databases (query languages, OLAP), statistics (data analysis), artificial intelligence (machine learning) Related concepts: data science, business intelligence
Transcript of Knowledge Discovery in Databases - vse.czberka/docs/4iz451/sl01-kdd-en.pdfKnowledge Discovery in...

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 1/22
Knowledge Discovery in Databases
(Information Harvesting, Data Archeology, Data
Mining, Knowledge Destilery, ....)
Non-trivial process of identifying valid, novel,
potentially useful and ultimately understandable
patterns from data (Fayyad a kol., 1996)
Data mining involves the use of sophisticated data
analysis tools to discover previously unknown, valid
patterns and relationships in large data sets
(Adriaans, Zantinge, 1999)
Analysis of observational data sets to find
unsuspected relationships and summarize data in
novel ways that are both understandable and useful
to the data owner (Hand, Manilla, Smyth, 2001)
Data mining is the process of analyzing hidden
patterns of data from different perspectives and
categorizing them into useful information
(techopedia.org, 2011)
Three sources: databases (query languages, OLAP),
statistics (data analysis), artificial intelligence
(machine learning)
Related concepts: data science, business intelligence

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 2/22
KDD Tasks
(Klosgen, Zytkow, 1997)
classification/prediction: the task is to
find knowledge applicable to automatically
process new examples
desription: the task is to find dominant
structure or relationships

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 3/22
search for „nuggets“: the task is to find
partial novel and surprising knowledge
(Chapman et al, 2000)
data description and summarization:
concise description of characteristics of
the data, typically in elementary and
aggregated form
segmentation: separation of the data into
interesting and meaningful subgroups or
classes
concept description: understandable
description of concepts or classes to gain
insight

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 4/22
classification: build classification models
(sometimes called classifiers) which assign
the correct class label to previously unseen
and unlabeled objects
prediction: similar to classification, but the
target attribute (class) is not a qualitative
discrete attribute but a continuous one.
Prediction also often deals with time
dependent concepts
dependency analysis: describe significant
dependencies (or associations) between data
items or events
deviation detection: focuses on discovering
the most significant changes in the data
from previously measured or normative
values

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 5/22
Application areas of KDD
Segmentation and classification (clients of a bank
or insurance company),
Credit Risk Assessment,
Fraud detection
Prediction of stock market prices,
Prediction of energy consumption,
Intrusion detection,
Churn Analysis (telco services providers, internet
providers),
Microarray data analysis (molecular biology),
Targeted marketing,
Medical diagnosis,
Market Basket Analysis.

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 6/22
Application areas (KDnuggets Poll)
CRM/Consumer analytics, 16.8%
Finance, 15.2%
Banking, 14.1%
Health care, 13.2%
Fraud Detection, 13.0%
https://www.kdnuggets.com/2018/04/poll-analytics-data-science-ml-applied-2017.html

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 7/22
Market basket analysis: data exploration

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 8/22
Market basket analysis: dependency analysis

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 9/22
Market basket analysis: classification
Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 10/22
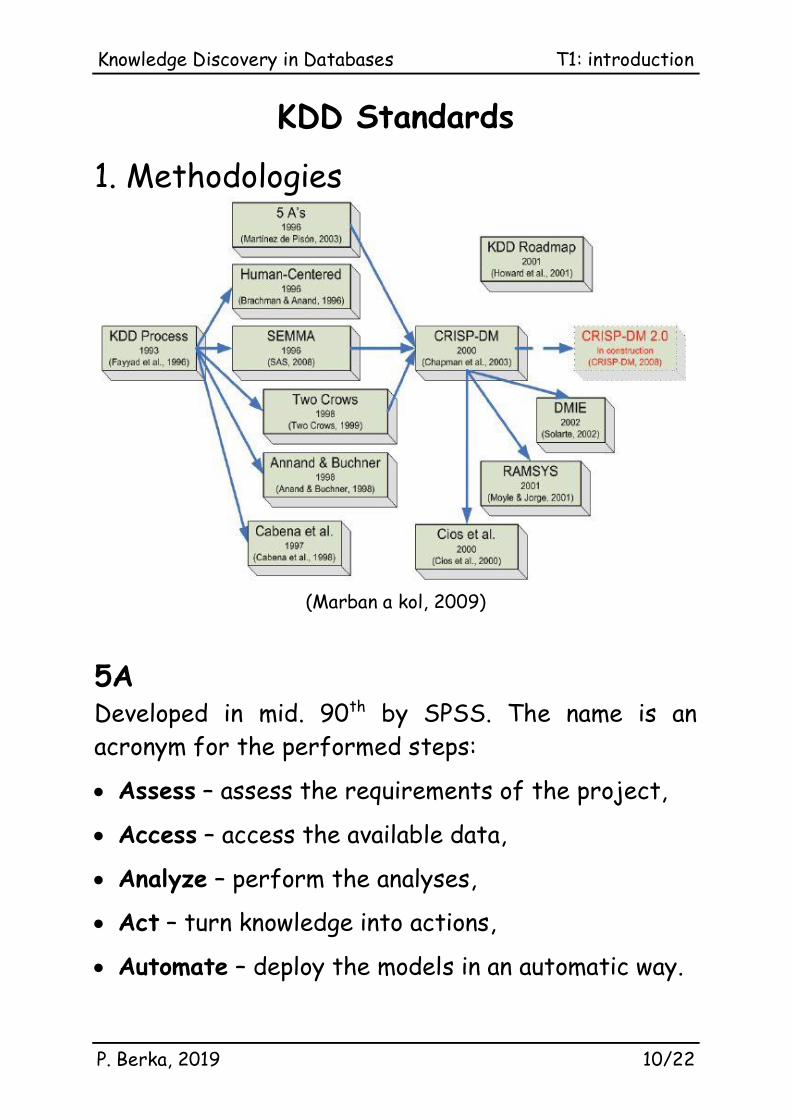
KDD Standards
1. Methodologies
(Marban a kol, 2009)
5A Developed in mid. 90th by SPSS. The name is an
acronym for the performed steps:
Assess – assess the requirements of the project,
Access – access the available data,
Analyze – perform the analyses,
Act – turn knowledge into actions,
Automate – deploy the models in an automatic way.

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 11/22
SEMMA Developed in mid. 90th by SAS:
Sample the data by creating one or more data
tables,
Explore the data by searching for relationships,
trends or anomalies,
Modify the data by creating, selecting, and
transforming the variables,
Model the relationships between input and output
variables by using various data mining techniques,
Assess the quality of the models.

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 12/22
CRISP-DM Currently a de-facto standard supported by most
data mining systems

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 13/22
2. Standards to describe models
Predictive Modeling Markup Language
Standard based on XML developed at Data Mining
Group (www.dmg.org), that allows to describe data,
data transformations and created models. Main parts
of a PMML document:
Header
Data Dictionary
Data Transformations
Model

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 14/22
<?xml version="1.0" ?>
<PMML version="4.0">
<Header copyright="P.B." description="An example decision tree model."/>
<DataDictionary numberOfFields="5" >
<DataField name="income" optype="categorical" />
<Value value="low"/>
<Value value="high"/>
<DataField name=account" optype= categorical " />
<Value value="low"/>
<Value value="medium"/>
<Value value="high"/>
<DataField name="sex" optype="categorical" >
<Value value="male"/>
<Value value="female"/>
</DataField>
<DataField name="unemployed" optype="categorical" >
<Value value="yes"/>
<Value value="no"/>
</DataField>
<DataField name=loan" optype="categorical" >
<Value value="A"/>
<Value value="n"/>
</DataField>
</DataDictionary>
<TreeModel modelName="loan aproval decision tree" >
<MiningSchema>
<MiningField name=“income"/>
<MiningField name="account"/>
<MiningField name="sex"/>
<MiningField name="unemployed"/>
<MiningField name="loan" usageType="predicted"/>
</MiningSchema>
<Node score="A">
<True/>
<Node score="A">
<SimplePredicate field="income" operator="equal" value="high"/>
</Node>
<Node score="n">
<SimplePredicate field="income" operator="equal" value="low"/>
<Node score="A">
<SimplePredicate field="account" operator="equal"
value="high"/>
</Node>
<Node score="n">
<SimplePredicate field="account" operator="equal"
value="low"/>
<Node score="n">
<SimplePredicate field="unemployed" operator="equal"
value="yes“/>
</Node>
<Node score="A">
<SimplePredicate field="unemployed" operator="equal"
value="no“/>
</Node>
</Node>
</Node>
</Node>
</TreeModel>
</PMML>

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 15/22
3. Programming standards (API)
SQL/MM Data Mining
Standard interface that enables to access data
mining algorithms from relational databases
OLE DB for Data Mining
API developed by Microsoft
Java Data Mining
CREATE MINING MODEL CreditRisk
(
CustomerId long key,
Income text discrete,
Account text discrete,
Sex text discrete,
Unemployed boolean discrete,
Loan text discrete predict,
)
USING [Microsoft Decision Tree]

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 16/22
Data Mining Systems
cover the whole KDD process (from data
preprocessing to model evaluation),
offer more data mining algorithms (than single-
purpose machine learning systems),
focus on visualization (both in the way how to
use the system and in the way how to present
and interpret data and results).
Types of systems:
Data mining suites - stand-alone tools that
implement a number of data mining and data
pre-processing algorithms (commercial or
free/open_source)
Programming tools -
Cloud solutions – Software As A Service
Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 17/22
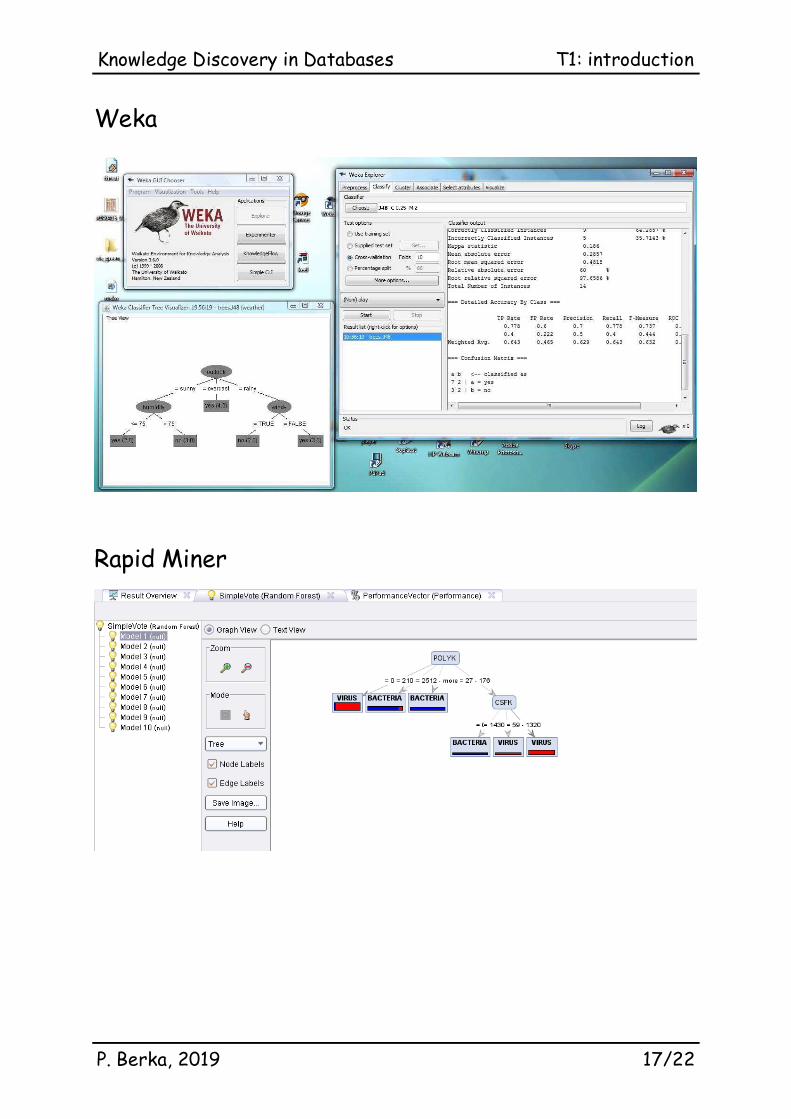
Weka
Rapid Miner

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 18/22
SAS Enterprise Miner
IBM SPSS Modeler (Clementine)

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 19/22
Gartner Magic Quadrant

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 20/22
KDnuggets Poll

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 21/22
KDD tools - usage 2017, 2018
https://www.kdnuggets.com/2018/05/poll-tools-analytics-data-science-machine-learning-results.html

Knowledge Discovery in Databases T1: introduction
P. Berka, 2019 22/22
KDD tools - current trends
1. Automatization of the whole KDD process to
make the analyzes available to non-expert
users
OptiML in BigML
RapidMiner: TurboPrep, Auto Model
Weka: Auto-Weka
Full automatization – Datarobot
2. Extending cloud platforms of key IT
companies Azure Machine Learning Studio,
Google Cloud Platform,
Machine Learning on AWS


















