
JOURNAL OF LA BURT: BERT-inspired Universal Representation ...
13
JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 BURT: BERT-inspired Universal Representation from Learning Meaningful Segment Yian Li, Hai Zhao Abstract—Although pre-trained contextualized language models such as BERT achieve significant performance on various downstream tasks, current language representation focuses on linguistic objective at a specific granularity. Thus this work introduces the universal representation learning, i.e., embeddings of different levels of linguistic unit in a uniform vector space. We present a universal representation model, BURT (BERT-inspired Universal Representation from learning meaningful segmenT), to encode different levels of linguistic unit into the same vector space. Specifically, we extract meaningful segments based on point-wise mutual information (PMI) to incorporate different granular objectives into the pre-training stage. We conduct experiments on datasets for English and Chinese including the GLUE and CLUE benchmarks, where our model surpasses its baselines and alternatives on a wide range of downstream tasks. We present our approach of constructing analogy datasets in terms of words, phrases and sentences and experiment with multiple representation models to examine geometric properties of the learned vector space through a task-independent evaluation. Finally, we verify the effectiveness of our method in two real-world text matching scenarios. As a result, our model significantly outperforms existing information retrieval (IR) methods and yields universal representations that can be directly applied to retrieval-based question-answering and natural language generation tasks. Index Terms—Artificial Intelligence, Natural Language Processing, Transformer, Language Representation. ✦ 1 I NTRODUCTION R EPRESENTATIONS learned by deep neural models have attracted a lot of attention in Natural Language Pro- cessing (NLP). However, previous language representation learning methods such as Word2Vec [1], LASER [2] and USE [3] focus on either words or sentences. Later proposed pre- trained contextualized language representations like ELMo [4], GPT [5], BERT [6] and XLNet [7] may seemingly handle different sized input sentences, but all of them focus on sentence-level specific representation still for each word, leading to unsatisfactory performance in real-world situa- tions. Although the latest BERT-wwm-ext [8], StructBERT [9] and SpanBERT [10] perform MLM on a higher linguistic level, the masked segments (whole words, trigrams, spans) either follow a pre-defined distribution or focus on a specific granularity. Besides, the random sampling strategy ignores important semantic and syntactic information of a sequence, resulting in a large number of meaningless segments. However, universal representation among different levels of linguistic units may offer a great convenience when it is needed to handle free text in language hierarchy in a • Y. Li, H. Zhao are with the Department of Computer Science and Engi- neering, Shanghai Jiao Tong University, and also with Key Laboratory of Shanghai Education Commission for Intelligent Interaction and Cognitive Engineering, Shanghai Jiao Tong University, and also with MoE Key Lab of Artificial Intelligence, AI Institute, Shanghai Jiao Tong University. E-mail: [email protected], [email protected]. • This paper was partially supported by National Key Research and Development Program of China (No. 2017YFB0304100), Key Projects of National Natural Science Foundation of China (U1836222 and 61733011), Huawei-SJTU long term AI project, Cutting-edge Machine Reading Comprehension and Language Model (Corresponding author: Hai Zhao). • This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible. unified way. As well known that, embedding representation for a certain linguistic unit (i.e., word) enables linguistics- meaningful arithmetic calculation among different vectors, also known as word analogy. For example, vector (“King”) - vector (“Man”) + vector (“Woman”) results in vector (“Queen”). Thus universal representation may generalize such good analogy features or meaningful arithmetic operation onto free text with all language levels involved together. For example, Eat an onion : Vegetable :: Eat a pear : Fruit. In fact, manipulating embeddings in the vector space reveals syntactic and semantic relations between the original se- quences and this feature is indeed useful in true applications. For example, “London is the capital of England.” can be formulized as v(capital)+ v(England) ≈ v(London). Then given two documents one of which contains “England” and “capital”, the other contains “London”, we consider these two documents relevant. In this paper, we explore the regularities of representa- tions including words, phrases and sentences in the same vector space. To this end, we introduce a universal analogy task derived from Google’s word analogy dataset. To solve such task, we present BURT, a pre-trained model that aims at learning universal representations for sequences of various lengths. Our model follows the architecture of BERT but differs from its original masking and training scheme. Specifically, we propose to efficiently extract and prune meaningful segments (n-grams) from unlabeled corpus with little human supervision, and then use them to modify the masking and training objective of BERT. The n-gram pruning algorithm is based on point-wise mutual information (PMI) and automatically captures different levels of language information, which is critical to improving the model capa- bility of handling multiple levels of linguistic objects in a unified way, i.e., embedding sequences of different lengths arXiv:2012.14320v2 [cs.CL] 31 Dec 2020
Transcript of JOURNAL OF LA BURT: BERT-inspired Universal Representation ...

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1
BURT: BERT-inspired Universal Representationfrom Learning Meaningful Segment
Yian Li, Hai Zhao
Abstract—Although pre-trained contextualized language models such as BERT achieve significant performance on various downstreamtasks, current language representation focuses on linguistic objective at a specific granularity. Thus this work introduces the universalrepresentation learning, i.e., embeddings of different levels of linguistic unit in a uniform vector space. We present a universal representationmodel, BURT (BERT-inspired Universal Representation from learning meaningful segmenT), to encode different levels of linguistic unitinto the same vector space. Specifically, we extract meaningful segments based on point-wise mutual information (PMI) to incorporatedifferent granular objectives into the pre-training stage. We conduct experiments on datasets for English and Chinese including the GLUEand CLUE benchmarks, where our model surpasses its baselines and alternatives on a wide range of downstream tasks. We present ourapproach of constructing analogy datasets in terms of words, phrases and sentences and experiment with multiple representation modelsto examine geometric properties of the learned vector space through a task-independent evaluation. Finally, we verify the effectiveness ofour method in two real-world text matching scenarios. As a result, our model significantly outperforms existing information retrieval (IR)methods and yields universal representations that can be directly applied to retrieval-based question-answering and natural languagegeneration tasks.
Index Terms—Artificial Intelligence, Natural Language Processing, Transformer, Language Representation.
F
1 INTRODUCTION
R EPRESENTATIONS learned by deep neural models haveattracted a lot of attention in Natural Language Pro-
cessing (NLP). However, previous language representationlearning methods such as Word2Vec [1], LASER [2] and USE[3] focus on either words or sentences. Later proposed pre-trained contextualized language representations like ELMo[4], GPT [5], BERT [6] and XLNet [7] may seemingly handledifferent sized input sentences, but all of them focus onsentence-level specific representation still for each word,leading to unsatisfactory performance in real-world situa-tions. Although the latest BERT-wwm-ext [8], StructBERT[9] and SpanBERT [10] perform MLM on a higher linguisticlevel, the masked segments (whole words, trigrams, spans)either follow a pre-defined distribution or focus on a specificgranularity. Besides, the random sampling strategy ignoresimportant semantic and syntactic information of a sequence,resulting in a large number of meaningless segments.
However, universal representation among different levelsof linguistic units may offer a great convenience when itis needed to handle free text in language hierarchy in a
• Y. Li, H. Zhao are with the Department of Computer Science and Engi-neering, Shanghai Jiao Tong University, and also with Key Laboratory ofShanghai Education Commission for Intelligent Interaction and CognitiveEngineering, Shanghai Jiao Tong University, and also with MoE Key Labof Artificial Intelligence, AI Institute, Shanghai Jiao Tong University.E-mail: [email protected], [email protected].
• This paper was partially supported by National Key Research andDevelopment Program of China (No. 2017YFB0304100), Key Projects ofNational Natural Science Foundation of China (U1836222 and 61733011),Huawei-SJTU long term AI project, Cutting-edge Machine ReadingComprehension and Language Model (Corresponding author: Hai Zhao).
• This work has been submitted to the IEEE for possible publication.Copyright may be transferred without notice, after which this versionmay no longer be accessible.
unified way. As well known that, embedding representationfor a certain linguistic unit (i.e., word) enables linguistics-meaningful arithmetic calculation among different vectors,also known as word analogy. For example, vector (“King”) -vector (“Man”) + vector (“Woman”) results in vector (“Queen”).Thus universal representation may generalize such goodanalogy features or meaningful arithmetic operation ontofree text with all language levels involved together. Forexample, Eat an onion : Vegetable :: Eat a pear : Fruit. Infact, manipulating embeddings in the vector space revealssyntactic and semantic relations between the original se-quences and this feature is indeed useful in true applications.For example, “London is the capital of England.” can beformulized as v(capital) + v(England) ≈ v(London). Thengiven two documents one of which contains “England” and“capital”, the other contains “London”, we consider thesetwo documents relevant.
In this paper, we explore the regularities of representa-tions including words, phrases and sentences in the samevector space. To this end, we introduce a universal analogytask derived from Google’s word analogy dataset. To solvesuch task, we present BURT, a pre-trained model thataims at learning universal representations for sequencesof various lengths. Our model follows the architecture ofBERT but differs from its original masking and trainingscheme. Specifically, we propose to efficiently extract andprune meaningful segments (n-grams) from unlabeled corpuswith little human supervision, and then use them to modifythe masking and training objective of BERT. The n-grampruning algorithm is based on point-wise mutual information(PMI) and automatically captures different levels of languageinformation, which is critical to improving the model capa-bility of handling multiple levels of linguistic objects in aunified way, i.e., embedding sequences of different lengths
arX
iv:2
012.
1432
0v2
[cs
.CL
] 3
1 D
ec 2
020

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 2
in the same vector space.Overall, our pre-trained models improves the perfor-
mance of baselines in both English and Chinese. In English,BURT-base reaches 0.7 percent gain on average over GoogleBERT-base. In Chinese, BURT-wwm-ext obtains 74.5% on theWSC test set, 13.4% point absolute improvement comparedwith BERT-wwm-ext and exceeds the baselines by 0.2% ∼0.6% point accuracy on five other CLUE tasks includingTNEWS, IFLYTEK, CSL, ChID and CMRC 2018. Extensiveexperimental results on our universal analogy task demon-strate that BURT is able to map sequences of variable lengthsinto a shared vector space where similar sequences areclose to each other. Meanwhile, addition and subtractionof embeddings reflect semantic and syntactic connectionsbetween sequences. Moreover, BURT can be easily applied toreal-world applications such as Frequently Asked Questions(FAQ) and Natural Language Generation (NLG) tasks, whereit encodes words, sentences and paragraphs into the sameembedding space and directly retrieves sequences that aresemantically similar to the given query based on cosinesimilarity. All of the above experimental results demonstratethat our well-trained model leads to universal representationthat can adapt to various tasks and applications.
2 BACKGROUND
2.1 Word and Sentence Embeddings
Representing words as real-valued dense vectors is a coretechnique of deep learning in NLP. Word embedding models[1], [11], [12] map words into a vector space where similarwords have similar latent representations. ELMo [4] attemptsto learn context-dependent word representations through atwo-layer bi-directional LSTM network. In recent years, moreand more researchers focus on learning sentence representa-tions. The Skip-Thought model [13] is designed to predict thesurrounding sentences for an given sentence. Logeswaranand Lee (2018) [14] improve the model structure by replacingthe RNN decoder with a classifier. InferSent [15] is trained onthe Stanford Natural Language Inference (SNLI) dataset [16]in a supervised manner. Subramanian et al. (2018) [17] andCer et al. (2018) [3] employ multi-task training and reportconsiderable improvements on downstream tasks. LASER [2]is a BiLSTM encoder designed to learn multilingual sentenceembeddings. Most recently, contextualized representationswith a language model training objective such as OpenAIGPT [5], BERT [6], XLNet [7] are expected to capture complexfeatures (syntax and semantics) for sequences of any length.Especially, BERT improves the pre-training and fine-tuningscenario, obtaining new state-of-the-art results on multiplesentence-level tasks. On the basis of BERT, further fine-tuningusing Siamese Network on NLI data can effectively producehigh quality sentence embeddings [?]. Nevertheless, most ofthe previous work concentrate on a specific granularity. Inthis work we extend the training goal to a unified level andenables the model to leverage different granular information,including, but not limited to, word, phrase or sentence.
2.2 Pre-Training Tasks
BERT is trained on a large amount of unlabeled dataincluding two training targets: Masked Language Model
(MLM) for modeling deep bidirectional representations,and Next Sentence Prediction (NSP) for understanding therelationship between two sentences. ALBERT [18] is trainedwith Sentence-Order Prediction (SOP) as a substitution ofNSP. StructBERT [9] has a sentence structural objectivethat combines the random sampling strategy of NSP andcontinuous sampling as in SOP. However, RoBERTa [19]and SpanBERT [10] use single contiguous sequences of 512tokens for pre-training and show that removing the NSPobjective improves the performance. Besides, BERT-wwm[8], StructBERT [10], SpanBERT [9] perform MLM on higherlinguistic levels, augmenting the MLM objective by maskingwhole words, trigrams or spans, respectively. Nevertheless,we concentrate on enhancing the masking and trainingprocedures from a broader and more general perspective.
2.3 Analysis and Applications
Previous explorations of vector regularities mainly studyword embeddings [1], [20]. After the introduction of sentenceencoders and Transformer models [22], more works weredone to investigate sentence-level embeddings. Usually theperformance in downstream tasks is considered to be themeasurement for model ability of representing sentences[3], [15], [23]. Some research proposes probing tasks tounderstand certain aspects of sentence embeddings [24],[25], [26]. Specifically, Rogers et al. (2020) [27] and Ma etal. (2019) [28] look into BERT embeddings and reveal itsinternal working mechanisms. Some work also explores theregularities in sentence embeddings [30], [31]. Nevertheless,little work analyzes words, phrases and sentences in thesame vector space. In this paper, We work on embeddingsfor sequences of various lengths obtained by different modelsin a task-independent manner.
Transformer-based representation models have madegreat progress in measuring query-Question or query-Answer similarities. Damani et al. (2020) [35] make ananalysis on Transformer models and propose a neuralarchitecture to solve the FAQ task. Sakata et al. (2019) [36]come up with an FAQ retrieval system that combines thecharacteristics of BERT and rule-based methods. In this work,we also evaluate the well-trained universal representationmodels on FAQ task.
3 METHODOLOGY
Our BURT follows the Transformer encoder [22] architecturewhere the input sequence is first split into subword tokensand a contextualized representation is learned for each token.We only perform MLM training on single sequences assuggested in [10]. The basic idea is to mask some of thetokens from the input and force the model to recover themfrom the context. Here we propose a unified masking methodand training objective considering different grained linguisticunits.
Specifically, we apply an pruning mechanism to collectmeaningful n-grams from the corpus and then perform n-gram masking and predicting. Our model differs from theoriginal BERT and other BERT-like models in several ways.First, instead of the token-level MLM of BERT, we incorporatedifferent levels of linguistic units into the training objective

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 3
Fig. 1. An illustration of n-gram pre-training.
Fig. 2. An example from the Chinese Wikipedia corpus. n-grams of different lengths are marked with dashed boxes in different colors in the upperpart of the figure. During training, we randomly mask n-grams and only the longest n-gram is masked if there are multiple matches, as shown in thelower part of the figure.
in a comprehensive manner. Second, unlike SpanBERT andStructBERT which sample random spans or trigrams, our n-gram sampling approach automatically discovers structureswithin any sequence and is not limited to any granularity.
3.1 N-gram Pruning
In this subsection, we introduce our approach of extracting alarge number of meaningful n-grams from the monolingualcorpus, which is a critical step of data processing.
First, we scan the corpus and extract all n-grams withlengths up to N using the SRILM toolkit1 [37]. In order tofilter out meaningless n-grams and prevent the vocabularyfrom being too large, we apply pruning by means of point-wise mutual information (PMI) [38]. To be specific, mutualinformation I(x, y) describes the association between tokensx and y by comparing the probability of observing x andy together with the probabilities of observing x and yindependently. Higher mutual information indicates strongerassociation between the two tokens.
I(x, y) = logP (x, y)
P (x)P (y)(1)
In practice, P (x) and P (y) denote the probabilities of x andy, respectively, and P (x, y) represents the joint probabilityof observing x followed by y. This alleviates bias towardshigh-frequency words and allows tokens that are rarely usedindividually but often appear together such as “San Francisco”to have higher scores. In our application, an n-gram denotedas w = (x1, . . . , xLw), where Lw is the number of tokens in
1. http://www.speech.sri.com/projects/srilm/download.html
w, may contains more than two words. Therefore, we presentan extended PMI formula displayed as below:
PMI(w) =1
Lw
(logP (w)−
Lw∑k=1
logP (xk)
)(2)
where the probabilities are estimated by counting the numberof observations of each token and n-gram in the corpus, andnormalizing by the size of the corpus. 1
Lwis an additional
normalization factor which avoids extremely low scores forlonger n-grams. Finally, n-grams with PMI scores below thechosen threshold are filtered out, resulting in a vocabularyof meaningful n-grams.
3.2 N-gram Masking
For a given input S = {x1, x2, . . . , xL}, where L is thenumber of tokens in S, special tokens [CLS] and [SEP] areadded at the beginning and end of the sequence, respectively.Before feeding the training data into the Transformer blocks,we identify all the n-grams in the sequence using theaforementioned n-gram vocabulary. An example is shown inFigure 2, where there are overlap between n-grams, whichindicates the multi-granular inner structure of the givensequence. In order to make better use of higher-level linguis-tic information, the longest n-gram is retained if multiplematches exist. Compared with other masking strategies, ourmethod has two advantages. First, n-gram extracting andmatching can be efficiently done in an unsupervised mannerwithout introducing random noise. Second, by utilizing n-grams of different lengths, we generalize the masking andtraining objective of BERT to a unified level where differentgranular linguistic units are integrated.

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 4
TABLE 1Statistics of datasets from GLUE and CLUE benchmarks. #Train, #Dev,#Test are the size of training, development and test sets, respectively. #L
is the number of labels. Sequences are simply divided into twocategories according to their length: “Long” and “Short”.
GLUE Length #Train #Dev #Test #L
CoLA Short 8.5k 1k 1k 2SST-2 Short 67k 872 1.8k 2MNLI Short-Short 393k 20k 20k 3QNLI Short-Short 105k 5.5k 5.5k 2RTE Short-Short 2.5k 277 3k 2MRPC Short-Short 3.7k 408 1.7k 2QQP Short-Short 364k 40k 391k 2STS-B Short-Short 5.8k 1.5k 1.4k -
CLUE Length #Train #Dev #Test #L
TNEWS Short 53k 10k 10k 15IFLYTEK Long 12k 2.6k 2.6k 119WSC Short 1.2k 304 290 2AFQMC Short-Short 34k 4.3k 3.9k 2CSL Long-Short 20k 3k 3k 2OCNLI Short-Short 50k 3k 3k 3CMRC18 Long 10k 1k 3.2k -ChID Long 85k 3.2k 3.2k -C3 Short 12k 3.8k 3.9k -
Following BERT, we mask 15% of all tokens in eachsequence. The data processing algorithm uniformly samplesone n-gram at a time until the maximum number of maskingtokens is reached. 80% of the time the we replace the entire n-gram with [MASK] tokens. 10% of the time it is replace withrandom tokens and 10% of the time we keep it unchanged.The original token-level masking is retained and consideredas a special case of n-gram masking where n = 1. We employdynamic masking as mentioned by Liu et al. (2019) [19],which means masking patterns for the same sequence indifferent epochs are probably different.
3.3 Traning ObjectiveAs depicted in Figure 1, the Transformer encoder generatesa fixed-length contextualized representation at each inputposition and the model only predicts the masked tokens.Ideally, a universal representation model is able to capturefeatures for multiple levels of linguistic units. Therefore,we extend the MLM training objective to a more generalsituation, where the model is trained to predict n-gramsrather than subwords.
maxθ
∑w
logP (w|x; θ) = maxθ
∑(i,j)
logP (xi, . . . , xj |x; θ) (3)
where w is a masked n-gram and x is a corrupted version ofthe input sequence. (i, j) represents the absolute start andend positions of w.
4 TASK SETUP
To evaluate the model ability of handling different linguisticunits, we apply our model on downstream tasks from GLUEand CLUE benchmark. Moreover, we construct a universalanalogy task based on Google’s word analogy dataset toexplore the regularity of universal representation. Finally, wepresent an insurance FAQ task and a retrieval-based languagegeneration task, where the key is to embed sequences of
different lengths in the same vector space and retrievesequences with similar meaning to the given query.
4.1 General Language UnderstandingStatistics of the GLUE and CLUE benchmarks are listed inTable 1. Besides the diversity of task types, we also findthat different datasets concentrates on sequences of differentlengths, which satisfies our need to examine the model abilityof representing multiple granular linguistic units.
4.1.1 GLUEThe General Language Understanding Evaluation (GLUE)benchmark [39] is a collection of tasks that is widely used toevaluate the performance of English language models. Wedivide eight NLU tasks from the GLUE benchmark into threemain categories.Single-Sentence Classification The Corpus of LinguisticAcceptability (CoLA) [40] is to determine whether a sentenceis grammatically acceptability or not. The Stanford SentimentTreebank (SST-2) [41] is a sentiment classification task thatrequires the model to predict whether the sentiment ofa sentence is positive or negative. In both datasets, eachexample is a sequence of words annotated with a label.Natural Language Inference Multi-Genre Natural LanguageInference (MNLI) [42], Stanford Question Answering Dataset(QNIL) [43] and Recognizing Textual Entailment (RTE) [?] arenatural language inference tasks, where a pair of sentencesare given and the model is trained to identify the relationshipbetween the two sentences from entailment, contradiction, andneutral.Semantic Similarity Semantic similarity tasks identifywhether the two sentences are equivalent or measure thedegree of semantic similarity of two sentences according totheir representations. Microsoft Paraphrase corpus (MRPC)[44] and Quora Question Pairs (QQP) dataset are paraphrasedatasets, where each example consists of two sentences and alabel of “1” indicating they are paraphrases or “0” otherwise.The goal of Semantic Textual Similarity benchmark (STS-B)[45] is to predict a continuous scores from 1 to 5 for each pairas the similarity of the two sentences.
4.1.2 CLUEThe Chinese General Language Understanding Evaluation(ChineseGLUE or CLUE) benchmark [46] is a Chinese versionof the GLUE benchmark for language understanding. We alsofind nine tasks from the CLUE benchmark can be classifiedinto three groups.Single Sentence Tasks We utilize three single-sentence classi-fication tasks including TouTiao Text Classification for NewsTitles (TNEWS), IFLYTEK [47] and the Chinese WinogradSchema Challenge (WSC) dataset. Examples from TNEWSand IFLYTEK are short and long sequences, respectively,and the goal is to predict the category that the given singlesequence belongs to. WSC is a coreference resolution taskwhere the model is required to decide whether two spansrefer to the same entity in the original sequence.Sentence Pair Tasks The Ant Financial Question MatchingCorpus (AFQMC), Chinese Scientific Literature (CSL) datasetand Original Chinese Natural Language Inference (OCNLI)[48] are three pairwise textual classification tasks. AFQMC

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 5
TABLE 2Examples from our word analogy dataset. The correct answers are in
bold.
A : B :: C Candidatesboy:girl::brother daughter, sister, wife, father, sonbad:worse::big bigger, larger, smaller, biggest, bet-
terBeijing:China::Paris France, Europe, Germany, Bel-
gium, LondonChile:Chilean::China Japanese, Chinese, Russian, Ko-
rean, Ukrainian
contains sentence pairs and binary labels, and the model isasked to examine whether two sentences are semanticallysimilar. Each example in CSL involves a text and severalkeywords. The model needs to determine whether these key-words are true labels of the text. OCNLI is a natural languageinference task following the same collection procedures ofMNLI.Machine Reading Comprehension Tasks CMRC 2018 [49],ChID [50], and C3 [51] are span-extraction based, clozestyle and free-form multiple-choice machine reading com-prehension datasets, respectively. Answers to the questionsin CMRC 2018 are spans extracted from the given passages.ChID is a collection of passages with blanks and correspond-ing candidates for the model to decide the most suitableoption. C3 is similar to RACE and DREAM, where the modelhas to choose the correct answer from several candidateoptions based on a text and a question.
4.2 Universal AnalogyAs a new task, universal representation has to be evaluated ina multiple-granular analogy dataset. The purpose of propos-ing a task-independent dataset is to avoid determining thequality of the learned vectors and interpret the model basedon a specific problem or situation. Since embeddings areessentially dense vectors, it is natural to apply mathematicaloperations on them. In this subsection, we introduce theprocedure of constructing different levels of analogy datasetsbased on Google’s word analogy dataset.
4.2.1 Word-level analogyRecall that in a word analogy task [1], two pairs of wordsthat share the same type of relationship, denoted as A : B ::C : D, are involved. The goal is to solve questions like “A isto B as C is to ?”, which is to retrieve the last word from thevocabulary given the first three words. The objective can beformulated as maximizing the cosine similarity between thetarget word embedding and the linear combination of thegiven vectors:
d∗ = argmaxd∗
cosine(c+ b− a, d)
cosine(u, v) =u · v‖u‖‖v‖
where a, b, c, d represent embeddings of the correspondingwords and are all normalized to unit lengths.
To facilitate comparison between models with differentvocabularies, we construct a closed-vocabulary analogy taskbased on Google’s word analogy dataset through negativesampling. Concretely, for each question, we use GloVe to
TABLE 3Statistics of our analogy datasets. #p and #q are the number of pairs and
questions for each category. #c is the number of candidates for eachdataset. #l (p/s) is the average sequence length in phrase/sentence-level
analogy datasets.
Dataset #p #q #c #l (p/s)
capital-common 23 506 5 6.0/12.0capital-world 116 4524 5 6.0/12.0city-state 67 2467 5 6.0/12.0male-female 23 506 5 4.1/10.1present-participle 33 1056 2 4.8/8.8positive-comparative 37 1322 2 3.4/6.1positive-negative 29 812 2 4.4/9.2
All 328 11193 - 5.4/10.7
rank every word in the vocabulary and the top 5 results areconsidered to be candidate words. If GloVe fails to retrievethe correct answer, we manually add it to make sure it isincluded in the candidates. During evaluation, the model isexpected to select the correct answer from 5 candidate words.Examples are listed in Table 2.
4.2.2 Phrase/Sentence-level analogy
To investigate the arithmetic properties of vectors for higherlevels of linguistic units, we present phrase and sentenceanalogy tasks based on the proposed word analogy dataset.We only consider a subset of the original analogy taskbecause we find that for some categories, such as “Australia”: “ Australian”, the same template phrase/sentence cannotbe applied on both words. Statistics are shown in Table 3.Semantic Semantic analogies can be divided into foursubsets: “capital-common”, “capital-world”, “city-state” and“male-female”. The first two sets can be merged into alarger dataset: “capital-country”, which contains pairs ofcountries and their capital cities; the third involves statesand their cities; the last one contains pairs with genderrelations. Considering GloVe’s poor performance on word-level “country-currency” questions (<32%), we discard thissubset in phrase and sentence-level analogies. Then weput words into contexts so that the resulting phrases andsentences also have linear relationships. For example, basedon relationship Athens : Greece :: Baghdad : Iraq, we selectphrases and sentences that contain the word “Athens” fromthe English Wikipedia Corpus2: “He was hired by the universityof Athens as being professor of physics.” and create examples:“hired by ... Athens” : “hired by ... Greece” :: “hired by ... Baghdad”: “hired by ... Iraq”. However, we found that such a questionis identical to word-level analogy for BOW methods likeaveraging GloVe vectors, because they treat embeddingsindependently despite the content and word order. To avoidlexical overlap between sequences, we replace certain wordsand phrases with their synonyms and paraphrases, e.g.,“hired by ... Athens” : “employed by ... Greece” :: “employedby ... Baghdad” : “hired by ... Iraq”. Usually sentences selectedfrom the corpus have a lot of redundant information. Toensure consistency, we manually modify some words duringthe construction of templates. However, this procedure willnot affect the relationship between sentences.
2. https://dumps.wikimedia.org/enwiki/latest

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 6
Query: Can 80-year-old people get accident insurance?
Q: Can I change the beneficiary?
A: Yes, the beneficiary can be modified.
Q: ������� ��Can seniors buy accident insurance?
A:�������� ���You can choose accident insurance for the elderly.
Q: How to make an online claim?
A: 8 0First, call the insurance company to report the case and apply for a claim. Second, ...
Fig. 3. Examples of Question-Answer pairs from our insurance FAQ dataset. The correct match to the query is highlighted.
TABLE 4Details of the templates.
Category Topics
Daily Scenarios Traveling, Recipe, Skin care, Beautymakeup, Pets
22
Sport & Health Outdoor sports, Athletics, Weight loss,Medical treatment
15
Reviews Movies, Music, Poetry, Books 16Persons Entrepreneurs, Historical/Public figures,
Writers, Directors, Actors17
General Festivals, Hot topics, TV shows 6Specialized Management, Marketing, Commerce,
Workplace skills17
Others Relationships, Technology, Education,Literature
14
All - 107
Syntactic We consider three typical syntactic analogies:Tense, Comparative and Negation, corresponding tothree subsets: “present-participle”, “positive-comparative”,“positive-negative”, where the model needs to distinguishthe correct answer from “past tense”, “superlative” and“positive”, respectively. For example, given phrases “Pigs arebright” : “Pigs are brighter than goats” :: “The train is slow”, themodel need to give higher similarity score to the sentencethat contains “slower” than the one that contains “slowest”.Similarly, we add synonyms and synonymous phrases foreach question to evaluate the model ability of learningcontext-aware embeddings rather than interpreting eachword in the question independently. For instance, “pleasant”≈ “not unpleasant” and “unpleasant” ≈ “not pleasant”.
4.3 Retrieval-based FAQThe sentence-level analogy discovers relationships betweensentences by directly manipulating sentence vectors. Espe-cially, we observe that sentences with similar meanings areclose to each other in the vector space, which we find isconsistent with the target of information retrieval task suchas Frequently Asked Question (FAQ). Such task is to retrieverelevant documents ( FAQs) given a user query, which can beaccurately done by only manipulating vectors representingthe sentences, such as calculating and ranking vector distancein terms of cosine similarity. Thus, we present an insuranceFAQ task in this subsection to explore the effectiveness ofBURT in real-world retrieval applications.
An FAQ task involves a collection of Question-Answer(QA) pairs denoted as {(Q1, A1), (Q2, A2), ...(QN , AN )},
where N is the number of QA pairs. The goal is to retrievethe most relevant QA pairs for a given query. We collectfrequently asked questions and answers between users andcustomer service from our partners in a Chinese onlinefinancial education institution. It contains over 4 typesof insurance questions, e.g., concept explanation (“what”),insurance consultation (“why”, “how”), judgement (“whether”)and recommendation. An example is shown in Figure 3. Ourdataset is composed of 300 QA pairs that are carefully se-lected to avoid similar questions so that each query has onlyone exact match. Because queries are mainly paraphrases ofthe standard questions, we use query-Question similarity asthe ranking score. The test set consists of 875 queries andthe average lengths of questions and queries are 14 and 16,respectively. The evaluation metric is Top-1 Accuracy (Acc.)and Mean Reciprocal Rank (MRR) because there is only onecorrect answer for each query.
4.4 Natural Language Generation
Moving from word and sentence vectors towards representa-tion for sequences of any lengths, a universal language modelmay have the ability of capturing semantics of free text andfacilitating various applications that are highly dependenton the quality of language representation. In this subsection,we introduce a retrieval-based Natural Language Generation(NLG) task. The task is to generate articles based on manuallycreated templates. Concretely, the goal is to retrieve oneparagraph at a time from the corpus which best describesa certain sentence from the template and then combine theretrieved paragraphs into a complete passage. The maindifficulty of this task lies in the need to compare semanticsof sentence-level queries (usually contain only a few words)and paragraph-level documents (often consist of multiplesentences).
We use articles collected by our partners in a mediacompany as our corpus. Each article is split into severalparagraphs and each document contains one paragraph. Thecorpus has a total of 656k documents and cover a wide rangeof domains, including news, stories and daily scenarios. Inaddition, we have a collection of manually created templatesin terms of 7 main categories, as shown in Table 4. Eachtemplate T = {s1, s2, . . . , sN} provides an outline of anarticle and contains up to N = 6 sentences. Each sentence sidescribes a particular aspect of the topic.
3. https://www.cluebenchmarks.com/rc.html4. https://gluebenchmark.com

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 7
TABLE 5CLUE test results scored by the evaluation server3. “acc” and “EM” denote accuracy and Exact Match, respectively.
Batch size: 8, 16; Length: 128, 256; Epoch: 2, 3, 5, 50; lr: 1e-5, 2e-5, 3e-5
ModelsSingle Sentence Sentence Pair MRC
Avg.TNEWS IFLYTEK WSC AFQMC CSL OCNLI CMRC18 ChID C3
(acc) (acc) (acc) (acc) (acc) (acc) (EM) (acc) (acc)
BERT 56.6 60.3 62.0 73.7 80.4 72.2 71.6 82.0 64.5 69.3MLM 56.5 60.2 70.7 73.3 79.3 70.6 69.1 81.3 64.8 69.5Span 56.7 59.6 72.1 73.5 79.7 71.0 71.6 82.2 65.3 70.2BURT 56.9 60.5 74.1 73.1 80.8 71.3 71.7 82.2 65.7 70.7
BERT-wwm-ext 56.8 59.4 61.1 74.1 80.6 73.4 74.0 82.9 68.5 70.1MLM 56.7 59.4 71.0 74.0 80.4 72.8 73.1 82.1 67.4 70.8Span 56.9 58.5 73.8 73.2 80.2 71.6 72.4 82.2 67.1 70.7BURT-wwm-ext 57.3 60.1 74.5 73.8 81.0 72.2 74.2 83.0 67.6 71.5
TABLE 6GLUE test results scored by the evaluation server4. We exclude the problematic WNLI set and recalculate the “Avg.” score. Results for BERT-base
and BERT-large are obtained from [6]. “mc” and “pc” are Matthews correlation coefficient [52] and Pearson correlation coefficient, respectively.
Batch size: 8, 16, 32, 64; Length: 128; Epoch: 3; lr: 3e-5
ModelsSingle Sentence NLI Semantic Similarity
Avg.CoLA SST-2 MNLI QNLI RTE MRPC QQP STS-B(mc) (acc) m/mm(acc) (acc) (acc) (F1) (F1) (pc)
BERT-base 52.1 93.5 84.6/83.4 90.5 66.4 88.9 71.2 87.1 79.7MLM 51.9 93.5 84.5/83.9 90.7 65.0 88.1 71.6 86.2 79.5Span 53.3 93.8 84.5/84.0 90.9 66.6 88.0 71.6 86.1 79.9BURT-base 55.7 94.5 84.7/84.1 91.1 67.1 88.2 71.6 86.4 80.4
BERT-large 60.5 94.9 86.7/85.9 92.7 70.1 89.3 72.1 87.6 82.2MLM 61.1 94.5 86.6/85.6 92.5 69.2 90.2 72.3 87.0 82.1Span 60.1 94.8 86.5/85.9 92.6 69.4 89.3 72.3 87.3 82.0BURT-large 62.6 94.7 86.8/86.0 92.7 70.8 89.7 72.3 87.3 82.5
The problem is solved in two steps. First, an index forall the documents is built using BM25. For each query, itwill return a set of candidate documents that are related tothe topic. Second, we use representation models to re-rankthe top 100 candidates: each query-document pair (q,d) ismapped to a score f(q,d), where the scoring function f isbased on cosine similarity. Quality of the generated passageswas assessed by two native Chinese speakers, who wereasked to examine whether the retrieved paragraphs were“relevant” to the topic and “conveyed the meaning” of thegiven sentence.
5 IMPLEMENTATION
5.1 Data Processing
We download the English and Chinese Wikipedia Corpus5
and pre-process with process_wiki.py6, which extractstext from xml files. Then for the Chinese corpus, we convertthe data into simplified characters using OpenCC. In orderto extract high-quality n-grams, we remove punctuationmarks and characters in other languages based on regularexpressions, and finally get an English corpus of 2,266Mwords and a Chinese corpus of 380M characters.
We calculate PMI scores of all n-grams with a maximumlength of N = 10 for each document instead of the entire
5. https://dumps.wikimedia.org6. https://github.com/panyang/Wikipedia Word2vec/blob/master
/v1/process wiki.py
corpus considering that different documents usually describedifferent topics. We manually evaluate the extracted n-gramsand find nearly 50% of the top 2000 n-grams contain 3∼ 4 words (characters for Chinese), and only less than0.5% n-grams are longer than 7. Although a larger n-gramvocabulary can cover longer n-grams, it will cause toomany meaningless n-grams. Therefore, for both English andChinese corpus, we empirically retain the top 3000 n-gramsfor each document, resulting in vocabularies of n-gramswith average lengths of 4.6 and 4.5, respectively. Finally, forEnglish, we randomly sample 10M sentences rather than usethe entire corpus to reduce training time.
5.2 Pre-training
As in BERT, sentence pairs are packed into a single sequenceand the special [CLS] token is used for sentence-levelpredicting. While in accordance with Joshi et al. (2020) [10],we find that single sentence training is better than the originalsentence pair scenario. Thus in our experiments, the input isa continuous sequence with a maximum length of 512.
Instead of training from scratch, we initialize both Englishand Chinese models with the officially released check-points (bert-base-uncased, bert-large-uncased,bert-base-chinse) and BERT-wwm-ext, which is trainedfrom the Chinese BERT using whole word masking onextended data [8]. Base models are comprised of 12 Trans-former layers, 12 heads, 768 dimensional hidden states and110M parameters in total. The English BERT-large has 24

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 8
TABLE 7Questions and candidates from the sentence-level “positive-negative” analogy dataset and similarity scores for each candidate sentence computed
by GloVe, USE and BURT-base. The correct sentences are in bold.
Barton’s inquiry was reasonable : Barton’s inquiry was not reasonable :: Changing the sign of numbers is an efficient algorithmchanging the sign of numbers is an inefficient algorithm GloVe: 0.96 USE: 0.89 BURT-base: 0.97
changing the sign of numbers is not an inefficient algorithm GloVe: 0.97 USE: 0.90 BURT-base: 0.96
Members are aware of their political work : Members are not aware of their political work :: This ant is a known speciesThis ant is an unknown species GloVe:0.94 USE:0.87 BURT-base: 0.96
This ant is not an unknown species GloVe: 0.95 USE:0.82 BURT-base: 0.95
TABLE 8Performance of different models on universal analogy datasets. Mean-pooling is applied to Transformer-based models to obtain fixed-length
embeddings. The last column shows the average accuracy of word, phrase and sentence analogy tasks.
Models Word Phrase Sentence Avg.semantic syntactic Avg. semantic syntactic Avg. semantic syntactic Avg.
GloVe [11] 82.6 78.0 80.3 0.0 40.9 20.5 0.2 39.8 20.0 40.3InferSent [15] 68.8 88.7 78.8 0.0 54.1 27.0 0.0 50.8 25.4 43.7GenSen [17] 44.5 84.4 64.5 0.0 54.4 27.2 0.0 44.9 22.4 38.0USE [3] 73.0 83.1 78.0 1.8 63.1 32.5 0.6 44.1 22.4 44.3LASER [2] 26.9 78.2 52.6 0.0 63.3 31.7 1.6 55.4 28.5 37.6ALBERT-base [18] 32.2 43.1 37.7 0.0 56.4 28.2 0.0 59.2 29.6 31.8ALBERT-xxlarge 32.1 37.5 34.8 0.9 50.5 25.7 0.3 50.3 25.3 28.6RoBERTa-base [19] 28.6 50.5 39.5 0.0 46.1 23.0 0.1 63.6 31.8 31.5RoBERTa-large 34.2 55.9 45.0 0.2 50.6 25.4 0.9 50.9 25.9 32.1XLNet-base [7] 23.2 49.1 36.1 1.9 65.6 33.8 0.8 63.5 32.2 34.0XLNet-large 23.4 42.0 32.7 4.7 53.5 29.1 5.6 48.4 27.0 29.6
BERT-base [6] 51.3 60.2 55.8 0.3 69.3 34.8 0.1 68.3 34.2 41.6MLM 62.9 61.1 62.0 2.7 59.8 31.3 0.2 61.8 31.0 41.4Span 63.5 58.9 61.2 1.9 68.9 35.4 0.1 63.1 31.6 42.7BURT-base 71.1 74.4 72.8 1.7 69.1 35.4 0.6 63.4 32.0 46.7
BERT-large 49.7 46.6 48.2 0.1 67.4 33.9 0.5 61.2 30.9 37.7MLM 65.0 50.7 57.9 1.0 63.4 32.2 0.5 56.7 28.6 39.6Span 66.5 54.1 60.3 2.7 64.2 33.5 0.7 58.4 29.6 40.5BURT-large 84.7 74.0 79.4 4.9 58.6 31.8 1.0 52.4 26.7 46.0
SBERT-base [?] 71.2 73.7 72.4 41.8 63.6 52.7 23.2 58.7 40.9 55.3SBURT-base 82.8 77.5 80.2 33.2 70.5 51.9 30.8 69.1 50.0 60.7SBERT-large 72.5 74.2 73.3 57.8 55.0 56.4 18.4 52.4 35.4 55.0SBURT-large 84.4 76.6 80.5 34.7 50.1 42.4 5.7 53.1 29.4 50.8
Transformer layers, 16 heads, 1024 dimensional hidden statesand 340M parameters in total. We use Adam optimizer [53]with initial learning rate of 5e-5 and linear warmup over thefirst 10% of the training steps. Batch size is set to 16 anddropout rate is 0.1. Each model is trained for one epoch.
5.3 Fine-tuning
Following BERT, in the fine-tuning procedure, pairs ofsentences are concatenated into a single sequence with aspecial token [SEP] in between. For both single sentenceand sentence pair tasks, the hidden state of the first token[CLS] is used for softmax classification. We use the samesets of hyperparameters for all the evaluated models. Allexperiments on the GLUE benchmark are ran with a totaltrain batch sizes between 8 and 64 and learning rates of 3e-5for 3 epochs. For tasks from the CLUE benchmark, we setbatch sizes to 8 and 16, learning rates between 1e-5 and 3e-5,and train 50 epochs on WSC and 2∼5 epochs on the resttasks.
5.4 Downstream-task Models
On GLUE and CLUE, we compare our model with threevariants: pre-trained models (Chinese BERT/BERT-wwm-ext, English BERT-base/BERT-large), models trained withthe same number of additional steps as our model (MLM),and models trained using random span masking with thesame number of additional steps as our model (Span). Forthe Span model, we simply replace our n-gram modulewith the masking strategy as proposed by [10], where thesampling probability of span length l is based on a geometricdistribution l ∼ Geo(p). We follow the parameter settingthat p = 0.2 and maximum span length lmax = 10.
We also evaluate the aforementioned models on ouruniversal analogy task. Baseline models include Bag-of-words (BoW) model from pre-trained word embeddings:GloVe, sentence embedding models: InferSent, GenSen, USEand LASER, pre-trained contextualized language models:BERT, ALBERT, RoBERTa and XLNet. To derive semanticallymeaningful embeddings, we fine-tune BERT and our modelon the Stanford Natural Language Inference (SNLI) [16] andthe Multi-Genre NLI Corpus [?] using a Siamese structurefollowing Reimers and Gurevych (2019) [?].

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 9
TABLE 9Examples of the retrieved paragraphs and corresponding comments from the judges. “B”-BM25, “L”-LASER, “S”-Span, “U”-BURT.
Query: 端午节的由来 (The Origin of the Dragon Boat Festival)
B: 一个中学的高级教师陈老师生动地解读端午节的由来,诵读爱好者进行原创诗歌作品朗诵,深深打动了在场的观众...(Mr. Chen, senior teacher at a middle School, vividly introduced the origin of the Dragon Boat Festival and people are recitingoriginal poems, which deeply moved the audience...)
L:今天是端午小长假第一天...当天上午,在车厢内满目挂有与端午节相关的民俗故事及有关诗词的文字... (Today is the firstday of the Dragon Boat Festival holiday...There are folk stories and poems posted in the carriage...)
S,U : ...端午节又称端阳节、龙舟节、浴兰节,是中华民族的传统节日。端午节形成于先秦,发展于汉末魏晋,兴盛于唐...(...Dragon Boat Festival, also known as Duanyang Festival, Longzhou Festival and Yulan Festival is a traditional festival of theChinese nation. It is formed in the Pre-Qin Dynasty, developed in the late Han and Wei-Jin, and prospered in the Tang...)
Comments: B and L is related to the topic but does not convey the meaning of the query.
Query: 狗的喂养知识 (Dog Feeding Tips)
B: ...创建一个“比特狗”账户,并支付99元领养一只“比特狗”。然后购买喂养套餐喂养“比特狗”,“比特狗”就能通过每天挖矿产生BTGS虚拟货币。 (...First create a “Bitdog” account and pay 99 yuan to adopt a “Bitdog”. Then buy a package tofeed the “Bitdog”, which can generate virtual currency BTGS through daily mining.)
L: 要养成定时定量喂食的好习惯,帮助狗狗更好的消化和吸收,同时也要选择些低盐健康的狗粮... (It is necessary to feedyour dog regularly and quantitatively to help them digest and absorb better. Meanwhile, choose some low-salt and healthy food...)
S:泰迪犬容易褪色是受到基因和护理不当的影响,其次是饮食太咸...一定要注意正确护理,定期洗澡,要给泰迪低盐营养的优质狗粮... (Teddy bear dog’s hair is easy to fade because of its genes and improper care. It is also caused by salty diet... So wemust take good care of them, such as taking a bath regularly, and preparing dog food with low salt...)
U : 还可以一周自制一次狗粮给狗狗喂食,就是买些肉类,蔬菜,自己动手做。偶尔吃吃自制狗粮也能增加狗狗的营养,和丰富狗狗的口味。日常的话,建议选择些适口性强的狗粮,有助磨牙,防止口腔疾病。 (You can also make dog food oncea week, such as meats and vegetables. Occasionally eating homemade dog food can also supplement nutrition and enrich the taste. Indaily life, it is recommended to choose some palatable dog food to help their teeth grinding and prevent oral diseases.)
Comments: B is not a relevant paragraph. S is relevant to the topic but is inaccurate.
TABLE 10Comparison of models performance on the FAQ dataset.
Method Acc. MRR
TF-IDF 73.7 0.813BM25 72.1 0.802LASER 79.9 0.856
BERT 76.8 0.831MLM 78.3 0.843Span 78.6 0.846BURT 82.2 0.872
BERT-wwm-ext 76.7 0.834MLM 76.7 0.834Span 79.3 0.856BURT-wwm-ext 80.7 0.863
For FAQ and NLG, we compare our models with statisti-cal methods such as TF-IDF and BM25, a sentence representa-tion model LASER [2], the pre-trained BERT/BERT-wwm-extand models trained with additional steps (MLM, Span). Weobserve that further training on Chinese SNLI and MNLIdatasets underperforms BERT on the FAQ dataset. Therefore,we only consider pre-trained models for these two tasks.
6 EXPERIMENTS
6.1 General Language UnderstandingTable 6 and show the results on the GLUE and CLUEbenchmarks, where we find that training BERT with ad-ditional MLM steps can hardly bring any improvementexcept for the WSC task. In Chinese, the Span model iseffective on WSC but is comparable to BERT on other tasks.
TABLE 11Results on NLG according to human judgment. “R” and “CM” represent
the percentage of paragraphs that are “relevant” and “convey themeaning”, respectively.
R BM25 LASER BERT MLM SPAN BURT
Judge1 60.3 63.9 65.9 65.0 69.3 71.8Judge2 61.8 61.6 67.3 67.5 71.5 71.0Avg. 61.1 62.8 66.6 66.3 70.4 71.4
CM BM25 LASER BERT MLM SPAN BURT
Judge1 43.5 42.5 48.5 46.1 51.6 54.2Judge2 41.2 38.4 47.8 45.5 53.9 56.5Avg. 42.4 40.5 48.2 45.8 52.8 55.4
BERT-wwm-ext is better than our model on classificationtasks involving pairs of short sentences such as AFQMC andOCNLI, which may be due to its relative powerful capabilityof modeling short sequences. Overall, both BURT and BURT-wwm-ext outperform the baseline models on 4 out of 6 taskswith considerable improvement, which sheds light on theireffectiveness of modeling sequences of different lengths. Themost significant improvement is observed on WSC (3.5%over the updated BERT-wwm-ext and 0.7% over the Spanmodel), where the model is trained to determine whetherthe given two spans refer to the same entity in the text. Weconjecture that the model benefits from learning to predictmeaningful spans in the pre-training stage, so it is betterat capturing the meanings of spans in the text. In English,our approach also improves the performance of BERT onvarious tasks from the GLUE benchmark, indicating thatour proposed PMI-based masking method is general and
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 10
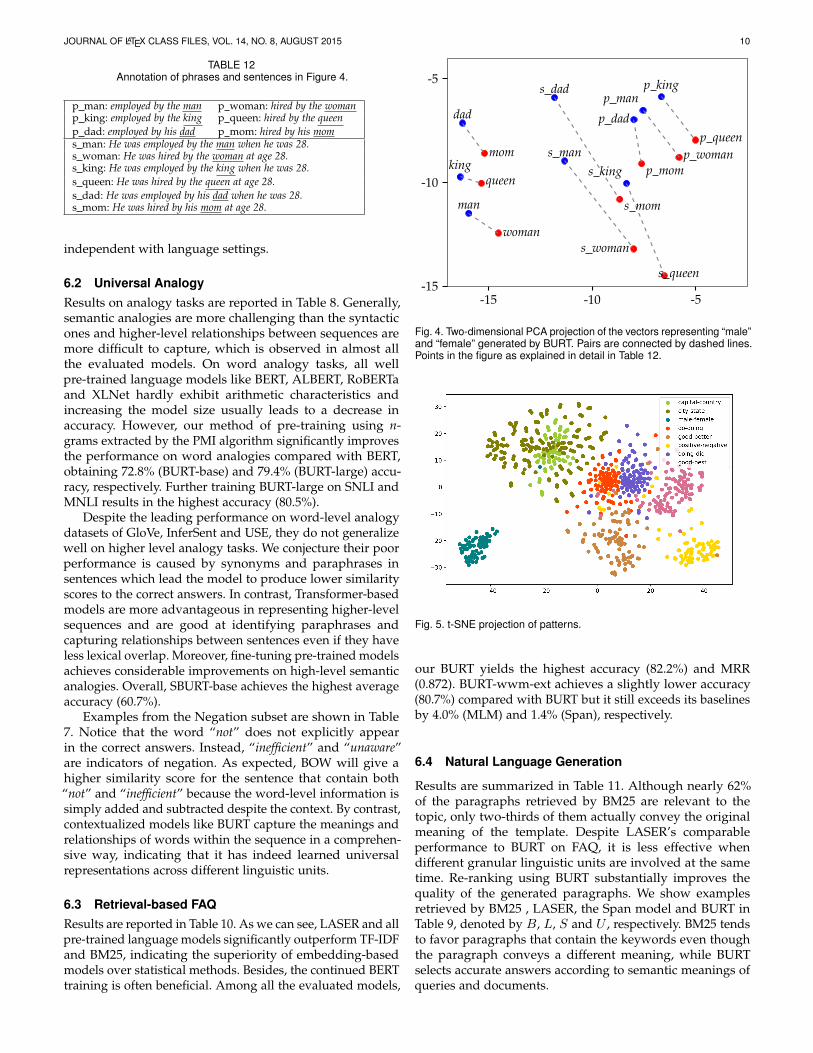
TABLE 12Annotation of phrases and sentences in Figure 4.
p man: employed by the man p woman: hired by the womanp king: employed by the king p queen: hired by the queenp dad: employed by his dad p mom: hired by his moms man: He was employed by the man when he was 28.s woman: He was hired by the woman at age 28.s king: He was employed by the king when he was 28.s queen: He was hired by the queen at age 28.s dad: He was employed by his dad when he was 28.s mom: He was hired by his mom at age 28.
independent with language settings.
6.2 Universal AnalogyResults on analogy tasks are reported in Table 8. Generally,semantic analogies are more challenging than the syntacticones and higher-level relationships between sequences aremore difficult to capture, which is observed in almost allthe evaluated models. On word analogy tasks, all wellpre-trained language models like BERT, ALBERT, RoBERTaand XLNet hardly exhibit arithmetic characteristics andincreasing the model size usually leads to a decrease inaccuracy. However, our method of pre-training using n-grams extracted by the PMI algorithm significantly improvesthe performance on word analogies compared with BERT,obtaining 72.8% (BURT-base) and 79.4% (BURT-large) accu-racy, respectively. Further training BURT-large on SNLI andMNLI results in the highest accuracy (80.5%).
Despite the leading performance on word-level analogydatasets of GloVe, InferSent and USE, they do not generalizewell on higher level analogy tasks. We conjecture their poorperformance is caused by synonyms and paraphrases insentences which lead the model to produce lower similarityscores to the correct answers. In contrast, Transformer-basedmodels are more advantageous in representing higher-levelsequences and are good at identifying paraphrases andcapturing relationships between sentences even if they haveless lexical overlap. Moreover, fine-tuning pre-trained modelsachieves considerable improvements on high-level semanticanalogies. Overall, SBURT-base achieves the highest averageaccuracy (60.7%).
Examples from the Negation subset are shown in Table7. Notice that the word “not” does not explicitly appearin the correct answers. Instead, “inefficient” and “unaware”are indicators of negation. As expected, BOW will give ahigher similarity score for the sentence that contain both“not” and “inefficient” because the word-level information issimply added and subtracted despite the context. By contrast,contextualized models like BURT capture the meanings andrelationships of words within the sequence in a comprehen-sive way, indicating that it has indeed learned universalrepresentations across different linguistic units.
6.3 Retrieval-based FAQResults are reported in Table 10. As we can see, LASER and allpre-trained language models significantly outperform TF-IDFand BM25, indicating the superiority of embedding-basedmodels over statistical methods. Besides, the continued BERTtraining is often beneficial. Among all the evaluated models,
-15 -10 -5-15
-10
-5
kingqueen
dad
mom
man
woman
p king
p queenp dad
p mom
p man
p womans king
s queen
s dad
s mom
s man
s woman
Fig. 4. Two-dimensional PCA projection of the vectors representing “male”and “female” generated by BURT. Pairs are connected by dashed lines.Points in the figure as explained in detail in Table 12.
Fig. 5. t-SNE projection of patterns.
our BURT yields the highest accuracy (82.2%) and MRR(0.872). BURT-wwm-ext achieves a slightly lower accuracy(80.7%) compared with BURT but it still exceeds its baselinesby 4.0% (MLM) and 1.4% (Span), respectively.
6.4 Natural Language Generation
Results are summarized in Table 11. Although nearly 62%of the paragraphs retrieved by BM25 are relevant to thetopic, only two-thirds of them actually convey the originalmeaning of the template. Despite LASER’s comparableperformance to BURT on FAQ, it is less effective whendifferent granular linguistic units are involved at the sametime. Re-ranking using BURT substantially improves thequality of the generated paragraphs. We show examplesretrieved by BM25 , LASER, the Span model and BURT inTable 9, denoted by B, L, S and U , respectively. BM25 tendsto favor paragraphs that contain the keywords even thoughthe paragraph conveys a different meaning, while BURTselects accurate answers according to semantic meanings ofqueries and documents.

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 11
-60 -40 -20 0 20 40
-60
-30
0
30
60
Can 80-year-old peopleget accident insurance?
Can seniors buyaccident insurance?
Will managers recommend productsto clients for their own benefit?
Can life insurance lastuntil the age of 80?
Is thereany insurance
that yourecommend?
Whichinsurance is
suitable for me?
Can I get insurance for my boyfriend?
Can I get insuranceafter an accident?
Fig. 6. t-SNE projection of BURT embeddings. Blue dots: queries, Reddots: sentences retrieved by BURT, Grey dots: sentences retrieved byTF-IDF and BM25.
7 VISUALIZATION
7.1 Single Pattern
Mikolov et al. (2013) [20] use PCA to project word embed-dings into a two-dimensional space to visualize a singlepattern captured by the Word2Vec model, while in this workwe consider embeddings for different granular linguisticunits. All pairs in Figure 4 belong to the “male-female”category and subtracting the two vectors results in roughlythe same direction.
7.2 Clustering
Given that embeddings of sequences with the same kind ofrelationship will exhibit the same pattern in the vector space,we obtain the difference between pairs of embeddings forwords, phrases and sentences from different categories andvisualize them by t-SNE. Figure 5 shows that by subtractingtwo vectors, pairs that belong to the same category automati-cally fall into the same cluster. Only the pairs from “capital-country” and “city-state” cannot be totally distinguished,which is reasonable because they all describe the relationshipbetween geographical entities.
7.3 FAQ
We show examples in Figure 6 where BURT successfullyretrieve the correct answer while TF-IDF and BM25 fail. Bothsentences “Can 80-year-old people get accident insurance?” and“Can life insurance last until the age of 80?” contain the word“80”, which is a possible reason why TF-IDF tends to believethey highly match with each other, ignoring that the twosentences are actually describing two different issues. Incontrast, using vector-based representations, BURT considers“seniors” as a paraphrase of “80-year-old people”. As depictedin Figure 6, queries are close to the correct responses andaway from other sentences.
8 CONCLUSION
This paper formally introduces the task of universal repre-sentation learning and then presents a pre-trained language
model for such a purpose to map different granular linguisticunits into the same vector space where similar sequenceshave similar representations and enable unified vector oper-ations among different language hierarchies.
In detail, we focus on the less concentrated languagerepresentation, seeking to learn a uniform vector form acrossdifferent linguistic unit hierarchies. Far apart from learningeither word only or sentence only representation, our methodextends BERT’s masking and training objective to a moregeneral level, which leverage information from sequencesof different lengths in a comprehensive way and effectivelylearns a universal representation from words, phrases tosentences.
Overall, our proposed BURT outperforms its baselines ona wide range of downstream tasks with regard to sequencesof different lengths in both English and Chinese languages.We especially provide an universal analogy task, an insuranceFAQ dataset and an NLG dataset for extensive evaluation,where our well-trained universal representation model holdsthe promise for demonstrating accurate vector arithmeticwith regard to words, phrases and sentences and in real-world retrieval applications.
REFERENCES
[1] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimationof word representations in vector space,” 2013.
[2] M. Artetxe and H. Schwenk, “Massively multilingual sentenceembeddings for zero-shot cross-lingual transfer and beyond,”Trans. Assoc. Comput. Linguistics, vol. 7, pp. 597–610, 2019. [Online].Available: https://transacl.org/ojs/index.php/tacl/article/view/1742
[3] D. Cer, Y. Yang, S.-y. Kong, N. Hua, N. Limtiaco, R. St. John,N. Constant, M. Guajardo-Cespedes, S. Yuan, C. Tar, B. Strope,and R. Kurzweil, “Universal sentence encoder for English,” inProceedings of the 2018 Conference on Empirical Methods in NaturalLanguage Processing: System Demonstrations. Brussels, Belgium:Association for Computational Linguistics, Nov. 2018, pp. 169–174.
[4] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee,and L. Zettlemoyer, “Deep contextualized word representations,”in Proceedings of NAACL-HLT, 2018, pp. 2227–2237.
[5] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever,“Improving language understanding by generative pre-training,” URL https://s3-us-west-2.amazonaws.com/openai-assets/researchcovers/languageunsupervised/language understandingpaper. pdf, 2018.
[6] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language under-standing,” 2018.
[7] Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. Salakhutdinov, and Q. V.Le, “Xlnet: Generalized autoregressive pretraining for languageunderstanding,” arXiv preprint arXiv:1906.08237, 2019.
[8] Y. Cui, W. Che, T. Liu, B. Qin, Z. Yang, S. Wang, and G. Hu, “Pre-training with whole word masking for chinese bert,” 2019.
[9] W. Wang, B. Bi, M. Yan, C. Wu, J. Xia, Z. Bao, L. Peng, and L. Si,“Structbert: Incorporating language structures into pre-trainingfor deep language understanding,” in International Conference onLearning Representations, 2020.
[10] M. Joshi, D. Chen, Y. Liu, D. S. Weld, L. Zettlemoyer, and O. Levy,“Spanbert: Improving pre-training by representing and predictingspans,” Transactions of the Association for Computational Linguistics,vol. 8, pp. 64–77, 2020.
[11] J. Pennington, R. Socher, and C. Manning, “Glove: Global vectorsfor word representation,” in Proceedings of the 2014 Conference onEmpirical Methods in Natural Language Processing (EMNLP). Doha,Qatar: Association for Computational Linguistics, Oct. 2014, pp.1532–1543.
[12] A. Joulin, E. Grave, P. Bojanowski, and T. Mikolov, “Bag of tricksfor efficient text classification,” 2016.

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 12
[13] R. Kiros, Y. Zhu, R. R. Salakhutdinov, R. Zemel, R. Urtasun,A. Torralba, and S. Fidler, “Skip-thought vectors,” in Advancesin neural information processing systems, 2015, pp. 3294–3302.
[14] L. Logeswaran and H. Lee, “An efficient framework for learningsentence representations,” in International Conference on LearningRepresentations (ICLR), 2018.
[15] A. Conneau, D. Kiela, H. Schwenk, L. Barrault, and A. Bordes,“Supervised learning of universal sentence representations from nat-ural language inference data,” in Proceedings of the 2017 Conferenceon Empirical Methods in Natural Language Processing. Copenhagen,Denmark: Association for Computational Linguistics, Sep. 2017,pp. 670–680.
[16] S. R. Bowman, G. Angeli, C. Potts, and C. D. Manning, “A largeannotated corpus for learning natural language inference,” inProceedings of the 2015 Conference on Empirical Methods in Natural Lan-guage Processing. Lisbon, Portugal: Association for ComputationalLinguistics, Sep. 2015, pp. 632–642.
[17] S. Subramanian, A. Trischler, Y. Bengio, and C. J. Pal, “Learninggeneral purpose distributed sentence representations via largescale multi-task learning,” in International Conference on LearningRepresentations, 2018.
[18] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Sori-cut, “Albert: A lite bert for self-supervised learning of languagerepresentations,” 2019.
[19] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis,L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimizedbert pretraining approach,” 2019.
[20] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean,“Distributed representations of words and phrases and theircompositionality,” 2013.
[21] O. Levy and Y. Goldberg, “Linguistic regularities in sparse andexplicit word representations,” in CoNLL 2014, 2014.
[22] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N.Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”in Advances in neural information processing systems, 2017, pp. 5998–6008.
[23] X. Liu, P. He, W. Chen, and J. Gao, “Multi-task deep neuralnetworks for natural language understanding,” in Proceedings of the57th Annual Meeting of the Association for Computational Linguistics.Florence, Italy: Association for Computational Linguistics, Jul. 2019,pp. 4487–4496.
[24] Y. Adi, E. Kermany, Y. Belinkov, O. Lavi, and Y. Goldberg, “Fine-grained analysis of sentence embeddings using auxiliary predictiontasks,” CoRR, 2016.
[25] A. Conneau, G. Kruszewski, G. Lample, L. Barrault, and M. Ba-roni, “What you can cram into a single vector: Probing sentenceembeddings for linguistic properties,” CoRR, 2018.
[26] G. Bacon and T. Regier, “Probing sentence embeddings for structure-dependent tense,” in Proceedings of the Workshop: Analyzing andInterpreting Neural Networks for NLP, BlackboxNLP@EMNLP 2018,Brussels, Belgium, November 1, 2018, 2018.
[27] A. Rogers, O. Kovaleva, and A. Rumshisky, “A primer in bertology:What we know about how bert works,” 2020.
[28] X. Ma, Z. Wang, P. Ng, R. Nallapati, and B. Xiang, “Universal textrepresentation from bert: An empirical study,” 2019.
[29] G. Jawahar, B. Sagot, and D. Seddah, “What does BERT learn aboutthe structure of language?” in ACL 2019, 2019.
[30] P. Barancıkova and O. Bojar, “In search for linear relations insentence embedding spaces,” in ITAT 2019, ser. CEUR WorkshopProceedings, 2019.
[31] X. Zhu and G. de Melo, “Sentence analogies: Exploring linguisticrelationships and regularities in sentence embeddings,” CoRR, 2020.
[32] K. Hammond, R. Burke, C. Martin, and S. Lytinen, “Faq finder: acase-based approach to knowledge navigation,” in Proceedings ofthe 11th Conference on Artificial Intelligence for Applications, 1995.
[33] V. Jijkoun and M. de Rijke, “Retrieving answers from frequentlyasked questions pages on the web,” in CIKM 2005, 2005.
[34] E. Sneiders, “Automated faq answering with question-specificknowledge representation for web self-service,” 2009.
[35] S. Damani, K. N. Narahari, A. Chatterjee, M. Gupta, and P. Agrawal,“Optimized transformer models for FAQ answering,” in PAKDD2020, ser. Lecture Notes in Computer Science, 2020.
[36] W. Sakata, T. Shibata, R. Tanaka, and S. Kurohashi, “FAQ retrievalusing query-question similarity and bert-based query-answerrelevance,” in SIGIR 2019, 2019.
[37] A. Stolcke, “Srilm - an extensible language modeling toolkit,” inINTERSPEECH, 2002.
[38] K. W. Church and P. Hanks, “Word association norms, mutualinformation, and lexicography,” Computational linguistics, vol. 16,no. 1, pp. 22–29, 1990.
[39] A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. Bowman,“GLUE: A multi-task benchmark and analysis platform for naturallanguage understanding,” in Proceedings of the 2018 EMNLP Work-shop BlackboxNLP: Analyzing and Interpreting Neural Networks forNLP, Nov. 2018, pp. 353–355.
[40] A. Warstadt, A. Singh, and S. R. Bowman, “Neural networkacceptability judgments,” 2019.
[41] R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Ng,and C. Potts, “Recursive deep models for semantic compositionalityover a sentiment treebank,” in Proceedings of the 2013 Conferenceon Empirical Methods in Natural Language Processing, Oct. 2013, pp.1631–1642.
[42] N. Nangia, A. Williams, A. Lazaridou, and S. Bowman, “TheRepEval 2017 shared task: Multi-genre natural language inferencewith sentence representations,” in Proceedings of the 2nd Workshopon Evaluating Vector Space Representations for NLP, Sep. 2017, pp.1–10.
[43] P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “SQuAD: 100,000+questions for machine comprehension of text,” in Proceedings of the2016 Conference on Empirical Methods in Natural Language Processing,Nov. 2016, pp. 2383–2392.
[44] W. B. Dolan and C. Brockett, “Automatically constructing a corpusof sentential paraphrases,” in Proceedings of the Third InternationalWorkshop on Paraphrasing (IWP2005), 2005.
[45] D. Cer, M. Diab, E. Agirre, I. Lopez-Gazpio, and L. Specia,“SemEval-2017 task 1: Semantic textual similarity multilingualand crosslingual focused evaluation,” in Proceedings of the 11thInternational Workshop on Semantic Evaluation (SemEval-2017), Aug.2017, pp. 1–14.
[46] L. Xu, H. Hu, X. Zhang, L. Li, C. Cao, Y. Li, Y. Xu, K. Sun, D. Yu,C. Yu, Y. Tian, Q. Dong, W. Liu, B. Shi, Y. Cui, J. Li, J. Zeng,R. Wang, W. Xie, Y. Li, Y. Patterson, Z. Tian, Y. Zhang, H. Zhou,S. Liu, Z. Zhao, Q. Zhao, C. Yue, X. Zhang, Z. Yang, K. Richardson,and Z. Lan, “CLUE: A Chinese language understanding evaluationbenchmark,” in Proceedings of the 28th International Conference onComputational Linguistics, Dec. 2020, pp. 4762–4772.
[47] LTD. IFLYTEK CO, “Iflytek: a multiple categories chinese textclassifier,” 2019.
[48] H. Hu, K. Richardson, L. Xu, L. Li, S. Kuebler, and L. S. Moss,“Ocnli: Original chinese natural language inference,” 2020.
[49] Y. Cui, T. Liu, W. Che, L. Xiao, Z. Chen, W. Ma, S. Wang, andG. Hu, “A span-extraction dataset for Chinese machine readingcomprehension,” in Proceedings of the 2019 Conference on EmpiricalMethods in Natural Language Processing and the 9th International JointConference on Natural Language Processing (EMNLP-IJCNLP), Nov.2019, pp. 5883–5889.
[50] C. Zheng, M. Huang, and A. Sun, “ChID: A large-scale ChineseIDiom dataset for cloze test,” in Proceedings of the 57th AnnualMeeting of the Association for Computational Linguistics, Florence,Italy, Jul. 2019, pp. 778–787.
[51] K. Sun, D. Yu, D. Yu, and C. Cardie, “Probing prior knowledgeneeded in challenging chinese machine reading comprehension,”ArXiv, vol. abs/1904.09679, 2019.
[52] B. Matthews, “Comparison of the predicted and observed sec-ondary structure of t4 phage lysozyme,” Biochimica et BiophysicaActa (BBA) - Protein Structure, vol. 405, no. 2, pp. 442 – 451, 1975.
[53] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza-tion,” 2017.
Yian Li received her Bachelor’s degree inElectronic and Information Engineering fromHuazhong University of Science and Technologyin 2019. She is working towards the M.S. degreein Department of Computer Science, ShanghaiJiao Tong University. Her research interests fo-cuses on natural language processing, especiallyin language representation and pre-training lan-guage model.

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 13
Hai Zhao received the BEng degree in sensorand instrument engineering, and the MPhil de-gree in control theory and engineering from Yan-shan University in 1999 and 2000, respectively,and the PhD degree in computer science fromShanghai Jiao Tong University, China in 2005.He is currently a full professor at departmentof computer science and engineering, ShanghaiJiao Tong University after he joined the universityin 2009. He was a research fellow at the CityUniversity of Hong Kong from 2006 to 2009, a
visiting scholar in Microsoft Research Asia in 2011, a visiting expert inNICT, Japan in 2012. He is an ACM professional member, and served asarea co-chair in ACL 2017 on Tagging, Chunking, Syntax and Parsing,(senior) area chairs in ACL 2018, 2019 on Phonology, Morphology andWord Segmentation. His research interests include natural languageprocessing and related machine learning, data mining and artificialintelligence.






![users.clas.ufl.eduusers.clas.ufl.edu/burt/Burt Glossator/Burt Glossator[39] .… · Web viewRead After Burning: Posthumous Publication and the Sur-vivance of Jacques Derrida’s](https://static.fdocuments.in/doc/165x107/6055f60615ec1e7d661caed7/usersclasufl-glossatorburt-glossator39-web-view-read-after-burning-posthumous.jpg)









![University of Floridausers.clas.ufl.edu/burt/Burt Glossator/Burt Glossator[37] .… · Web viewRead After Burning: Posthumous Publication and the Sur-vivance of Jacques Derrida’s](https://static.fdocuments.in/doc/165x107/5f5fb03ad1931178a8190530/university-of-glossatorburt-glossator37-web-view-read-after-burning-posthumous.jpg)

