
Johnny Miller – Cassandra + Spark = Awesome- NoSQL matters Barcelona 2014
43
Training Day | December 3rd Beginner Track • Introduction to Cassandra • Introduction to Spark, Shark, Scala and Cassandra Advanced Track • Data Modeling • Performance Tuning Conference Day | December 4 th Cassandra Summit Europe 2014 will be the single largest gathering of Cassandra users in Europe. Learn how the world's most successful companies are transforming their businesses and growing faster than ever using Apache Cassandra. http://bit.ly/cassandrasummit2014
-
Upload
nosqlmatters -
Category
Data & Analytics
-
view
663 -
download
1
Transcript of Johnny Miller – Cassandra + Spark = Awesome- NoSQL matters Barcelona 2014

Training Day | December 3rd
Beginner Track • Introduction to Cassandra • Introduction to Spark, Shark, Scala and
Cassandra
Advanced Track • Data Modeling • Performance Tuning Conference Day | December 4th Cassandra Summit Europe 2014 will be the single largest gathering of Cassandra users in Europe. Learn how the world's most successful companies are transforming their businesses and growing faster than ever using Apache Cassandra.
http://bit.ly/cassandrasummit2014

Cassandra + Spark = Awesome
Johnny Miller, Solutions Architect @CyanMiller www.linkedin.com/in/johnnymiller

©2014 DataStax Confidential. Do not distribute without consent. 3
Who is DataStax?
Founded in April 2010
OUR INVESTORS
500+ customers
30% of the Fortune 100 300+ employees
38 countries worldwide Powering critical systems
DATASTAX BY THE NUMBERS
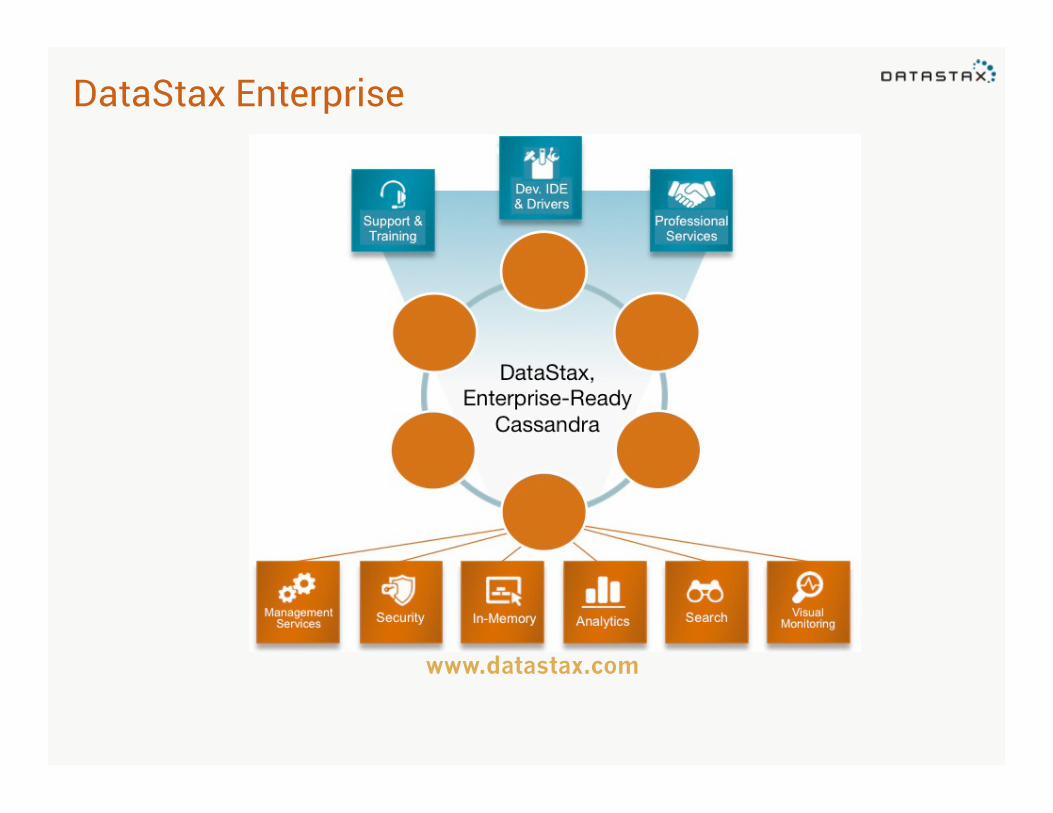
DataStax Enterprise
www.datastax.com

DataStax Enterprise is free for startups
• Unlimited, free use of the software in DataStax Enterprise.
• No limit on number of nodes or other hidden restrictions.
• If you’re a startup, it’s free!
www.datastax.com/startups

Training Day | December 3rd
Beginner Track • Introduction to Cassandra • Introduction to Spark, Shark, Scala and
Cassandra
Advanced Track • Data Modeling • Performance Tuning Conference Day | December 4th Cassandra Summit Europe 2014 will be the single largest gathering of Cassandra users in Europe. Learn how the world's most successful companies are transforming their businesses and growing faster than ever using Apache Cassandra.
http://bit.ly/cassandrasummit2014

What is Apache Cassandra?
Apache Cassandra™ is a massively scalable NoSQL OLTP database. Cassandra is designed to handle big data workloads across multiple data centers with no single point of failure, providing enterprises with continuous availability without compromising performance.
Cassandra is: • A Highly distributed database • Low latency – very near real-time • 100% availability – No SPOF • Highly scalable – Linear Scalability • Wide Column Store • Disk Optimised
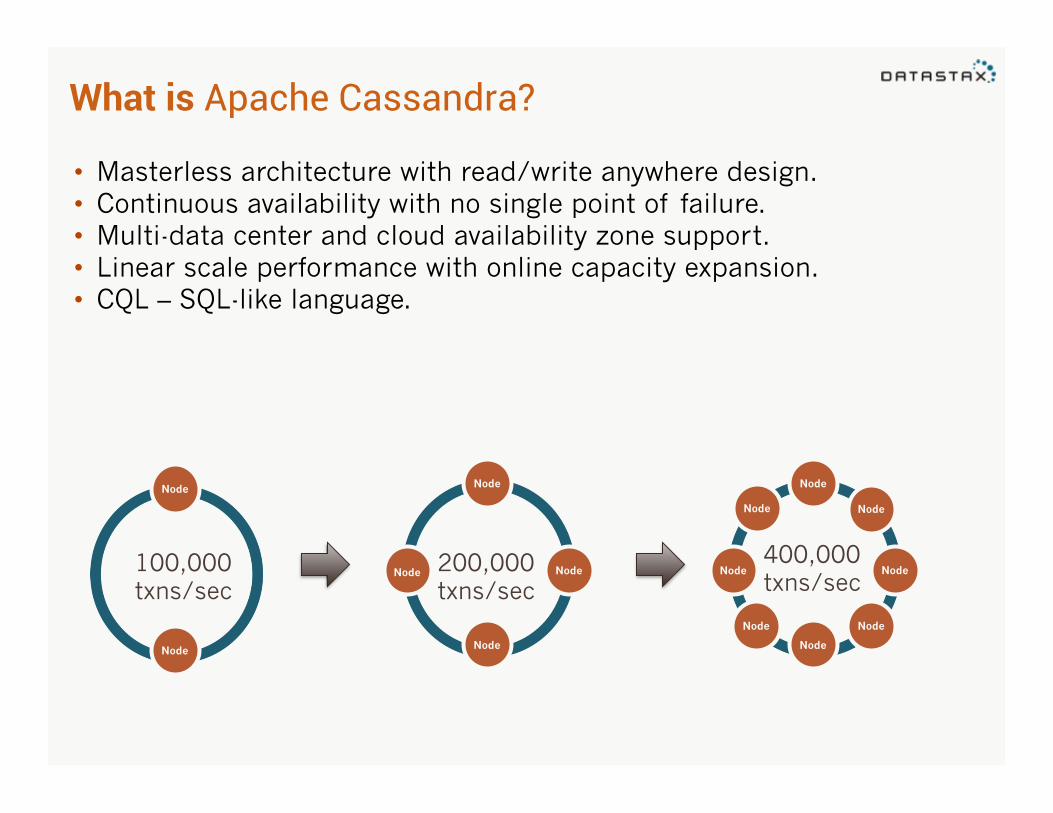
What is Apache Cassandra?
• Masterless architecture with read/write anywhere design. • Continuous availability with no single point of failure. • Multi-data center and cloud availability zone support. • Linear scale performance with online capacity expansion. • CQL – SQL-like language.
Node
Node
100,000 txns/sec
Node
Node
Node
Node
Node Node 200,000 txns/sec
Node Node
Node
Node Node
Node
400,000 txns/sec

“In terms of scalability, there is a clear winner throughout our experiments. Cassandra achieves the highest throughput for the maximum number of nodes in all experiments with a linear increasing throughput.” Solving Big Data Challenges for Enterprise Application Performance Management, Tilman Rable, et al., August 2013, p. 10. Benchmark paper presented at the Very Large Database Conference, 2013. http://vldb.org/pvldb/vol5/p1724_tilmannrabl_vldb2013.pdf
http://techblog.netflix.com/2011/11/benchmarking-cassandra-scalability-on.html
Netflix Cloud Benchmark… End Point Independent NoSQL Benchmark Highest in throughput…
Lowest in latency…
Cassandra: A Leader in Performance

• Cassandra was designed with the understanding that system/hardware failures can and do occur
• Peer-to-peer, distributed system • All nodes the same • Data partitioned among all nodes in the cluster • Custom data replication to ensure fault tolerance
Cassandra Architecture Overview
Node 1
Node 4
Node 5 Node 2
Node 3

• Multi data centre support out of the box • Configurable replication factor • Configurable data consistency per request • Active-Active replication architecture
Cassandra Architecture Overview
Node 1 1st copy
Node 4
Node 5 Node 2 2nd copy
Node 3
Node 1 1st
Node 4
Node 5 Node 2 2nd copy
Node 3 3rd copy
DC: USA DC: EU

Cassandra Query Language
CREATE TABLE sporty_league (
team_name varchar,
player_name varchar,
jersey int,
PRIMARY KEY (team_name, player_name)
);
SELECT * FROM sporty_league WHERE team_name = ‘Mighty Mutts’ and player_name = ‘Lucky’;
INSERT INTO sporty_league (team_name, player_name, jersey) VALUES ('Mighty Mutts',’Felix’,90);

Adoption
http://db-engines.com/en/ranking November 2014


Performance & Scale
DataStax works for small to huge deployments.
• DataStax Enterprise footprint @ Netflix • 80+ Clusters • 2500+ nodes • 4 Data Centres (Amazon Regions) • > 1 Trillion transactions per day See: http://www.datastax.com/resources/casestudies/netflix

Cassandra Use Cases
• Playlists/Collections • Personalisation/Recommendation • Messaging • Fraud Detection • Internet of Things/Sensor Data • Time Series
©2014 DataStax Confidential. Do not distribute without consent. 16

Apache Spark
• Distributed computing framework • Created by UC AMP Lab since 2009 • Apache Project since 2010 • Solves problems Hadoop is bad at
• Iterative Algorithms • Interactive Machine Learning • More general purpose than MapReduce
• Streaming!
©2014 DataStax Confidential. Do not distribute without consent. 17

Fast * Logistic Regression Performance

Components
Shark or
Spark SQL Streaming ML
Spark (General execution engine)
Graph
Cassandra
Compatible

Analytics Workload Isolation

Analytics High Availability
* All nodes are Spark Workers
* By default resilient to Worker failures
* First Spark node promoted as Spark
Master
* Standby Master promoted on failure
* Master HA available in DataStax
Enterprise

API
map ! reduce !

API
map !filter !groupBy !sort !union !join !leftOuterJoin !rightOuterJoin !
reduce !count !fold !reduceByKey !groupByKey !cogroup !cross !zip !
sample !take !first !partitionBy!mapWith!pipe !save !... !

API
* Resilient Distributed Datasets
* Collections of objects spread across a cluster, stored in RAM or on Disk
* Built through parallel transformations
* Automatically rebuilt upon failure
* Operations
* Transformations (e.g. map, filter, groupBy
* Actions (e.g. count, collect, save)

A Quick Comparison to Hadoop
©2014 DataStax Confidential. Do not distribute without consent. 25
HDFS
map()
reduce()
map()
reduce()

A Quick Comparison to Hadoop
©2014 DataStax Confidential. Do not distribute without consent. 26
HDFS
map()
reduce()
map()
reduce()
Data Source 1 Data
Source 2
map()
join()
cache()
transform() transform()

Word Count Example • 1. package org.myorg; • 2. • 3. import java.io.IOException; • 4. import java.util.*; • 5. • 6. import org.apache.hadoop.fs.Path; • 7. import org.apache.hadoop.conf.*; • 8. import org.apache.hadoop.io.*; • 9. import org.apache.hadoop.mapred.*; • 10. import org.apache.hadoop.util.*; • 11. • 12. public class WordCount { • 13. • 14. public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { • 15. private final static IntWritable one = new IntWritable(1); • 16. private Text word = new Text(); • 17. • 18. public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { • 19. String line = value.toString(); • 20. StringTokenizer tokenizer = new StringTokenizer(line); • 21. while (tokenizer.hasMoreTokens()) { • 22. word.set(tokenizer.nextToken()); • 23. output.collect(word, one); • 24. } • 25. } • 26. } • 27. • 28. public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { • 29. public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { • 30. int sum = 0; • 31. while (values.hasNext()) { • 32. sum += values.next().get(); • 33. } • 34. output.collect(key, new IntWritable(sum)); • 35. } • 36. } • 37. • 38. public static void main(String[] args) throws Exception { • 39. JobConf conf = new JobConf(WordCount.class); • 40. conf.setJobName("wordcount"); • 41. • 42. conf.setOutputKeyClass(Text.class); • 43. conf.setOutputValueClass(IntWritable.class); • 44. • 45. conf.setMapperClass(Map.class); • 46. conf.setCombinerClass(Reduce.class); • 47. conf.setReducerClass(Reduce.class); • 48. • 49. conf.setInputFormat(TextInputFormat.class); • 50. conf.setOutputFormat(TextOutputFormat.class); • 51. • 52. FileInputFormat.setInputPaths(conf, new Path(args[0])); • 53. FileOutputFormat.setOutputPath(conf, new Path(args[1])); • 54. • 55. JobClient.runJob(conf); • 57. } • 58. }
©2014 DataStax Confidential. Do not distribute without consent. 27

Word Count Example • 1. package org.myorg; • 2. • 3. import java.io.IOException; • 4. import java.util.*; • 5. • 6. import org.apache.hadoop.fs.Path; • 7. import org.apache.hadoop.conf.*; • 8. import org.apache.hadoop.io.*; • 9. import org.apache.hadoop.mapred.*; • 10. import org.apache.hadoop.util.*; • 11. • 12. public class WordCount { • 13. • 14. public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { • 15. private final static IntWritable one = new IntWritable(1); • 16. private Text word = new Text(); • 17. • 18. public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { • 19. String line = value.toString(); • 20. StringTokenizer tokenizer = new StringTokenizer(line); • 21. while (tokenizer.hasMoreTokens()) { • 22. word.set(tokenizer.nextToken()); • 23. output.collect(word, one); • 24. } • 25. } • 26. } • 27. • 28. public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { • 29. public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { • 30. int sum = 0; • 31. while (values.hasNext()) { • 32. sum += values.next().get(); • 33. } • 34. output.collect(key, new IntWritable(sum)); • 35. } • 36. } • 37. • 38. public static void main(String[] args) throws Exception { • 39. JobConf conf = new JobConf(WordCount.class); • 40. conf.setJobName("wordcount"); • 41. • 42. conf.setOutputKeyClass(Text.class); • 43. conf.setOutputValueClass(IntWritable.class); • 44. • 45. conf.setMapperClass(Map.class); • 46. conf.setCombinerClass(Reduce.class); • 47. conf.setReducerClass(Reduce.class); • 48. • 49. conf.setInputFormat(TextInputFormat.class); • 50. conf.setOutputFormat(TextOutputFormat.class); • 51. • 52. FileInputFormat.setInputPaths(conf, new Path(args[0])); • 53. FileOutputFormat.setOutputPath(conf, new Path(args[1])); • 54. • 55. JobClient.runJob(conf); • 57. } • 58. }
©2014 DataStax Confidential. Do not distribute without consent. 28
1. file = spark.textFile("hdfs://...") 2. counts = file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) 3. counts.saveAsTextFile("hdfs://...")

Word Count Example • 1. package org.myorg; • 2. • 3. import java.io.IOException; • 4. import java.util.*; • 5. • 6. import org.apache.hadoop.fs.Path; • 7. import org.apache.hadoop.conf.*; • 8. import org.apache.hadoop.io.*; • 9. import org.apache.hadoop.mapred.*; • 10. import org.apache.hadoop.util.*; • 11. • 12. public class WordCount { • 13. • 14. public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { • 15. private final static IntWritable one = new IntWritable(1); • 16. private Text word = new Text(); • 17. • 18. public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { • 19. String line = value.toString(); • 20. StringTokenizer tokenizer = new StringTokenizer(line); • 21. while (tokenizer.hasMoreTokens()) { • 22. word.set(tokenizer.nextToken()); • 23. output.collect(word, one); • 24. } • 25. } • 26. } • 27. • 28. public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { • 29. public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { • 30. int sum = 0; • 31. while (values.hasNext()) { • 32. sum += values.next().get(); • 33. } • 34. output.collect(key, new IntWritable(sum)); • 35. } • 36. } • 37. • 38. public static void main(String[] args) throws Exception { • 39. JobConf conf = new JobConf(WordCount.class); • 40. conf.setJobName("wordcount"); • 41. • 42. conf.setOutputKeyClass(Text.class); • 43. conf.setOutputValueClass(IntWritable.class); • 44. • 45. conf.setMapperClass(Map.class); • 46. conf.setCombinerClass(Reduce.class); • 47. conf.setReducerClass(Reduce.class); • 48. • 49. conf.setInputFormat(TextInputFormat.class); • 50. conf.setOutputFormat(TextOutputFormat.class); • 51. • 52. FileInputFormat.setInputPaths(conf, new Path(args[0])); • 53. FileOutputFormat.setOutputPath(conf, new Path(args[1])); • 54. • 55. JobClient.runJob(conf); • 57. } • 58. }
©2014 DataStax Confidential. Do not distribute without consent. 29
1. file = spark.textFile("hdfs://...") 2. counts = file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) 3. counts.saveAsTextFile("hdfs://...")
10x to 100x the speed of MapReduce

Spark / Shark Benchmark
©2014 DataStax Confidential. Do not distribute without consent. 30

Spark Streaming
©2014 DataStax Confidential. Do not distribute without consent. 31

Spark Streaming
• Scales to 100’s of nodes • High performance streaming
• In-memory processing • Data processed in small batches • Designed to be fault tolerant
• Maintains information in low level data abstraction elements that are able to be rebuilt upon faults
©2014 DataStax Confidential. Do not distribute without consent. 32

Spark Streaming
• Spark primary data abstraction item • Resilient Distributed Dataset (RDD)
• Immutable collection of elements that can be processed in parallel • RDD can be reconstructed from source in case of node failures
• Descretized Stream (DStream) • continuous stream of RDD’s
©2014 DataStax Confidential. Do not distribute without consent. 33

Spark Streaming
* Micro batching (each batch represented as RDD)
* Fault tolerant
* Exactly-once processing
* Unified stream and batch processing framework
* Supports Kafka, Flume, ZeroMQ, Kinesis, MQTT producers.
DStream Data Stream
RDD

Spark Streaming Example import com.datastax.spark.connector.streaming._ // Spark connection options val conf = new SparkConf(true)... // streaming with 1 second batch window val ssc = new StreamingContext(conf, Seconds(1)) // stream input val lines = ssc.socketTextStream(serverIP, serverPort) // count words val wordCounts = lines.flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _) // stream output wordCounts.saveToCassandra("test", "words") // start processing ssc.start() ssc.awaitTermination()

Spark SQL
• SQL-92 and HiveQL compatible query engine • Currently only SELECT and INSERT queries • Support for in-memory computation • Pushdown of predicates to Cassandra when possible

Spark SQL and HQL Example
import com.datastax.spark.connector._ // Connect to the Spark cluster val conf = new SparkConf(true)... val sc = new SparkContext(conf) // Create Cassandra SQL context val cc = new CassandraSQLContext(sc) // Execute SQL query val rdd = cc.sql("INSERT INTO ks.t1 SELECT c1,c2 FROM ks.t2") // Execute HQL query val rdd = cc.hql("SELECT * FROM keyspace.table JOIN ... WHERE ...")

Spark
• The next big thing! • Simple to use • Works great with Cassandra • Fast distributed processing – faster than MapReduce • Streaming • Machine Learning
• Classification, Collaborative filtering, Clustering, Optimization
©2014 DataStax Confidential. Do not distribute without consent. 38

Real-time Big Data!
©2014 DataStax Confidential. Do not distribute without consent. 39
Data Enrichment
Batch Processing Machine Learning
Pre-computed aggregates
Data
NO ETL

Real-Time Big Data Use Cases
• Recommendation Engine • Internet of Things • Fraud Detection • Risk Analysis • Buyer Behaviour Analytics • Telematics, Logistics • Business Intelligence • Infrastructure Monitoring
©2014 DataStax Confidential. Do not distribute without consent. 40

Partnership
©2014 DataStax Confidential. Do not distribute without consent. 41

How to use Spark with Cassandra?
* DataStax Cassandra Spark driver * Open source: https://github.com/datastax/cassandra-driver-spark
* DataStax Enterprise Analytics

Thank You
We power the big data apps that transform business.
©2013 DataStax Confidential. Do not distribute without consent.


















