


John Levesque Nov 16, 2001 levesque@cray - Nvidia · John Levesque Nov 16, 2001 [email protected] 2...
25
Transcript of John Levesque Nov 16, 2001 levesque@cray - Nvidia · John Levesque Nov 16, 2001 [email protected] 2...

1John Levesque Nov 16, 2001 [email protected]

John Levesque Nov 16, 2001 [email protected] 2
We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users’ requirements for a very high performance node with very high memory bandwidth.
Buddy Bland, ORNL Project Director OLCF-3HPCWire Interview, October 14, 2011
“
”

John Levesque Nov 16, 2001 [email protected] 3
XK6 Compute Node Characteristics
Host Processor AMD Series 6200 (Interlagos)
Tesla X2090 Perf. 665 Gflops
Host Memory 16, 32, or 64GB1600 MHz DDR3
Tesla X090Memory
6GB GDDR5170 GB/sec
Gemini High Speed Interconnect
Upgradeable to Kepler many-core processor

4John Levesque Nov 16, 2001 [email protected]
Accelerator Tools
Optimized Libraries
Analysis and Scoping
Tools
Compiler Directives

Accelerator Tools
Statistics gathering for identification of potential accelerator kernels
Statistics gathering for code running on accelerator
Optimized Libraries
Utilization of Autotuning framework for generating optimized accelerator library
Whole program analysis to performance scoping for OpenMP and OpenACC directives
John Levesque Nov 16, 2001 [email protected] 5

Open standard for addressing the acceleration of Fortran, C and C++ applications
Originally designed by Cray, PGI and Nvidia
Directives can be ignored on systems without accelerator
Can be used to target accelerators from Nvidia, AMD and Intel
John Levesque Nov 16, 2001 [email protected] 6

8John Levesque Nov 16, 2001
Final Configuration
Name Titan
Architecture XK6
Processor 16-Core AMD
Cabinets 200
Nodes 18,688
Cores/node 16
Total Cores 299,008
Memory/Node 32GB
Memory/Core 2GB
Interconnect Gemini
GPUS TBD

CAM-SE Denovo LAMMPS
PFLOTRAN S3D WL-LSMS
Early Science Applications
9John Levesque Nov 16, 2001

Key code kernels have been ported and their performance project a 4X speed up on XK6 over Jaguar
10John Levesque Nov 16, 2001
CAM-SE

Major REMAP kernel
John Levesque Nov 16, 2001 [email protected]
11
All times in Millisecs OpenMP Parallel DO24Threads MagnyCours
Original REMAP 65.30
Rewrite for porting to accelerator
32.65
Hand Coded CUDA 10.2
OpenACC directives 10.6

WL-LSMS
The kernel responsible for 95% of the compute time on the CPU has been ported and shows a 2.5X speed up over the replaced CPU
12John Levesque Nov 16, 2001
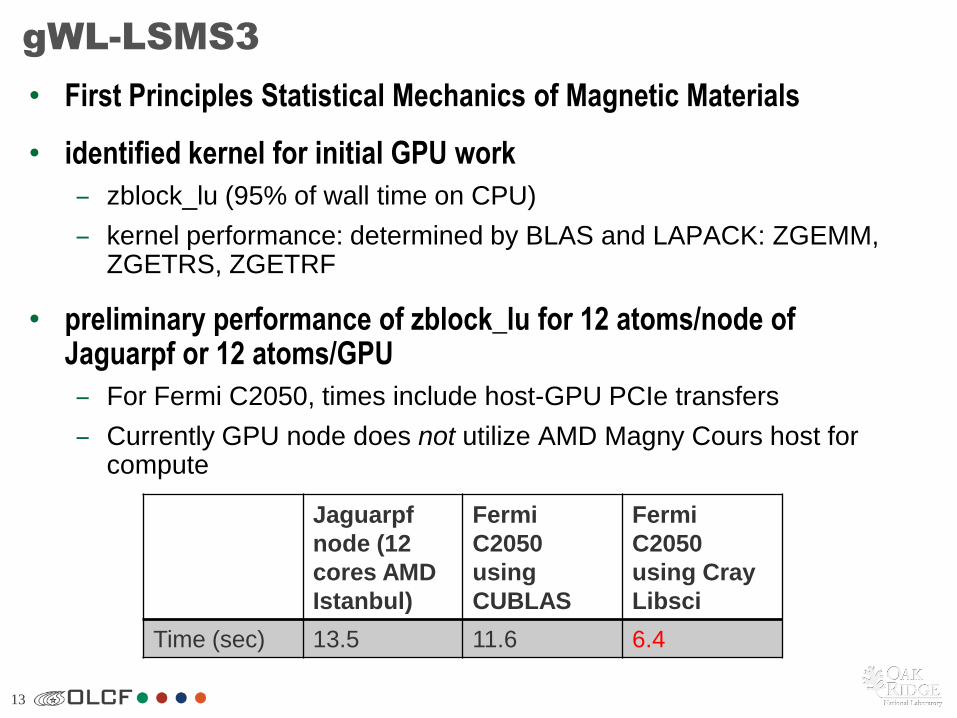
13
gWL-LSMS3
• First Principles Statistical Mechanics of Magnetic Materials
• identified kernel for initial GPU work
– zblock_lu (95% of wall time on CPU)
– kernel performance: determined by BLAS and LAPACK: ZGEMM, ZGETRS, ZGETRF
• preliminary performance of zblock_lu for 12 atoms/node of Jaguarpf or 12 atoms/GPU
– For Fermi C2050, times include host-GPU PCIe transfers
– Currently GPU node does not utilize AMD Magny Cours host for compute
Jaguarpf
node (12
cores AMD
Istanbul)
Fermi
C2050
using
CUBLAS
Fermi
C2050
using Cray
Libsci
Time (sec) 13.5 11.6 6.4

14John Levesque Nov 16, 2001
Denovo
The 3-D sweep kernel, 90% of the runtime, runs 40X faster on Fermi compared to an Opteron core. The new GPU-aware sweeper also runs 2X faster on CPUs compared to the previous CPU-based sweeper due to performance optimizations

Single Major Kernel - SWEEP
• The sweep code is written in C++ using MPI and CUDA runtime calls.
• CUDA constructs are employed to enable generation of both CPU and GPU object code from a single source code.
• C++ template metaprogramming is used to generate highly optimized code at compile time, using techniques such as function inlining and constant propagation to optimize for specific use cases.
John Levesque Nov 16, 2001 [email protected]
15

Denovo Performancermance data
0
2
4
6
8
10
12
14
1 4 16 64 256 1024
Seco
nd
s
Nodes
Jaguar, Denovo, old sweeper
Jaguar, Denovo, new sweeper
Jaguar, standalone new sweeper
Fermi, standalone new sweeper, extrapolated
Fermi + Gemini, standalone sweeper, estimated
16John Levesque Nov 16, 2001

LAMMPS
Currently seeing a 2X-5X speed up over the replaced CPU
17John Levesque Nov 16, 2001

Host-Device Load Balancing
• Split work further by spatial domain to improve data locality on GPU
• Further split work not ported to GPU across more CPU cores
• Concurrent calculation of routines not ported to GPUwith GPU force calculation
• Concurrent calculation of force on CPU and GPU
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
1 3 5 7 9 11 13 15Nodes
Other
Comm
Pair+Neigh+GPUComm
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
1 3 5 7 9 11 13 15Nodes
GPU-Comm Other Comm Neigh Pair
10
100
1000
1 2 4 8 16
Lo
op
Tim
e (
s)
Nodes
CPU (12ppn)
GPU (2ppn)
GPU LB (12 ppn)
GPU-N (2ppn)
GPU-N LB (12ppn)
18John Levesque Nov 16, 2001

S3D
Full Application running using new OpenACC directives. Target performance 4x JaguarPF
19John Levesque Nov 16, 2001

Covert OpenMP Regions to OpenACC
John Levesque Nov 16, 2001 [email protected]
21
All times in Seconds OpenMP Parallel DO16 Threads Interlagos
OpenACC ParallelConstruct
Getrates 1.18 .235
Diffusive Flux 1.99 1.21
Point wise Compute .234 .174
Total Run /cycleEntire application
4.37 2.80

Copyright 2011 Cray Inc. Supercomputing 2011
Transfer from host to accelerator Communication on hostComputation on the accelerator Computation on hostTransfer for accelerator to host
Timestep Loop RK loop !$acc data in integrate(Major Arrays on AcceleratorTimestep Loop RK loop !$acc intialization in rhsf(1,2)Timestep Loop RK loop !$acc update host(U,YSPECIES,TEMP)Timestep Loop RK loop !$acc parallel loop in rhsf (3)Timestep Loop RK loop MPI Halo Update for U,YSPECIES, TEMP)Timestep Loop RK loop !$acc update device(grad_U,grad_Ys,grad_T)Timestep Loop RK loop !$acc parallel loopin rhsf (4-5)Timestep Loop RK loop !$acc update host(mixMW)Timestep Loop RK loop MPI Halo Update for mixMWTimestep Loop RK loop !$acc update device(grad_mixMW)Timestep Loop RK loop !$acc parallel loop in rhsf(6,7,8,9)Timestep Loop RK loop MPI Halo Update for TMMPTimestep Loop RK loop Fill RHS array on hostTimestep Loop RK loop !$acc update device(diffFlux)Timestep Loop RK loop !$acc parallel loop in rhsf(10)Timestep Loop RK loop !$acc update host(diffFlux)Timestep Loop RK loop MPI Halo Update for diffFluxTimestep Loop RK loop !$acc update device(diffFlux,rhs)Timestep Loop RK loop !$acc parallel loop in rhsf(11,12)Timestep Loop RK loop !$acc update host(rhs)

Copyright 2011 Cray Inc. Supercomputing 2011
Host | Host | Acc | Acc Copy | Acc Copy | Calls |Function
Time% | Time | Time | In | Out | | PE=HIDE
| | | (MBytes) | (MBytes) | |
100.0% | 283.637 | 220.669 | 276847.501 | 111725.395 | 10420 |Total
|-------------------------------------------------------------------------------------------------
| 21.2% | 60.213 | -- | -- | -- | 120 |[email protected]
| 6.9% | 19.587 | -- | -- | -- | 120 |[email protected]
| 6.8% | 19.209 | -- | -- | -- | 120 |[email protected]
| 5.0% | 14.306 | 14.306 | 32602.500 | -- | 120 |[email protected]
| 5.0% | 14.157 | 14.157 | 32805.000 | -- | 120 |[email protected]
| 4.8% | 13.533 | 13.533 | 30881.250 | -- | 120 |[email protected]
| 4.8% | 13.506 | 13.506 | 30881.250 | -- | 120 |[email protected]
| 4.8% | 13.478 | 13.478 | 30881.250 | -- | 120 |[email protected]
| 3.4% | 9.758 | 9.758 | 22376.250 | -- | 120 |[email protected]
| 3.4% | 9.738 | -- | -- | -- | 120 |[email protected]
| 3.0% | 8.509 | 8.509 | -- | 32602.500 | 120 |[email protected]
| 2.6% | 7.388 | 7.388 | 17010.000 | -- | 120 |[email protected]
| 2.6% | 7.372 | 7.372 | 17010.000 | -- | 120 |[email protected]
| 2.5% | 7.078 | 7.078 | 16402.500 | -- | 120 |[email protected]
| 2.4% | 6.862 | 6.862 | 15795.000 | -- | 120 |[email protected]
| 2.4% | 6.856 | 6.856 | 15795.000 | -- | 120 |[email protected]
| 2.1% | 5.834 | -- | -- | -- | 120 |[email protected]
| 1.9% | 5.499 | 5.499 | -- | 22376.250 | 120 |[email protected]
| 1.8% | 5.157 | 5.157 | -- | 21060.000 | 120 |[email protected]
| 1.5% | 4.167 | 4.167 | -- | 16605.000 | 120 |[email protected]
| 1.3% | 3.792 | -- | -- | -- | 120 |[email protected]
| 1.3% | 3.656 | -- | -- | -- | 120 |[email protected]
| 1.1% | 2.996 | -- | -- | -- | 120 |[email protected]
| 1.0% | 2.707 | -- | -- | -- | 20 |[email protected]
| 0.9% | 2.531 | 2.531 | -- | -- | 120 |[email protected]
| 0.9% | 2.474 | 2.474 | 5670.000 | -- | 120 |[email protected]
| 0.8% | 2.242 | 2.242 | 4906.645 | -- | 20 |[email protected]
| 0.6% | 1.626 | 1.626 | 3729.375 | -- | 20 |[email protected]
| 0.5% | 1.452 | 1.452 | -- | 5670.000 | 120 |[email protected]
| 0.5% | 1.444 | 1.444 | -- | 5670.000 | 120 |[email protected]
| 0.5% | 1.388 | 1.388 | -- | 4906.645 | 20 |[email protected]
| 0.4% | 1.039 | -- | -- | -- | 120 |[email protected]
| 0.2% | 0.705 | -- | -- | -- | 20 |[email protected]
| 0.2% | 0.691 | 0.691 | -- | 2835.000 | 20 |[email protected]
| 0.2% | 0.659 | 0.659 | -- | -- | 120 |[email protected]
| 0.2% | 0.498 | 0.498 | -- | -- | 120 |[email protected]
| 0.2% | 0.497 | 0.497 | -- | -- | 120 |[email protected]
| 0.1% | 0.390 | -- | -- | -- | 120 |[email protected]
| 0.1% | 0.289 | 0.289 | 0.135 | -- | 120 |[email protected]
| 0.0% | 0.072 | 0.072 | 101.250 | -- | 120 |[email protected]
| 0.0% | 0.048 | 13.827 | -- | -- | 120 |[email protected]

Copyright 2011 Cray Inc. Supercomputing 2011
982. #ifdef GPU
983. G---------<> !$acc parallel loop private(i,ml,mu) present( temp, pressure, yspecies,rb,rf,cgetrates)
984. #else
985. !$omp parallel private(i, ml, mu)
986. !$omp do
987. #endif
988. g----------< do i = 1, nx*ny*nz, ms
989. g ml = i
990. g mu = min(i+ms-1, nx*ny*nz)
991. g gr4 I----> call reaction_rate_vec_1( temp, pressure, yspecies, ml, mu, rb,rf,cgetrates )
992. g----------> end do
993. #ifdef GPU
994. !$acc end aparallel loop
995. #else
996. !$omp end parallel
997. #endif
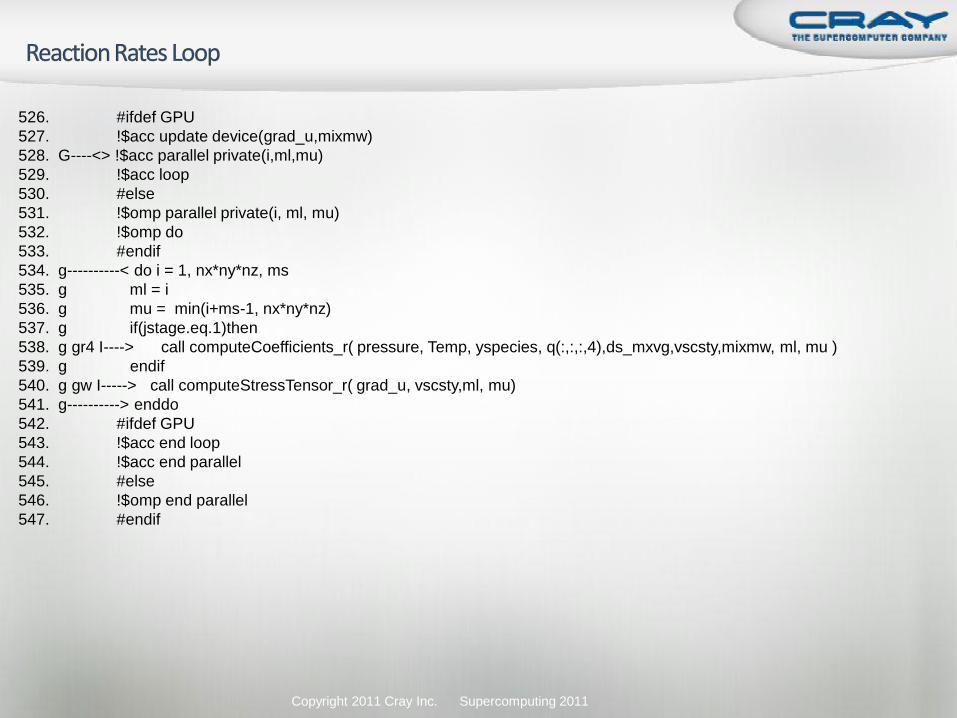
Copyright 2011 Cray Inc. Supercomputing 2011
526. #ifdef GPU
527. !$acc update device(grad_u,mixmw)
528. G----<> !$acc parallel private(i,ml,mu)
529. !$acc loop
530. #else
531. !$omp parallel private(i, ml, mu)
532. !$omp do
533. #endif
534. g----------< do i = 1, nx*ny*nz, ms
535. g ml = i
536. g mu = min(i+ms-1, nx*ny*nz)
537. g if(jstage.eq.1)then
538. g gr4 I----> call computeCoefficients_r( pressure, Temp, yspecies, q(:,:,:,4),ds_mxvg,vscsty,mixmw, ml, mu )
539. g endif
540. g gw I-----> call computeStressTensor_r( grad_u, vscsty,ml, mu)
541. g----------> enddo
542. #ifdef GPU
543. !$acc end loop
544. !$acc end parallel
545. #else
546. !$omp end parallel
547. #endif


















