
Japanese Dependency Structure Analysis Based on Maximum Entropy Models Kiyotaka Uchimoto † Satoshi...
24
Japanese Dependency Structure Analysis Based on Maximum Entropy Models Kiyotaka Uchimoto † Satoshi Sekine ‡ Hitoshi Isahara † † Kansai Advanced Research Center, Communications Research Laboratory ‡ New York University
-
date post
22-Dec-2015 -
Category
Documents
-
view
229 -
download
2
Transcript of Japanese Dependency Structure Analysis Based on Maximum Entropy Models Kiyotaka Uchimoto † Satoshi...

Japanese Dependency Structure Analysis Based on
Maximum Entropy Models
Kiyotaka Uchimoto † Satoshi Sekine ‡
Hitoshi Isahara †
† Kansai Advanced Research Center, Communications Research Laboratory
‡ New York University

Outline
BackgroundProbability model for estimating
dependency likelihoodExperiments and discussionConclusion

Background
Preparing a dependency matrix Finding an optimal set of dependencies for the
entire sentence
dependency
太郎は赤いバラを買いました。Taro bought a red rose.
太郎は
赤い
バラを
買いました。
Taro_wa bara_wo kai_mashita
Taro rose bought
太郎 は バラ を 買い ました。赤 いAka_i
red
bunsetsu
Japanese dependency structure analysis

Background (2)
Approaches to preparing a dependency matrix Rule-based approach
• Several problems with handcrafted rules– Coverage and consistency
– The rules have to be changed according to the target domain.
Corpus-based approach

Background (3)
Corpus-based approach Learning the likelihoods of dependencies from
a tagged corpus (Collins, 1996; Fujio and Matsumoto, 1998; Haruno et al., 1998)
Probability estimation based on the maximum entropy models (Ratnaparkhi, 1997)
Maximum Entropy model learns the weights of given features from a
training corpus

Probability modelAssigning one of two tags
Whether or not there is a dependency between two bunsetsus
Probabilities of dependencies are estimated from the M. E. model.
Overall dependencies in a sentence Product of probabilities of all dependencies
• Assumption: Dependencies are independent of each other.
or
:bunsetsudependency

f i
fhgi
i
fhgi
i
i
hfP ),(
),(
)|(
M. E. model
.:0
1&
)"(:)("
,),(:1
),(
otherwise
f
verbMajorPOSHeadPosteriorx
truexhhasif
fhg動詞
corpustestthefrom
derivablenInformatioh
dependencynoisThere
dependencyaisTheref
:
:0
:1

Feature setsBasic features (expanded from Haruno’s list
(Haruno, 1998)) Attributes on a bunsetsu itself
• Character strings, parts of speech, and inflection types of bunsetsu
Attributes between bunsetsus• Existence of punctuation, and the distance between b
unsetsus
Combined features

a b c deAnterior bunsetsu
Posterior bunsetsu
Taro_wa bara_wo kai_mashita
Taro rose bought
太郎 は バラ を 買い ました。
dependency
赤 いAka_i
red
Feature sets
Basic features: a, b, c, d, eCombined features
Twin: (b,c), Triplet: (b,c,e), Quadruplet: (a,b,c,d), Quintuplet: (a,b,c,d,e)
“Head” “Type” “Head” “Type”

AlgorithmDetect the dependencies in a sentence by analyzi
ng it backwards (from right to left). Characteristics of Japanese dependencies
• Dependencies are directed from left to right• Dependencies do not cross• A bunsetsu, except for the rightmost one, depends on only
one bunsetsu• In many cases, the left context is not necessary to determin
e a dependency
Beam search

Experiments
Using the Kyoto University text corpus (Kurohashi and Nagao, 1997) a tagged corpus of the Mainichi newspaper Training: 7,958 sentences (Jan. 1st to 8th) Testing: 1,246 sentences (Jan. 9th)
The input sentences were morphologically analyzed and their bunsetsus were identified correctly.

Results of dependency analysisDependencyaccuracy
Sentenceaccuracy
Deterministic(k=1)
87.14%(9,814/11,263)
40.60%(503/1,239)
Best beam search(k=11)
87.21%(9,822/11,263)
40.60%(503/1,239)
Baseline 64.09%(7,219/11,263)
6.38%(79/1,239)
• When analyzing a sentence backwards, the previous context has almost no effect on the accuracy.

0
0.2
0.4
0.6
0.8
1
0 5 10 15 20 25 30Number of bunsetsus in a sentence
Dep
ende
ncy
accu
racy 0.8714
Relationship between the number of bunsetsus and accuracy
• The accuracy does not significantly degrade with increasing sentence length.

a b c deAnterior bunsetsu
Posterior bunsetsu
“Head” “Type” “Head” “Type”
Features and accuracyExperiments without the feature sets
Useful basic features • Type of the anterior bunsetsu (-17.41%) and the part-of-spe
ech tag of the head word on the posterior bunsetsu (-10.99%)
• Distance between bunsetsus (-2.50%), the existence of punctuation in the bunsetsu (-2.52%), and the existence of brackets (-1.06%)
preferential rules with respect to the features

Features and accuracyExperiments without the feature sets
Combined features are useful (-18.31%).
Basic features are related to each other.
Features Accuracy
Without quadrupletand quintuplet features
84.27% (-2.87%)
Withouttriplet, quadruplet,and quintuplet features
81.28% (-5.86%)
Without all combinations 68.83% (-18.31%)

Lexical features and accuracyExperiment with the lexical features of the hea
d word Better accuracy than that without them (-0.84%) Many idiomatic expressions
• They had high dependency probabilities.– “ 応じて (oujite, according to)--- 決める (kimeru, decide)”
– “ 形で (katachi_de, in the form of)
--- 行われる (okonawareru, be held)”
• More training data Expect to collect more of such expressions

8082848688909294
0 1000 2000 3000 4000 5000 6000 7000 8000
Number of training data (sentences)
Par
sing
acc
urac
y (%
)
training testing
Number of training data and accuracy
• Accuracy of 81.84% even with 250 sentences
• M. E. framework has suitable characteristics for overcoming the data sparseness problem.
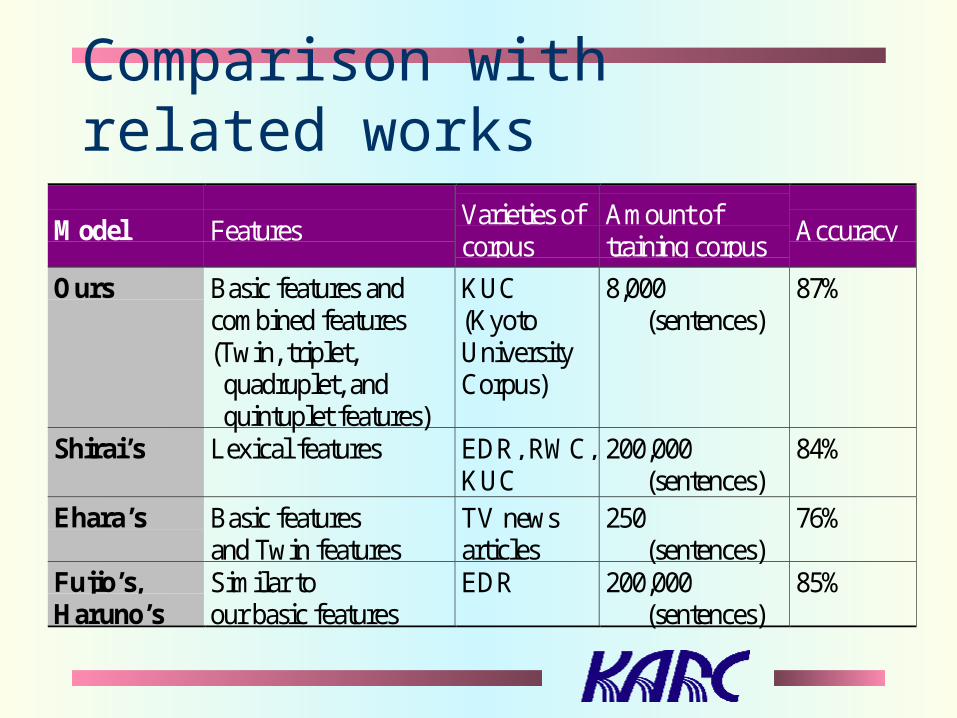
Model FeaturesVarieties ofcorpus
Amount oftraining corpus
Accuracy
Ours Basic features andcombined features(Twin, triplet, quadruplet, and quintuplet features)
KUC(KyotoUniversityCorpus)
8,000 (sentences)
87%
Shirai’s Lexical features EDR, RWC,KUC
200,000 (sentences)
84%
Ehara’s Basic featuresand Twin features
TV newsarticles
250 (sentences)
76%
Fujio’s,Haruno’s
Similar toour basic features
EDR 200,000 (sentences)
85%
Comparison with related works

Comparison with related works (2)
Combining a parser based on a handmade CFG and a probabilistic dependency model (Shirai, 1998) Using several corpora: the EDR corpus, RWC
corpus, and Kyoto University corpus.
Accuracy achieved by our model was about 3% higher than that of Shirai’s model. Using a much smaller set of training data.

Comparison with related works (3)M. E. model (Ehara, 1998)
Set of similar kinds of features to ours• Only the combination of two features
Using TV news articles for training and testing• Average sentence length = 17.8 bunsetsus• cf. 10 in the Kyoto University corpus
Difference in the combined features We also use triplet, quadruplet, and quintuplet featu
res (+5.86%). Accuracy of our system was about 10% higher than
Ehara’s system.

Comparison with related works (4)
Maximum Likelihood model (Fujio, 1998)Decision tree models and a boosting
method (Haruno, 1998) Set of similar kinds of features to ours Using the EDR corpus for training and testing
• EDR corpus is ten times as large as our corpus. Accuracy was around 85%, which is slightly
worse than ours.

Comparison with related works (5)
Experiments with Fujio’s and Haruno’s feature sets
The important factor in the statistical approaches is feature selection.
Feature set Accuracy
Fujio’s setHaruno’s set
85.71% (-1.43%)86.47% (-0.67%)

Future work
Feature selection Automatic feature selection (Berger, 1996, 1998;
Shirai, 1998)
Considering new features How to deal with coordinate structures
• Taking into account a wide range of information

ConclusionJapanese dependency structure analysis based on
the M. E. model. Dependency accuracy of our system
• 87.2% using the Kyoto University corpus Experiments without feature sets
• Some basic and combined features strongly contribute to improve the accuracy.
Number of training data and accuracy• Good accuracy even with a small set of training data• M. E. framework has suitable characteristics for
overcoming the data sparseness problem.


















