
IT 20303 The Relational DBMS Section 06. Relational Database Theory Physical Database Design.
36
IT 20303 • The Relational DBMS • Section 06
-
Upload
betty-freeman -
Category
Documents
-
view
235 -
download
2
Transcript of IT 20303 The Relational DBMS Section 06. Relational Database Theory Physical Database Design.

IT 20303
• The Relational DBMS
• Section 06
Relational Database Theory
• Physical Database Design

Relational Database Theory
• Physical Database Design– Goals
• Improve performance–By minimizing disk I/O
• Improving management of the data
–By grouping tables that can be managed as a group

Relational Database Theory
• Physical design decisions are based on:
– Use of the data (volume, frequency)
– Features supported by the specific RDBMS
– Disk storage configuration

Relational Database Theory
• DBA initially sets up the physical database
– Tunes physical parameters on a ongoing basis
• As usage patterns change
• As new hardware/software options become available

• Steps in Physical Design Process– Determine which tables can be managed
as a group• Many RDBMSs support the concept of
a Container (Oracle Tablespace, db space, Access uses the .mdb)
–A collection of tables, and indexes
Relational Database Theory

– Develop a plan for allocating tables to disk devices• Consider parallel disk controllers• Group tables together that are
frequently joined• Distribute heavily accessed table to
different disk devices–To avoid excessive head movement
on one disk
Relational Database Theory

– Build indexes on table columns, based on frequency of use
– Restructure tables if necessary
• Fragment large tables into multiple smaller ones
• De-normalize tables if appropriate
Relational Database Theory
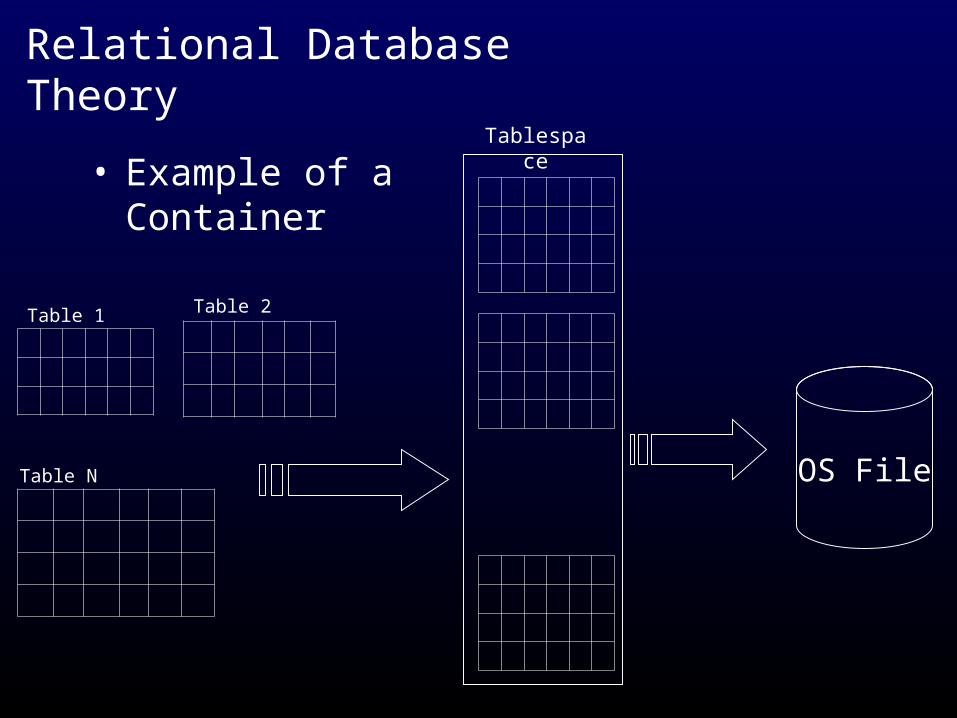
Relational Database Theory
• Example of a Container
Table 1 Table 2
Table N
Tablespace
OS File

• Managing a collection of Tables, Indexes– Purpose of container concept
• Relate tables, indexes to physical disk files
• Aid in the management of the database–Example: A tablespace can be
taken offline, backed up, and restored while the remainder of the database is online
Relational Database Theory
– Support clustering data from related tables in the same file
• So that related data is read with the same I/O request
Relational Database Theory

• How the RDBMS processes a user request
– RDBMS parses, validates, and optimizes the SQL request
– Determines disk file in which the table is written
• Specific to each RDBMS & OS
Relational Database Theory
– Initiates I/O request to operating system, if necessary
• I/O is requested if file is not currently in buffers
– Processes execution plan using data in its buffer
Relational Database Theory

• Indexes
– Index is a separate structure (table)
• Points into the data table
• Built on one or more columns in the data table
Relational Database Theory

• Comments on Indexing– An index can be built on any column or
combination of columns– An index can be unique or non-unique– An index on the primary key is called the
primary index– Most RDBMSs use an internal row id as
the pointer to the row– Use of the index is transparent to the user
Relational Database Theory

• Use of an index
– Provides access to a row based on data value(s)
– Avoids duplicates – only way
– Supports sequential processing on the indexed field
– Improves performance
Relational Database Theory

• Use of an index improves performance on Retrieval– Processing an index is more efficient than
processing a table – for reads• Index is usually small, relative to the
table–Can be held entirely in memory
• The smaller the index value, the more entries per block the more likely the index will be in memory
Relational Database Theory

• Most RDBMSs use a type of B-Tree Index
– B-tree indexes were designed for efficient search of a sorted list
– Algorithms exist for managing and maintaining B-trees
Relational Database Theory

• B-trees were introduced by Bayer (1972) and McCreight.
– They are a special m-ary balanced tree used in databases because their structure allows records to be inserted, deleted, and retrieved with guaranteed worst-case performance
Relational Database Theory
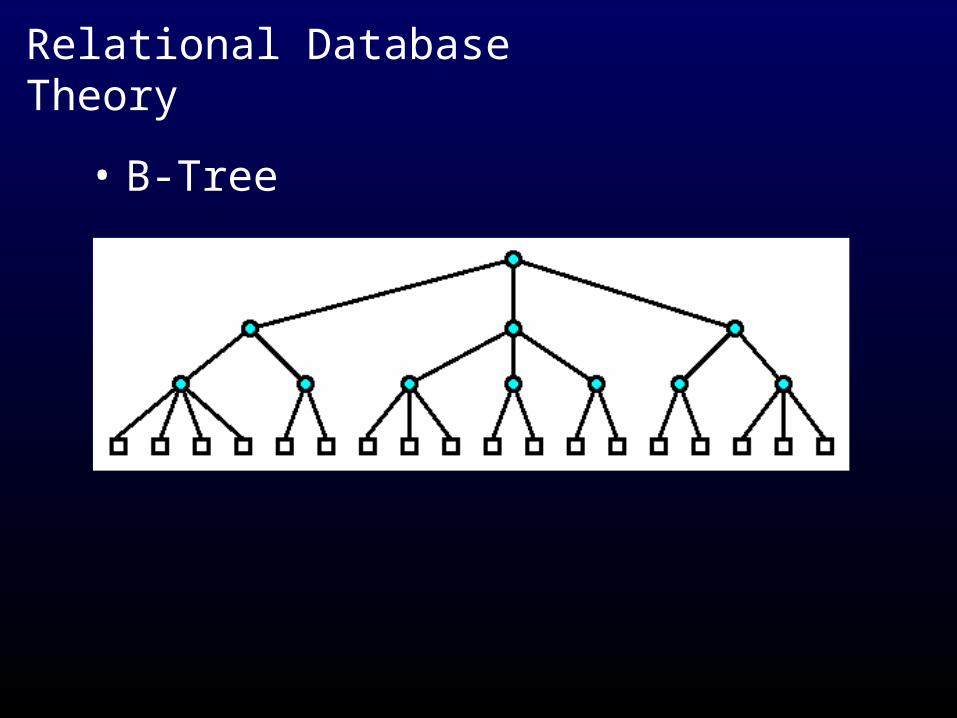
• B-Tree
Relational Database Theory

• Use of index degrades performance on Updates
– Inserting a row is the source of much disk I/O (overhead)
• Every index on the table must be searched and updated also
Relational Database Theory
• Frequently inserting rows leads to index block overflow
– Causes much disk I/O as overflow condition is processed
Relational Database Theory

• Techniques for managing volatile tables (many interests, deletes)
– Partially fill index blocks when creating the index
– Periodically restructure (Drop, Create) the indexes
Relational Database Theory

• Indexing: Strengths and Weaknesses– Strengths
• Improves performance on retrieval of data
• Can be built or dropped at any time• Usage is transparent to the user
– Weaknesses• Degrades update performance
Relational Database Theory

• De-normalization– De-normalization means combining two
(or more) tables• Usually done when tables are
frequently joined– De-normalization (joining two tables)
depends on usage• Depends on how applications and
users access the data
Relational Database Theory

• De-normalization is done to improve performance
– Tailors data structures for one specific application’s use
– Improves performance of one type of access at expense of others
Relational Database Theory

Relational Database Theory
• De-normalization Trade-Offs
Normalization De-normalization
Eliminates update anomalies Improves performance for specific application(s)
Minimizes data redundancy
Supports simpler logic
Provides application-independent database design
Encourages sharing of data

• When to De-Normalize– This is EVIL, Do Not Do…– When does de-normalization have
minimal impact?• Data is accessed primarily on a
read-only basis• Data is accessed primarily by one
application
Relational Database Theory

• When to de-normalize
– After database design is done and tables are normalized to 3NF
– After clustering related tables in the same logical container
– After considering trade-offs and usage of data
Relational Database Theory

• Alternatives to de-normalization– Physical placement of data
• Use of container• Can improve performance without
impacting logical design– Selective hardware upgrades
• More main memory, expanded storage, cache storage devices
Relational Database Theory

• Fragmentation – Better alternative to de-normalization– Means breaking one table into two (or
more) tables• Usually done when one table is very
large• Or groups of user almost exclusively
access a subset of data in a table
Relational Database Theory

• Fragmentation can be based on selection or projection– Must be able to reconstruct the
original table – by union or join– Primary key column(s) must be
included in all vertical fragments• Disadvantage is that the DBA must be
aware of all the fragmented tables
Relational Database Theory

• Physical Design Review
Relational Database Theory

Relational Database Theory
• Physical Database Design– Goals
• Improve performance–By minimizing disk I/O
• Improving management of the data
–By grouping tables that can be managed as a group

• Indexing: Strengths and Weaknesses– Strengths
• Improves performance on retrieval of data
• Can be built or dropped at any time• Usage is transparent to the user
– Weaknesses• Degrades update performance
Relational Database Theory
• Questions?
Relational Database Theory


















