
ISEB Course Study
93
A foundation Course in Software Testing Module A: Fundamentals of Testing : 1. Why is T esting Necessary Testing is necessary because the existence of faults in software is inevitable. Beyond fault-detection, the modern view of testing holds that fault-prevention (e.g. early fault detection/removal from requireme nts, designs etc. through static tests) is at least as important as detecting faults in software by executing dynamic tests. 1.1. What a re Er rors, faults, failures, and Reliability 1.1.1.An Error is… A human action producing an incorrect result The error is the activity undertaken by an analyst, designer, develo per, or tester whose outcome is a f ault in the deliverable being produced. When programmers make errors, they introduce faults to program code We usually think of programmers when we mention errors, but any person involved in the developmen t activities can make the error, which injects a fault into a deliverable. 1.1.2. A Fault is… A manifestation of human error in software A fault in software is caused by an unintentional action by someone building a deliverable. We normally think of programmers when we talk about software faults and human error. Human error causes faults in any project deliverable. Only faults in software cause software to fail. This is the most familiar situation. Faults may be caused by requirements, design or coding errors All software development activities are prone to error. Faults may occur in all software deliverables when they are first being written or when they are being maintained. Software faults are static - they are characteristics of the code they exist in When we test software, it is easy to believe that the faults in the software move. Software faults are static. Once injected into the software, they will remain there until exposed by a test and fixed. 1.1.3.A failure is… A deviation of the software from its expected delivery or service Software fails when it behaves in a different way that we expect or require. If we use the software properly and enter data correctly into the software but it behaves in an unexpected way, we say it fails. Software faults cause software failures when the program is executed with a set of inputs that expose the fault. A failure occurs when software does the 'wrong' thing We can say that if the software does the wrong thing, then the software has failed. This is a judgemen t made by the user or tester. You cannot tell whether software fails unless you know how the software is meant to behave. This might be explicitly stated in requirements or you might have a sensible expectation that the software should not 'crash'. 1.1.4.Reliability is… The probability that software will not cause the failure of a system for a specified time under specified conditions It is usually easier to consider reliability from the point of view of a poor product. One could say that an unreliable product fails often and without warning and lets its users down. However, this is an incomplete view. If a product fails regularly, but the users are unaffected, the product may still be deemed reliable. If a product fails only very rarely, but it fails without warning and brings catastrophe, then it might be deemed unreliable. Software with faults may be reliable, if the faults are in code that is rarely used If software has faults it might be reliable because the faulty parts of the software are rarely or never used - so it does not fail. A lega cy system may have hundreds or t housand s of known faults, but these exist in parts of the s ystem of low criticality so the system may still be deemed reliable by its users. 1.2. Why do we te st? 1.2.1.Some informal reasons • To ensure that a system does what it is supposed to do • To assess the quality of a system • To demonstrate to the user that a system conforms to requirements • To learn what a system does or how it behaves. 1.2.2.A technicians view
Transcript of ISEB Course Study

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 1/93
A foundation Course in Software Testing
Module A: Fundamentals of Testing :
1. Why is Testing NecessaryTesting is necessary because the existence of faults in software is inevitable. Beyond fault-detection, the modern view of testingholds that fault-prevention (e.g. early fault detection/removal from requirements, designs etc. through static tests) is at least asmportant as detecting faults in software by executing dynamic tests.
1.1. What are Errors, faults, failures, and Reliability
1.1.1.An Error is…
A human action producing an incorrect result The error is the activity undertaken by an analyst, designer, developer, or tester whose outcome is a fault in thedeliverable being produced.
When programmers make errors, they introduce faults to program codeWe usually think of programmers when we mention errors, but any person involved in the development activities canmake the error, which injects a fault into a deliverable.
1.1.2. A Fault is…
A manifestation of human error in softwareA fault in software is caused by an unintentional action by someone building a deliverable. We normally think of programmers when we talk about software faults and human error. Human error causes faults in any project deliverable.Only faults in software cause software to fail. This is the most familiar situation.
Faults may be caused by requirements, design or coding errorsAll software development activities are prone to error. Faults may occur in all software deliverables when they are firstbeing written or when they are being maintained.
Software faults are static - they are characteristics of the code they exist inWhen we test software, it is easy to believe that the faults in the software move. Software faults are static. Onceinjected into the software, they will remain there until exposed by a test and fixed.
1.1.3.A failure is…
A deviation of the software from its expected delivery or serviceSoftware fails when it behaves in a different way that we expect or require. If we use the software properly and enter data correctly into the software but it behaves in an unexpected way, we say it fails. Software faults cause softwarefailures when the program is executed with a set of inputs that expose the fault.A failure occurs when software does the 'wrong' thingWe can say that if the software does the wrong thing, then the software has failed. This is a judgement made by theuser or tester. You cannot tell whether software fails unless you know how the software is meant to behave. This mightbe explicitly stated in requirements or you might have a sensible expectation that the software should not 'crash'.
1.1.4.Reliability is…
The probability that software will not cause the failure of a system for a specified time under specified conditionsIt is usually easier to consider reliability from the point of view of a poor product. One could say that an unreliableproduct fails often and without warning and lets its users down. However, this is an incomplete view. If a product failsregularly, but the users are unaffected, the product may still be deemed reliable. If a product fails only very rarely, but itfails without warning and brings catastrophe, then it might be deemed unreliable.
Software with faults may be reliable, if the faults are in code that is rarely used If software has faults it might be reliable because the faulty parts of the software are rarely or never used - so it does notfail. A legacy system may have hundreds or thousands of known faults, but these exist in parts of the system of lowcriticality so the system may still be deemed reliable by its users.
1.2. Why do we test?1.2.1.Some informal reasons
• To ensure that a system does what it is supposed to do• To assess the quality of a system
• To demonstrate to the user that a system conforms to requirements
• To learn what a system does or how it behaves.
1.2.2.A technicians view

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 2/93
• To find programming mistakes
• To make sure the program doesn't crash the system
1.3. Error and how do they occur 1.3.1.Imprecise capture of requirementsImprecision in requirements are the most expensive faults we encounter. Imprecision takes the form of incompleteness,inconsistencies, lack of clarity, ambiguity etc. Faults in requirements are inevitable, however, because requirementsdefinition is a labour-intensive and error-prone process.
1.3.2.Users cannot express their requirements unambiguously
When a business analyst interviews a business user, it is common for the user to have difficulty expressingrequirements because their business is ambiguous. The normal daily workload of most people rarely fits into a perfectlyclear set of situations. Very often, people need to accommodate exceptions to business rules and base decisions on gutfeel and precedents which may be long standing (but undocumented) or make a decision 'on the fly'. Many of the rulesrequired are simply not defined, or documented anywhere.
1.3.3.Users cannot express their requirements completely It is unreasonable to expect the business user to be able to identify all requirements. Many of the detailed rules thatdefine what the system must do are not written down. They may vary across departments. Under any circumstance, theuser being interviewed may not have experience of all the situations within the scope of the system.
1.3.4.Developers do not fully understand the business.Few business analysts, and very few developers have direct experience of the business process that a new system is to
support. It is unreasonable to expect the business analyst to have enough skills to question the completeness or correctness of a requirement. Underpinning all this is the belief that users and analysts talk the same language in thefirst place, and can communicate.
1.4. Cost of a single faultWe know that all software has faults before we test it. Some faults have a catastrophic effect but we also know that not allfaults are disastrous and many are hardly noticeable.
1.4.1.Programmer errors may cause faults which are never noticed It is clear that not every fault in software is serious. We have all encountered problems with software that causes usgreat alarm or concern. But we have also encountered faults for which there is a workaround, or which are obvious, butof negligible importance. For example, a spelling mistake on a user screen, which our customers never see, which hasno effect on functionality may be deemed 'cosmetic'. Some cosmetic faults are trivial. However, in some circumstances,
cosmetic may also mean serious. What might our customers think if we spelt quality incorrectly on our Web site homepage?
1.4.2.If we are concerned about failures, we must test more.If a failure of a certain type would have serious consequences, we need to test the software to ensure it doesn't fail inthis way. The principle is that where the risk of software failure is high, we must apply more test effort. There is a straighttrade off between the cost of testing and the potential cost of failure.
1.5. Exhaustive testing1.5.1.Exhaustive testing of all program paths is usually impossibleExhaustive path testing would involve exercising the software through every possible program path. However, even'simple' programs have an extremely large number of paths. Every decision in code with two outcomes, effectivelydoubles the number of program paths. A 100-statement program might have twenty decisions in it so might have
1,048,576 paths. Such a program would rightly be regarded as trivial compared to real systems that have manythousand or millions of statements. Although the number of paths may not be infinite, we can never hope to test allpaths in real systems.
1.5.2.Exhaustive testing of all inputs is also impossibleIf we disregard the internals of the system and approach the testing from the point of view of all possible inputs andtesting these, we hit a similar barrier. We can never hope to test all the infinite number of inputs to real systems.
1.5.3.If we could do exhaustive testing, most tests would be duplicates that tell us nothingEven if we used a tool to execute millions of tests, we would expect that the majority of the tests would be duplicates andthey would prove nothing. Consequently, test case selection (or design) must focus on selecting the most important or useful tests from the infinite number possible.
1.6. Effectiveness and efficiency
A test that exercises the software in ways that we know will work proves nothingWe know that if we run the same test twice we learn very little second time round. If we know before we run a test, that it willalmost certainly work, we learn nothing. If we prepare a test that explores a new piece of functionality or a new situation, we

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 3/93
know that if the test passes we will learn something new - we have evidence that something works. If we test for faults incode and we try to find faults in many places, we increase our knowledge about the quality of the software. If we find faults,we can fix them. If we do not find faults, our confidence in the software increases.
Effective testsWhen we prepare a test, we should have some view on the type of faults we are trying to detect. If we postulate a fault andlook for that, it is likely we will be more effective.In other words, tests that are designed to catch specific faults are more likely to find faults and are therefore more effective.
Efficient testsIf we postulate a fault and prepare a test to detect that, we usually have a choice of tests. We should select the test that hasthe best chance of finding the fault. Sometimes, a single test could detect several faults at once. Efficient tests are thosethat have the best chance of detecting a fault.
1.7. Risks help us to identify what to testThe principle here is that we look for the most significant and likely risks and use these to identify and prioritise our tests.
We identify the most dangerous risks of the systemRisks drive our testing. The more typical risks are:
(1) Gaps in functionality may cost users their time. An obvious risk is that we may not have built all the required featuresof the system. Some gaps may not be important, but others may badly undermine the acceptability of the system. For example, if a system allows customer details to be created, but never amended, then this would be a serious problem, if
customers moved location regularly, for example.
(2) Poor design may make software hard to use. For some applications, ease of use is critical. For example, on a website used to take orders from household customers, we can be sure that few have had training in the use of the Net or more importantly, our web site. So, the web site MUST be easy to use.
(3) Incorrect calculations may cost us money. If we use software to calculate balances for customer bank accounts, our customers would be very sensitive to the problem of incorrect calculations. Consequently, tests of such software wouldbe very high in our priorities.
(4) Software failure may cost our customers money. If we write software and our customers use that software to, say,manage their own bank accounts then, again, they would be very sensitive to incorrect calculations so we should of course test such software thoroughly.
(5) Wrong software decision may cost a life. If we write software that manages the control surfaces of an airliner, wewould be sure to test such software as rigorously as we could as the consequences of failure could be loss of life andinjury.
We want to design tests to ensure we have eliminated or minimised these risks.
We use testing to address risk in two ways:
Firstly we aim to detect the faults that cause the risks to occur. If we can detect these faults, they can be fixed, retested andthe risk is eliminated or at least reduced.
Secondly, if we can measure the quality of the product by testing and fault detection we will have gained an understanding
of the risks of implementation, and be better able to decide whether to release the system or not.
1.8. Risks help us to determine how much we test
We can evaluate risks and prioritise themNormally, we would constitute a brainstorming meeting, attended by the business and technical experts. From this weidentify the main risks and prioritise them as to which are most likely to occur and which will have the greatest impact.What risks conceivably exist? These might be derived from past or current experience. Which are probable, so we reallyought to consider them?The business experts need to assess the potential impact of each risk in turn. The technical experts need to assess thepotential impact of each risk. If the technical risk can be translated into a business risk, the business expert can then assigna level of impact.For each risk in turn, we identify the tests that are most appropriate. That is, for each risk, we select system features and/or
test conditions that will demonstrate that a particular fault that causes the risk is not present or it exposes the fault so therisk can be reduced.
We never have enough time to test everything so...The inventory of risks are prioritised and used to steer decision making on the tests that are to be prepared.We test more where the risk of failure is higher. Tests that address the most important risks will be prioritised higher.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 4/93
We test less where the risk of failure is lower. Tests that do not address any identified risk or address low priority risks maybe de-scoped.Ultimately, the concept of risks helps us to ensure the most important tests are implemented in our limited budget. Only inthis way can we achieve a balanced test approach.
1.9. Testing and qualityTesting and quality are obviously closely related. Testing can measure quality of a product and indirectly, improve its quality.
Testing measures qualityTesting is a measurement activity. Testing gives us an insight into how closely the product meets it specification so itprovides an objective measure of its fitness for purpose.If we assess the rigour and number of tests and if we count the number of faults found, we can make an objectiveassessment of the quality of the system under test.
Testing improves qualityWhen we test, we aim to detect faults. If we do detect faults, then these can be fixed and the quality of the product can beimproved.
1.10.Testing and confidenceWe know that if we run tests to detect faults and we find faults, then the quality of the product can be improved. However, if we look for faults and do not find any, our confidence is increased.
If we buy a software package
Although our software supplier may be reputable and have a good test process, we would normally assume that the productworks, but we would always test the product to give us confidence that we really are buying a good product.We may believe that a package works, but a test gives us the confidence that it will work.
When we buy a car, cooker, off-the-peg suitWhen we buy mass produced goods, we normally assume that they work, because the product has probably been tested inthe factory. For example, a new car should work, but before we buy we would always give the car an inspection, a test driveand ask questions about the car's specification - just to make sure it would be suitable.Essentially, we assume that mass produced goods work, but we need to establish whether they will work for us.
When we buy a kitchen, haircut, bespoke suitFor some products, we are involved in the requirements process. If we had a kitchen designed we know that although wewere involved in the requirements, there are always some misunderstandings, some problems due to the imperfections of
the materials and our location and the workmanship of the supplier. So, we would wish to be kept closely informed of progress and monitor the quality of the work throughout.To recap, if we were involved in specifying or influencing the requirements, we need to test.
1.11.Testing and contractual requirementsTesting is normally a key activity that takes place as part of the contractual arrangement between the supplier and user of software. Acceptance test arrangements are critical and are often defined in their own clause in the contract. Acceptancetest dates represent a critical milestone and have two purposes: to protect the customer from poor products and to providethe supplier with the necessary evidence that they have completed their side of the bargain. Large sums of money maydepend on the successful completion of acceptance tests.
• When we buy custom-built software, a contract will usually state
o the requirements for the software
o the price of the software
o the delivery schedule and acceptance process• We don't pay the supplier until we have received and acceptance tested the software
• Acceptance tests help to determine whether the supplier has met the requirements.
1.12.Testing and other requirementsSoftware requirements may be imposed:
There are other important reasons why testing may figure prominently in a project plan.
Some industries, for example, financial services, are heavily regulated and the regulator may impose rigorous conditions onthe acceptability of systems used to support an organisation's activities.
Some industries may self-regulate, others may be governed by the law of the land.
The Millennium bug is an obvious example of a situation where customers may insist that a supplier's product is compliantin some way, and may insist on conducting tests of their own.
For some software, e.g., safety-critical, the type and amount of testing, and the test process itself, may be defined byindustry standards.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 5/93
On almost all development or migration projects, we need to provide evidence that a software product is compliant in oneway or another. It is, by and large, the test records that provide that evidence. When project files are audited, the mostreliable evidence that supports the proposition that software meets its requirements is derived from test records.
1.13.Types of faults in a system
Fault Type %
Requirements 8.1
Features and functionality 16.2
Structural Bugs 25.2
Data 22.4
Implementation and Coding 9.9
Integration 9.0
System, SoftwareArchitecture
1.7
Test Definition andExecution
2.8
Other, Unspecified 4.7
This table is derived from Beizer's Software TestTechniques book. It demonstrates the relativefrequency of faults in software. Around 25% of
bugs are due to 'structure'. These are normallywrong or imprecise decisions made in code. Oftenprogrammers concentrate on these. There aresignificant percentages of other types. Mostnotable is that 8% are requirements faults. Weknow that these are potentially the mostexpensive because they could cost more than therest of the faults combined.The value of categorising faults is that it helps usto focus our testing effort where it is mostimportant. We should have distinct test activitiesthat address the problems of poor requirements,structure, integration etc. In this way, we will have
a more effective and efficient test regime.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 6/93
2. Cost and Economics of Testing
2.1. Life Cycle costs of testing
Whole Lifecycle
Initial Development(20%)
Maintenance (80%)
Testing50%
Testing 75%
Testing = 75% of the whole lifecycle cost.
The split of costs described in the table is a great generalisation. Suffice to say, that the costs of testing in the majorityof commercial system development is between 40 and 60%. This includes all testing such as reviews, inspections andwalkthroughs, programmer and private testing as well as more visible system and acceptance tests. The percentagemay be more (or less) in your environment, but the important issue is that the cost of testing is very significant.
Once deployed in production, most systems have a lifespan of several years and undergo repeated maintenance.Maintenance in many environments could be considered to be an extended development process. The significance of testing increases dramatically, because changing existing software is error-prone and difficult, so testing to explore thebehaviour of existing software and the potential impact of changes takes very much longer. In higher integrityenvironments, regression testing may dominate the budget.
The consequence of all this is that over the entire life of a product, testing costs may dominate all development costs.
2.2. Economics of testingThe trick is to do the right amount of the right kind of testing.
Too much testing is a waste of moneyDoing more testing than is appropriate is expensive and likely to waste money because we are probably duplicating effort.
Too little is costlyDoing too little testing is costly, because we will leave faults in the software that may cost our business users dearly. Thecost of the faults may cost more than the testing effort that could have removed them.
Even worse is the wrong kind of testing
Not only do we waste money by doing too much testing in some areas, by doing too little in other areas, we might missfaults that could cost us our business.
2.3. Influences on the economics of testingHow much does testing cost? If we are to fit the right amount of testing into our development budget, we need to know whatinfluences these costs.
Degree of risk to be addressedObviously, if the risk of failure is high, we are more likely to spend more time testing. We would spend little time testing amacro which helped work out car mileage for expenses. We might check the results of a single test and think "that soundsabout right". If we were to test software upon which our life depended for example, an aeroplane control system, we aremuch more likely to commit a lot of time to testing to ensure it works correctly.
Efficiency of the test processLike all development activities, there are efficient and inefficient ways to perform tasks. Efficient tests are those whichexercise all the diverse features of the software in a large variety of situations. If each test is unique, it is likely to be a veryefficient test. If we simply hire people to play with some software, if we don't give them guidance and don't adopt asystematic approach, it is unlikely that we will cover all the software or situations we need to without hiring a large number of people to run tests. This is likely to be very inefficient and expensive.
Level of automationMany test activities are repetitive and simple. Test execution is particularly prone to automation by a suitable tool. Using atool, tests can be run faster, more reliably and cheaper than people can ever run them.Skill of the personnelSkilled testers adopt systematic approaches to organisation, planning, preparation and execution of tests. Unskilled testersare disorganised, ineffective and inefficient. And expensive too.
The target quality required.If quality is defined as 'fitness for purpose', we test to demonstrate that software meets the needs of its users and is fit for purpose. If we must be certain that software works in every way defined in the requirements, we will probably need toprepare many more tests to explore every piece of defined functionality in very detailed ways.
2.4. How much Testing is enough?

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 7/93
There are an infinite number of tests we could apply and software is never perfectWe know that it is impossible (or at least impractical) to plan and execute all possible tests. We also know that software cannever be expected to be perfectly fault-free (even after testing). If 'enough' testing were defined as 'when all the faults havebeen detected', we obviously have a problem - we can never do 'enough'.
So how much testing is enough?So is it sensible to talk about 'enough' testing?
Objective coverage measures can be used:There are objective measures of coverage (targets) that we can arbitrarily set, and meet. These are normally based on thetraditional test design techniques (see later).Test design techniques give an objective target. The test design and measurement techniques set out coverage items andthen tests can be designed and measured against these. Using these techniques, arbitrary targets can be set and met.
standards may impose a level of testingSome industries have industry specific standards. DO-178b is a standard for airborne software, and mandates stringent testcoverage targets and measures.
But all too often, time is the limiting factor The problem is that for all but the most critical developments, even the least stringent test techniques may generate manymore tests than are possible or acceptable within the project budget available. In many cases, testing is time limited.Ultimately, even in the highest integrity environments, time limits what testing can be done.
We may have to rely on a consensus view to ensure we do at least the most important tests. Often the test measurementtechniques give us an objective 'benchmark', but possibly, there will be an impractical number of tests, so we usually needto arrive at an acceptable level of testing by consensus. It is an important role for the tester to provide enough informationon risks and the tests that address these risks so that the business and technical experts can understand the value of doingsome tests while understanding the risks of not doing other tests. In this way, we arrive at a balanced test approach.
2.5. Where are the bugs?
Of course, if we knew that, we could fix them and go home!What a silly question! If we knew where the bugs were, we could simply fix each one in turn and perfect the system. Wecan't say where any individual fault is, but we can make some observations on, say a macroscopic level.
Experience tells us…Experience tells us a number of things about bugs.
Bugs are sociable! - they tend to cluster Bugs are sociable, they tend to cluster. Suppose you were invited into the kitchen in a restaurant. While you are there, alarge cockroach scurries across the floor and the chef stamps on it and kills it saying "I got the bug". Would you still want toeat there? Probably not. When you see a bug in this context we say "it's infested". It's the same with software faults.Experience tells us that bugs tend to cluster, and the best place to find the next bug is in the vicinity of the last one found.some parts of the system will be relatively bug-freeOff the shelf components are likely to have been tested thoroughly and used in many other projects. Bugs found in thesecomponents in production have probably been reported and corrected. The same applies to legacy system code that isbeing reused in a new project.
Bug fixing and maintenance are error-prone - 50% of changes cause other faults.Bug fixing and maintenance are error-prone - 50% of changes cause other faults. Have you ever experienced the 'Fridaynight fix' that goes wrong? All too often, minor changes can disrupt software that works. Tracing the potential impact of changes to existing software is extremely difficult. Before testing, there is a 50% chance of a change causing a problem (aregression) elsewhere in existing software. Maintenance and bug-fixing are error-prone activities.The principle here is that faults do not uniformly distribute themselves through software. Because of this, our test activitiesshould vary across the software, to make the best use of tester's time.
2.6. What about the bugs we can't find?If not in the business critical parts of the system - would the users care?If we've tested the business critical parts of the software, we can say that the bugs that get through are less likely to be of great concern to the users.
If not in the system critical parts of the system - should be low impactIf we've tested the technically critical parts of the software, we can say that the bugs that get through are less likely to causetechnical failures, so perhaps there's no issue there either. Faults should be of low impact.
If they are in the critical parts of the system

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 8/93
The bugs remaining in the critical part of the system should be few and far between. If bugs do get through and are in thecritical parts of the software, at least we can say that this is the least likely situation as we will have eliminated the vastmajority of such problems.Such bugs should be very scarce and obscure.
2.7. Balancing cost and risk
Can always do more testing - there is no upper limitEven for the simplest systems, we know that there are an infinite number of tests possible. There is no upper limit on thenumber of tests we could run.
Ultimately, time and cost limit what we can doIt is obvious we have to limit the amount of testing because our time and money is limited. So we must look for a balancebetween the cost of doing testing and the potential or actual risks of not testing.
Need to balance:We need to balance the cost of doing testing against the potential cost of risk.It is reasonably easy to set a cost or time limit for the testing. The difficult part is balancing this cost against a risk. Thepotential impact of certain risks may be catastrophic and totally unacceptable at any cost. However, we really need to take aview on how likely the risks are. Some catastrophic failures may be very improbable. Some minor failures may be verycommon but be just as serious if they happen too often. In either case, a judgement on how much testing is appropriatemust be made.
2.8. ScalabilityScalability in the context of risk and testing relates to how we do the right amount of the right kind of testing. Not all systemscan or should be tested as thoroughly as is technically possible.Not every system is safety-critical. In fact the majority of systems support relatively low-criticality business processes. Theprinciple must be that the amount of testing must be appropriate to the risks of failure in the system when used inproduction.
Not all systems, sub-systems or programs require the same amount of testingIt is obviously essential that testing is thorough when we are dealing with safety critical software. We must obviously do asmuch as possible. But low criticality systems need testing too, but how much testing is reasonable in this circumstance? Theright amount of testing needs to be determined by consensus. Will the planned test demonstrate to the satisfaction of themain stakeholders that the software meets its specification, that it is fault free?
Standards and procedures have to be scalable depending onThe risks, timescales and cost, and the quality required govern the amount and type of testing that should be done.Standards and procedures, therefore, must be scalable depending on these factors.Our test approach may be unique to today's project, but we normally have to reuse standard procedures for test planning,design and documentation. Within your organisation, there may be a single methodology for all system development, but itis becoming more common for companies to adopt flexible development methodologies to accommodate the variety inproject scale, criticality and technology.It is less common for those organisations to have flexible test strategies that allow the tester to scale the testing anddocumentation in a way that is consistent with the project profile. A key issue in assessing the usefulness of a test strategyis its flexibility and the way it copes with the variety in software projects.The principle means by which we can scale the amount of testing is to adopt some mechanism by which we can measurecoverage. We select a coverage measure to define a coverage target and to measure the amount of testing done againstthat target to give us an objective measure of thoroughness and progress.
Fundamental Test Process :
3. Testing Process3.1. What is a test?A test is a controlled exercise involving:
What is a test? Do you remember the biology or physics classes you took when you were 13 or 14? You were probablytaught the scientific method where you have a hypothesis, and to demonstrate the hypothesis is true (or not) you set up anexperiment with a control and a method for executing a test in a controlled environment.
Testing is similar to the controlled experiment. (You might call your test environment and work area a test 'lab'). Testing is a
bit like the experimental method for software.
You have an object under test that might be a piece of software, a document or a test plan.
The test environment is defined and controlled.
You define and prepare the inputs - what we’re going to apply to the software under test.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 9/93
You also have a hypothesis, a definition of the expected results. So, that’s kind of the absolute fundamentals of what a testit. You need those four things.
When a test is performed you get
Have you ever been asked to test without requirements or asked to test without having any software? It's not very easy todo is it?
When you run a test, you get an actual outcome. The outcome is normally some change of state of the system under testand outputs (the result). Whatever happens as a result of the test must be compared with the expected outcome (your hypothesis). If the actual outcome matches the expected outcome, you hypothesis is proven. That is what a test is.
3.2. Expected results
When we run a test, we must have an expected result derived from the baselineJust like a controlled experiment, where a hypothesis must be proposed in advance of the experiment taking place, whenyou run a test, there must be an expected outcome defined beforehand. If you don't have an expected result, there is a riskthat the software does what it does and because you have nothing to compare its behaviour to, you may assume that thesoftware works correctly. If you don’t have an expected result at all, you have no way of saying whether the software iscorrect or incorrect because you have nothing to compare the software's behaviour with.Boris Beizer (ref) suggests that if you watch an eight-year old play pool – they put the cue ball on the table; they address thecue ball, hit it as hard as they can, and if a ball goes in the pocket, the kid will say, "I meant that". Does that sound familiar?
What does a professional pool player do? A pro will say, "xxx ball in the yyy pocket". They address the cue ball, hit it as hardas they can, and if it goes in, they will say, "I meant that" and you believe them.It’s the same with testing. A kiddie tester will run some tests and say “that looks okay" or "that sounds right…”, but there willno comparison, no notion of comparison with an expected result - there is no hypothesis. Too often, we are expected to testwithout a requirement or an expected result. You could call it 'exploratory testing' but strictly, it is not testing at all.
An actual result either matches or does not match the expected resultWhat we are actually looking for is differences between our expected result and the actual result.
If there is a difference, there may be a fault in the software and we should investigate.If we see a difference, the software may have failed, and that is how we are going to infer the existence of faults in thesoftware.
3.3. What are the test activities?
Testing includes:It is important to recognise that testing is not just the act of running tests. What are the testing activities then?Testing obviously includes the planning and scoping of the test and this involves working out what you’re going to do in thetest - the test objectives.
Specification and preparation of test materials delivers the executable test itself. This involves working out test conditions,cases, and creating test data, expected results and scripts themselves.
Test execution involves actually running the test itself.Part of test execution is results recording. We keep records of actual test outcomes.Finally, throughout test execution, we are continually checking for whether we have met our coverage target, our completion
criteria.
The object under test need not be machine executable.The other key point to be made here is that testing, as defined in this course, covers all activities for static and dynamictesting. We include inspections, reviews, walkthrough activities so static tests are included here too. We'll go through thetypical test activities in overview only.
3.4. Test planning
How the test strategy will be implementedTest planning comes after test strategy. Whereas a strategy would cover a complete project lifecycle, a test plan wouldnormally cover a single test stage, for example system testing. Test planning normally involves deciding what will be doneaccording to the test strategy but also should say how we’re going to do things differently from that strategy. The plan must
state what will be adopted and what will be adapted from the strategy.
Identifies, at a high level, the scope, approach and dependenciesWhen we are defining the testing to be done – we identify the components to be tested. Whether it is a program, a sub-system, a complete system, an interfacing system, you may need additional infrastructure. If we’re testing a singlecomponent, we may need to have stubs and drivers and other scaffolding, other material in place to help us on a test. Thisis the basic scoping information defined in the plan.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 10/93
Having identified what is to be tested, we would normally specify an approach to be taken for test design. We could say thattesting is going to be done by users, left to themselves (a possible, but not very sophisticated approach) – or that formal testdesign techniques will be used to identify test cases and work that way. Finally, the approach should describe how testingwill be deemed complete. Completion criteria (often described as exit or acceptance criteria) state how management can judge that the testing is completed. Very briefly, that’s what planning is about.
3.5. Test specification
Test inventory (logical test design)With specification we are concerned with identifying, at the next level down from planning, the features of a system to betested – described by the requirements that we would like to cover. For each feature, we would normally identify theconditions to test by using a test design technique. Tests are designed in this way to achieve the acceptance criteria. Whenwe design the test, select the features to test, then identify test conditions, as we do this, we build up an inventory of testconditions and using the features and conditions inventory we can have enough detail to say that we've covered features,and exercised those features adequately.As we build up the inventory of test conditions, we might, for example find that there are 100 test conditions to exercise inour test. From the test inventory, we might estimate how long it will take to complete the test and execute it. It may be thatwe haven’t got enough time. The project manager says, "you’d like to do 100 tests, but we’ve only got time to do 60". So,part of the process of test specification must be to prioritise test conditions. We might go through the test inventory and labelfeatures and test conditions high, medium and low priority. So, test specification generates a prioritised inventory of testconditions. Because we know that when we design a test, we may not have time to complete the test, prioritisation is alwayspart of specification.
Test preparation (test implementation)From the inventory, we can expand that into the test scripts, the procedures, and the materials that we’re going to use todrive the testing itself. From the sequence of test steps and conditions, we can identify requirements for test data in thedatabase and perhaps initial conditions or other environmental set-up. From the defined input data for the test cases we canthen predict expected results. Test specification ends with the delivery of test scripts, including input data and expectedresults.
3.6. Test execution and recording
Tests follows the scripts, as definedWe go to the trouble of creating test scripts for the sole purpose of executing the test, and we should follow test scriptsprecisely. The intention is that we don’t deviate from the test script because all the decisions have been made up front.
Verify that actual results meet expected resultsDuring test execution, we verify that actual results match the expected results.
Log test executionAs we do this, we log progress – test script passes, failures, and we raise incident reports for failures.
3.7. Test checking for completionThe test process as defined in BS7925-2 – the standard for component testing – has been nominated as the standardprocess that tests should follow. This is reasonable for most purposes, as it is fairly high-level.
The slight problem with it is that there is a notion in the standard process that every time you run a test, you must check tosee whether you have met the completion criteria. With component level tests, this works fine, but with system testing itdoesn’t work that way. You don’t want to have to say, “have I finished yet?” after every test case, because it doesn’t work
that way.In the standard process, there is a stage called Test Checking for Completion. It is during this activity that we checkwhether we have met our completion criteria.
Completion criteria vary with different test stages. In system and acceptance testing, we tend to require that the test planhas been completed without a failure. With component testing, we may be more driven by the coverage target, and we mayhave to create more and more tests to achieve our target.
• Objective, measurable criteria for test completion, for example
o All tests run successfully
o All faults found are fixed and re-tested
o Coverage target (set and) met
o Time (or cost) limit exceeded
• Coverage items defined in terms of
o Requirements, conditions, business transactions
o Code statements, branches.
Often, time pressure forces a decision to stop testing. Often, development slips and testing is ‘squeezed’ to ensure atimely delivery into production. This is a compromise but it may be that some faults are acceptable. When time runs outfor testing, the decision to continue testing or to release the system forces a dilemma on the project. “Should we releasethe system early (on time), with faults, or not?” It is likely that if time runs out you may be left with the fact that some

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 11/93
tests have failures and are still outstanding. Some tests you may not have run yet. So it is common that the completioncriteria are compromised.
If you do finish all of your testing and there is still time leftover, you might choose to write some more tests, but this isn’tvery likely. If you do run out of time, there is the third option: you could release the system, but continue testing to theend of the plan. If you find faults after release, you can fix them in the next package. You are taking a risk but there maybe good reasons for doing so. However, clear-cut as the textbooks say completion criteria are, it’s not usually as clean.Only in high-integrity environments does testing continue until the completion criteria are met.
• Under time pressure in low integrity systems
o Some faults may be acceptable (for this release)
o Some tests may not be run at all• If there are no tests left, but there is still time
o Maybe some additional tests could be run
• You may decide to release the software now, but testing could continue.
3.8. Coverage
What we use to quantify testingTesting is open ended - we can never be absolutely sure we have done the right amount, so we need at least to be able toset objective targets for the amount of testing to measure our progress against. Coverage is the term for the objectivemeasures we use to define a target for the amount of testing required, as well as how we measure progress against thattarget.
Defines an objective target for the amount of testing to performWe select coverage measure to help us define an objective target for the amount of testing.
Measures completeness or thoroughnessAs we prepare or execute tests, we can measure progress against that target to determine how complete or thorough our testing has been.
Drives the creation of tests to achieve a coverage targetThe coverage target is usually based on some model of the requirements or the software under test. The target sets outrequired number of coverage items to be achieved. Most coverage measures give us a systematic definition of the way wemust design or select tests, so we can use the coverage target and measure as a guide for test design. If we keep creatingtests until the target is met, then we know the tests constitute a thorough and complete set of tests.
Quantifies the amount of testing to make estimation easier.The other benefit of having objective coverage measures is that they generate low-level items of work that can haveestimated effort assigned to them. Using coverage measures to steer the testing means we can adopt reasonable bottom-up estimation methods, at least for test design and implementation.
3.9. Coverage definitionsThe good thing about coverage definitions are that we can often reduce the difficult decision of how much testing isappropriate to a selection of test coverage measures. Rather than say we will do a lot of testing, we can reduce an un-quantifiable statement to a definition of the coverage measures to be used.For example, we can say that we will test a certain component by covering all branches in the code and all boundary valuesderived from the specification. This is a more objective target that is quantifiable.Coverage targets and measures are usually expressed as percentages. 100% coverage is achieved when all coverageitems are exercised in a test.
Coverage measures - a model or method used to quantify testing (e.g. decision coverage)Coverage measures are based on models of the software. The models represent an abstraction of the software or itsspecification. The model defines a technique for selecting test cases that are repeatable and consistent and can be used bytesters across all application areas.
Coverage item -the unit of measurement (a decision)Based on the coverage model, the fundamental unit of coverage, called a coverage item, can be derived. From thedefinition of the coverage item, a comprehensive set of test cases can be derived from the specification (functional testcases) or from the code (structural test cases).
Functional techniquesFunctional test techniques are those that use the specification or requirements for software to derive test cases. Examplesof functional test techniques are equivalence partitioning, boundary value analysis and state transitions.
Structural techniques.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 12/93
Structural test techniques are those that use the implementation or structure of the built software to derive test cases.Examples of structural test techniques are statement testing, branch testing, linear code sequence and jump (LCSAJ)testing.
3.10.Structural coverageThere are over fifty test techniques that are based on the structure of code. Most are appropriate to third generationlanguages such as COBOL, FORTRAN, C, BASIC etc. In practice, only a small number of techniques are widely used astools support is essential to measure coverage and make the techniques practical.
Statement, decision, LCSAJ...The most common (and simplest) structural techniques are statement and branch (also known as decision) coverage.
Measures and coverage targets based on the internal structure of the codeCoverage measures are based on the structure (the actual implementation) of the software itself. Statement coverage isbased on the executable source code statements themselves. The coverage item is an executable statement. 100%statement coverage requires that tests be prepared which, when executed, every executable statement is exercised.Decision testing depends on the decisions made in code. The coverage item is a single decision outcome and 100%decision coverage requires all decision outcomes to be covered.
Normal strategy:The usual approach to using structural test techniques is as follows:
(1) Use coverage tool to instrument code. A coverage tool is used to pre-process the software under test. The tool
inserts instrumentation code that has no effect on the functionality of the software under test, but logs the paths throughthe software when it is compiled and run through tests.
(2) Execute tests. Test cases are prepared using a functional technique (see later) and executed on the instrumentedsoftware under test.
(3) Use coverage tool to measure coverage. The coverage tool is then used to report on the actual coverage achievedduring the tests. Normally, less than 100% coverage is achieved. The tool identifies the coverage items (statements,branches etc.) not yet covered.
(4) Enhance test to achieve coverage target. Additional tests are prepared to exercise the coverage items not yetcovered.
(5) Stop testing when coverage target is met. When tests can be shown to have exercised all coverage items (100%coverage) no more tests need be created and run.
Note that 100% coverage may not be possible in all situations. Some software exists to trap exceptional or obscure error conditions and it may be very difficult to simulate such situations. Normally, this requires special attention or additionalscaffolding code to force the software to behave the way required. Often the 100% coverage requirement is relaxed to takeaccount of these anomalies.
Structural techniques are most often used in component or link test stages as some programming skills are required to usethem effectively.
3.11.Functional coverageThere are fewer functional test techniques than structural techniques. Functional techniques are based on the specification
or requirements for software. Functional test techniques do not depend on the code, so are appropriate for all software at allstages, regardless of the development technology.
Equivalence partitions, boundary values, decision tables etc.The most common (and simplest) functional test techniques are equivalence partitioning and boundary value analysis.Other techniques include decision tables, state transition testing.
Measures based on the external behaviour of the systemCoverage measures are based on the behaviours described in the external specification. Equivalence partitioning is basedon partitioning the inputs and outputs of a system and exercising each partition at least once to achieve coverage. Thecoverage item is an equivalence partition. 100% coverage requires that tests be prepared which, when executed, exerciseevery partition. Boundary values are the extreme values for each equivalence partition. Test cases for every identifiedboundary value are required to achieve 100% boundary value coverage.
Inventories of test cases based on functional techniquesThere are few tools that support functional test techniques. Those that do tend to require the specification or requirementsdocuments to be held in a structured manner or even using a formal notation. Most commonly, a specification is analysedand tables or inventories of logical test cases are built up and comprise a test specification to be used to prepare test data,scripts and expected results.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 13/93
The value of recording test cases in a tabular format is that it becomes easier to count and prioritise these test cases if thetester finds that too many are generated by the test technique.
Using a test technique to analyse a specification, we can be confident that we have covered all the system behaviours andthe full scope of functionality, at least as seen by the user. The techniques give us a powerful method to ensure we createcomprehensive tests which are consistent in their depth of coverage of the functionality, e.g., we have a measure of thecompleteness of our testing.
3.12.Completion, closure, exit, or acceptance criteriaAll the terms above represent criteria that we define before testing starts to help us to determine when to stop testing. Wenormally plan to complete testing within a pre-determined timescale, so that if things go to plan, we will stop preparing andexecuting tests when we achieve some coverage target. At least as often, however, we run out of time, and in thesecircumstances, it is only sensible to have some statement of intent to say what testing we should have completed before westop. The decision to stop testing or continue can then be made against some defined criteria, rather than by 'gut feel'.
Trigger to say: "we've done enough"The principle is that given there is no upper limit on how much testing we could do, we must define some objective andrational criteria that we can use to determine whether 'we've done enough'.
Objective, non-technical for managersManagement may be asked to define or at least approve exit criteria, so these criteria must be understandable bymanagers. For any test stage, there will tend to be multiple criteria that, in principle, must be met before the stage can end.There should always be at least one criterion that defines a test coverage target. There should also be a criterion that
defines a threshold beneath which the software will be deemed unacceptable. Criteria should be measurable, as it isinevitable that some comparison of the target with reality must be performed. Criteria should also be achievable, at least inprinciple. Criteria that can never be achieved are of little value.Some typical types of criterion which are used regularly are listed below.
3.13.Limitations of testingMany non-testers believe that testing is easy, that software can be tested until it is fault free, that faults are uniformly difficult(or easy) to detect. Testers must not only understand that there are limits to what can be achieved, but they must also beable to explain these limitations to their peers, developers, project manager and users.
Testing is a sampling activity, so can never prove 'mathematical' correctnessWe know that testers can only run a small proportion of all possible tests. Testing is really a 'sampling' activity. We only ever scratch the surface of software in our tests. Because of this we can never be 100% or mathematically certain that all faults
have been detected. It is a simple exercise to devise new fault in software which none of our current tests would detect. Inreality, faults appear in a pseudo-random way, so obscure or subtle faults are always likely to foil the best tester.
Always possible to create more tests so it is difficult to know when you are finishedEven when we believe we have done enough testing, it is relatively simple to think of additional tests that might enhance our test plan. Even though the test techniques give us a much more systematic way of designing comprehensive tests, there isnever any guarantee that such tests find all faults. Because of this testers are tempted into thinking that there is alwaysanother test to create and so are 'never satisfied' that enough testing has been done; that they never have enough time totest.Given these limitations, there are two paradoxes which can help us to understand how we might better develop good testsand the limitations of our 'art'.
Testing paradoxes:
(1) The best way to gain confidence in software is to try and break it. The only way we can become confident in our softwareis for us to try difficult, awkward and aggressive tests. These tests are most likely to detect faults. If they do detect faults, wecan fix the software and the quality of the software is increased. If they do not detect a fault, then our confidence in thesoftware is increased. Only if we try and break the software are we likely to get the required confidence.
(2) You don't know how good your testing is until maybe a year after release. A big problem for testers is that it is very difficult todetermine whether the quality or effectiveness of our testing is good or bad until after the software has gone into production. It ishe faults that are found in production by users that give us a complete picture of the total number of bugs that should havebeen found. Only when these bugs have been detected can we derive a view on our test effectiveness. The more bugs found inesting, compared to production, the better our testing has been. The difficulty is that we might not get the true picture until allproduction bugs have been found, and that might take years!
3.14.The Psychology of TestingTesters often find they are odds with their colleagues. It can be counter-productive if developers think the testers are ‘out toget them’ or ‘are sceptical, nit-picking pedants whose sole aim is to hold up the project’. Less professional managers canconvince testers that they do not add value or are a brake on progress.
3.14.1.Goal 1: make sure the system works – implicationsA successful test shows a system is working

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 14/93
Like all professional activities, it is essential that testers have a clear goal to work towards. Let’s consider one way of expressing the goal of a tester. ‘Making sure the system works’. If you asked a group of programmers ‘what is thepurpose of testing?’, they’d probably say something like, ‘to make sure that the program works according to thespecification’, or a variation on this theme. This is not an unreasonable or illogical goal, but there are significantimplications to be considered. If your job as a tester is to make sure that a system works, the implication is that asuccessful test shows that the system is working.
Finding a fault undermines the effectiveness of testersIf ‘making sure it works’ is our goal, it undermines the job of the testers because it is de-motivating. It seems that thebetter we are at finding faults, the farther we get from our goal, so it is de-motivating. It is also destructive becauseeveryone in the project is trying to move forward, but the testers continually hold the project back. Testers become theenemy of progress and we aren’t ‘team players’.Under pressure, if a tester wants to meet their goal, the easiest thing to do is to prepare ‘easy’ tests, simply to keep thepeace. The boss will then say ‘good job’.It is the wrong motivation because the incentive to a tester becomes don’t find faults, don’t rock the boat. If you’re noteffective at finding faults, you can’t have confidence in the product – you’ve never pushed it hard enough to haveconfidence. You won’t know whether the product will actually work.
Quality of released software will be low because:If ‘making sure it works’ is our goal, then the quality of the relased software will be low. Why?If our incentive is not to find faults, we are less likely to be effective at finding them. If it is less likely that we will findthem, the number of faults remaining after testing will be higher and the quality of the software will be lower. So, it’s badnews all around, having this goal.
3.14.2.Goal 2: locate faultsA successful test is one that locates a faultWhat is a better goal? A better goal is to locate faults, to be error-centric or focus on faults and use that motivation to dothe job. In this case, a successful test is one that finds a fault.
If finding faults is the testers' aim:If finding faults is your aim,that is, you see your job as a fault detective, this is a good motivation because when youlocate a fault, it is a sign that you are doing a good job. It is a positive motivation.It is constructive because when you find a fault, it won’t be found by the users of the product. The fault can be fixed andthe quality of the product can be improved.
Your incentive will now be to create really tough tests. If your goal is to find faults, and you try and don’t find any, then
you can be confident that the product is robust. Testers should have a mindset which says finding faults is the goal. If the purpose of testing is to find faults, when faults are found, it might upset a developer or two, but it will help the projectas a whole.
3.14.3.Tester mindsetSome years ago, there was a popular notion that testers should be put into “black teams”. Black teams were a popular idea in the late 1960s and early 1970s. If a successful test is one that locates a fault, the thinking went, then the testersshould celebrate finding faults, cheering even. Would you think this was a good idea if you were surrounded bydevelopers? Of course not.
There was an experiment some years ago in IBM. They set up a test team, who they called the 'black team' becausethese guys were just fiends. Their sole aim was to break software. Whatever was given to them to test, they were goingto find faults in it. They developed a whole mentality where they were the ‘bad guys’.
They dressed in black, with black, Stetson hats and long false moustaches all for fun. They really were the bad guys, just like the movies. They were very effective at finding faults in everyone’s work products, and had great fun, but theyupset everyone whose project they were involved in. They were most effective, but eventually were disbanded.Technically, it worked fine, but from the point of view of the organisation, it was counterproductive. The idea of a “blackteam” is cute, but keep it to yourself: it doesn’t help anyone if you crow when you find a fault in a programmer's code.You wouldn’t be happy if one of your colleagues tells you, your product is poor and laughs about it. It’s just not funny.The point to be made about all this is that the tester’s mindset is critical.
Testers must have a split personalityTesters need a split personality in a way. Perhaps you need to be more ‘mature’ than the developers. You have to beable to see a fault from both points of view.
Pedantic, sceptical, nit-picking to softwareSome years ago, we were asked to put a slide together, saying who makes the best testers, and we thought andthought, but eventually, all we could think of was, they’ve got to be pedantic and sceptical and a nitpicker. Now, if youcalled someone a pedant, a sceptic, and a nitpicker, they’d probably take an instant dislike to you. Most folk wouldregard such a description as abusive because these are personal attributes that we don’t particularly like in other people, do we? These are the attributes that we should wear, as a tester, when testing the product. When discussing

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 15/93
failures with developers however, we must be much more diplomatic. We must trust the developers, but we doubt theproduct.Most developers are great people and do their best, and we have to get on with them – we’re part of the same team, butwhen it comes to the product, we distrust and doubt it. But we don’t say this to their faces. We doubt the quality of everything until we’ve tested it. Nothing works, whatever “works” means, until we’ve tested it.
Impartial, advisory, constructive to developers:But we are impartial, advisory and constructive to developers. We are not against them, we are on the same team. Wehave to work with them, not against them. Because it is human nature to take a pride in their work and take criticism of their work personally, bear in mind this quote: ‘tread lightly, because you tread on their dreams’.If development slips and they are late, you can be assured that they’ve been put under a lot of pressure to deliver ontime and that they’re working very long hours, and working very hard. Whether they’re being effective is another question, but they’ve been working hard to deliver something to you on time to test. So, when you find the bug, youdon’t go up to them and say, this is a lot of rubbish – they are not going to be pleased. They are very emotionallyattached to their own work, as we all are with our own work, our own creation. You have to be very careful about howyou communicate problems with them. Be impartial; it is the product that is poor, not the person. You want to advisethem – here are the holes in the road, we don’t want you guys to fall into. And be constructive – this is how we can getout of this hole. Diplomatic but firm. No, it’s not a feature, it’s a bug.The other thing is, if the developer blames you for the bug being there – you know, you didn’t put the bug in there, didyou? Sometimes developers think that the bug wouldn’t be there if you didn’t test it. You know that psychology, ‘it wasn’tthere until you tested it’. You have to strike quite a delicate balance: you’ve got to be able to play both sides of thegame. In some ways, it’s like having to deal with a child. I don’t mean that developers are children, but you may bedealing blows to their emotions, so you have to be careful.
Retesting and Regression Testing:
3.15.Re-TestingA re-test is a test that, on the last occasion you ran it, the system failed and a fault was found, and now you’re repeating thatsame test to make sure that the fault has been properly corrected. This is called re-testing. We know that every test planwe’ve ever run has found faults in the past, so we must always expect and plan to do some re-testing.
Does your project manager plan optimistically? Some project managers always plan optimistically. They ask the testers:“how long is the testing going to take?”. To which the tester replies perhaps “four weeks if it goes as well as possible…”, andwhat happens is the tester suggest that, with things going perfectly well, maybe it takes a month, knowing that it should taketwice as long because things do go wrong, you do find faults, there are delays between finding a fault, fixing it, and re-testing. The project manager pounces on the ‘perfect situation’, and plans optimistically. Some project managers plan on the
basis of never finding faults, which is absolutely crazy. We must always expect to do some re-testing.• If we run a test that detects a fault we can get the fault corrected
• We then repeat the test to ensure the fault has been properly fixed
• This is called re-testing
• If we test to find faults, we must expect to find some faults so...
• We always expect to do some re-testing.
3.16.Regression testingRegression testing is different from re-testing. We know that when we change software to fix a fault, there’s a significantpossibility that we will break something else. Studies over many years reveal that the probability of introducing a new faultduring corrective maintenance is around 50%. The 50% probability relates to creating a new fault in the software beforetesting is done. Testing will reduce this figure dramatically, but it is unsafe and perhaps negligent not to test for theseunwanted side-effects.
• When software is fixed, it often happens that 'knock-on' effects occur
• We need to check that only the faulty code has changed
• 50% chance of regression faults
• Regression tests tell us whether new faults have been introduced
o i.e. whether the system still works after a change to the code or environment has been made
"Testing to ensure a change has not caused faults in unchanged parts of the system"A regression test is a check to make sure that when you make a fix to software the fix does not adversely affect other functionality.The big question, “is there an unforeseen impact elsewhere in the code?” needs to be answered. The need existsbecause fault-fixing is error-prone. It’s as simple as that. Regression tests tell you whether software that worked beforethe fix was made, still works. The last time that you ran a regression test, by definition, it did not find a fault; this time,
you’re going to run it again to make sure it still doesn’t expose a fault.A more formal definition of regression testing is – testing to ensure a change has not caused faults in unchanged partsof the system.
Not necessarily a separate stage

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 16/93
Some people regard regression testing as a separate stage, but it’s not a separate stage from system/acceptancetesting, for example, although a final stage in a system test might be a regression test. There is some regression testingat every test stage, right from component testing through to acceptance testing.
Regression testing most important during maintenance activitiesRegression testing is most important where you have a live production system requiring maintenance. When users arecommitted to using your software, the most serious problem the users encounter that is worse than having a bug in newcode (which they may not yet be dependent on), is having a bug in code that they’re using today and are dependent on.Users get most upset when you 'go backwards' - that is, a system that used to work, stops working. They may not mindlosing a few weeks because you’re late with a new delivery. They do mind if you screw up the system they trust and aredependent on at the moment.
Effective regression testing is almost always automated.Effective regression testing is almost always automated. Manual regression testing is boring, tedious and testers maketoo many errors themselves. If it's not automated, it is likely that the amount of regression testing being done isinadequate. More on tools later.
3.17.Selective regression tests
An entire test may be retained for subsequent use as a regression test packIt is possible that you may, on a system test say, keep the entire system test plan and run it in its entirety as a regressiontest.
This may be uneconomic or impracticalBut for most environments, keeping an entire system test for regression purposes is just too expensive. What normallyhappens is that the cost of maintaining a complete system test as a regression test pack is prohibitive. There will be somuch maintenance to do on it because no software is static. Software always requires change, so regular changes areinevitable. Most organisations choose to retain between 10% and 20% of a test plan as the regression test pack.
Regression tests should be selected to:Criteria for selecting these test might be for example, they exercise the most critical or the most complex functionality. Butalso, it might be what is easiest to automate. A regression test does not necessarily need to exercise only the mostimportant functionality. Many simple, lightweight regression tests might be just as valuable as a small number of verycomplex ones. If you have a GUI application, a regression test might just visit every window on the screen. A very simpletest indeed, but it gives you some confidence that the developers haven’t screwed up the product completely. This is quitean important consideration. Selecting a regression test is all very well, but if you’re not going to automate it, it’s not likely to
be run as often as you like.
3.18.Automating regression tests
Some might say that manual regression tests are a contradiction in termsManual regression testing is a contradiction in terms but regression tests are selected on the basis that they are perhaps themost stable parts of the software.
Regression tests are the most likely to be stable and run repeatedly so:The tests that are easiest to automate are the ones that don’t find the bugs because you’ve run them once to completion.The problem with tests that did find bugs is that they cannot be be automated so easily.The paradox of automated regression testing is that the tests that are easiest to automate are the tests that didn’t find faultsthe last time we ran them. So the tests we end up automating often aren't the best ones.
Stable tests/software are usually easiest to automate.Even if we do have a regression test pack, life can be pretty tough, because the cost of maintenance can become aconsiderable overhead. It’s another one of the paradoxes of testing. Regression testing is easy to automate in a stableenvironment, but we need to create regression tests because the environment isn’t stable.We don’t want to have to rebuild our regression test every time that a new version of software comes along. We want to justrun them, to flush out obvious inconsistencies within a system. The problem is that the reason we want to do regressiontesting is because there is constant change in our applications, which means that regression testing is hard, because wehave to maintain our regression test packs in parallel with the changing system.
3.19.Expected ResultsWe’ve already seen that the fundamental test process requires that an outcome (expected result) must be predicted beforethe test is run. Without an expected result the test cannot be interpreted as a pass or fail. Without some expectation of the
behaviour of a system, there is nothing to compare the actual behaviour with, so no decision on success or failure can bemade. This short section outlines the importance of baselines and expected results.
3.20.External specifications and baselines
Specifications, requirements etc. define what the software is required to do

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 17/93
As a tester, I’m going to look at a requirements or a design document and identify what I need to test, the features that I’mgoing to have to exercise, and the behaviour that should be exhibited when running under certain conditions. For eachcondition that I’m concerned with, I want an expected result so that I can say whether the system passes or fails the testwhen I run it. Usually, developers look at a design specification, and work out what must be built to deliver the requiredfunctionality. They take a view on what the required features are. Then, they need to understand the rules that the featuremust obey. Rules are normally defined as a series of conditions against which the feature must operate correctly, andexhibit the required behaviour. But what is the required behaviour? The developer infers the required behaviour from thedescription of the requirement and develops the program code from that.
Without requirements, developers cannot build, testers cannot testRequirements, design documents, functional specifications or program specs are all examples of baselines. They aredocuments that tell us what a software system is meant to do. Often, they vary in levels of detail, technical language or scope, and they are all used by developers and testers. Baselines (should) not only provide all the information required tobuild software system but also how to test it. That is, baselines provide the information for a tester to demonstrateunambiguously that a system does what is required.
Programmers need them to write the codeIt looks like the developer uses the baseline in a very similar way to the tester. They both look for features, then conditionsand finally a description of the required behaviour. In fact, the early development thought process is exactly the same for both. Some developers might say that they use use-cases and other object-oriented methods but this reflects a differentnotation for the same thing. Overall, it’s the same sequence of tasks. What does this mean? It means that withoutrequirements, developers cannot build software and testers cannot test. Getting the baseline right (and early) benefitseveryone in the development and test process. What about poor baselines? These tend to be a bigger problem for testers
than developers. Developers tend not to question baselines in the same way as testers. There are two mindsets at work butthe impact of poor baselines can be dramatic. Developers do question requirements but they tend to focus on issues suchas how easy (or difficult) it will be to build the features, what algorithms, system services, new techniques will be required?Without good statements of required behaviour developers can still write code because they are time-pressured into doingso and have time to question users personally or make assumptions.
Testers need them to:How do testers use specifications? First they identify the features to be tested and then, for each feature, the conditions (therules) to be obeyed. For every condition defined, there will usually be a different behaviour to be exhibited by the systemand this is inferred from the description of the requirement.Testers have no independent definition of the behaviour of a system other than the system itself, so they have nothing to‘test against’. By the time a system reaches system test, there is little time to recover the information required to plancomprehensive tests. The testers need them to identify the things that need testing and to compare test results with
requirements.
3.21.Baseline as an oracle for required behaviour
When we test we get an actual resultA baseline is a generic term for the document used to identify the features to test and expected results. Whether it’sacceptance, system, integration or component testing, there should be a baseline. The baseline says what the softwareshould do.
We compare results with requirements to determine whether a test has passedFrom the baseline, you get your expected results, and from the test, you have your actual results.
A baseline document describes how we require the system to behave
The baseline tells you what the product under test should do. That’s all the baseline is.
Sometimes the 'old system' tells us what to expect.In a conversion job, the baseline is the regression test. The baseline is where you get your expected results. The next pointto be made is the notion of an oracle. An oracle (with a lowercase “o”) is a kind of ‘font of all knowledge’. If you ask theoracle a question, it gives you the answer. If you need to know what software should do, you go back to the baseline, andthe baseline should tell you exactly what the software should do, in all circumstances. A test oracle tells you the answer tothe question, ‘what is the expected result?’. If you’re doing a conversion job (consider the Year 2000 work you may havedone), the old system gives you the oracle of what the new system must continue to do. You’re going to convert it withoutchanging any functionality. You must make it ‘compliant’ without changing the behaviour of the software.
3.22.Expected results
The concern about expected results is that we should define them before we run the tests. Otherwise, we’ll be tempted tosay that, whatever the system does when we test it, we’ll pass the result as correct. That’s the risk. Imagine that you’reunder pressure from the boss (‘don’t write tests…just do the testing…’). The pressure is immense, so it’s easier to not writeanything down, to not think what the results should be, to run some informal tests and pass them as correct. Expectedresults, (even when good baselines aren’t available) should always be documented.
• If we don't define expected result before we execute the test...

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 18/93
o A plausible, but erroneous, result may be interpreted as the correct result
o There may be a subconscious desire to see the software pass the test
• Expected results must be defined before test execution, derived from a baseline

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 19/93
4. Prioritisation of TestsWe’ve mentioned coverage before, and we need to go into a little bit more detail on coverage. Were you ever given enough timeo test? Probably not. So what happens when you do some initial work to specify a test and then estimate the effort required tocomplete the testing tasks? Normally, your estimates are too high, things need prioritisation and some tests will be ‘de-scoped’.This is entirely reasonable because we know that at some point the cost of testing must be balanced against the risk of release.
4.1. Test inventories, risk, and prioritisation
There is no limit to how much testing we could do, so we must prioritiseThe principle is that we must adopt a prioritisation scheme for selecting some tests above others. As we start from highestpriority and scan the tests in decreasing order of priority, there must be a point at which we reach the first test that is of toolow a priority to be done. All tests of a lower priority still are de-scoped.
How much testing should we do?Suppose we built an inventory of test cases and perhaps we had a total of a hundred tests. We might estimate from pastexperience that 100 tests will take 100 man days to complete. What does the Project Manager say? ‘You’ve only got 60days to do the job.’ You’d better prioritise the tests and lose 40 or so to stay within budget.Suppose you had reviewed the priority of all of the test cases with users and technical experts, and you could separate teststhat are in scope from those that are out of scope. As a tester, you might feel that the tests that were left in scope were justnot enough. But what could you do? How do you make a case for doing more testing? It won’t help to say to the boss, ‘thisisn’t enough’ - showing what is in the test plan will not convince. It is what is not in the test plan that will persuade the bossto reconsider.
If you can describe the risk associated with the tests that will not be done, it will be much easier to make your case for moretesting. In order to assess whether ‘the line’ has been drawn in the right place, you need to see what is above and below thethreshold.The message is therefore: always plan to do slightly more testing than there is time for to provide evidence of where thethreshold falls. Only in this way can you make a case for doing more testing.
We must use risk assessment to help us to prioritise.How can we associate a risk with a test? Is it possible to associate a risk with each test? As testers we must try - if we can’tassociate a risk with a test, then why bother with the test at all? So we must state clearly that if a feature fails in some way,the impact would be, perhaps a measurable or intangible cost associated. Or would the failure be cosmetic, and of noconsequence? Could we lose a customer? What is the (potential) cost of that?Project managers understand risk. Business users understand risk. They know what they don’t want to happen. Identifyingthe unpleasant consequences that could arise will help you to persuade management to allocate more resources.
Alternatively, the management may say, ‘yes, we understand the risks of not testing, but these are risks we must take’.So, instead of a risk being taken unconsciously, the risk is being taken consciously. The managers have taken a balanced judgement.
4.2. Test inventory and prioritisation
To measure progress effectively, we must define the scope of the testingTo measure progress effectively, we need to be able to define the scope of the testing in a form where coveragemeasurement can be applied. At the highest level, in system and acceptance test plans, we would normally define thefeatures of the system to be tested and the tests to be implemented which will give us confidence that faults have beeneliminated and the system has been thoroughly tested.
Inventory of tests enable us to prioritise AND estimate
Test inventories not only enable us to prioritise the tests to stay within budget, but they also enable us to estimate the effortrequired. Because inventories are documented in a tabular format, we can use the inventories to keep track of the testingthat has been planned, implemented and executed while referencing functional requirements at a level which the user andsystem experts can understand.
4.3. Prioritisation of the tests
Never have enough timeThe overriding reason why we prioritise is that we never have enough time, and the prioritisation process helps us to decidewhat is in and out of scope.
First principle: to make sure the most important tests are included in test plansSo, the first principle of prioritisation must be that we make sure that the most important tests are included in the test plans.
That’s pretty obvious.
Second principle: to make sure the most important tests are executedThe second principle is however, that we must make sure that the most important tests are run. If, when the test executionphase starts and it turns out that we do run out of time before the test plan is complete, we want to make sure that, if we doget squeezed, the most important tests, at least, have been run. So, we must ensure that the most important tests arescheduled early to ensure that they do get run.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 20/93
If tests reveal major problems, better find them early, to maximise time available to correct problems.There is also a most important benefit of running the most important tests first. If the most important tests reveal problemsearly on, you have the maximum amount of time to fix them and recover the project.
4.4. Most important tests
Most important tests are those that:What do we mean by the most important tests? The most important tests are those that address the most serious risks,exercise the most critical features and have the best chance of detecting faults.
Criteria for prioritising tests:There are many criteria that can be used to promote (or demote) tests. Here are the three categories we use most for prioritising requirements, for example. You could refine these three into lower level categories if you wish. The threecategories are critical, complex and error-prone. We use these to question requirements and assign a level of criticality. Inthe simplest case, if something is critical, complex or error-prone, it is deemed to be high priority in the tests.
4.5. Critical
When you ask a user which parts of the system are more critical than others, what would you say? ‘We’d like to prioritise thefeatures of the system, so it would help us if you could tell me which requirements are high-priority, the most critical’. Whatwould you expect them to say?‘All of our requirements are critical’. Why? Because they believe that when they de-prioritise something, it is going to get
pushed out, de-scoped, and they don’t want that to happen. They want everything they asked for so they are reluctant toprioritise. So, you have to explain why you’re going through this process because it is most important that you test the mostcritical parts of the software a bit more than those parts of the system that are less critical. The higher the criticality of afeature, the greater the risk, the greater the need to test it well.People will co-operate with you, once they realise what it is that you’re trying to achieve. If you can convince them thattesting is not uniform throughout the system, that some bits need more than others, you just want a steer. These are waysof identifying what is more important.
The features of the system that are fundamental to it's operationWe have to admit that criticality is in the eye of the beholder. Management may say that their management report is themost important thing, that the telesales agents are just the drones that capture data. Fine for managers’ egos, but thankfully,most managers do recognise that the important thing is to keep the operation going – they can usually give a good steer onwhat is important.
What parts of the system do the users really need to do their job?As a tester, you have to get beyond the response, ‘it’s all critical!’ You might ask, ‘which parts of the system do you really,really need?’ You have to get beyond this kind of knee-jerk reaction that everything is critical. You have to ask, ‘what isreally, really important?’
What components must work, otherwise the system is seriously undermined?Another way of putting it might be to ask, if parts of a system were not available, could the user still do their job? What partscould be lost, without fear of the business coming crashing down? Is there a way that you can articulate a question to usersthat allows you to get that information you need?
4.6. Complex
If you know an application reasonably well, then you will be able to say, for example, that these user screens are prettysimple, but the background or batch processes that do end-of-the-day processing are very complicated. Or perhaps that theuser-interface is very simple, apart from these half dozen screens that calculate premiums, because the functionality behindthose screens consists of a hundred thousand lines of code. Most testers and most users could work out which are the mostcomplex parts of system to be tested.
Aspects of the system which are recognised to be complexAre computer systems uniformly simple throughout? Certainly not. Are computer systems uniformly complex throughout?Not usually. Most systems have complex parts and less complex parts. If you think about one of your systems, could youidentify a complex, complicated or difficult to understand part of your system? Now, could you identify a relatively simplepart of the same system? Probably.
Undocumented, poorly documented
And what do we know about complexity in software? It means that it is difficult to get right. It tends to be error-prone.Complex could mean that it is just undocumented. If you can’t find anyone who knows how the software should work, how isthe developer going to get it right? Are the business rules so complicated that no one knows how they work? It’s not going tobe very easy to get right, is it?
Difficult to understand from business or system point of view

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 21/93
Perhaps there are areas of functionality that the users don’t understand. Perhaps you are dealing with a legacy system thatno-one has worked on continuously and kept pace with the rules that are implemented in the software. Perhaps the originaldeveloper of a system has left the company. Perhaps the systems was (or is) developed using methods which do notinvolve writing documentation?
Inadequate business or system knowledge.If there isn’t any business or technical knowledge available, this is a sure sign that it will be more complicated or difficult toget right. So it is error-prone.Can you think of any parts of your system that the developers hate changing? Most systems have a least favourite areawhere there’s a sign that says swamp! This is where the alligators live and it’s really dangerous.So the issue of complexity is a real issue and you know that if there are parts of the system that people don’t like to go near,requirements which the developers are really wary of taking on – you know that they’re going to make mistakes. So, youshould test more.
4.7. Error-proneThe third question is error-prone. There is of course a big overlap with complexity here – most complex software is error-prone. But sometimes, what appear to be simpler parts of a system may turn out to be error-prone.
Experience of difficulty in the pastIs there a part of one of your systems, where every time there is a release, there are problems in one area? If you have ahistory of problems in the past, history will tend to repeat itself. If you’re involved in a project to replace an existing system,where should your concerns be?
Existing system has history of problems in this areaWhere problems occurred in the old system, it is most likely that most of these problems will occur in the future on the newsystem. The developers may be using new technology, component-based, object-oriented or rapid application developmentmethods, but the essential difficulties in building reliable software systems are unchanged. Many of the problems of the pastwill recur. It has been said, that people who fail to learn from the failures in history are doomed to repeat them. It’s just thesame with software.
Difficult to specify, difficult to implement.You may not be directly involved in the development of requirements, specification or design document or the coding.However, by asking about the problems that have occurred in earlier phases of a project, you should gain some valuableinsights into where the difficulties and potential pitfalls lurk. Where there have been difficulties in eliciting requirements,specification and implementation, these are definitely areas that you should considered promoting in your test plans.A problem for you as a tester is that you may not have direct experience of these phases, so you must ask for assistance
from both the business side and the technicians. All testers need to take advice from the business and the technical experts.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 22/93
Module B: Testing Throughout the Software Life Cycle
5. Testing Through the LifecycleThe generally accepted proposition in software testing is that best practice is to test throughout the development lifecycle.deally, you should test early, in the middle, and at the end, not just at the end. Early testing is more likely to be tests of requirements, designs, and the techniques used are technical reviews, inspections and so on. We need to fit test activitieshroughout the lifecycle and this module considers the way that this should work. In doing this, we must discuss how both staticests (reviews etc.) and dynamic tests fit in.
5.1. Verification, validation, and testing (V,V& T)Verification, validation and testing (VV&T) are three terms that were linked some years ago as a way of describing thevarious test activities through the lifecycle. In commercial IT circles VV&T is considered a little old fashioned. However, inhigher integrity environments, VV&T are widely used terms so we must address these now.In this course, we consider testing to include all the activities used to find faults in documents and code and gain confidencethat a system is working. Of these activities, some are verification activities and the remainder are validation activities. V&Vare useful ways of looking at the test activities in that at nearly all stages of development, there should be some aspect of both happening to ensure software products are build ‘to spec’ and meet the needs of their customer.
VerificationThe principle of verification is this: verification checks that the product of a development phase meets its specification,whatever form that specification takes. More formally, verification implies that all conditions laid down at the start of adevelopment phase are met. This might include multiple baseline or reference documents such as standards, checklists or
templates.
Validation is really concerned with testing the final deliverable – a system, or a program – against user needs or requirements. Whether the requirements are formally documented or exist only as user expectations, validation activitiesaim to demonstrate that the software product meets these requirements and needs. Typically, the end-user requirementsare used as the baseline. An acceptance test is the most obvious validation activity.
Also defined as "did we build the system right?"Essentially, verification asks the following questions: ‘Did we build the system the way that we said we would?’When we component test, the component design is the baseline, and we test the code against the baseline.The user may have no knowledge of these designs or components - the user only sees the final system. If the test activity isnot based on the original business requirements of the system, the test activity is probably a verification activity.
Defined as: "determination of the correctness of the products of software development with respect to the user needs andrequirements"In other words, validation is the determination of the correctness of the products of a software development with respect tothe users' needs and requirements.
Verification activities are mainly (but not exclusively) the concern of the suppliers of the system.Verification tends to be more the concern of the supplier/developer of the software product, rather than the concern of theuser, at least up until system testing. A technician asks: did we build this product the way we specified?
"did we build the right system?"Validation is asking the question, 'Did we build the right system?'.Where the focus is entirely on verification, it is possible to successfully build the wrong system for users.Both verification and validation activities are necessary for a successful software product.
5.2. Ad hoc development
Pre mid-1970's development was more focused on "programs" than "systems"In the late sixties and early seventies, software development focused on distinct programs that performed specificprocessing roles.
Programming methods were primitiveTechniques and tools for managing large scale systems and their complexity did not exist, so functionality was usuallydecomposed into manageable chunks which skilled programmers could code. Characteristics of these developments were:
(1) Analysis, as a disciplined activity was missing.
(2) Analysis techniques were intuitive. ‘Design’ was a term used by programmers to describe their coding activity.
(3) Requirements were sketchy. Testing was not a distinct activity at all, but something done by programmers on an informalbasis.
(4) Programs were written without designs. The main consequence of this approach was that systems were very expensive,fault prone and very difficult to maintain.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 23/93
5.3. Structured methodologies
More complex systems and technologies demanded more structureDuring the seventies, it became apparent that the way that software had been built in the past would not work in the future.Projects in some business areas were becoming very large, the costs were skyrocketing, and the general view was thatthere should be a more engineering-based structure to the way that people built software.
Structured methods for programmingStructured methods, for programming, analysis and project management emerged and by the mid eighties, dominated alllarge-scale development activities. There were strict methods for programming, ways of constructing software that waseasier to maintain, and design criteria that people could apply and benefit from.
Structured systems analysis methodsThe requirements to the design process became structured in terms of a series of stages: requirements definition, analysis,high-level design, low-level design, program specification, and so on. There was a natural flow from high-level abstractdocuments down to concrete, particular technical documents and finally the code.
Relational database technologyDatabases continue to be the core of most large systems, and as relational systems emerged in the eighties and standardsfor SQL and related tools became mainstream, developers were released from many of the low-level data manipulationtasks in code.End-user tools and the promise of client/server architectures mean end users can query corporate databases with ease.
Project management discipline and toolsWhen software projects started to be organised into sequences of stages, each with defined deliverables, dependenciesand skills requirements, the tools and disciplines of traditional project management could then be used.
All combined to make up various "structured methodologies".Structured methods continue to be the preferred method for larger projects, even though analysis and design techniquesand development technologies are more object-based nowadays.
5.4. Development lifecycles
Various models of developmentThere are various development models, the main ones being:
Waterfall modelThe ‘Waterfall Approach’ to development, where development is broken up into a series of sequential stages, was theoriginal textbook method for large projects. There are several alternatives that have emerged in the last ten years or so.
Spiral modelThe Spiral model of development acknowledges the need for continuous change to systems as business change proceedsand that large developments never hit the target 100% first time round (if ever). The Spiral model regards the initialdevelopment of a system as simply the first lap around a circuit of development stages. Development never ‘stops’, in that acontinuous series of projects refine and enhance systems continuously.
Incremental prototypingIncremental prototyping is an approach that avoids taking big risks on big projects. The idea is to run a large project as a
series of small, incremental and low-risk projects. Large projects are very risky because by sheer volume, they becomecomplex. You have lots of people, lots of communication, mountains of paperwork, and difficulty. There are a number of difficulties associated with running a big project. So, this is a way of just carving up big projects into smaller projects. Theprobability of project failure is lowered and the consequence of project failure is lessened.
Rapid Application DevelopmentRapid Application Development or RAD, is about reducing our ambitions. In the past, it used to be that 80% of the projectbudget would go on the 20% of functionality that, perhaps, wasn’t that important – the loose ends, bells and whistles. So,the idea with RAD is that you try and spend 20% of the money but get 80% of the valuable functionality and leave it at that.You start the project with specific aims of achieving a maximum business benefit with the minimum delivery. This isachieved by ‘time-boxing’, limiting the amount of time that you’re going to spend on any phase and cutting down ondocumentation that, in theory, isn’t going to be useful anyway because it’s always out of date. In a way, RAD is a reaction tothe waterfall model, as the Waterfall model commits a project to spending much of its budget on activities that do not
enhance the customer’s perceived value for money.
Certain common stages:In all of the models of development, there are common stages: defining the system, and building the system.
5.5. Static testing in the lifecycle

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 24/93
Static tests are tests that do not involve executing software. Static tests are primarily used early in the lifecycle. Alldeliverables, including code, can also be statically tested. All these test techniques find faults, and because they usually findfaults early, static test activities provide extremely good value for money.
Reviews, walkthroughs, inspections of (primarily) documentationActivities such as reviews, inspections, walkthroughs and static analysis are all static tests. Static tests operate primarily ondocumentation, but can also be used on code, usually before dynamic tests are done.
RequirementsMost static testing will operate on project deliverables such as requirements and design specification or test plans. However,any document can be reviewed or inspected. This includes project terms of reference, project plans, test results and reports,user documentation etc.
DesignsReview of the design can highlight potential risks that if identified early can either be avoided or managed.
CodeThere are techniques that can be used to detect faults in code without executing the software. Review and inspectiontechniques are effective but labour intensive.Static analysis tools can be used to find statically detectable faults in millions of lines of code.
Test plans.It is always a good idea to get test plans reviewed by independent staff on the project - usually business people as well as
technical experts.
5.6. Dynamic testing in the lifecycle
Static tests do not involve executing the software. Dynamic tests, the traditional method of running tests by executing thesoftware, are appropriate for all stages where executable software components are available.
Program (unit, component, module)Dynamic tests start with component level testing on routines, programs, class files, and modules. Component testing is thestandard terms for tests that are often called unit, program or module tests.
Integration or link testingThe process of assembly of components into testable sub-systems is called integration (in the small) and link tests aim to
demonstrate that the interfaces between components and sub-systems work correctly.
System testingSystem-level tests are split into functional and non-functional test types.Non-functional tests address issues such as performance, security, backup and recovery requirements.Functional tests aim to demonstrate that the system, as a whole, meets its functional specification.
User acceptance testing.Acceptance (and user acceptance) tests address the need to ensure that suppliers have met their obligations and that user needs have been met.
5.7. Test planning in the lifecycle
Unit test plans are prepared during the programming phaseAccording to the textbook, developers should prepare a test plan based on a component specification before they startcoding. When the code is available for testing, the test plan is used to drive the component test.Test plans should be reviewed. At unit test level, test plans should be reviewed against the component specification. If testdesign techniques are used to select test cases the plans might also be reviewed against a standard, (the Component TestStandard BS7925-2, for example).
System and acceptance test plans written towards the end of the physical design phase includingThe system and acceptance test plans include the test specifications and the acceptance criteria. System and acceptancetests should also be planned early, if possible. System-level test plans tend to be large documents - they take a lot longer toplan and organise at the beginning and to run and analyse at the end. System test planning normally involves a certainamount of project planning, resourcing and scheduling because of its scale. It’s a bigger process entirely requiring muchmore effort than testing a single component.
Test plans for components and complete systems should be prepared well in advance for two reasons. Firstly, the processof test design detects faults in baseline documents (see later) and second to allow time for the preparation of test materialsand test environments. Test planning depends only on good baseline documents so can be done in parallel with other development activities. Test execution is on the critical path – when the time comes for test execution, all preparations for testing should be completed.
5.8. Building block approach

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 25/93
We normally break up the test process into a series of building blocks or stages. The hope is that we can use a 'divide andconquer' approach and break down the complex testing problem into a series of smaller, simpler ones.
• Building block approach implies
o testing is performed in stages
o testing builds up in layers.
A series of (usually) sequential stages, each having distinct objectives, techniques, methods, responsibilitiesdefined. Each test stage addresses different risks or modes of failure. When one test stage completes, we 'trust'the delivered product and move onto a different set of risk areas.
•But what happens at each stage?
• How do we determine the objectives for each layer?
The difficult problem for the tester is to work out how each layer of testing contributes to the overall test process. Our aim must be to ensure that there are neither gaps nor overlaps in the test process.
5.9. Influences on the test processWhat are the influences that we must consider when developing our test strategy?
The nature and type of faults to test for What kind of faults are we looking for? Low level, detailed programming faults are best found during component testing.Inconsistencies of the use of data transferred between complete systems can only be addressed very late in the testprocess, when these systems have been delivered.The different types of faults, modes of failure and risk affect how and when we test.
The object under testWhat is the object under test? A single component, a subsystem or a collection of systems?
Capabilities of developers, testers, usersCan we trust the developers to do thorough testing, or the users, or the system testers? We may be forced to rely on lesscompetent people to test earlier or we may be able to relax our later testing, because we have great confidence on earlier tests.
Availability of: environment, tools, dataAll tests need some technical infrastructure. But have we adequate technical environments, tools and access to test data?These can be a major technical challenge.
The different purpose(s) of testingOver the course of the test process, the nature of the purpose of testing changes. Early on, the main aim is to find faults, butthis changes over time to generating evidence that software works and building confidence.
5.10.Staged testing - from small to largeThe stages of testing are influenced mainly by the availability of software artefacts during the build process. The buildprocess is normally a bottom-up activity, with components being built first, then assembled into sub-systems, then the sub-systems are combined into a complete, but standalone, system and finally, the complete system is integrated with other systems in its final configuration. The test stages align with this build and integration process.
• Start by testing each program in isolation
• As tested programs become available, we test groups of programs - sub-systems
• Then we combine sub-systems and test the system
•
Then we combine single systems with other systems and test
5.11.Layered testing - different objectivesGiven the staged test process, we define each stage in terms of its objectives. Early test stages focus on low-level anddetailed tests that need single, isolated components in small-scale test environments. This is all that is possible. The testingtrend moves towards tests of multiple systems using end-to-end business processes to verify the integration of multiplesystems working in collaboration. This requires large-scale integrated test environments.
• Objectives at each stage are different
• Individual programs are tested for their conformance to their specification
• Groups of programs are tested for conformance to the physical design
• Sub-systems and systems are tested for conformance to the functional specifications and requirements.
5.12.Typical test strategy

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 26/93
5.13.V model: waterfall and locks
5.14.Typical test practice
5.15.Common problems
If there is little early testing, such as requirements or design reviews, if component testing and integration testing in thesmall don't happen, what are the probable consequences?
Lots of reworkFirstly, lots of faults that should have been found by programmers during component testing cause problems in system test.System testing starts late because the builds are unreliable and the most basic functionality doesn't work. The time taken tofix faults delays system testing further, because the faults stop all testing progressing.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 27/93
Delivery slippageRe-programming trivial faults distracts the programmers from serious fault fixing.Re-testing and regression testing distract the system testers.The overall quality of the product is poor, the product is late and the users become particularly frustrated because theycontinue to find faults that they are convinced should have been detected earlier.
Cut back on function, deliver low quality or even the wrong system.Time pressure forces a decision: ship a poor quality product or cut back on the functionality to be delivered. Either way, theusers get a system that does not meet their requirements at all.
5.16.Fault cost curve
5.17.Front-loading and its advantages"Front-loaded" testing is a discipline that promotes the idea that all test activities should be done as early as possible.This could mean doing early static tests (of requirements, designs or code), or dynamic test preparation as early as possible
in the development cycle.• The principle is to start testing early
• Reviews, walkthroughs and inspections of documents during the definition stages are examples of early tests
• Start preparing test cases early. Test case preparation "tests" the document on which the cases are based
• Preparing the user manual tests the requirements and design
What are the advantages of a front-loaded test approach?
• Requirements, specification and design faults are detected earlier and are therefore less costly (remember the fault-
cost curve)
• Requirements are more accurately captured, because test preparation finds faults in baselines
• Test cases are a useful input to designers and programmers (they may prefer them to requirements or design
documents)
•Starting early spreads the workload of test preparation over the whole project
5.18.Early test case preparation

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 28/93
5.19.V-modelThe V-model is a great way to explain the relationship of development and test activities and promotes the idea of front-loaded testing.However, it really only covers the dynamic testing (the later stuff) and the front-loading idea is a sensible add-on. Taken at
face value, the V-model retains the old-fashioned idea that testing is a 'back-door' activity that happens at the end, so it is apartial picture of how testing should be done.
Instils concept of layered and staged testingThe testing V-model reinforces the concept of layered and staged testing. The testing builds up in layers, each test stagehas its own objectives, and doing testing in layers promotes efficiency and effectiveness.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 29/93
Test Documentation or High Level Test PlanHigh Level (or Master) Test Planning is an activity that should take place as soon as possible after the go-ahead on a newdevelopment project is received. If testing (in all its various forms) will take 50% of the overall project budget, then high level testplanning should consume 50% of all project planning, shouldn't it? This module covers the issues that need to be considered indeveloping an overall test approach for your projects.
a. How to scope the testing?When testers are asked to test a system, they wait for the software to be kindly delivered by the developers (at their convenience) and in whatever environment is available at the time, start gently running (not executing) some testtransactions on the system.NOT!Before testers can even think about testing at any stage, there must be some awkward questions asked of the projectmanagement, sponsors, technical gurus, developers and support staff.In many ways, this is the fun part of the project. The testers must challenge some of the embedded assumptions on howsuccessful and perfect the development will be and start to identify some requirements for the activities that will no doubtoccur late in the project.
What stages of testing are required?Full scale early reviews, code inspections, component, link, system, acceptance, large scale integration tests?Or a gentle bit of user testing at the end?
How do we identify what to test?
What and where are the baselines? Testers cannot test without requirements or designs. (Developers cannot build? (Butthey usually try)).
How much testing is enough?Who will set the budget for testing? Testers can estimate, but we all know that testers assume the worst and aim too high.Who will take responsibility for cutting the test budget down to size?
How can we reduce the amount of testing?We know we'll be squeezed during test planning and test execution. What rationale will be used to reduce the effort?
How can we prioritise and focus the testing?What are the risks to be addressed? How can we use risk to prioritise and scope the test effort? What evidence do we needto provide to build confidence?
b. Test deliverablesThis is a diagram lifted from the IEEE 829 Standard for Software Test Documentation. The standard defines acomprehensive structure and organisation for test documentation and composition guidelines for each type of document.In the ISEB scheme IEEE 829 is being promoted as a useful guideline and template for your project deliverables.You don't need to memorise the content and structure of the standard, but the standard number IEEE829 might well begiven as a potential answer in an examination question.NB: it is a standard for documentation, but makes no recommendation on how you do testing itself.
c. Master Test Plan

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 30/93
The Master Test Plan sets out the overall approach to how testing will be done in your project. Existing company policiesand plans may be input to your project, but you may have to adapt these to your particular objectives.Master test planning is a key activity geared towards identifying the product risks to be addressed in your project and howtests will be scheduled, resourced, planned, designed, implemented, executed, documented, analysed, approved andclosed.
• Addresses project/product and/or individual application/system issues
• Focus of strategies, roles, responsibilities, resources, and schedules
• The roadmap for all testing activities
• Identifies the detailed test plans required
• Adopts/adapts test strategy/policies.
d. Master Test Plan Outline1. Test Plan Identifier 2. References3. Introduction4. Test Items5. Software Risk Issues6. Features to be Tested 7. Features not to be Tested 8. Approach9. Item Pass/Fail Criteria10. Suspension Criteria and Resumption Requirements11. Test Deliverables
12. Remaining Test Tasks13 Environmental Needs14. Staffing and Training Needs15. Responsibilities16. Schedule17. Planning Risks and Contingencies18. Approvals19. Glossary
e. Brainstorming – agendaIt is helpful to have an agenda for the brainstorming meeting. The agenda should include at least the items below. We find ituseful to use the Master Test Plan (MTP) headings as an agenda and for the testers to prepare a set of questionsassociated with each heading to 'drive' the meeting.
• To set the scene, introduce the participants
• Identify the systems, sub-systems and other components in scope
• Identify the main risks
o what is critical to the business?
o which parts of the system are critical?
• Make a list of issues and define ownership
• Identify actions to get test planning started.
Many of the issues raised by the testers should be resolved at the meeting. However, individuals should be actionedto research possible alternatives or to resolve the ourstanding issues.
f. MTP Headings
IEEE 829 Main Headings and Guidelines
1. Test plan identifier
• unique, generated number to identify this test plan, its level and the level of software that it is related to
• preferably the test plan level will be the same as the related software level
• may also identify whether the test plan is a Master plan, a Level plan, an integration plan or whichever plan
level it represents.
2. References
• list all documents that support this test plan.
• e.g. Project Plan, Requirements specifications, design document(s)
• development and test standards
3. Introduction

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 31/93
• the purpose of the Plan, possibly identifying the level of the plan (master etc.).
• the executive summary part of the plan.
4. Test Items (Functions)
• what you intend to test
• developed from the software application inventories as well as other sources of documentation and information
• includes version numbers, configuration requirements where needed
• delivery schedule issues for critical elements.
5. Software risk issues
• critical areas are, such as:
o delivery of a third party product
o new version of interfacing software
o ability to use and understand a new package/tool
o extremely complex functions
o error-prone components
o Safety, multiple interfaces, impacts on client, government regulations and rules.
6. Features to be tested
• what is to be tested (from the USERS viewpoint)
• level of risk for each feature
7. Features not to be tested
• what is NOT to be tested (from the Users viewpoint)
• WHY the feature is not to be tested.
8. Approach (Strategy)
•overall strategy for this test plan e.g.
o special tools to be used
o metrics to be collected
o configuration management policy
o combinations of HW, SW to be tested
o regression test policy
o coverage policy etc.
9. Item pass/fail criteria
• completion criteria for this plan
• at the Unit test level this could be:
o all test cases completedo a specified percentage of cases completed with a percentage containing some number of minor faults
o code coverage target met
• at the Master test plan level this could be:
o all lower level plans completed
o test completed without incident and/or minor faults.
10. Suspension criteria and resumption requirements
• when to pause in a series of tests
• e.g. a number or type of faults where more testing has little value
•
what constitutes stoppage for a test or series of tests• what is the acceptable level of faults that will allow the testing to proceed past the faults.
11. Test deliverables

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 32/93
• e.g. test plan document, test cases, test design specifications, tools and their outputs, incident logs and
execution logs, problem reports and corrective actions
12. Remaining test tasks
• where the plan does not cover all software
• e.g. where there are outstanding tests because of phased delivery.
13. Environmental needs
• special requirements such as:
• special hardware such as simulators, test drivers etc.
• how test data will be provided
14. Staffing and training
• e.g. training on the application/system
• training for any test tools to be used.
15. Responsibilities
• who is in charge?
• who defines the risks?
• who selects features to be tested and not tested
• who sets overall strategy for this level of plan.
16. Schedule
• based on realistic and validated estimates.
17. Planning risks and contingencies
• overall risks to the project with an emphasis on testing• lack of resources for testing lack of environment
• late delivery of the software, hardware or tools.
18. Approvals
• who can approve the process as complete?
19. Glossary
• used to define terms and acronyms used in the document, and testing in general, to eliminate confusion and
promote consistent communications.
6. Stages of TestingThis module sets out the six stages of testing as defined in the ISEB syllabus and provides a single slide description of eachstage. The modules that follow this one describe the stages in more detail.
6.1. Test stagesWe’ve had a look at the “V” model and we’ve had a general discussion about what we mean by layered and stage testing.Here is a description of the stages themselves.
6.2. Component testingComponent testing is the lowest-level component that has its own specification. It’s programmer-level testing.
Objectives To demonstrate that a program performs as described in itsspecification.To demonstrate publicly that a program is ready to be includedwith the rest of the system (for Link Testing).
Test technique Black and white box.Object under A single program or component

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 33/93
testResponsibility Usually, the component's author Scope Each component is tested separately, but usually a programmer
performs some Ad Hoc Testing before formal Component Testing.
Component testing is the lowest level of testing. The purpose of it is to demonstrate that a program performs as described inits specification. Typically, you are testing against a program specification. Techniques – black and white box testingtechniques are used. The programmers know how to work out test cases to exercise the code by looking at the code (whitebox testing). When the programmers are using the program spec to drive their testing, then this is black box testing. Objectunder test – a single program, a module, class file, or any other low-level, testable object. Who does it ? Normally, theauthor of the component. It might not be, but usually, it is the same person that wrote the code.
6.3. Integration testingThen, we have integration testing in the small. This is the testing of the assembly of these components into subsystems.Component testing and integration testing in the small, taken together, are subsystem testing.
Objectives To demonstrate that a collection of components interface together as described in the physical design.
Test technique White box.Object under test
A sub-system or small group of components sharing an interface.
Responsibility A member of the programming team.Scope Components should be Link Tested as soon as a meaningful
group of components have passed component testing.Link Testing concentrates on the physical interfacing betweencomponents.
Integration testing in the small, is also called link testing. The principle here is that we’re looking to demonstrate that acollection of components, which have been integrated, have interfaced with each other. We’re testing whether or not thoseinterfaces actually work, according to a physical design. It’s mainly white box testing, that is, we know what the interfacelooks like technically (the code). Object under test – usually more than one program or component or it could be all of thesub-programs making up a program. Who does it ? Usually a member of the programming team because it’s a technicaltask.
6.4. Functional system testingFunctional system testing is typically against a functional specification and is what we would frequently call a system test.
Objectives To demonstrate that a whole system performs as described in the logical design or functional specification documents.
Test technique Black box, mainly.
Object under test A sub-system or system.
Responsibility A test team or group of independent testers.
Scope System testing is often divided up into sub-system tests followed by full system tests. It isalso divided into testing of "functional" and "non-functional" requirements.
The objective of functional system testing is to demonstrate that the whole system performs according to its functionalspecification. The test techniques are almost entirely black box. Functional testing is usually done by more than one person
- a team of testers. The testers could be made up of representatives from different disciplines, e.g., business analysts,users, etc. or they could be a team of independent testers (from outside the company developing or commissioning thesystem).
6.5. Non-functional system testingNon-functional system testing is the tests that address things like performance, usability, security, documentation, and soon.
Objectives To demonstrate that the non-functional requirements (e.g. performance, volume, usability,security) are met.
Test technique Normally a selection of test types including performance, security, usability testing etc.
Object under test A complete, functionally tested system.
Responsibility A test team or group of independent testers.
Scope Non-functional system testing is often split into several types of test organised by therequirement type.
Non-functional requirements describe HOW the system delivers its functionality. Requirements specifying the performance,usability, security, etc. are non-functional requirements. You need a complete system, functionally tested system that is

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 34/93
reliable and robust enough to test without it crashing every five minutes. You may be able to start the preparation of the non-functional tests before the system is stable, but the actual tests have to be run on the system as it will be at the time when itis ready for production.
6.6. Integration Testing in LargeVery few systems live in isolation these days. All systems talk to other systems. So, where you have a concern of integrationof one system with another – integration testing, in the large addresses this. You might also call this end-to-end testing.One issue with integration is that integration doesn’t happen at the beginning or the end; it happens throughout. At almostevery stage, there’s a new aspect of integration that needs to be tested. Whether you’re dealing with integration of methodsin a class file or really low-level integration, program-to-program, subsystem-to-subsystem, or system-to-system, this is anaspect of integration testing. And the web itself is like one big integrated network. So, integration happens throughout, butthe two areas where integration is usually addressed as integration specifically is with integrating components into sub-systems (integration testing in the small) and system to system testing (integration testing in the large).
Objectives To demonstrate that a new or changed system interfaces correctly with other systems.
Test technique Black and white box.
Object under test A collection of interfacing systems.
Responsibility Inter-project testers.
Scope White box tests cover the physical interfaces between systems.White box tests cover the inter-operability of systems.Black-box tests verify the data consistency between interfacing systems.
Integration testing in the large involves testing multiple systems and paths that span multiple systems. Here, we’re lookingat whether the new or changed interfaces to other systems actually work correctly. Many of the tests will operate 'end-to-end' across multiple systems. This is usually performed by a team of testers.
6.7. User acceptance testingAnd the last one is acceptance testing. Covering user acceptance and contract acceptance, if applicable. Contractacceptance is not necessarily for the user’s benefit, but it helps you understand whether or not you should pay the supplier.
Objectives To satisfy the users that the delivered system meets their requirements and that thesystem fits their business process.
Test technique Entirely black box.
Object under test An entire systemResponsibility Users, supported by test analysts.
Scope The structure of User Testing is in many ways similar to System Testing, however theUsers can stage whichever tests that will satisfy them that their requirements have beenmet.User Testing may include testing of the system alongside manual procedures anddocumentation.
Here, we are looking at an entire system. Users will do most of the work, possibly supported by more experienced testers.
6.8. Characteristics of test stages
Part of the test strategy for a project will typically take the form of diagram documenting the stages of testing. For eachstage, we would usually have a description containing ten or eleven different headings.
ObjectivesWhat are the objectives? What is the purpose of this test? What kind of errors are we looking for?
Test techniques (black or white box)What techniques are going to be used here? What methods are we going to use to derive test plans?
Object under testWhat is the object under test?
Responsibility
Who performs the testing?
ScopeAs for the scope of the test, how far into the system you will go in conducting a test. How do you know when to stop?

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 35/93
7. Component TestingThe first test stage is component testing. Component testing is also known as unit, module or program testing (most often unit).Component testing is most often done by programmers or testers with strong programming skills.
7.1. Relationship of coding to testingThe way that developers do testing is to interleave testing with writing of code – they would normally code a little, test a little.To write a program (say 1,000 lines of code), a programmer would probably write the main headings, the structure, and themain decisions but not fill out the detail of the processes to be performed. In other words, they would write a skeletalprogram with nothing happening in the gaps. And then they’d start to fill in the gaps. Perhaps they’d write a piece of codethat captures information on the screen. And then they’d test it. And then they’ll write the next bit, and then test that, and soon. Code a little, test a little. That is the natural way that programmers work.
• Preparing tests before coding exposes faults before you commit them to code
• Most programmers code and test in one step
• Usual to code a little, test a little
• Testing mixed with coding is called ad hoc testing.
7.2. Component Testing Objectives
Component testing is often called unit, module or program testingFormal component testing is often called unit, module or program testing.
Objectives are to demonstrate that:
The purpose of component testing is to demonstrate the component performs as specified in a program spec or acomponent spec. This is the place where you ensure that all code is actually tested at least once. The code may never beexecuted in the system test so this might be the last check it gets before going live. This is the opportunity to make sure thatevery line of code that has been written by a programmer has been exercised by at least one test. Another objective is, if you like, the exit criteria. And that is, the component must be ready for inclusion in a larger system. It is ready to be used asa component. It’s trusted, to a degree.
7.3. Ad Hoc Testing
Ad hoc testing does not have a test planNow as far as unit testing is concerned, a unit test covers the whole unit. That’s what a unit test is. It’s a complete, formaltest of one component. There is a process to follow for this. If a programmer had not done any testing up to this point, thenthe program almost certainly would not run through the test anyway.
So programmers, in the course of developing a program, do test. But this is not component testing, it is ad hoc testing. It’scalled ad hoc because it doesn’t have a test plan. They test as they write. They don't usually use formal test techniques. It’susually not repeatable, as they can’t be sure what they’ve done (they haven’t written it down). They usually don’t log faultsor prepare incidence reports. If anything, they scribble a note to themselves.
Criteria for completing ad hoc testing:The criteria for completing ad hoc testing is to ask whether doing a formal unit test is viable? Is it reliable enough or is it stillfalling over every other transaction? Is the programmer aware of any faults?
7.4. Ad hoc testing v component testing
Ad hoc Testing:
• Does not have a test plan
• Not based on formal case design
o Not repeatable
o Private to the programmer
• Faults are not usually logged
Component Testing
• Has a test plan
• Based on formal test case design
o Must be repeatable
o Public to the team
o Faults are logged
7.5. Analysing a component specificationThe programmer is responsible for preparing the formal unit test plan. This test is against the program specification. In order to prepare that test plan, the programmer will need to analyse the component spec to prepare test cases. The keyrecommendation with component testing is to prepare a component test plan before coding the program. This has a number of advantages and is not increasing the workload, as test preparation needs to be done at some point anyway.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 36/93
Specification reviewers ask 'how would we test this requirement' among other questions
If specifications aren't reviewed, the programmer is the first person to 'test' the specificationWhen reviewing a specification, look for ambiguities, inconsistencies and omissions. Omissions are hardest to spot.Preparing tests from specifications finds faults in specifications.
Preparing tests from specifications finds faults in specifications.In preparing the tests, the programmer may find bugs in the specification itself. If tests are prepared after the code is written,it is impossible for a programmer to eliminate assumptions that they may have made in coding from their mind, so tests willbe self-fulfilling.
Get clarification from the author
• informal walkthroughs
• explains your understanding of the specification
May look obvious how to build the program, but is it obvious how to test ?
• if you couldn't test it, can you really build it?
• how will you demonstrate completion/success?
7.6. Informal Component Testing
Informal component testing is usually based on black box techniques. The test cases are usually derived from thespecification by the programmer. Usually they are not documented. It may be that the program cannot be run except usingdrivers and maybe, a debugger to execute the tests. It’s all heavily technical, and the issue is – how will the programmer
execute tests of a component if the component doesn’t have a user interface? It’s quite possible.The objective of the testing is to ensure that all code is exercised (tested) at least once. It may be necessary to use thedebugger to actually inject data into the software to make it exercise obscure error conditions. The issue with informalcomponent testing is – how can you achieve confidence that the code that’s been written has been exercised by a test whenan informal test is not documented? What evidence would you look for to say that all the lines of code in a program havebeen tested? How could you achieve that?Using a coverage measurement tool is really the only way that it can be shown that everything has been executed. But didthe code produce the correct results? This can really only be checked by tests that have expected output that can becompared against actual output.The problem with most software developers is that they don’t use coverage tools.
• Usually based on black box techniques
• Tables of test cases may be documented
• Tests conducted by the programmer
• There may be no separate scripts
• Test drivers, debugger used to drive the tests
o to ensure code is exercised
o to insert required input data
7.7. Formal component test strategy
Before code is written:In a more formal environment, we will tend to define the test plan before the code is written.We define a target for black and white box coverage.We’d use black box techniques early on, to prepare a test plan based on the specification.
After code is written:And then when we run the tests prepared using the black box techniques, we measure the coverage. We might say, for example, we’re going to design tests to cover all the equivalence partitions. We prepare the tests and then run them. But wecould have also have a statement coverage target. We want to cover every statement in the code at least once. You get thisinformation by running the tests you have prepared with a coverage tool. When you see the statements that have not beencovered, you generate additional tests to exercise that code. The additional tests are white box testing although the originaltests may be black box tests.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 37/93
8. Integration Testingntegration is the process of assembly of tested components into sub-systems and complete systems. Integration is often doneusing a 'big-bang' approach, that is, an entire system may be assembled from its components in one large build. This can makesystem testing problematic, as many underlying integration faults may cause a 'complete' system to be untestable.
Best practices promote two incremental integration approaches:
Bottom-up - building from low-level components towards the complete systemTop-down - building from the top control programs first, adding more and more functionality toward the complete system.
8.1. Software integration and link testingThere is a lot of confusion concerning integration. If you think about it, integration is really about the process of assembly of a complete system from all of its components. But even a component consists of the assembly of statements of programcode. So really, integration starts as soon as coding starts. When does it finish? Until a system has been fully integratedwith other systems you aren't finished, so integration happens throughout the project. Here, we are looking at integrationtesting 'in the small'. It's also called link testing.
• In the coding stage, you are performing "integration in the very small"
• Strategies for coding and integration:
o bottom up, top down, "big bang"
o appropriate in different situations
• Choice based on programming tool
• Testing also affects choice of integration strategy
8.2. Stubs and top down testing
The first integration strategy is 'top down'. What this means is that the highest level component, say a top menu, is writtenfirst. This can't be tested because the components that are called by the top menu do not yet exist. So, temporarycomponents called 'stubs' are written as substitutes for the missing code. Then the highest level component, the to menu,can be tested.When the components called by the top menu are written, these can be inserted into the build and tested using the topmenu component. However, the components called by the top menu themselves may call lower level components that donot yet exist. So, once again, stubs are written to temporarily substitue for the missing components.This incremental approach to integration is called 'top down'.
8.3. Drivers and bottom up testing
The second integration strategy is 'bottom up'. What this means is that the lowest level components are written first. Thesecomponents can't be tested because the components that call them do not yet exist. So, temporary components called'drvers' are written as substitutes for the missing code. Then the lowest level components, can be tested using the testdriver.When the components that call our lowest level components are written, these can be inserted into the build and tested inconjunction with the lowest level components that they call. However, the new components themselves require drivers to be
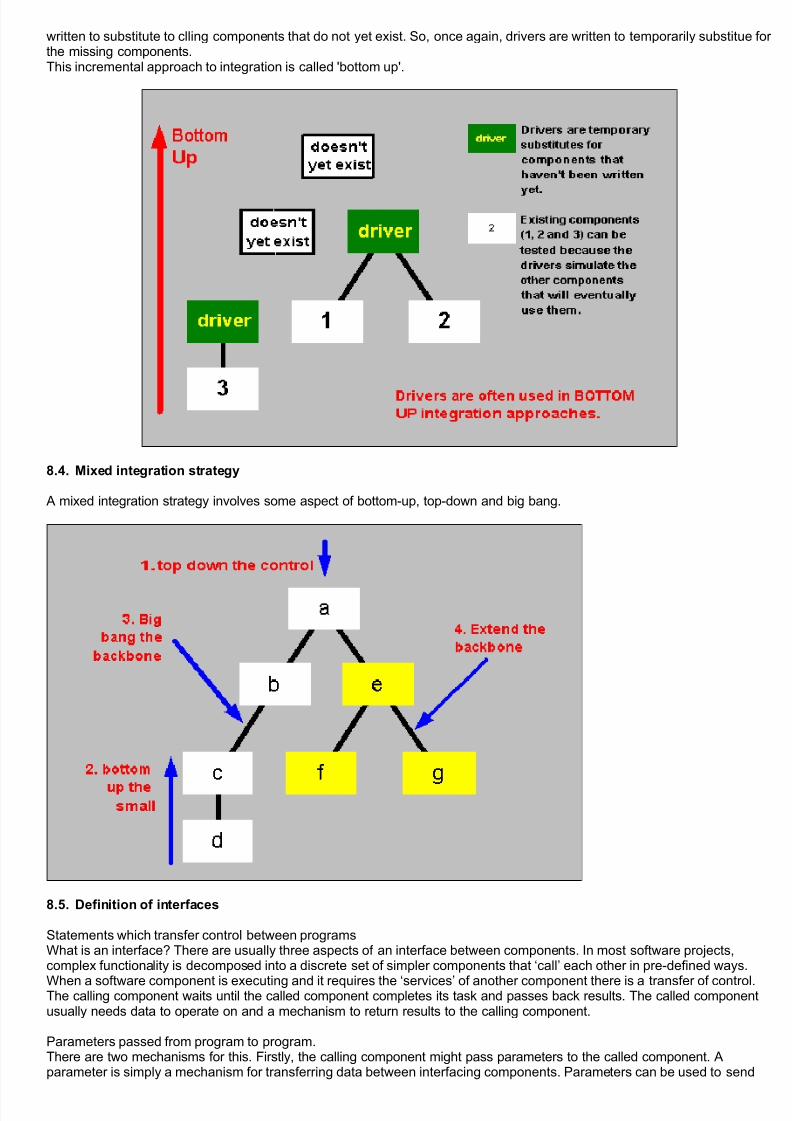
8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 38/93
written to substitute to clling components that do not yet exist. So, once again, drivers are written to temporarily substitue for the missing components.This incremental approach to integration is called 'bottom up'.
8.4. Mixed integration strategy
A mixed integration strategy involves some aspect of bottom-up, top-down and big bang.
8.5. Definition of interfaces
Statements which transfer control between programsWhat is an interface? There are usually three aspects of an interface between components. In most software projects,complex functionality is decomposed into a discrete set of simpler components that ‘call’ each other in pre-defined ways.
When a software component is executing and it requires the ‘services’ of another component there is a transfer of control.The calling component waits until the called component completes its task and passes back results. The called componentusually needs data to operate on and a mechanism to return results to the calling component.
Parameters passed from program to program.There are two mechanisms for this. Firstly, the calling component might pass parameters to the called component. Aparameter is simply a mechanism for transferring data between interfacing components. Parameters can be used to send

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 39/93
(but not change data) or receive data (the results of calculations, say) or both. Parameters are visible only to thecomponents that use them in a transfer of control.
Global variables defined at the time of transfer The second way that data is exchanged by interfacing components is to use global data. Global data is available to all or aselected number of components. Just like parameters, components may be allowed to read from or write to global data or todo both.
8.6. Interface bugsIf we look at how faults find their way into interfaces, interface bugs are quite variable in how they occur. These are whitebox tests in that link testing requires knowledge of the internals of the software, in the main. The kind of faults found duringlink testing reveals inconsistencies between two components that share an interface. Very often, problems with integrationtesting highlight a common problem in software projects and that is one of communications. Individuals and project teamsoften fail to communicate properly so misunderstandings and poor assumptions concerning the requirements for aninterface occur. Link testing normally requires a knowledge of the internals of the software components to be tested, so isnormally performed by a member of the development team.
Transfer of control to the wrong routineOne kind of bug that we can detect through link testing is a transfer of control bug. The decision to call a component iswrong; that is, the wrong component is invoked. Within a called component it may be possible to return control back to thecalling component in the incorrect way so that the wrong component regains control after the called component completesits task.
Programs validate common data inconsistentlyWhen making a call to a function or component, a common error is to supply the incorrect type, number, or order of parameters to the called component. Type could be a problem where we may substitute a string value or a numeric value,and this is not noticed until the software is executed. Perhaps, we supply the wrong number of parameters, where thecomponent we call requires six parameters and we only supply five. It may be that the software does not fail and recognizethat this has happened. Interface bugs can also occur between components that interpret data inconsistently. For example,a parameter may be passed to a component, which has been validated using a less stringent rule than that required by thecalled component. For example, a calling component may allow values between one and ten, but the called component mayonly allow values between one and five. This may cause a problem if non-valid values are actually supplied to the calledcomponent.
Readonly parameters or global data that is written to.Parameters passed between components may be treated inconsistently by different components. A read-only parameter
might be changed by a called component or a parameter passed for update may not be updated by the called component.Much data is held as global data, so is not actually passed across interfaces – rather, it is shared between manycomponents. The common example is a piece of global memory, which is shared by processes running on the sameprocessor. In this case, the ownership of global data and the access rights to creating, reading, changing, and deleting thatdata may be inconsistent across the components. One more issue, which is common, is where we get the type and number of parameters correct, but we mistake the order of parameters – so, two parameters which should be passed in the order A,then B with values A=‘yes’ and B=‘no’ might be supplied in the wrong order, B, then A, and would probably result in a failureof the called component
8.7. Call characteristicsOther integration problems relate to transfer of control between programs. Where the transfer of control occurs in ahierarchical or a lateral sequence.
Function/subroutine calls implement a hierarchical transfer of controlControl may be passed by a component that calls another component. This implements a hierarchical transfer of controlfrom parent to child and then back again, when the child component finishes execution.When testing these, ensure that the correct programs are called and return of control follows the correct path up thehierarchy.Attempt recursion: A calls B calls C calls B etc.
Object/method calls can implement lateral transfer of controlWhere one object creates another object that then operates indepedently to the first, this might be considered to be a lateraltransfer of control.When testing these, ensure that the correct programs or methods are called and the 'chain of control' ends at the correctpoint. Also check for loops: A calls B calls C calls A.
8.8. Aborted calls
An interactive screen is entered, then immediately exitedAborted calls sometimes cause problems in software. If you imagine a system’s menu hierarchy, a new window might beopened and then immediately exited by the user. This would simulate a user making a mistake in the application or changing their mind, perhaps. Aborted calls can cause calling components difficulties because they don’t expect the calledcomponent to return immediately, rather, that it should return data.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 40/93
An interactive screen has commands to return to the top menu, or exit completelyTwo other examples would be where a screen when entered by a user may have an option to return to the calling screenbut might also have the facility to return to the top menu or exit the application entirely. The controlling program, whichhandles all menu options, perhaps, may not expect to have to deal with returns to top menus or complete exit from theprogram.
A routine checking input parameters immediately exits:Another issue with regard to aborted calls is where a called component checks the data passed to it across the interface. If this data fails the check, the called component returns control to the calling component. The bug assumption would be thatthe calling component cannot actually handle the exception.
does the calling routine handle the exception properly?Is it expecting the called component to return control when it finds an error? It may not be able to handle this exception at all
8.9. Data flows across interfacesThere are several mechanisms for passing parameters between components across interfaces. It is possible to select thewrong mechanism and this is a serious problem, in that the called component cannot possibly interpret the data correctly if the call mechanism is incorrect. There are three ways that parameters can be passed:
BY VALUE - read-only to the called routineThe first is passed ‘by value’, and in effect, what happens is the contents of the variable are passed and the variable isredone as far as that component call is concerned.
BY REFERENCE - may be read/written by called routineThe variable can be passed ‘by reference’, which allows the called component to examine the data contained within thevariables but also provides the reference, allowing it to write back into that variable and return data to the core component.
Handles are pointers to pointers to data and need "double de-referencing"Handles are a common term used for pointers to pointers to data. In effect, these references are a label, which points to anaddress or some other data. These handles are de-referenced and de-referenced again to detect where the data is, thatactually has been passed across an interface.
8.10.Global dataInterface testing should also address the use of global data. Global data might be an area of memory shared by multiplesystems or components. Global data could also refer to the content of a database record or perhaps the system time, for
example.
May reduce memory required
May simplify call mechanisms between routinesUse of global data is very convenient from the programmer’s point of view because it simplifies the call mechanism betweencomponents. You don’t need parameters any more.
Lazy programmers over-use global dataBut it’s a lazy attitude when one uses global data too much because global data is particularly error-prone because of themisunderstandings that can occur between programmers in the use of global data. Global data is, in a way, a shortcut, thatallows programmers not to have to communicate as clearly. Explicitly defined interfaces between processes written bydifferent programmers force those programmers to talk to each other, discuss the interface, and clarify any assumption
made about data that is shared between their components.
8.11.Assumptions about parameters and global data
Assumed initialised e.g.:The kinds of assumptions that can be made, that cause integration faults in the use of that global data, are assumptionsabout initialisation. A component may assume that some global data will always exist under all circumstances. For example,the component may assume that the global data is always set by the caller, or that a particular variable is incrementedbefore, rather than after the call (or vice versa). This may not be a safe assumption.
Other assumptions:Other assumptions relate to the "ownership" of global data. A component may assume that it can set the value of globaldata and no other program can unset it or change it in anyway. Other assumptions can be that global data is always correct;
that is, under no circumstances can it be changed and be made inconsistent with other information held within a component.A component could also make erroneous assumptions about the repeatability or re-entry of a routine.All of these assumptions may be mistaken if the rules for use of global data are not understood.
8.12.Inter-module parameter checking
Does the called routine explicitly check input parameters?

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 41/93
The final category of integration bugs, which might be considered for testing are intermodule parameter checking; that is,does one component explicitly check the value supplied on its input?
Does the calling routine checkDoes the calling component check the return status? Does it actually take the values returned from the called componentand validate these return values are correct?
Programming or interface standards should define whether callers, called or both routines perform checking and under whatcircumstances.The principle of all integration testing and all inter-component parameter passing is that interface standards must be clear about how the calling and the called components process passed data and shared data. The issue about integration andintegration testing is that documenting these interfaces can eliminate many, if not all, interface bugs. In summary, mostinterface bugs relate to shared data and mistaken assumptions about the use of that data across interfaces. Whereprogrammers do not communicate well within the programming team, it is common to find interface problems andintegration issues within that team. The same applies to different teams who do not document their interfaces and agree theprotocol is to be used between their different software products.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 42/93
9. System and Acceptance TestingSystem and acceptance testing focus on the testing of complete systems.This module presents a few observations about the similarities and differences between system and acceptance testingbecause the differences are slight, but important.The most significant difference between acceptance and system testing is one of viewpoint.System testing is primarily the concern of the developers or suppliers of software.Acceptance testing is primarily the concerns of the users of software.
9.1. SimilaritiesAim to demonstrate that documented requirements have been metLet’s take an as an example, a middle-of-the-road IT application. Say, you’re building a customer information system, or ahelp desk application, or a telesales system. The objective of both system and acceptance testing is one aim - todemonstrate that the documented requirements have been met. The documented requirements might be the businessrequirements or what’s in the functional spec, or the technical requirements.
Should be independent of designers/ developersIn systems and acceptance testing there’s a degree of independence between the designers of the test and the developersof the software.
Formally designed, organised and executedThere also needs to be a certain amount of formality because it’s a team effort, it’s never one individual system testing.
Incidents raised, managed in a formal wayPart of the formality is that you run tests to a plan and you manage incidents.
Large scale tests, run by managed teams.Another similarity is that both systems and acceptance tests are usually big tests – they’re usually a major activity within theproject.
9.2. System testing
A systematic demonstration that all features are available and work as specifiedIf you look at system testing from the point of the view of the supplier of the software, system testing tends to be viewed ashow the supplier demonstrates that they’ve met their commitment. This might be in terms of a contract or with respect tomeeting a specification for a piece of software that they’re going to sell.
Run by/on behalf of suppliers of softwareIt tends to be inward looking. The supplier does it. We’re looking at how the supplier is going to demonstrate that what theydeliver to a customer is okay. Now, that may not be what the customer wants, but they’re looking at it from the point of viewof their contract or their specification. This makes it kind of an introspective activity. Because it is done by the organisationthat developed the software, they will tend to use their own trusted documentation, the functional specification that theywrote. They will go through their baseline document in detail and identify every feature that should be present and preparetest cases so that they can demonstrate that they comprehensively meet every requirement in the specification.
9.3. Functional and non-functional system testingSystem testing splits into two sides - functional testing and non-functional testing. There is almost certainly going to be aquestion on functional and non-functional testing so I need to be quite clear about what the difference between these twoare.
Functional system testingThe simplest way to look at functional testing is that users will normally write down what they want the system to do, whatfeatures they want to see, what behaviour they expect to see in the software. These are the functional requirements. Thekey to functional testing is to have a document stating these things. Once we know what the system should do, then wehave to execute tests that demonstrate that the system does what it says in the specification. Within system testing, faultdetection and the process of looking for faults is a major part of the test activities. It’s less about being confident. It’s moreabout making sure that the bugs are gone. That’s a major focus of system testing.
Non-functional system testingNon-functional testing is more concerned with what we might call technical requirements – like performance, usability,security, and other associated issues. These are things that, very often, users don’t document well. It’s not unusual to see afunctional requirement document containing hundreds of pages and a non-functional requirement document of one page.
Requirements are often a real problem for non-functional testing. Another way to look at non-functional testing is to focus onhow it delivers the specified functionality. How it does what it does. Functional testing is about what the system must do.Non-functional is about how it delivers that service. Is it fast? Is it secure? Is it usable? That’s the non-functional side.
9.4. Acceptance testing

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 43/93
Acceptance testing is from a user viewpoint. We tend to treat the system as a great big black box and we’ll look at it fromthe outside. We don’t take much interest in knowing how it was built, but we need to look at it from the point of view of howwe will use it.
Fit with business process is the imperativeHow does the system meet our business requirements? How does it fit the way that we do business? Simplistically, doesthe system help me do my job as a user? If it makes my life harder, I’m not going to use it, no matter how clever it is or howsophisticated the software is.
Emphasis on essential featuresUsers will test the features that they expect to use and not every single feature offered, either because they don’t use everyfeature or because some features are really not very important to them.
Tests designed around how users use the system.The tests are geared around how the system fits the work to be done by the user and that may only use a subset of thesoftware.
Usual to assume that all major faults have been removed and the system worksIt is usual to assume at acceptance testing that all major faults have been removed by the previous component, link andsystem testing and that the system 'works'. In principle, if earlier testing has been done thoroughly, then it should be safe toassume the faults have been removed. In practice, earlier testing may not have been thorough and acceptance testing canbecome more difficult.When we buy an operating system, say a new version of Microsoft Windows, we will probably trust it if it has become widely
available. But will we trust that it works for our usage? If we’re Joe Public and we’re just going to do some word-processing,we’ll probably assume that it is okay. It’s probably perfectly adequate, and we’re going to use an old version of Word on itand it will probably work just fine. If on the other hand, we are a development shop and we’re writing code to do with devicedrivers, it needs to be pretty robust. The presumption that it works is no longer safe because we’re probably going to try andbreak it. That’s part of our job. So this aspect of reliability, this assumption about whether or not it works, is basically fromyour own perspective.
Acceptance tests:Acceptance testing is usually on a smaller scale than the system test. Textbook guidelines say that functional system testingshould be about four times as much effort as acceptance testing. You could say that for every user test, the suppliers shouldhave run, around four tests. So, system tests are normally of a larger scale than acceptance tests.On some occasions, the acceptance test is not a separate test, but a sub-set of the system test. The presumption is thatwe’re hiring a company to write software on our behalf and we’re going to use it when it’s delivered. The company
developing the software will run their system testing on their environment. We will also ask them to come to our testenvironment and to rerun a subset of their test that we will call our acceptance test.
9.5. Design-based testingDesign-based testing tends to be used in highly technical environments. For example, take a company who are rewriting abilling system engine that will fit into an existing system. We may say that a technical test of the features will serve as anacceptance test as it is not appropriate to do a ‘customer’ or ‘user’ based test. It would be more appropriate to run a test inthe target environment (where it will eventually need to run). So, it’s almost like the supplier will do a demonstration test.Given that system testing is mainly black box, it relies upon design documents, functional specs, and requirementsdocuments for its test cases. We have a choice, quite often, of how we build the test. Again, remember the “V” model, wherewe have an activity to write requirements, functional specs, and then do design. When we do system testing, what usuallyhappens is that it’s not just the functional spec that is used. Some tests are based on the design. And no supplier who isproviding a custom-built product should ignore the business requirements because they know that if they don’t meet the
business requirements, the system won’t be used. So, frequently, some tests may be based on the business requirementsas well. Tests are rarely based on the design alone.
We can scan design documents or the features provided by the system:Let’s think about what the difference is between testing against these different baselines (requirements, functional specsand design documents). Testing against the design document is using a lower level, more technically-oriented document.You could scan the document and identify all of the features that have been built. In principle, this is what has been built.Remember that it is not necessarily what the user has asked for, but what was built. You can see from the design documentwhat conditions, what business rules, what technical rules have been used. We can therefore test those rules. A design-based test is very useful because it can help demonstrate that the system works correctly. We can demonstrate that we builtit the way that we said we would.
Design based tests:
If you base your tests on a design, it’s going to be more oriented towards the technology utilised and what was built rather than what was asked for. Remember that the users requirements are translated into a functional spec and eventually to adesign document. Think of each translation as an interpretation. Two things may happen – a resulting feature doesn’t deliver functionality in the way a user intended and also if a feature is missing, you won’t spot it.So, if you test against the design document, you will never find a missing requirement because it just won’t be there to findfault with (if there’s a hole in your software it’s because there’s a hole in your design). There is nothing to tell you what is"missing" using the design document alone.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 44/93
A design-based test is also strongly influenced by the system provided. If you test according to the design, the test willreflect how the system has been designed and not how it is meant to be used in production. Tests that are based on designwill tend to go through features, one by one, right through the design document from end to end. It won’t be tested in theways that users will use it, and that might not be as good a test.
9.6. Requirements-based testing
We can scan requirements documents:The requirements document says what the users want. If we scan the requirements document, it should say which featuresshould be in the system. And it should say which business rules and which conditions should be addressed. So, it gives usnformation about what we want the system to do.
Requirements based tests:f it can be demonstrated that the system does all these things, then the supplier has done a good job. But testing may showhat actually there are some features that are missing in the system. If we test according to the requirements document, it will benoticeable if things are missing.Also, the test is not influenced by the solution. We don’t know and we don’t care how the supplier has built the product. We’reesting it as if it were a black box. We will test it the way that we would use it and not test it the way that it was built.
9.7. Requirements v specificationsIs it always possible to test from the requirements? No. Quite often, requirements are too high-level or we don’t have them.If it’s a package, the requirements may be at such a high-level that we are saying, for example, we want to do purchasing,invoice payment, and stock control. Here’s a package, go test it.
In reality, requirements documents are often too vague to be the only source of information for testing. They’re rarely inenough detail. One of the reasons for having a functional spec is to provide that detail; the supplier needs that level of detailto build the software. The problem is that if you use the functional spec or the design document to test against, there mayhave been a mistranslation and that means that the system built does not meet the original requirements or that somethinghas been left out.
Functional specification
Developers: "this is what we promised to build"The requirements are documented in a way that the users understand. And the functional spec, which is effectively theresponse from the supplier, gives the detail and the supplier will undertake to demonstrate how it meets the usersrequirements. The functional spec is usually structured in a different way than the requirements document. A lot more detail,and in principle, every feature in the functional spec should reflect how it meets these requirements. Quite often, you’ll see
two documents delivered – one is the functional spec and one is a table of references between a feature of the system andhow it meets a requirement. And in principle, that’s how you would spot gaps. In theory, a cross-reference table should helpan awful lot.
User or business requirementsSystem tests may have a few test cases based on the business requirements just to make sure that certain things work theway that they were intended, but most of the testing tends to use the functional spec and the design documents.
Users: "this is what we want"From the point of view of acceptance testing, you assume system testing has been done. The system test is probably morethorough than the acceptance test will be. When you come to do an acceptance test, you use your business requirementsbecause you want to demonstrate to the users that the software does what they want. When a gap is detected becausewhat the user wanted is different than what the developers built, then you have a problem. And that is probably why you still
need system testing and acceptance testing.Not always the same thing...Probably the real value is that whoever wrote the table has by default checked that all of the features are covered. But manyfunctional specs will not have a cross-reference table to the requirements. This is a real problem because these could belarge documents, maybe 50 pages, 100 pages… this might be 500 pages.
9.8. Problems with requirementsAnother thing about a loose requirement is that when the supplier comes and delivers the system and you test against thoserequirements, if you don’t have the detail, the supplier is going to say, you never said that you were going to do that,because you didn’t specify that. So, the supplier is expecting payment for a product that the users don’t think works. Thesupplier contracted to deliver a system that met the functional specs, not the business requirements. You have to be verycareful.
Requirements don't usually give us enough information to test
intents, not detailed implementationTypically a requirements statement says ‘this is what we intend to do with the software’ and ‘this is what we want thesoftware to do’. It doesn’t say how it will do it. It’s kind of a wish list and that’s different than a statement of actuality. It’sintent, not implementation.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 45/93
need to identify features to testFrom this ‘wish list’ you need to identify all of the features that need to be tested. Take an example of a requirementsstatement that says ‘the system must process orders’. How will it process orders? Well, that’s up to the supplier. So, it’s hardto figure out from the requirements how to test it; often you need to look at the specification.
many details might be assumed to exist, but can't be identified from requirementsWhen the user writes the requirement, many details might be assumed to exist. The supplier won’t necessarily have thoseassumptions, so they will deliver what they think will work. Assumptions arise from knowledge that you have yourself, butyou didn’t transmit to the requirements document. A lot of low-level requirements, like field validation and steps of theprocess don’t appear in a requirements document. Again, looking at the processes of a large SAP system, they areincredibly complicated. You have a process called “The Order Process”, and within SAP, there may be 40 screens that youcan go through. Now, nobody would use 40 screens to process an order. But SAP can deliver a system that, in theory, coulduse all 40.The key to it is the configuration that selects only those bits that are useful to you. All that detail backs up the statement‘process an order’ is the difference between processing an order as you want to do it versus something that’s way over thetop. Or the opposite can happen, that is, having a system that processes an order too simplistically when you needvariations. That’s another reason why you have to be careful with requirements.
9.9. Business process-based testingThe alternative to using the requirements document is to say from a user’s point of view, ‘we don’t know anything abouttechnology and we don’t want to know anything about the package itself, we just want to run our business and see whether the software supports our activities’.
Start from the business processes to be supported by the system
use most important processesTesting from a viewpoint of business process is no different from the unit testing of code. Testing code is white box testing.In principle, you find a way of modelling the process, whether it’s software or the business, you draw a graph, trace paths,and you say that our covering the paths gives us confidence that we’ve done enough.From the business point of view, usually you identify the most important processes because you don’t have time to doeverything. What business decisions need to be covered? Is it necessary to test every variation of the process? It depends.What processes do we need to feel confident about in order to give us confidence that the system will be correct?
what business decisions need to be coveredFrom this point of view, the users would construct a diagram on how they want a process to work. The business may havean end-to-end process where there’s a whole series of tasks to follow, but within that, there are decisions causing
alternative routes. In order to test the business process, we probably start with the most straightforward case. Then,because there are exceptions to the business rules, we start adding other paths to accommodate other cases. If you have abusiness process, you can diagram the process with the decision points (in other words, you can graph the process). Whentesters see a graph, as Beizer says, ‘you cover it’. In other words, you make up test cases to take you through all of thepaths. When you’ve covered all the decisions and activities within the main processes, then we can have some confidencethat the system supports our needs.
is a more natural way for users to specify tests.Testing business processes is a much more natural way for users to define a test. If you ask users to do a test and you givethem a functional spec and sit them at a terminal, they just don’t know where to start. If you say, construct some businessscenarios through your process and use the system, based on your knowledge based on the training course, they are far more likely to be capable of constructing test cases. And this works at every level, whether you’re talking about the highestlevel business processes or the detail of how to process a specific order type. Even if at the moment a particular order type
is done manually, the decisions taken, whether by a computer or manually, can be diagrammed.
9.10.User Acceptance testing
Intended to demonstrate that the software 'fits' the way the users want to workWe have this notion of fit between the system and the business. The specific purpose of the user acceptance test is todetermine whether the system can be used to run the business.
Planned and performed by or on behalf of usersIt’s usually planned and performed by, or on the behalf of, the users. The users can do everything or you can give the usersa couple of skilled testers to help them construct a test plan.It’s also possible to have the supplier or another third-party do the user acceptance test on behalf of the users as anindependent test, but this cannot be done without getting users involved.
User input essential to ensure the 'right things' are checkedIt’s not a user test unless you’ve got some users involved. They must contribute to the design of that test and haveconfidence that the test is representative of the way they want to work. If the users are going to have someone else run atest, they must buy into that and have confidence in the approach. The biggest risk with an independent test group (i.e., notthe users) is that the tests won’t be doing what the user would do.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 46/93
Here’s an example. Most people have bought a second-hand car. Suppose that you went into a showroom, into theforecourt. And you walk around the forecourt in a car dealer’s, and the model that you want is there. And you look at it andyou think, well the colour is nice, and you look inside the window and the mileage is okay. And you know from themagazines that it goes really, really fast. And you think, well I’d like to look at this. And the car dealer walks up to you andsays, hello sir – can I help you? And you say "I’d like to look at this car, I’d like to take it for a test drive". And the car dealer says, "no, no, no – you don’t want to do that, I’ve done that for you."Would you buy the car? It’s not likely that you’re going to buy the car?Assuming that the car dealer is trustworthy, why wouldn’t you buy a car from a dealer that said he’d tested the car out onyour behalf?Because, his requirements may be different than yours. If he does the test – if he designs the test and executes the test –it’s no guarantee that you’ll like it.Software testing differs from this example in one respect. Driving a car is a very personal thing – the seat’s got to be right,the driving position, the feel, the noise, etc. It’s a personal preference.With software, you just want to make sure that it will do the things that the user wants. So, if the user can articulate whatthese things are, potentially, you can get a third party to do at least part of the testing. And sometimes, user acceptancetests can be included, say as part of a systems test done by the supplier, and then re-run in the customer’s environment.The fundamental point here is that the users have to have confidence that the tests represent the way they want to dobusiness.
When buying a package, UAT may be the only form of testing applied.Packages are a problem because there is no such notion of system testing; you only have acceptance testing. That’s theonly testing that’s visible if it’s a package that you’re not going to change. Even if it is a package that you are only going toconfigure (not write software for), UAT is the only testing that’s going to happen.
A final stage of validationUAT is usually your last chance to do validation. Is it the right system for me?
Users may stage any tests they wish but may need assistance with test design, documentation and organisationThe idea of user acceptance testing is that users can do whatever they want. It is their test. You don’t normally restrictusers, but they often need assistance to enable them to test effectively.
Model office approach:Another approach to user acceptance testing is using a model office. A model office uses the new software in anenvironment modelled on the business. If, for example, this is a call centre system, then we may set up 5 or 6 workstations,with headsets and telephone connections, manned by users. The test is then run using real examples from the business.So, you’re testing the software, the processes by the people who will be using it. Not only will you test the software, you will
find out whether their training is good enough to help them do their job. So a model office is another way of approachingtesting and for some situations, it can be valuable.
9.11.Contract acceptance testing
Aims to demonstrate that the supplier's obligations are metContract acceptance testing is done to give you evidence that the supplier’s contractual obligations have been met. In other words, the purpose of a contract acceptance is to show that a supplier has done what they said they would do and youshould now pay them.
Similar to UAT, focusing on the contractual requirements as well as fitness for purposeThe test itself can take a variety of forms. It could be a system test done by a supplier. It could be what we call a factoryacceptance test which is a test done by the supplier that is observed, witnessed if you like, by the customer. Or you might
bring the software to the customer’s site and run a site acceptance test. Or it could even be the user acceptance test.
Contract should state the acceptance criteriaThe contract should have clear statements about the acceptance criteria, the acceptance process and the acceptancetimescales.
Stage payments may be based on successful completion.Contract acceptance, when you pay the supplier, might be on the basis of everything going correctly, all the way through,that is 100% payment on final completion of the job. Alternatively, payment might be staged against particular milestones.This situation is more usual, and is particularly relevant for large projects involving lots of resources spanning severalmonths or even a year or more. In those cases, for example, we might pay 20% on contract execution and thereafter allpayments are based on achievement. Say another 20% on completion of the build and unit test phase, 20% when thesystems test is completed satisfactorily, 20% when the performance criteria are met, and the final 20% only when the users
are happy as well. So, contract acceptance testing is really any testing that has a contractual significance and in general, itis linked with payment. The reference in the contract to the tests, however, must be specific enough that it is clear to bothparties whether the criteria have been met.
9.12.Alpha and beta testing
Often used by suppliers of packages (particularly shrink-wrapped)

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 47/93
Up to now, we’ve been covering variations on system and acceptance testing. Are there more types of testing? Hundreds,but here are a few of the more common ones.Alpha and beta testing are normally conducted by suppliers of packaged (shrink-wrapped) software. For example, Microsoftdoes beta testing for Windows 95, and they have 30,000 beta testers. The actual definitions for alpha and beta testing willvary from supplier to supplier, so it’s a bit open to interpretation what these tests are meant to achieve. In other words,there’s no definitive description of these test types, but the following guidelines generally apply.
Alpha testing normally takes place on the supplier siteAn alpha test is normally done by users that are internal to the supplier. An alpha test is an early release of a product, thatis, before it is ready to ship to the general public or even to the beta testers. Typically it is given to the marketers or other parties who might benefit from knowing the contents of the product. For example, the marketers can decide how they willpromote its features and they can start writing brochures. Or we might give it to the technical support people so that theycan get a feel for how the product works. To recap, alpha testing is usually internal and is done by the supplier.
Beta testing usually conducted by users on their site.Beta testing might be internal, but most beta testing involves customers using a product in their own environment.Sometimes beta releases are made available to big customers because if the customer wants them to take the next version,they may need a year or two years planning to make it happen. So, they’ll get a beta version of the next release so theyunderstand what’s coming and they can plan for it. A beta release of a product is very often a product that’s nearly finished,and is reasonably stable, and usually includes new features that hopefully are of some use to the customer and you areasking your customers to take a view.
Assess reaction of marketplace to the product
You hear stories about Microsoft having 30,000 beta testers, and you think, don’t they do their own testing? Who are thesepeople? Why are they doing this testing for Microsoft?This type of beta testing is something different. Microsoft isn’t using 30,000 people to find bugs, they have differentobjectives. Suppose that they gave a beta version of their product out which had no bugs. Do you think that anyone wouldcall them up and say, ‘I like this feature but could you change it a bit’? They leave bugs in so that people will come back tothem and give them feedback. So, beta testers are not testers at all really, they’re part of a market research programme. It’sbeen said that only 30% of a product is planned, the rest is based on feedback from marketers, internal salesmen, betaprogrammers, so on and so forth. And that’s how a product is developed.When they get 10,000 reports of bugs in a particular area of the software, they know that this is a really useful feature,because everybody who is reporting bugs must be using it! They probably know all about the bug before the product wasshipped, but this is a way to see what features people are using. If another bug is only reported three times, then it’s not avery useful feature, otherwise you would have heard about it more. Let’s cut it out of the product. There’s no point indeveloping this any farther. In summary, beta testing may not really be testing, it may be market research.
9.13.Extended V ModelIt’s the same as you’ve seen before, but maybe there’s an architectural aspect to this. Multiple systems collaborate in anarchitecture to deliver a service. And the testing should reflect a higher level than just a system level. It could be thought of as the acceptance test of how the multiple systems deliver the required functionality.
9.14.Phase of Integration

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 48/93
Integration testing is not easy – you need an approach or a methodology to do it effectively. First, you need to identify all of the various systems that are in place and then you need to do analysis to decide the type of fault you may find, followed bya process to create a set of tests covering the paths through integration, i.e., the connection of all these systems. And finally,you have to have a way of predicting the expected results so that you can tell whether the systems have produced thecorrect answer.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 49/93
10. Non-Functional System TestingNon-functional requirements (NFR) relate are those that state how a system will deliver its functionality. NFRs are as importantas functional requirements in many circumstances but are often neglected. The following seven modules provide an introductiono the most important nonfunctional test types.
10.1.Non-functional test typesHere are the seven types of non-functional testing to be covered in the syllabus. Performance and stress testing are themost common form of non-functional test performed, but for the purpose of the examination, you should understand thenature of the risks to be addressed and the focus of each type of test.
•
Load, performance and stress• Security
• Usability
• Storage and Volume
• Installation
• Documentation
• Backup and recovery
10.2.Non-functional requirements
Functional - WHAT the system doesFirst, let’s take an overview of non-functional requirements. Functional requirements say what the system should do.
Non-functional - HOW system does itNon-functional requirements say how it delivers that functionality – for example, it should be secure, have fast responsetime, be usable, and so on.
Requirements difficultiesThe problem with non-functional requirements is that usually they’re not written down. Users naturally assume that a systemwill be usable, and that it will be really fast, and that it will work for more than half the day, etc. Many of these aspects of howa system delivers the functionality are assumptions. So, if you look at a functional spec, you’ll see 200 pages of functionalspec and then, maybe, one page of functional requirements, and then maybe one page of non-functional requirements. If they are written down rather than assumed, they usually aren’t written down to the level of detail that they need to be testedagainst.
Service Level Agreements may define needs.Suppose you’re implementing a system into an existing infrastructure and you will have a service level agreement thatspecifies the service to be delivered – the response times, the availability, security, etc.
Requirements often require further investigation before testing can start.In most cases, it is not until this service level agreement is required that the non-functional requirements are discussed. It iscommon for the first activity of non-functional testing to be to establish the requirements.
10.3.Load, Performance and Stress TestingLet’s establish some definitions about performance testing. We need to separate load, performance, and stress testing.
10.4.Testing with automated loads
Background or load testingBackground or load testing is any test where you have some kind of activity on the system. For example, maybe you want totest for locking in a database. You might run some background transactions and then try to have a transaction thatintercepts these. The purpose of this test clearly is not about response times. It’s usually to see if the functional behaviour of the software changes when there is a load.
Stress testingStress testing is where you push the system as hard as you can, up to its threshold. You might record response times, butstress testing is really about trying to break the system. You increase the load until the system can’t cope with it anymoreand something breaks. Then you fix that and retest. This cycle continues until you have a system that will endure anythingthat daily business can hand it.
Performance testing
Performance testing is not (and this is where it differs from functional testing) a single test. Performance testing aims toinvestigate the behaviour of a system under varying loads. It’s a whole series of tests. And basically, the objective of performance testing is to create a graph based on a whole series of tests. The idea is to measure the response times fromthe extremes of a low transaction rate to very high transaction rate. As you run additional tests with higher loads, theresponse time gets worse. Eventually, the system will fail because it cannot handle the transaction rate. The primarypurpose of the test is to show that at the load that the system was designed for, the response times meet the requirement.Another objective of performance or stress testing is to tune the system, to make it faster.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 50/93
Whether you are doing load testing, performance testing or stress testing, you will need an automated tool to be effective.Performance testing can be done with teams of people, but it gets very boring very quickly for the people that are doing thetesting, it’s difficult to control the test, and often difficult to evaluate the results.
10.5.Formal performance test objectivesThe performance test will need to show that the system meets the stated requirements for transaction throughput. Thismight be that it can process the required number of transactions per hour and per day within the required response times for screen-based transactions or for batch processes or reports. The performance criteria needs to be met while processing therequired transaction volumes using a full sized production database in a production-scale environment.
• To show system meets requirements for
o
transaction throughputo response times
• To demonstrate
o system functions to specification with
o acceptable response times while
o processing the required transaction volumes on
o a production sized database
10.6.Other objectivesPerformance testing will vary depending on the objectives of the business. Frequently there are other objectives besidesmeasuring response times and loads.
Assess system's capacity for growth
The other things that you can learn from a performance test is the system’s capacity for growth. If you have a graphshowing today’s load and performance and then build up to a larger load and measurement of the performance, you willknow how what the effect of business growth will be before it happens.
Stress tests to identify weak pointsWe also use a stress test to identify weak points – that is, to break things under test conditions so that we can make themmore robust for the future and less likely to break in production. We can run the tests for long periods just to see if it willsupport that.
Soak, concurrency tests over extended periods to find obscure bugsSoak or concurrency tests can be run over extended timeframes and after hours of running, may reveal bugs that may onlyrarely occur in a production situation. Bugs detected in a soak test will be easier to trace than those detected in live running.
Test bed to tune architectural componentsWe can use performance tests to tune components. For example, we can try a test with a big server or a faster network. So,it’s a test bed for helping us choose the best components.
10.7.Pre-requisites for performance testingIt all sounds straightforward enough, but before you can run a test, there are some important prerequisites. You might callthese entry criteria.
Measurable, relevant, realistic requirementsYou must have some requirements to test against. This seems obvious, but quite often the requirements are so vague, thatbefore you can do performance testing you need to establish the realistic, detailed performance criteria.
Stable software systemYou must have also have stable software - it shouldn’t crash when you put a few transactions through it. Given that you willbe putting tens of thousands of transactions through a system, if you can’t get more than a few hundred transactionsthrough the system before it falls over, then you’re not ready to do performance testing.
Actual or comparable production hardwareThe hardware and software you will use for the performance testing must be comparable to the production hardware. If it’sgoing to be implemented on the mainframe, you need a mainframe to test it on. If you need servers and wide area networksand you need to simulate thousands of users, then you need to simulate thousands of users. This is not simple at all.
Controlled test environmentYou need a test environment that’s under control. You can’t share it. You’re going to be very demanding on the supportresources when you’re running these tests.
Tools (test data, test running, monitoring, analysis and reporting).And you need tools. Not just one tool but maybe six or seven or eight. In fact, you need a whole suite of tools.
Process.And you need a process. You need an organised way, a method to help you determine what to do and how to do it.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 51/93
10.8.The 'task in hand'
Client application running and response time measurementThe task at hand isn’t just generating a load on an environment and running the application. You also need to take responsetime measurements. In other words, you have to instrument the test.Imagine a fitness test of an athlete on a treadmill in a lab. It’s a controlled environment. The subject has sensors fitted tomonitor pulse rate, oxygen, breathing, oxygen intake, carbon dioxide expelled, blood pressure, sweat, etc. The test is one of monitoring the athlete when running at different speeds over different timeframes. The test could be set up to testendurance or it could be set up to test maximum performance for bursts of activity. No matter what the test is, it is uselessas an experiment, unless the feedback from the sensors is collected.
Load generationWith an application system, you will keep upping the transaction rate and load until it breaks, and that’s the stress test.
Resource monitoring.But knowing the performance of a system is not enough. You must know what part of the system is doing what. Inevitablywhen you first test a client-server system, the performance is poor. But this information is not useful at all unless you canpoint to the bottleneck(s). In other words, you have to have instrumentation.Actually, there’s no limit to what you can monitor. The things to monitor are all the components of the service including thenetwork. The application itself may have instrumentation/logging capability that can measure response times. Mostdatabases have monitoring tools. NT, for example, has quite sophisticated monitoring tools for clients. There’s almost nolimit to what you can monitor. And you should try to monitor everything that you might need because re-running a test tocollect more statistics is very expensive.
10.9.Test architecture schematicLoad generation and client application running don't have to be done by the same tool.
Resource monitoring is normally done by a range of different tools as well as instrumentation embedded in application or middleware code.
In our experience, you always need to write some of your own code to fill in where proprietary tools cannot help.
10.10.Response time/load graphsPerformance testing is about running a series of tests and measuring the performance of different loads. Then you need tolook at the results from a particular perspective. If that is the response time, then look at the maximum load you can applyand still meet the response time requirements. If you are looking at load statistics, you can crank the load up to more thanyour ‘design’ load, and then take a reading.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 52/93
10.11.Test, analyse, refine, tune cyclePerformance testing tends to occur in three stages. One stage is fixing the system to the point where it will run. At first theperformance test ends when the system breaks. Quite literally, you’ll run a test and the database or a server will fall over.
Or the application on the client crashes. Things break and they get fixed. Then the test is rerun until the next thing falls over.The next stage is identifying the areas of very poor performance that need tuning and attention. Typically, this is whensomebody forgot to put the indexes on the database or an entire table of 10,000 rows is being read rather than a single row.The system works (sort of), but it’s slow, dead slow. Or maybe you’re using some unreasonable loads and you’re trying torun 10,000 transactions an hour through an end of month report or something crazy. So, the test itself might also need somerefinement too.Eventually, you get to the point where performance is pretty good, and then you’re into the final stage, producing the graphs.And remember, with performance testing, unlike functional testing when you usually get a system that works when you getto the end, there is no guarantee that you’ll get out of this stage. Just because a supplier has said that an architecture wouldsupport 2,000 users, doesn’t mean that it is actually possible.To recap, performance testing is definitely a non-trivial and complex piece of work. Assuming that you get the prerequisitesof a test environment and decent tools, the biggest obstacles are usually having enough time and stable software. As a ruleof thumb, for a performance test that has value, it usually takes around 8-10 elapsed weeks to reach the point where the
first reliable tests can be run. Then the system breaks and rework is required, and the start of the iteration phase begins.Again, a rule of thumb for an iteration of test, analyse, tune is about two weeks.
10.12.Security TestingThe purpose of this section is not to describe precisely how to do security testing (it’s a specialist discipline that not manypeople can do), but to look at the risks and establish what should be tested.
10.13.Security threats

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 53/93
When we consider security, we normally think of hackers working late into the night, trying to crack into banks andgovernment systems. Although hackers are one potential security problem, the scope of system security spans a broadrange of threats.
Natural or physical disasters such as fire, floods, power failuresSecurity covers undesirable events over which we have no control. However, there are often measures we can take thatprovide a recovery process or contingency.
Accidental faults such as accidental change, deletion of data, lack of backups, insecure disposal of media, poor proceduresEven the best laid plans can be jeopardised by accidents or unforseen chains of events.
Deliberate or malicious actions such as hacking by external people or disgruntled or fraudulent employeesHackers are a popular stereotype presented in the movies. Although the common image of a hacker is of a young collegedropout working long into the night, the most threatening hacker is likely to be a professional person, with intimateknowledge of operating system, networking and application vulnerabilities who makes extensive use of automated tools tospeed up the process dramatically.
10.14.Security Testing
Can an insider or outsider attack your system?There’s an IBM advertisement that illustrates typical security concerns rather well. There are these two college dropouts.One of them says, ‘I’m into the system, I’m in. Look at these vice-presidents, Smith earns twice as much as Jones.’ (He’sinto the personnel records.) 'And it's funny they don’t know about it… well, they do now. I’ve just mailed the whole company
with it'. Whether this is a realistic scenario or not isn't the point - hackers can wreak havoc, if they can get into your systems.
CIA model:The way that the textbooks talk about security is the CIA model.Confidentiality is usually what most people think of when they think of security. The question here is "are unauthorisedpeople looking at restricted data?" The system needs to make certain that authorisation occurs on a person basis and adata basis.The second security point is Integrity. This means not just exercising restricted functionality, but guarding against changes or destruction of data. Could the workings of a system be disrupted by hacking in and changing data?And the third security point is availability. It’s not a case of unauthorized functions, but a matter of establishing whether unauthorised access or error could actually disable the system.
10.15.Testing access control
Access control has two functions:Primarily, if we look at the restrictions of function and data, the purpose of security features and security systems is to stopunauthorized people from performing restricted functions or accessing protected data. And don’t forget the opposite – toallow authorized people to get at their data.
Tests should be arranged accordingly:So, the tests are both positive tests and negative tests. We should demonstrate that the system does what it should anddoesn’t do what it shouldn’t do. Basically, you’ve got to behave like a hacker or a normal person. So, you set up authorisedusers and test that they can do authorized things. And then you test as an unauthorised person and try to do the samethings. And maybe you have to be more devious here and trying getting at data through different routes. It’s pretty clear what you try and do. The issue really is – authorized people, restricted access, and the combinations of those two.
10.16.Security test case exampleWhen testing the access control of a system or application, a typical scenario is to set up the security configuration and thentry to undermine it. By executing tests of authorised and unauthorised access attempts, the integrity of the system can bechallenged and demonstrated.
• Make changes to security parameters
• Try successful (and unsuccessful) logins
• Check:
o are the passwords secure?
o are security checks properly implemented?
o are security functions protected?
10.17.Usability TestingWe’re all much more demanding about usability than we used to be. As the Web becomes part of more and more people'slives, and the choice on the web increases, usability will be a key factor in retaining customers. Having a web site with poor usability may mean the web site (and your business) may fail.
10.18.The need for usability testing
Users are now more demanding

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 54/93
Usability can be critical and not just cosmeticThe issue of usability for web-based systems is critical rather than cosmetic- usability is absolutely a ‘must have’; poor usability will result in poor sales and the company’s image will suffer.Usability requirements may differ. For some systems, the goal of the system is user productivity and if this isn’t achieved,then the system has failed. User productivity can be doubled or halved by the construction of the system.For management/executive information systems (MIS/EIS), for example, the only usability requirement is that it’s easy touse by managers who may access the system infrequently.In the main today, a system has to be usable enough that it makes the users’ job easier. Otherwise, the system will fall intodisuse or never be implemented.
10.19.User requirements
Perceived difficulty in expressing requirementsAgain, as with all non-functional test areas, getting requirements defined is a problem for usability testing. There is aperceived difficulty in writing the rules, e.g., documenting the requirements. It is possible to write down requirements for usability. Some of them are quite clear-cut.
Typical requirements:
• Messages to users will be in plain English. If you’ve got a team of twenty programmers all writing different
messages, inconsistencies with style, content and structure are inevitable.
• Commands, prompts and messages must have a standard format, should have clear meanings and be consistent.
• Help functions should be available, and they need to be meaningful and relevant.
• User should always know what state the system is in. Will the user always know where they are? If the phone ringsand they get distracted, can they come back and finish off their task, knowing how they got where they were?
• Another aspect of usability is the feedback that the system gives them – does it help or does it get in the way?
The system will help (not hinder) the user:The previous slide showed positive things that people want that could be tested for. But there’s also ‘features’ that youdon’t want.
For example, if the user goes to one screen and inputs data, and then goes into another screen and is asked for thedata again, this is a negative usability issue.
The user shouldn’t have to enter data that isn’t required. Think of a paper form where you have to fill box after box of N/A (not applicable). How many of these are appropriate? The programmer may be lazy and put up a blank form,expecting data to be input, and then processing begins. But it is annoying if the system keeps coming back asking for more data or insists that data is input when for this function, it is irrelevant.The system should only display informational messages as requested by the user.To recap, the system should not insist on confirmation for limited choice entries, must provide default values whenapplicable, and must not prompt for data it does not need.
These requirements can be positively identified or measured.To summarise, once you can identify requirements, you can make tests.
10.20.Usability test cases
Test cases based on users' working scenariosWhat do we mean by usability test cases?The way that we would normally approach this issue is to put a user in a room with a terminal or a PC and ask them tofollow some high-level test scripts. For example, you may be asking them to enter an order, but we’re not going to tell themhow to do it on a line-by-line basis. We’re just going to give them a system, a user manual and a sheet describing the data,and then let them get on with it. Afterwards you ask them to describe their experience.
Other considerations:There are a number of considerations regarding usability test cases.There could be two separate tests staged – one for people that have never seen the system and one for the experiencedusers. These two user groups have different requirements; the new user is likely to need good guidance and theexperienced user is likely to be frustrated by over-guidance, slow responses, and lack of short cuts. Of course to be valid,you need to monitor the results (mistakes made, times stuck, elapsed time to enter a transaction, etc.).
10.21.Performing and recording testsUser testing can be done formally in a usability lab. Take, for example, a usability lab for a call centre. Four workstationswere set up, each with a chair and a PC and a telephone head set monitored by cameras and audio recording so that theusers actions could be replayed and analysed. The monitors were wired effectively to a recording studio and observationbooth. From the booth or from replays of the films, you could see what the user did and what they saw on the screen, andalso what they heard and what they said. From watching these films, you can observe where the system is giving them

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 55/93
difficulty. There are usability labs that, for example, record eye blink rates as this allegedly correlates to a users perceptionof difficulty.
• Need to monitor the user
o how often and where do they get stuck?
o number of references to help
o number of references to documentation
o how much time is lost because of the system?
When running usability tests, it is normal practice to log all anomalies encountered during the tests. In a usabilitylaboratory with video and audio capture of the user behaviour and the keystroke capture off the system under test, a
complete record of the testing done can be obtained. This is the most sophisticated, (but expensive) approach, but justhaving witnesses observe users can be very effective.It is common to invite the participants to 'speak their mind' as they work. In this way, the developers can understand thethought processes that users go through and get a thorough understanding of their frustrations.
• Need to monitor faults
o how many wrong screen or function keys etc.
o how many faults were corrected on-line
o how many faults get into the database
• Quality of data compared to manual systems?
• How many keystrokes to achieve the desired objective? (too many?)
10.22.Satisfaction and frustration factors
The fact that your software works and that you think that your instructions are clear, does not mean that it will never gowrong. Just because you’re shipping 100,000 CD’s with installation kits, doesn’t mean that will always work. Even if you’vegot the best QA process in the world – if you’re shipping a shrink-wrapped product, you have to test whether people of varying capability who have never seen anything like this before can install it from the instructions. So, that’s the kind of thing that usability labs are used for.The kind of information that might get captured is how many times mistakes are made. If you have selected appropriateusers for the lab, then the mistakes are due to usability problems in the system.
• Users often express frustration - find out why
• Frustrated expert users
o do menus or excess detail slow them down?
o do trivial entries require constant confirmation
• Frustrated occasional users
o are there excess options that are never used?
o help documentation doesn't help or is irrelevant
o users don't get feedback and reassurance
10.23.Storage and Volume TestingStorage and volume testing are very similar and are often confused. Storage tests address the problem of a systemexpanding beyond its capacity and failing. Volume testing addresses the risk that a system cannot handle the largest (andsmallest) tasks that users need to perform.
Storage tests demonstrate that a system's usage of disk or memory is within the design limits over time e.g. can the systemhold five-years worth of system transactions?The question is, "can a system, as currently configured, hold the volume of data that we need to store in it?"Assume you are buying an entire system including the software and hardware. What you’re buying should last longer than
six months, or more than a year, or maybe five years. You want to know whether the system that you buy today can support,say, five years worth of historical data.So, for storage testing, you aim to predict the eventual volume of data based on the number of transactions processed over the system's lifetime. Then, by creating that amount of data, you test that the system can hold it and still operate correctly.
Volume tests demonstrate that a system can accommodate the largest (& smallest) tasks it is designed to perform e.g. canend of month processes be accommodated?The volume-tests are simply looking at how large (or small) a task can the system accommodate?Not how many transactions per second (i.e. transaction rate), but how big a task in terms of the number of transactions intotal? The limiting resource might be long-term storage on disk, but it might also be short-term storage in memory, as well.Rather than you saying, we want to get hundreds of thousands of transactions per hour through our system, we are asking,‘can we simultaneously support a hundred users, or a thousand users’? We want to push the system to accommodate asmany parallel streams of work as it has been designed for...and a few more.
10.24.RequirementsMany people wouldn't bother testing the limits of a system if they thought that the system would give them plenty of warningas a limit is approached so that the eventual failure is predictable. Disk space is compatively cheap these days so storagetesting is not the issue it once was. On the other hand, systems are getting bigger and bigger by the day and the failuresmight be more extreme.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 56/93
Requirement is for the system to:Testing the initial and anticipated storage and volume requirements involves loading the data to the levels specified in therequirements documents and seeing if the system still works. You can’t just create a mountain of dummy data and then walkaway.
If the system becomes overloaded (in terms of data volumes) thenStorage and volume testing should also include the characteristics of the system when it is approaching the design limits(say, the maximum capacity of a database). When the system approaches the threshold, does the system crash or does itwarn you that the limits are going to be exceeded? Is there a way to recover the situation if it does fail? In IT, when a systemfails in a way which we can do something about it, we say that it 'fails gracefully'.
10.25.Running testsWhen you run tests on a large database, you’re going to wait for failures to occur. You have to consider that as you keepadding rows, eventually it will fail. What happens when it does fail? Do you have a simple message and no one can processtransactions or is it less serious than that? Do you get warnings before it fails?
The test requires the application to be used with designed data volumes
Creation of the initial database by artificial means if necessary (data conversion or randomly generated)How do you build a production-sized database for a new system? To create a production-sized database you may need togenerate millions and millions of rows of data which obey the rules of the database.
Use a tool to execute selected transactions
You almost certainly can’t use the application because you’d have to run it forever and ever, until you could get that amountof data in. The issue there is that you have to use a tool to build up the database. But you need very good knowledge of thedatabase design.
automated performance test if there is oneYou may need to run a realistic performance test. Volume tests usually precede the performance tests because you can re-use the production-sized database for performance testing.
10.26.Pre-requisitesWhen constructing storage and volume tests there are certain pre-requisites that must be arranged before testing can start.It is common, as in many non-functional areas, for there to be no written requirements. The tester may need to conductinterviews and analysis to document the actual requirements.Often the research required to specify these tests is significant and requires detailed technical knowledge of the application,
the business requirements, the database structure and the overall technical architecture.• Technical requirements
o database files/tables/structures
o initial and anticipated record counts
• Business requirements
o standing data volumes
o transaction volumes
• Data volumes from business requirements using system/database design knowledge.
10.27.Installation TestingInstallation testing is relevant if you’re selling shrink-wrapped products or if you expect your 'customers', who may be in-house users, to do installations for themselves.
If you are selling a game or a word-processor or a PC-operating system, and it goes in a box with instructions, an install kit,a manual, guarantees, and anything else that’s part of the package, then you should consider testing the entire packagefrom installation to use.
The installation process must work because if it’s no good, it doesn’t matter how good your software is; if people can’t getyour software installed correctly, they’ll never get your software running - they'll complain and may ask for their money back.
10.28.Requirements
Can the system be installed and configured using supplied media and documentation?
shrink-wrapped software may be installed by naïve or experienced users
server or mainframe-based software or middleware usually installed by technical staff
The least tested code and documentation?The installation pack is, potentially, the least tested part of the whole product because it’s the very last thing that you can do.The absolutely last thing you can do, because you may have burnt the CD’s already. Once you've burnt the CD's, they can’t be

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 57/93
changed. There’s a very short period of time between having a stable, releasable product and shipping it. So, installation testingcan be easily forgotten or done minimally.
he last thing written, so may be flaky, but is the first thing the user will see and experience.
10.29.Running testsTests are normally run on a clean, 'known' environment that can be easily restored (you may need to do this several times).
Typical installation scenarios are to install, re-install, de-install the product and verify the correct operation of the product inbetween installations.
The integrity of the operating system and the operation of other products that reside on the system under test is also amajor consideration. If a new software installation causes other existing products to fail, users would regard this as a veryserious problem. Diagnosis of the cause is normally extremely difficult and restoration of the orginal configuration is often acomplicated, risky affair. Because the risk is so high, this form of regression testing must be included in the overallinstallation test plan to ensure that your users are not seriously inconvenienced.
• On a 'clean' environment, install the product using the supplied media/documentation
• For each available configuration:
o are all technical components installed?
o does the installed software operate?
o do configuration options operate in accordance with the documentation?
• Can the product be reinstalled, de-installed cleanly?
10.30.Documentation testing
The product to be tested is more than the softwareThe product to be tested is more than just the software. When the user buys software, they might receive a CD-Romcontaining the software itself, but they also buy other materials including the user guide, the installation pack, theregistration card, the instructions on the outside, etc.
Documentation can be viewed as all of the material that helps users use the software. In addition to the installation guide,the user guide, it also includes online Help, all of the graphical images and the information on the packaging box itself.If it is possible for these documents to have faults, then you should consider testing them.
• Documentation can include:
o user manuals, quick reference cards
o installation guides, online help, tutorials, read me files, web site information
o packaging, sample databases, registration forms, licences, warranty, packing lists...
10.31.Risks of poor documentationDocumentation testing consists of checking or reviewing all occurrences of forms and narratives for accuracy and clarity. If the documentation is poor, people will perceive that the product is of low quality.No matter how good the product is, if the documentation is weak, it will taint the users' view of the product.
• Software unusable, error prone, slower to use
• Increased costs to the supplier
o support desk becomes a substitute for the manual
o many problems turn out to be user errors
o many 'enhancements' requested because the user can't figure out how to do things
• Bad manuals turn customers off the product
• Users assume software does things it doesn't and may sue you!
10.32.Hardcopy documentation test objectives
Accuracy, completeness, clarity, ease of useDocumentation testing tends to be very closely related to usability.
Does the document reflect the actual functionality of the documented system?User documentation should reflect the product, not the requirements. Are there features present that are not documented, or worse still, are there features missing from the system?
Does the document flow reflect the flow of the system?
User documentation should follow the path or flow that a user is likely to use, and not just describe features one by onewithout attention to their sequence of use. This means that you have to test documentation with the product.
Does the organisation of the document make it easy to find material?Since the purpose of documentation is to make usage of the system easier, the organisation of the documentation is a keyfactor in achieving this objective.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 58/93
10.33.Documentation test objectives
Documentation may have several drafts and require multiple testsEarly tests concentrate on target audience, scope, organisation issues - reviewed against system requirements documents.Later tests concentrate on accuracy. Eventually, we will use the documentation to install and operate the system and this of course has to be as close to perfect as possible.Documentation tests often find faults in the software. Overall, tests should concentrate on content, not style.
Online help has a similar approachTypical checks of on-line documentation cover:does the right material appear in the right context?have online help conventions been obeyed?do hypertext links work correctly?is the index correct and complete?Online help should be task-oriented: is it easy to find help for common tasks? Is help concise, relevant, useful?
10.34.Backup and Recovery TestingWe have all experienced hardware and software failures. The processes we use to protect ourselves from loss of our mostprecious resource (data) are our backup and recovery procedures.
Backup and recovery tests demonstrate that these processes work and can be relied upon if a major failure occurs.
The kind of scenarios and the typical way that tests are run is to perform full and partial backups and to simulate failures,
verifying that the recovery processes actually work. You also want to demonstrate that the backup is actually capturing thelatest version of the database, the application software, and so on.
• Can incremental and full system backups be performed as specified?
• Can partial and complete database backups be performed as specified?
• Can restoration from typical failure scenarios be performed and the system recovered?
10.35.Failure scenarios
A large number of scenarios are possible, but few can be tested. The tester needs to work with the technical architect toidentify the range of scenarios that should be considered for testing. Here are some examples.
• Loss of machine - restoration/recovery of entire environment from backups
• Machine crash - automatic database restoration/recovery to the point of failure
• Database roll-back to a previous position and roll-forward from a restored position
Typical Test Senario
Typically you take checkpoints using reports showing specific transactions and totals of particular subsets of data as you goalong. Start by performing a full backup, then do some reports, execute a few transactions to change the content of thedatabase and rerun the reports to demonstrate that you have actually made those changes, followed by an incrementalbackup.
Then, reinstall the system from the full backup, and verify with the reports that the data has been restored correctly. Applythe incremental back up and verify the correctness, again by rerunning the reports. This is typical of the way that tests of minor failures and recover scenarios are done.
• Perform a full backup of the system
o
Execute some application transactionso Produce reports to show changes ARE present
• Perform an incremental backup
• Restore system from full backup
o Produce reports to show changes NOT present
• Restore system from partial backup
o Produce reports to show changes ARE present.
While entering transactions into the database, bring the machine down by causing (or simulating) a machine crashYou can also do more interesting tests that simulate a disruption. While entering transactions into the system, bring themachine down - pull the plug out, do a shut-down, or simulate a machine crash. You should, of course, seek advice from thehardware engineers of the best way to simulate these failures without causing damage to servers, disks, etc.
Reboot the machine and demonstrate by means of query or reporting, that the database has recovered the transactionscommitted up to the point of failure.The principle is again that when you reboot the system and bring it back on line, you have to conduct a recovery from thefailure. This type of testing requires you to identify components and combinations of components that could fail, andsimulate the failures of whatever could break, and then using your systems, demonstrate that you can recover from this.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 59/93
11. Maintenance TestingThe majority of effort expended in the IT industry is to do with maintenance. The problem is that the textbooks don’t talk aboutmaintenance very much because it's often complicated and 'messy'. In the real world, systems last longer than the project thatcreated them. Consequently, the effort required to repair and enhance systems during their lifetime exceeds the effort spentbuilding them in the first place.
11.1.Maintenance considerations
Poor documentation makes it difficult to define baselinesThe issue with maintenance testing is often that the documentation, if it exists, is not relevant or helpful when it comes todoing testing.
Maintenance changes are often urgentSpecifically here we are talking about corrective maintenance, that is, bug-fixing maintenance rather than newdevelopments. The issue about bug-fixing is that it’s often required immediately. If it is a serious bug that’s just come to light,it has to be fixed and released back into production quickly. So, there is pressure not to do elaborate testing. And don’tforget, there’s pressure on the developer to make the change in a minimal time. This situation doesn’t minimise his error rate!
11.2.Maintenance routesEssentially, there are two ways of dealing with maintence changes. Maintenance fixes are normally packaged intomanageable releases.
•
Groups of changes are packaged into releases; for adaptive or non-urgent corrective maintenance.• Urgent changes handled as emergency fixes; usually for corrective maintenance
It is often feasible to treat maintenance releases as abbreviated developments. Just like normal development, there are twostages: definition and build.
11.3.Release DefinitionMaintenance programmers do an awful lot of testing. Half of their work is usually figuring out what the software does and thebest way to do this is to try it out. They do a lot of investigation initially to find out how the system works. When they havechanged the system, they need to redo that testing.
Development Phase/Activity Maintenance Tasks
Feasibility Evaluate Change Request (individually) toestablish feasibility and priority
Package Change Requests into amaintenance package
User Requirements Specification Elaborate Change Request to get fullrequirements
Design Specify changesDo Impact AnalysisSpecify secondary changes
11.4.Maintenance and regression testing
Maintenance package handled like development except testing focuses on code changes and ensuring existing functionalitystill works
What often slips is the regression testing unless you are in a highly disciplined environment. Unless you’ve got anautomated regression test pack, maintenance regression testing is usually limited to a minimal amount. That’s whymaintenance is risky.
If tests from the original development project exist, they can be reused for maintenance regression testing, but it's morecommon for regression test projects aimed at building up automated regression test packs to have to start from scratch.If the maintenance programmers record their tests, they can be adapted for maintenance regression tests.
Regression testing is the big effort. Regression testing dominates the maintenance effort as it is usually takes more thanhalf of the total effort for maintenance. So, part of your maintenance budget must be to do a certain amount of regressiontesting and, potentially, automation of that effort as well.
Maintenance fixes are error-prone - 50% chance of introducing another fault so regression testing is key
Regression testing dominates test effort - even with tool support
If release is urgent and time is short, can still test after release
11.5.Emergency maintenance

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 60/93
You could make the change and install it, but test it in your test environment. There’s nothing stopping you from continuingto test the system once it’s gone into production. In a way, this is a bit more common than it should be.Releasing before all regression testing is complete is risky, but if testing continues, the business may not be exposed for toolong as any bugs found can be fixed and released quickly.
• Usually "do whatever is necessary"
• Installing an emergency fix is not the end of the process
• Once installed you can:
o continue testing
o include it for proper handling in the next maintenance release

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 61/93
12. Introduction to Testing Techniques ( C & D)
12.1.Test Techniques and the Lifecycle
12.2.Testing throughout the life cycle: the W model
12.3.Comparative testing efficiencies
Module C: Black Box or Functional Testing
12.3.1.Equivalence Partitioning
12.3.1.1.1.Equivalence partitioning
12.3.1.1.2.Equivalence partitioning example
12.3.1.1.3.Identifying equivalence classes
12.3.1.1.4.Output partitions
12.3.1.1.5.Hidden partitions
12.3.2.Boundary Value Analysis
12.3.2.1.Boundary value analysis example
12.4.White Box or Structural Testing
12.4.1.Statement Testing and Branch Testing
12.4.1.1.1.Path testing
12.4.1.1.2.Models and coverage
12.4.1.1.3.Branch coverage
12.4.1.1.4.Coverage measurement
12.4.1.1.5.Control flow graphs
12.4.1.1.6.Sensitising the paths
12.4.1.1.7.From paths to test cases
12.5.White Box vs. Black Box Testing
12.6.Effectiveness and efficiency
12.7.Test Measurement Techniques
12.8.Error Guessing
12.8.1.Testing by intuition and experience
12.8.2.Examples of traps
Module D: Reviews or Static Testing
i. Why do peer reviews?
ii. Cost of fixing faults
iii. Typical quantitative benefits
iv. What and when to review
v. Types of Review

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 62/93
vi. Levels of review 'formality'
vii. Informal reviews
viii. Walkthroughs
ix. Formal technical review
x. Inspections
xi. Conducting the review meeting
xii. Three possible review outcomes
xiii. Deliverables and outcomes of a review
xiv. Pitfalls
g. Static Analysis
i. Static analysis defined
ii. Compilers
iii. 'Simple' static analysis
iv. Data flow analysis
v. Definition-use examples
vi. Nine possible d, k, and u combinations
vii. Code and control-flow graph
viii. Control flow graph
ix. Control flow (CF) graphs and testing
x. Complexity measures

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 63/93
Module E : Test Management
h. OrganisationWe need to consider how the testing team will be organised. In small projects, it might be an individual who simply has toorganise his own work. In bigger projects, we need to establish a structure for the various roles that different people in theteam have. Establishing a test team takes time and attention in all projects.
i. Who does the testing?
So who does what in the overall testing process?
Programmers do the ad-hoc testingIt’s quite clear that the programmers should do the ad hoc testing. They probably code a little and test a little simply todemonstrate to themselves that the last few lines of code they have created work correctly. It’s informal, undocumentedtesting and is private to the programmer. No one outside the programming team sees any of this.
Programmers, or other team members may do sub-system testingSubsystem testing is component testing and link testing. The programmers who wrote the code and interfaces normally dothe testing simply because it requires a certain amount of technical knowledge. On occasions, it might be conducted byanother member of the programming team, either to introduce a degree of independence or to spread out the workload.
Independent teams usually do system testingSystem testing addresses the entire system. It is the first point at which we’d definitely expect to see some independent test
activity (in so far as the people who wrote the code won’t be doing the testing). For a nontrivial system, it’s a large-scaleactivity and certainly involves several people requiring problem management and attention to organisational aspects. Teammembers include dedicated testers and business analysts or other people from the IT department, and possibly someusers.
Users (with support) do the users acceptance testingUser acceptance testing, on the other hand, is always independent. The users bring their business knowledge to thedefinition of a test. However, they normally need support on how to organise the overall process and how to construct testcases that are viable.
Independent organisations may be called upon to do any of the above testing formally.On occasions there is a need to demonstrate complete independence in testing. This is usually to comply with someregulatory framework or perhaps there is particular concern over risks due to a lack of independence. An independent
company may be hired to plan and execute tests. In principle, third party companies and outsource companies, can do anyof the layers of testing from component through system or user acceptance testing, but it’s most usual to see them doingsystem testing or contractual acceptance testing.
j. Independence
Independence of mind is the issueWhen we think about independence in testing, it’s not who runs the test that matters. If a test has been defined in detail, theperson running the test will be following instructions (put simply, the person will be following the test script). Whether a toolor a person executes the tests is irrelevant because the instructions describe exactly what that tester must do. When a testfinds a bug, it’s very clear that it’s the person who designed that test that has detected the bug and not the person whoentered the data. So, the key issue of independence is not who executes the test but who designs the tests.
Good programmers can test their own code if they adopt the right attitudeThe biggest influence on the quality of the tests is the point of the view of the person designing those tests. It’s very difficultfor a programmer to be independent. They find it hard to eliminate their assumptions. The problem a programmer has is thatsub-consciously they don’t want to see their software fail. Also, programmers are usually under pressure to get the job donequickly and they are keen to write the next new bit of code which is what they see as the interesting part of the job. Thesefactors make it very difficult for them to construct test cases and have a good chance of detecting faults.Of course, there are exceptions and some programmers can be good testers. However, their lack of independence is abarrier to them being as effective as a skilled independent tester.
Buddy-checks/testing can reduce the risk of bad assumptions, cognitive dissonance etc.A very useful thing to do is to get programmers in the same team to swap programs so that they are planning andconducting tests on their colleague’s programs. In doing this, they bring a fresh viewpoint because they are not intimatelyfamiliar with the program code; they are unlikely to have the same assumptions and they won’t fall into the trap of ‘seeing’
what they want to see. The other reason that this approach is successful is that programmers feel less threatened by their colleagues than by independent testers.
Most important is who designs the testsTo recap, if tests are documented, then the test execution should be mechanical; that is, anyone could execute those tests.Independence doesn’t affect the quality of test execution, but it significantly affects the quality of test design. The only

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 64/93
reason for having independent people execute tests would be to be certain that the tests are actually run correctly, i.e.,using a consistent set of data and software (without manual intervention or patching) in the designated test environment.
k. Test team roles
Test manager A Test Manager is really a project manager for the testing project; that is, they plan, organise, manage, and control thetesting within their part of the project.There are a number of factors, however, that set a Test Manager apart from other IT project managers. For a start, their keyobjective is to find faults and on the surface, that is in direct conflict with the overall project’s objective of getting a productout on time. To others in the overall project, they will appear to be destructive, critical and sceptical. Also, the nature of thetesting project changes markedly when moving from early stage testing to the final stages of testing. Lastly, a test manager needs a set of technical skills that are quite specific. The Test Manager is a key role in successful testing projects.
Test analystTest analysts are the people, basically, who scope out the testing and gather up the requirements for the test activities tofollow.In many ways, they are business analysts because they have to interview users, interpret requirements, and construct testsbased on the information gained.Test analysts should be good documenters, in that they will spend a lot of time documenting test specifications, and theclarity with which they do this is key to the success of the tests.The key skills for a test analyst are to be able to analyse requirements, documents, specifications and design documents,and derive a series of test cases. The test cases must be reviewable and give confidence that the right items have been
covered.Test analysts will spend a lot of time liasing with other members of the project team.Finally, the test analyst is normally responsible for preparing test reports, whether they are involved in the execution of thetest or not.
Tester What do testers do? Testers build tests. Working from specifications, they prepare test procedures or scripts, test data, andexpected results. They deal with lots of documentation and their understanding and accuracy is key to their success. As wellas test preparation, testers execute the tests and keep logs of their progress and the results. When faults are found, thetester will retest the repaired code, usually by repeating the test that detected the failure. Often a large amount of regressiontesting is necessary because of frequent or extensive code changes and the testers execute these too. If automation is wellestablished, a tester may be in control of executing automated scripts too.
Test automation technicianThe people who construct automated tests, as opposed to manual tests, are ‘test automation technicians’. These peopleautomate manual tests that have been proven to be valuable. The normal sequence of events is for the test automationtechnician to record (in the same way as a tape-recorder does) the keystrokes and actual outputs of the system. Therecording of the test scripts is used as input to the automation process where using the script language provided by the toolthey will be manipulated into an automated test.The role of the test automation technician is therefore to create automated test scripts from manual tests and fit them into anautomated test suite. The automated scripts are small programs that must be tested like any other program. These testscripts are often run in large numbers.Other activities within the scope of the test automation technician is the preparation of test data, test cases, and expectedresults based on documented (designed) test plans. Very often, they need to invent ‘dummy data’ because every item of data will not be in the test plan. The test automation technician may also be responsible for executing the automated scriptsand preparing reports on the results if tool expertise is necessary to do this.
l. Support staff
DBA to help find, extract, manipulate test dataEvery system has a database as its core. The DBA (database administrator) will need to support the activities of the tester for setting up the test database. They may be expected to help find, extract, manipulate, and construct test data for use intheir tests. This may involve the movement of large volumes of data as it is common for whole databases to be exportedand imported at the end and start of test cycles. The DBA is a key member of the team.
System, network administratorsThere are a whole range of technical staff that needs to be available to support the testers and their test activities,particularly, from system testing through to acceptance testing.. Operating system specialists, administrators and network administrators may be required to support the test team,
particularly in the non-functional side of testing. In a performance test, for example, system and network configurations mayhave to change to improve performance.
Toolsmiths to build utilities to extract data, execute tests, compare results etc.Where automation is used extensively, a key part of any large team involves individuals known as tool smiths, that is,people able to write software as required. These are people who have very strong technical backgrounds; programmers,

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 65/93
who are there to provide utilities to help the test team. Utilities may be required to build or extract test data, to run tests, asharnesses, drivers and to compare results.
Experts to provide directionThere are two further areas where specialist support is often required. On the technical side, the testers may needassistance in setting up the test environment. From a business perspective, expertise may be required to construct systemand acceptance tests that meet the needs of business users. In other words, the test team may need support from expertson the business.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 66/93
i. Configuration ManagementConfiguration Managemenr or CM is the management and control of the technical resources required to construct a softwareartefact. A brief definition, but the management and control of software projects is a complex undertaking, and manyorganisations struggle with chaotic or non-existent control of change, requirements, software components or build.t is the lack of such control that causes testers particular problems. Because of this, CM is introduced to give a flavour of thesymptoms of poor CM and the four disciplines that make up CM.
m. Symptoms of poor configuration management
Can't find latest version of source code or match source to objectThe easiest way to think about where configuration management (CM) fits is to consider some of the symptoms of poor configuration management. Typical examples are when the developer cannot find the latest version of the source codemodule in development or no one can find the source code that matches the version in production.
Can't replicate previously released version of code for a customer Or if you are a software house and you can’t find the customised version of software that was released to a single customer and there’s a fault reported on it.
Bugs that were fixed suddenly reappear Another classic symptom of poor CM is that a bug might have been fixed, the code retested and signed off, and then thebug reappears in a later version.What might have happened was that the code was fixed and released in the morning, and then in the afternoon it was
overwritten by another programmer who was working on the same piece of code in parallel. The changes made by the firstprogrammer were overwritten by the old code so the bug reappeared.
Wrong functionality shippedSometimes when the build process itself is manual and/or unreliable, the version of the software that is tested does notbecome the version that is shipped to a customer.
Wrong code testedAnother typical symptom is that after a week of testing, the testers report the faults they have found only to be told by thedevelopers ‘actually, you’re testing the wrong version of the software’.
Symptoms of poor configuration management are extremely serious because they have significant impacts on testers; mostobviously on productivity, but it can be a morale issue as well because it causes a lot of wasted work.
Tested features suddenly disappear Alternatively, tested features might suddenly disappear. The screen you might have tested in the morning, is no longer visible or available in the afternoon.
Can't trace which customer has which version of codeThis becomes a serious support issue, usually undermining customer confidence.
Simultaneous changes made to same source module by multiple developers and some changes lost.Some issues of control are caused by developers themselves, overwriting each other’s work. Here’s how it happens.There are two changes required to the same source module. Unless we work on the changes serially, which causes adelay, two programmers may reserve the same source code. The first programmer finishes and one set of changes isreleased back into the library. Now what should happen is that when the second programmer finishes, he applies the
changes of the first programme to his code. Faults occur when this doesn’t happen! The second programmer releaseshis changed code back into the same library, which then overwrites the first programmer’s enhancement of the code.This is the usual cause of software fixes suddenly disappearing.
n. Configuration management defined"A four part discipline applying technical and administrative direction, control and surveillance at discrete points in time for the purpose of controlling changes to the software elements and maintaining their integrity and traceability throughout thesystem development process."
Configuration Management, or CM, is a sizeable discipline and takes three to five days to teach comprehensively. However,in essence, CM is easy to describe. It is the "control and management of the resources required to construct a softwareartefact".However, although the principles might be straightforward, there is a lot to the detail. CM is a very particular process that
contributes to the management process for a project. CM is a four-part discipline described on the following slides.
o. The answers Configuration Management (CM) provides
What is our current software configuration?

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 67/93
When implemented, CM can provide confidence that the changes occurring in a software project are actually under control.CM can provide information regarding the current software configuration; whatever version you’re testing today, you canaccurately track down the components and versions comprising that release.
What is its status?A CM system will track the status of every component in a project, whether that be tested, tested with bugs, bugs fixed butnot yet tested, tested and signed off, and so on.
How do we control changes to our configuration?Before a change is made, a CM system can be used to identify, at least at a high level, the impact on any other componentsor behaviour in the software. Typically, an impact-analysis can help developers understand when they make a change to asingle component, what other components call the one that is being changed. This will give an indication as to whatpotential side effects could exist when the change has been made.
What changes have been made to our software?Not only will a CM system have information about current status, it will also keep a history of releases so that the version of any particular component within that release can be tracked too. This gives you trace-ability back to changes over thecourse of a whole series of releases.
Does anyone else's changes affect our software?The CM system can identify all changes that have been made to the version of software that you are now testing. In thatrespect, it can contribute to the focus for testing on a particular release.
p. Software configuration managementThere are four key areas of Configuration Management or "CM". Configuration Identification relates to the identification of every component that goes into making an application. Very broadly, these are details like naming conventions, registrationof components within the database, version and issue numbering, and control form numbering.
In Status Accounting, all the transactions that take place within the CM system are logged, and this log can be used for accounting and audit information within the CM library itself. This aspect of CM is for management.
Configuration Auditing is a checks and balances exercise that the CM tool itself imposes to ensure integrity of the rules,access rights and authorisations for the reservation and replacement of code.
Configuration Control has three important aspects: the Controlled Area/Library, Problem/Defect Reporting, and ChangeControl.
The Controlled Area/Library function relates to the controlled access to the components; the change, withdrawal, andreplacement of components within the library. This is the gateway that is guarded to ensure that the library is not changed inan unauthorized way.
The second aspect of Configuration Control is problem or defect reporting. Many CM systems allow you to log incidents or defects against components. The logs can be used to drive changes within the components in the CM system. For example,the problem defect reporting can tell you which components are undergoing change because of an incident report. Also, for

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 68/93
a single component, it could tell you which incidents have been recorded against that component and what subsequentchanges have been made.The third area of Configuration Control is Change Control itself. In principle, this is the simple act of identifying whichcomponents are affected by a change and maintaining the control over who can withdraw and change code from thesoftware library. Change Control is the tracking and control of changes.
q. CM support to the tester
What does configuration management give to the tester?
A strong understanding and implementation of CM helps testers...A well-implemented CM system helps testers manage their own testware, in parallel with the software that is being tested.
Manage their own testware and their revision levels efficientlyIn order to ensure that the test materials are aligned with the versions of software components, a good CM system allowstest specifications and test scripts to be held or referenced within the CM system itself (whether the CM system holds thetestware items or the references to them doesn’t really matter).
Associate a given version of a test with the appropriate version of the software to be testedWith the test references recorded beside the components, it is possible to relate the tests used to each specific version of the software.
Ensure traceability to requirements and problem reports.The CM system can provide the link between requirements documents, specifications, test plans, test specifications, andeventually to an incident report. Some CM tools provide support to testers throughout the process and some CM systems
just have the incident reporting facilities that relate directly to the components within a CM system.
Ensure problem reports can identify s/w and h/w configurations accuratelyIf the CM system manages incident reports, it’s possible to identify the impact of change within the CM system itself. Whenan incident is recorded or logged in the CM system under ‘changes made to a component’, the knock-on effects in other areas of the software can potentially be identified through the CM system. This report will give an idea of the regressiontests that might be worth repeating.
Ensure the right thing is built by developmentGood CM also helps to ensure that the developers actually build the software correctly. By automating part of the process, agood CM tool eliminates human errors from the build process itself.
Ensure the right thing is testedThis is obviously a good thing because it ensures that the right software is tested.
Ensure the right thing is shipped to the customer.And the right software is shipped to a customer. In other words, the processes of development, testing and release to thecustomer’s site are consistent. Having this all under control improves the quality of the deliverable and the productivity of the team.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 69/93
r. CM support to the project manager
A strong understanding and implementation of CM helps the project manager to:
A CM tool provides support to the project manager too. A good CM implementation helps the project manager understandand control the changes to the requirements, and potentially, the impacts.
It allows the project members to develop code, knowing that they won’t interfere with each other’s code, as they reserve,create, and change components within the CM system.
Programmers are frequently tempted to ‘improve’ code even if there are no faults reported; they will sometimes makechanges that haven’t been requested in writing or supported by requirements statements. These changes can causeproblems and a good CM tool makes it less likely and certainly more difficult for the developers to make unauthorisedchanges to software.
The CM system also provides the detailed information on the status of the components within the library and this gives theproject manager a closer and more technical understanding of the project deliverables themselves.Finally, the CM system ensures the traceability of software instances right back to the requirements and the code that hasbeen tested.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 70/93
i. Test Estimation, Monitoring, and Controln this module, we consider the essential activities required to project manage the test effort. These are estimation, monitoringand control. The difficulty with estimation is obvious: the time taken to test is indeterminate, because it depends on the quality of he software - poor software takes longer to test. The paradox here, is that we won't know the quality of the software until wehave finished testing.
Monitoring and control of test execution is primarily concerned with the management of incidents. When a system is passed intohe system-level testing, confidence in the quality of the system is finally determined. Confidence may be proved to be wellfounded or unfounded. In chaotic environments, system test execution can be traumatic because many of the assumptions of completeness and correctness may be found wanting. Consequently, the management of system level testing demands a highevel of management commitment and effort.
The big questions - "How much testing is enough?" also arises. Just when can we be confident that we have done enoughesting, if we expect that time will run out before we finish? According to the textbook, we should finish when the test completioncriteria are met, but handling the pressure of squeezed timescales is the final challenge of software test management.
s. Test estimatesIf testing consumes 50% of of the development budget, should test planning comprise 50% of all project planning?
Test Stage NotionalEstimate
Unit 40%
Link/Integration 10%
System 40%
Acceptance 10%
Ask a test manager how long it will take to test a systemand they’re likely to say, ‘How long is a piece of string?’
To some extent, that’s true, but only if you don’t scopethe job at all! It is possible to make reasonableestimates if the planning is done properly and theassumptions are stated clearly.Let’s start by looking at how much of the project cost istesting. Textbooks often quote that testing consumesapproximately 50% of the project budget on theaverage. This can obviously vary depending on theenvironment and the project. This figure assumes thattest activities include reviews, inspections, documentwalk-throughs (project plans, design and requirements),as well as the dynamic testing of the softwaredeliverables from components through to complete
systems. It’s quite clear that the amount of effortconsumed by testing is very significant indeed.If one considers the big test effort in a project is,perhaps, half of the total effort in a project, it’sreasonable to propose that test planning, the planningand scheduling of test activities, might consume 50% of all project planning. And that’s quite a serious thing toconsider.
t. Problems in estimating
Total effort for testing is indeterminateLet’s look at the problems in estimating; the difficulty that we have with estimating is that the total effort for testing is
indeterminate.If you just consider test execution, you can’t predict before you start how many faults will be detected. You certainly can’tpredict their severity; some may be marginal, but others may be real ‘show stoppers’. You can’t predict how easy or difficultit will be to fix problems. You can’t predict the productivity of the developers. Although some faults might be trivial, othersmight require significant design changes. You can’t predict when testing will stop because you don’t know how many timesyou will have to execute your system test plan.
But if you can estimate test design, you can work out ratios.However, you can still estimate test design, even if you cannot estimate test execution. If you can estimate test design,there are some rules of thumb that can help you work out how long you should provisionally allow for test execution.
Total effort for testing is indeterminateLet’s look at the problems in estimating; the difficulty that we have with estimating is that the total effort for testing is
indeterminate.If you just consider test execution, you can’t predict before you start how many faults will be detected. You certainly can’tpredict their severity; some may be marginal, but others may be real ‘show stoppers’. You can’t predict how easy or difficultit will be to fix problems. You can’t predict the productivity of the developers. Although some faults might be trivial, othersmight require significant design changes. You can’t predict when testing will stop because you don’t know how many timesyou will have to execute your system test plan.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 71/93
But if you can estimate test design, you can work out ratios.However, you can still estimate test design, even if you cannot estimate test execution. If you can estimate test design,there are some rules of thumb that can help you work out how long you should provisionally allow for test execution.
u. Allowing enough time to test
Allow for all stages in the test processOne reason why testing often takes longer than the estimate is that the estimate hasn’t included all of the testing tasks! Inother words, people haven’t allowed for all the stages of the test process.
Don't underestimate the time taken to set up the testing environment, find data etc.For example, if you’re running a system or acceptance test, the construction, set-up and configuration of a test environmentcan be a large task. Test environments rarely get created in less than a few days and sometimes require several weeks.
Testing rarely goes 'smoothly'Part of the plan must also allow for the fact that we are testing to find faults. Expect to find some and allow for system teststo be run between two and three times.
v. 1 – 2 – 3 rulesThe ‘1-2-3 Rule’ is useful, at least, as a starting point for estimation. The principle is to split the test activities into threestages – specification, preparation, and execution. The ‘1-2-3 Rule’ is about the ratio of the stages.
1 day to specify tests (the test cases)
For every day spent on the specification of the test (the test cases or in other words, a description of the conditions to betested), then it will take two days to prepare the tests.
2 days to prepare testsIn the test preparation step we are including specifying the test data, the script, and the expected results.
1-3 days to execute tests (3 if it goes badly)Finally, we say that if everything goes well, it will take one-day to execute the test plan. If things go badly, then it may takethree days to execute the tests.
1-2-3 is easy to remember, but you may have different ratiosSo, the rule becomes ‘one day to specify’, ‘two days to prepare’, ‘one day to execute if everything goes well’. Now, becausewe know that testing rarely goes smoothly, we should allow for 3 days to execute the tests. And that is the ‘3’ in the ‘1-2-3’
rule. The idea of ‘1-2-3’ is easy to remember, but you have to understand that the ratios are based on experience that maynot be applicable to your environment. It may be because of the type of system, the environment, the standards applicable,the availability of good test data, the application knowledge of the testers assigned or any number of other factors, whichmay cause these ratios to vary. From your experience, you may also realize that perhaps, a one-day allowance for aperfectly running test may be way too low. And in fact, it may be that the ratio of test execution to specification is muchhigher than 3, when it goes badly.
Important thing is to separate spec/prep/exe.The key issue is to separate specification from preparation and execution and then allocate ratios relating to your ownenvironment and experience.
w. Estimate versus actualHere's an example of what might happen, the first time you use the 1-2-3 rule. Typically, things will not go exactly as
planned. However, the purpose of an estimate is to have some kind of plan that can be monitored. When reality strikes, youcan adjust your estimates for next time and hopefully, have a more accurate estimate based on real metrics, not guesswork.
• Suppose you estimated that it would take:
o 5 days to specify the test and…
o 10 days to prepare the test and…
o 5 to 15 days to execute the test
• When you record actual time it may be that:
o preparation actually took 3 times specification
o and execution actually took 1.5 times specification (it went very well)
• Then, you might adjust your 1, 2, 1-3 ratios to: 1, 4, 1.5-4.5
x. Impact of development slippages
Slippages imply a need for more testing:Let’s look at how a slippage of development impacts testing. We know this never happens, don’t we? Well, if it did and thedevelopers, for whatever reason, proposed that they slipped the delivery into your test environment by two weeks, whatoptions do you have? The first thing you might ask is ‘What is the cause of the slippage?’Were the original estimates too low? Is it now recognised that the project is bigger than was originally thought? Or is theproject more complicated than anticipated, either because of the software or the business rules? Or is the reason for

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 72/93

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 73/93
What tests remain to be completed? If there are tests of critical functionality that remain to be done, it would be unsafe tostop testing and release now. If we are coming towards the end of the test plan, the stakeholders and management maytake the view testing can stop before the test plan is complete if (and only if) the outstanding tests cover functionality that isnon-critial or low risk.
The job of the tester is to provide sufficient information for the stakeholders and management to make this judgement.
bb. Running out of time
If you have additional test to run, what are the risks of not running before release?Suppose we’re coming towards the end of the time in the plan for test execution, what is the risk of releasing the softwarebefore we complete the test plan?
What are the severity of outstanding faults?We have to take a look at the severity of the outstanding faults. For each of the outstanding faults, we have to take a viewon whether the fault would preclude release. That is, is this problem so severe that the system wouldn’t be worth using or would cause an unacceptable disruption to the business.Alternatively, there may be outstanding faults that the customer won’t like, but they could live with if necessary. It may alsobe a situation where the fault relates to an end-of-month process or procedure, which the software has to support. If theend-of-month procedure won’t be executed for another forty days or it is a procedure that could be done manually for thefirst month, then you may still decide to go ahead with the implementation.
Can you continue testing, but release anyway?One last point to consider – just because the software is released doesn’t mean that testing must stop. The test team cancontinue to find and record faults rather than waiting for the users to find problems.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 74/93
i. Incident ManagementWe’ve talked about incidents occurring on tests already, but we need to spend some time talking about the management of ncidents. Once the project moves into system or acceptance testing phases, to some extent, the project is driven by thencidents. It’s the incidents that trigger activities in the remainder of the project. And the statistics about the incidents provide agood insight as to the status of the project at any moment in time.
cc. What is an incident?
Unplanned events occurring during testing that have a bearing on the success of the testThe formal definition of an incident is an event that occurs during the testing that has a bearing on the success of the test.This might be a concern over the quality of the software because there’s a failure in the test itself. Or it may be somethingthat’s outside the control of the testers, like machine crashes, or there’s a loss of the network, or maybe a lack of testresource.
Something that stops or delays testingGoing back to the formal definition, an incident is something that occurred that has a bearing on the test. Incidentmanagement is about logging and controlling those events. They may relate to either the system under test or theenvironment or the resource available to conduct the test.
Incidents should be logged when independent testers do the testingIncidents are normally formally logged during system and aceptance testing, when independent teams of testers areinvolved.
dd. When a test result is different from the expected result...
It could be...When you run a test and the expected results do not match the actual results, it could be due to a number of reasons. Theissue here is that the tester shouldn’t jump to the conclusion that it’s a software fault.For example, it could be something wrong with the test itself; the test script may be incorrect in the commands it expected toappear or the expected result may have been predicted incorrectly.Maybe there was a misinterpretation of the requirements.It could be that the tester executing the test didn’t follow the script and made a slip in the entry of some test data and that iswhat’s caused the software to behave differently than expected.It could be that the results themselves are correct but the tester misunderstood what they saw on the screen or on a printedreport.
Another issue could be that it might be the test environment. Again, test environments are often quite fluid and changes arebeing made continuously to refine their behaviour. Potentially, a change in the configuration of the software in the testenvironment could cause a changed behaviour of the software under test.Maybe the wrong version of a database was loaded or the base parameters were changed since the last test.Finally, it could be something wrong with the baseline; that is, the document upon which the tests are being based isincorrect. The requirement itself is wrong.
Or it COULD BE a software fault.It could be any of the reasons above, but it could also be a software fault. A tester’s role in interpreting incidents is that theyshould be really careful about identifying what the nature of the problem is before they consider calling it a ‘software fault’.There is no faster way to upset developers than raising incidents that are classified as software faults, but upon closer investigation, are not. Although the testers may be under great pressure to complete their tests on time and feel that they donot have time for further analysis, typically the developers are under even greater pressure themselves.
ee. Incident logging
Tester should stop and complete an incident logWhat happens when you run a test and the test itself displays an unexpected result? The tester should stop what they’redoing and complete an incident log. It’s most important that the tester completes the log at the time of the test and not wait afew minutes and perhaps do it when it’s more convenient. The tester should log the event as soon as possible after itoccurs.What goes into an incident log? The tester should describe exactly what is wrong. What did they see? What did theywitness that made them think that the software was not behaving the way it should? They should record the test scriptthey’re following and potentially, the test step at which the software failed to meet an expected result. If appropriate, theyshould attach any output – screen dumps, print outs, any information that might be deemed useful to a developer so thatthey can reproduce the problem. Part of the incident log should be an assessment on whether the failure in this script has
an impact on other tests that have to be completed. Potentially, if a test fails, it may be a test that has no bearing on thesuccessful completion of any other test. It’s completely independent. However, some tests are designed to create test datafor later tests. So, it may be that a failure in one script may cause the rest of the scripts that need to be completed on thatday to be shelved because they cannot be run without the first one being corrected.Why do we create incident logs with such a lot of detail? Consider what happens when the developer is told that there maybe a potential problem in the software. The developer will use the information contained in the incident report to reproducethe fault. If the developer cannot reproduce the fault (because there’s not enough information on the log), it’s unreasonable

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 75/93
to expect him to fix the problem – he can’t see anything wrong! In cases like this, the developer will say that that no fault hasbeen found when they run the test. In a way, the software is innocent until proven guilty. And that’s not just becausedevelopers are being difficult. They cannot start fixing a problem if they have no way to diagnose where the problem mightbe.So, in order not to waste a lot of time for the developers and yourself, it’s most important that incident logs are createdaccurately.One further way of passing information test infomation to developers is to record tests using a record/playback tool. It is notthat the developer uses the script to replay the test, rather, that they have the exact keystrokes, button presses and datavalues required to reproduce the problem. It stops dead the comment, "you must have done something wrong, run it again."This might save you a lot of time.
ff. Typical test execution and incident management processIf you look at the point in the diagram where we run a test, you will see that after we run the test itself we raise an incident tocover any unplanned event.It could be that the tester has made an error so this is not a real incident and needn’t be logged.Where a real incident arises, it should be diagnosed to identify the nature of the problem. It could be that we decide that it isnot significant so the test could still proceed to completion.
gg. Incident management process
Diagnose incidentIf it’s determined that there’s a real problem that can be reproduced by the tester and it’s not the tester’s fault, the incidentshould be logged and classified. It will be classified, based on the information available, as to whether it is an environmentalproblem, a testware problem or a problem with the software itself. It will then be assigned to the relevant team or to aperson who will own the problem, even if it is only temporarily.
hh. Resolving the incidentHere are the most common incident types and how they would normally be resolved.
Fix tester If the tester made a slip during the testing, they should restart the script and follow it to the letter.
Fix testware: baseline, test specs, scripts or expected resultsIf the problem is the accuracy of any of the test materials these need to be corrected quickly and the test restarted. Onoccasion, it may be the baseline document itself that is at fault (and the test scripts reflect this problem. The baseline itself should be corrected and the test materials adjusted to align with the changed baseline. Then the test must restart.
Fix environment
If the environment is at fault, then the system needs reconfiguring correctly, or the test data adjusting/rebuilding to restorethe environment to the required, known state. Then the test should restart.
Fix-software, re-build and releaseWhere the incident revealed a fault in the software, the developers will correct the fault and re-release the fix. In this case,the tester needs to restore the test environment to the required state and re-test using the script that exposed the fault.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 76/93
Then queue for re-test.Often, there has to be a delay (while other tests complete) before failed tests can be re-run. In this case, the re-tests willhave to wait until the test schedule allows them to be run.
ii. Incident classificationi. Priority
Priority determined by testersWe’ve covered the type of problem. Let’s look at, first, the issue of priority. This means priority from a testing viewpointand is the main influence about when the problem will get fixed. The tester should decide whether an incident is of high,medium, or low priority, or whatever gradations you care to implement. To recap, the priority indicates the urgency of this problem to the testers themselves so the urgency relates to, how big an impact the failure has on the rest of testing.A high priority would be one that stops all testing. And if no testing can be done and at this point in the project, testing ison the critical path, then the whole project stops.If the failed script stops some but not all testing, then it might be considered a medum priority incident.It might be considered a low priority incident if all other tests can proceed.
ii. Severity
Severity determined by usersLet’s talk about severity. The severity relates to the acceptability or otherwise of the faults found. Determination of theseverity should be done by the end users themselves. Ultimately, the severity reflects the acceptability of that fault in thefinal deliverable. So, a software fault that is severe would relate to a fault that is unacceptable as far as the delivery of
the software into production is concerned. If a high severity fault is in the software at the time of the end of the test, thenthe system will be deemed unacceptable.
If the fault is minor, it might be deemed of low severity and users might choose to implement this software even if it stillhad the fault.
jj. Software fixing
The developers must have enough information to reproduce the problemLet’s look briefly at what developers do with incident reports and when they come to fix software faults. Developers musthave enough information to reproduce the problem.
If developers can't reproduce it, they probably can't fix it
Because if the developers cannot reproduce it, they probably cannot fix the issue because they cannot see it. Testers cananticipate this problem by trying to reproduce the problem themselves. They should also make sure that their description of the incident is adequate.
Incidents get prioritised and developer resources get assigned according to priority.To revisit the priority assigned to an incident, developer resources will get assigned according to that priority. This isn’t thesame as the severity. The decision that we’ll have to make towards the end of the test phase is "which incidents get workedupon based on priority and also severity"?

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 77/93
kk. TestabilityEssentially, we can think of testability as the ease by which a tester can specify, implement, execute and analyse tests of software. This module touches on an issue that is critical to the tester
ll. Testability definitions (testable requirements)
The extent to which software facilitates both the establishment of test criteria and the evaluation of the software with respect tohose criteria" or
"The extent to which the definition of requirements facilitates analysis of the requirements to establish test criteria."
mm.A broad definition of testabilityHere is a less formal, broader definition of testability, which overlaps 80-90% with the standard, but is actually more useful.Testability is the ease by which testers can do their job.
The ease by which testers can:
It’s the ease by which a tester can specify tests. Namely, are the requirements in a form that you can derive test plans fromin a straightforward, systematic way?
The ease by which a tester can prepare tests. How difficult is it to construct test plans and procedures that are effective?Can we create a relatively simple test database, simple test script?
Is it easy to run tests and understand and interpret the test results? Or when we run tests, does it take days to get to thebottom about where the results are? Do we have to plough through mountains of data? In other words, we are talking aboutthe ease by which we can analyse results and say, pass or fail.
How difficult is it to diagnose incidents and point to the source of the fault.
nn. Requirements and testability
Cannot derive meaningful tests from untestable requirementsRequirements are the main problem that we have as testers. If we have untestable requirements, it is impossible to derivemeaningful tests. That is the issue. You might ask, 'if we are unable to build test cases, how did the developers know whatto build?' This is a valid question and highlights the real problem. The problem is that it is quite feasible for a developer to
just get on with it and build the system as he sees it. But if the requirements are untestable, it’s impossible to see if he builtthe right system. But that's the testers' problem.
Complex systems can be untestable:In today’s distributed, web-enabled, client/server world, there is a problem of the system complexity effectively rendering thesystem untestable. It’s too complex for one person to understand. The specs may be nonexistent, but if they were written,they are far too technical for most testers to understand. Most of the functionality is hidden. We’re building verysophisticated, complex systems from off-the-shelf components. This is good news. It makes the developer’s job mucheasier because they just import functionality. But the testing effort hasn’t been reduced. We still have to test the same oldway, regardless of who built it and whether it’s off-the-shelf or not. So, life for the tester is just as hard as ever, but thedevelopers are suddenly, remarkably, more productive. The difficulty for testers is that they are being asked to test morecomplex systems with less resource because, of course, you only need 20% of the effort of the developers.
oo. Complex systems and testability
Can't design tests to exercise vast functionalitySo testers are expected to test more and more. They are under additional pressure now that off-the-shelf components arebeing used more. One of the difficulties we have is that we can’t design enough tests. We may have a system that has beenbuilt by three people in about a month, but it can still be massively complex. We can’t possibly design tests to exercise all of the functionality.
Can't design tests to exercise complex interactions between componentsWe know that these systems are built from components, but we don’t know where there are interactions betweencomponents. So we know that there are interactions, but because we don’t exactly where they are, we can’t test themspecifically. Do the developers test them? It’s difficult to say. They tend to trust brought-in software because they say, we’rebuying off-the-shelf components, it must work. And they are much more concerned with their own custom-built code than
off-the-shelf stuff.
Difficult to diagnose incidents when raised.When you run a test, is it clear what’s gone wrong? The problem with all of these components is that they’re all message-based. There’s not a clear hierarchy of responsibility – which event triggered what. You have lots of service components, alltalking to each other simultaneously. There is no sequencing you can track. So, you can’t diagnose faults very easily at all.This is a big issue for testers.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 78/93
pp. Improving testabilityTestability is going the wrong way. It’s getting worse. How might we improve testability? Here are a few ideas that influencetestability, that have a critical effect on testing.
Requirements reviewed by testers for testabilityOne way might be to get the testers to review the requirements as they are written. They would review it from the point of view of how will I prepare test plans on this document?
Software understandable by testersIf you could get developers to write software that testers could understand, that would help, but this is probably impractical.Or is it? If the testers can’t understand it, how are the users going to understand it? The users need to.
Software easy to configure to testWhen you buy a car, you expect it to work. Why do you have to test it? If you’re buying a factory-made product, you expectit to have been significantly tested before it reaches you, and it should work. But even with the example of a car, the onlything you can do to test it is to drive it. This is rather like the functional test. You still won’t know whether the engine will fallapart after 20,000 miles. Software has the same problems. If you do want to test it, you’ve suddenly opened up a can of worms. You have to have such knowledge of the technical architecture and how it all works together that it’s anoverwhelming task. How can we possibly create software that is understandable from the point of view of testers gettingunder the bonnet and looking at the lower-level components? To effectively test components, you need to be able toseparate them and test them in isolation. This can be really difficult.
Software which can provide data about its internal stateThe most promising trend is that software is beginning to have instrumentation that will tell you about its behaviour internally. So, quite a lot of the services that run on servers in complex environments generate logging that you can trace astesters.
Behaviour which is easy to interpretAnother thing that we need to make testability easier is behaviour that is easy to interpret. That is, it’s obvious when thesoftware is working correctly or incorrectly.
Software which can 'self-test'.Wouldn't it be nice if software could 'self-test'? Just like hardware, software could perhaps make decisions about itsbehaviour and tell you when it’s going wrong. Operating system software and some embedded systems do self diagnosis toverify that their internal state is sound. Most software doesn’t do that of course.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 79/93
i. Standards for Testing
qq. Types of standard
rr. What the standard covers...
A generic test process for software component testingBS7925-2 is a good document. Although it’s wordy with lots of standard-sounding language, it is highly recommended inthat it provides a generic clean process for component testing. It is uncomplicated from that point of view. It’s probably moreappropriate for a high-integrity environment with formal unit testing, than a small commercial environment. That does notmean that it’s completely useless to you if you’re working in a ‘low-integrity’ environment or you don’t have formal unittesting.
A component is the lowest level software entity with an separate specificationThe component is the lowest-level software entity with a separate spec. If you have a spec for a piece of code, whatever you were going to test against that spec, you could call that a component. It might be a simple sub-routine, a little piece of “C” or it could be a class file, or a window in an application. It could be anything that you might call a module, where you canseparate it out and test it in isolation against the document that specifies its behaviour. To recap, if you can test it inisolation, it’s probably a component.
Intended to be auditable, as its use may be mandated by customersThe purpose of a standard, among other things, is to be auditable. One of the intended uses of the standard is that potential
customers may mandate to suppliers of software that this standard is adhered to.
Covers dynamic execution only.It only covers dynamic testing, so it’s not about inspections, reviews, or anything like that. It’s about dynamic tests at acomponent level.
ss. The standard does not cover...
The standard makes clear statements about its scope.
Selection of test design or measurement techniquesThe standard does not cover the selection of test design or measurement techniques. What that means is that it cannot tellyou which test design or measurement technique you should use in your application area because there are no definitive
metrics that prove that one technique is better than another. What the standard does provide is a definition of the mostuseful techniques that are available.The test design and measurement techniques that you should use on your projects would normally be identified in your owninternal standards or be mandated by industry standards that you may be obliged to use.
Personnel selection or who does the testingThe standard doesn’t tell you who should do the testing. Although the standard implies that independence is a ‘good thing’,it only mandates that you document the degree of independence employed. It doesn’t imply that an independent individualor company must do all the testing or that another developer or independent tester must do test design. There are norecommendations in that regard.
Implementation (how required attributes of the test process are to be achieved e.g. tools)The standard doesn’t make any recommendations or instructions to do with the implementation of tests. It doesn’t give you
any insight as to how the test environment might be created or what tools you might use to execute tests themselves. It’sentirely generic in that regard.
Fault removal (a separate process to fault detection).Finally, fault removal is regarded as a separate process to fault detection. The process of fault removal normally occurs inparallel with the fault detection process but is not described in the standard.
tt. The component test strategy...
... shall specify the techniques to be employed in the design of test cases and the rationale for their choice...What the component-testing standard does say is that you should have a strategy for component testing. The test strategyfor components should specify the techniques you are going to employ in the design of test cases and the rationale for their choice. So although the standard doesn’t mandate one test technique above another, it does mandate that you record the
decision that nominated the techniques that you use.
... shall specify criteria for test completion and the rationale for their choice...The standard also mandates that within your test strategy you specify criteria for test completion. These are also oftencalled exit or acceptance criteria for the test stage. Again, it doesn’t mandate what these criteria are, but it does mandatethat you document the rationale for the choice of those criteria

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 80/93
Degree of independence required of personnel designing test cases e.g.:
A significant issue, with regard to component testing, is the degree of independence required by your test strategy. Again,the standard mandates that your test strategy defines the degree of independence used in the design of test cases butdoesn’t make any recommendation on how independent these individuals or the ‘test agency’ will be.
The standard does offer some possible options for deciding who does the testing. For example, you might decide that theperson who writes the component under test also writes the test cases. You might have an independent person writing thetest cases or you might have people from a different section in the company, from a different company. You might ultimatelydecide that a person should not choose the test cases at all - you might employ a tool to do this
uu. Documentation required...Finally, the standard mandates that you document certain other issues in a component test strategy.
Whether testing is done in isolation, bottom-up or top-down approaches, or some mixture of theseThe first one of these is that the strategy should describe how the testing is done with regard to the component's isolation;that is, whether the component is tested in a bottom-up or top-down method of integration or some mixture of these. Therequirement here is to document whether you’re using stubs and drivers, in addition to the components of the test, toexecute tests.
Environment in which component tests will be executedThe next thing that the strategy mandates is a description of the environment in which the component testing takes place.Here, one would be looking at the operating system, database, and other scaffolding software that might be required for
component tests to be completed. Again, this might cover issues like the networking and Internet infrastructure that you mayhave to test the components within.
est process that shall be used for component testing.The standard mandates that you document the process that you will actually use. Whether you use the process in BS7925-2 or not, the process that you do use should be described in enough detail for an auditor to understand how the testing hasactually been done
vv. Test measurement techniquesThere are five stages in the component test process described in the standard. The standard mandates that the testprocess activities occur in a defined order; that is, planning, specification, execution, and recording, and the verification of test completion occur in that order. It is clear that in many circumstances, there can be iterations around the loops of thesequence, of the five activities, and there is also a possibility of repeated stages on one or more of the test cases within the
test plan for a component. The documentation for the test process in use in your environment should define the testingactivities to be performed and the inputs and outputs of each activity.
Planning starts the test process and Check for Completion ends it. These activities are carried out for the whole component.Specification, Execution, and Recording can, on any one iteration, be carried out for a subset of the test cases associatedwith a component. It is possible that later activities for one test case can occur before earlier activities for another.Whenever a fault is corrected by making a change or changes to test materials or the component under test, the affectedactivities should be repeated. The five generic test activities are briefly described:
Planning: The test plan should specify how the project component test strategy and project test plan apply to the componentunder test. This includes specific identification of all exceptions to project test strategies and all software with which thecomponent under test will interact during test execution, such as drivers and stubs.
Specification: Test cases should be designed using the test case design techniques selected in the test planning activity.Each test case should identify its objective, the initial state of the component, its input(s), and the expected outcome. Theobjective should be described in terms of the test case design technique being used, such as the partition boundariesexercised.
Execution: Test cases should be executed as described in the component test specification.
Recording: For each test case, test records should show the identities and versions of the component under test and thetest specification. The actual outcome should also be recorded. It should be possible to establish that all the specifiedtesting activities have been carried out by reference to the test reports. Any discrepancy between the actual outcome andthe expected outcome should be logged and analysed in order to establish where the problem lies. The earliest test activitythat should be repeated in order to remove the discrepancy should be identified. For each of the measure(s) specified astest completion criteria in the plan, the coverage actually achieved should also be recorded.
Check for Completion: The test records should be checked against the test completion criteria. If these criteria are not met,the earliest test activity that has to be repeated in order to meet the criteria shall be identified and the test process shall berestarted from that point. It may be necessary to repeat the test specification activity to design further test cases to meet atest coverage target

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 81/93
ww.Standard definition of Technique
The standard gives you comprehensive definitions of the techniques to be used within the testing itself.
Test case design techniques to help users design testsThe aim is that test case design techniques can help the users of the standard to construct test cases themselves.
Test measurement techniques to help users (and customers) measure the testingThe measurement techniques will help testers, and potentially customers, to measure how much testing has actually beendone.
To promoteThe purpose in using these design and measurement techniques is to promote a set of consistent and repeatable testpractices within the component testing discipline. The process and techniques provide a common understanding betweendevelopers, testers, and the customers of software of how testing has been done. This will enable an objective comparisonof testing done on various components, potentially by different suppliers.
xx. Test case design and measurementOne innovation of the standard is that it clarifies two important concepts of test design and test measurement.
Test design:The test design activity is split into two, what you might call the analysis, and then the actual design of the test casesthemselves. The analysis uses a selected model of the software (control flowgraphs), or the requirements (equivalence
partitions) and the model is used to identify what are called coverage items. From the list of coverage items, test cases aredeveloped that will exercise (cover) each coverage item. For example, if you are using control flowgraphs as a model for thesoftware under test, you might use the branch-outcomes as the coverage item to derive test cases from.
Test measurement:The same model can then be used for test measurement. If you adopt the branch coverage model and your coverage itemsare the branches themselves, you can set an objective coverage target and that could be, for example, “100% branchcoverage”.Coverage targets based on the techniques in the standard can be adopted before the code is designed or written. Thetechniques are objective. You’ll certainly achieve a degree of confidence that the software has been exercised adequately,but the test design process is repeatable in that the rule is objective. If you follow the technique and the process that usesthat technique to derive test cases then, in principle, the same test cases will be extracted from that model.Normally, coverage targets are set at 100% but sometimes this is impractical perhaps because some branches in softwaremay be unreachable except by executing obscure, error conditions. Test coverage targets less than 100% may be used inthese circumstances
Model could be used to find faults in a baseline.The process of deriving test cases from a specification can find faults in the specification. Black-box techniques in particular make missing or conflicting requirements stand out and easily identified.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 82/93
yy. Test case desing techniqueThese are the test design techniques defined in the BS 7925-2 Standard for Component Testing. In this course, we will lookat the techniques in red in a little more detail. They are manadatory for the ISEB syllabus. We will also spend a little timelooking at State Transition Testing (in blue) but there will not be a question on this in the exam.
Equivalence partitioning Data flow
Boundary value analysis Branch condition
State transition Branch condition combination
Cause-effect graphing Modified condition decision
Syntax LCSAJStatement Random
Branch/decision Other techniques.
zz. Test measurement techniqueNearly all of the the test design techniques can be used to to define coverage targets. In this course, we will look at thetechniques in red in a little more detail. They are manadatory for the ISEB syllabus. We will also spend a little time looking atState Transition Testing (in blue) but there will not be a question on this in the exam.
Equivalence partitioningcoverage
Data flow coverage
Boundary value coverage Branch condition coverage
State transition coverage Branch condition combination coverage
Cause-effect graphing Modified condition decision coverageStatement coverage LCSAJ coverage
Branch/decision coverage Random testing

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 83/93
Module F: Tool Support for Testing :i. Tool Support for Testing
There are a surprising number of types of CAST (Computer Aided Software Testing) Tools now available. Tools are available tosupport test design, preparation, execution, analysis and management. This module provides an overview of the main types of est tool available and their range of applicability in the test process.
aaa.Types of CAST Tool
bbb.Categories of CAST tools
ccc.Static analysis tools
ddd.Requirements testing tools
eee.Test design tools
fff. Test data preparation tools
ggg.Batch test execution tools
hhh.On-line test execution tools
iii. GUI testing
jjj. GUI test stages
kkk.Test harnesses
lll. Test drivers
mmm.File comparison
nnn.Performance testing toolkit
ooo.Debugging
ppp.Dynamic analysis
qqq.Source coverage
rrr. Test ware management
sss.Incident management
ttt. Analysis, reporting, and metrics

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 84/93
i. Tool Selection and Implementation
uuu.Overview of the selection process
vvv.Where to start
www.Tool selection considerations
xxx.CAST limitations
yyy.CAST availability
zzz.The tool selection and evaluation team
aaaa.Evaluating the shortlist
bbbb.Tool implementation process
cccc.Pilot project
dddd.Evaluation of pilot
eeee.Planned phased installation
ffff. Keys to success
gggg.More keys to success
hhhh.Three routes to "shelf ware"
iiii. Documentation
jjjj. Test Database
kkkk.Test Case
llll. Test Matrix

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 85/93
i. Glossary and Testing Terms
mmmm.Acceptance testing: Formal testing conducted to enable a user, customer, or other authorized entity to determinewhether to accept a system or component.
nnnn.Actual outcome: The behaviour actually produced when the object is tested under specified conditions.
oooo.Ad hoc testing: Testing carried out using no recognised test case design technique.
pppp.Alpha testing: Simulated or actual operational testing at an in-house site not otherwise involved with the softwaredevelopers.
qqqq.Arc testing: See branch testing.
rrrr. Backus-Naur form: A metalanguage used to formally describe the syntax of a language.
ssss.Basic block: A sequence of one or more consecutive, executable statements containing no branches.
tttt. Basis test set: A set of test cases derived from the code logic which ensure that 100\% branch coverage is achieved.
uuuu.Bebugging: See error seeding.
vvvv.Behaviour: The combination of input values and preconditions and the required response for a function of a system.The full specification of a function would normally comprise one or more behaviours.
wwww.Beta testing: Operational testing at a site not otherwise involved with the software developers.
xxxx.Big-bang testing: Integration testing where no incremental testing takes place prior to all the system's componentsbeing combined to form the system.
yyyy.Black box testing: See functional test case design.
zzzz.Bottom-up testing: An approach to integration testing where the lowest level components are tested first, then used tofacilitate the testing of higher level components. The process is repeated until the component at the top of the hierarchyis tested.
aaaaa.Boundary value analysis: A test case design technique for a component in which test cases are designed whichinclude representatives of boundary values.
bbbbb.Boundary value coverage: The percentage of boundary values of the component's equivalence classes, which havebeen exercised by a test case suite.
ccccc.Boundary value testing: See boundary value analysis.
ddddd.Boundary value: An input value or output value which is on the boundary between equivalence classes, or anincremental distance either side of the boundary.
eeeee.Branch condition combination coverage: The percentage of combinations of all branch condition outcomes in every
decision that have been exercised by a test case suite.
fffff.Branch condition combination testing: A test case design technique in which test cases are designed to executecombinations of branch condition outcomes.
ggggg.Branch condition coverage: The percentage of branch condition outcomes in every decision that have beenexercised by a test case suite.
hhhhh.Branch condition testing: A test case design technique in which test cases are designed to execute branch conditionoutcomes.
iiiii. Branch condition: See decision condition.
jjjjj. Branch coverage: The percentage of branches that have been exercised by a test case suite
kkkkk.Branch outcome: See decision outcome.
lllll. Branch point: See decision.
mmmmm.Branch testing: A test case design technique for a component in which test cases are designed to execute

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 86/93
nnnnn.Branch outcomes.
ooooo.Branch: A conditional transfer of control from any statement to any other statement in a component, or anunconditional transfer of control from any statement to any other statement in the component except the next statement,or when a component has more than one entry point, a transfer of control to an entry point of the component.
ppppp.Bug seeding: See error seeding.
qqqqq.Bug: See fault.
rrrrr.Capture/playback tool: A test tool that records test input as it is sent to the software under test. The input cases storedcan then be used to reproduce the test later.
sssss.Capture/replay tool: See capture/playback tool.
ttttt.CAST: Acronym for computer-aided software testing.
uuuuu.Cause-effect graph: A graphical representation of inputs or stimuli (causes) with their associated outputs (effects),which can be used to design test cases.
vvvvv.Cause-effect graphing: A test case design technique in which test cases are designed by consideration of cause-effectgraphs.
wwwww.Certification: The process of confirming that a system or component complies with its specified requirements and isacceptable for operational use.
xxxxx.Chow's coverage metrics: See N-switch coverage. [Chow]
yyyyy.Code coverage: An analysis method that determines which parts of the software have been executed (covered) by thetest case suite and which parts have not been executed and therefore may require additional attention.
zzzzz.Code-based testing: Designing tests based on objectives derived from the implementation (e.g., tests that executespecific control flow paths or use specific data items).
aaaaaa.Compatibility testing: Testing whether the system is compatible with other systems with which it should
communicate.
bbbbbb.Complete path testing: See exhaustive testing.
cccccc.Component testing: The testing of individual software components.
dddddd.Component: A minimal software item for which a separate specification is available.
eeeeee.Computation data use: A data use not in a condition. Also called C-use.
ffffff.Condition coverage: See branch condition coverage.
gggggg.Condition outcome: The evaluation of a condition to TRUE or FALSE.
hhhhhh.Condition: A Boolean expression containing no Boolean operators. For instance, A<B is a condition but A and B is
not.
iiiiii. Conformance criterion: Some method of judging whether or not the component's action on a particular specified inputvalue conforms to the specification.
jjjjjj. Conformance testing: The process of testing that an implementation conforms to the specification on which it is based.
kkkkkk.Control flow graph: The diagrammatic representation of the possible alternative control flow paths through acomponent.
llllll. Control flow path: See path.
mmmmmm.Control flow: An abstract representation of all possible sequences of events in a program's execution.
nnnnnn.Conversion testing: Testing of programs or procedures used to convert data from existing systems for use inreplacement systems.
oooooo.Correctness: The degree to which software conforms to its specification.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 87/93
pppppp.Coverage item: An entity or property used as a basis for testing.
qqqqqq.Coverage: The degree, expressed as a percentage, to which a test case suite has exercised a specified coverageitem.
rrrrrr.C-use: See computation data use.
ssssss.Data definition C-use coverage: The percentage of data definition C-use pairs in a component that are exercised bya test case suite.
tttttt.Data definition C-use pair: A data definition and computation data use, where the data use uses the value defined in thedata definition.
uuuuuu.Data definition P-use coverage: The percentage of data definition P-use pairs in a component that are exercised bya test case suite.
vvvvvv.Data definition P-use pair: A data definition and predicate data use, where the data use uses the value defined in thedata definition.
wwwwww.Data definition: An executable statement where a variable is assigned a value.
xxxxxx.Data definition-use coverage: The percentage of data definition-use pairs in a component that are exercised by a
test case suite.
yyyyyy.Data definition-use pair: A data definition and data use, where the data use uses the value defined in the datadefinition.
zzzzzz.Data definition-use testing: A test case design technique for a component in which test cases are designed toexecute data definition-use pairs.
aaaaaaa.Data flow coverage: Test coverage measure based on variable usage within the code. Examples are datadefinition-use coverage, data definition P-use coverage, data definition C-use coverage, etc.
bbbbbbb.Data flow testing: Testing in which test cases are designed based on variable usage within the code.
ccccccc.Data use: An executable statement where the value of a variable is accessed.
ddddddd.Debugging: The process of finding and removing the causes of failures in software.
eeeeeee.Decision condition: A condition within a decision.
fffffff.Decision coverage: The percentage of decision outcomes that have been exercised by a test case suite.
ggggggg.Decision outcome: The result of a decision (which therefore determines the control flow alternative taken).
hhhhhhh.Decision: A program point at which the control flow has two or more alternative routes.
iiiiiii.Design-based testing: Designing tests based on objectives derived from the architectural or detail design of the software
(e.g., tests that execute specific invocation paths or probe the worst case behaviour of algorithms).
jjjjjjj.Desk checking: The testing of software by the manual simulation of its execution.
kkkkkkk.Dirty testing: See negative testing.
lllllll.Documentation testing: Testing concerned with the accuracy of documentation.
mmmmmmm.Domain testing: See equivalence partition testing.
nnnnnnn.Domain: The set from which values are selected.
ooooooo.Dynamic analysis: The process of evaluating a system or component based upon its behaviour during execution.
ppppppp.Emulator: A device, computer program, or system that accepts the same inputs and produces the same outputs asa given system.
qqqqqqq.Entry point: The first executable statement within a component.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 88/93
rrrrrrr.Equivalence class: A portion of the component's input or output domains for which the component's behaviour isassumed to be the same from the component's specification.
sssssss.Equivalence partition coverage: The percentage of equivalence classes generated for the component, which havebeen exercised by a test case suite.
ttttttt.Equivalence partition testing: A test case design technique for a component in which test cases are designed toexecute representatives from equivalence classes.
uuuuuuu.Equivalence partition: See equivalence class.
vvvvvvv.Error guessing: A test case design technique where the experience of the tester is used to postulate what faultsmight occur, and to design tests specifically to expose them.
wwwwwww.Error seeding: The process of intentionally adding known faults to those already in a computer program for thepurpose of monitoring the rate of detection and removal, and estimating the number of faults remaining in the program.
xxxxxxx.Error: A human action that produces an incorrect result.
yyyyyyy.Executable statement: A statement which, when compiled, is translated into object code, which will be executedprocedurally when the program is running and may perform an action on program data.
zzzzzzz.Exercised: A program element is exercised by a test case when the input value causes the execution of that
element, such as a statement, branch, or other structural element.
aaaaaaaa.Exhaustive testing: A test case design technique in which the test case suite comprises all combinations of inputvalues and preconditions for component variables.
bbbbbbbb.Exit point: The last executable statement within a component.
cccccccc.Expected outcome: See predicted outcome.
dddddddd.Facility testing: See functional test case design.
eeeeeeee.Failure: Deviation of the software from its expected delivery or service. [Fenton]
ffffffff.Fault: A manifestation of an error in software. A fault, if encountered may cause a failure.
gggggggg.Feasible path: A path for which there exists a set of input values and execution conditions which causes it to beexecuted.
hhhhhhhh.Feature testing: See functional test case design.
iiiiiiii.Functional specification: The document that describes in detail the characteristics of the product with regard to itsintended capability.
jjjjjjjj.Functional test case design: Test case selection that is based on an analysis of the specification of the componentwithout reference to its internal workings.
kkkkkkkk.Glass box testing: See structural test case design.
llllllll.Incremental testing: Integration testing where system components are integrated into the system one at a time until theentire system is integrated.
mmmmmmmm.Independence: Separation of responsibilities, which ensures the accomplishment of objective evaluation.After [do178b].
nnnnnnnn.Infeasible path: A path, which cannot be exercised by any set of possible input values.
oooooooo.Input domain: The set of all possible inputs.
pppppppp.Input value: An instance of an input.
qqqqqqqq.Input: A variable (whether stored within a component or outside it) that is read by the component.
rrrrrrrr.Inspection: A group review quality improvement process for written material. It consists of two aspects; product(document itself) improvement and process improvement (of both document production and inspection). After [Graham]
ssssssss.Installability testing: Testing concerned with the installation procedures for the system.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 89/93
tttttttt.Instrumentation: The insertion of additional code into the program in order to collect information about programbehaviour during program execution.
uuuuuuuu.Instrumented: A software tool used to carry out instrumentation.
vvvvvvvv.Integration testing: Testing performed to expose faults in the interfaces and in the interaction between integratedcomponents.
wwwwwwww.Integration: The process of combining components into larger assemblies.
xxxxxxxx.Interface testing: Integration testing where the interfaces between system components are tested.
yyyyyyyy.Isolation testing: Component testing of individual components in isolation from surrounding components, withsurrounding components being simulated by stubs.
zzzzzzzz.LCSAJ coverage: The percentage of LCSAJs of a component, which is exercised by a test case suite.
aaaaaaaaa.LCSAJ testing: A test case design technique for a component in which test cases are designed to executeLCSAJs.
bbbbbbbbb.LCSAJ: A Linear Code Sequence And Jump, consisting of the following three items (conventionally identified byline numbers in a source code listing): the start of the linear sequence of executable statements, the end of the linear
sequence, and the target line to which control flow is transferred at the end of the linear sequence.
ccccccccc.Logic-coverage testing: See structural test case design. [Myers]
ddddddddd.Logic-driven testing: See structural test case design.
eeeeeeeee.Maintainability testing: Testing whether the system meets its specified objectives for maintainability.
fffffffff.Modified condition/decision coverage: The percentage of all branch condition outcomes that Independently affect adecision outcome that have been exercised by a test case suite.
ggggggggg.Modified condition/decision testing: A test case design technique in which test cases are designed to executebranch condition outcomes that independently affect a decision outcome.
hhhhhhhhh.Multiple condition coverage: See branch condition combination coverage.
iiiiiiiii.Mutation analysis: A method to determine test case suite thoroughness by measuring the extent to which a test casesuite can discriminate the program from slight variants (mutants) of the program. See also error seeding.
jjjjjjjjj.Negative testing: Testing aimed at showing software does not work.
kkkkkkkkk.Non-functional requirements testing: Testing of those requirements that do not relate to functionality. I.e.performance, usability, etc.
lllllllll.N-switch coverage: The percentage of sequences of N-transitions that have been exercised by a test case suite.
mmmmmmmmm.N-switch testing: A form of state transition testing in which test cases are designed to execute all validsequences of N-transitions.
nnnnnnnnn.N-transitions: A sequence of N+1 transitions.
ooooooooo.Operational testing: Testing conducted to evaluate a system or component in its operational environment.
ppppppppp.Oracle: A mechanism to produce the predicted outcomes to compare with the actual outcomes of the softwareunder test.
qqqqqqqqq.Outcome: Actual outcome or predicted outcome. This is the outcome of a test. See also branch outcome,condition outcome, and decision outcome.
rrrrrrrrr.Output domain: The set of all possible outputs.
sssssssss.Output value: An instance of an output.
ttttttttt.Output: A variable (whether stored within a component or outside it) that is written to by the component.
uuuuuuuuu.Partition testing: See equivalence partition testing.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 90/93
vvvvvvvvv.Path coverage: The percentage of paths in a component exercised by a test case suite.
wwwwwwwww.Path sensitising: Choosing a set of input values to force the execution of a component to take a given path.
xxxxxxxxx.Path testing: A test case design technique in which test cases are designed to execute paths of a component.
yyyyyyyyy.Path: A sequence of executable statements of a component, from an entry point to an exit point.
zzzzzzzzz.Performance testing: Testing conducted to evaluate the compliance of a system or component with specifiedperformance requirements.
aaaaaaaaaa.Portability testing: Testing aimed at demonstrating the software can be ported to specified hardware or software platforms.
bbbbbbbbbb.Precondition: Environmental and state conditions, which must be fulfilled before the component can beexecuted with a particular input value.
cccccccccc.Predicate data use: A data use in a predicate.
dddddddddd.Predicate: A logical expression, which evaluates to TRUE or FALSE, normally to direct the execution path incode.
eeeeeeeeee.Predicted outcome: The behaviour predicted by the specification of an object under specified conditions.
ffffffffff.Program instrumented: See instrumented.
gggggggggg.Progressive testing: Testing of new features after regression testing of previous features.
hhhhhhhhhh.Pseudo-random: A series, which appears to be random but is in fact generated according to some prearrangedsequence.
iiiiiiiiii.P-use: See predicate data use.
jjjjjjjjjj.Recovery testing: Testing aimed at verifying the system's ability to recover from varying degrees of failure.
kkkkkkkkkk.Regression testing: Retesting of a previously tested program following modification to ensure that faults havenot been introduced or uncovered as a result of the changes made.
llllllllll.Requirements-based testing: Designing tests based on objectives derived from requirements for the softwarecomponent (e.g., tests that exercise specific functions or probe the non-functional constraints such as performance or security). See functional test case design.
mmmmmmmmmm.Result: See outcome.
nnnnnnnnnn.Review: A process or meeting during which a work product, or set of work products, is presented to projectpersonnel, managers, users or other interested parties for comment or approval. [ieee]
oooooooooo.Security testing: Testing whether the system meets its specified security objectives.
pppppppppp.Serviceability testing: See maintainability testing.
qqqqqqqqqq.Simple subpath: A subpath of the control flow graph in which no program part is executed more thannecessary.
rrrrrrrrrr.Simulation: The representation of selected behavioural characteristics of one physical or abstract system by another system. [ISO 2382/1].
ssssssssss.Simulator: A device, computer program, or system used during software verification, which behaves or operateslike a given system when provided with a set of controlled inputs.
tttttttttt.Source statement: See statement.
uuuuuuuuuu.Specification: A description of a component's function in terms of its output values for specified input valuesunder specified preconditions.
vvvvvvvvvv.Specified input: An input for which the specification predicts an outcome.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 91/93
wwwwwwwwww.State transition testing: A test case design technique in which test cases are designed to execute statetransitions.
xxxxxxxxxx.State transition: A transition between two allowable states of a system or component.
yyyyyyyyyy.Statement coverage: The percentage of executable statements in a component that have been exercised by atest case suite.
zzzzzzzzzz.Statement testing: A test case design technique for a component in which test cases are designed to executestatements.
aaaaaaaaaaa.Statement: An entity in a programming language, which is typically the smallest indivisible unit of execution.
bbbbbbbbbbb.Static analysis: Analysis of a program carried out without executing the program.
ccccccccccc.Static analyser: A tool that carries out static analysis.
ddddddddddd.Static testing: Testing of an object without execution on a computer.
eeeeeeeeeee.Statistical testing: A test case design technique in which a model is used of the statistical distribution of theinput to construct representative test cases.
fffffffffff.Storage testing: Testing whether the system meets its specified storage objectives.
ggggggggggg.Stress testing: Testing conducted to evaluate a system or component at or beyond the limits of its specifiedrequirements.
hhhhhhhhhhh.Structural coverage: Coverage measures based on the internal structure of the component.
iiiiiiiiiii.Structural test case design: Test case selection that is based on an analysis of the internal structure of thecomponent.
jjjjjjjjjjj.Structural testing: See structural test case design.
kkkkkkkkkkk.Structured basis testing: A test case design technique in which test cases are derived from the code logic toachieve 100% branch coverage.
lllllllllll.Structured walkthrough: See walkthrough.
mmmmmmmmmmm.Stub: A skeletal or special-purpose implementation of a software module, used to develop or test acomponent that calls or is otherwise dependent on it. After [IEEE].
nnnnnnnnnnn.Sub-path: A sequence of executable statements within a component.
ooooooooooo.Symbolic evaluation: See symbolic execution.
ppppppppppp.Symbolic execution: A static analysis technique that derives a symbolic expression for program paths.
qqqqqqqqqqq.Syntax testing: A test case design technique for a component or system in which test case design is based
upon the syntax of the input.
rrrrrrrrrrr.System testing: The process of testing an integrated system to verify that it meets specified requirements.
sssssssssss.Technical requirements testing: See non-functional requirements testing.
ttttttttttt.Test automation: The use of software to control the execution of tests, the comparison of actual outcomes topredicted outcomes, the setting up of test preconditions, and other test control and test reporting functions.
uuuuuuuuuuu.Test case design technique: A method used to derive or select test cases.
vvvvvvvvvvv.Test case suite: A collection of one or more test cases for the software under test.
wwwwwwwwwww.Test case: A set of inputs, execution preconditions, and expected outcomes developed for a particular objective, such as to exercise a particular program path or to verify compliance with a specific requirement.
xxxxxxxxxxx.Test comparator: A test tool that compares the actual outputs produced by the software under test with theexpected outputs for that test case.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 92/93
yyyyyyyyyyy.Test completion criterion: A criterion for determining when planned testing is complete, defined in terms of atest measurement technique.
zzzzzzzzzzz.Test coverage: See coverage.
aaaaaaaaaaaa.Test driver: A program or test tool used to execute software against a test case suite.
bbbbbbbbbbbb.Test environment: A description of the hardware and software environment in which the tests will be run, andany other software with which the software under test interacts when under test including stubs and test drivers.
cccccccccccc.Test execution technique: The method used to perform the actual test execution, e.g. manual,capture/playback tool, etc.
dddddddddddd.Test execution: The processing of a test case suite by the software under test, producing an outcome.
eeeeeeeeeeee.Test Generator: A program that generates test cases in accordance to a specified strategy or heuristic.
ffffffffffff.Test Harness: A testing tool that comprises a test driver and a test comparator.
gggggggggggg.Test Measurement Technique: A method used to measure test coverage items.
hhhhhhhhhhhh.Test Outcome: See outcome.
iiiiiiiiiiii.Test Plan: A record of the test planning process detailing the degree of tester independence, the test environment,
the test case design techniques and test measurement techniques to be used, and the rationale for their choice.
jjjjjjjjjjjj.Test Procedure: A document providing detailed instructions for the execution of one or more test cases.
kkkkkkkkkkkk.Test Records: For each test, an unambiguous record of the identities and versions of the component under
test, the test specification, and actual outcome.
llllllllllll.Test Script: Commonly used to refer to the automated test procedure used with a test harness.
mmmmmmmmmmmm.Test Specification: For each test case, the coverage item, and the initial state of the software
under test, the input, and the predicted outcome.
nnnnnnnnnnnn.Test Target: A set of test completion criteria.
oooooooooooo.Testing: The process of exercising software to verify that it satisfies specified requirements and to detect
errors.
pppppppppppp.Thread Testing: A variation of top-down testing where the progressive integration of components follows
the implementation of subsets of the requirements, as opposed to the integration of components by successively lower levels.
qqqqqqqqqqqq.Top-Down Testing: An approach to integration testing where the component at the top of the component
hierarchy is tested first, with lower level components being simulated by stubs. Tested components are then used to testlower level components. The process is repeated until the lowest level components have been tested.
rrrrrrrrrrrr.Unit Testing: See component testing.
ssssssssssss.Usability Testing: Testing the ease with which users can learn and use a product.
tttttttttttt.Validation: Determination of the correctness of the products of software development with respect to the user
needs and requirements.
uuuuuuuuuuuu.Verification: The process of evaluating a system or component to determine whether the products of the
given development phase satisfy the conditions imposed at the start of that phase.
vvvvvvvvvvvv.Volume Testing: Testing where the system is subjected to large volumes of data.
wwwwwwwwwwww.Walkthrough: A review of requirements, designs, or code characterized by the author of the object
under review guiding the progression of the review.
xxxxxxxxxxxx.White box testing: See structural test case design.

8/14/2019 ISEB Course Study
http://slidepdf.com/reader/full/iseb-course-study 93/93


















