
Is attention necessary for object identification? Evidence from eye movements during the inspection...
12
Is attention necessary for object identification? Evidence from eye movements during the inspection of real-world scenes Geoffrey Underwood * , Emma Templeman, Laura Lamming, Tom Foulsham School of Psychology, University of Nottingham, Nottingham NG7 2RD, UK Received 3 October 2006 Available online 11 January 2007 Abstract Eye movements were recorded during the display of two images of a real-world scene that were inspected to determine whether they were the same or not (a comparative visual search task). In the displays where the pictures were different, one object had been changed, and this object was sometimes taken from another scene and was incongruent with the gist. The experiment established that incongruous objects attract eye fixations earlier than the congruous counterparts, but that this effect is not apparent until the picture has been displayed for several seconds. By controlling the visual saliency of the objects the experiment eliminates the possibility that the incongruency effect is dependent upon the conspicuity of the chan- ged objects. A model of scene perception is suggested whereby attention is unnecessary for the partial recognition of an object that delivers sufficient information about its visual characteristics for the viewer to know that the object is improb- able in that particular scene, and in which full identification requires foveal inspection. Ó 2006 Elsevier Inc. All rights reserved. Keywords: Attention; Scene perception; Eye movements; Visual saliency; Object congruency; Comparative visual search 1. Introduction The gist of a scene can be perceived with a very brief glimpse, and presumably some of the objects that together form the scene and contribute to the gist are necessarily perceived during this interval (Biederman, 1972; Biederman, Glass, & Stacy, 1973; Biederman, Rabinowitz, Glass, & Stacy, 1974; Potter, 1976; Potter & Levy, 1969; Potter, Staub, Rado, & O’Connor, 2002). Objects that violate the gist of a scene are identified less readily than those that are congruent (Biederman, Mezzanotte, & Rabinowitz, 1982; Boyce, Pollatsek, & Ray- ner, 1989; Davenport & Potter, 2004), but there is a paradox here, because incongruous objects can be iden- tified sufficiently early to attract attention and eye fixations (Loftus & Mackworth, 1978; Underwood & Foulsham, 2006). The evidence for these two conclusions comes from studies in which scenes are displayed, but in which different tasks are used, and therein may lay the resolution to the paradox. In the present study, we sought further evidence of the power of incongruous objects to attract early eye fixations in a comparative 1053-8100/$ - see front matter Ó 2006 Elsevier Inc. All rights reserved. doi:10.1016/j.concog.2006.11.008 * Corresponding author. Fax: +44 115 951 5324. E-mail address: geoff[email protected] (G. Underwood). Available online at www.sciencedirect.com Consciousness and Cognition 17 (2008) 159–170 Consciousness and Cognition www.elsevier.com/locate/concog
-
Upload
geoffrey-underwood -
Category
Documents
-
view
214 -
download
1
Transcript of Is attention necessary for object identification? Evidence from eye movements during the inspection...

Available online at www.sciencedirect.com
ConsciousnessConsciousness and Cognition 17 (2008) 159–170
andCognition
www.elsevier.com/locate/concog
Is attention necessary for object identification? Evidencefrom eye movements during the inspection of real-world scenes
Geoffrey Underwood *, Emma Templeman, Laura Lamming, Tom Foulsham
School of Psychology, University of Nottingham, Nottingham NG7 2RD, UK
Received 3 October 2006Available online 11 January 2007
Abstract
Eye movements were recorded during the display of two images of a real-world scene that were inspected to determinewhether they were the same or not (a comparative visual search task). In the displays where the pictures were different, oneobject had been changed, and this object was sometimes taken from another scene and was incongruent with the gist. Theexperiment established that incongruous objects attract eye fixations earlier than the congruous counterparts, but that thiseffect is not apparent until the picture has been displayed for several seconds. By controlling the visual saliency of theobjects the experiment eliminates the possibility that the incongruency effect is dependent upon the conspicuity of the chan-ged objects. A model of scene perception is suggested whereby attention is unnecessary for the partial recognition of anobject that delivers sufficient information about its visual characteristics for the viewer to know that the object is improb-able in that particular scene, and in which full identification requires foveal inspection.� 2006 Elsevier Inc. All rights reserved.
Keywords: Attention; Scene perception; Eye movements; Visual saliency; Object congruency; Comparative visual search
1. Introduction
The gist of a scene can be perceived with a very brief glimpse, and presumably some of the objects thattogether form the scene and contribute to the gist are necessarily perceived during this interval (Biederman,1972; Biederman, Glass, & Stacy, 1973; Biederman, Rabinowitz, Glass, & Stacy, 1974; Potter, 1976; Potter &Levy, 1969; Potter, Staub, Rado, & O’Connor, 2002). Objects that violate the gist of a scene are identified lessreadily than those that are congruent (Biederman, Mezzanotte, & Rabinowitz, 1982; Boyce, Pollatsek, & Ray-ner, 1989; Davenport & Potter, 2004), but there is a paradox here, because incongruous objects can be iden-tified sufficiently early to attract attention and eye fixations (Loftus & Mackworth, 1978; Underwood &Foulsham, 2006). The evidence for these two conclusions comes from studies in which scenes are displayed,but in which different tasks are used, and therein may lay the resolution to the paradox. In the present study,we sought further evidence of the power of incongruous objects to attract early eye fixations in a comparative
1053-8100/$ - see front matter � 2006 Elsevier Inc. All rights reserved.doi:10.1016/j.concog.2006.11.008
* Corresponding author. Fax: +44 115 951 5324.E-mail address: [email protected] (G. Underwood).

160 G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170
visual search task. Evidence of incongruous objects attracting attention is evidence of the pre-attentive iden-tification of the inconsistency between the object and the gist of the scene.
Incongruous objects are identified with greater difficulty than corresponding objects that are consistent withthe gist. The gist of a scene captures the schema, and may be described in a single word or a short phrase (see,for example, Biederman, 1981; Potter, 1999; Treisman, 2006; Underwood, 2005). Thus we might see and rec-ognise a picture as depicting a bathroom scene, or a roadway scene, or a harbour scene. In each of these sceneswe would expect to see certain objects—a sink, a bar of soap, a towel, a toothbrush and shaving kit in the caseof a bathroom, for example—and if an object from another scene is present—a tennis ball in the sink, per-haps—it would be regarded as violating the gist. Such an object would be recognised with greater difficultythan if it had appeared in picture showing a sports changing room, with racquets, a towel and sports clotheson a bench. The towel belongs to both scenes and would contribute to the gist of both, whereas the otherobjects belong exclusively to one scene or the other. The early perception of the gist of a scene has been wellestablished by Potter and her colleagues with a rapid serial visual presentation task (for example, Potter, 1976;Potter & Levy, 1969; Potter et al., 2002). In this task a series of photographs is presented with a brief exposureof each picture, and target scenes are found to be identified even when subsequent recognition memory is poor.
The conclusion that we have rapid identification of scene gist also follows from Biederman’s studies inwhich viewers attempted to identify objects in briefly presented photographs that were shown individually(for example, Biederman, 1972; Biederman et al., 1973, 1974). When pictures were cut up and re-arranged,thereby disturbing the gist of the scene, objects that remained in their unjumbled locations were recognisedwith more difficulty. The interaction between objects and their context of presentation has also been demon-strated by Davenport and Potter (2004) with very brief presentations that precluded eye movements. Objectswere copied onto background scenes that represented a contextual gist, and objects that violated the gist wereidentified less well than those that were consistent (for example, a football player superimposed into the fore-ground of a church interior or into an image of a sports field).
Using a different approach, Li, VanRullen, Koch, and Perona (2002) have concluded that certain objectscan be identified without attention. Viewers focussed their attention on a central probe task, in which fivesmall letters were presented at varying orientations. The task was to say whether they were all the same orwhether one was different from the others (the letters were Ts and Ls and this discrimination was performedwith 77% accuracy when it was the only task). A picture of an object was presented in a corner of the screenfor 27 ms, followed by a visual mask, and as well as making a judgement about the central letters they wereasked to say whether the picture showed an animal or not. Performance on the picture task was not reliablydifferent when it was performed alone and with full attention, or when it was performed with the letter dis-crimination task. This result suggests that attention is not required for the identification of objects in pictures,although Evans and Treisman (2005) argue that animals are a special case of objects with particular evolution-ary salience, and reported that when pictures of humans were used as distractors, performance falls off, sug-gesting that detection in the Li et al. experiment depended on the identification of component features such asa beak or wings.
The evidence suggests that the gist of a picture can be perceived quickly, and that this context aids the rec-ognition of objects that are consistent with the scene. Violations of gist result in impaired recognition, as theydid with the gist-reduced jumbled pictures used by Biederman et al. (1973, 1974), and with the identification ofinconsistent objects (Biederman et al., 1982; Davenport & Potter, 2004). These studies demonstrate thatobjects that violate the gist are recognised with greater difficulty than those that contribute to the gist. Thisconclusion appears from a number of studies, and conflicts with the conclusion from studies of picture per-ception in which eye movements are recorded.
Objects that violate the gist have a recognition disadvantage but paradoxically they also they attract atten-tion and eye fixations earlier than their congruous counterparts. Mackworth and Morandi (1967) presentedtwo natural pictures to viewers, each for 10 s, and recorded their eye movements while they judged whichone they preferred. Fixations were more frequent on regions of the pictures that were regarded subjectivelyas being most informative, with non-informative regions often not fixated at all. Mackworth and Morandiconcluded that ‘‘peripheral vision edited out the redundant stimuli in the pictures’’ (p. 549) and that pictorialinformation is used by the eye guidance mechanism. Their results were confirmed by Antes (1974), who used alarger sample of pictures, and who additionally found that the first fixation on the picture tended to be on a

G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170 161
region judged as being informative. These two results suggest that our viewing of a picture can be guided bythe processing of meaningful elements prior to their fixation and close inspection, and this conclusion was sup-ported by Loftus and Mackworth’s (1978) experiment with line-drawings of simple scenes. In these picturesthere were sometimes objects that violated the gist—Biederman et al. (1982) would have described theseobjects as having a probability violation, in that the object would not be expected to be present in that scene(for example, an octopus in a farmyard, or a tractor in an underwater scene). Viewers tended to fixate theanomalous object with the first fixation, and they tended to fixate these objects earlier than a gist-consistentobject drawn in the same region of the picture. Underwood and Foulsham (2006) have confirmed this effect ofincongruous objects attracting eye fixations earlier than congruous objects, using photographs of real-worldscenes containing objects that were misplaced (for example, a tube of toothpaste on a coffee table placed nextto a sofa).
If inconsistent objects are recognised with greater difficulty than their counterparts, as suggested by theresults reported by Biederman et al. (1982), Boyce et al. (1989) and by Davenport and Potter (2004), whydo they attract attention? Before commenting on this paradox it is important to note that the idea of earlyfixations being attracted to anomalous objects has not gone unchallenged. De Graef, Christiaens, and d’Ydew-alle (1990) and Henderson, Weeks, and Hollingworth (1999) recorded eye fixations while their viewers inspect-ed line-drawings of familiar scenes that sometimes contained objects that were out of place. These anomalousobjects attracted early fixations in neither of these studies. In tasks in which viewers looked for impossibleobjects (De Graef et al.), or in preparation for a recognition memory test (Henderson et al.) or to determinethe presence or absence of a named object (Henderson et al.), there was no evidence of the earlier fixation ofanomalous relative to gist-consistent objects. One possibility that might explain this inconsistency in the pat-tern of results follows from inspection of the stimuli used in the different experiments. Whereas De Graef et al.and Henderson et al. used drawings taken from photographs and accordingly were visually complex withmany lines in them, Loftus and Mackworth (1978) used simpler hand-drawn sketches that contained sufficientinformation to convey the intended gist, but little detail. In the one case, the inconsistent object was surround-ed by other objects and lines and appeared against a rich background, and in the Loftus and Mackworth pic-ture the object was drawn against a plain background. Subjectively, looking for the inconsistency in the DeGraef et al. and Henderson et al. pictures requires a fine-grained object-by-object serial search, whereas theinconsistent object in the Loftus and Mackworth example ‘‘pops out’’ and requires no search. One possibility,therefore, is that the objects in some experiments are more visually conspicuous and that this property thenfacilitates their early fixation.
Object conspicuity is known to attract attention, and has led to a theory in which the early allocation ofvisual attention to objects is determined by their visual saliency relative to other objects. Itti and Koch(2000) proposed that during the initial viewing of an image a saliency map is built using low-level visual dis-continuities of colour, intensity and line orientation. Saliency peaks on this map represent regions that are dis-tinct from their surroundings, and attention is first attracted to the highest peak. Once a fixation has beenmade then a process of inhibition of return is activated and attention moves to the next highest peak, andso on. An understanding of the semantics of the scene follows only after attention has been allocated toregions according to their saliency ranks. The model makes good predictions about the early locations ofeye fixations on static and dynamic pictures in free-viewing and recognition memory tasks (Itti, 2006; Park-hurst, Law, & Niebur, 2002; Underwood & Foulsham, 2006; Underwood, Foulsham, van Loon, Humphreys, &Bloyce, 2006), although it is less successful when viewers are required to search the scene for a specific object(Underwood & Foulsham, 2006; Underwood et al., 2006), and the model has now been modified byNavalpakkam and Itti (2005) to take the purpose of viewing into account. The anomalous objects drawnin the Loftus and Mackworth (1978) pictures may have had higher saliency values than those used in theDe Graef et al. (1990) and Henderson et al. (1999) studies, and this may have been associated with the attrac-tion of early fixations. Of course, saliency does not explain why Loftus and Mackworth found a differencebetween consistent and inconsistent objects—only why the difference does not emerge when the objects areobscured by rich backgrounds. One of the purposes of the present study was to determine whether incongru-ous objects attract early eye fixations in pictures of real-world scenes, and our secondary aim was to investi-gate the role of visual saliency in the attention given to these objects. Photographs rather than line-drawings

162 G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170
were used, and the saliency values of objects used to determine whether the effect of congruency resulted fromtheir conspicuity.
Eye movements were recorded while viewers looked at pairs of pictures that were displayed side by side in acomparative visual search task (Pomplun, Reingold, & Shen, 2001; Pomplun et al., 2001). The task was to saywhether the two pictures were the same or different. On those trials where the two pictures were not identical,there was only one difference between them. Each scene had a readily identifiable gist, with background items(furniture, domestic appliances) and other objects that were contextually consistent. Scenes were photo-graphed a second time with one object replaced, and this object was either consistent with the gist, or itwas out of place. The saliency values of all objects were determined used an algorithm described by Ittiand Koch (2000), and a set of pictures created in which the new object was conspicuous or inconspicuous,as well as being congruent or incongruent.
The comparative visual search (CVS) task—known in newspapers as a ‘spot the difference’ game—was usedbecause it requires a search of objects in the scene rather than a search for one object. In previous experiments,we have used a task in which viewers searched for a target object—a piece of fruit or a small ball—and theother objects could be neglected completely, resulting in loss of eye fixation data (Underwood & Foulsham,2006; Underwood et al., 2006). In the CVS task used here the object of interest that varied in congruency andsaliency, was also the object that was changed between pictures, and so inspection was highly probable. Thistask has been used previously to establish that viewers characteristically make a series of comparative fixa-tions, looking first at an object in one picture and than at the corresponding region in the other picture todetermine whether they are identical or not. This object-to-object comparison strategy has been reported instudies using computer-generated images of indoor scenes (Gajewski & Henderson, 2005) and using arraysof objects (Galpin & Underwood, 2005). Detection of a difference depended upon direct fixation of the chan-ged object in those studies, indicating that the task is performed with a serial comparison of objects. Using avariable number of circular Gabor patches with varying contrast as their paired stimuli, Scott-Brown, Baker,and Orbach (2000) have established that even with simple stimuli task performance depends upon the numberof elements to be compared, confirming the serial nature of the search for changes. This suggests that viewersmake little use of visual memory, and rely instead upon a serial comparison process of individual objects.Accordingly, we expected a high proportion of fixated target objects here. The question asked with the exper-iment was whether fixations were attracted by the incongruency and by the conspicuity of an object in thescene.
2. Methods
2.1. Participants
The volunteers were 24 members of the university community who were paid for their participation. All hadnormal or corrected-to-normal vision.
2.2. Materials and apparatus
Pairs of digital colour photographs were prepared for presentation on a 36 · 27 cm computer monitor, with40 pairs of identical images and 40 pairs with one object replaced in otherwise identical images. An additionaleight pairs of images were prepared for practice. The images were photographs of real-world indoor scenesfrom offices, workshops and domestic rooms. For the pairs containing a change, two photographs were takenfrom the same position, with an object replaced by another of similar size. For the pairs containing no change,a photograph was duplicated. The scenes were photographed in portrait orientation, so that they could be dis-played side by side on the monitor, and there was a gap of 0.5 cm between them (subtending 0.46 deg at theviewing distance of 60 cm). Each of the paired images was shown at 17.8 · 23.0 cm, thereby subtending17.5 · 22.5 deg at the viewing distance.
Four types of changes were made to create the pairs of images that differed by one object. Pairs of objectscould vary in their visual conspicuity and in their semantic congruency. The high conspicuity condition wasdefined by one of the objects having high saliency according to the Itti and Koch (2000) algorithm. The pro-
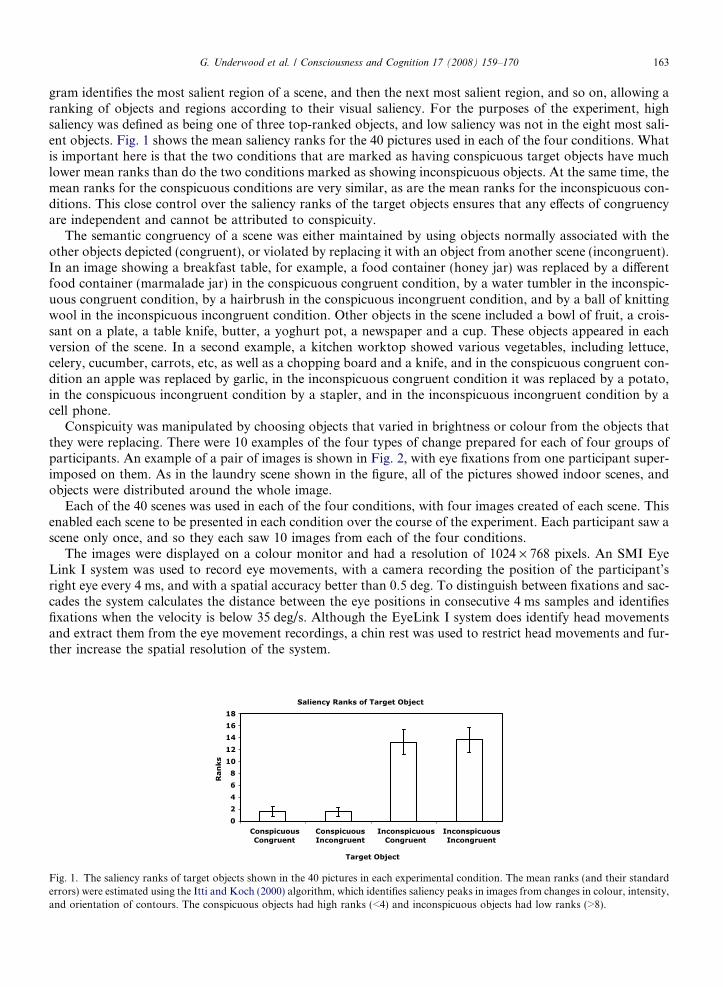
G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170 163
gram identifies the most salient region of a scene, and then the next most salient region, and so on, allowing aranking of objects and regions according to their visual saliency. For the purposes of the experiment, highsaliency was defined as being one of three top-ranked objects, and low saliency was not in the eight most sali-ent objects. Fig. 1 shows the mean saliency ranks for the 40 pictures used in each of the four conditions. Whatis important here is that the two conditions that are marked as having conspicuous target objects have muchlower mean ranks than do the two conditions marked as showing inconspicuous objects. At the same time, themean ranks for the conspicuous conditions are very similar, as are the mean ranks for the inconspicuous con-ditions. This close control over the saliency ranks of the target objects ensures that any effects of congruencyare independent and cannot be attributed to conspicuity.
The semantic congruency of a scene was either maintained by using objects normally associated with theother objects depicted (congruent), or violated by replacing it with an object from another scene (incongruent).In an image showing a breakfast table, for example, a food container (honey jar) was replaced by a differentfood container (marmalade jar) in the conspicuous congruent condition, by a water tumbler in the inconspic-uous congruent condition, by a hairbrush in the conspicuous incongruent condition, and by a ball of knittingwool in the inconspicuous incongruent condition. Other objects in the scene included a bowl of fruit, a crois-sant on a plate, a table knife, butter, a yoghurt pot, a newspaper and a cup. These objects appeared in eachversion of the scene. In a second example, a kitchen worktop showed various vegetables, including lettuce,celery, cucumber, carrots, etc, as well as a chopping board and a knife, and in the conspicuous congruent con-dition an apple was replaced by garlic, in the inconspicuous congruent condition it was replaced by a potato,in the conspicuous incongruent condition by a stapler, and in the inconspicuous incongruent condition by acell phone.
Conspicuity was manipulated by choosing objects that varied in brightness or colour from the objects thatthey were replacing. There were 10 examples of the four types of change prepared for each of four groups ofparticipants. An example of a pair of images is shown in Fig. 2, with eye fixations from one participant super-imposed on them. As in the laundry scene shown in the figure, all of the pictures showed indoor scenes, andobjects were distributed around the whole image.
Each of the 40 scenes was used in each of the four conditions, with four images created of each scene. Thisenabled each scene to be presented in each condition over the course of the experiment. Each participant saw ascene only once, and so they each saw 10 images from each of the four conditions.
The images were displayed on a colour monitor and had a resolution of 1024 · 768 pixels. An SMI EyeLink I system was used to record eye movements, with a camera recording the position of the participant’sright eye every 4 ms, and with a spatial accuracy better than 0.5 deg. To distinguish between fixations and sac-cades the system calculates the distance between the eye positions in consecutive 4 ms samples and identifiesfixations when the velocity is below 35 deg/s. Although the EyeLink I system does identify head movementsand extract them from the eye movement recordings, a chin rest was used to restrict head movements and fur-ther increase the spatial resolution of the system.
Fig. 1. The saliency ranks of target objects shown in the 40 pictures in each experimental condition. The mean ranks (and their standarderrors) were estimated using the Itti and Koch (2000) algorithm, which identifies saliency peaks in images from changes in colour, intensity,and orientation of contours. The conspicuous objects had high ranks (<4) and inconspicuous objects had low ranks (>8).

Fig. 2. An example of a pair of pictures presented in the experiment, with the eye fixations of one viewer superimposed on the image. Thecircles represent fixations, with their durations indicated by their diameters. The first fixation was made to a marker in the center of thescreen, between the two pictures, and the participant then made two fixations on the picture on the right, one of which was sufficiently nearto the incongruous object (a can of tomatoes) to be regarded as an object fixation. A saccade to the left picture was then made to the regionof the picture corresponding to the region where the tomato can would have been. The decision was made shortly after fixating this region.
164 G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170
2.3. Design and procedure
A 2 (high vs. low conspicuity) · 2 (congruent vs. incongruent) within-groups design was used according tothe characteristics of the changed object. The change of object was made equally often to the photographappearing on the right and on the left. There were 10 images in each of the four conditions, with each imagecreated from a readily identifiable scene. Four images were created from each scene, and four sets of imagescompiled for display to different sets of participants. Within each set of images each scene appeared once, andeach of the four experimental conditions was represented equally often. The purpose of this design manipu-lation was to ensure that all participants saw every scene, and that any differences between conditions couldnot be attributed to differences between scenes. Each participant thereby saw images in each of the four con-ditions, and each scene appeared in each condition over the course of the experiment. A further 40 images wereprepared with identical photographs, and so there were equal numbers of same and different trials. All partic-ipants saw the same set of 40 same trials.
The experiment started with a 9-point calibration procedure and once successful a set of eight pairs of pho-tographs used for practice and to demonstrate the type of pictures used. Examples from all conditions wereused during practice. The participants were instructed to first fixate a marker in the center of the computermonitor, and when the pair of photographs appeared they were to say whether they were the same or differentby pressing one of two keys on the computer keyboard. The pair of pictures remained on the screen until theparticipant responded.
3. Results
The measures taken were response accuracy and response time to decide whether the pictures were the sameor different, and eye movement recordings. The data from the same trials were discarded as our variables ofinterest were introduced in the different trials. The same trials were, in effect, fillers. The eye movement record-ings yielded measures of the total number of fixations per trial, the number of fixations made (and the timeelapsed) prior to the first fixation on the introduced, new object, the number of fixations made (and the timeelapsed) prior to the first fixation of the original object of interest, and the duration of the first fixation on theobject introduced into the scene (the changed object) in one picture and the corresponding object that was tobe substituted (the original object) in the other member of the pair. The means of these data are presented inTable 1.

Table 1Measures taken during inspection of pictures containing a change, for pairs in which the change introduced a congruent or incongruentobject, and when the change was visually conspicuous or inconspicuous (standard deviations in parentheses)
Congruent object Incongruent object
Conspicuousobject
Inconspicuousobject
Conspicuousobject
Inconspicuousobject
Inspection time (ms) 3223 (951) 3080 (811) 2775 (591) 2731 (599)Total number of eye fixations 13.12 (4.15) 12.58 (3.69) 11.25 (2.75) 11.04 (2.39)Number of fixations prior to fixation of
changed object8.96 (2.49) 8.63 (2.68) 8.04 (2.16) 7.38 (1.97)
Number of fixations prior to fixation of originalobject
9.29 (2.87) 8.25 (2.59) 7.83 (1.83) 7.96 (2.07)
Time prior to fixation of changed object (ms) 1943 (584) 1857 (642) 1707 (510) 1550 (514)Time prior to fixation of original object (ms) 2051 (686) 1747 (628) 1663 (438) 1737 (559)First fixation duration on changed object (ms) 227 (46) 210 (40) 227 (63) 236 (49)First fixation duration on original object (ms) 229 (39) 222 (99) 237 (45) 237 (48)Total inspection of changed object (ms) 452 (138) 413 (102) 432 (86) 440 (86)Total inspection of original object (ms) 388 (92) 392 (99) 420 (96) 382 (65)
G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170 165
Response accuracy was greater than 85% and no further analysis of the accuracy data was undertaken. Themeans for the total inspection of the display, from onset to the time when the response was made, were sub-mitted to a 2 · 2 analysis of variance with congruency and conspicuity as the factors. This ANOVA showed aneffect of congruency of the replacement object, F(1, 23) = 10.74, MSE = 355497, p < .01, with images contain-ing congruent objects (3152 ms) requiring longer inspection than those with an incongruous object (2753 ms).There was no main effect of conspicuity, F(1,23) = 1.57, MSE = 132666, and no interaction, F < 1. The over-all inspection of the pair of pictures was reflected by the analysis of eye fixations in a second ANOVA. Thenumber of fixations made on a pair of pictures varied according to the congruency of the replacement object,F(1, 23) = 11.72, MSE = 5.976, p < .01, with more fixations when the replacement was congruous (12.85) thanwhen it was incongruous (11.15). There was no main effect of conspicuity, F(1, 23) = 1.29, MSE = 2.614, andno interaction, F < 1.
The remaining analyses were made to determine how quickly the objects of interest were inspected, andused the time and number of fixations made prior to the first fixation on the changed object and on its coun-terpart original object in the pair of images displayed. In the pictures of a laundry scene in Fig. 2, the partic-ipant has quickly found the inappropriate can of tomatoes (incongruous changed object) and moved to inspectthe corresponding location where washing capsules constitute an original object. For these analyses, fixationon an object required a non-moving eye to dwell within 1 deg of the boundary of the object. Three ANOVAs,each with three within-groups factors (changed/original object, high/low congruency, high/low saliency), wereused to analyse measures of: the number of fixations prior to fixation of each object; the time elapsed beforefixation of each object; and the mean duration of the first fixation on each object.
The ANOVA of the number of fixations prior to the first fixation of the two objects of interest object indi-cated a main effect of congruency, F(1, 23) = 8.69, MSE = 5.30, p < .01, with pictures containing two congru-ous objects receiving more fixations (8.78) than those containing an incongruous object (7.80). There was nomain effect of conspicuity, F(1,23) = 1.90, MSE = 5.80, no effect of object inspected, F < 1 and there were nointeractions. This measure is also indicated in Fig. 3, which shows the cumulative probability of fixating anobject, as a function of congruency and conspicuity, on successive fixation numbers up to the twentieth fixa-tion. Whereas the two functions for incongruous objects tend to be higher (i.e., greater probability of fixation)than the two functions for congruous objects, the difference does not appear in the initial fixations on thedisplay.
The ANOVA of the time elapsed prior to the first fixation of the objects also indicated an effect of congru-ency, F(1,23) = 8.10, MSE = 328276, p < .01, with pictures containing two congruous objects receiving laterfixations (1899 ms after display onset) than those containing an incongruous object (after 1664 ms). This anal-ysis showed no main effect of conspicuity, F(1,23) = 2.21, MSE = 305170, no effect of object inspected, F < 1,and no interactions.

Fig. 3. Cumulative probability of fixating a changed object.
166 G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170
The durations of the first fixations on the objects showed an effect of congruency, F(1, 23) = 4.57,MSE = 1459, p < .05, with longer fixations (234 ms) on incongruous objects than on their congruous counter-parts (222 ms). There was no effect of conspicuity, F < 1, no effect of object inspected, F(1, 23) = 1.38,MSE = 1459, and there were no interactions.
4. Discussion
The two aims of this study were (i) to determine whether objects that were inconsistent with the gist of thebackground scene attracted early fixations; and (ii) to determine whether this incongruency effect dependedupon the object being visually conspicuous. The first question was prompted by an inconsistency in previousstudies of incongruity, with one report of the early fixation of an object that was inconsistent with the gist ofthe scene (Loftus & Mackworth, 1978) not confirmed in two subsequent studies that also used eye fixations asthe main measure (De Graef et al., 1990; Henderson et al., 1999). It is important to resolve this questionbecause it has a bearing on the issue of whether objects in scenes can be recognised pre-attentively (see Liet al., 2002; Evans & Treisman, 2005). If they can, then we might expect to see informative or interestingobjects, such as those that violate the gist, being recognised early and without foveal inspection. The represen-tation formed by this pre-attentive recognition process might then be available to the mechanism that guideseye fixations. Objects that attract eye fixations have been processed to the extent that the representation can beused by the eye guidance mechanism, and if it is the scene semantics that influence guidance then we can con-clude that the meaning of the object/scene relationship has been recognised prior to focal attention being givento the object.
The present study provides some support for the view that objects can be recognised prior to their fixationand that this process of recognition can be used to guide future eye movements. The evidence is supportive inthat incongruent objects that violated the scene gist were fixated earlier than objects that were consistent withthe gist. Incongruent objects were fixated earlier than their congruent counterparts and with fewer fixationsbetween onset of the display and first fixation of the object. Other eye fixation measures also indicated an effectof object congruency, including the longer inspection of the display, a greater number of fixations on the dis-play, and longer durations of fixations on the object when the display contained an incongruous object. Thissensitivity to the congruency between the object and the scene indicates that the object is identified to someextent prior to its first fixation. We have not established that objects are fully identified prior to the first fix-ation, only that they have been recognised to the extent that it is established they are not consistent with theother objects in the context of the scene, some of which may have been fixated and fully identified. Prior totheir fixation then, objects may be partially recognised and their relationship with other objects perceived

G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170 167
as being incongruous. This incomplete representation may include the shape, colouring and other visual fea-tures that together will identify the object as belonging to a category of items that are improbable members ofthat scene. In the laundry scene shown in Fig. 2 for example, a can of any variety is improbable in the locationshown, and the viewer does not need to identify it as a food can or as a can of tomatoes to appreciate theincongruency. Closer inspection provides this detail of information, but it may be the early partial identifica-tion that demands fixation of the object.
The results provide only partial support for the early recognition of objects because the first fixation of thecritical object did not occur until several fixations after first inspection of the pictures. Loftus and Mackworth(1978) reported a difference in the probability of fixation between congruent and incongruent objects on thesecond fixation, suggesting that the incongruency was recognised almost immediately upon the appearance ofthe display. In the present experiment, there was no evidence of such an early difference in the fixation ofobjects (see Fig. 3), and there was a mean of 7.8 fixations prior to fixation of the incongruous object. Thiswas lower than the corresponding number of fixations prior to fixation of a congruous object (8.69 fixations),but not indicative of the immediate identification of an object that violated the gist of the scene. Perhaps thiswas a result of using scenes containing more complexity than the line-drawings used by Loftus andMackworth, with more fixations required to build a representation of the image.
One possible explanation of the variability of results found in previous studies that have used line-drawingsis that the incongruency effect may emerge only when the incongruent object is visually salient and is conspic-uous against its background scene. There was no effect of conspicuity according to any of the measures takenhere. This result argues against the hypothesis that the incongruency effect depends upon the visual conspicu-ity of an incongruent object—it was not the brightness or the colour of an incongruent object that resulted inits earlier fixation.
The absence of an effect of conspicuity on the attention given to pictures of real-world scenes contradictsthe predictions made by models of visual saliency that suggest that the early representation of an image is builtwith low-level visual features and that it is these features that are used by the eye guidance mechanism(Henderson et al., 1999; Itti, 2006; Itti & Koch, 2000). The first stage of picture processing involves the build-ing of a saliency map according to these models, and this map uses visual discontinuities such as brightness,colour and line orientation rather than the identities of the objects depicted. Only after scanning the image is asemantic representation developed. The early appreciation of the gist of a scene (for example, Biederman,1972; Biederman et al., 1973, 1974; Potter, 1976; Potter & Levy, 1969; Potter et al., 2002), and the difficultyin identifying objects that violate the gist (for example, Biederman et al., 1982; Boyce et al., 1989; Davenport &Potter, 2004) argue for scene semantics being appreciated within the first glimpse of a display, and so perhapsthe visual saliency map can be built in parallel with a semantic saliency map. In some tasks the conspicuity ofan object attracts early fixations, but in others it appears to be of minimal importance. When set a task toeither freely inspect a scene (Parkhurst et al., 2002) or to inspect it in preparation for a recognition memorytest (Underwood & Foulsham, 2006; Underwood et al., 2006), the saliency values of objects made good pre-dictions about the locations of fixations during the early inspection of the picture. When searching for specificobjects however, viewers did not tend to look at conspicuous objects. By analogy, when searching for a bunchof keys on a cluttered desktop our eyes are not drawn to brightly coloured pens or to the gleaming covers ofstudent textbooks, but to locations determined by the probability of finding the keys. This is the cognitiveoverride of visual saliency and is representative of purposeful inspection. In the search task used here the view-er’s purpose was not to find a specific object, and the target object could, in principle be located anywhere inthe scene. Visual saliency again did not predict early fixations, however, and this questions the generality of thesaliency map hypothesis.
Loftus and Mackworth (1978) suggested a three-stage model of scene perception that it largely confirmedby the current evidence. These stages are the rapid determination of the gist of a scene, the partial recognitionof objects in the scene, and the computation of the conditional probabilities of objects appearing in that scene.The eye guidance mechanism then makes use of these conditional probabilities, directing fixations to objectswith low probability of occurrence. The first two stages must occur in parallel, otherwise we have the conun-drum of the gist being recognised prior to identification of the component objects. If there is partial identifi-cation of the objects—we might recognise an object as a bottle, or a piece of fruit, for example, withoutidentifying the type of bottle or the type of fruit—then the gist of the scene can be established as the sum

168 G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170
of the features identified. An object that violates the gist may then cause a perturbation or discontinuity in thissemantic saliency map and this activity will attract fixations as the viewer attempts to resolve the inconsisten-cy. This model of scene perception may resolve the paradox of why incongruent objects are difficult to identifyand yet attract eye fixations. The partial recognition of a non-fixated object may be sufficient to determine thatit violates the gist of the scene and that it requires more detailed inspection, and when it is fixated the incon-sistency between the object and its context delays full identification. An alternative to this view of gist iden-tification comes from recent work on low-level vision.
Individual objects may be represented incompletely according to the model assumed here, and this incom-plete processing may be sufficient to indicate that they are incongruous. The scene itself may be processed to apoint where the gist or schema is perceived without detailed knowledge being available to identify isolatedobjects. An alternative view presented by Oliva and Torralba (2001) argues that scenes can be categorisedaccording to general categories that correspond to their gist on the basis of low-level early visual processing.Perhaps then, scenes can be recognised prior to object identification. This early processing delivers a represen-tation of the shape of the scene—what Oliva and Torralba call the ‘‘spatial envelope’’. Boundaries such ashorizontal surfaces, walls, sections and the roughness of those surfaces can be determined using coarse visualinformation, and can be sufficient to identify the scene as belong to a category such as a city street, a coast, ora forest. They identified five spatial envelope properties (naturalness, openness, roughness, expansion and rug-gedness) that could be used to account for the categorisation responses of participants shown pictures of nat-ural scenes. The spectral structures of the pictures also corresponded to the natural categories of scenes,leading to the suggestion that basic distinctions between scenes can be made using spatial information alone.McCotter, Gosselin, Sowden, and Schyns (2005) established the plausibility of scene categorisation using thespectral distribution of visual information with a task in which viewers successfully placed Fourier-trans-formed images into one of eight categories (e.g., highway, street, coast, mountain). Further, the spectral infor-mation associated with these categories was scene-specific, suggesting that an analysis of the spectralcomponents could be used to identify the gist. Schyns and Oliva (1994) also demonstrated how coarse-leveldescriptions of images can facilitate scene recognition prior to identification of the component objects.
Torralba, Oliva, Castelhano, and Henderson (2006) have developed the idea that the spatial envelope canbe used to identify the gist of a scene, in a ‘‘contextual guidance’’ model that infers the semantic category of ascene on the basis of the appearance of basic geometrical forms in combination with the spatial relationshipsbetween regions and otherwise unidentified forms or blobs. In parallel with this analysis of the global imagefeatures is a process of object identification that uses the visual saliency of local regions. In this version of themodel the outputs of a local pathway that uses saliency and the global pathway that uses the scene image fea-tures combine with task constraints to enable the viewer to predict where in the scene the most useful infor-mation is likely to be located. For example, if the task if to search for pedestrians in a scene, the local pathwaywill build a saliency map of regions and objects of high conspicuity that might include an area of high contrastbetween a building and the sky. However, such saliency peaks will be overridden by the output of a parallelprocess of contextual modulation in which the horizontal surface of the street is identified by the global path-way in combination with task knowledge to direct the search to the most likely parts of a street scene wherepedestrians will be found. The global pathway uses Oliva and Torralba’s (2001) spatial envelope to identify theholistical properties of the image and guides attention probabilistically to the most relevant regions.
The early identification of the gist using the low-level spectral components of the image provides an alter-native answer to the paradoxical question of how the gist could be recognised earlier than the componentobjects if recognition of the gist itself depends upon recognition of those components. Oliva and Torralba(2001) have demonstrated how early processing of non-semantic information about a scene can be used toidentify the gist, and the Torralba et al. (2006) model views this process as being in parallel with the identi-fication of regions of local interest. The gist can then be perceived at the same time as objects are recognised,and so the serial inspection of objects in the scene would eventually lead to one of them being recognised asbeing incongruous only after the identification of the gist. This process would account for the apparent conun-drum of the components being recognised prior to the gist, but could only provide an explanation of the pres-ent results if the gist of the pictures used here can be identified using their spectral properties. In the studiesthat demonstrated that the gist can be perceived prior to object identification, viewers classified impoverishedimages as belonging to known categories—city buildings, highways, beaches, fields, mountains and forests, for

G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170 169
example. The images used in the present experiment were cluttered indoor scenes showing desks, worktops,tables and bathrooms, and it is uncertain whether their similarity would prevent the individual identificationof their gists using low-level visual information only. However the gist is recognised—using the spectral prop-erties of the image or using the partial identification of objects in the scene—we have established that incon-gruous objects that violate the gist attract attention more readily than equivalent congruous objects, and thatthis attraction is not dependent upon visual conspicuity.
Acknowledgments
We are grateful to Laurent Itti for the use of his saliency software, to the Nuffield Foundation for theirsupport of this project with award URB/32989, and to the UK Engineering and Physical Sciences ResearchCouncil (EPSRC) for support with project award EP/E006329/1.
References
Antes, J. R. (1974). The time course of picture viewing. Journal of Experimental Psychology, 103, 62–70.Biederman, I. (1972). Perceiving real-world scenes. Science, 177, 77–80.Biederman, I. (1981). On the semantics of a glance at a scene. In M. Kubovy & J. R. Pomerantz (Eds.), Perceptual Organization
(pp. 213–253). Hillsdale, NJ: Erlbaum.Biederman, I., Glass, A. L., & Stacy, E. W. (1973). On the information extracted from a glance at a scene. Journal of Experimental
Psychology, 103, 597–600.Biederman, I., Mezzanotte, R. J., & Rabinowitz, J. C. (1982). Scene perception: detecting and judging objects undergoing relational
violations. Cognitive Psychology, 14, 143–177.Biederman, I., Rabinowitz, J. C., Glass, A. L., & Stacy, E. W. (1974). On the information extracted from a glance at a scene. Journal of
Experimental Psychology, 103, 597–600.Boyce, S. J., Pollatsek, A., & Rayner, K. (1989). Effect of background information on object recognition. Journal of Experimental
Psychology: Human Perception and Performance, 15, 556–566.Davenport, J. L., & Potter, M. C. (2004). Scene consistency in object and background perception. Psychological Science, 15, 559–564.De Graef, P., Christiaens, D., & d’Ydewalle, G. (1990). Perceptual effects of scene context on object identification. Psychological Research,
52, 317–329.Evans, K. K., & Treisman, A. (2005). Perception of objects in natural scenes: Is it really attention free? Journal of Experimental
Psychology: Human Perception and Performance, 31, 1476–1492.Gajewski, D. A., & Henderson, J. M. (2005). Minimal use of working memory in a scene comparison task. Visual Cognition, 12, 979–1002.Galpin, A. J., & Underwood, G. (2005). Eye movements during search and detection in comparative visual search. Perception &
Psychophysics, 67, 1313–1331.Henderson, J. M., Weeks, P. A., & Hollingworth, A. (1999). The effects of semantic consistency on eye movements during scene viewing.
Journal of Experimental Psychology: Human Perception and Performance, 25, 210–228.Itti, L. (2006). Quantitative modelling of perceptual salience at human eye position. Visual Cognition, 14, 959–984.Itti, L., & Koch, C. (2000). A saliency-based search mechanism for overt and covert shifts of visual attention. Visual Research, 40,
1489–1506.Li, F. F., VanRullen, R., Koch, C., & Perona, P. (2002). Rapid natural scene categorization in the near absence of attention. Proceedings
of the National Academy of Sciences (USA), 99, 9596–9601.Loftus, G. R., & Mackworth, N. H. (1978). Cognitive determinants of fixation location during picture viewing. Journal of Experimental
Psychology: Human Perception and Performance, 4, 565–572.Mackworth, N. H., & Morandi, A. J. (1967). The gaze selects informative details within pictures. Perception & Psychophysics, 2,
547–552.McCotter, M., Gosselin, F., Sowden, P., & Schyns, P. (2005). The use of visual information in natural scenes. Visual Cognition, 12,
938–953.Navalpakkam, V., & Itti, L. (2005). Modeling the influence of task on attention. Vision Research, 45, 205–231.Oliva, A., & Torralba, A. (2001). Modeling the shape of the scene: a holistic representation of the spatial envelope. International Journal of
Computer Vision, 42, 145–175.Parkhurst, D., Law, K., & Niebur, E. (2002). Modeling the role of salience in the allocation of overt visual attention. Vision Research, 42,
107–123.Pomplun, M., Reingold, E. M., & Shen, J. (2001). Investigating the visual span in comparative search: the effects of task difficulty and
divided attention. Cognition, 81, 57–67.Pomplun, M., Sichelschmidt, L., Wagner, K., Clermont, T., Rickheit, G., & Ritter, H. (2001). Comparative visual search: a difference that
makes a difference. Cognitive Science, 25, 3–36.Potter, M. C. (1976). Short-term conceptual memory for pictures. Journal of Experimental Psychology: Human Learning and Memory, 2,
509–522.

170 G. Underwood et al. / Consciousness and Cognition 17 (2008) 159–170
Potter, M. C. (1999). Understanding sentences and scenes: the role of conceptual short-term memory. In V. Coltheart (Ed.), Fleeting
Memories: Cognition of Brief Visual Stimuli (pp. 13–46). Cambridge, Mass: M.I.T. Press.Potter, M. C., & Levy, E. I. (1969). Recognition memory for a rapid sequence of pictures. Journal of Experimental Psychology, 81, 10–15.Potter, M. C., Staub, A., Rado, J., & O’Connor, D. H. (2002). Recognition memory for briefly presented pictures: the time course of rapid
forgetting. Journal of Experimental Psychology: Human Perception and Performance, 28, 1163–1175.Schyns, P. G., & Oliva, A. (1994). From blobs to boundary edges: evidence for time and spatial scale dependent scene recognition.
Psychological Science, 5, 195–200.Scott-Brown, K. C., Baker, M. R., & Orbach, H. S. (2000). Comparison blindness. Visual Cognition, 7, 253–267.Torralba, A., Oliva, A., Castelhano, M. S., & Henderson, J. M. (2006). Contextual guidance of eye movements and attention in real-world
scenes: The role of global features in object search. Psychological Review, 113, 766–786.Treisman, A. (2006). How the deployment of attention determines what we see. Visual Cognition, 14, 411–443.Underwood, G. (2005). Eye fixations on pictures of natural scenes: Getting the gist and identifying the components. In G. Underwood
(Ed.), Cognitive Processes in Eye Guidance (pp. 163–187). Oxford: Oxford University Press.Underwood, G., & Foulsham, T. (2006). Visual saliency and semantic incongruency influence eye movements when inspecting pictures.
Quarterly Journal of Experimental Psychology, 18, 1931–1949.Underwood, G., Foulsham, T., van Loon, E., Humphreys, L., & Bloyce, J. (2006). Eye movements during scene inspection: a test of the
saliency map hypothesis. European Journal of Cognitive Psychology, 59, 321–342.


















