
Introduzione al Deep Learning: tecniche e software per...
28
Modena, 16/05/2016 Introduzione al Deep Learning: tecniche e software per applicazioni nell’impresa AKA Deep Learning Exposed Ing. Simone Calderara Imagelab 4 Computer Vision, Pattern Recognition & Machine Learning Dief University Of Modena and Reggio Emilia Contact: [email protected]
Transcript of Introduzione al Deep Learning: tecniche e software per...

Modena,
16/05/2016
Introduzione al Deep Learning: tecniche e software per applicazioni nell’impresa
AKA Deep Learning Exposed
Ing. Simone Calderara
Imagelab 4 Computer Vision, Pattern Recognition & Machine Learning
Dief University Of Modena and Reggio Emilia
Contact: [email protected]
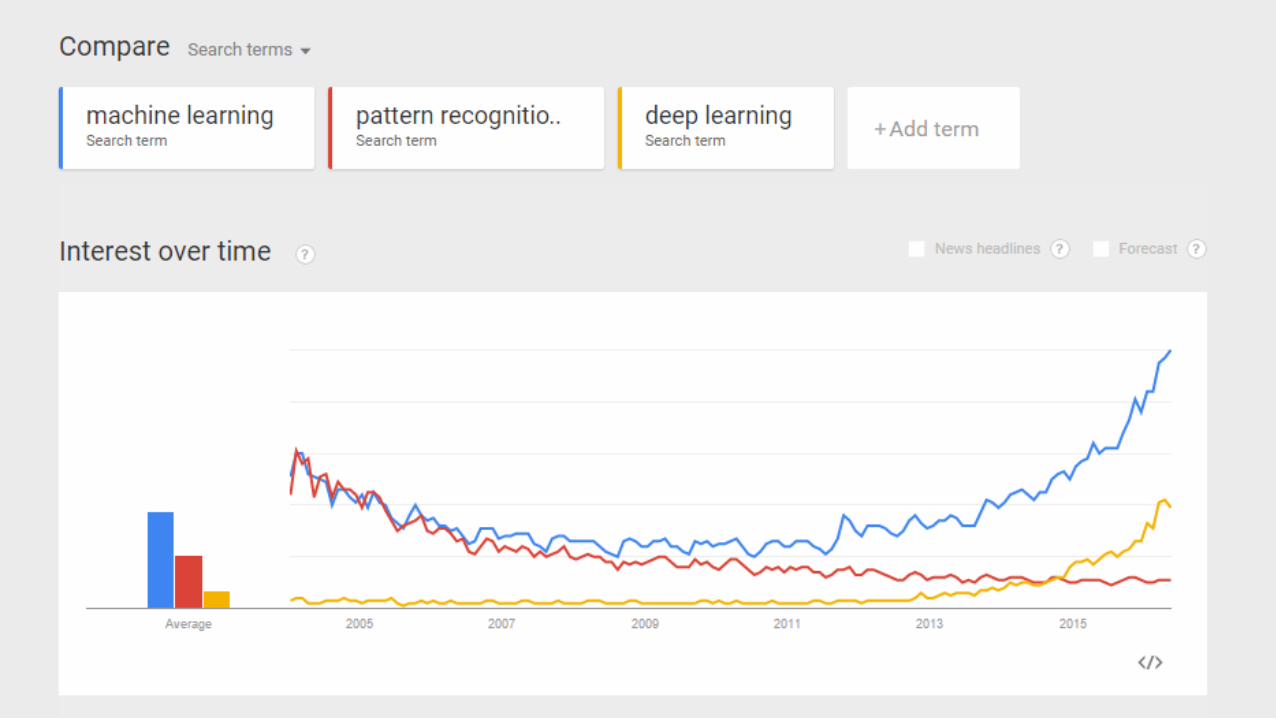

Looking Forward
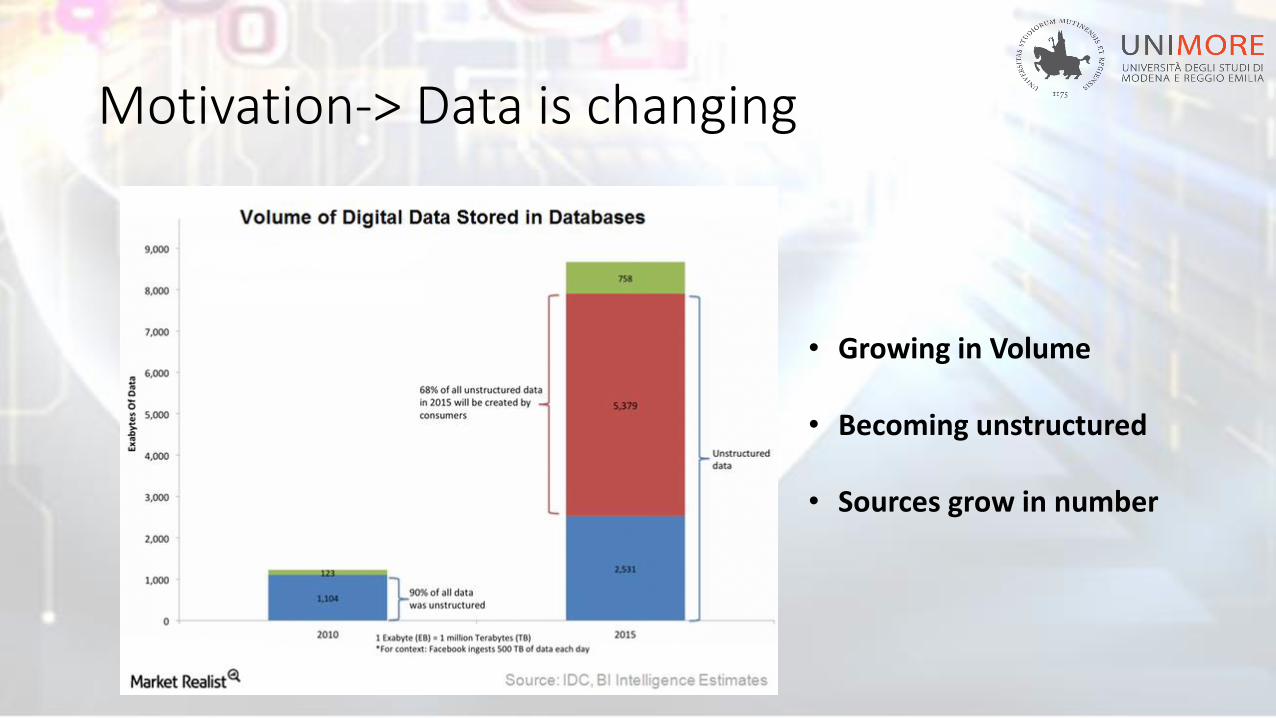
Motivation-> Data is changing
• Growing in Volume
• Becoming unstructured
• Sources grow in number

Investments in the Deep Learning Trend
• «Harward Business Review: Deep Learning is the 10° Tech Trends you can’t ignore in 2015»
• “Gartner Identifies DL in the Top 10 Strategic Technology”
• Software and Service Providers:• IBM ha investito complessivamente in AI 1Billion Dollar 2010-2015• Baidu hired former Google exec Andrew Ng as chief scientist for its U.S.-based lab ( A deep learning expert)• Facebook hired Yan LeCun Deep learning Guru for the Facebook AI Projects• Google created a resident deep Learning LAB the Google Brain Project
• Hardware manifacturer:• Qualcom Snapdragon 820 SDK for deep learning• NVIDIA Deep learning Toolkit Cuda-Based• ….
• Robotic Industries• Toyota• Boston Dynamics
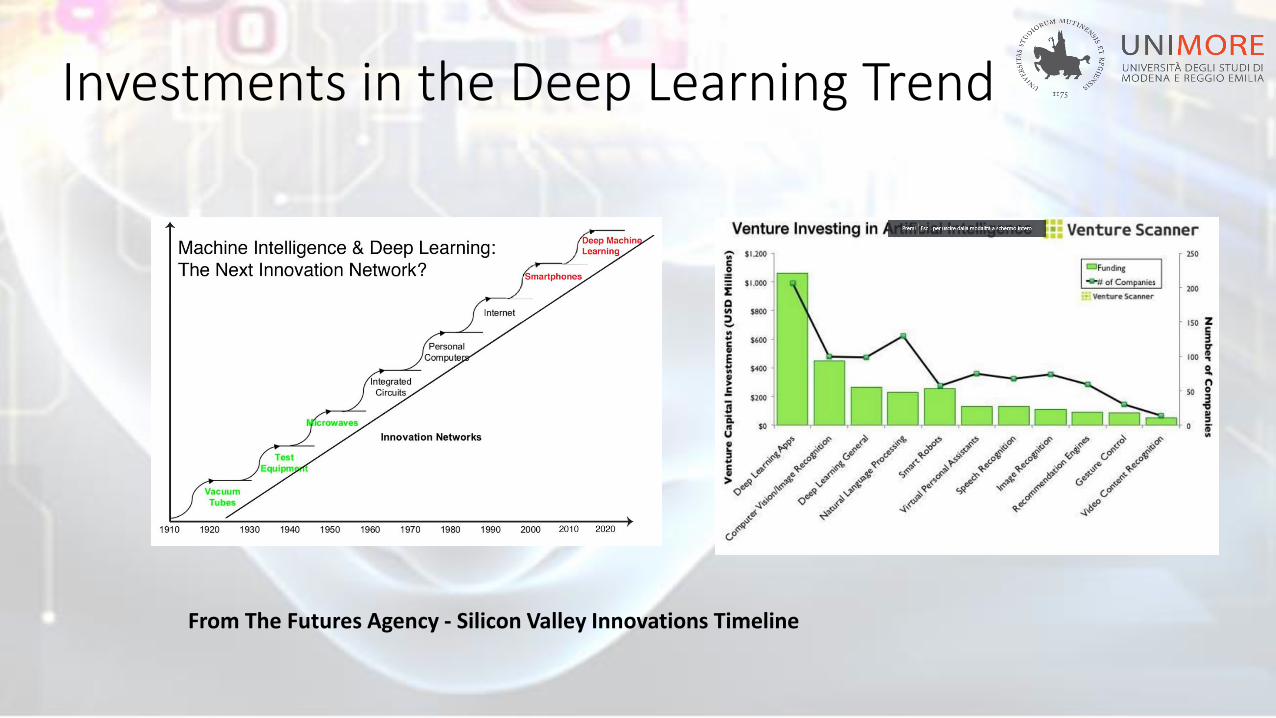
From The Futures Agency - Silicon Valley Innovations Timeline
Investments in the Deep Learning Trend

To 2016-> and the future
• 2008-2013 Years of theoretical studies and hardware production
• 2016->……… Time to bring out the application
• “Google and Movidius who have teamed up to increase adoption (of deep learning technology) within mobile devices.”
• Google changed the «Page Rank» algorithm with «Rank Brain» Deep learning based• Facebook «face recognition» is deep learning based• Google and Apple cars use DL to drive autonomous vehicles• Toyota is spending $1 billion on AI in Silicon Valley for autonomous cars• ….
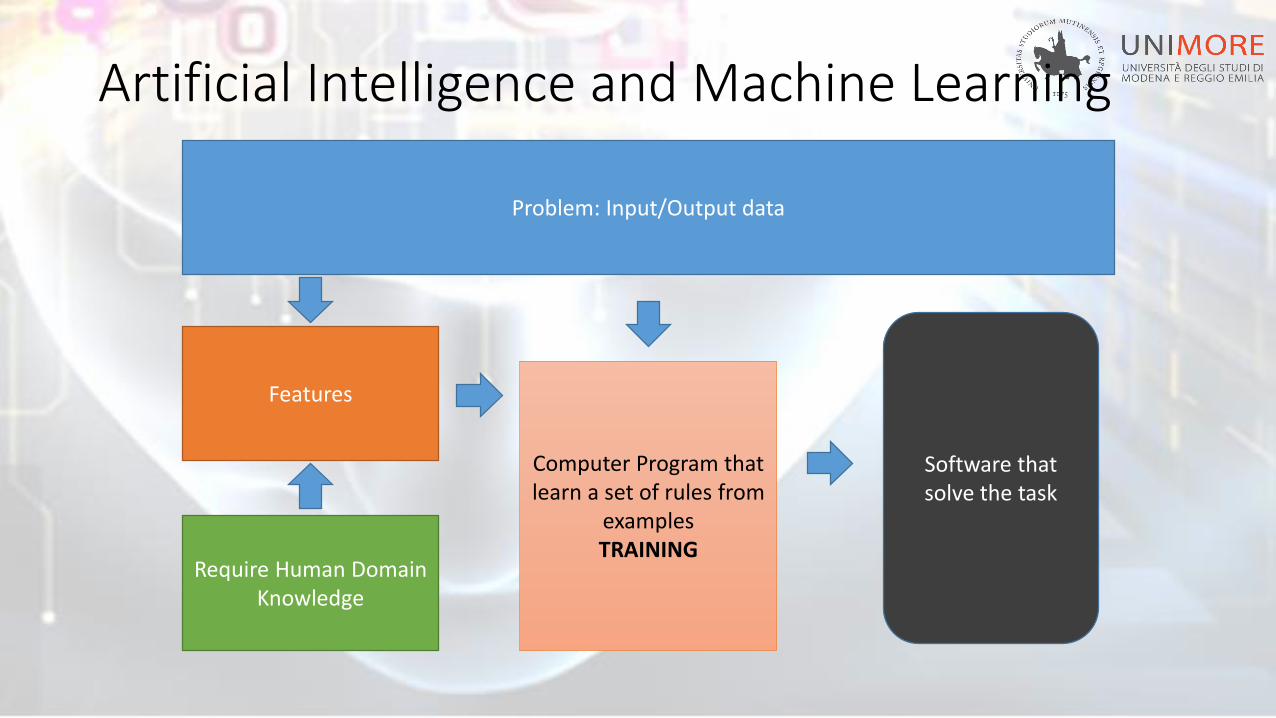
Artificial Intelligence and Machine Learning
Problem: Input/Output data
Features
Require Human Domain Knowledge
Computer Program thatlearn a set of rules from
examplesTRAINING
Software thatsolve the task
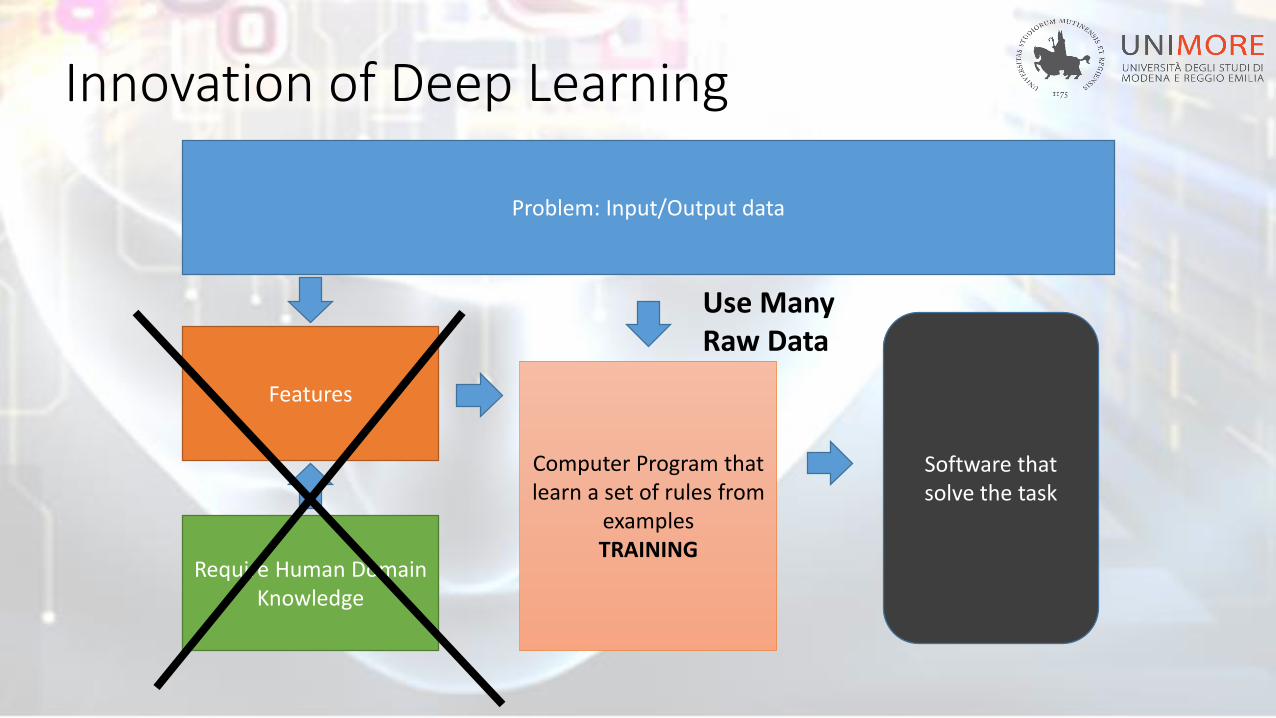
Innovation of Deep Learning
Problem: Input/Output data
Features
Require Human Domain Knowledge
Computer Program thatlearn a set of rules from
examplesTRAINING
Software thatsolve the task
Use ManyRaw Data

Much more Data are needed: OCR Example
Tesseract Google OCR
• 800 Chars needed for Training
• Avg Trainig Time 10 minutes
• Core i7 PC NO GPU
Deep Neural Network
• 5000 chars needed for Training
• Avg Training time 30 minutes
• Core i7 PC + NVIDIA GPU CARD
Technology Accuracy
Tesseract eng language 40%
Tesseract trained language 60%
DEEP neural network(NN)
98%
DEMO code @http://christopher5106.github.io/computer/vision/2015/09/14/comparing-tesseract-and-deep-learning-for-ocr-optical-character-recognition.html
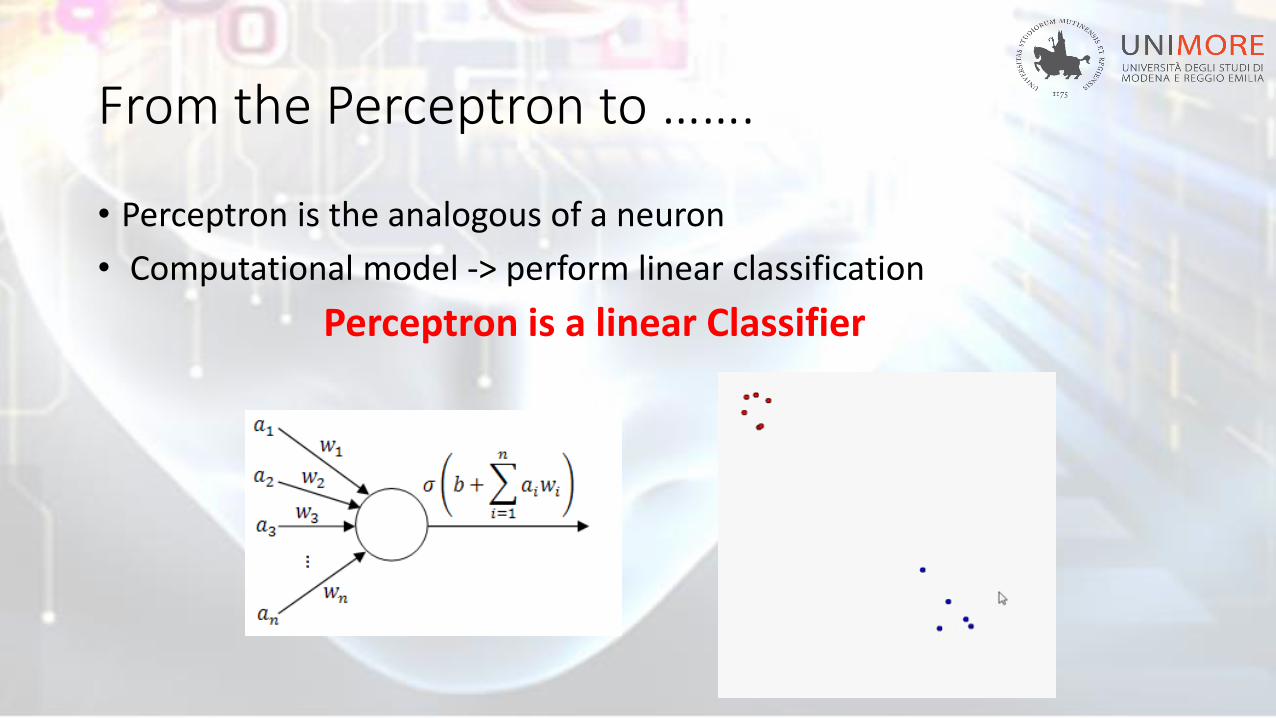
From the Perceptron to …….
• Perceptron is the analogous of a neuron
• Computational model -> perform linear classification
Perceptron is a linear Classifier
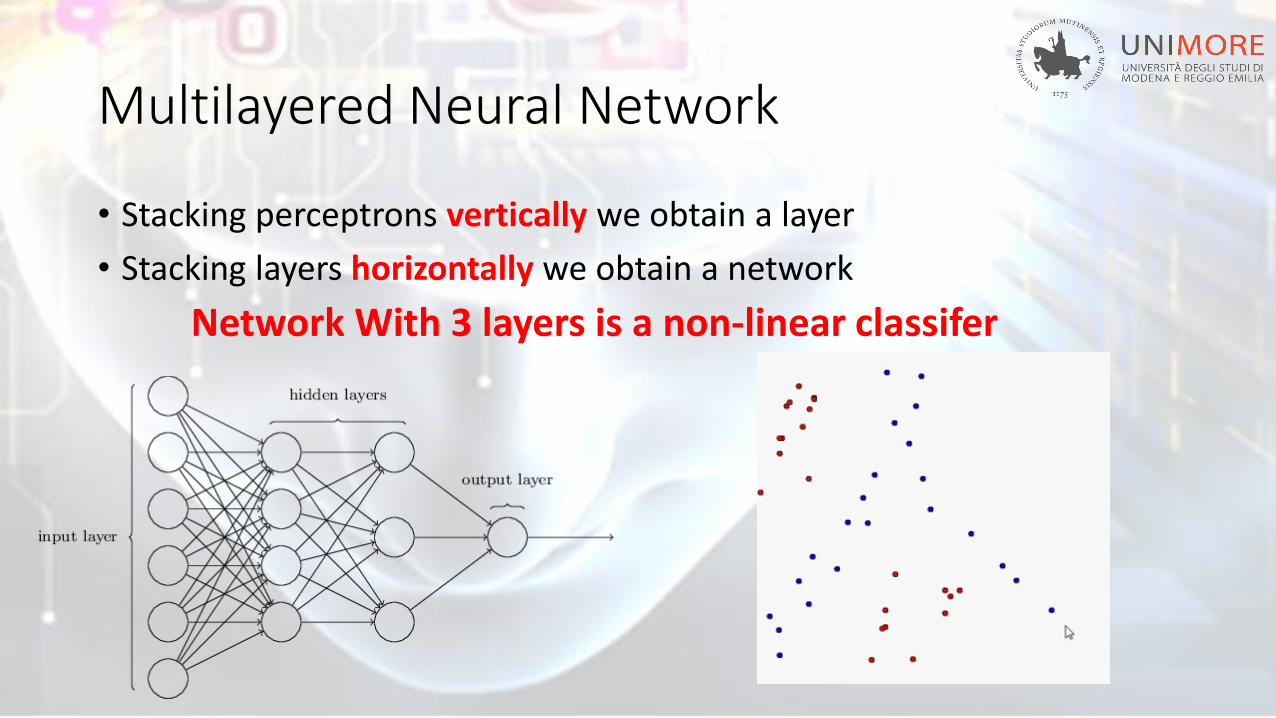
Multilayered Neural Network
• Stacking perceptrons vertically we obtain a layer
• Stacking layers horizontally we obtain a network
Network With 3 layers is a non-linear classifer
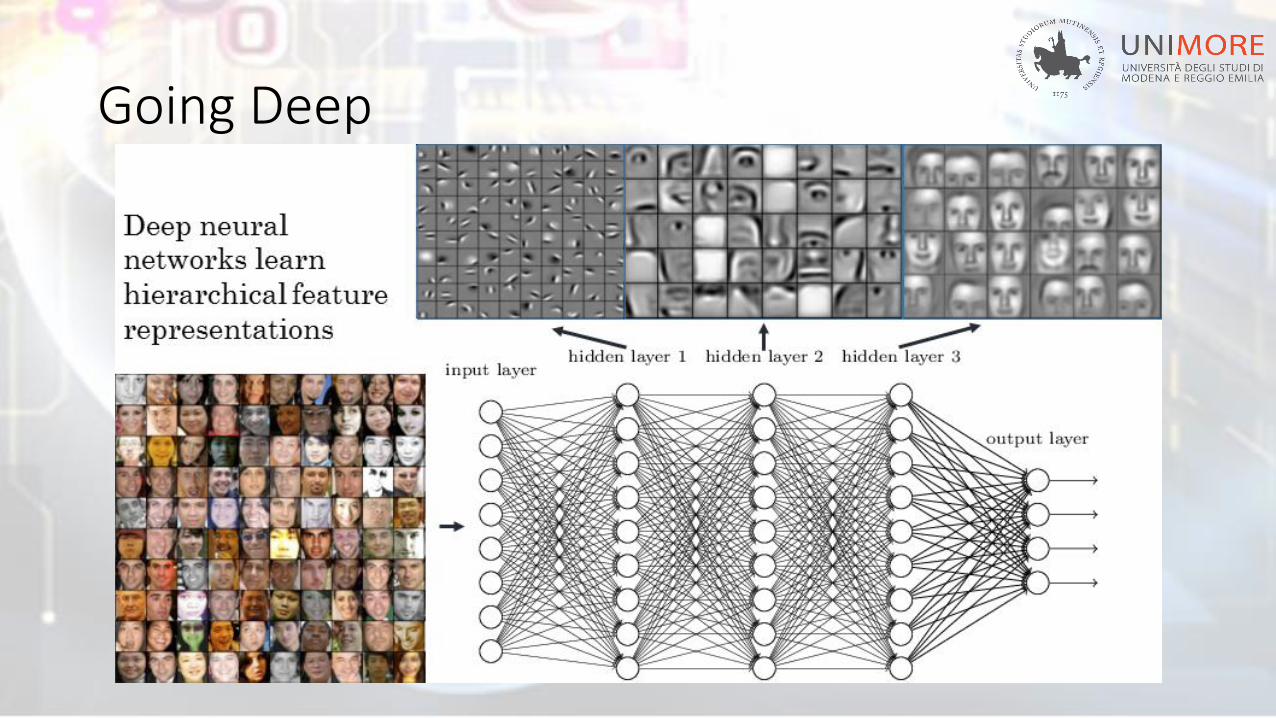
Going Deep
Why using multiples hidden layers?

Deep Networks For:
Numerical Data -> Deep Neural NetworkApplications: Production management, Prediction, Controls and Robotics
Multimedia Data-> Convolutional NetworkApplications: Image and Video classification, Face recognition, Licence Plate Detection, OCRs..
Time series -> Recurrent Neural NetworkApplications: Financial Analysis, Audio and Speech analysis, Text analysis and traslation, Forecasting

Numerical Data -> Deep Neural Network
Pros:• Use Digital Sensors data as input• Theoretically can learn every
classification function• Can predict a flexible number of
outcomes
Cons:• Many parameters to be learned• Many training data needed• Input dimension must be kept
small
From CES2016 Red car is human guided
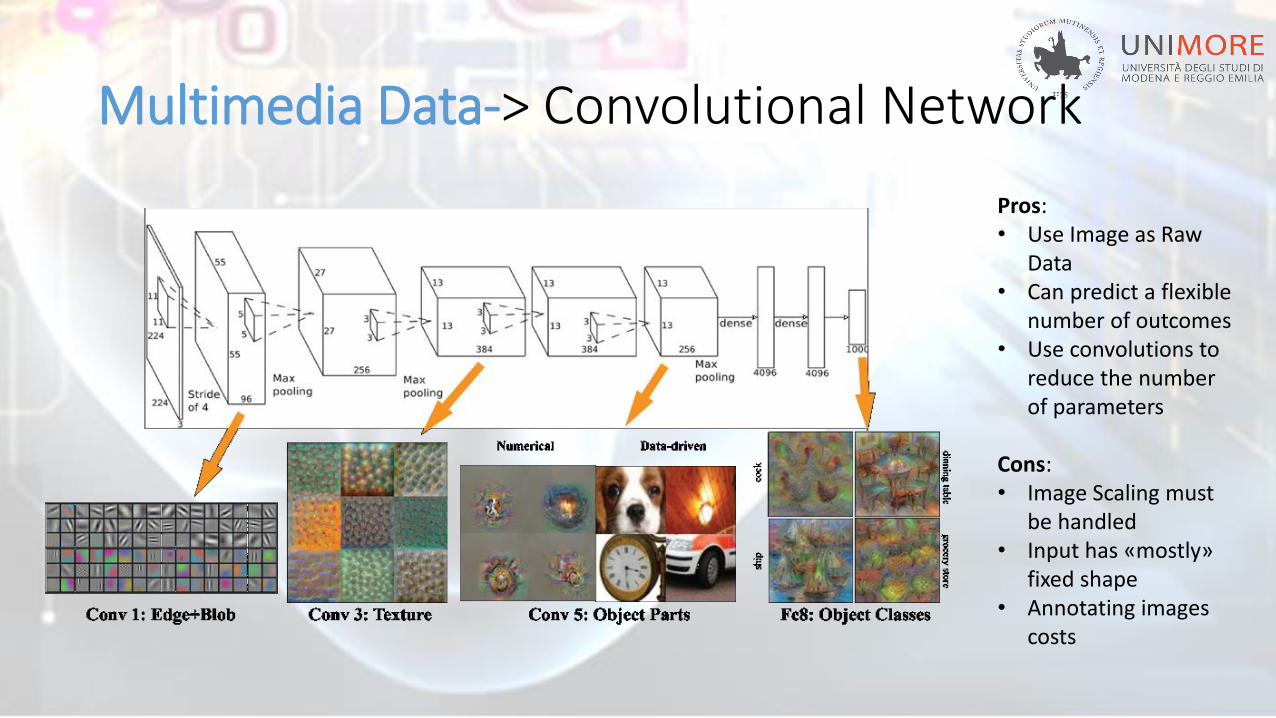
Multimedia Data-> Convolutional Network
Pros:• Use Image as Raw
Data• Can predict a flexible
number of outcomes• Use convolutions to
reduce the numberof parameters
Cons:• Image Scaling must
be handled• Input has «mostly»
fixed shape• Annotating images
costs

Automatic Bin Picking
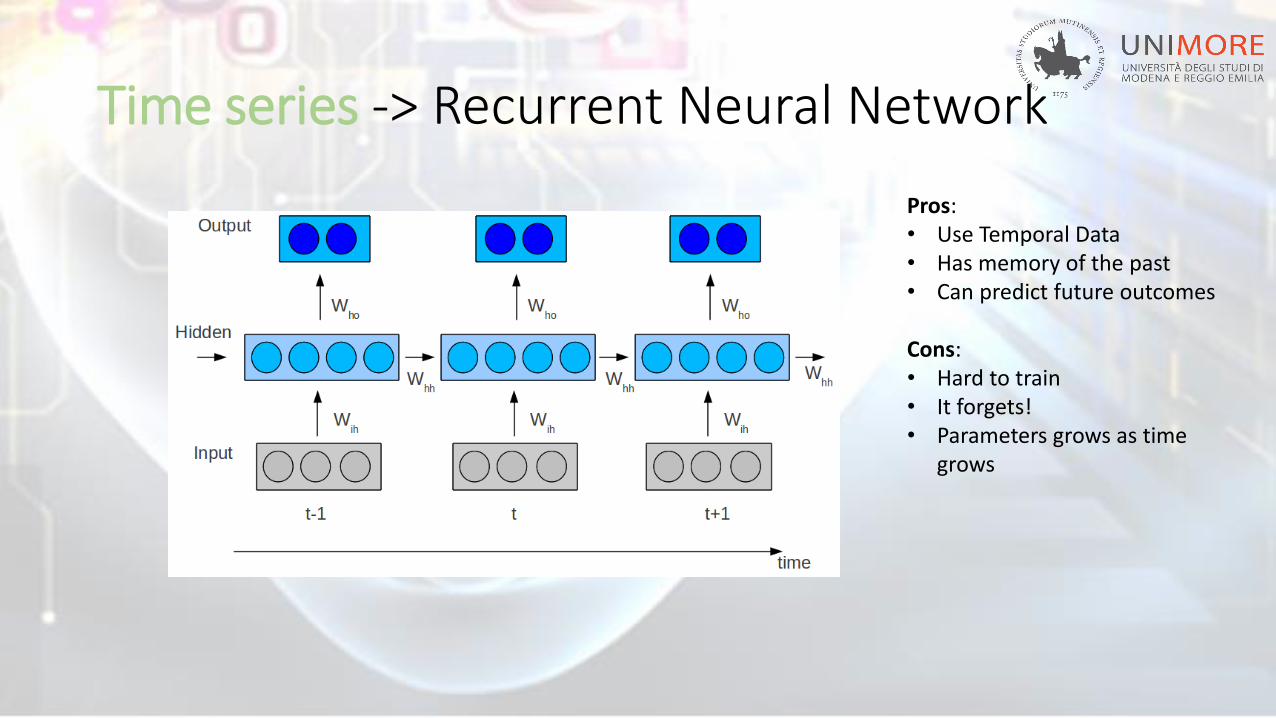
Time series -> Recurrent Neural Network
Pros:• Use Temporal Data• Has memory of the past• Can predict future outcomes
Cons:• Hard to train• It forgets!• Parameters grows as time
grows

Text and Music Writing
Robot Dynamics Control

How to train the models?
Experience is crucial and there are many details and hyperparametrs
There are plenty of tools that help building and training networks
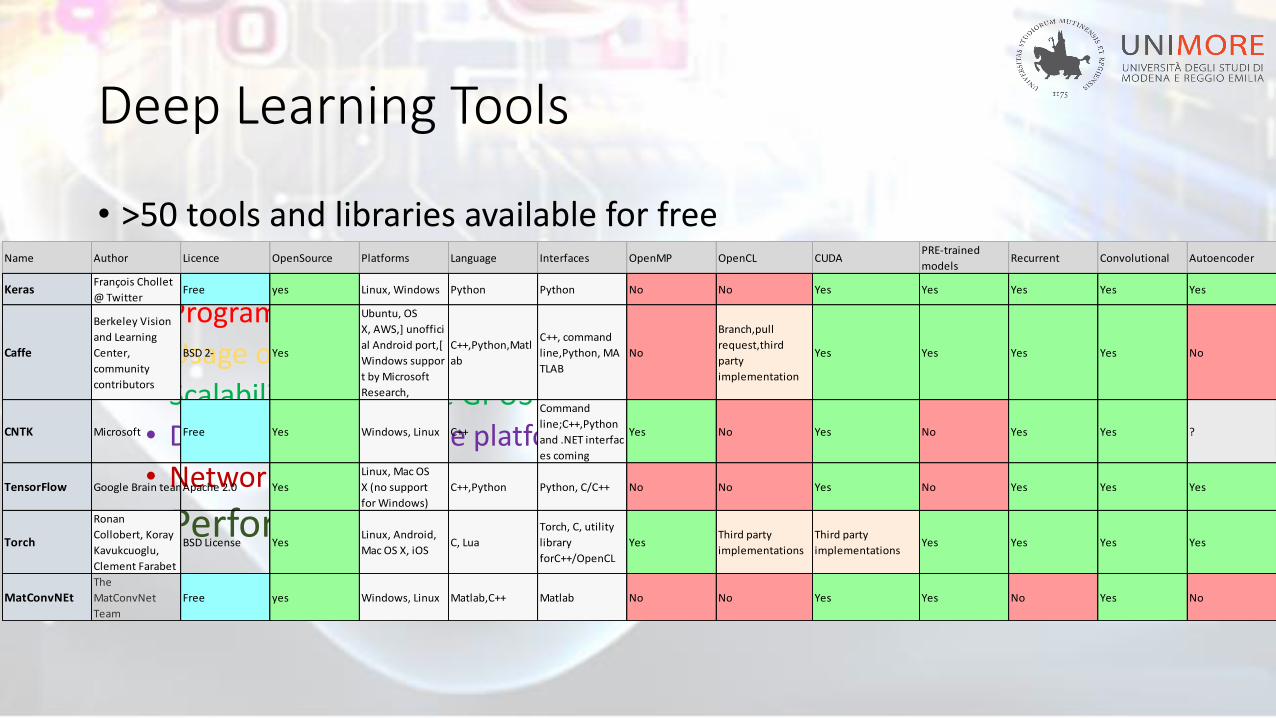
Deep Learning Tools
• >50 tools and libraries available for free
• Tools differs for:• Programming language (C++, Matlab,Java Python)
• Usage of CPU or GPU
• Scalability on multiple GPUS
• Deployment on mobile platform
• Network description (programming language vs meta-scripting language)
• Performance!!
Name Author Licence OpenSource Platforms Language Interfaces OpenMP OpenCL CUDAPRE-trained
modelsRecurrent Convolutional Autoencoder
KerasFrançois Chollet
@ TwitterFree yes Linux, Windows Python Python No No Yes Yes Yes Yes Yes
Caffe
Berkeley Vision
and Learning
Center,
community
contributors
BSD 2- Yes
Ubuntu, OS
X, AWS,] unoffici
al Android port,[
Windows suppor
t by Microsoft
Research,
C++,Python,Matl
ab
C++, command
line,Python, MA
TLAB
No
Branch,pull
request,third
party
implementation
Yes Yes Yes Yes No
CNTK Microsoft Free Yes Windows, Linux C++
Command
line;C++,Python
and .NET interfac
es coming
Yes No Yes No Yes Yes ?
TensorFlow Google Brain teamApache 2.0 Yes
Linux, Mac OS
X (no support
for Windows)
C++,Python Python, C/C++ No No Yes No Yes Yes Yes
Torch
Ronan
Collobert, Koray
Kavukcuoglu,
Clement Farabet
BSD License YesLinux, Android,
Mac OS X, iOSC, Lua
Torch, C, utility
library
forC++/OpenCL
YesThird party
implementations
Third party
implementationsYes Yes Yes Yes
MatConvNEtThe
MatConvNet
Team
Free yes Windows, Linux Matlab,C++ Matlab No No Yes Yes No Yes No

Caffe (http://caffe.berkeleyvision.org)• Expressive architecture Models and optimization
are defined by configuration without hard-coding.
• Switch between CPU and GPU by setting a single flag to train on a GPU machine then deploy to commodity clusters or mobile devices.
• Extensible code fosters active development.
• Speed: Caffe can process over 60M images per day with a single NVIDIA K40 GPU*. That’s 1 ms/image for inference and 4 ms/image for learning.
• Community: Many models available at CaffeModel Zoo
Network description through meta-languagelayer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 64 dim: 1 dim: 28 dim: 28 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}

Keras (http://keras.io)
• Keras is a minimalist, highly modular neural networks library, written in Python and capable of running on top of either TensorFlow or Theano.
• Allows for easy and fast prototyping
• supports both convolutional networks and recurrent networks, as well as combinations of the two.
• supports arbitrary connectivity schemes (including multi-input and multi-output training).
• runs seamlessly on CPU and GPU.
Network description through code
model.add(Dense(512, input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(X_train, Y_train,
batch_size=batch_size, nb_epoch=nb_epoch,
verbose=1, validation_data=(X_test, Y_test))
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])

Tensor Flow (https://www.tensorflow.org/)• TensorFlow isn't a rigid neural networks library.
If you can express your computation as a data flow graph
• TensorFlow runs on CPUs or GPUs, and on desktop, server, or mobile computing platforms.
• Using TensorFlow allows industrial researchers to push ideas to products faster
• Auto-Differentiation Gradient based machine learning algorithms will benefit from TensorFlow's automatic differentiation capabilities.
• TensorFlow comes with an easy to use Python interface and a no-nonsense C++ interface to build and execute your computational graphs
• Maximize Performance supports 32 up to CPU cores and 4 GPU cards
# Hidden 1
with tf.name_scope('hidden1'):
weights = tf.Variable(
tf.truncated_normal([IMAGE_PIXELS, hidden1_units],
stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))),
name='weights')
biases = tf.Variable(tf.zeros([hidden1_units]),
name='biases')
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)
# Hidden 2
with tf.name_scope('hidden2'):
weights = tf.Variable(
tf.truncated_normal([hidden1_units, hidden2_units],
stddev=1.0 / math.sqrt(float(hidden1_units))),
name='weights')
biases = tf.Variable(tf.zeros([hidden2_units]),
name='biases')
hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases)
# Linear
with tf.name_scope('softmax_linear'):
weights = tf.Variable(
tf.truncated_normal([hidden2_units, NUM_CLASSES],
stddev=1.0 / math.sqrt(float(hidden2_units))),
name='weights')
biases = tf.Variable(tf.zeros([NUM_CLASSES]),
name='biases')
logits = tf.matmul(hidden2, weights) + biases
return logits
Network description through Python language

CNTK (https://www.cntk.ai)
• CPU and GPU with a focus on GPU Cluster
• Windows and Linux
• automatic numerical differentiation
• Efficient static and recurrent network training through batching
• data parallelization within and across machines with 1-bit quantized SGD and memory sharing during execution planning
• Modularized: separation of computational networks, execution engine, learning algorithms
• Network definition language (NDL) and model editing language (MEL)
# conv1
kW1 = 5
kH1 = 5
cMap1 = 16
hStride1 = 1
vStride1 = 1
# weight[cMap1, kW1 * kH1 * inputChannels]
# Conv2DReLULayer is defined in Macros.ndl
conv1 = Conv2DReLULayer(featScaled, cMap1, 25, kW1, kH1, hStride1, vStride1, 10, 1)
# pool1
pool1W = 2
pool1H = 2
pool1hStride = 2
pool1vStride = 2
# MaxPooling is a standard NDL node.
pool1 = MaxPooling(conv1, pool1W, pool1H, pool1hStride, pool1vStride, imageLayout=$imageLayout$)
# conv2
kW2 = 5
kH2 = 5
cMap2 = 32
hStride2 = 1
vStride2 = 1
# weight[cMap2, kW2 * kH2 * cMap1]
# ConvNDReLULayer is defined in Macros.ndl
conv2 = ConvNDReLULayer(pool1, kW2, kH2, cMap1, 400, cMap2, hStride2, vStride2, 10, 1)
Network description through meta-language
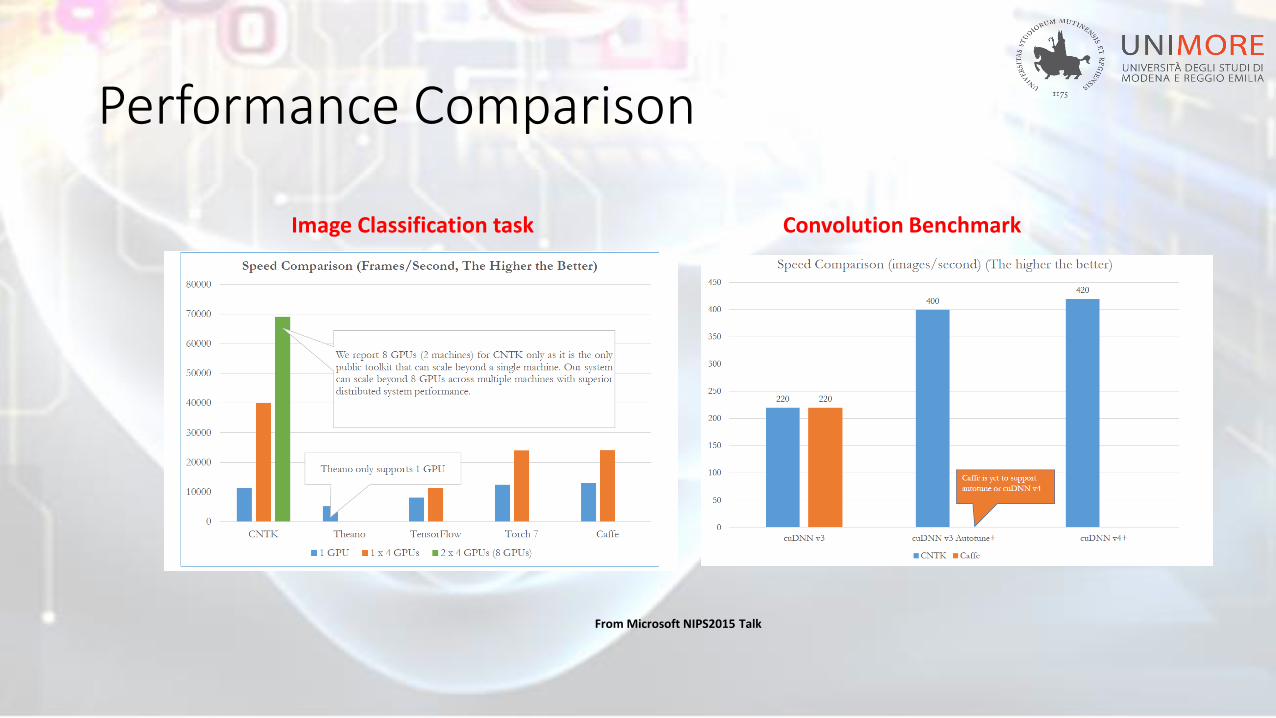
Performance Comparison
Image Classification task
From Microsoft NIPS2015 Talk
Convolution Benchmark

Drawbacks?
They are NOT!
Supervised Deep Learning works surprisingly goodBUT
• Need lot of annotated data-> High Cost
• Training is computational Expensive-> Specific Hardware
• Training a Network is a matter of experience -> DeepNetwork Expert are both scientists and artisans

What Next?
1. Training on raw crowdsourced data ->
DEEP unsupervised Learning
1. Training given an observable reward ->
DEEP reinforcement learning
1. Achieving Real time performance on mobile hardware










![[Ebook ita - security] introduzione alle tecniche di exploit - mori - ifoa - 2003](https://static.fdocuments.in/doc/165x107/55d1308cbb61ebcf5f8b45db/ebook-ita-security-introduzione-alle-tecniche-di-exploit-mori-ifoa.jpg)







