
Introduction to Speech Corpora@Stanford Neal Snider, [email protected] For LIN110, April 12 th,...
26
Introduction to Speech Corpora@Stanford Neal Snider, [email protected] For LIN110, April 12 th , 2005 (adapted from slides by Florian Jaeger)
-
Upload
agatha-phelps -
Category
Documents
-
view
227 -
download
0
Transcript of Introduction to Speech Corpora@Stanford Neal Snider, [email protected] For LIN110, April 12 th,...

Introduction to Speech Corpora@Stanford
Neal Snider,
For LIN110,
April 12th, 2005
(adapted from slides by Florian Jaeger)
Before we get to the real stuff… This presentation will be available online at:
http://www.stanford.edu/dept/linguistics/corpora/material/ling110/
Local support Where are our corpora? Setting up your account on AFS
Local support
Where can you get help with your project? Your TA The Corpora@Stanford website (http://www.
stanford.edu/dept/linguistics/corpora/) The [email protected] email list (you
have to subscribe first) The corpus TA ([email protected])

Where are our corpora? (1)
AFS: AFS is Stanford’s file sharing system The linguistic corpora are stored at:
/afs/ir/data/linguistic-data/
You need to register for AFS access You need to set up your account

Where are our corpora? (2)
Corpus Computer The computer is the one closest to the printer in
the linguistics department’s computer cluster (MJH, 1st floor)
The corpora are stored on partition D:\ Mapping the drive via a network:

The real part
Example project
Overview of available corpora Where to find them How does the annotation look like?
How to search speech corpora

Example projects (1)
Differences in the realization of phonemes depending on their context ‘Context’ can be segmental [1]
How does the realization of syllabic /m/ differ depending on the preceding onset?
Word final vowel aspiration ‘Context’ can be supra-segmental: [3]
How does the realization of syllabic /m/ differ at the beginning/end of conversations/utterances/sentences?
Reduction of complex clusters

Example projects (2)
‘Context’ could also include the register, style (formal vs. informal), genre (reading a fairy tale vs. reading an article), different dialects, etc. [2]
Pitch contours related to specific meanings [1] Steady-state pitch contours
Available corpora
Handout in http://www.stanford.edu/dept/linguistics/corpora/material/X_speech_corpora/X_phonetic corpora.doc
See also: http://www.stanford.edu/dept/linguistics/corpora/

Switchboard – spontaneous AE speech
Transcripts uploaded to AFS: /afs/ir/data/linguistic-data/Switchboard/
Sound files available on CD
available in several formats: All in one file Separate files for
Syllables Words Orthographic transcription

Example annotations (Switchboard) Some files in Switchboard

Switchboard – all in one fileAnnotation key (1)
Key: SENTENCE: word1 word2 ... (2005_A_0041) WORD: word canonical? [lm-probs] [rates]
[positions] [morebigrams] part-of-speech phone1 phone2 ...
SYL: baseform transcribed syl_structure stress length [lm-probs] [rates] [positions]
PHONE: baseform stress syl_part [lm-probs] [rates] [positions] tran1 tran2 ...

Switchboard – all in one fileAnnotation key (2) [lm-probs]= trigram unigram trigram-unigram [rates]= seg_tr_syl seg_tr_phn lex_syl lex_phn enrate vrate nvrate mrate mfrate
enmmfrate mmfrate [positions] = word_num_in_utterance word_num_in_turn [morebigrams] = bigram reverse-bigram reverse-trigram center-trigram part-of-speech = syntactic part of speech (currently only done for the word "to") wordX= word number X in acoustically segmented `sentence' canonical?= can if canonical (pronlex) pronunciation, alt otherwise trigram= p(word | previous two words) unigram= p(word) trigram-unigram = difference between two probabilities seg_tr_syl= transcribed syllable rate between closest two pauses seg_tr_phn= transcribed phone rate between closest two pauses lex_syl= lexical syllabic rate (i.e. as determined from wd transcription) lex_phn= lexical phone rate (i.e. as determined from wd transcription)

Switchboard – all in one fileAnnotation key (3) enrate= old enrate measure vrate= voicing rate nvrate= another voicing rate mrate= sub-part of mrate measure mfrate= sub-part of mrate measure enmmfrate= *this is what we call mrate* average of enrate, mrate,
mfrate mmffrate= average of mrate, mfrate baseform= pronunciation as written in dictionary transcribed= transcribed syllable syl_structure= onset/nucleus/coda markings from dictionary stress= syllable stress marking from dictionary P=primary S=secondary
N=none length= syllable length tranX= transcribed phone X corresponding to baseform phone

QuickTime™ and aTIFF (LZW) decompressor
are needed to see this picture. QuickTime™ and aTIFF (LZW) decompressor
are needed to see this picture.
Arpabet

Example annotations (Switchboard – all in one file)SENTENCE: like finding a proper nursing home (2005_A_0041)WORD: like 1 can -2.408 -2.152 -0.256 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 0 26 l ay kSYL: l_ay_k l_ay_k O_N_C P 0.258 -2.408 -2.152 -0.256 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59
3.48 0 26PHONE: l P O -2.408 -2.152 -0.256 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 0 26 lPHONE: ay P N -2.408 -2.152 -0.256 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 0 26 ayPHONE: k P C -2.408 -2.152 -0.256 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 0 26 kWORD: finding 2 alt -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 f ay n ih
ngSYL: f_ay_n f_ay_n O_N_C P 0.358 -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59
3.48 1 27PHONE: f P O -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 fPHONE: ay P N -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 ayPHONE: n P C -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 nSYL: d_ih_ng NULL_ih_ng O_N_C N 0.117 -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64
3.59 3.48 1 27PHONE: d N O -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 NULL 1 27PHONE: ih N N -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 ihPHONE: ng N C -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 ng

Boston Radio Transcripts
Includes read news etc. (i.e. non-spontaneous read speech)
Transcripts uploaded to AFS at: /afs/ir/data/linguistic-data/Boston-University-Radio
Sound files available on CD

Example annotations (Boston Radio) Boston News Corpus
H# 0 4 >endsil DH 4 5 IH+1 9 10 S 19 9 >This HH 28 5 AA+1 33 9 L 42 12 AX 54 4 DCL 58 3 D 61 1 EY 62 16 >holiday S 78 11 IY+1 89 14 Z 103 7 EN 110 20 …

Example annotations (Boston Radio) XWAVES/PRAAT readable:
signal st43/f3ast43p1 type 1 color 76 font -*-times-medium-r-*-*-17-*-*-*-*-*-*-* separator ; nfields 1 # 0.035000 76 H# 0.085000 76 DH 0.185000 76 IH+1 0.275000 76 S 0.325000 76 HH 0.415000 76 AA+1 0.535000 76 L 0.575000 76 AX 0.605000 76 DCL 0.615000 76 D 0.775000 76 EY 0.885000 76 S …
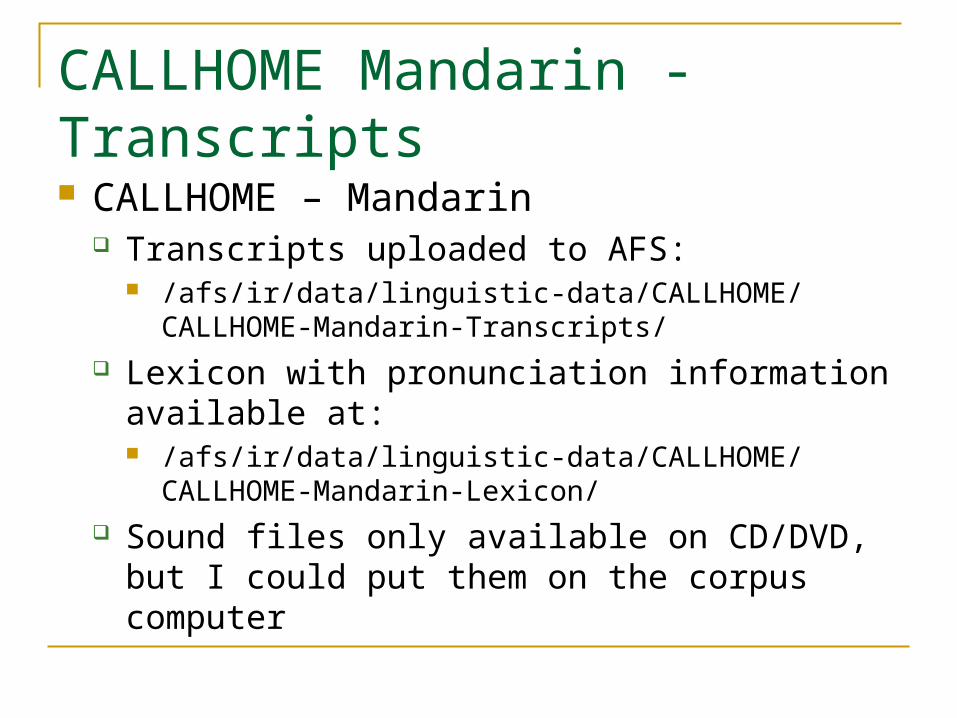
CALLHOME Mandarin - Transcripts CALLHOME – Mandarin
Transcripts uploaded to AFS: /afs/ir/data/linguistic-data/CALLHOME/CALLHOME-
Mandarin-Transcripts/ Lexicon with pronunciation information available
at: /afs/ir/data/linguistic-data/CALLHOME/CALLHOME-
Mandarin-Lexicon/ Sound files only available on CD/DVD, but I could
put them on the corpus computer

TIMIT – dialect variation
Telephone recording of 8 major dialects of American English
(orthographic) transcripts on AFS, sound files available on CD
Comparable dialect corpora exist for the British Isles (IViE; stored on the corpus computer)

Example annotations (TIMIT)
TIMIT Word label (.wrd):
7470 11362 she 11362 16000 had 15420 17503 your 17503 23360 dark 23360 28360 suit 28360 30960 in 30960 36971 greasy
Phonetic label (.phn): (Note: beginning and ending silence regions are marked with h#) 0 7470 h# 7470 9840 sh 9840 11362 iy 11362 12908 hv 12908 14760 ae 14760 15420 dcl 15420 16000 jh 16000 17503 axr
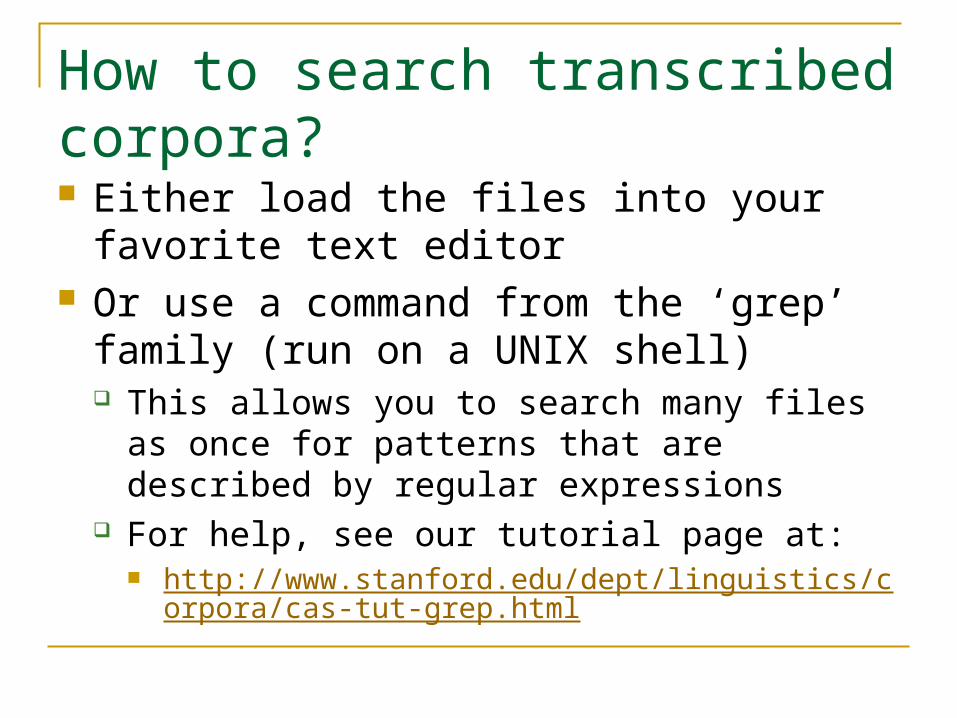
How to search transcribed corpora? Either load the files into your favorite text
editor Or use a command from the ‘grep’ family (run
on a UNIX shell) This allows you to search many files as once for
patterns that are described by regular expressions For help, see our tutorial page at:
http://www.stanford.edu/dept/linguistics/corpora/cas-tut-grep.html

Example annotations (Switchboard – all in one file)SENTENCE: like finding a proper nursing home (2005_A_0041)WORD: like 1 can -2.408 -2.152 -0.256 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 0 26 l ay kSYL: l_ay_k l_ay_k O_N_C P 0.258 -2.408 -2.152 -0.256 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59
3.48 0 26PHONE: l P O -2.408 -2.152 -0.256 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 0 26 lPHONE: ay P N -2.408 -2.152 -0.256 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 0 26 ayPHONE: k P C -2.408 -2.152 -0.256 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 0 26 kWORD: finding 2 alt -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 f ay n ih
ngSYL: f_ay_n f_ay_n O_N_C P 0.358 -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59
3.48 1 27PHONE: f P O -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 fPHONE: ay P N -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 ayPHONE: n P C -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 nSYL: d_ih_ng NULL_ih_ng O_N_C N 0.117 -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64
3.59 3.48 1 27PHONE: d N O -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 NULL 1 27PHONE: ih N N -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 ihPHONE: ng N C -3.604 -4.256 0.652 4.64 10.43 3.87 9.89 3.80 2.32 5.79 2.32 4.64 3.59 3.48 1 27 ng

Demo search
egrep '^SYL: [a-z_]+ [a-z_]*ow.{1,3}m[a-z_]* ’
Actual phonological pattern


















