
Using Natural Language Parsing (NLP) for Automated Requirements Quality Analysis

Introduction to NLP
Syntax and Parsing (Part II)
Prof. Reut TsarfatyBar Ilan University
November 24, 2020

Introducing the Parsing Problem
Previously: What is a Parse Tree?I HierarchicalI Phrase-Structure (all labeled spans)I Dependency-Structure (all lexical relations)
Today: The Parsing Task
Sentence, Grammar→ Parser → Parse-Tree
I The Parsing ObjectiveI Training: Learn the grammarI Prediction: Find the best tree

Previously on NLP@BIU
Formal GrammarA finite generative device that allows usto generate all & only sentences in a language
Definition:A formal G grammar is a tuple
G = 〈T ,N ,S,R〉
I T is a finite set of terminal symbols (alphabet)I N is a finite set of non-terminal symbolsI S ∈ N is start SymbolI R is a finite set of rules

Formal Languages Hierarchy
Formal Languages Hierarchy (Chomsky 1959)I a,b, .. ∈ TI A,B, .. ∈ NI α, β, γ ∈ (N ∪ T )∗
Language RulesRegular A→ aB
A→ BaContext-Free A→ α
Context-Sensitive βAγ → βαγ
Unrestricted α→ β
Natural Language is at least Context-Free!

Context-Free Grammars
A Context-Free GrammarA context free grammar G is a tuple
G = 〈T ,N ,S,R〉
I T is a finite set of terminal symbolsI N is a finite set of non-terminal symbolsI S ∈ N is start SymbolI R is a finite set of context-free
R = {A→ α|A ∈ N and α ∈ (N ∪ T )∗}
InterpretationA→ α ∈ R rewrites A into α independently of A’s context

Context-Free Grammars
Example: A Toy Context-Free Grammar forEnglish
G =
T = {sleeps, saw ,man,woman,dog,with, in, the}N = {S,NP,VP,PP,V0,V1,NN,DT , IN}S ∈ NR =
S → NP VPVP → V0VP → V1 NPNP → DT NNNP → NP PPPP → IN NP
V0 → sleepsV1 → sawNN → manNN → womanNN → dogDT → theIN → withIN → in

What Can We Do with Context-Free Grammars?
Context-Free DerivationI s1 =S // applying S→ NP VP
I s2 = NP VP // applying NP→ DT NNI s3 = DT NN VP // applying DT→ theI s4 = the NN VP // applying NN→ manI s5 = the man VP // applying VP→ V0I s6 = the man V0 // applying V0→ sleepsI s7 = the man sleeps
We say that s1...s7 derives the sentence ”the man sleeps”

What Can We Do with Context-Free Grammars?
Context-Free DerivationI s1 =S // applying S→ NP VPI s2 = NP VP // applying NP→ DT NN
I s3 = DT NN VP // applying DT→ theI s4 = the NN VP // applying NN→ manI s5 = the man VP // applying VP→ V0I s6 = the man V0 // applying V0→ sleepsI s7 = the man sleeps
We say that s1...s7 derives the sentence ”the man sleeps”

What Can We Do with Context-Free Grammars?
Context-Free DerivationI s1 =S // applying S→ NP VPI s2 = NP VP // applying NP→ DT NNI s3 = DT NN VP // applying DT→ the
I s4 = the NN VP // applying NN→ manI s5 = the man VP // applying VP→ V0I s6 = the man V0 // applying V0→ sleepsI s7 = the man sleeps
We say that s1...s7 derives the sentence ”the man sleeps”

What Can We Do with Context-Free Grammars?
Context-Free DerivationI s1 =S // applying S→ NP VPI s2 = NP VP // applying NP→ DT NNI s3 = DT NN VP // applying DT→ theI s4 = the NN VP // applying NN→ man
I s5 = the man VP // applying VP→ V0I s6 = the man V0 // applying V0→ sleepsI s7 = the man sleeps
We say that s1...s7 derives the sentence ”the man sleeps”

What Can We Do with Context-Free Grammars?
Context-Free DerivationI s1 =S // applying S→ NP VPI s2 = NP VP // applying NP→ DT NNI s3 = DT NN VP // applying DT→ theI s4 = the NN VP // applying NN→ manI s5 = the man VP // applying VP→ V0
I s6 = the man V0 // applying V0→ sleepsI s7 = the man sleeps
We say that s1...s7 derives the sentence ”the man sleeps”

What Can We Do with Context-Free Grammars?
Context-Free DerivationI s1 =S // applying S→ NP VPI s2 = NP VP // applying NP→ DT NNI s3 = DT NN VP // applying DT→ theI s4 = the NN VP // applying NN→ manI s5 = the man VP // applying VP→ V0I s6 = the man V0 // applying V0→ sleeps
I s7 = the man sleepsWe say that s1...s7 derives the sentence ”the man sleeps”

What Can We Do with Context-Free Grammars?
Context-Free DerivationI s1 =S // applying S→ NP VPI s2 = NP VP // applying NP→ DT NNI s3 = DT NN VP // applying DT→ theI s4 = the NN VP // applying NN→ manI s5 = the man VP // applying VP→ V0I s6 = the man V0 // applying V0→ sleepsI s7 = the man sleeps
We say that s1...s7 derives the sentence ”the man sleeps”

Derivations and Parse-Trees
Every LMCF Derivation corresponds to a single tree
I s1 = SI s2 = NP VPI s3 = DT NN VPI s4 = the NN VPI s5 = the man VPI s6 = the man V0I s7 = the man sleeps
S
NP
DT
the
NN
man
VP
V0
sleeps

Left-Most Derivations and Parse-Trees
Every LMCF Derivation corresponds to a single tree
I s1 = SI s2 = NP VPI s3 = DT NN VPI s4 = the NN VPI s5 = the man VPI s6 = the man V0I s7 = the man sleeps
S
NP
DT
the
NN
man
VP
V0
sleeps

Left-Most Derivations and Parse-Trees
Every LMCF Derivation corresponds to a single tree
I s1 = SI s2 = NP VPI s3 = DT NN VPI s4 = the NN VPI s5 = the man VPI s6 = the man V0I s7 = the man sleeps
S
NP
DT
the
NN
man
VP
V0
sleeps

Left-Most Derivations and Parse-Trees
Every LMCF Derivation corresponds to a single tree
I s1 = SI s2 = NP VPI s3 = DT NN VPI s4 = the NN VPI s5 = the man VPI s6 = the man V0I s7 = the man sleeps
S
NP
DT
the
NN
man
VP
V0
sleeps

Left-Most Derivations and Parse-Trees
Every LMCF Derivation corresponds to a single tree
I s1 = SI s2 = NP VPI s3 = DT NN VPI s4 = the NN VPI s5 = the man VPI s6 = the man V0I s7 = the man sleeps
S
NP
DT
the
NN
man
VP
V0
sleeps

Left-Most Derivations and Parse-Trees
Every LMCF Derivation corresponds to a single tree
I s1 = SI s2 = NP VPI s3 = DT NN VPI s4 = the NN VPI s5 = the man VPI s6 = the man V0I s7 = the man sleeps
S
NP
DT
the
NN
man
VP
V0
sleeps

Left-Most Derivations and Parse-Trees
Every LMCF Derivation corresponds to a single tree
I s1 = SI s2 = NP VPI s3 = DT NN VPI s4 = the NN VPI s5 = the man VPI s6 = the man V0I s7 = the man sleeps
S
NP
DT
the
NN
man
VP
V0
sleeps

Left-Most Derivations and Parse-Trees
Every LMCF Derivation corresponds to a singleParse-TreeI s1 = SI s2 = NP VPI s3 = DT NN VPI s4 = the NN VPI s5 = the man VPI s6 = the man V0I s7 = the man sleeps
S
NP
DT
the
NN
man
VP
V0
sleeps

Left-Most Derivations and Parse-Trees
Derivation of a StringWe say that G derives s and write G⇒∗ sIff there exists a derivation S ⇒∗ s
Derivation of a treeWe say that G generates tree t and write G⇒∗ tIff there exists a derivation S ⇒∗ s that corresponds to t
Generative CapacityI Weak Generative Capacity
LG = {s|G⇒∗ s}
I Strong Generative Capacity
TG = {t |G⇒∗ t}

Coming Up: How do we parse using a CFG?
Statistical Parsing
→ The Statistical Parsing ObjectiveI Probabilistic Context-Free Grammars (PCFGs)I Search with PCFGsI Training with PCFGs

Strings and Parse-TreesThe Yield FunctionA function from trees to the sequence of terminals in the leaves
Y : TG → LG
String s is GrammaticalIff ∃t1 such that G⇒∗ t1 and Y(t1) = s
String s is AmbiguousIff ∃t1, t2 (t1 6= t2) such that G⇒∗ t1, t2 and Y(t1) = Y(t2) = s
S
NP
NN
time
VP
VB
flies
RB
fast
S
NP
NN
time
NN
flies
VP
VB
fast
http://en.wikipedia.org/wiki/Catalan_number

Strings and Parse-TreesThe Yield FunctionA function from trees to the sequence of terminals in the leaves
Y : TG → LG
String s is GrammaticalIff ∃t1 such that G⇒∗ t1 and Y(t1) = s
String s is AmbiguousIff ∃t1, t2 (t1 6= t2) such that G⇒∗ t1, t2 and Y(t1) = Y(t2) = s
S
NP
NN
time
VP
VB
flies
RB
fast
S
NP
NN
time
NN
flies
VP
VB
fast
http://en.wikipedia.org/wiki/Catalan_number

Strings and Parse-TreesThe Yield FunctionA function from trees to the sequence of terminals in the leaves
Y : TG → LG
String s is GrammaticalIff ∃t1 such that G⇒∗ t1 and Y(t1) = s
String s is AmbiguousIff ∃t1, t2 (t1 6= t2) such that G⇒∗ t1, t2 and Y(t1) = Y(t2) = s
S
NP
NN
time
VP
VB
flies
RB
fast
S
NP
NN
time
NN
flies
VP
VB
fast
http://en.wikipedia.org/wiki/Catalan_number

Strings and Parse-TreesThe Yield FunctionA function from trees to the sequence of terminals in the leaves
Y : TG → LG
String s is GrammaticalIff ∃t1 such that G⇒∗ t1 and Y(t1) = s
String s is AmbiguousIff ∃t1, t2 (t1 6= t2) such that G⇒∗ t1, t2 and Y(t1) = Y(t2) = s
S
NP
NN
time
VP
VB
flies
RB
fast
S
NP
NN
time
NN
flies
VP
VB
fast
http://en.wikipedia.org/wiki/Catalan_number

Strings and Parse-TreesThe Yield FunctionA function from trees to the sequence of terminals in the leaves
Y : TG → LG
String s is GrammaticalIff ∃t1 such that G⇒∗ t1 and Y(t1) = s
String s is AmbiguousIff ∃t1, t2 (t1 6= t2) such that G⇒∗ t1, t2 and Y(t1) = Y(t2) = s
S
NP
NN
time
VP
VB
flies
RB
fast
S
NP
NN
time
NN
flies
VP
VB
fast
http://en.wikipedia.org/wiki/Catalan_number

The Parsing Problem: Our Objective Function
Deriving the objective function:
t∗ = argmax{t |Y(t)=x}P(t |x)
= argmax{t |Y(t)=x}P(t , x)P(x)
= argmax{t |Y(t)=x}P(t , x)
= argmax{t |Y(t)=x}P(t)

The Parsing Problem: Our Objective Function
Deriving the objective function:
t∗ = argmax{t |Y(t)=x}P(t |x)
= argmax{t |Y(t)=x}P(t , x)P(x)
= argmax{t |Y(t)=x}P(t , x)
= argmax{t |Y(t)=x}P(t)

The Parsing Problem: Our Objective
I We will assign probabilities P(t) to parse-trees s.t.
∀t : G⇒∗ t : P(t) > 0
∑G⇒∗t
P(t) = 1
I The probability P(t) ranks parse-trees
t∗ = arg max{t |G⇒∗t}
P(t)
This is the objective function of the parsing problem.I Key Challenges: How to find t? How to calculate P(t)?

The Parsing Problem: Our Objective
I We will assign probabilities P(t) to parse-trees s.t.
∀t : G⇒∗ t : P(t) > 0
∑G⇒∗t
P(t) = 1
I The probability P(t) ranks parse-trees
t∗ = arg max{t |G⇒∗t}
P(t)
This is the objective function of the parsing problem.
I Key Challenges: How to find t? How to calculate P(t)?

The Parsing Problem: Our Objective
I We will assign probabilities P(t) to parse-trees s.t.
∀t : G⇒∗ t : P(t) > 0
∑G⇒∗t
P(t) = 1
I The probability P(t) ranks parse-trees
t∗ = arg max{t |G⇒∗t}
P(t)
This is the objective function of the parsing problem.I Key Challenges: How to find t? How to calculate P(t)?

Coming Up Next:
X The Statistical Parsing Objective→ Probabilistic Context-Free Grammars (PCFGs)I Search with PCFGsI Training with PCFGs

Probabilistic Context-Free Grammars
DefinitionA probabilistic context free grammar G is a tuple
G = 〈T ,N ,S,R,P〉
Where:I 〈T , N , S, R〉 is a CFGI P is a function assigning probabilities to rules:
P : R → (0,1]∑{α|A→α}
P(A→ α) = 1
InterpretationGiven A, it rewrites into (or emits) α in probability P(A→ α),independently of context. Notation: P(A→ α) = P(α|A)

Probabilistic Context-Free Grammars
The probability of a treeI Given a probabilistic context free grammar
G = 〈T ,N ,S,R,P〉I Given a parse-tree t composed of k rules of the form:
A1 → α1,A2 → α2, ... ∈ RI We define:
P(t)=P(A1 → α1)× ...× P(Ak → αk ) =k∏
i=1
P(Ai → αi)
Given the independence assumption of CFG

Probabilistic Context-Free Grammars
The probability of a treeI Given a probabilistic context free grammar
G = 〈T ,N ,S,R,P〉I Given a parse-tree t composed of k rules of the form:
A1 → α1,A2 → α2, ... ∈ RI We define:
P(t)=P(A1 → α1)× ...× P(Ak → αk ) =k∏
i=1
P(Ai → αi)
Given the independence assumption of CFG

Probabilistic Context-Free Grammars: Example
A Toy Grammar for English
G =
T = {sleeps, saw ,man,woman,dog,with, in, the}N = {S,NP,VP,PP,Vi ,Vt ,Vd ,NN,DT , IN}S ∈ NR = Rgram ∪ RlexP =
S → NP VP 1.0VP → V0 0.3VP → V1 NP 0.7NP → DT NN 0.6NP → NP PP 0.4PP → IN NP 1.0
V0 → sleeps 1.0V1 → saw 1.0NN → man 0.2NN → woman 0.2NN → dog 0.6DT → the 1.0IN → with 0.6IN → in 0.4

Probabilistic Context-Free Grammars: Example
Derivation ProbabilityI s1 = S 1.0
I s2 = NP VP × P(S→ NP VP)I s3 = DT NN VP × P(NP→ DT NN)I s4 = the NN VP × P(DT→ the)I s5 = the man VP × P(NN→ man)I s6 = the man V0 × P(VP→ V0)I s7 = the man sleeps × P(V0→ sleeps)
The PCFG generates a tree for ”the man sleeps” with prob:
1.0× 0.6× 1.0× 0.1× 0.3× 1.0 = 0.018

Probabilistic Context-Free Grammars: Example
Derivation ProbabilityI s1 = S 1.0I s2 = NP VP × P(S→ NP VP)
I s3 = DT NN VP × P(NP→ DT NN)I s4 = the NN VP × P(DT→ the)I s5 = the man VP × P(NN→ man)I s6 = the man V0 × P(VP→ V0)I s7 = the man sleeps × P(V0→ sleeps)
The PCFG generates a tree for ”the man sleeps” with prob:
1.0× 0.6× 1.0× 0.1× 0.3× 1.0 = 0.018

Probabilistic Context-Free Grammars: Example
Derivation ProbabilityI s1 = S 1.0I s2 = NP VP × P(S→ NP VP)I s3 = DT NN VP × P(NP→ DT NN)
I s4 = the NN VP × P(DT→ the)I s5 = the man VP × P(NN→ man)I s6 = the man V0 × P(VP→ V0)I s7 = the man sleeps × P(V0→ sleeps)
The PCFG generates a tree for ”the man sleeps” with prob:
1.0× 0.6× 1.0× 0.1× 0.3× 1.0 = 0.018

Probabilistic Context-Free Grammars: Example
Derivation ProbabilityI s1 = S 1.0I s2 = NP VP × P(S→ NP VP)I s3 = DT NN VP × P(NP→ DT NN)I s4 = the NN VP × P(DT→ the)
I s5 = the man VP × P(NN→ man)I s6 = the man V0 × P(VP→ V0)I s7 = the man sleeps × P(V0→ sleeps)
The PCFG generates a tree for ”the man sleeps” with prob:
1.0× 0.6× 1.0× 0.1× 0.3× 1.0 = 0.018

Probabilistic Context-Free Grammars: Example
Derivation ProbabilityI s1 = S 1.0I s2 = NP VP × P(S→ NP VP)I s3 = DT NN VP × P(NP→ DT NN)I s4 = the NN VP × P(DT→ the)I s5 = the man VP × P(NN→ man)
I s6 = the man V0 × P(VP→ V0)I s7 = the man sleeps × P(V0→ sleeps)
The PCFG generates a tree for ”the man sleeps” with prob:
1.0× 0.6× 1.0× 0.1× 0.3× 1.0 = 0.018

Probabilistic Context-Free Grammars: Example
Derivation ProbabilityI s1 = S 1.0I s2 = NP VP × P(S→ NP VP)I s3 = DT NN VP × P(NP→ DT NN)I s4 = the NN VP × P(DT→ the)I s5 = the man VP × P(NN→ man)I s6 = the man V0 × P(VP→ V0)
I s7 = the man sleeps × P(V0→ sleeps)The PCFG generates a tree for ”the man sleeps” with prob:
1.0× 0.6× 1.0× 0.1× 0.3× 1.0 = 0.018

Probabilistic Context-Free Grammars: Example
Derivation ProbabilityI s1 = S 1.0I s2 = NP VP × P(S→ NP VP)I s3 = DT NN VP × P(NP→ DT NN)I s4 = the NN VP × P(DT→ the)I s5 = the man VP × P(NN→ man)I s6 = the man V0 × P(VP→ V0)I s7 = the man sleeps × P(V0→ sleeps)
The PCFG generates a tree for ”the man sleeps” with prob:
1.0× 0.6× 1.0× 0.1× 0.3× 1.0 = 0.018

Probabilistic Context-Free Grammars: Example
Derivation ProbabilityI s1 = S 1.0I s2 = NP VP × P(S→ NP VP)I s3 = DT NN VP × P(NP→ DT NN)I s4 = the NN VP × P(DT→ the)I s5 = the man VP × P(NN→ man)I s6 = the man V0 × P(VP→ V0)I s7 = the man sleeps × P(V0→ sleeps)
The PCFG generates a tree for ”the man sleeps” with prob:
1.0× 0.6× 1.0× 0.1× 0.3× 1.0 = 0.018

Probabilistic Context-Free Grammars: Example
Probability of the derivation == Probability of the treep( S
NP
DT
the
NN
man
VP
V0
sleeps
) =
1.0× 0.6× 1.0× 0.1× 0.3× 1.0 = 0.018
Probability of the string =? Probability of the tree

Probabilistic Context-Free Grammars
The Probability of a stringGiven a probabilistic context free grammar G = 〈T ,N ,S,R,P〉Given a string s yielded by different trees {t |Y(t) = s}
p(s) =∑
{t |G⇒∗t ,Y(t)=s}
p(t)
Note that p(s) defines a language model.It can be formally shown that∑
{s|s∈L(G)}
p(s) = 1

Probabilistic Context-Free Grammars
The Probability of a stringGiven a probabilistic context free grammar G = 〈T ,N ,S,R,P〉Given a string s yielded by different trees {t |Y(t) = s}
p(s) =∑
{t |G⇒∗t ,Y(t)=s}
p(t)
Note that p(s) defines a language model.It can be formally shown that∑
{s|s∈L(G)}
p(s) = 1

Coming Up Next:
X Context-Free Grammars (CFGs)X Probabilistic Context-Free Grammars (PCFGs)→ Search with PCFGsX Training PCFGs

Assume a Sentence s and a CFG G
What Questions Can We Answer?
I Is s derived by G ?I What are all trees t of s derived by G ?I What is the best tree t for s derived by G ?
Fortunately, They are all answered by the same algorithm!

Assume a Sentence s and a CFG G
What Questions Can We Answer?
I Is s derived by G ?I What are all trees t of s derived by G ?I What is the best tree t for s derived by G ?
Fortunately, They are all answered by the same algorithm!

The CYK Algorithm
demo deck

The CYK Algorithm
ObservationThe probability of a tree rooted in X is made up of three termsI The probability of the rule X → YZI The probability of the subtree rooted at YI The probability of the subtree rooted at Z
X
Y
xi ....xs
Z
xs+1....xj
The Dynamic Engine
p(i , j ,X ) = P(X → YZ ) ×p(i , s,Y ) ×p(s + 1, j ,Z )

The CKY Algorithm (Probabilistic Version)
I Input:sentence S = x1...xn, PCFG G = 〈T ,N ,S,R,P〉
I Initialization: // lex rulesFor i ∈ 1...n, for X ∈ N ,I if X → xi ∈ R then CKY (i − 1, i ,X ) = P(X → xi) (o/w 0)
I Algorithm: // gram rulesFor len = 2...(n − 1)
For i = 0...(n − len)Set j = i + lenFor all X ∈ N
CKY (i , j ,X ) = maxX→YZ∈R,s∈(i+1)...(j−1) P(X → YZ )×CKY (i , s,Y )×CKY (s + 1, j ,Z )
BP(i , j ,X ) = arg maxX→YZ∈R,s∈(i+1)...(j−1) P(X → YZ )×CKY (i , s,Y )×CKY (s + 1, j ,Z )

The CYK Algorithm
I Output:I Recognition: If CKY (0,n,S) > 0 return trueI Probability: CKY (0,n,S)I Tree: BP(0,n,S)

The ParseEval Evaluation Metrics
Assume the following trees: How can we compare them?(g) A
B
C
w1
D
w2
E
F
w3(h) A
C
w1
B
D
w2
E
w3

The ParseEval Evaluation MetricsAssume the following trees: How can we compare them?
(g) A
B
C
w1
D
w2
E
F
w3
→
(0, A, 3)(0, B, 2)(0, C, 1)(1, D, 2)(2, E, 3)(2, F, 3)
(h) A
C
w1
B
D
w2
E
w3
→
(0, A, 3)(1, B, 3)(0, C, 1)(1, D, 2)(2, E, 3)

The ParseEval Evaluation MetricsAssume the following trees: How can we compare them?
(g) A
B
C
w1
D
w2
E
F
w3
→
(0, A, 3)(0, B, 2)(0, C, 1)(1, D, 2)(2, E, 3)(2, F, 3)
→
(0, A, 3)(0, B, 2)(0, C, 1)(1, D, 2)(2, E, 3)(2, F, 3)
→ Recall = 46
(h) A
C
w1
B
D
w2
E
w3
→
(0, A, 3)(1, B, 3)(0, C, 1)(1, D, 2)(2, E, 3)
→
(0, A, 3)(1, B, 3)(0, C, 1)(1, D, 2)(2, E, 3)
→ Precision = 45

The ParseEval Evaluation MetricsLet Tg the set of tuples of the gold treeLet Th the set of tuples of the hypothesized treeLet Tintersect = Tg ∩ Th be their set intersection
Precision
P =Tintersect
Th
Recall
R =Tintersect
Tg
Recall
F1 =2× P × R
P + R

The ParseEval Evaluation Metrics
The Standard Practice: Discard Root and POS Tags
(g) A
B
C
w1
D
w2
E
F
w3
→ (0, B, 2)(2, E, 3)
→ Recall = 02
(h) A
C
w1
B
D
w2
E
w3
→ (1, B, 3) → Precision = 01

Probabilistic Context-Free Grammars
Where do the rules/probabilities come from?
I Make them up ourselvesI Ask genius linguists to write rulesI Ask smart linguistic grad-students to annotate treesI And then, easy: Read off a PCFG from the trees

Probabilistic Context-Free Grammars
Where do the rules/probabilities come from?I Make them up ourselves
I Ask genius linguists to write rulesI Ask smart linguistic grad-students to annotate treesI And then, easy: Read off a PCFG from the trees

Probabilistic Context-Free Grammars
Where do the rules/probabilities come from?I Make them up ourselvesI Ask genius linguists to write rules
I Ask smart linguistic grad-students to annotate treesI And then, easy: Read off a PCFG from the trees

Probabilistic Context-Free Grammars
Where do the rules/probabilities come from?I Make them up ourselvesI Ask genius linguists to write rulesI Ask smart linguistic grad-students to annotate treesI And then, easy: Read off a PCFG from the trees

Treebank Grammars
A TreebankI A set of sentences annotated with their correct parse trees
ExamplesI English: The WSJ Treebank for English (40K sentences)I Hebrew: The Haaretz Treebank (6.5K sentences)I Swedish: The TalBanken Treebank (5K sentences)
Also Arabic, Basque, Chinese, French, Czech, Ger-man, Hindi, Hungarian, Korean, Portuguese, Spanish,And more...

Treebank Grammars
Constituency Treebanks Bracketed Format
( (S (NP (DT the)(NN man)) (VP (VB sleeps))))
⇔
S
NP
DT
the
NN
man
VP
VB
sleeps

Treebank Grammars
TrainingI T : all observed terminalsI N : all observed non-terminalsI R : all observed rules in the derivations
I P : Maximum Likelihood Estimation (MLE):We define a count function over the corpus
Count : R → N
And calculate the relative frequencies
P̂(A→ α) =Count(A→ α)∑γ Count(A→ γ)
=Count(A→ α)
Count(A)

Treebank Grammars
TrainingI T : all observed terminalsI N : all observed non-terminalsI R : all observed rules in the derivationsI P : Maximum Likelihood Estimation (MLE):
We define a count function over the corpus
Count : R → N
And calculate the relative frequencies
P̂(A→ α) =Count(A→ α)∑γ Count(A→ γ)
=Count(A→ α)
Count(A)

Treebank Grammars
Training Example
S
NP
NNP
John
VP
VB
likes
NP
NNP
Mary
⇒
S→ NP VP (1)VP→ VB NP (1)NP→ NNP (1)NNP→ Mary (0.5)NNP→ John (0.5)VB→ likes (1)

Treebank Grammars
Training Example
S
NP
NNP
John
VP
VB
likes
NP
NNP
Mary
⇒
S→ NP VP (1)VP→ VB NP (1)NP→ NNP (1)NNP→ Mary (0.5)NNP→ John (0.5)VB→ likes (1)

How Good are Treebank Grammars?
Charniak 1996:A CYK statistical parser based on a treebank grammar trainedon the WSJ Penn Treebank scored F=75 on an unseen testset.

Limitations of Treebank Grammars
Challenges with “Vanilla PCFGs”I Challenge: Independence assumptions are too strongI Challenge: Independence assumptions are too weakI Challenge: Lack of sensitivity to Lexical Information

(1) Independence Assumptions are too Strong
Problem (1): Locality
S
NP
he
VP
V
likes
NP
her
⇒
S → NP VP (1)VP → V NP (1)NP → he (1/2)NP → her (1/2)V → likes (1)
⇒ S
NP
her
VP
V
likes
NP
he

(1) Independence Assumptions are too Strong
Solution (1): Vertical Markovization (v = 0,1,2...)
S
NP@S
he
VP@S
V@VP
likes
NP@VP
her
⇔
S → NP@S VP@S (1)VP → V@VP NP@VP (1)NP@S → he (1)NP@VP → her (1)V@VP → likes (1)

(1) Independence Assumptions are too Strong
Solution (1): Vertical Markovization (v = 0,1,2...)
S
NP@S
he
VP@S
V@VP
likes
NP@VP
her
⇔
S → NP@S VP@S (1)VP → V@VP NP@VP (1)NP@S → he (1)NP@VP → her (1)V@VP → likes (1)

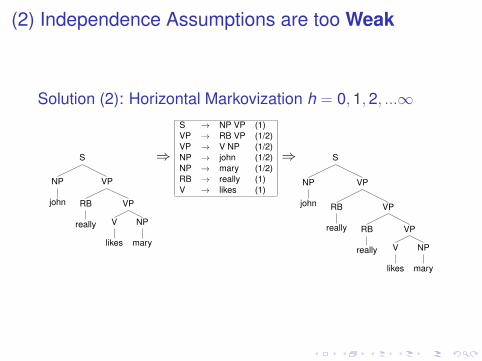
(2) Independence Assumptions are too Weak
Problem (2): Specificity
S
NP
john
VP
RB
really
V
likes
NP
mary
⇒
S → NP VP (1)VP → RB V NP (1)NP → john (1/2)NP → mary (1/2)RB → really (1)V → likes (1)
6⇒ S
NP
john
VP
RB
really
RB
really
V
likes
NP
mary
(2) Independence Assumptions are too Weak
Solution (2): Horizontal Markovization h = 0,1,2, ...∞
S
NP
john
VP
RB
really
VP
V
likes
NP
mary
⇒
S → NP VP (1)VP → RB VP (1/2)VP → V NP (1/2)NP → john (1/2)NP → mary (1/2)RB → really (1)V → likes (1)
⇒ S
NP
john
VP
RB
really
VP
RB
really
VP
V
likes
NP
mary

Two-Dimensional ParameterizationSolution (2): Binarization and Markovization h = 0
VP
V
saw
NN
mary
PP
in-class
PP
on-tuesday
PP
last-week
⇒
VP
V
saw
-@VP
NN
mary
-@VP
PP
in-class
-@VP
PP
on-tuesday
-@VP
PP
last-week

Two-Dimensional ParameterizationSolution (2): Binarization and Markovization h = 1
VP
V
saw
NN
mary
PP
in-class
PP
on-tuesday
PP
last-week
⇒
VP
V
saw
V@VP
NN
mary
NN@VP
PP
in-class
PP@VP
PP
on-tuesday
PP@VP
PP
last-week

Two-Dimensional ParameterizationSolution (2): Binarization and Markovization h = 2
VP
V
saw
NN
mary
PP
in-class
PP
on-tuesday
PP
last-week
⇒
VP
V
saw
-,V@VP
NN
mary
V,NN@VP
PP
in-class
NN,PP@VP
PP
on-tuesday
PP,PP@VP
PP
last-week

Limitations of Treebank PCFGs
Challenges with “Vanilla PCFGs”
X Challenge: Independence assumptions are too strongX Challenge: Independence assumptions are too weak→ Challenge: Lack of sensitivity to Lexical Information

(3) Lack of sensitivity to Lexical Information
Problem (3): No Lexical Dependencies(t1) S
NP
John
VP
VP
V
ate
NP
pizza
PP
P
with
NP
a-fork
(t2) S
NP
John
VP
V
ate
NP
NP
pizza
PP
P
with
NP
a-fork

(3) Lack of sensitivity to Lexical Information
Problem (3): No Lexical Dependencies(t1) S
NP
John
VP
VP
V
ate
NP
pizza
PP
P
with
NP
a-fork
(t2) S
NP
John
VP
V
ate
NP
NP
pizza
PP
P
with
NP
a-fork

(3) Lack of sensitivity to Lexical Information
Problem (3): No Lexical Dependencies(t1) S
NP
John
VP
VP
V
ate
NP
pizza
PP
P
with
NP
olives
(t2) S
NP
John
VP
V
ate
NP
NP
pizza
PP
P
with
NP
olives

(3) Lack of sensitivity to Lexical Information
Solution to (3): Lexicalized GrammarsS
NP
workers
VP
VP
V
dumped
NP
sacks
PP
P
into
NP
bins

(3) Lack of sensitivity to Lexical Information
Solution to (3): Lexicalized GrammarsS
NP/workers
workers
VP
VP
V/dumped
dumped
NP/sacks
sacks
PP
P/into
into
NP/bins
bins

(3) Lack of sensitivity to Lexical Information
Solution to (3): Lexicalized GrammarsS
NP/workers
workers
VP
VP/dumped
V/dumped
dumped
NP/sacks
sacks
PP/bins
P/into
into
NP/bins
bins

(3) Lack of sensitivity to Lexical Information
Solution to (3): Lexicalized GrammarsS
NP/workers
workers
VP/dumped
VP/dumped
V/dumped
dumped
NP/sacks
sacks
PP/bins
P/into
into
NP/bins
bins

(3) Lack of sensitivity to Lexical Information
Solution to (3): Lexicalized GrammarsS/dumped
NP/workers
workers
VP/dumped
VP/dumped
V/dumped
dumped
NP/sacks
sacks
PP/bins
P/into
into
NP/bins
bins

(3) Lack of sensitivity to Lexical Information
Solution to (3): Lexicalized CKYExtending CYK:
X(head)
Y(head)
xi ...xs
Z(dep)
xs+1...xj
Maximizing CYK [i ; j ;head ;X ]:I For all symbols XI For all splits sI For all head possibilities h on the rightI For all head possibilities h on the left

Variations of Phrase Structure Parsing
Challenges with “Vanilla PCFGs”
X Challenge: Independence assumptions are too strongX Challenge: Independence assumptions are too weakX Challenge: Lack of sensitivity to Lexical Information
What’s Next...Are there better/other/quicker alternatives?


















