
Introduction to Information Retrieval (Part 2) By Evren Ermis.
40
Introduction to Information Retrieval (Part 2) By Evren Ermis
-
Upload
stanley-fox -
Category
Documents
-
view
225 -
download
0
Transcript of Introduction to Information Retrieval (Part 2) By Evren Ermis.

Introduction to Information Retrieval(Part 2)
By Evren Ermis

2
Introduction to Information Retrieval
Retrieval models Vector-space-model Probabilistic model Relevance feedback
Evaluation Performance evaluation Retrieval Performance evaluation
Reference Collections Evaluation measures

3
Vector-space-model
Binary weights are too limiting Non-binary weights to index terms
In querie In documents
Compute the degree of similarity Sorting in order of similarity allows
considering documents which match partially

4
Vector-space-model
Considering every document as vector
Similarity by correlation between vectors
5
0
1
3:vector Obtain
5x. t 0x, t 1x, t 3x, t termsindex contains d Document 4321
d
qd
qdqdsim
),(

5
Vector-space-model
Not predicting wether relevant or not But ranking according to similarity Document can be retrieved although
matches the querie only partially Use threshold d to filter documents with
similarity < d

6
Vector-space-model
Index term weights features that better describe the seeked
documents:
intra-cluster similarity distinguish the seeked documents from the
rest:
inter-cluster dissimilarity

7
Vector-space-model
Index term weights Intra-cluster similarity
Inter-cluster dissimilarityjji,
,
,,
ddocument in i index term of frequence freqmax
jll
jiji freq
freqtf
ii n
Nidf log

8
Vector-space-model
Index term weights The weight of a term in a document is then
calculated as product of the tf factor and the idf factor
Or for the queryijiji idftfw ,,
iqll
qiqi idf
freq
freqw
,
,, max
5.05.0

9
Vector-space-model
Advantages Improves retrieval performance Partial matching allowed Sort according to similarity
Disadvantages Assumes that index terms are independent

10
Probabilistic model
Assuming that there is a set of documents, containing exactly the relevant documents and no other (ideal answer set)
Problem is that we don‘t know that set‘s properties Index terms to characterize the properties Use a initial guess at query time to receive a
probabilistic discription of the ideal answer set Use this to retrieve a first set of documents Interaction with user to improve probabilistic
discription of ideal answer set

11
Probabilistic model
Interaction with user to improve probabilistic discription of ideal answer set
The probabilistic approach is to model the description in probabilistic terms without the user
Problem:
Don‘t know how to compute the probabilties of relevance

12
Probabilistic model
how to compute the probabilties of relevance As measure of similarity
P(dj relevant-to q)/P(dj non-relevant-to q)
Odds of document dj being relevant to query q
So using similarity function:
setanswer ideal is R where
|
|1log
|1
|log~),(
1,,
t
i i
i
i
ijiqij
RkP
RkP
RkP
RkPwwqdsim

13
Probabilistic model
Problem:
we don‘t have the set R at the beginning Necessary to find initial probabilities Make two assumptions:
P(kj|R) is constant for all index terms Distribution of index terms among the non-relevant
documents can be approximated by the distribution of index terms among all documents

14
Probabilistic model
So we get:
Now we can retrieve documents containing query terms and provide initial probabilistic ranking for them
N
nRkP
RkP
ij
j
|
5.0|

15
Probabilistic model
Now we can use these retrieved documents to improve our assumed probabilities
Let V be a subset of the retrieved documents and Vi a subset of V containing the i-th index term, then:
VN
VnRkP
V
VRkP
iij
ij
|
|

16
Probabilistic model
Advantages: Documents are ranked in decreasing order of
their probability being relevant Disadvantages:
Need guess for initial separation of relevant and non-relevant documents
Does not consider frequence of occurences of index term in a document

17
Relevance feedback
Query reformulation strategy User depicts relevant documents out of the
retrieval Method selects important terms attached to the
user-identified documents Enhances new gained information in a new
query formulation and reweighting of the terms

18
Relevance feedback for vector model
vectors of relevant documents have similarity among themselves
non-relevant documents have vectors that are dissimilar to the relevant ones
Reformulate the query such that it gets closer to term-weight vector space of the relevant documents

19
Relevance feedback for vector model
ones.relevant -non thefrom documentsrelevant thehingdistinguisfor or query vectbest is
11Then,documents.
relevant all containing ofsubset thebe Let documents. all ofset thebe Let
rjrj Cdj
rCdj
ropt
r
dCN
dC
q
CCC

20
Relevance feedback for probabilistic model
Replacing V by Dr and Vi by Dr,i,
whereas Dr set of user chosen documents, and Dr,i is the subset of Dr containing the index term ki.
r
irij
r
irj
DN
DnRkP
D
DRkP
,
,
|
|

21
Relevance feedback for probabilistic model
Using this replacement and rewriting the similarity function for probabilistic model we get:
Reweighting of the index terms already in the query
Not expanding the query by new index terms
t
i
r
iri
r
iri
r
ir
r
ir
jiqij
DN
Dn
DN
Dn
D
D
D
D
wwqdsim1 ,
,
,
,
,,
1
log
1
log~),(

22
Relevance feedback for probabilistic model
Advantages: Feedback directly related toderivation of new weights Reweighting is optimal under assumptions of
term independence Binary document indexing
Disadvantages: Document term weights not regarded in feedback loop Previous term weights in query disregarded No query expansion
Not as effectively as vector modification method

23
Evaluation
Types of evaluation: Performance of the system(time and space) Functional analysis in which the specified
system functionalities are tested How precise is the answer set Reference collection Evaluation measure

24
Performance Evaluation
Performance of the indexing structures Interaction with the operating system Delays in communication channels Overheads introduced by the many
software layers

25
Retrieval performance evaluation
Reference collection consists of collection of documents Set of example information requests Set of relevant documents for each request
Evaluation measure Uses reference collection Quantifies the similarity between the documents
retrieved by a retrieval strategy and the provided set of relevant documents

26
Reference collection
Exist several different reference collection TIPSTER/TREC CACM CISI Cystic Fibrosis etc.
Choose TIPSTER/TREC for further discussion

27
TIPSTER/TREC
conference „Text Retrieval Conference“ Built under the TIPSTER program Large test collection (over 1 million
documents) For each conference a set of reference
experiments is designed Research groups use these to compare their
retrieval systems

28
Evaluation measure
Exist several different evaluation measures Recall and precision Average precision Interpolated precision Harmonic mean( F-measure ) E-measure Satisfaction, Frustation, etc.
Choose Recall and precision as the most used ones for further discussion
29
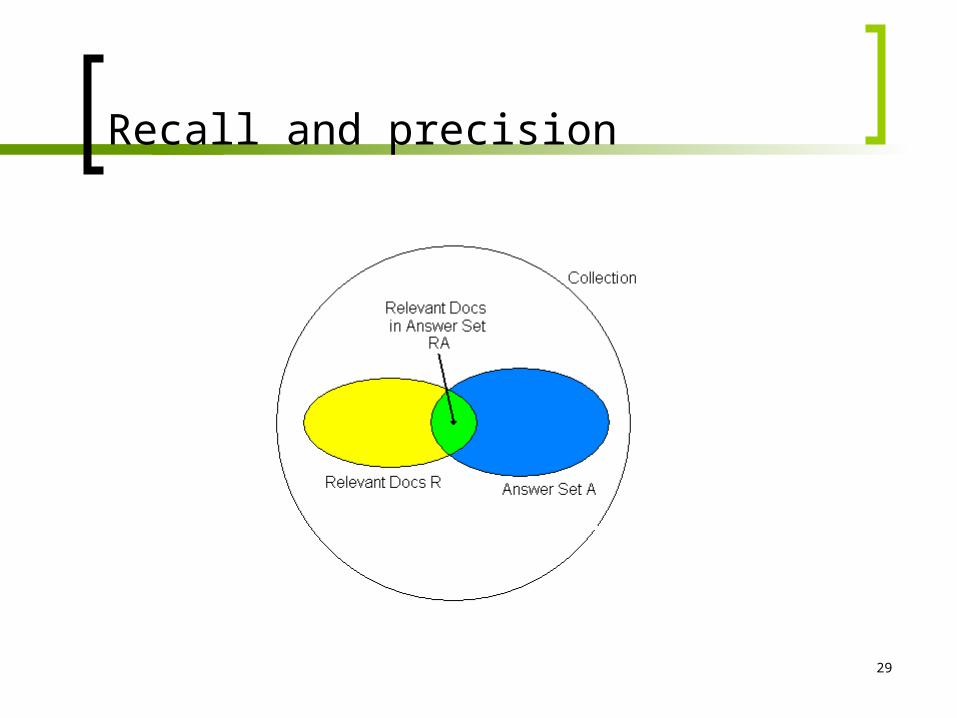
Recall and precision

30
Recall and precision
Definitions for recall: Recall is the fraction of relevant documents which has
been retrieved.
And precision: Precision is the fraction of retrieved documents which is
relevant.
R
RaRecall
A
RarecisionP

31
Precision vs. Recall
Assume that all documents in A have been examined
But user is not confronted with all docs Instead sorted according to relevance Recall and precision vary as the user
proceeds examination of docs Proper evaluation requires precision
vs. recall curve
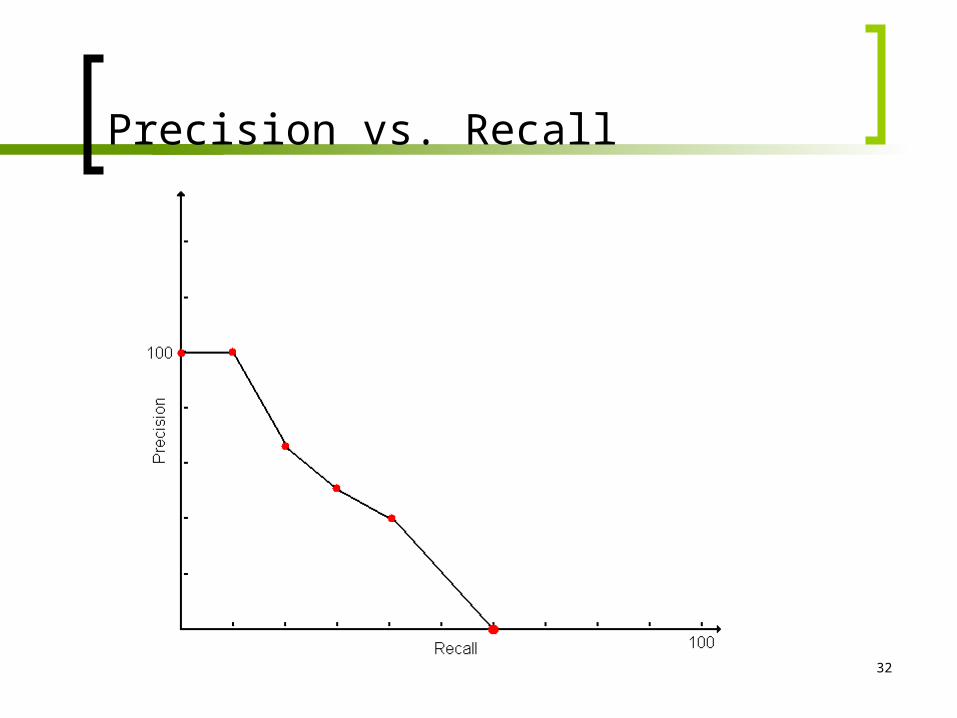
32
Precision vs. Recall

33
Average precision
Example figure for one query To evaluate the retrieval algorithm have
to run several distinct queries Get distinct precision vs. recall curves Average the precision figures at each
recall level
qN
i q
i
N
rPrP
1

34
Interpolated precision
Recall levels for each query distinct from 11 standard recall levels
Interpolation procedure is necessary Let rj be the j-th standard recall level with
j=1,2,…,10. Then,
rPrPjj rrrj 1
max
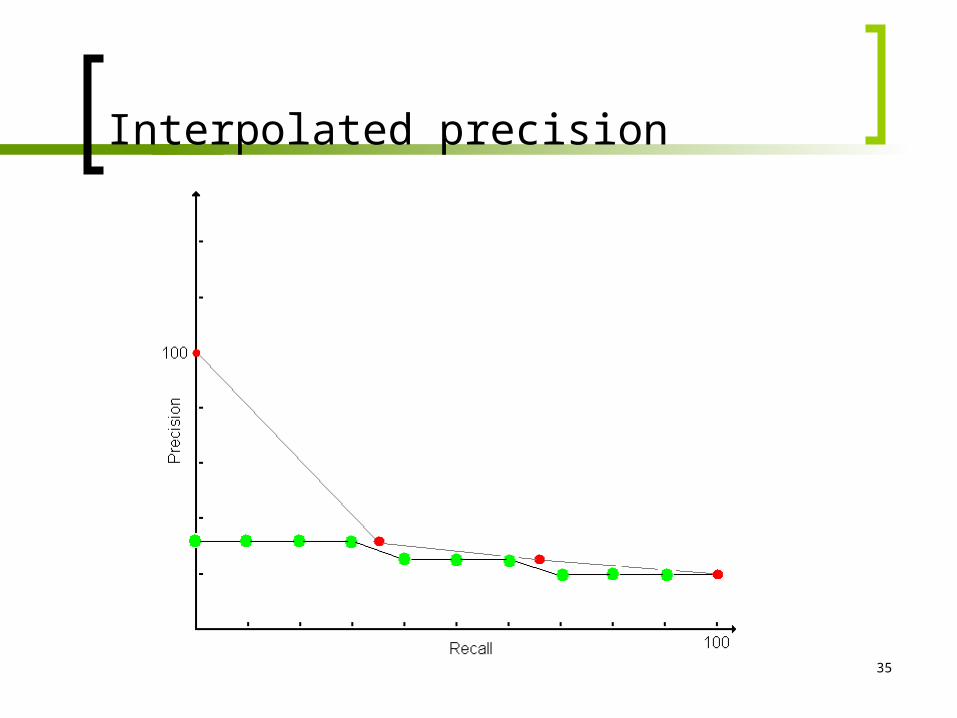
35
Interpolated precision
36
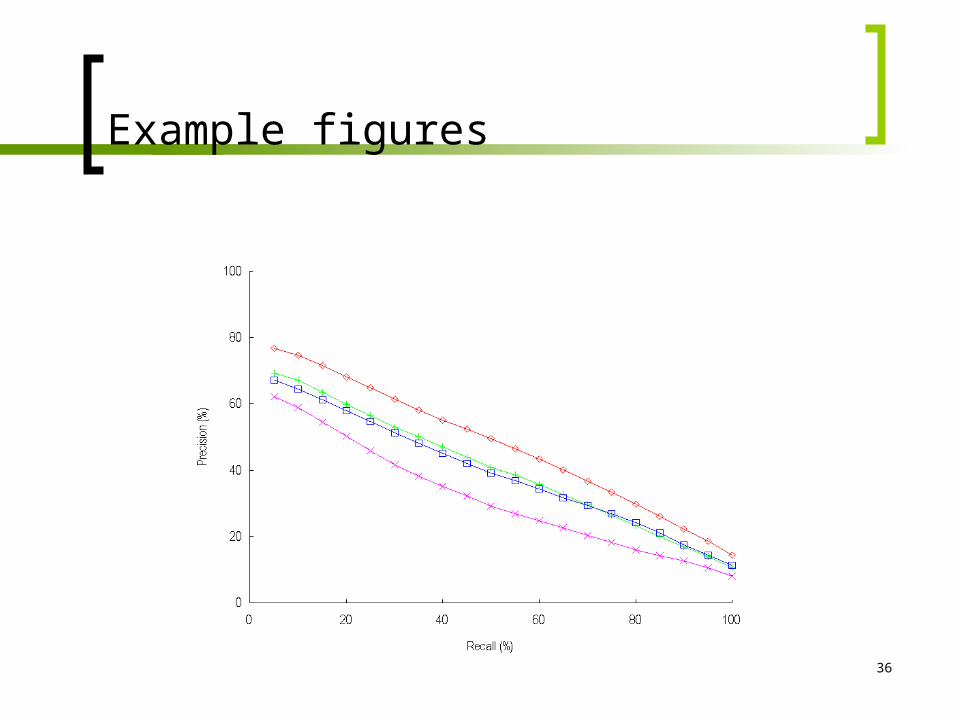
Example figures

37
Harmonic Mean( F-measure )
Harmonic mean defined as:
F high if recall and precision high Therefore maximum F interpreted as
best compromise between recall and precision
jPjr
jF11
2

38
E-measure
User specifies if more interest in recall or precision
E-measure defined as:
b is user specified and reflects relative importance of recall and precision
jPjrb
bjE
1
11 2
2

39
Conclusion
Introduced two most popular models for information retreival: Vector space model Probabilistic model
Introduced evaluation methods to quantify performance of Information Retrieval Systems ( Recall and Precision, … )

40
References Baeza-Yates:
„Modern Information Retrieval“ (1999) G.Salton:
„The Smart Retrieval System – Experiments in Automatic Document Processing“ (1971)
S.E.Roberston, K.Spark Jones:
Relevance weighting of search terms –
Journal of American Society for Information Sciences (1976) N.Fuhr:
„Probabilistic model in information retrieval“ (1992) TREC NIST website: http://trec.nist.gov J.J.Rocchio:
Relevance feedback in information retrieval (1971)


















