

Introduction to Hadoop Ecosystem
63
© Introduction to
-
Upload
getindata -
Category
Technology
-
view
64 -
download
1
Transcript of Introduction to Hadoop Ecosystem

©
Introduction to

©
■■
●
●

©
■ StreamRockTM
●
©
■ StreamRockTM

©
■●
●
●

©

©

©
■■■

©
■■■■
●
■■
●

©
■■■■
●
■■
●

©
■

©
A Definition For Your Daddy

©
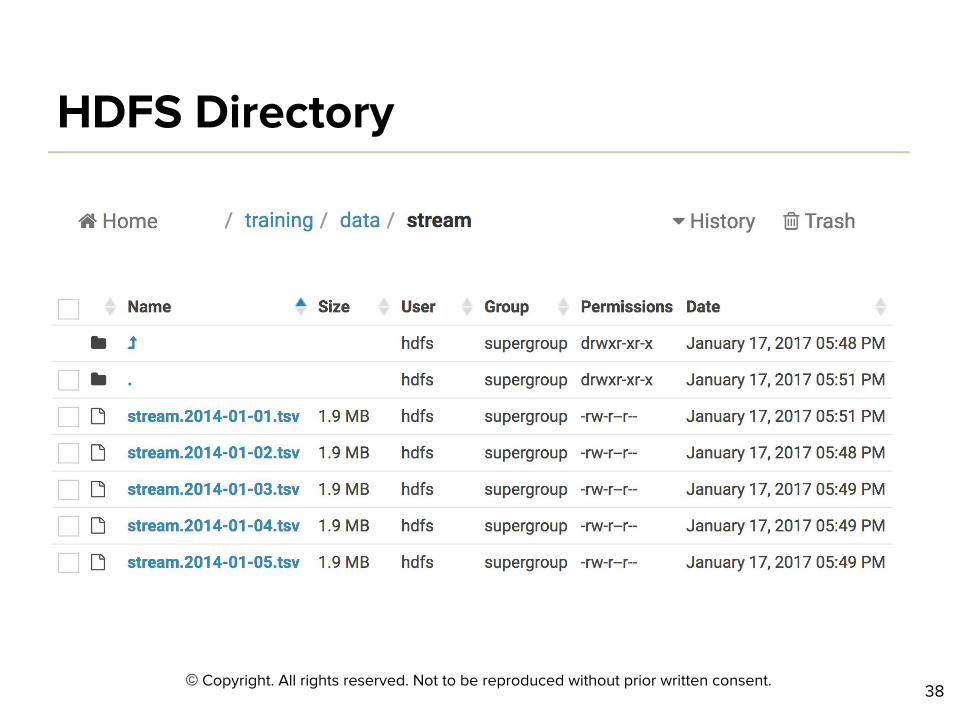
$ hdfs dfs -ls /user/tiger
$ hdfs dfs -put songs.txt /user/tiger
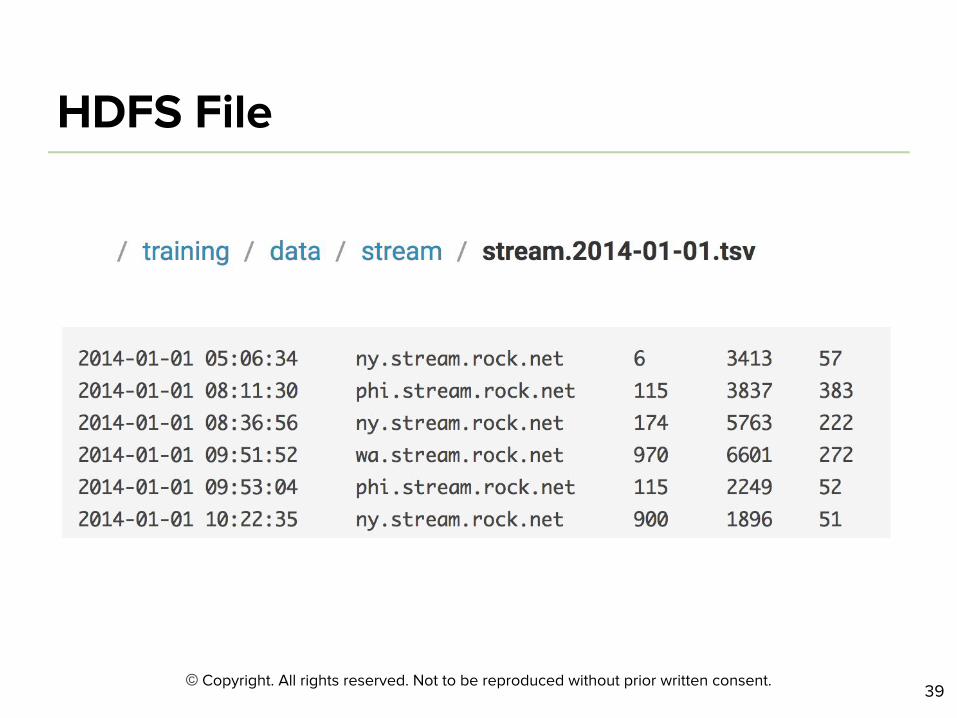
$ hdfs dfs -cat /user/tiger/songs.txt
$ hdfs dfs -mkdir songs
$ hdfs dfs -mv songs.txt songs
$ hdfs dfs -rmr songs

©
■
$ hdfs dfs -put songs.txt /user/tiger
Question?
©
■■
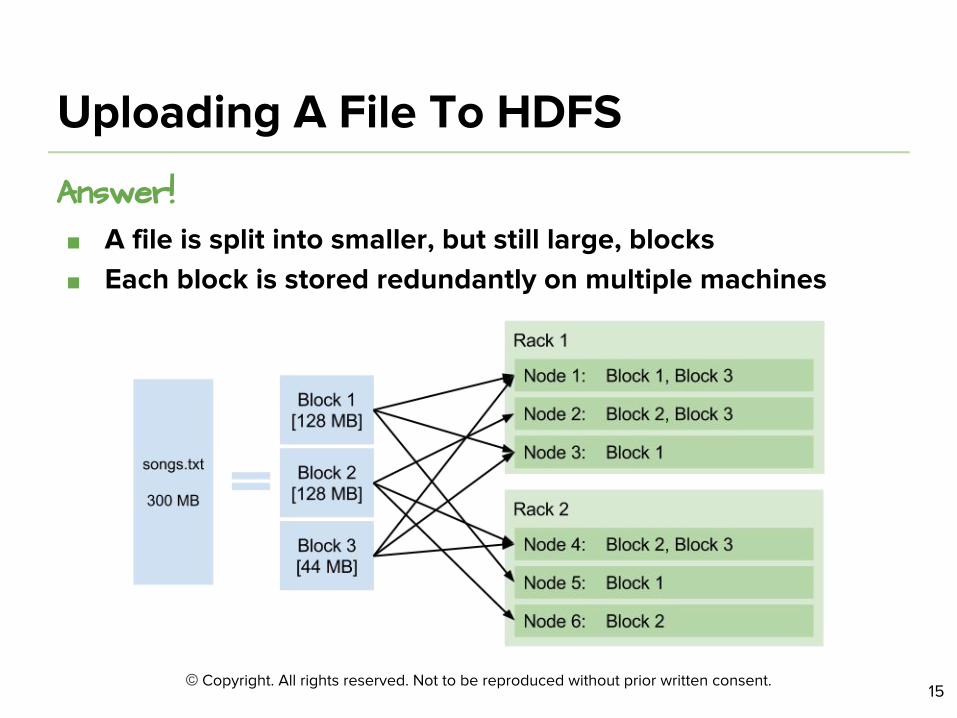
Answer!

©
■●
●
■
Image source: http://pixgood.com/slicing-bread.html

©
■
$ hdfs dfs -cat /user/tiger/songs.txt
Question?

©
■●
●
●
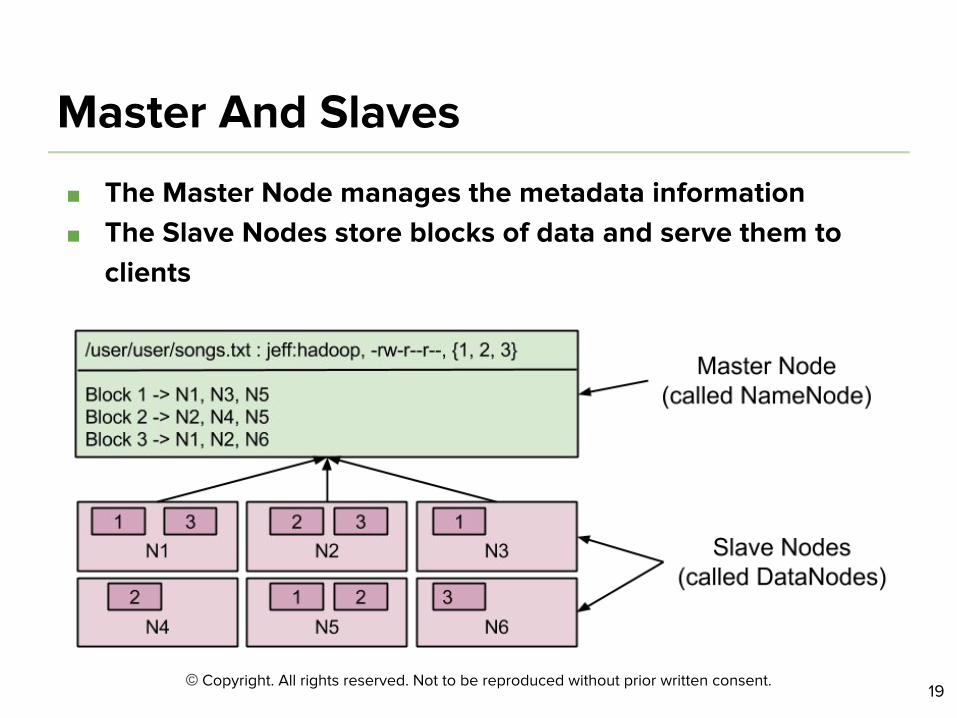
Answer!
©
■■

©
■●
■●
●■
■●

©
■●
■●
■●

©
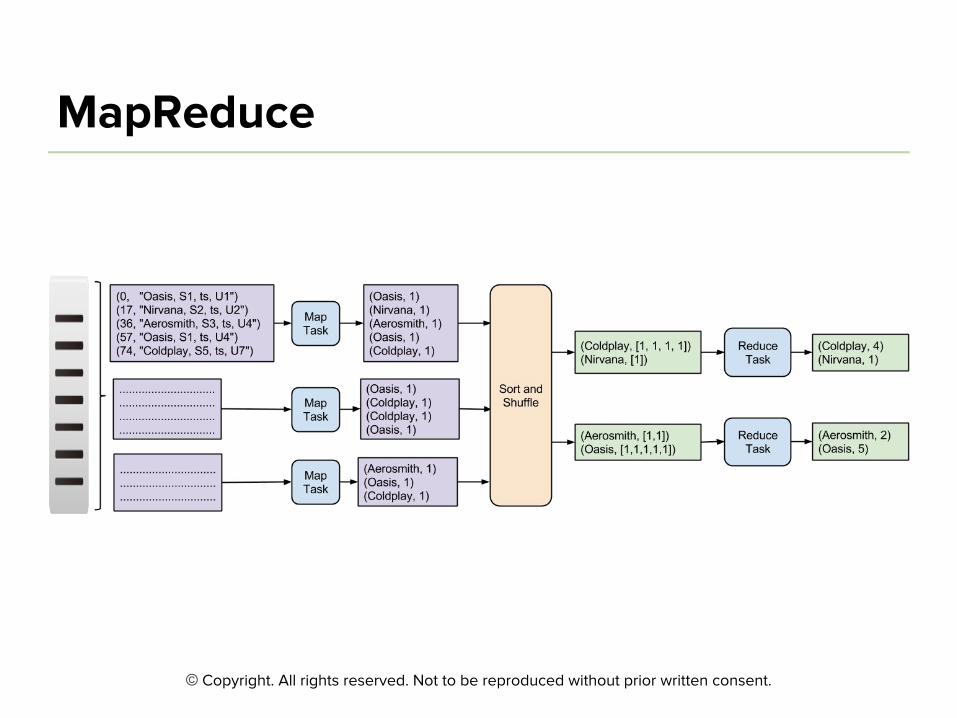
©

©
■■■■
©
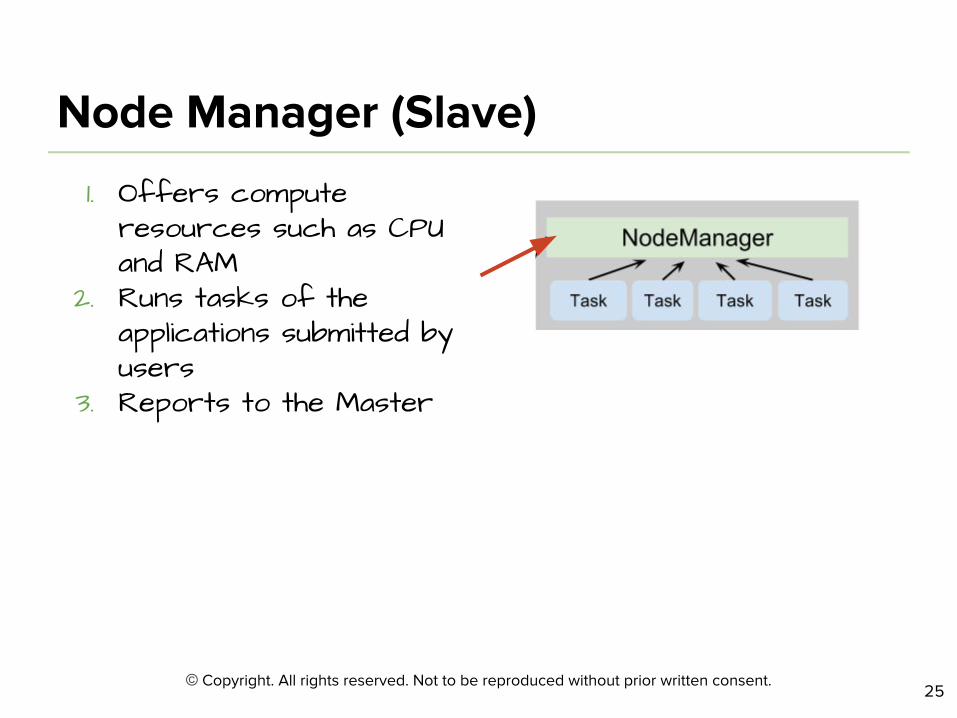
1. Offers compute resources such as CPU and RAM
2. Runs tasks of the applications submitted by users
3. Reports to the Master
©
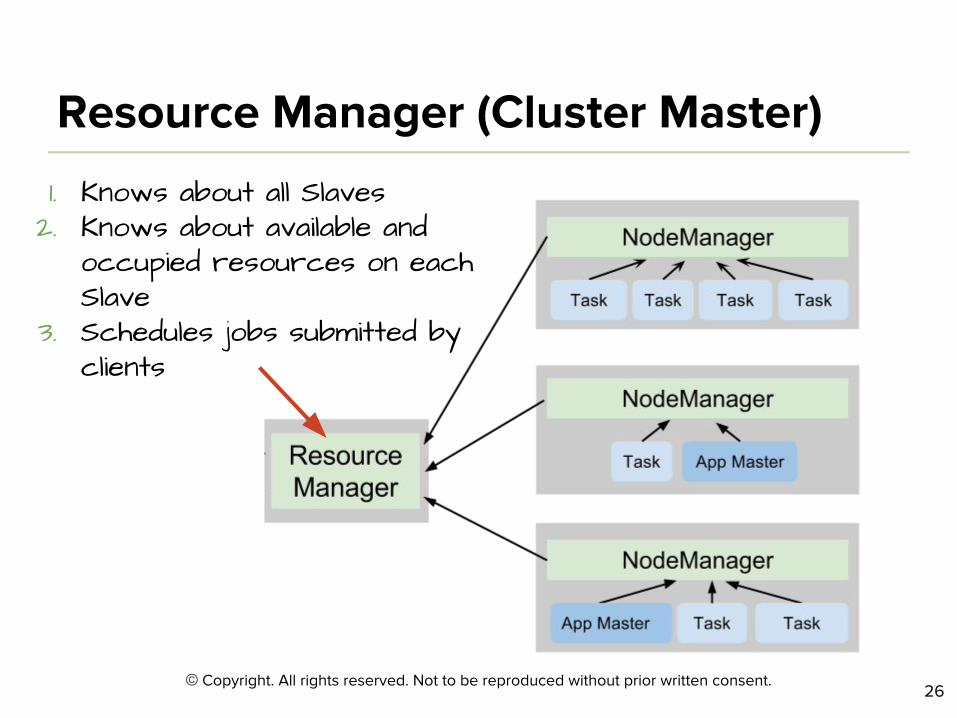
1. Knows about all Slaves2. Knows about available and
occupied resources on each Slave
3. Schedules jobs submitted by clients
©
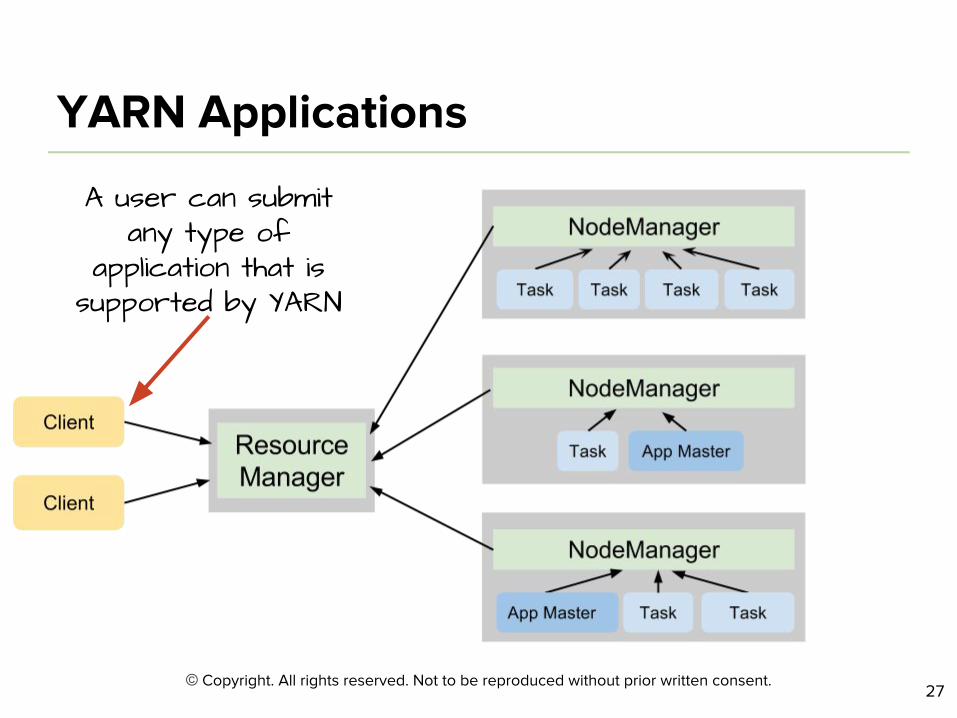
A user can submit any type of
application that is supported by YARN
©
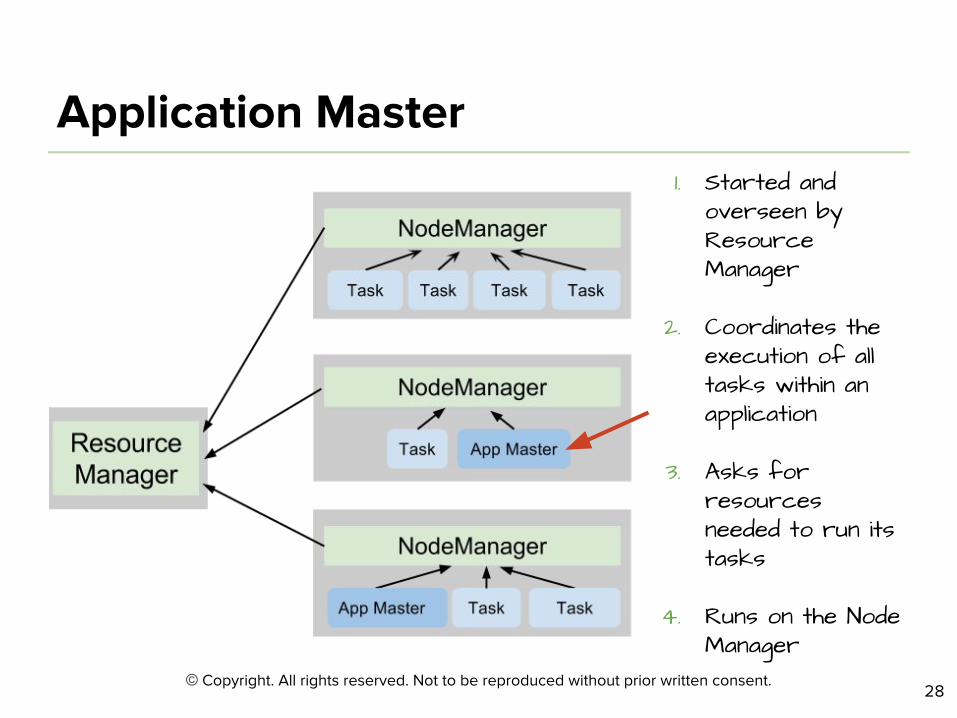
1. Started and overseen by Resource Manager
2. Coordinates the execution of all tasks within an application
3. Asks for resources needed to run its tasks
4. Runs on the Node Manager
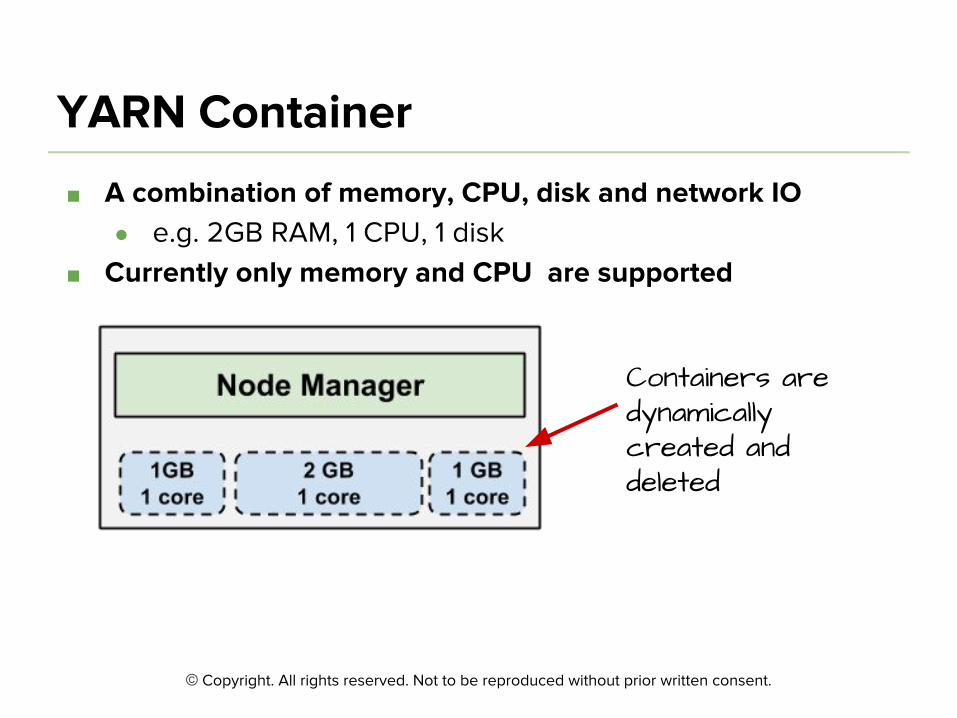
©
■●
■
Containers are dynamically created and deleted

©
■
■●
■

©
■
■
■
■
■
■
●
●

©
■
Large volume of data
Computation e.g. a JAR file
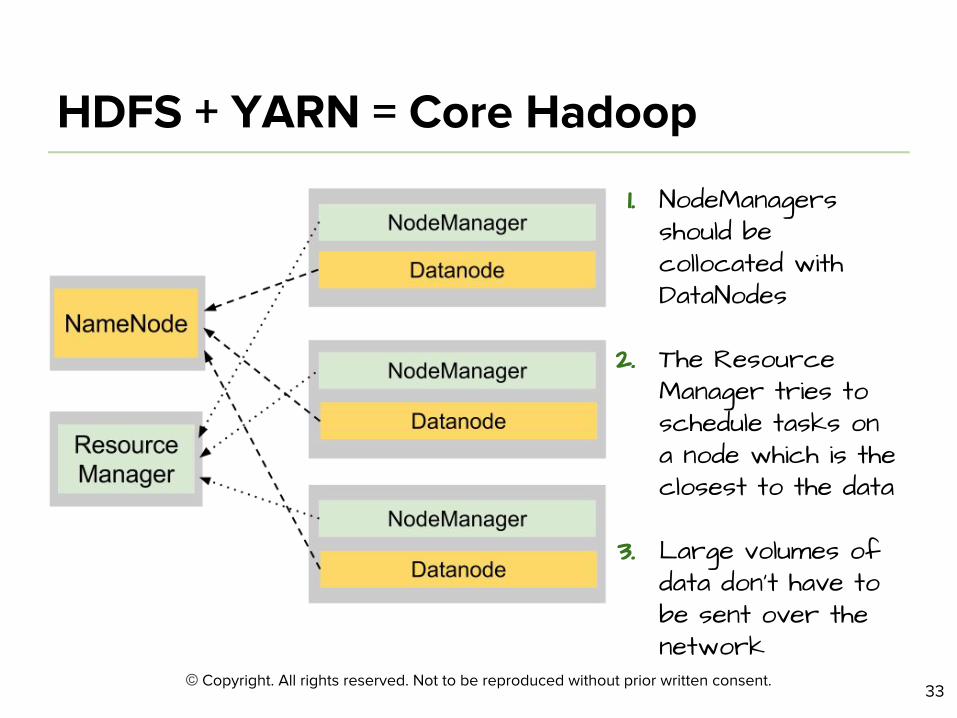
©
1. NodeManagers should be collocated with DataNodes
2. The Resource Manager tries to schedule tasks on a node which is the closest to the data
3. Large volumes of data don’t have to be sent over the network

©
■

©
Their reality■■
●
■
Their conclusion■
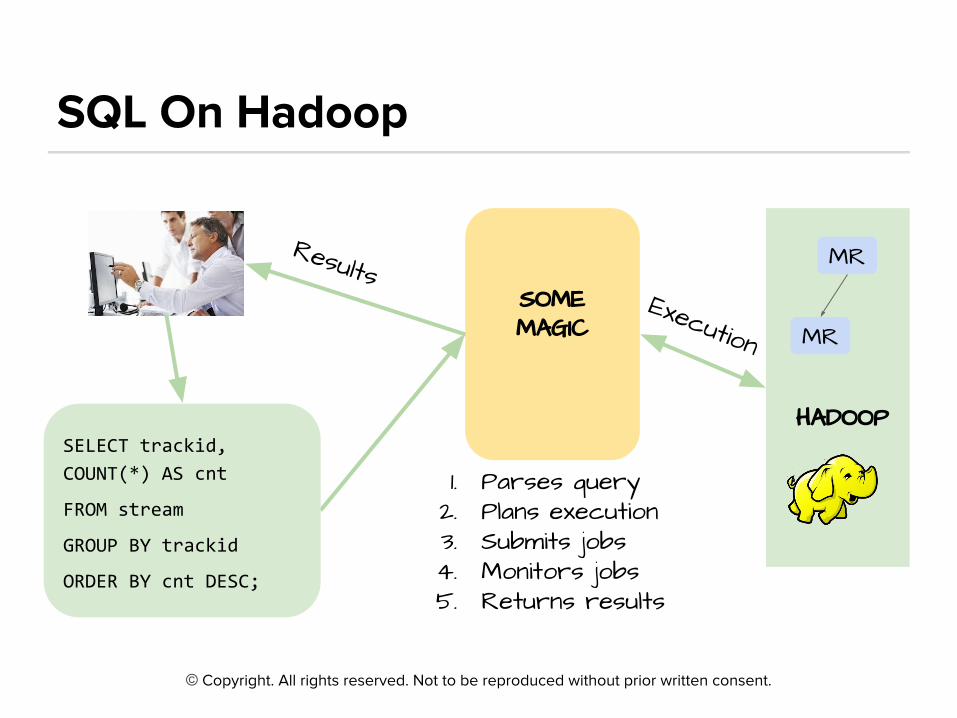
©
HADOOP
MR
MRSOME MAGIC
1. Parses query2. Plans execution3. Submits jobs4. Monitors jobs5. Returns results
Execution
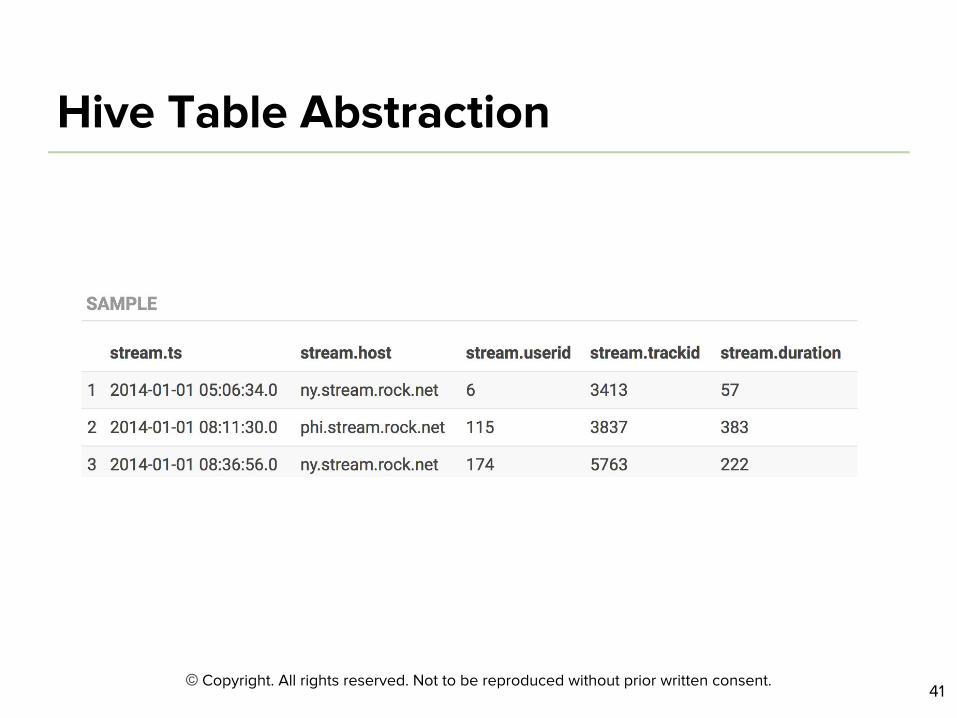
SELECT trackid,
COUNT(*) AS cnt
FROM stream
GROUP BY trackid
ORDER BY cnt DESC;
Results
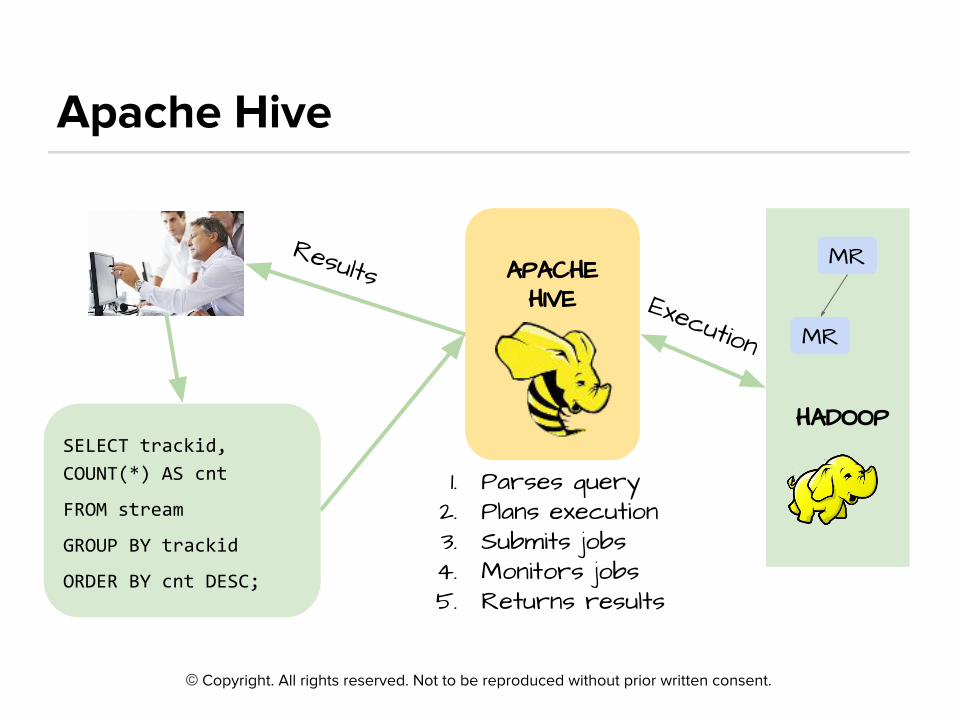
©
HADOOP
MR
MR
APACHE HIVE
Results
1. Parses query2. Plans execution3. Submits jobs4. Monitors jobs5. Returns results
Execution
SELECT trackid,
COUNT(*) AS cnt
FROM stream
GROUP BY trackid
ORDER BY cnt DESC;
©
©

©
©

©
■●
●
●
●
©
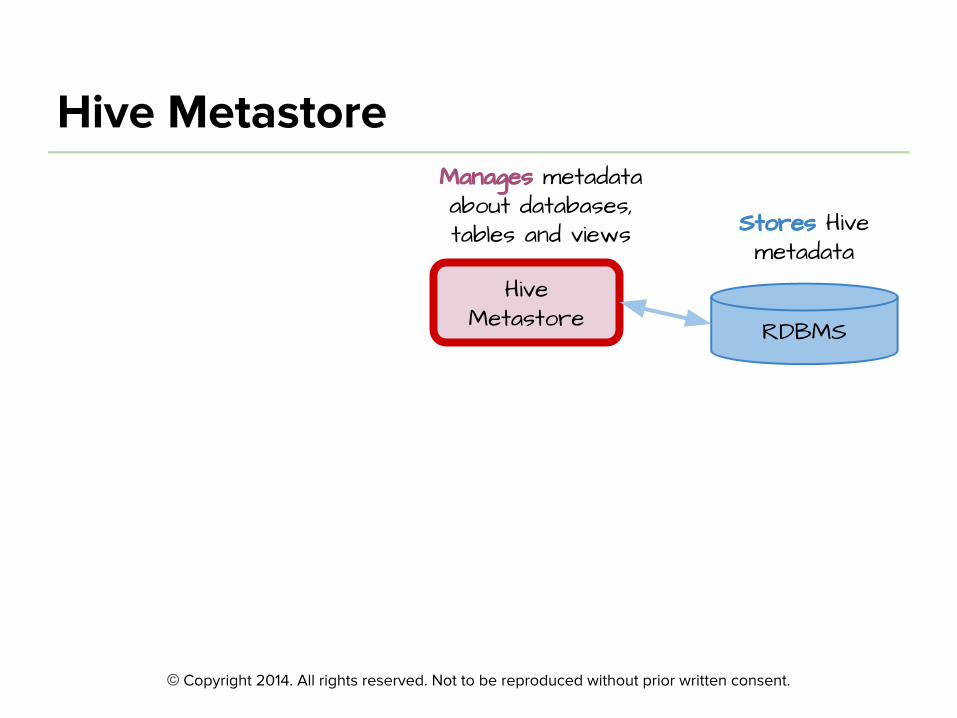
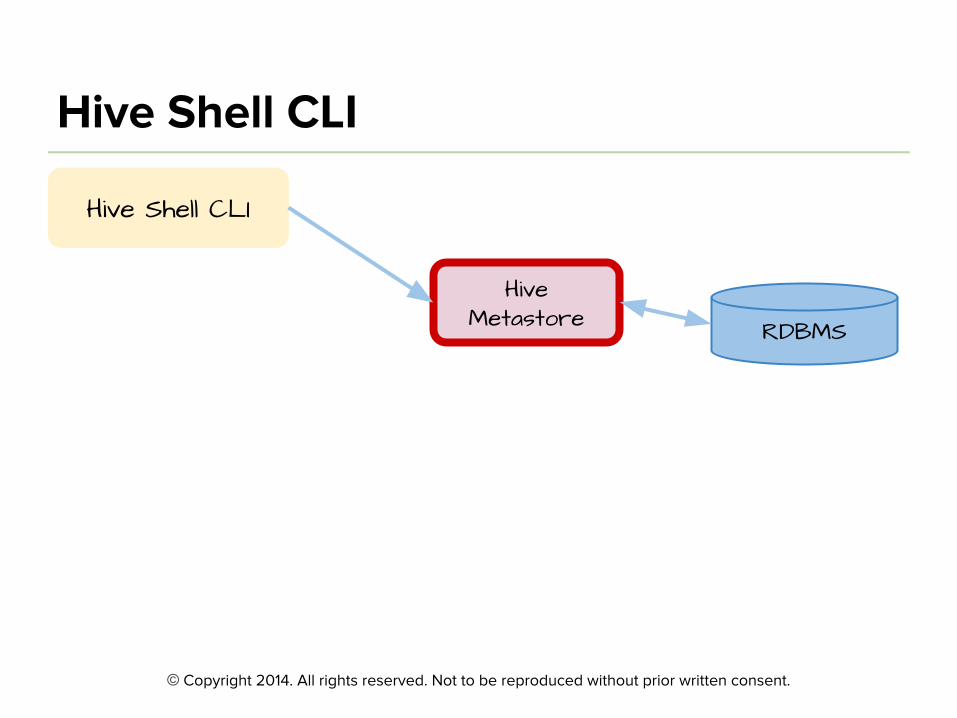
RDBMS
Hive Metastore
Stores Hive metadata
Manages metadata about databases, tables and views
©
Hive Shell CLI
RDBMS
Hive Metastore
©
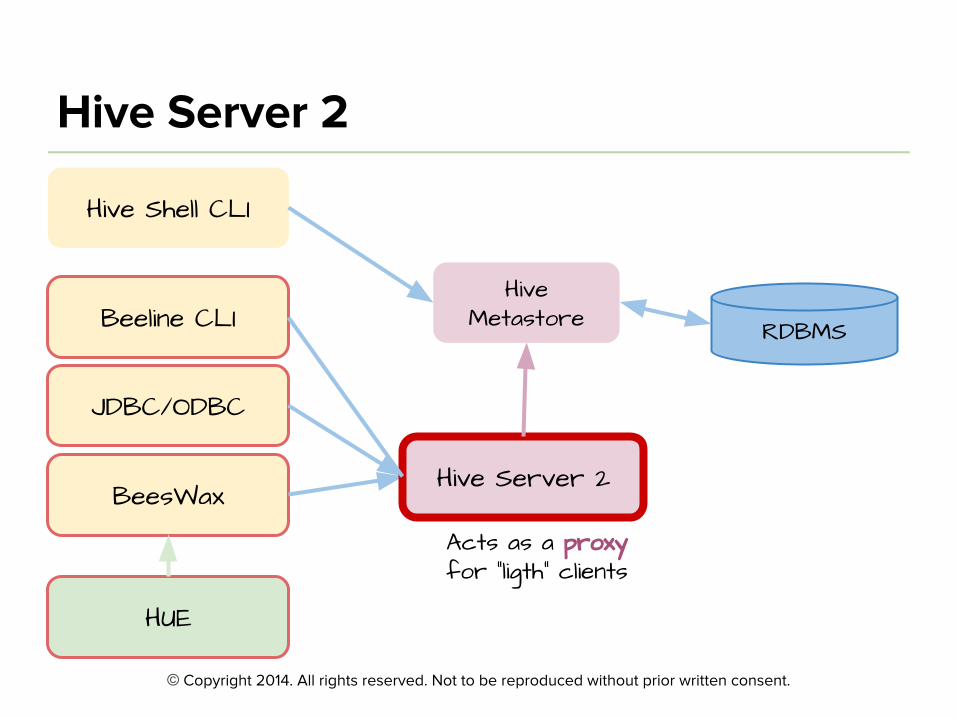
Hive Shell CLI
BeesWax
HUE
RDBMS
Hive Metastore
Acts as a proxy for “ligth” clients
JDBC/ODBC
Hive Server 2
Beeline CLI
©

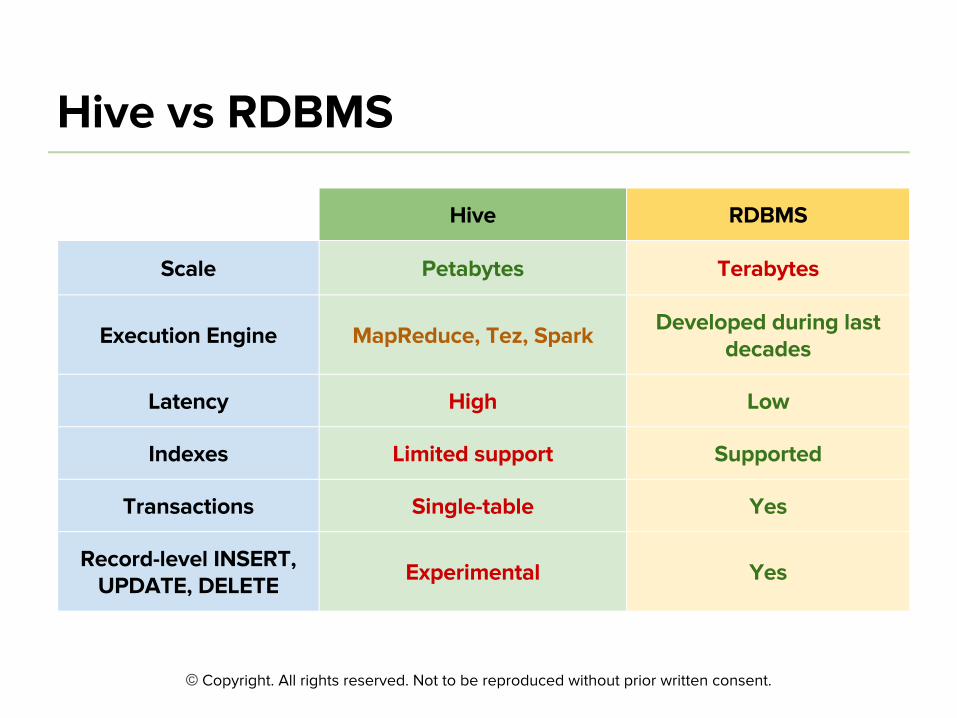
©
■
■
©
©
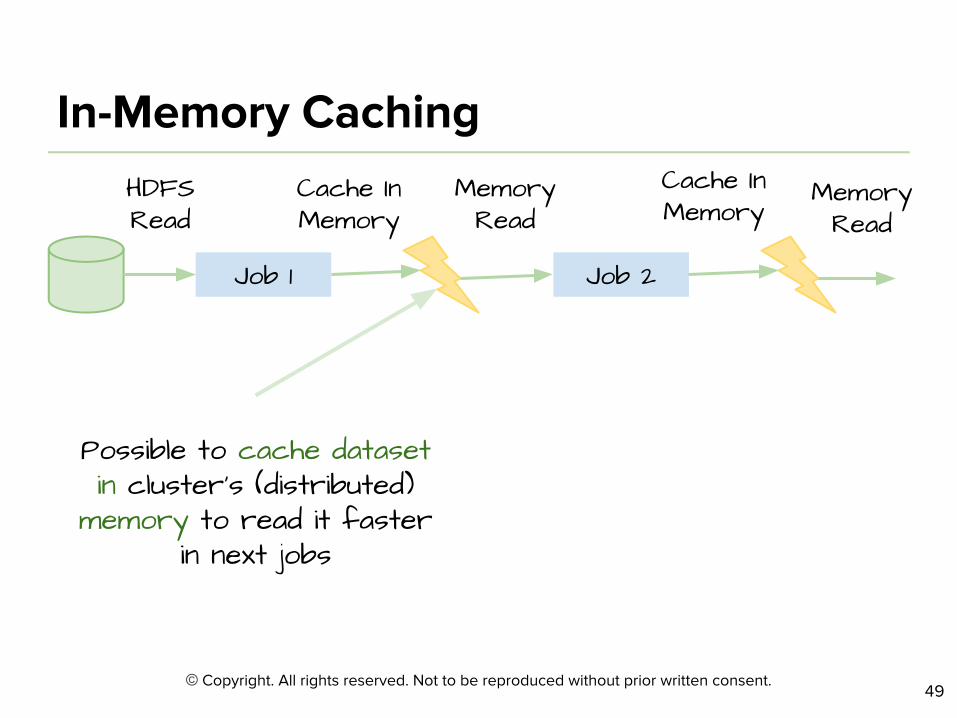
Job 1 Job 2
Possible to cache dataset in cluster’s (distributed)
memory to read it faster in next jobs
HDFS Read
Memory Read
Cache In Memory
Cache In Memory
Memory Read
©
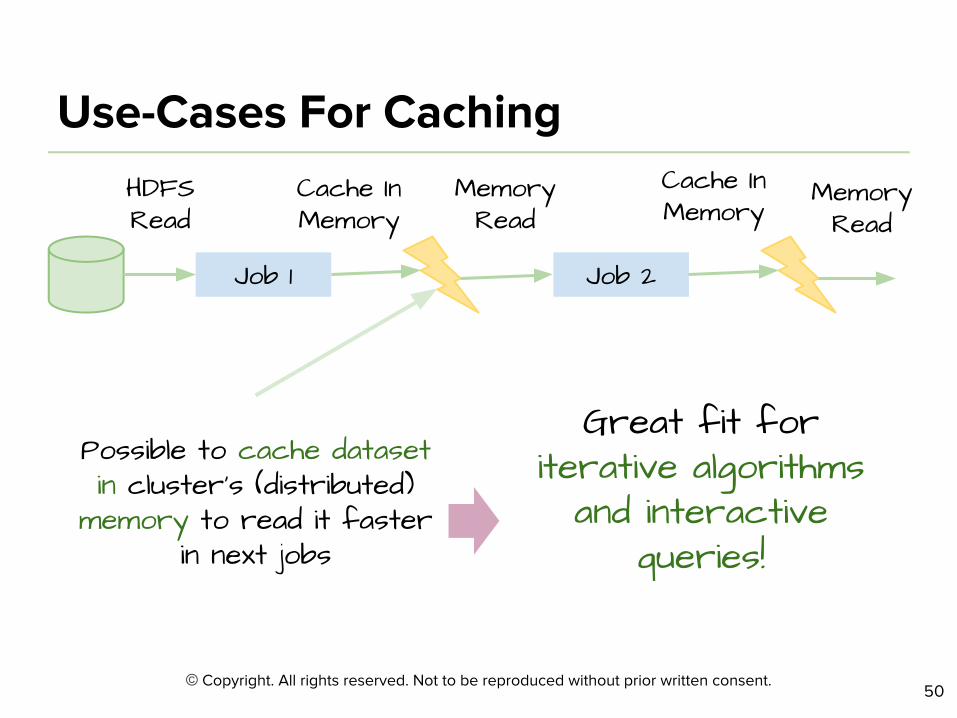
Job 1 Job 2
Great fit for iterative algorithms
and interactive queries!
HDFS Read
Memory Read
Cache In Memory
Cache In Memory
Possible to cache dataset in cluster’s (distributed)
memory to read it faster in next jobs
Memory Read
©
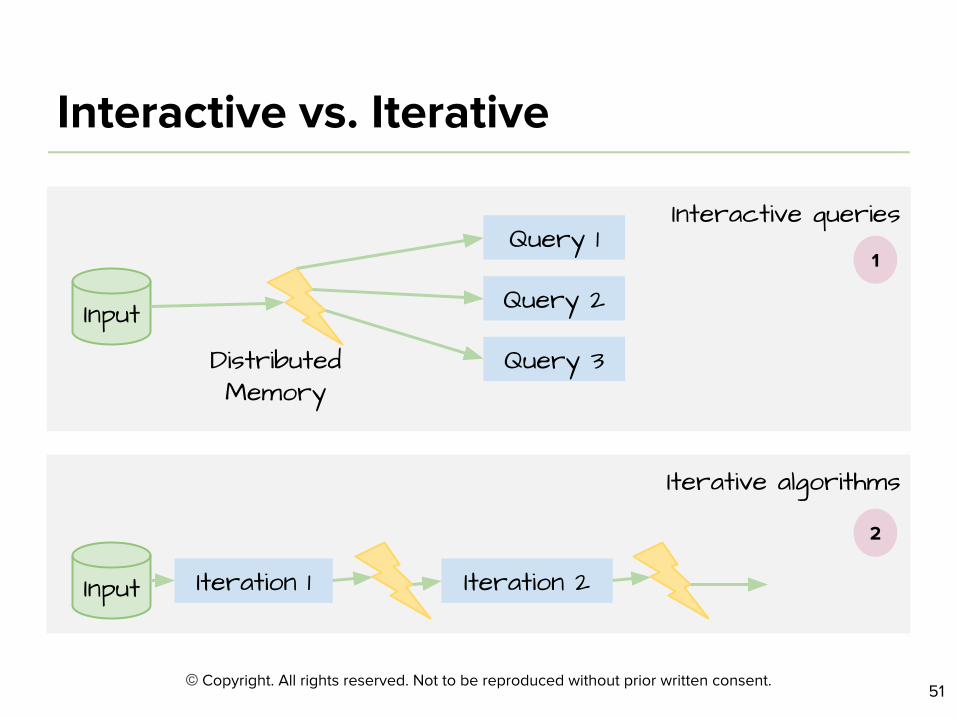
Interactive queries
Iterative algorithms
Input Query 2
Query 1
Query 3
Input Iteration 1 Iteration 2
Distributed Memory
©
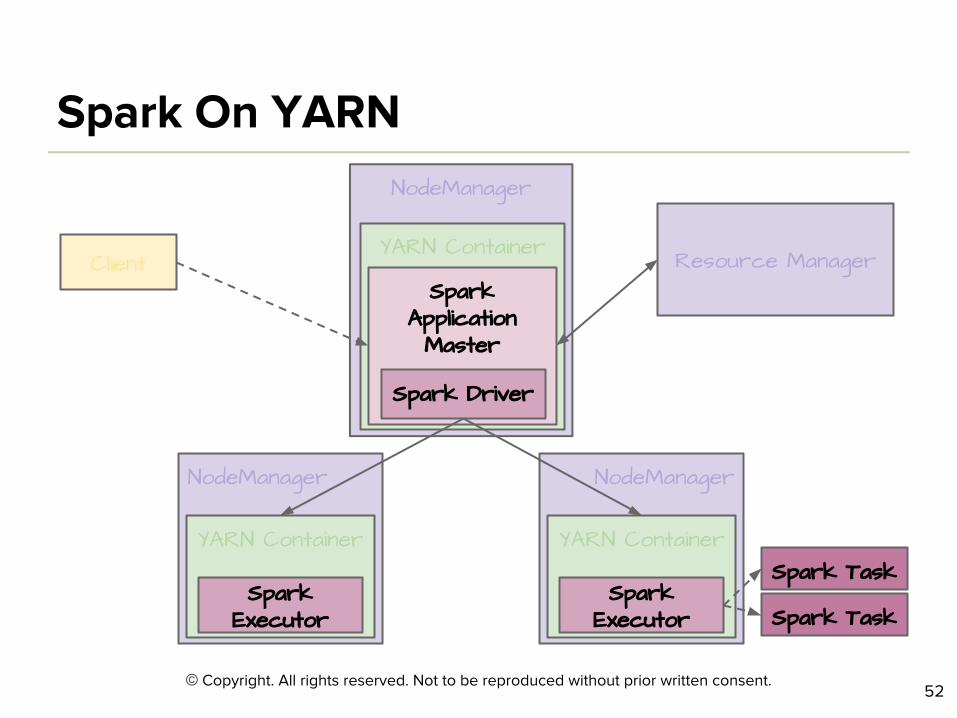
NodeManager
ClientYARN Container
Spark Application Master
Spark Driver
Resource Manager
NodeManager
YARN Container
Spark Executor Spark Task
NodeManager
YARN Container
Spark Executor
Spark Task

©
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 20g \
--executor-cores 3 \
lib/spark-examples*.jar \
10
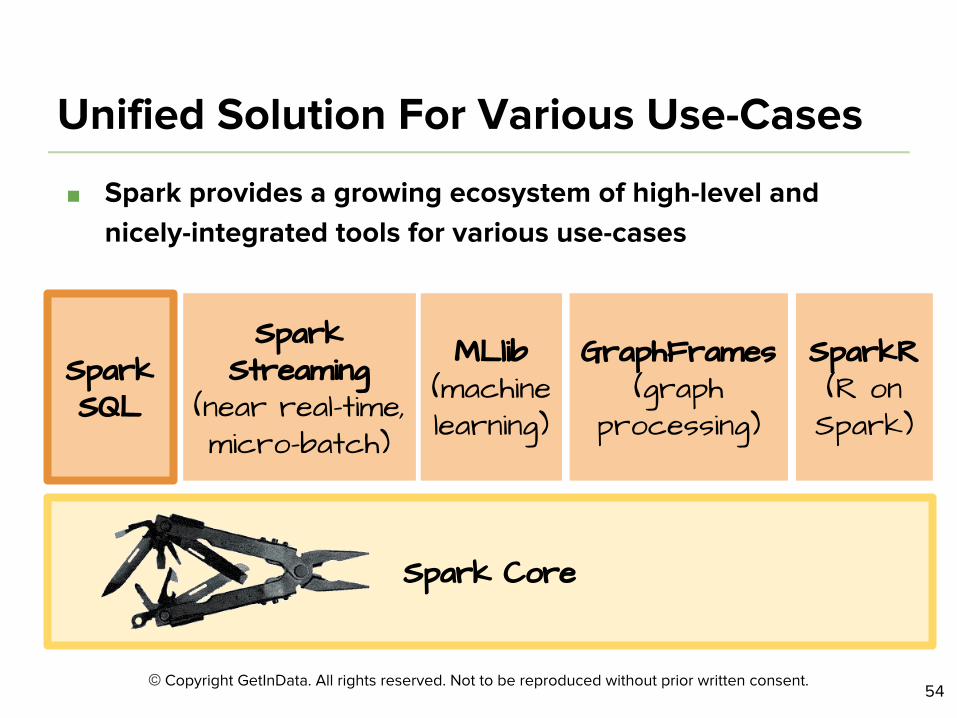
©
■
Spark Core
Spark SQL
Spark Streaming
(near real-time, micro-batch)
MLlib (machine learning)
GraphFrames (graph
processing)
SparkR (R on Spark)
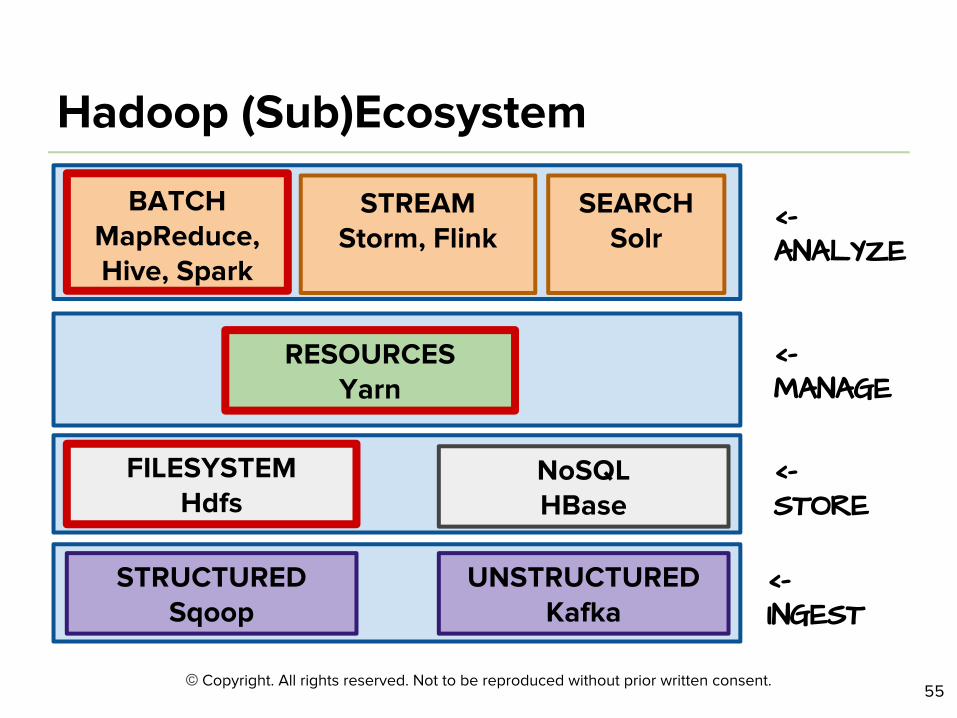
©
<- INGEST
<- STORE
<- MANAGE
<- ANALYZE

©
■ StreamRockTM
●
■●
●
●
●
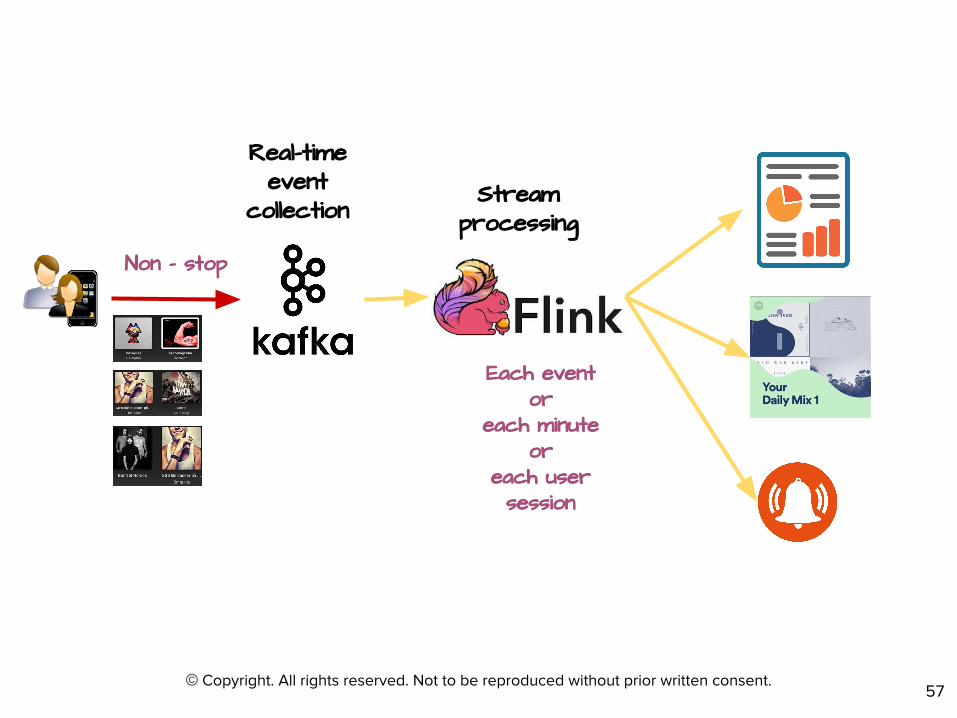
©
Non - stop
Each event or
each minute or
each user session
Real-time event
collectionStream
processing

©
■●
■●
●

©
StreamRockTM
■●
■●

©

©

©


















