Introduction to Hadoop and HDFS. Table of Contents Hadoop – Overview Hadoop Cluster HDFS.
23
Introduction to Hadoop and HDFS
-
Upload
erin-logan -
Category
Documents
-
view
282 -
download
9
Transcript of Introduction to Hadoop and HDFS. Table of Contents Hadoop – Overview Hadoop Cluster HDFS.

Introduction to Hadoop and
HDFS

Table of Contents
Hadoop – Overview
Hadoop Cluster
HDFS

Hadoop Overview

What is Hadoop ?
• Hadoop is an open source framework for writing and running distributed applications that process large amounts of data.
• Hadoop’s accessibility and simplicity give it an edge over writing and running large distributed programs
• On the other hand, its robustness and scalability make it suitable for even the most demanding jobs at Yahoo and Facebook.
• Hadoop cluster is a set of commodity machines networked together in one location.

Key distinctions of Hadoop
• Accessible - Hadoop runs on large clusters of commodity machines or on cloud computing services such as Amazon’s Elastic Compute Cloud (EC2 ).
• Robust - Because it is intended to run on commodity hardware, Hadoop is architected with the assumption of frequent hardware malfunctions. It can gracefully handle most such failures.
• Scalable - Hadoop scales linearly to handle larger data by adding more nodes to the cluster.
• Simple - Hadoop allows users to quickly write efficient parallel code.

Comparing SQL databases and Hadoop
• SCALE-OUT INSTEAD OF SCALE-UP
• KEY/VALUE PAIRS INSTEAD OF RELATIONAL TABLES
• FUNCTIONAL PROGRAMMING (MAPREDUCE) INSTEAD OF DECLARATIVE QUERIES (SQL)
• OFFLINE BATCH PROCESSING INSTEAD OF ONLINE TRANSACTIONS

Hadoop Ecosystem
• HDFS
A distributed file system that runs on large clusters of commodity machines.
• MapReduceA distributed data processing model and execution environment that runs on
large clusters of commodity machines.
• PigA data flow language and execution environment for exploring very large
datasets. Pig runs on HDFS and MapReduce clusters.

Hadoop Ecosystem
• Hive
A distributed data warehouse. Hive manages data stored in HDFS and provides a query language based on SQL (and which is translated by the runtime engine to MapReduce jobs) for querying the data.
• HBase
A distributed, column-oriented database. HBase uses HDFS for its underlying storage, and supports both batch-style computations using MapReduce and point queries (random reads).

Hadoop Cluster

Detail Hadoop Architecture
Client
NN JT
TT TT TT
TA
SK
TA
SK
TA
SK
DN DN DN
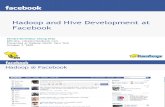
Hadoop Framework
MAP/Reduced Job
HDFS Framework / File system
structured
unstructured
semi-structured
structured
unstructured
Semi-structured

Typical Workflow
• Load data into the cluster (HDFS writes)
• Analyze data (MAP/ Reduce job)
• Store results in the cluster (HDFS write)
• Read results from the cluster (HDFS reads)

Example

Hadoop Distributed File System
(HDFS)

Hadoop Distributed File System
• Shared multi-petabyte file system for entire cluster. Managed by a single NameNode
File are written, read, renamed, deleted, but append only
optimized for streaming reads of large files.
• Files are broken into uniform sized blocks. Blocks are typically 128 MB (64 MB default)
Replicated to several DataNodes, for reliability.
• Data is distributed to many nodes Bandwidth scales linearly with the number of disks
Avoids single path to all data
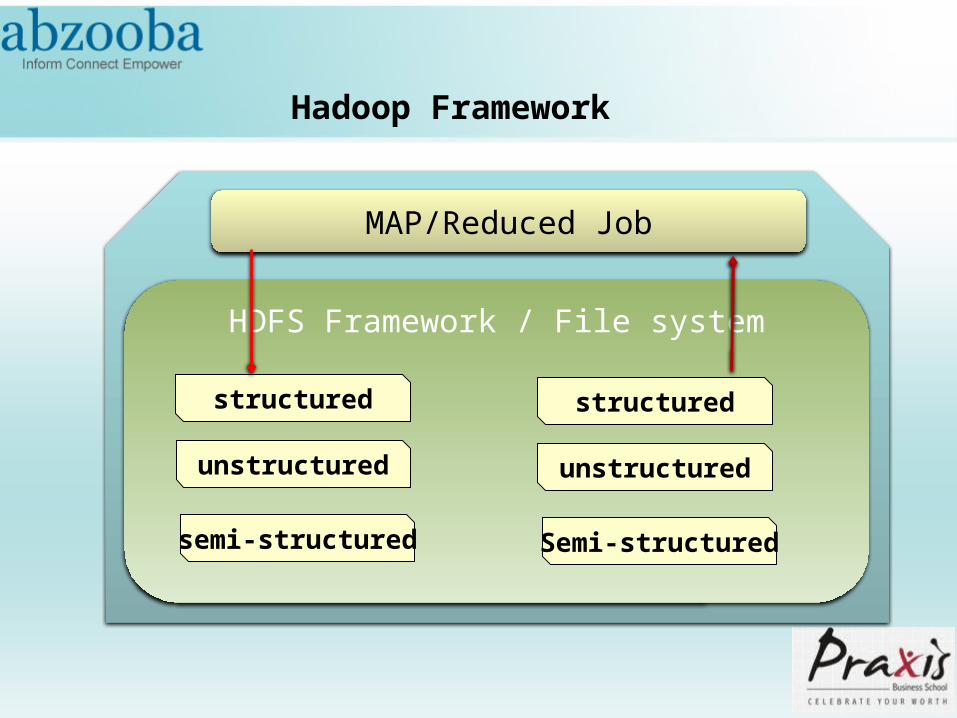
Job Assignment
• Move map task to where the data is.
• Job Tracker assigns job based on the location of the data.
• The computation of job task are done mostly on servers containing the data.
• Handles recovery of task failures.
TT
TA
SK
DN
TT
TA
SK
DN
Job Tracker
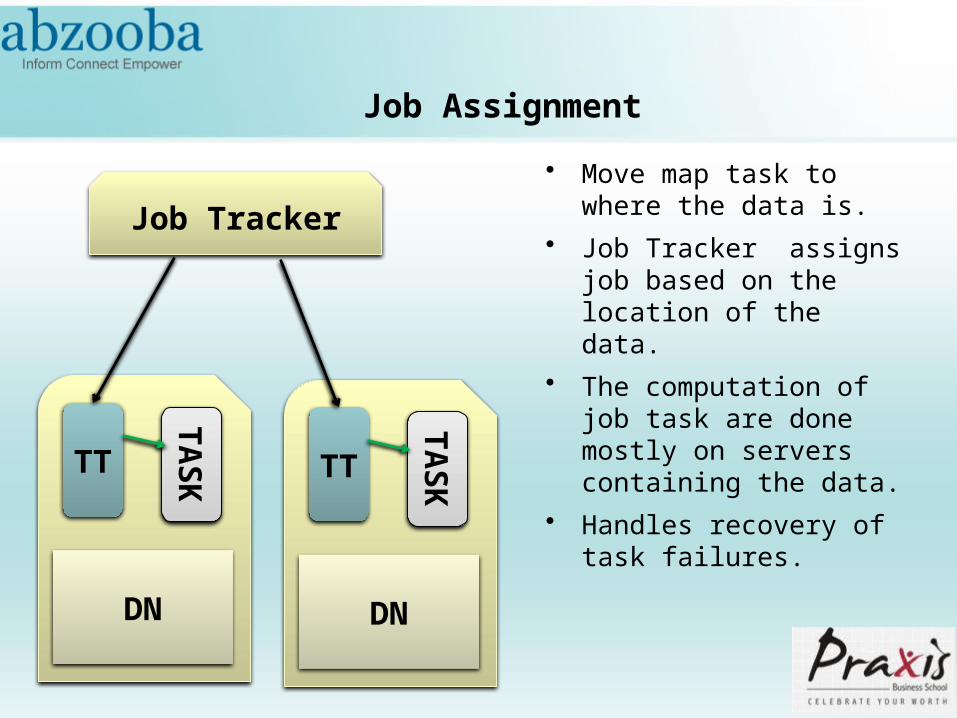
HDFS Demons on Nodes
Name Node
Date Node
Date Node
Date Node
Date Node
Hadoop Data File System
(HDFS) supports storage
of massive amount of data
on commodity hardware.

Inside a DataNode
• Each Data Node can have thousands of Blocks of data
• Blocks by default are 64 MB each
-- Often set at 128 MB
DATA NODE
Blocks

Writing data to HDFS
• Blocks of data are replicated.
• Allows computation to be brought close to data.
• Replication increases the chances data locality.
Tasks are assigned to local node (when possible and then local rack.
Replication also supports reliability (node failure).
• A Job is decomposed into Tasks that scan the data.
Block A
Node
Block B Block C
Block A
Block C
Node
Block B
Block A
Node
Block A
Block C
Node
Block B
Block C
Block B

Inside a Task Tracker Node
• The administrator will assign slots for running maps and reduces.
A given node may have 4 map slots and 8 reduce slots The particular number is site dependent.
Varies with work load and machine configuration.
• Slots are designed as is being either map or reduce slots
• Each node may be individually configured.
• A slot will run a JVM to run a mapper or reducer.

Map Reduce Architecture
HDFS
Map Reduce
Node (Map) Node (Reduce)
InputMapCode
Partitioner
Sort
Reduce code
Output

Map Reduce Overview
• MapReduce works on <Key, Value> pairs

Thank You