
UniProt Domain Architecture Alignment: A New Approach for ...
Upload
phoebe-bridgesCategory
view
221download
0
Introduction to databases
Tuomas Hätinen

Topics
File Formats
Databases
- Primary structure: UniProt
- Tertiary structure: PDB
Database integration system
- Sequence retrieval system (eg SRS, Hands on session)

File formats
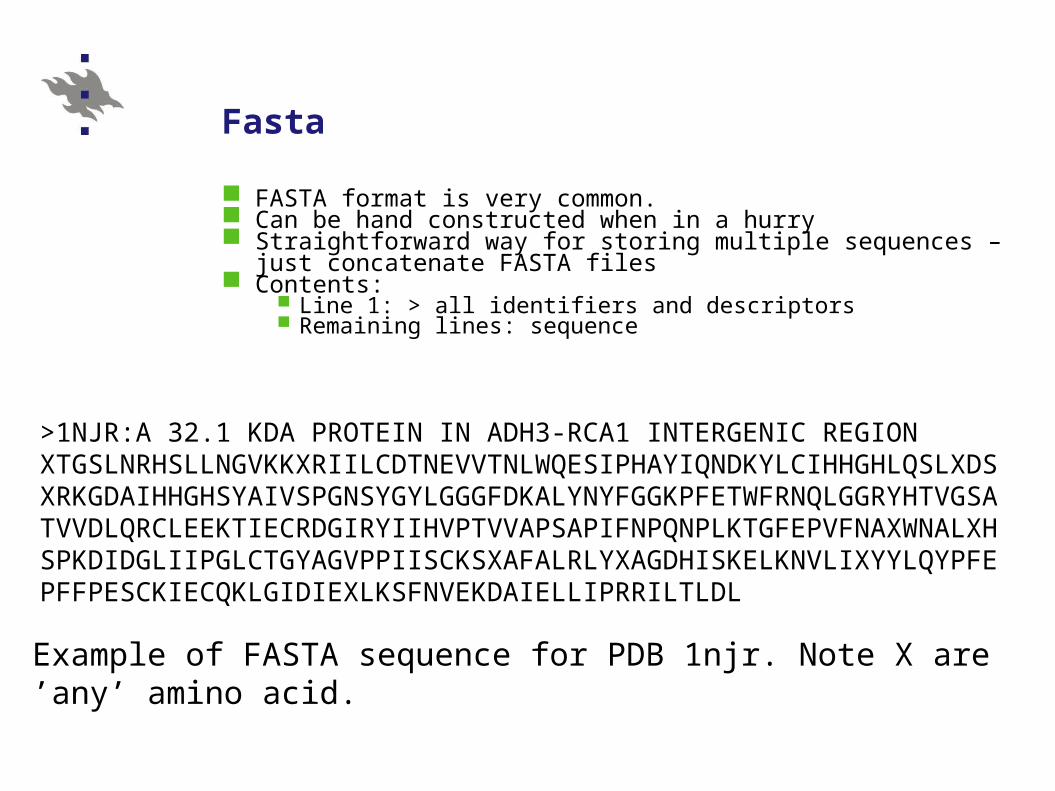
Fasta
FASTA format is very common. Can be hand constructed when in a hurry Straightforward way for storing multiple sequences – just concatenate
FASTA files Contents:
Line 1: > all identifiers and descriptors Remaining lines: sequence
>1NJR:A 32.1 KDA PROTEIN IN ADH3-RCA1 INTERGENIC REGIONXTGSLNRHSLLNGVKKXRIILCDTNEVVTNLWQESIPHAYIQNDKYLCIHHGHLQSLXDSXRKGDAIHHGHSYAIVSPGNSYGYLGGGFDKALYNYFGGKPFETWFRNQLGGRYHTVGSATVVDLQRCLEEKTIECRDGIRYIIHVPTVVAPSAPIFNPQNPLKTGFEPVFNAXWNALXHSPKDIDGLIIPGLCTGYAGVPPIISCKSXAFALRLYXAGDHISKELKNVLIXYYLQYPFEPFFPESCKIECQKLGIDIEXLKSFNVEKDAIELLIPRRILTLDL
Example of FASTA sequence for PDB 1njr. Note X are ’any’ amino acid.

SwissPROT, EMBL, TrEMBL, UniProt format
Each line begins with a 2
letter identifier
UniProt format closely
resembles EMBL format
except that considerably
more information about
physical and biochemical
properties is provided

SwissPROT format
Example of SwissProt entry. Line types are fully explained in:
http://au.expasy.org/sprot/userman.html#linetypes

SwissPROT format
Example of SwissProt entry. Line types are fully explained in:
http://au.expasy.org/sprot/userman.html#linetypes

Databases

Key concepts
Experimental database Contains experimental meassurements
E.g. EMBL, PDB
Derived database Derived from experimental databases
E.g. UniProtKB
Database stability Accession numbers
Non-redundancy Annotation

Nucleic sequence databases – experimental data
GenBank
DDBJ
EMBL
EBI
NCBI
CIB
*Submissions *Updates
EMBLNIG
NIH
*Submissions *Updates
*Submissions *Updates
EUROPEUSA
JAPAN

Raw Protein sequence databases
EBI
NCBI
EMBL
NIHGen Bank
DDBJ
EMBL
DNA sequences DBs Proteins seq DBs
Trans
Gen Pept
TrEMBL
SwissPROT
PIR-PSD
UniPROT
Trans
Entrez
Sub/Up
Sub/Up
Sub/Up
Sub/Up
SRS

UniProt
Universal Protein Resource Protein Sequence database UniProt Consortium
European Bioinformatics Institute
Swiss Institute of Bioinformatics
PIR Georgetown University
Mission
- Maintain high quality, stable, comprehensive, fully
classified and annotated protein sequence
knowledgebase, with extensive cross-references and
querying interfaces

Organization of UniProt databases
UniProt Archive (UniParc)
All available protein
sequences
UniProt Knowledgebase
(UniProtKB)
Annotated proteins
sequences
UniProt Reference Clusters
(UniRef)
Reduced redundancy for
faster searching
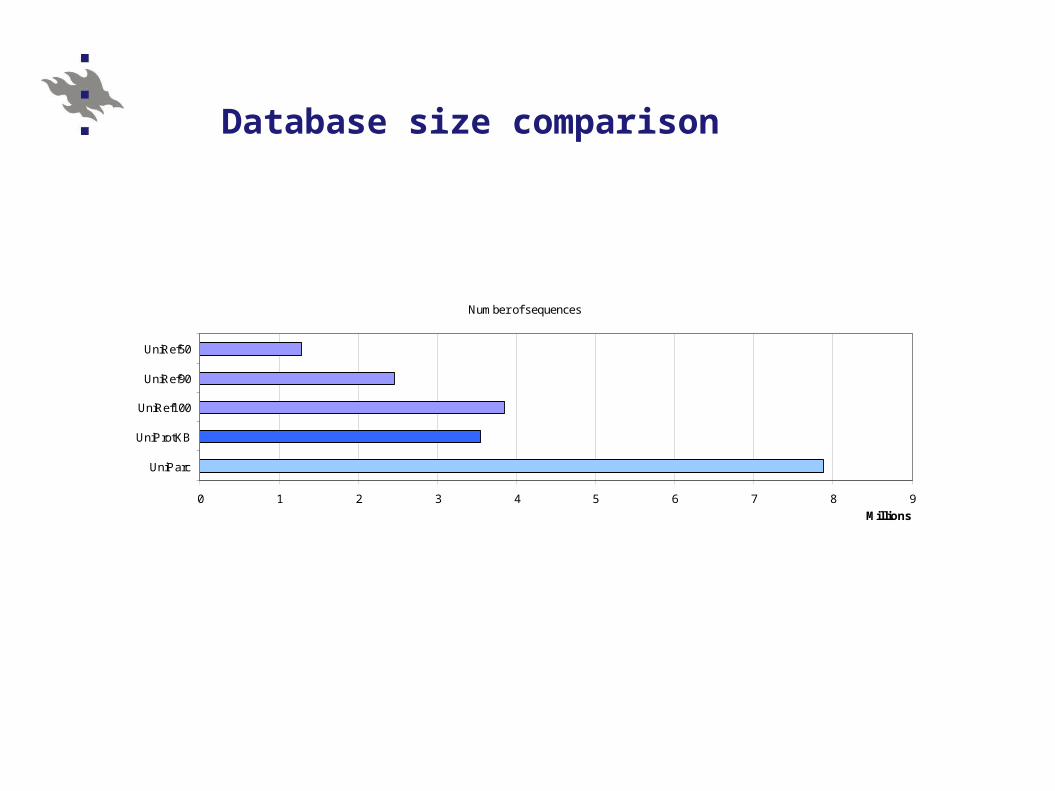
Database size comparison
Number of sequences
0 1 2 3 4 5 6 7 8 9
UniParc
UniProtKB
UniRef100
UniRef90
UniRef50
Millions

UniProtKB
Annontated entries UniParc =>UniProtKB UniProt/TrEMBL
Automated annotation
UniProt/SwissProt Manual annotation

SWISSPROT
Started as part of a Phd thesis, first version released in
1986. Now a collaboration between Swiss Institute of
Bioinformatics and EBI. Rich source for protein sequence data A well annotated source for sequences Largely non-redundant Updated daily, cross referenced with more than 30
different databases. Let us view a sample entry

TrEMBL
1996: TrEMBL (Translation of EMBL) released Computer-annotated entries derived from the translation
of all coding sequences in EMBL database except those
already in SWISS-PROT complement to Swiss-Prot and sequence
Sequences included to Swissprot by annotators

Errors in databases
Be aware of errors in the databases:
sequence errors:
- genome projects’ error rate is 1/10,000 nts;- ESTs’ error rate is 1/100nts.
annotation errors:
- Programs do not always give correct annotations.- SwissProt is a protein database curated and annotated manually
by biologists. - Manual curation doe

Errors in databases
Be aware of errors in the databases:
sequence errors:
- genome projects’ error rate is 1/10,000nts;- ESTs’ error rate is 1/100nts.
annotation errors:
- Automated computer programs do not always give correct annotations.
- SwissProt is a protein database curated and annotated manually by biologists.
- most reliable database, but is not up-to-date


















