
Introduction to BLAST - Math & Statistics Department |...
24
1 Introduction to BLAST Utah State University – Fall 2017 Statistical Bioinformatics (Biomedical Big Data) Notes 12
Transcript of Introduction to BLAST - Math & Statistics Department |...

1
Introduction to BLAST
Utah State University – Fall 2017
Statistical Bioinformatics (Biomedical Big Data)
Notes 12

2
References
Chapter 2 of Biological Sequence Analysis
(Durbin et al., 2001)
http://blast.ncbi.nlm.nih.gov/Blast.cgi

3
Basic Local Alignment Search Tool
Finds regions of similarity between a query
sequence and a growing database
Breaks query & database into fragments:
(words)
Starts out by aligning fragments, then
extends alignment
Not optimal alignment, but a good heuristic
approachsimplified, rule of thumb

4
Recall FASTA file from pairseqsim library
library(Biostrings)
f1 <- "C://folder//ex.fasta" # see slide 20 of Notes 11
ff <- readAAStringSet(f1, "fasta")
as.character(ff[1])
At1g01010 NAC domain protein, putative
MEDQVGFGFRPNDEELVGHYLRNKIEGNTSRDVEVAISEVNICSYDPWNLRFQSKYKSRDA
MWYFFSRRENNKGNRQSRTTVSGKWKLTGESVEVKDQWGFCSEGFRGKIGHKRVLVFLDGR
YPDKTKSDWVIHEFHYDLLPEHQRTYVICRLEYKGDDADILSAYAIDPTPAFVPNMTSSAG
SVVNQSRQRNSGSYNTYSEYDSANHGQQFNENSNIMQQQPLQGSFNPLLEYDFANHGGQWL
SDYIDLQQQVPYLAPYENESEMIWKHVIEENFEFLVDERTSMQQHYSDHRPKKPVSGVLPD
DSSDTETGSMIFEDTSSSTDSVGSSDEPGHTRIDDIPSLNIIEPLHNYKAQEQPKQQSKEK
VISSQKSECEWKMAEDSIKIPPSTNTVKQSWIVLENAQWNYLKNMIIGVLLFISVISWIIL
VG

5
We’ll start here, with
protein BLAST:
(blastp)
http://blast.ncbi.nlm.nih.gov/Blast.cgi

6
paste sequence
here
(or accession /
gi number)
nr database is
most general
click here to start
search
for querying
specific
subsequences
set parameters (next slide)

7
select scoring
scheme here
# “significant”
matches
expected just
by chance in
database
fragment sizes to
begin alignments
8
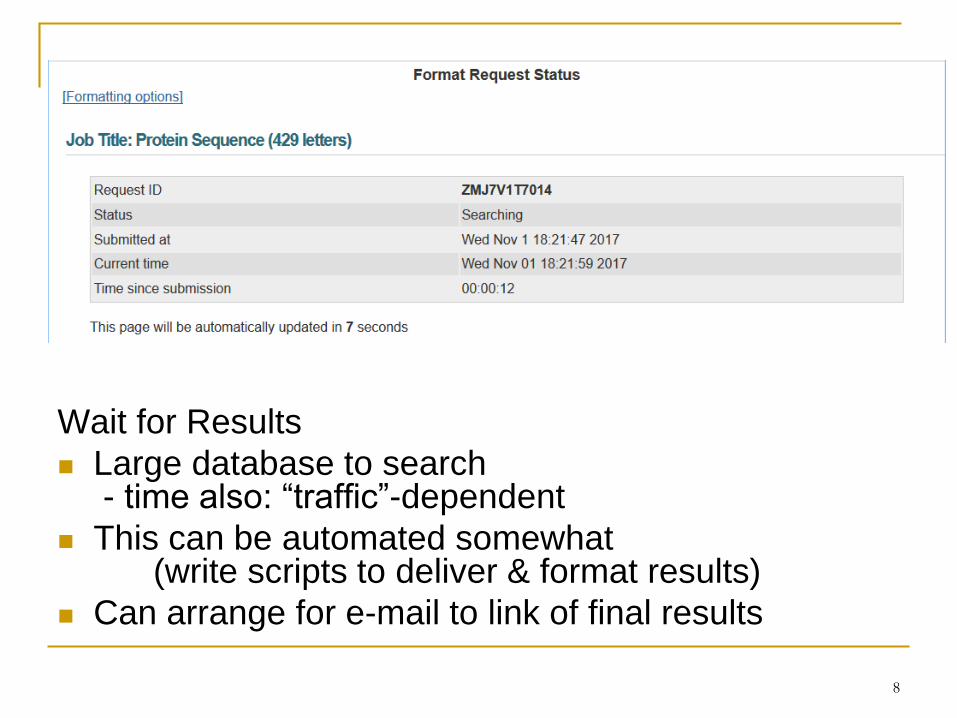
Wait for Results
Large database to search- time also: “traffic”-dependent
This can be automated somewhat(write scripts to deliver & format results)
Can arrange for e-mail to link of final results

9
Visualize
alignments,
colored by
score
Scroll down
or click on
alignments
to see more
information
most
interested in
top scoring
alignments

10
We already knew
this one; probably
more interested in
other “good”
alignments

11
Normalized alignment score
The expected # of sequences to score higher than this one in the
database search, just by chance
links to
gene
info
…
12
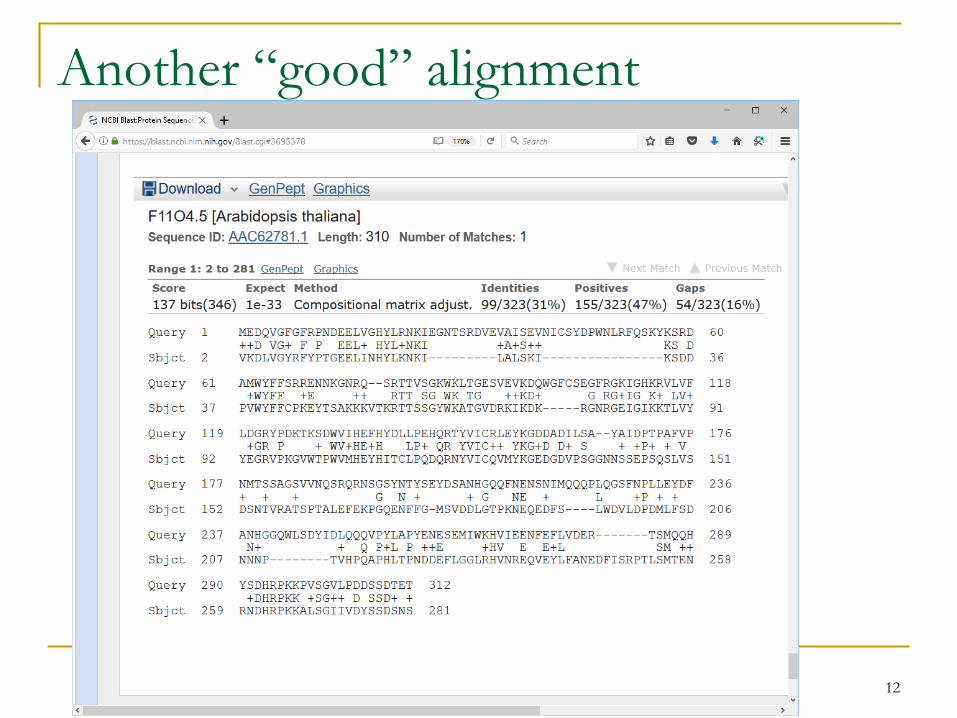
Another “good” alignment

Distribution of maximum score
13
Think of alignment score as sum of indep. random
variables.
Then the distribution of this score can be considered
approximately normal. (why?)
The asymptotic distribution of the maximum MN of a
series of N independent normal random variables is
the extreme value distribution:
Use this to calculate the probability that the best
match from a search of N unrelated sequences has
score greater than our observed largest score S.
x
N eNKMP exp

14
E-value of a local, ungapped alignment
system scoringfor scale natural
size space searchfor scale natural
residues) in database, of length(or sequence database of length
sequencequery of length
where
,exp
: theis Sleast at of
scores withs HSP'ofnumber expected theThen
).alignments local ungapped scoring- top theof (one
pair"segment scoring-high"a be Let HSP
K
n
m
SnmKE
E-value
depend on qa and s(a,b)
2log
log
:is scorebit theaside,an As
KSS

15
Statistical Significance of an Alignment
E
E
a
eXPXP
eE
EXP
a
EEaXP
EXEEPoissonX
X
1010
!0)exp(0
!)exp(
][ );(~
Sleast at score withs HSP'of #
0
Probability of observing a result at least as extreme as what was
seen, just by chance, when the sequences are all unrelated (Null)
= P-value
Still need to look at biological similarity
16
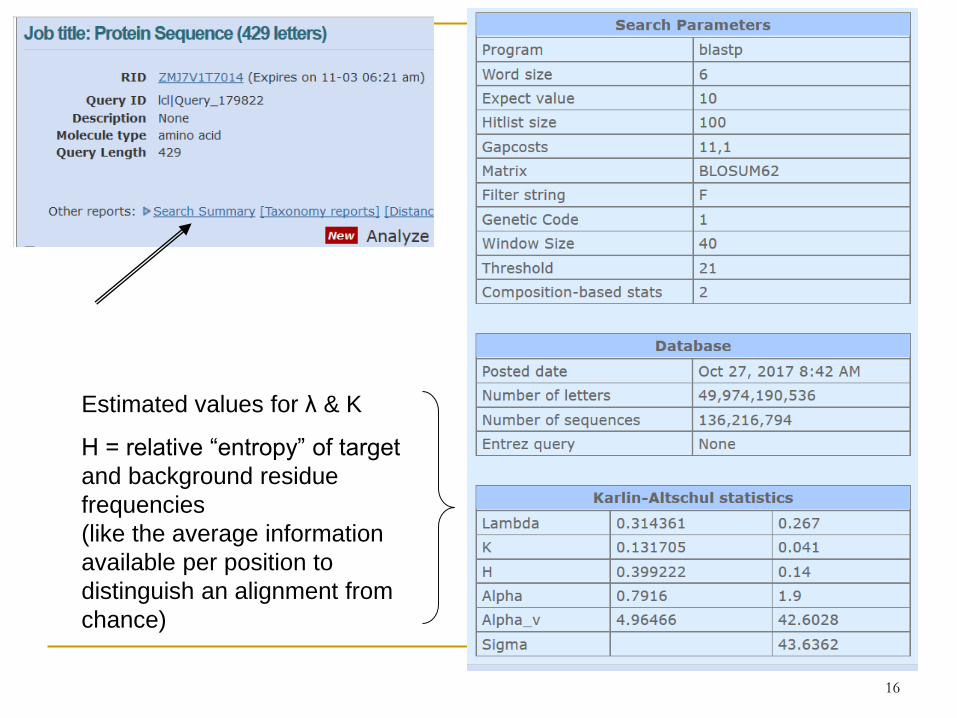
Estimated values for λ & K
H = relative “entropy” of target
and background residue
frequencies
(like the average information
available per position to
distinguish an alignment from
chance)

17

18
Sub-tree

19
Other resources to consider
Altschul et al. (1990) “Basic Local Alignment
Search Tool.” Journal of Molecular Biology
215:403-410.
Mitrophanov & Borodovsky (2006) “Statistical
significance in biological sequence analysis.”
Briefings in Bioinformatics 7(1):2-24

20

Nexus file format
21
(NOTE: can’t have duplicate tip labels; added (1), (2), & (3);
http://www.stat.usu.edu/jrstevens/bioinf/tree1.nex )

Phylogenetic trees in R
22

23
library(phylobase)
tree <- readNexus("C:\\folder\\tree1.nex")
treePlot(tree, type="phylogram")
(We may return to these trees in another discussion)

24
Summary
BLAST
look at finding global alignment
from smaller, local alignments
E-value
expected number of better scores
just by chance,
when sequences are not related
Statistical significance ≠ biological relevance


















