
Introduction To Bioinformatics - Purdue Genomics...
72
1 Biol47800/59500 Bioinformatics Introduction To Bioinformatics Biol 47800 & 59500-012
Transcript of Introduction To Bioinformatics - Purdue Genomics...

1 Biol47800/59500 Bioinformatics
Introduction To BioinformaticsBiol 47800 & 59500-012

2 Biol47800/59500 Bioinformatics
Biol47800 – Introduction to Bioinformatics
• For Undergrads: BIOL 47800 (3 credits)
• For Grads: BIOL 59500-003 (4 credits)
• Instructor: Michael Gribskov
Hockmeyer 331, 494-6933
Office hours by appointment, see my calendar
http://www.google.com/[email protected]

3 Biol47800/59500 Bioinformatics
Course work
• Lectures◦ The syllabus gives a list of readings in the text that should be completed
BEFORE the lecture. Note that I do not discuss all the material in the text in class. Nevertheless, any of the assigned material is likely to appear in exams.
• Homework◦ Homework assignments, generally weekly. Handed in/posted on Friday, due
on the following Friday as indicated on the schedule.
• Quizzes◦ There will be at least two quizzes. Each quiz will last 30 minutes. The
quizzes are closed book, closed notes and no calculators or computers.
• Exams◦ Two midterms are tentatively scheduled for 27 September and 1 November.
The exams are closed book, closed notes and no calculators or computers. The material to be covered will be described in detail in class. The two midterms will each emphasize material covered during the relevant portion of the class, but the second will include some material from the first exam. The final exam will cover the entire course, but will emphasize the material covered since the second midterm.

4 Biol47800/59500 Bioinformatics
Assessment and GradingActivity Points Each Points Overall
Final 300 300
Midterms 100 200
Homework 20 240
Quizzes 30 60
Total 800
Anticipated Grade Ranges
• A 100% - 85% A+ > 95% A- <90%
• B 85% - 75% B+ > 83% B- <77%
• C 75% - 65% C+ > 73% C- <67%
• D 50% - 65%
• F <50%
Ranges may be moved downward
but will not be moved upward

5 Biol47800/59500 Bioinformatics
Policies - Academic behavior
• Academic dishonesty of any kind (cheating, plagiarism,
fabrication of data, improper collaboration, etc.) is not tolerated
and is grounds for failing the course (grade F) and notification
of University administration for further disciplinary action.
• All assignments will be explicitly labeled for individual versus
group effort; groups will be instructed as to the rules for
collaboration.
• All questions about course policy and administration should be
directed to the instructor.

6 Biol47800/59500 Bioinformatics
Textbook
• Primary Text:
◦ Understanding BioinformaticsZvelebil and BaumGarland ScienceISBN: 978-0-8153-4024-9
◦ Also available as ebook– http://store.vitalsource.com/show/978-1-1369-7696-4
– 180 day e-rental: $69.00 (50% off list)
– 1 year e-rental: $82.00 (40% off list)
– E-book purchase: $96.00 (30% off list)
◦ Amazon
– new: $84.69
– used: from $61.67
– rent: $19.75
– Kindle – buy: $80.46
– Kindle – rent: from $28.98

7 Biol47800/59500 Bioinformatics
• Bioinformatics/Computational Biology
◦ Bioinformatics – originally the application of databases in biology – it has
come to mean any kind of computational analysis and is synonymous
with computational biology
• Main Topics
◦ Genomics (DNA and protein sequence analysis)
◦ Evolution and Phylogenetics
◦ Systems Biology
◦ Protein structure

8 Biol47800/59500 Bioinformatics
Schedule Week 1 19 Aug – 23 Aug
• Introduction & motivation
• Tree thinking & Sequences and Evolution
◦ Tree thinking handout – Reading/Tree thinking; Baum, 2005
• Intro to sequence comparison

9 Biol47800/59500 Bioinformatics
Genomics
Genomics – Study of the whole nucleotide sequence
of an organism

10 Biol47800/59500 Bioinformatics
Genomics

11 Biol47800/59500 Bioinformatics
Genomics
What is genomics good for?
• Forensics - Genotyping
• Medical diagnostics
◦ Genetic diseases
◦ Drug response/sensitivity
• Identifying new diseases
◦ Contagion (2011)
◦ Outbreak (1995)
◦ Andromeda strain (1971)
• Identifying genes and what they do
• Understanding the whole cell

12 Biol47800/59500 Bioinformatics
Genomics
Key technologies
• Methods to isolate very small amounts of DNA from
environment or tissue (PCR – polymerase chain reaction)
• Automated machines to rapidly determine DNA base sequence
(DNA sequencer)
• Reasoning on trees
• Computational approaches
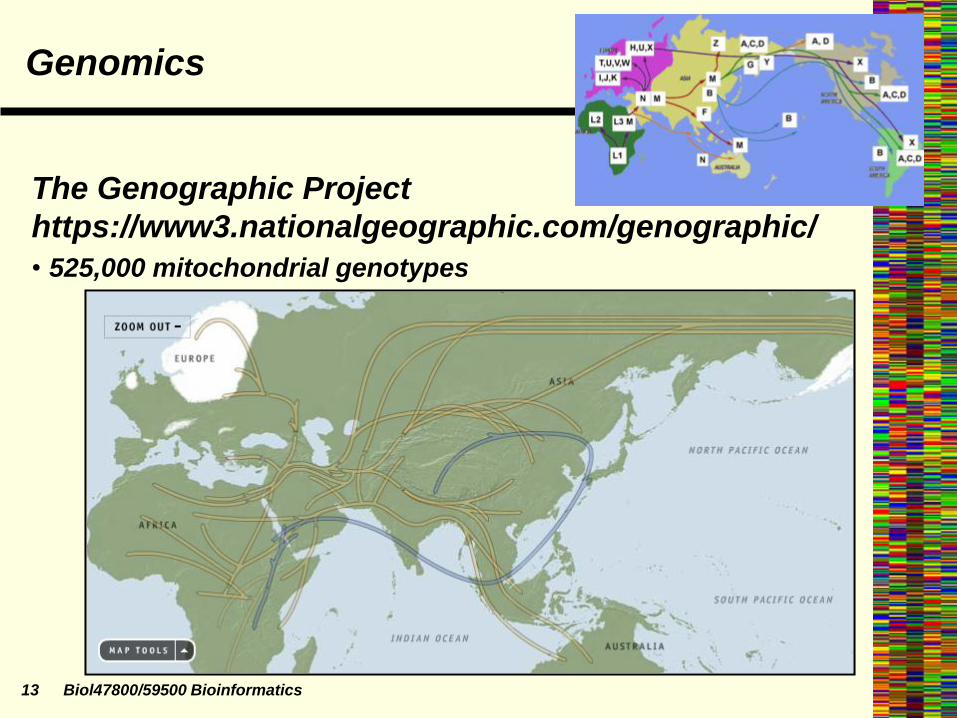
13 Biol47800/59500 Bioinformatics
Genomics
The Genographic Project
https://www3.nationalgeographic.com/genographic/
• 525,000 mitochondrial genotypes

14 Biol47800/59500 Bioinformatics
Genomics
Haplotype H
• L0/L1/L2 – subsaharan african 150 – 80,000 BC
• L3 northern africa – 80,000 BC
• N/R middle east – 60,000 BC
• Pre-HV/HV central asia – 60 - 30,000 BC
• H europe – 30,000 BC

15 Biol47800/59500 Bioinformatics
Genomics
Mitochondrial inheritance
• Mitochondria have their own DNA and replicate separately from
nuclear DNA
• Mitochondria are inherited from the mother only
• Mitochondria have very limited recombination or transposable
elements
• Good for making trees in the 10 Kyr to 1 Myr range

16 Biol47800/59500 Bioinformatics
Genomics
Gain and loss of mitochondrial lineages
• Due purely to chance, some lineages die out
• no children
• no female children
• Random mutations
gradually change
sequence
• Since changes are
small, you can tell
the relationships
between new and
old forms

17 Biol47800/59500 Bioinformatics
Genomics
1918 "Spanish" flu pandemic
• Appeared suddenly
• So different from other flu strains that there was no resistance
~ 2% mortality
• 25-30% of world population infected
• Killed 40-100 million worldwide, 675,000 US (in 4 months)
◦ Today a similar pandemic would kill in the 100
millions
◦ Similar pandemic today would cause 2 million
US deaths
• Using modern techniques, sequences have been
obtained from pathology samples, frozen
tissues, etc

18 Biol47800/59500 Bioinformatics
Genomics

19 Biol47800/59500 Bioinformatics
Genomics
HIV infection

20 Biol47800/59500 Bioinformatics
Genomics
Identification of AIDS/HIV
• 1978 - Gay men in the US and Sweden -- and heterosexuals in Tanzania and Haiti -- begin showing signs of what will later be called AIDS.
• 1980 - 31 known deaths identified in US
• 1981 - CDC reports 5 young homosexual men treated for Pneumocystis carinii at 3 different LA hospitals have with multiple infections including cytomegalovirus, 2 die
• 1981 - 26 cases of Karposi Sarcoma identified in the last 30 months among gay males, 8 died within 2 years
• 1987 - first drugs
• 1981 - deaths US 234
• 1982 - deaths US 853 AIDS is defined, linked to blood transfusion
• 1983 - deaths US 2,304 retrovirus isolated (HTLV-III, LAV)
• 1984 - deaths US 4,300 HIV sequenced (HTLV-III)
• 1985 - deaths US 2960 cumulative 16,301 first blood test
• 1986 - deaths US
• 1987 - deaths US 4,100 first drugs
• 1988 - deaths US 4,900
• 1989 - deaths US 14,500
• 1990 - deaths US 18,500
• 1991 - deaths US 20,500
• 1992 - deaths US 23,400
• 1993 - deaths US 41,900
• 1994 - deaths US 32,300
• 1995 - deaths US 48,400
• 1996 - deaths US 35,000
• 1997 - death count US 21,400, worldwide 6.4 million, 22 million infected
• 2004 - death count US 17,557, cumulative 524,000 (0.2 % of US population)
• 2007 - approximately 30-36 million infected worldwide (0.8% of population)
• since the beginning of the AIDS epidemic, 617,025 people have died of AIDS in the US

21 Biol47800/59500 Bioinformatics
Genomics
AIDS
• Many AIDS drugs are targeted at the HIV protease
◦ HIV protein is translated as a single large protein (polyprotein) and must
be cut up into individual pieces by the HIV encoded protease
◦ How was the protease identified as a target?
– sequence comparison showed homology to aspartic proteases
– aspartic proteases were already being investigated as drug targets
– inferences were made based on homology modeling

22 Biol47800/59500 Bioinformatics
Genomics
Understanding a genome
• The human genome has been completely sequenced.
• How do we find the important genes
◦ genes related to human genetic diseases: sickle cell anemia, Parkinson's
disease, Huntingtons's disease, cystic fibrosis
◦ multi-factor diseases hypertension, obesity, schizophrenia, diabetes,
cancer
• How do we figure out how the genetic differences lead to
disease?
• How do we generate hypotheses about possible functions?
◦ DNA binding
◦ Enzyme activity
◦ Signal Transduction
◦ etc.

23 Biol47800/59500 Bioinformatics
• Bioinformatics/Computational Biology
◦ Bioinformatics – originally the application of databases in biology – it has
come to mean any kind of computational analysis and is synonymous
with computational biology
• Main Topics
◦ Genomics (DNA and protein sequence analysis)
◦ Evolution and Phylogenetics
◦ Systems Biology
◦ Protein structure

24 Biol47800/59500 Bioinformatics
Lecture 2 – 21 August

25 Biol47800/59500 Bioinformatics
Schedule Week 1
19 Aug – 23 Aug
• Introduction & motivation
• Tree thinking & motivation
◦ Tree thinking handout – Reading/Tree thinking; Baum, 2005
• Intro to sequence comparison
• Reading for next week
◦ Ch 4.1-4.4
Ch 5.2

26 Biol47800/59500 Bioinformatics
Tree thinking
• Trees represent biological relationships
◦ species
◦ genes
◦ sequences
◦ data
• Adjacent branches are the most closely
related
• Biology uses trees because history is a
fundamental explanation for why the
world is how it is

27 Biol47800/59500 Bioinformatics
Genomics
Four Corners virus
• May 1993 – a young physically fit Navaho man suffering from
shortness of breath is admitted to the hospital in new Mexico
and dies rapidly. His fiancée had died a few days earlier with
similar symptoms.
• Within a few hours, five other deaths of young healthy people
from acute respiratory failure were identified.
• Mortality rate >80% in initial patients/victims
• Many causes were investigated and rejected:
◦ Bubonic plague
◦ Bacterial sepsis
◦ Herbicide exposure
◦ Influenza

28 Biol47800/59500 Bioinformatics
Genomics
Four Corners virus
• Symptoms suggested a virus
• Eventually, an previously unknown Hantavirus was identified
from tissue samples
◦ Low cross reactivity of patient antibodies to known Hantaviruses
◦ PCR amplification and sequencing
• How does this help?

29 Biol47800/59500 Bioinformatics
Genomics
Four Corners virus
• All known Hantaviruses are known to be transmitted by rodents
• 1700 rodents were trapped from June to August
1993 near the homes of victims. Trapped
rodents were dissected and analyzed.
• About 30% of deer mice (Peromyscus maniculatus)
were found to carry the unknown strain of Hantavirus
• In November 1993 the specific virus was isolated (now called Sin
Nombre virus)

30 Biol47800/59500 Bioinformatics
Genomics
Four Corners virus
• Steps
◦ Identification of sequence
◦ Identification of known viruses with similar sequence
◦ Inference of virus characteristics based on known viruses

31 Biol47800/59500 Bioinformatics
Tree thinking

32 Biol47800/59500 Bioinformatics
Tree Thinking
• When a characteristic, for instance
black or blond hair, is distributed along
a tree in a way that implies inheritance,
we can
◦ infer the ancestral characteristics
◦ we can infer the characteristics of current
members of the tree
• When characteristics are distributed
without regard to inheritance they are
independent (or the tree is wrong)
?
a b
?

33 Biol47800/59500 Bioinformatics
Genomics
Tree thinking
• Phylogenetic trees maximize the similarity in characters
between related species
• Which tree is more correct?
Left to right position means nothing in a tree!

34 Biol47800/59500 Bioinformatics
Genomics
Tree thinking
• Branches with a more recent common ancestor are more
closely related
• Common features are likely to come from ancestors, and to be
shared in sibling lineages

35 Biol47800/59500 Bioinformatics
Genomics
Spread of HIV

36 Biol47800/59500 Bioinformatics
Genomics
Looking at similar molecules can tell us
• where they came from (history)
• how they work (mapping knowledge)
• The key starting point is the knowledge that you are looking at
molecules that are ancestrally related. This is called homology

37 Biol47800/59500 Bioinformatics
Genomics
What is Homology?
• Seen in the light of evolution, biology is, perhaps, intellectually the most satisfying and inspiring science. Without that light it becomes a pile of sundry facts some of them interesting or curious but making no meaningful picture as a whole.Nothing in biology makes sense except in the light of evolution, Theodosius Dobzhansky (1900-1975)
• homology - the presence of a similar feature because of descent from a common ancestor ◦ Homology cannot be observed. We can’t actually see the ancestral
organisms/molecules and trace descent.
◦ Homology is an inference, a conclusion we draw based on observed similarity.
◦ Homology is an all-or-none relationship – no partial homology
•
• homoplasy - the presence of a similar feature because of convergence. ◦ Text pg 74 implies this might be common, but it is not.

38 Biol47800/59500 Bioinformatics
Genomics
Why is homology Important?
• Homology strongly suggests that the molecules have similar structure and function
• Some time in the past, the molecules had identical structure and function
• Biology is conservative - small accumulations of mutations lead to small changes in function, but not to radical changes
• If you can prove homology, you have a strong basis for predicting similar structure and function
• Known information about related molecules can be "mapped" onto unknown molecules
Highly
Similar
Sequence
Homology
(Common
Ancestry)
Similar
Structure &
Function

39 Biol47800/59500 Bioinformatics
Genomics
Convergence is Unlikely
• There are (very) many ways to fold a polypeptide to place
specific chemical groups at specific locations. There is no
reason, a priori, why proteins with a specific function should
have similar 3-D structures.
• Therefore, there is no reason, a priori, why unrelated
sequences should have any detectable similarity in sequence.
Significantly similar molecular sequences are very unlikely to
arise by chance - i.e., homoplasy on the molecular level is very
unlikely.
• When we see significant similarity, we infer that the
sequences/structures are homologous, i.e., at some point in the
past they shared an identical sequence and structure.

40 Biol47800/59500 Bioinformatics
Genomics
Constraints
• The only thing that keeps sequences tied to each other is the
commonality of structure and function arising from homology,
and ongoing constraints on the function of the molecule.
• Mutations are free to happen in portions of the molecule with
no function
◦ Non-coding region
◦ Disorder region of protein
◦ Third position of codon
• If a molecule is essential or useful, mutations that disrupt the
regulation, structure, or function are deleterious and selected
against.
• The function therefore constrains the evolution of the molecule
– mutations accumulate more slowly in regions that have
important functions.

41 Biol47800/59500 Bioinformatics
Genomics
How important is homology?
• Many developmental genes in mammals are homologous to
genes in drosophila
• Fundamental processes of replication, transcription, and
translation are homologous in all living things
• How much of what we know about molecular function comes
from inferred homology?
Over 95% of genes with "known" functions have their functions
"determined" by sequence matching, i.e., by homology

42 Biol47800/59500 Bioinformatics
Genomics
Inferring homology
• We can only make inferences about function when we know we
are comparing the "same" things.
◦ homologous genes
◦ homologous proteins
• Typical argument: This gene in mouse is the same as a gene in
humans, therefore it does about the same thing
• How do you…
◦ … find the same gene in two genomes?
◦ … find the same protein in two proteomes?
◦ … guess the function of a new gene?

43 Biol47800/59500 Bioinformatics
Genomics
How is homology determined?
• Because molecular homoplasy is unlikely, significant sequence
similarity strongly indicates homology
Similarity ≈ homology
• Similarity is determined by sequence matching or comparison,
more commonly called sequence alignment
• Approaches
◦ Dotplots
◦ Alignments
◦ Database searches

44 Biol47800/59500 Bioinformatics
Genomics
Homology
• Sequences alignments and database searches let us
◦ Find homologous sequences (genes/proteins)
◦ Map information from known systems to new ones
– Gene identification
– Gene function
– Metabolic and regulatory systems
• Two common classes of homologs
◦ Orthologs – genes separated by a speciation event, i.e., the same gene
in two species
◦ Paralogs – genes separated by a duplication events, originally the same
but now diverged with possibly different functions

45 Biol47800/59500 Bioinformatics
Genomics
Dotplots – a simple way to compare sequences
1 VLSPADKTNVKAAWGKVGAHAGEYGAEALERMFLSFPTTKTYFPHF.... 46
.||.::. | ..||||:|. .:.|.|.| |:| : |.| . |..|
1 GLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLK 50
. . . . .
47 ..DLSHGSAQVKGHGKKVADALTNAVAHVDDMPNALSALSDLHAHKLRVD 94
| .:|.::| || .| .||.. : . :. ...:.:|.: || | ::.
51 SEDEMKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIP 100
. . . .
95 PVNFKLLSHCLLVTLAAHLPAEFTPAVHASLDKFLASVSTVLTSKYR 141
. :.::|.|:: .|... |::|.:..::.::| |. ... :.|.|:
101 VKYLEFISECIIQVLQSKHPGDFGADAQGAMNKALELFRKDMASNYK 147

46 Biol47800/59500 Bioinformatics
Genomics
Change over Time
• How do genes (proteins, regulatory networks) change over
time?
• Is the evolutionary process random?
• Why do the changes we see in proteins have such a non-
random distribution
Mutations change the sequence of the DNA, causing changes in the
properties of the encoded proteins
While different mutagens have different preferences, mutations are
essentially random with respect to the position of genes
The changes we see are the result of two processes: Mutation
(random) and selection (non-random). If you assume that genes
have useful functions, different mutations affect the function to
different extents. The structure and function of the gene and the
encoded protein constrain which mutations are compatible with the
function

47 Biol47800/59500 Bioinformatics
Genomics
Dotplots
• Simplest method - put a dot wherever sequences are identical
• A little better - use a scoring table, put a dot wherever the
residues have better than a certain score
• Or, put a dot wherever you get at least n matches in a row
(identity matching, compare/word)
• Even better - filter the plot

48 Biol47800/59500 Bioinformatics
Dotplots
M Y S E Q U E N C E
H
I
S
S
E
Q
E
N
C
E
H I S S E Q E N C E
M Y S E Q U E N C E
H I S S E Q E N C E
M Y S E Q U E N C E
Genomics

49 Biol47800/59500 Bioinformatics
Genomics
Dotplots

50 Biol47800/59500 Bioinformatics
A C C T T G T C C T C T T T A C C T G C C G A A
A C G T T G A C C T G T A A C C T G C C G A T T
Window Length = Segment = Span = 6
Genomics
Dotplots
• Windowed scores
◦ Calculate a score within a window
◦ Move the window over one
A C C T T G T C C T C T T T A C C T G C C G A A
A C G T T G A C C T G T A A C C T G C C G A T T

51 Biol47800/59500 Bioinformatics
Genomics
RecA DNA sequence from Helicobacter pylori and Streptococcus
mutans, window/ match shown below figure
2/2 4/4

52 Biol47800/59500 Bioinformatics
Genomics
RecA DNA sequence from Helicobacter pylori and Streptococcus
mutans, window/ match =9/6

53 Biol47800/59500 Bioinformatics
Genomics
RecA DNA sequence from Helicobacter pylori and Streptococcus
mutans, window/ match = 12/8

54 Biol47800/59500 Bioinformatics
Genomics
Dot Matrix Plots
• What can you see in dotplots?
◦ Similar regions
◦ Repeated sequences
◦ Rearrangements
◦ RNA structures

55 Biol47800/59500 Bioinformatics
Dotplots/Repeats
Genomics
Repeat type 1 Repeat type 2
Length of repeat
# of repeats = # parallel lines

56 Biol47800/59500 Bioinformatics
Genomics
Drosophila Notch protein
EGF repeats
Lin12 repeats
“low entropy” sequences

57 Biol47800/59500 Bioinformatics
Genomics
Repeated sequence in E. coli ribosomal protein S1
1 2 3 4 5 6• Found only in gram-negative
bacteria
• Ancient duplication of IF-1
like gene (6-fold)
• Common domain in other
protein such as polynucleo-
tide phosphorylase
• Typically binds as trimer
• Repeats specialized after
duplication

58 Biol47800/59500 Bioinformatics
1 VLSPADKTNVKAAWGKVGAHAGEYGAEALERMFLSFPTTKTYFPHF.... 46
.||.::. | ..||||:|. .:.|.|.| |:| : |.| . |..|
1 GLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLK 50
. . . . .
47 ..DLSHGSAQVKGHGKKVADALTNAVAHVDDMPNALSALSDLHAHKLRVD 94
| .:|.::| || .| .||.. : . :. ...:.:|.: || | ::.
51 SEDEMKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIP 100
. . . .
95 PVNFKLLSHCLLVTLAAHLPAEFTPAVHASLDKFLASVSTVLTSKYR 141
. :.::|.|:: .|... |::|.:..::.::| |. ... :.|.|:
101 VKYLEFISECIIQVLQSKHPGDFGADAQGAMNKALELFRKDMASNYK 147
Genomics
Homology
• Homologous sequences
show up as diagonal lines
in dotplots
• Basis for methods to find
homologous sequences

59 Biol47800/59500 Bioinformatics
Lecture 3 – 23 August

60 Biol47800/59500 Bioinformatics
• Week 1
◦ Introduction & motivation
◦ Tree thinking & motivation
– Tree thinking handout – Reading/Tree thinking; Baum, 2005
◦ Intro to sequence comparison
• Week 2 - 27 Aug – 31 Aug
◦ Monday – Alignments/Dynamic Programming
◦ Wednesday - Alignments /Scoring Systems
◦ Friday – Alignments /Scoring Systems

61 Biol47800/59500 Bioinformatics
Genomics
Repeated sequence in E. coli ribosomal protein S1
• Found only in gram-negative
bacteria
• What does this pattern
mean?
1 2 3 4 5 6
• Ancient duplication of IF-1
like gene (6-fold)
• Common domain in other
proteins such as polynucleo-
tide phosphorylase
• Typically binds as trimer
• Repeats specialized after
duplication
• Last repeat can be deleted

62 Biol47800/59500 Bioinformatics
Sequence Comparison
Dotplots of Sequence Rearrangements
A B C A BC
A B C
AB
C

63 Biol47800/59500 Bioinformatics
Sequence Comparison
Dotplots of Sequence Inversions
CTATTGGAGG AGAAGGCCGA GAGGAGCAGG ACGGCGGGAA GAGGAGTGCG GAACCCGCGG
GATAACCTCC TCTTCCGGCT CTCCTCGTCC TGCCGCCCTT CTCCTCACGC CTTGGGCGCC
CTATTGGAGG AGAAGGCCGA TTCCCGCCGT CCTGCTCCTC GAGGAGTGCG GAACCCGCGG
GATAACCTCC TCTTCCGGCT AAGGGCGGCA GGACGAGGAG CTCCTCACGC CTTGGGCGCC

64 Biol47800/59500 Bioinformatics
Sequence Comparison
Dotplots of Sequence Inversions
GATAACCTCCTCTTCCGGCTAAGGGCGGCAGGACGAGGAGCTCCTCACGCCTTGGGCGCC
CTATTGGAGGAGAAGGCCGAGAGGAGCAGGACGGCGGGAAGAGGAGTGCGGAACCCGCGG
CTATTGGAGGAGAAGGCCGATTCCCGCCGTCCTGCTCCTCGAGGAGTGCGGAACCCGCGG
CTATTGGAGGAGAAGGCCGAGAGGAGCAGGACGGCGGGAAGAGGAGTGCGGAACCCGCGG
Original sequence vs inverted sequenceOriginal sequence vs
inverted sequence reverse complement

65 Biol47800/59500 Bioinformatics
Sequence Comparison
Dotplot of base-paired RNA
A T
C
C
G
G
G
G
C
C
C
A
T T
GACCGCTTACGGTC
G A C C G T A A G C G G T C
G A C C
G C T T
A C G G
T C
Red dots = base paired region
Dotplot of sequences vs
reverse-complement (other
strand of same sequence)

66 Biol47800/59500 Bioinformatics
1 VLSPADKTNVKAAWGKVGAHAGEYGAEALERMFLSFPTTKTYFPHF.... 46
.||.::. | ..||||:|. .:.|.|.| |:| : |.| . |..|
1 GLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLK 50
. . . . .
47 ..DLSHGSAQVKGHGKKVADALTNAVAHVDDMPNALSALSDLHAHKLRVD 94
| .:|.::| || .| .||.. : . :. ...:.:|.: || | ::.
51 SEDEMKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIP 100
. . . .
95 PVNFKLLSHCLLVTLAAHLPAEFTPAVHASLDKFLASVSTVLTSKYR 141
. :.::|.|:: .|... |::|.:..::.::| |. ... :.|.|:
101 VKYLEFISECIIQVLQSKHPGDFGADAQGAMNKALELFRKDMASNYK 147
Sequence Comparison
Homology
• Homologous sequences
show up as diagonal lines
in dotplots
• Basis for methods to find
homologous sequences

67 Biol47800/59500 Bioinformatics
Sequence Comparison
Dotplots and Alignments
1 VLSPADKTNVKAAWGKVGAHAGEYGAEALERMFLSFPTTKTYFPHF.... 46
.||.::. | ..||||:|. .:.|.|.| |:| : |.| . |..|
1 GLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLK 50
. . . . .
47 ..DLSHGSAQVKGHGKKVADALTNAVAHVDDMPNALSALSDLHAHKLRVD 94
| .:|.::| || .| .||.. : . :. ...:.:|.: || | ::.
51 SEDEMKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIP 100
. . . .
95 PVNFKLLSHCLLVTLAAHLPAEFTPAVHASLDKFLASVSTVLTSKYR 141
. :.::|.|:: .|... |::|.:..::.::| |. ... :.|.|:
101 VKYLEFISECIIQVLQSKHPGDFGADAQGAMNKALELFRKDMASNYK 147
An alignment is a one-to-one matching of two sequences, with the addition
of gaps (spaces) to improve the matching

68 Biol47800/59500 Bioinformatics
Sequence Comparison
Measuring the difference between sequences
ACGGTTAGCAAA
||||||| ||||
ACGGTTACCAAA
ACGGTTAGCAAA
|||| || ||||
ACGGATACCAAA
ACGGTTAGCAAA
|| ||| ||||
ACCCTTACCAAA
ACGGTTAGCAAA
| ||
CCTTACCAAAAC
ACGGTTAGCAAA
| | |||
CCTTACCAAAAC
ACGGTTAGCAAA
||| ||||
CCTTACCAAAAC
ACGGTTAGCAAA
| |||
CCTTACCAAAAC
1 2 3 Distance
11 10 9 Similarity
Sequences may have to be offset to optimize score
Match Score

69 Biol47800/59500 Bioinformatics
Sequence Comparison
Measuring the difference between sequences
• What if sequences need spaces, what should the score be?
AGTTACGGCAAA
||||| |
AGTTAGCAAA
AGTTACGGCAAA
|||||
AGTTAGCAAACC
AGTTACGGCAAA
||||| |||||
AGTTA..GCAAACC
ATCTAGCAG.T.C.A
|| | || | | |
CT.G.AGCTCCCA
• Allowing gaps makes it easier to get a high score.
• Intuitively, there should be some negative score for gaps.
• Otherwise any pair of random sequences can get a high
score.

70 Biol47800/59500 Bioinformatics
Sequence Comparison
Measuring the difference between sequences
• Sequences alignments use a scoring function based on the
number of matches and mismatches, and a function based on
the number of gaps
Match = Nmatch – Nmismatch – f(gap)
• The score than unrelated sequences might get (on average)
also matters

71 Biol47800/59500 Bioinformatics
Sequence Comparison
Finding the best alignment
• Without gaps – just slide the two sequences past each other
and choose the offset with the highest score
◦ Requires time proportional to the square of the length of the sequences
( O(L2) )
• With gaps
◦ For each offset,
– for each possible gap position
– For each possible gap length
– For each possible number of gaps
– Calculate score ( O(LL) )

72 Biol47800/59500 Bioinformatics
Sequence Comparison
Dynamic Programming Alignment
• Dynamic programming allows an optimal (highest scoring)
alignment that considers all possible numbers and lengths of
gaps to be found in O(L2) time
• Dynamic programming uses a recursive definition of an optimal
alignment
• Alignment is guaranteed to be "optimal"
◦ Given: the scoring systems used and gap penalties
• Don't confuse optimal with correct - Even unrelated sequences
can be optimally aligned!


















