
Introduction to Apache Flink™: How Stream Processing is Shaping ...
44
Introduction to Apache Flink™: How Stream Processing is Shaping the Data Engineering Space [email protected] Tzu-Li (Gordon) Tai @tzulitai
Transcript of Introduction to Apache Flink™: How Stream Processing is Shaping ...

Introduction to Apache Flink™:How Stream Processing is Shaping
the Data Engineering Space
Tzu-Li (Gordon) Tai
@tzulitai

● 戴資力(Gordon)● Apache Flink Committer● Co-organizer of Apache Flink Taiwan User Group● Software Engineer @ VMFive● Java, Scala● Enjoy developing distributed systems
Who am I?

Data Streaming is becomingincreasingly popular
1

Stream processing is enabling the obvious: continuous processing on data that is continuously produced
2

Streaming is the next programming paradigm for data applications, and you need to start thinking in terms
of streams
3

01 The Traditional Batch Wayt
...
HDFSFile
MapReduce /Spark / Flink
Jobs
● Continouslyingesting data
● Periodicbatch files
● Periodicbatch jobs
4

01 The Traditional Batch Wayt
...
cross boundary
intermediateresults
● Jobs often has “dangling” results near batch boundaries
● Need to save them, and input into the next batch job
5

02 Key Observations for Batch
6
● Way too many moving parts
● Implicit treatment of time (the batch boundaries)
● Treating continuous state as discrete
● Troublesome to get accurate, correct results

03 The “Ideal” Streaming Wayt
...
Streaming processor that handles …
(1) continuous state(2) out-of-order events
scalably, robustly, and efficiently
7

04 Apache Flink
Apache Flinkan open-source platform for distributed stream and batch data processing
● Apache Top-Level Project since Jan. 2015
● Streaming Dataflow Engine at its core○ Low latency○ High Throughput○ Stateful○ Accurate○ Distributed
8

04 Apache Flink
Apache Flinkan open-source platform for distributed stream and batch data processing
● ~260 contributors, ~25 Committers / PMC
● Used adoption:○ Alibaba - realtime search optimization○ Uber - ride request fulfillment marketplace○ Netflix - Stream Processing as a Service (SPaaS)○ Kings Gaming - realtime data science dashboard○ ...
9

04 Apache Flink
10

05 Scala Collection-like APIcase class Word (word: String, count: Int)
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap(_.split(“ ”)).map(word => Word(word,1)).groupBy(“word”).sum(“count”).print()
val lines: DataStream[String] = env.addSource(new KafkaSource(...))
lines.flatMap(_.split(“ ”)).map(word => Word(word,1)).keyBy(“word”).timeWindow(Time.seconds(5)).sum(“count”).print()
DataSet API
DataStream API
11

05 Scala Collection-like API
.filter(...).flatmap(...).map(...).groupBy(...).reduce(...)
● Becoming the de facto standard for new generation API to express data pipelines
● Apache Spark, Apache Flink, Apache Beam ...
12

06 What does Flink’s Engine do?
YourCode
process records one-at-a-time
...
● Computation on a never-ending stream of data records
13

06 What does Flink’s Engine do?
YourCode...
● System distributes the computation across the cluster
YourCode...
YourCode...
14

07 Streaming Dataflow Runtime
JobManager
TaskManager
TaskManager
TaskManager
TaskManager
TaskManager
TaskManager
ExecutionGraph
(parallel) TaskManager
TaskManager
TaskManager
Application Code
(DataSet /DataStream)
Optimizer / Graph
Generator
JobGraph(logical)
Client
concurrently executed
distributed queues as push-based data shipping channels
15

07 Streaming Dataflow Runtime
1. Record “A” enters Task 1, and is processed
2. The record is serialized into an output buffer at Task 1
3. The buffer is shipped to Task 2’s input buffer
Observation: Buffers need to be available throughout the process (think blocking queues used between threads)
● A slightly closer look into the transmission of data ...
Taken from anoutput buffer pool
Taken from aninput buffer pool
16

07 Streaming Dataflow Runtime● Natural, built-in backpressure
● Receiving data at a higher rate than a system can process during a temporary load spike
○ ex. GC talls at processing tasks○ ex. data source natural load spike
Normal stable case:
Temporary load spike:
Ideal backpressure handling:
17

● Due to one-at-a-time processing, Flink has very powerful built-in windowing (certainly among the best in the current streaming framework solutions)
○ Time-driven: Tumbling window, Sliding window○ Data-driven: Count window, Session window
07 Flexible Windows
18

07 Time Windows
Tumbling Time Window Sliding Time Window
19

07 Count-Triggered Windows
20

07 Session Windows
21
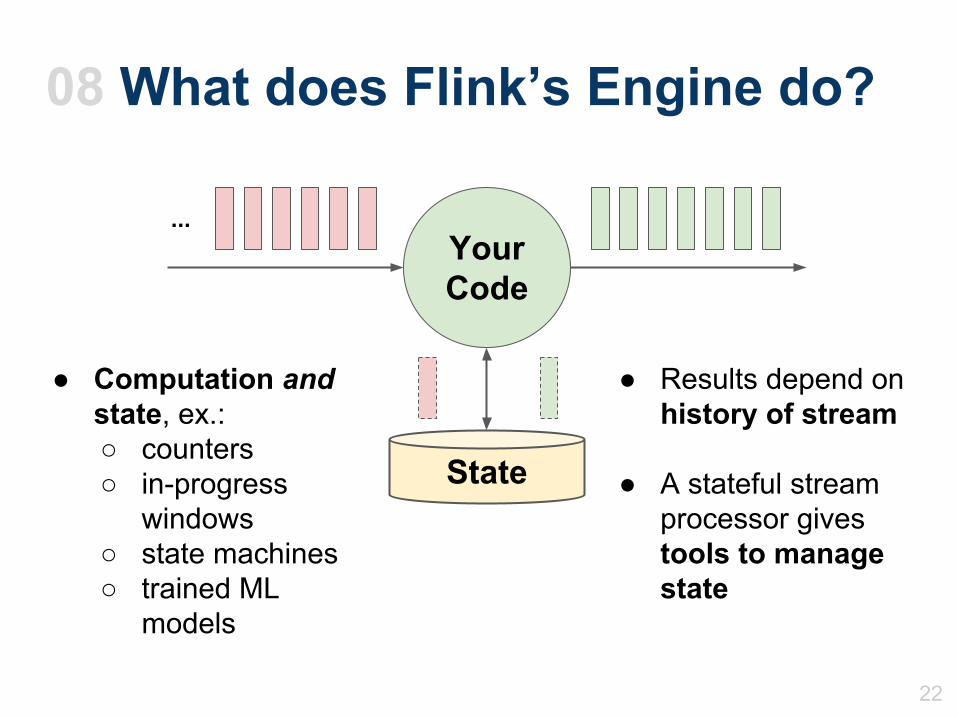
08 What does Flink’s Engine do?
YourCode
...
State
● Computation and state, ex.:○ counters○ in-progress
windows○ state machines○ trained ML
models
● Results depend onhistory of stream
● A stateful streamprocessor gives tools to manage state
22

09 What does Flink’s Engine do?
YourCode
...
State
● Processingdepends on timestamps of whenevents were generated
● Core mechanics is called watermarks: basically a way to measure and advance clock time, instead of relying on machine time
t1t2 t3t4 t1 - t2 t3 - t4
23
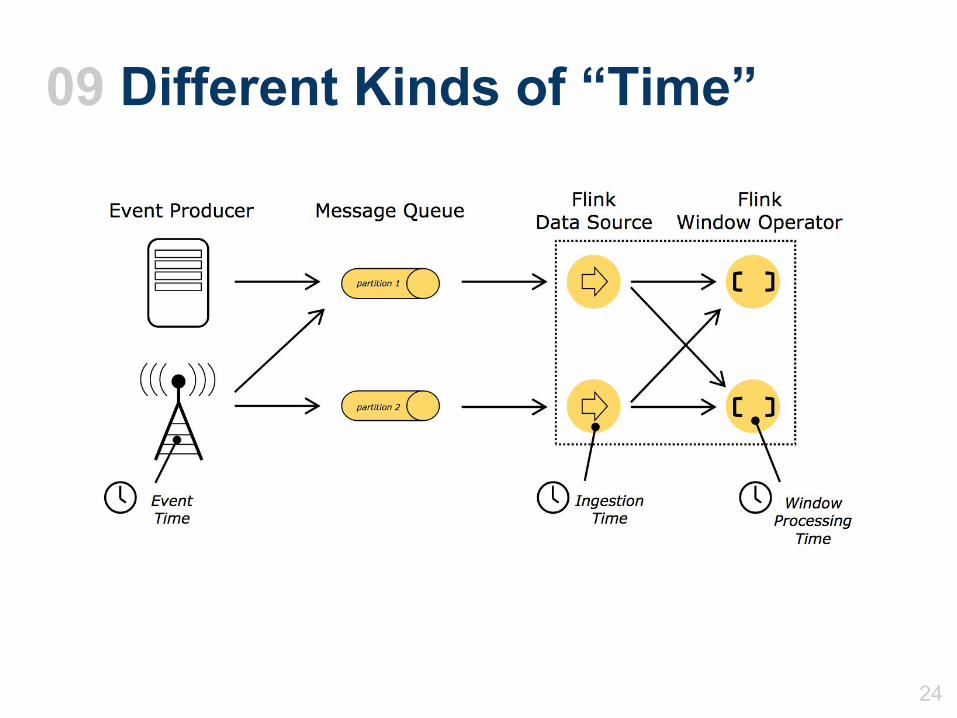
09 Different Kinds of “Time”
24

09 Why Wall Time is Incorrect
● Think Twitter hash-tag count every 5 minutes
○ We would want the result to reflect the number of Twitter tweets actually tweeted in a 5 minute window
○ Not the number of tweet events the stream processor receives within 5 minutes
25

09 Why Wall Time is Incorrect
● Think replaying a Kafka topic on a windowed streaming application …
○ If you’re replaying a queue, windows are definitely wrong if using a wall clock
26

10 Flink’s Streaming Fault Tolerance
YourCode
YourCode
YourCode
State
State
State
...
...
...
...
...
...
...
...
...
YourCode
YourCode
YourCode
State
State
State
● Any operator in a Flink streaming topology can be stateful● How to ensure that the states are correct upon failure?
27

10 Flink’s Streaming Fault Tolerance
● First, a recap of some guarantee concepts:
○ At-least-once: records may be processed more than once.Think counting: may over count, resulting in wrong state
○ Exactly-once “state”: records appear to be processed only once, with respect to the state.Think counting: even on failure, each record is counted exactly once
○ End-to-end exactly-once: records appear to be processed only once, even to external systemsThink counting: for results stored externally, even after failure, the results remain correct
28

11 Flink’s Streaming Fault Tolerance
YourCode
YourCode
YourCode
State
State
State
...
...
...
...
...
...
...
...
...
YourCode
YourCode
YourCode
State
State
State
● Flink checkpoints: a combined snapshot of all operator state, with the corresponding position in the source
● Based on Chandly-Lamport Algorithm: does not haltany computation while taking consistent snapshots
29

12 Flink’s Savepoints
● Flink checkpoints: consistent snapshots of the whole topology state that the system periodically takes
● Flink savepoints: manually triggered checkpoints that can be persisted, and used to initialize state for a new streaming job
tt1 t2 t3
savepointstate at t1
savepointstate at t2
savepointstate at t3
30

13 So, back to this ...
t
...
HDFSFile
MapReduce /Spark / Flink
Jobs
31

13 So, back to this ...
t
...
Streaming processor that handles …
(1) continuous state(2) out-of-order events
scalably, robustly, and efficiently
32

14 What Flink provides, in a nutshell example
● No stateless point-in-time
33

14 What Flink provides, in a nutshell example
● Processing, or re-processing, in the batch way
34

14 What Flink provides, in a nutshell example
● Batch is inherently unsuitable for the nature of continuously generated data
● State is corrupt at boundaries
35

14 What Flink provides, in a nutshell example
● Flink’s Stateful streaming naturally treats state continuously as it processes your continuous data, and continuously generates results
36

14 What Flink provides, in a nutshell example
● On reprocessing: initial state for the job reflects all previous history data in the stream
37

14 What Flink provides, in a nutshell example
● On reprocessing: event-time processing guarantees correct results, even when fast-forwarding to the head of stream
event-time processing
38

15 Final Takeaways
● Stateful Streaming correctly embraces the nature of continuously generated data, and is the new programming paradigm for their applications.
● Streaming isn’t only about real-time. Realtime is only a natural advantage of streaming.
39

15 Final Takeaways● The choice is all about your data, and your code.
● Think:○ Is your data unbounded, or bounded?
■ Unbounded: click streams, page visits, impressions …■ Bounded: (???)
● Think:○ Does your code change faster than your data?
■ Data exploration, data mining, feature engineering …■ In this case, it doesn’t really matter whether you use batch or streaming
○ Or does your data change faster than your code?■ Production ETL pipelines, warehousing, serving, etc.■ For accuracy and robustness, definitely think and design in terms of
streaming
40

15 Final Takeaways
● Upcoming features in Flink:
○ Dynamic scaling, with stateful streaming○ Queryable state○ Incremental state checkpointing○ Even more savepoint functionality
41

15 Final Takeaways
● How Flink’s technology covers the application space:
Application
Realtime applications
Continuous applications
Analytics on historical data
Request/Response Apps
Technology
Low-latency stateful streaming
High-latency stateful streaming
Batch as special case of streaming
Queryable state
42












![Efficient Datastream Sampling on Apache Flink · For the sampling task all implemented algorithms perform as stream operators in the Apache Flink framework. Apache Flink [2] is an](https://static.fdocuments.in/doc/165x107/5ec57af17810c0214a0c2f45/efficient-datastream-sampling-on-apache-flink-for-the-sampling-task-all-implemented.jpg)





