Introduction à DocumentDB
27
MS Azure DocumentDB MSDEVMTL GROUPE AZURE OCTOBER 26 TH , 2015
-
Upload
msdevmtl -
Category
Technology
-
view
560 -
download
1
Transcript of Introduction à DocumentDB

MS Azure DocumentDBMSDEVMTLGROUPE AZUREOCTOBER 26TH, 2015

Who am I?
Vincent-Philippe LauzonCloud Solution ArchitectMicrosoft Canada
Blog: http://vincentlauzon.comTwitter: http://twitter.com/@vplauzon

Audience
I’ve read about Azure
I’ve tried Azure
Working with Azure
Azure is what I do

No SQL
NO SQL → Not Only SQL Other than Tabular / Relational model Less / No up-front (schema) design Easier to scale horizontally (cluster) Make them a better match for big data Each Product makes different tradeoffs Younger & less complete feature set

No SQL on Azure
Fully Managed Table Storage (Key Value) Redis (Key Value) Hadoop HBase (Wide Column) Hadoop Hive (ad hoc tables) DocumentDB (Document)
Through Marketplace MongoDB (Document) CouchBase (Document) Cassandra (Wide Column) Neo4J (Graph)
Azure DocumentDB
NoSQL document database as-a-service Query JSON docs: whole docs are indexed Familiar languages: SQL & JavaScript Fast / Predictable Performance (SSD) Tunable consistency Flexible document schema without sacrificing
queryability
Will be available on Azure Stack (on premise)
Conceptual Domain
101010
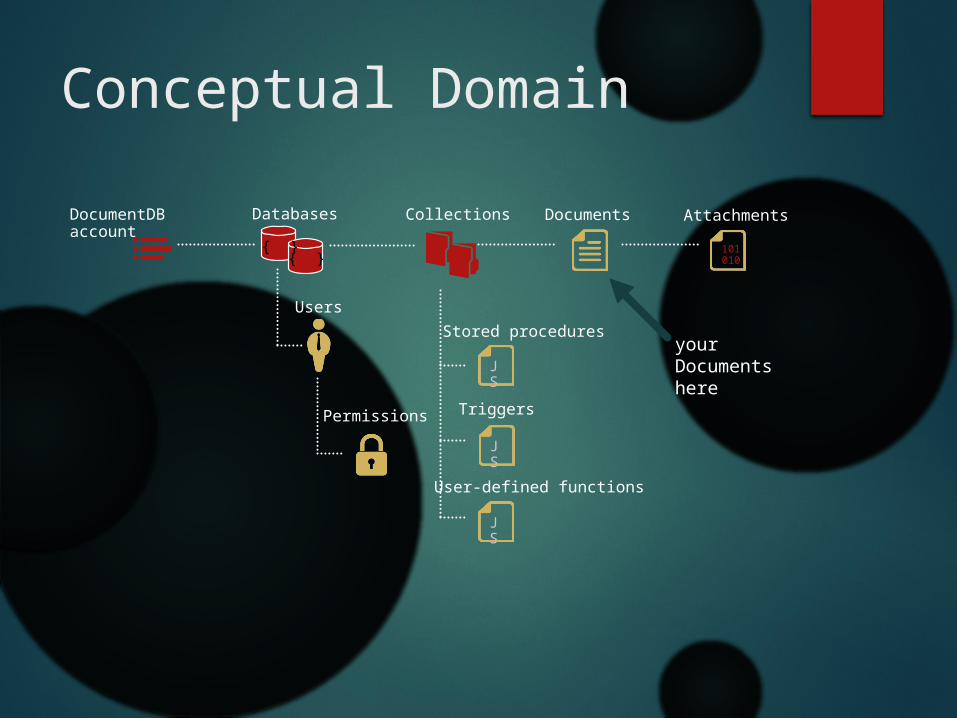
DocumentDB account
Databases
Users
Permissions
Collections Documents Attachments
Stored procedures
Triggers
User-defined functions
your Documents here
{ }{ }
JS
JS
JS

Demo: Account Creation & Adding Documents

Collections
Collections are not tables Unit of partitioning / Scaling Unit Transaction boundary No enforced schema, flexible Queries or updates stay within one collection Size of 10 Gb
For more, you need to shard through multiple collections
e.g. Spill-over, Range

Demo: Simple Querying
More on querying
Visit the Querying Playground: https://www.documentdb.com/sql/demo
Use the cheat sheet http://aka.ms/docdbcheatsheet
Data Migration Tool: https
://azure.microsoft.com/en-us/documentation/articles/documentdb-import-data/

Querying limitation
Within a collection No inter-document joins (yet?) Beside filtering, only ORDER BY is supported No aggregation yet
No COUNT No GROUP BY No SUM, AVG, etc.
SQL for queries only No batch UPDATE or DELETE or CREATE

Indexing
Every property is indexed! Unless you opt out
You can opt-out selectively Leave out paths Per collection (policy) or per document
Indexing mode: consistent vs lazy Kind: hash, range & spatial Automatic vs manual You might want to fiddle with it: indexes take space You can now change them online!

Demo: Looking at indexing policy

Consistency
Set at the account level Can be overridden at the query level 4 Levels
Strong Bounded staleness Session Eventual

Demo: Looking at consistency level

DocumentDB at Microsoft
over 425 million unique usersstore 20TB of JSON document data
under 15ms writes and single digit ms reads
store for 40+ app / device combinations
available globally to serve all markets
user data store
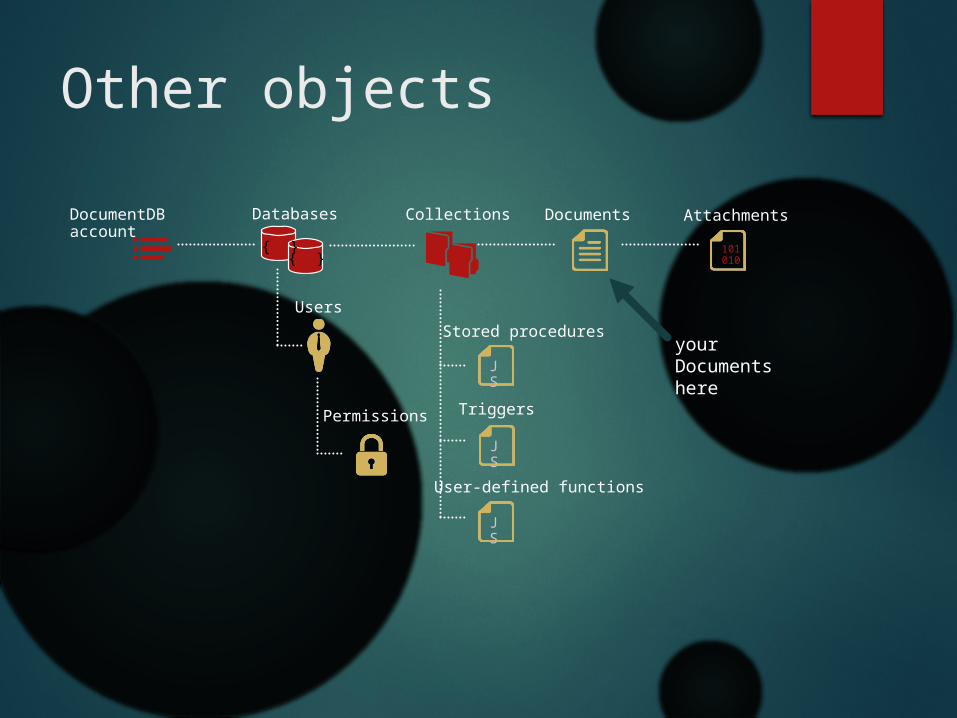
Other objects
101010
DocumentDB account
Databases
Users
Permissions
Collections Documents Attachments
Stored procedures
Triggers
User-defined functions
your Documents here
{ }{ }
JS
JS
JS

Limitations / Quotas
https://azure.microsoft.com/en-us/documentation/articles/documentdb-limits/
Entity Quota
Accounts 5 (soft)
Dbs / Account 100
Permissions / Account 2M
Sprocs, Triggers & UDFs / collection 25
Max Execution Time / Sproc, Triggeer 5 seconds
Collections / DB 100 (soft)
ID Length 255 chars
AND, OR / query 20

Demo: .NET SDK

Data Modeling – Polymorphism
Put every document type in a collection
Discriminate on document type somehow documentType property or other mechanism
Use Collection as scaling units not as categorization unit

Data Modeling – Denormalization
Optimize for read (no inter-doc joins) Embed relationships in document
One-to-few relationships Data changing infrequently Data that is integral to documents When embed provides better reading perf
Make sure the pattern fit: you read much more than you write
Gone wrong: blog posts & comments Leverage x-doc transaction (stored procs)

Data Modeling – Normalization
Normalize One-to-many (unbound) Many-to-many Frequent changes
If nothing in here fits: stick with relational

Integration within Azure
Indexer for Azure Search https://azure.microsoft.com/en-us/documentation/
articles/search-howto-connecting-azure-sql-database-to-azure-search-using-indexers-2015-02-28/
Power BI: https
://azure.microsoft.com/en-us/blog/unleashing-insights-from-data-in-documentdb-with-power-bi/
Data Factory: both source & sink Sink in Stream Analytics:
https://azure.microsoft.com/en-us/blog/azure-stream-analytics-and-documentdb-for-your-iot-application/
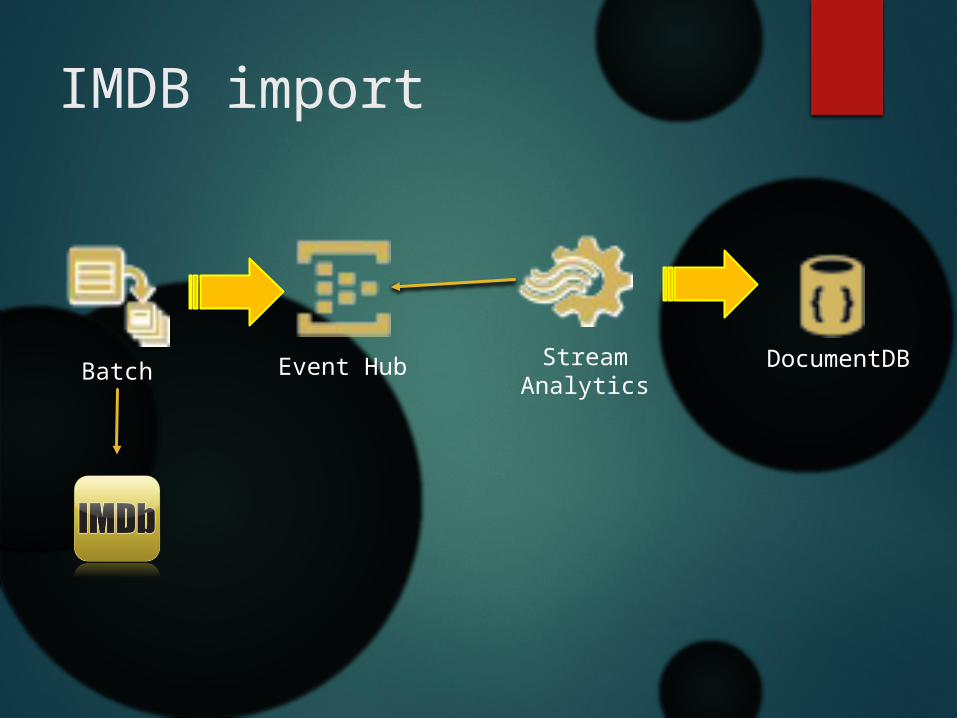
IMDB import
Batch Event Hub StreamAnalytics
DocumentDB
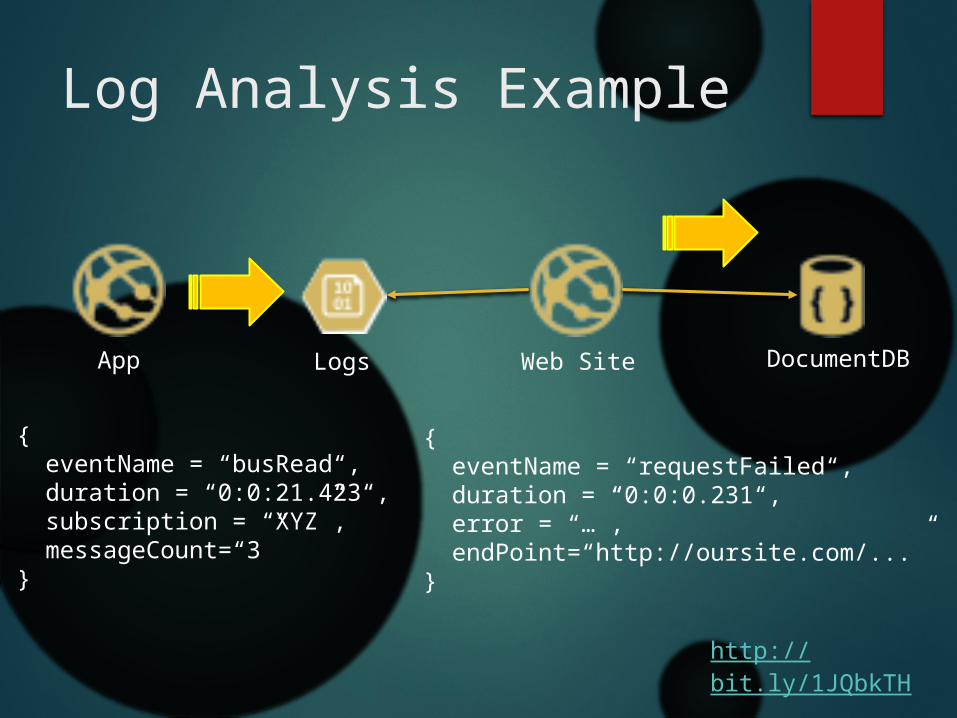
Log Analysis Example
DocumentDBWeb SiteApp Logs
{ eventName = “busRead“, duration = “0:0:21.423“, subscription = “XYZ”, messageCount=“3”}
http://bit.ly/1JQbkTH
{ eventName = “requestFailed“, duration = “0:0:0.231“, error = “…”, endPoint=“http://oursite.com/...”}

Thank you!
All demo material is available here: http://bit.ly/1SrhVcA