
Introduc)on*to*Apache*Kaa - · PDF fileIdeal*Architecture:*Stream*Data ... Oracle Oracle...
27
Introduc)on to Apache Ka1a Jun Rao Cofounder of Confluent
-
Upload
truongkhanh -
Category
Documents
-
view
229 -
download
1
Transcript of Introduc)on*to*Apache*Kaa - · PDF fileIdeal*Architecture:*Stream*Data ... Oracle Oracle...

Introduc)on to Apache Ka1a
Jun Rao Co-‐founder of Confluent

Agenda
• Why people use Ka1a • Technical overview of Ka1a • What’s coming
What’s Apache Ka1a
Distributed, high throughput pub/sub system

Ka1a Usage
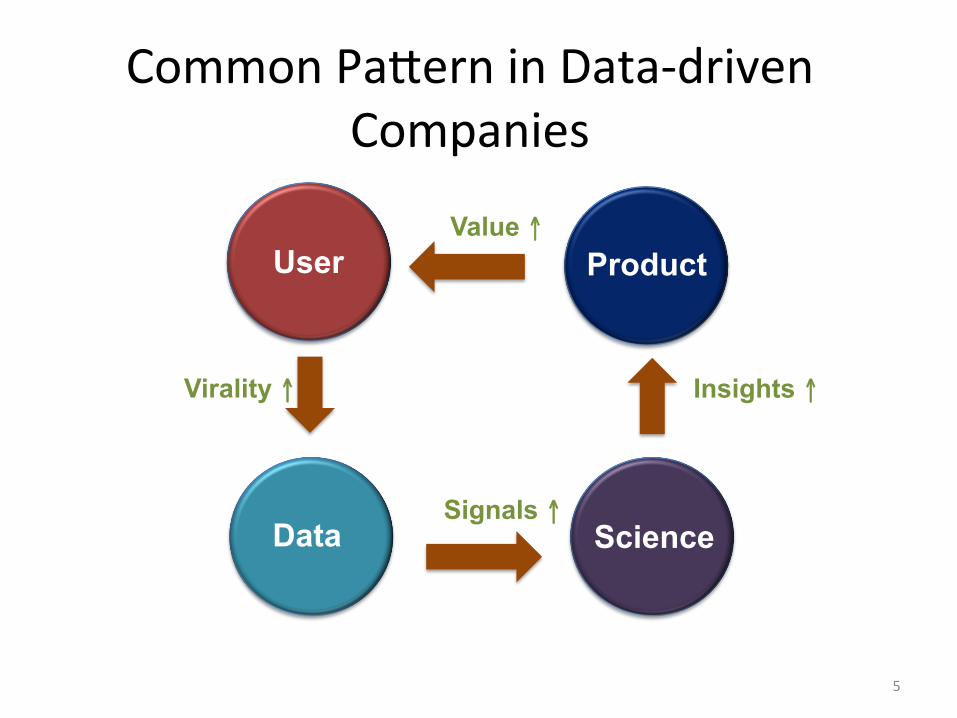
Common PaIern in Data-‐driven Companies
5
Value ↑
Insights ↑
Product
Science Data
User
Virality ↑
Signals ↑

GeLng Data Is Hard
• Data scien)sts spent 70% )me on geLng and cleaning data
• Why?

Variety in Data Sources • Database records
– Users, products, orders • Business metrics
– Clicks, impressions, pageviews • Opera)onal metrics
– CPU usage, requests/sec • Applica)on logs
– Service calls, errors • IOT • …

Variety in New Specialized Systems
• Batch oriented – Hadoop ecosystem (Pig, Hive, Spark, …)
• Real )me – Key/value store (Cassandra, MongoDB, HBase, …) – Search (Elas)cSearch, Solr, …) – Stream processing (Storm, Spark streaming, Samza) – Graph (GraphLab, FlockDB, …) – Time series DB (open TSDB, …) – …
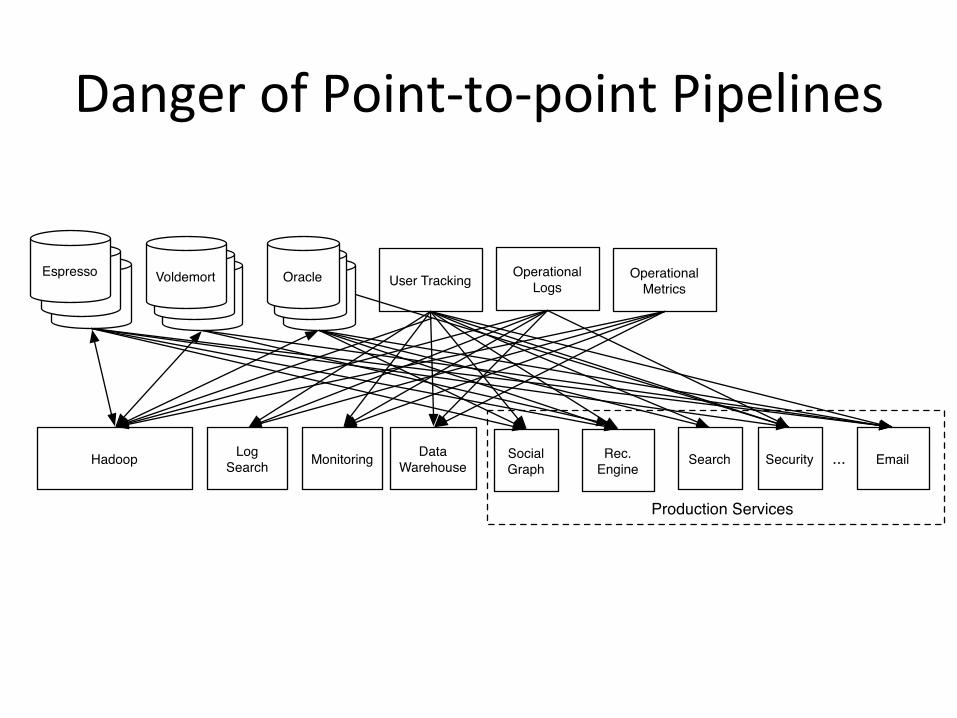
Danger of Point-‐to-‐point Pipelines
OracleOracle
Oracle User Tracking
Hadoop Log Search Monitoring Data
WarehouseSocial Graph
Rec. Engine
Search Email
VoldemortVoldemort
VoldemortEspresso
EspressoEspresso Operational
LogsOperational
Metrics
Production Services
...Security
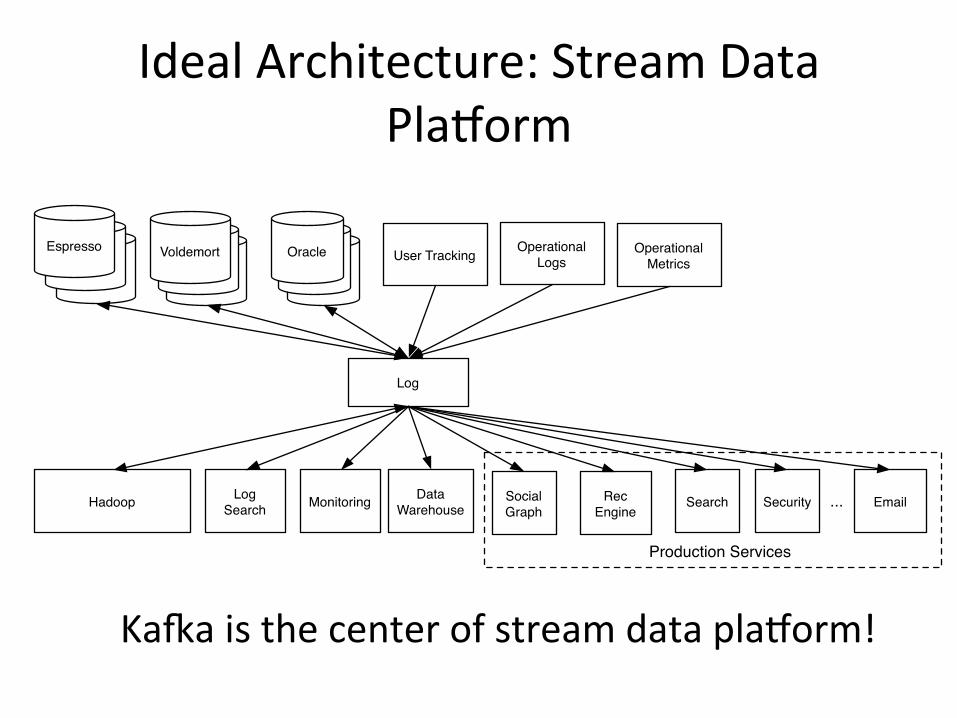
Ideal Architecture: Stream Data Plaborm
Ka1a is the center of stream data plaborm!
OracleOracle
Oracle User Tracking
Hadoop Log Search Monitoring Data
WarehouseSocial Graph
Rec Engine
Search Email
VoldemortVoldemort
VoldemortEspresso
EspressoEspresso Operational
LogsOperational
Metrics
Production Services
...Security
Log

Ka1a at LinkedIn
• 800 billion messages, 175 TB data per day • 13 million messages wriIen/sec • 65 million messages read/sec • Tens of thousands of producers • Thousands of consumers

Agenda
• Why people use Ka1a • Technical overview of Ka1a
– Throughput and scalability – Real )me and batch consump)on – Durability and availability
• What’s coming

Concepts and API
• Producer (Java) byte[] key = "key".getBytes(); byte[] value = "value".getBytes(); record = new ProducerRecord("my-topic", key, value); producer.send(record);
streams[] = Consumer.createMessageStreams("topic1", 1); for(message: streams[0]) { // do something with message }
• Consumer (Java)
• Topic defines a message queue
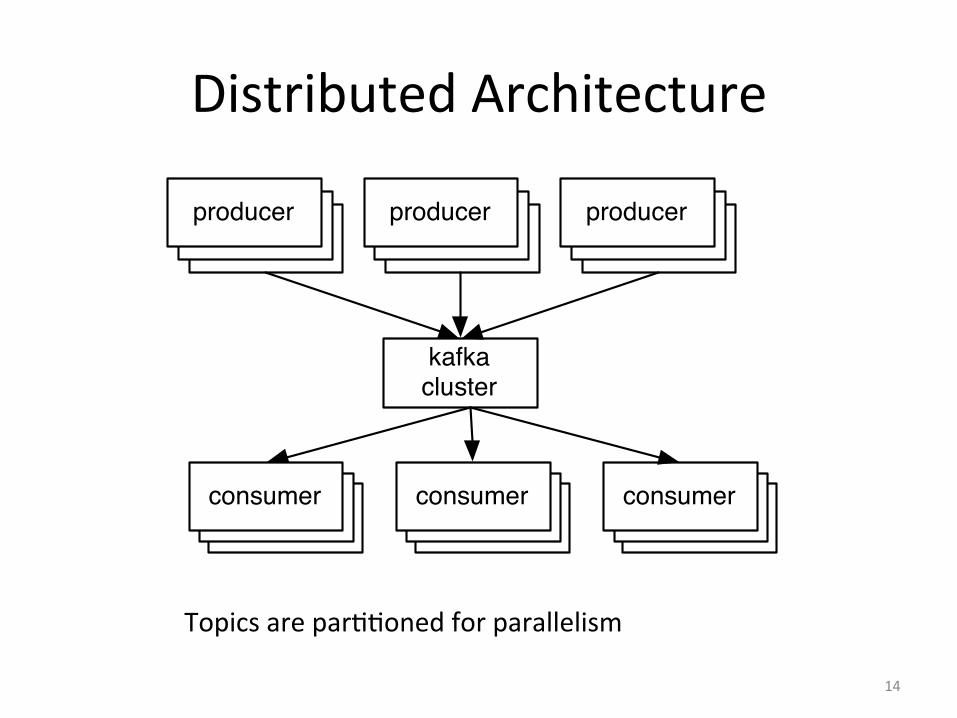
Distributed Architecture
14
Topics are par))oned for parallelism
producer
kafka cluster
producerproducerproducerproducerproducer
producerproducerproducer
consumerconsumerconsumerconsumerconsumerconsumer
consumerconsumerconsumer

Built-‐in Cluster Management
• Automated failure detec)on and failover – Leverage Apache Zookeeper
• Online data movement

Simple Efficient Storage with a Log
16
0 1 2 3 4 5 6 7 8 9 10 11 12Log
Data Source
writes
Destination System A(time = 7)
reads
Destination System B(time = 11)
reads

Batching and Compression
• Batching – Producer, broker, consumer
• Compression – Gzip, snappy, lz4 – End-‐to-‐end

Real Time and Batch Consump)on
• Mul)-‐subscrip)on model • Data persisted on disk, NOT cached in JVM
– Rely on pagecache • Zero-‐copy transfer (broker -‐> consumer) • Ordered consump)on per topic par))on
– Significantly less bookkeeping

Durability and Availability
Built-‐in replica)on • Configurable replica)on factor • Tolera)ng f – 1 failures with f replicas • Automated failover

Replicas and Layout
• Topic par))on has replicas • Replicas spread evenly among brokers
topic1-part1
logs
broker 1
topic1-part2
logs
broker 2
topic2-part2
topic2-part1
logs
broker 3
topic1-part1
logs
broker 4
topic1-part2
topic2-part2 topic1-part1 topic1-part2
topic2-part1
topic2-part2
topic2-part1
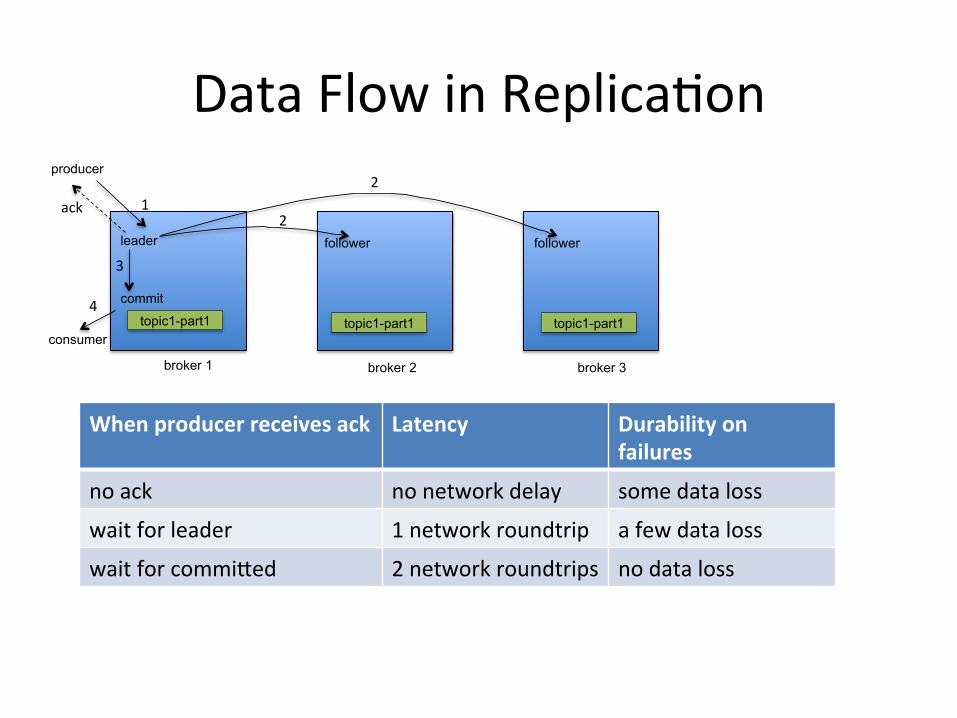
Data Flow in Replica)on
broker 1
producer
leader
broker 2
follower
broker 3
follower
4
2
2
3
commit
ack
When producer receives ack Latency Durability on failures
no ack no network delay some data loss
wait for leader 1 network roundtrip a few data loss
wait for commiIed 2 network roundtrips no data loss
topic1-part1 topic1-part1 topic1-part1 consumer
1

Extend to Mul)ple Par))ons
Leaders are evenly spread among brokers
broker 1 broker 2
topic3-part1 follower
broker 3
topic3-part1 follower
topic1-part1
producer
leader
topic1-part1
follower
topic1-part1
follower
broker 4
topic3-part1 leader
producer topic2-part1
producer
leader
topic2-part1
follower
topic2-part1
follower

Agenda
• Why people use Ka1a • Technical overview of Ka1a • What’s coming

Stream Data Plaborm

Future Releases of Apache Ka1a • New java consumer client
– BeIer performance – Easier protocol for non-‐java client
• Security – Authen)ca)on: SSL and Kerberos – Authoriza)on
• BeIer cluster management – More automated tools – Quotas
• Transac)onal support – Exactly once delivery

Confluent
• Mission: Make stream data plaborm a reality • Ka1a development and support • Product:
– Metadata management (released) – Rest endpoint (released) – Connectors for common systems – Monitor data flow end-‐to-‐end – Stream processing integra)on

Q&A
• More info on Apache Ka1a – hIp://ka1a.apache.org/
• Confluent – hIp://confluent.io – hIp://confluent.io/careers
• Ka1a meetup tonight at 6:30 (Texas V)
![HEJ99 Kaa Iyesus (Caa Iesus) (church), 12/37 [+ WO Gu] filekaa (O) 1. having great fervour; 2. toasted and pounded coffee; kea (T) and, also HEJ99 Kaa Iyesus (Caa Iesus) (church),](https://static.fdocuments.in/doc/165x107/5ca2007088c9932f098d43a2/hej99-kaa-iyesus-caa-iesus-church-1237-wo-gu-o-1-having-great-fervour.jpg)

![KAA 505 – Separation Techniques [Kaedah Pemisahan]web.usm.my/chem/pastyear/files/KAA505_Sem2_2008_2009.pdf · KAA 505 – Separation Techniques [Kaedah Pemisahan] ... Apakah parameter](https://static.fdocuments.in/doc/165x107/5c812ed009d3f2c3348c179f/kaa-505-separation-techniques-kaedah-pemisahanwebusmmychempastyearfileskaa505sem220082009pdf.jpg)











![KAA 501 Quality Control In Chemistry [Kawalan Mutu …web.usm.my/chem/pastyear/files/KAA501_Sem1_2011_2012_BI.pdf · KAA 501 – Quality Control In Chemistry [Kawalan Mutu Dalam Kimia]](https://static.fdocuments.in/doc/165x107/5ad72eb27f8b9a98098c6cfb/kaa-501-quality-control-in-chemistry-kawalan-mutu-webusmmychempastyearfileskaa501sem120112012bipdfkaa.jpg)



