
IntEx: A Syntactic Role Driven Protein-Protein Interaction Extractor for Bio-Medical Text Syed...
28
IntEx: A Syntactic Role Driven Protein-Protein Interaction Extractor for Bio-Medical Text Syed Toufeeq Ahmed Deepthi Chidambaram Hasan Davulcu Chitta Baral
-
date post
19-Dec-2015 -
Category
Documents
-
view
219 -
download
0
Transcript of IntEx: A Syntactic Role Driven Protein-Protein Interaction Extractor for Bio-Medical Text Syed...

IntEx: A Syntactic Role Driven Protein-Protein Interaction Extractor for Bio-Medical Text
Syed Toufeeq Ahmed
Deepthi Chidambaram
Hasan Davulcu
Chitta Baral

Outline
Introduction Issues and Challenges Our Approach (IntEx System) Evaluation Future Work Conclusion Demo

Introduction
Genomic Research in the last decade has resulted in humongous amount of data, and most of these findings are in form of free text.
PubMed/ MedLine has around 12 millions abstracts online.
An automated tool to extract information from free text (bio-medical) will be of great use to researchers (biologists).

Issues that make extraction difficult (Seymore, McCallum et al.1999) The task involves free text – hence there are
many ways of stating the same fact. The genre of text is not grammatically simple. The text includes a lot of technical
terminology unfamiliar to existing natural language processing systems.
Information may need to be combined across several sentences.
There are many sentences from which nothing should be extracted.

Challenges
Interactions specified in different ways
1. HMBA inhibits MEC-1 cell proliferation.
2. GBMs commonly overexpress the oncogenes EGFR and PDGFR, and contain mutations and deletions of tumor suppressor genes PTEN and TP53.
3. Protein kinase B (PKB) has emerged as the focal point for many signal transduction pathways, regulating multiple cellular processes such as glucose metabolism, transcription, apoptosis, cell proliferation, angiogenesis, and cell motility.

Challenges (cont.)
Anaphora resolution Pronominals – “It activates HMBA”. Sortal anaphora – “Both enzymes are phosphorylated”. Event anaphora – “This reaction acts in a mediated
environment.”
Multiple interactions in Complex sentences
Most of the tumor-suppressive properties of Pten are dependent on its lipid phosphatase activity, which inhibits the phosphatidylinositol-3'-kinase (PI3K)/Akt signaling pathway through dephosphorylation of phosphatidylinositol-(3,4,5)-triphosphate

Our Approach (IntEx System)
Identify syntactic roles, such as Subject, Object , Verb and modifiers of a sentence.
Using these syntactic roles, transform complex sentences into multiple simple clauses.
Extract Protein-Protein interactions from these simple clausal structures.
Simple Pronoun resolution to identify references across multiple sentences.
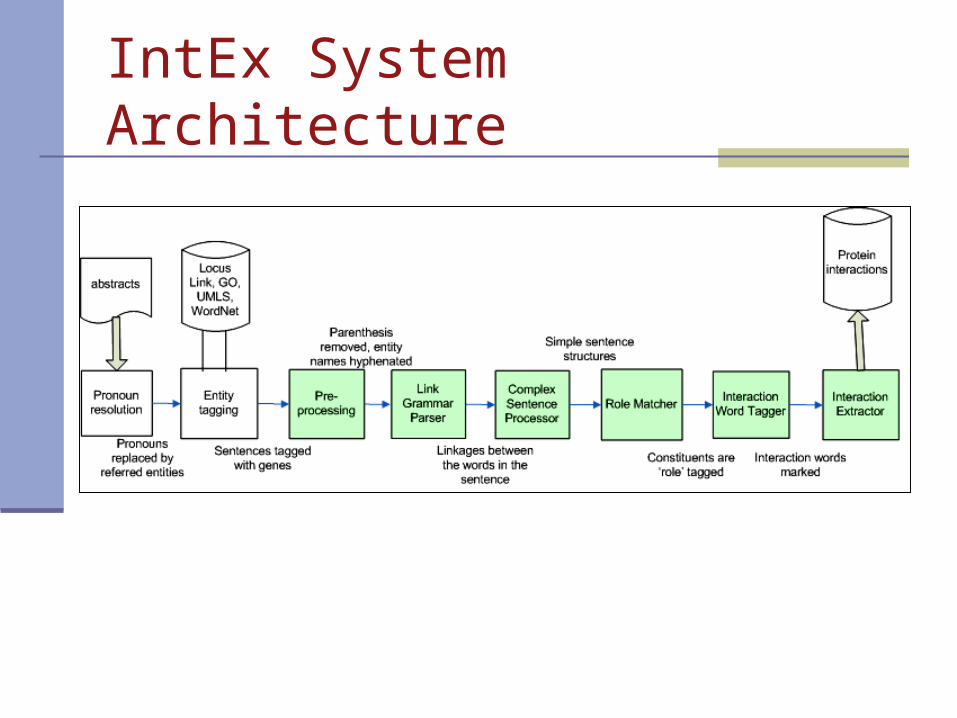
IntEx System Architecture

IntEx System Components
Pronoun Resolution Tagging: tagging biological entities with the
help of biomedical and linguistic gazetteers. Complex Sentence Processing: splitting
complex sentences into simple clausal structures made of up syntactic roles.
Interaction Extractor: extracting complete interactions by analyzing the matching contents of syntactic roles and their linguistically significant combinations.

Pronoun Resolution
Ku loads onto dsDNA ends and it can diffuse along the DNA in an energy-independent manner.
Ku loads onto dsDNA ends and Ku can diffuse along the DNA in an
energy-independent manner.
Pronouns in abstracts – third person - It, itself, them, themselves.
Replace pronouns with first noun group that matches the Person/number agreement.

Tagging
Dictionary lookup using gene/protein gazetteers from UMLS, LocusLink etc..
To tag new gene names, we used regular expressions (alpha numeric names, combination of lower case and upper case characters etc..).
Some heuristics like using proper nouns, NP chunking to improve recall.
‘Interaction word’ list is derived from UMLS and WordNet.

Complex Sentence Processing
Upon growth factor stimulation of quiescent cells, Gene100 declineslate in Gene101 and Gene102 is replaced by Gene103, which is absent
in quiescent cells.
Upon growth factor stimulation of quiescent cells, Gene100 declines
late in Gene101.
Gene102 is replaced by Gene103.
Gene103 is absent in quiescent cells.

Complex Sentence Processing
Verb-based approach. Identify clauses in complex sentences using Link
Grammar Linkages Build simple clause sentences from them (for
each main verb) in the following Clause Format: Subject | Verb | Object | Modifying phrase

Link Grammar Parser(Sleator, D. and D. Temperley ,1993)
Sentence: “The cat chased a snake”
Link Grammar Representation:

Interaction Extractor: Role Type Matching
Role Type Description
Elementary If the role contains a Protein name or an interaction word.
Partial If the role has a Protein name and an interaction word.
Complete If the role has at least two Protein names and an interaction word.
Various syntactic roles (such as Subject , Object and Modifying phrase) and their linguistically significant combinations makes up roles

Roles: Examples
Elementary(Subject) Elementary
(Object)
Partial(Modifying Phrase)
“HMBA could inhibit the MEC-1 cell proliferation by down-regulation of PCNA expression.”
Interaction(Verb)

Interaction Extractor Algorithm
complete (G,I,G) interact: {G,I,G}
complete (G,I,G) interact: {G,I,G}
complete (G,I,G) interact: {G,I,G}
Elementary (G1) Elementary (G2)
Is Main Verb
an Interaction (I)
?
Interaction : { G1, I, G2 }
Partial (I,G2)
Interaction : { G1, I, G2 }
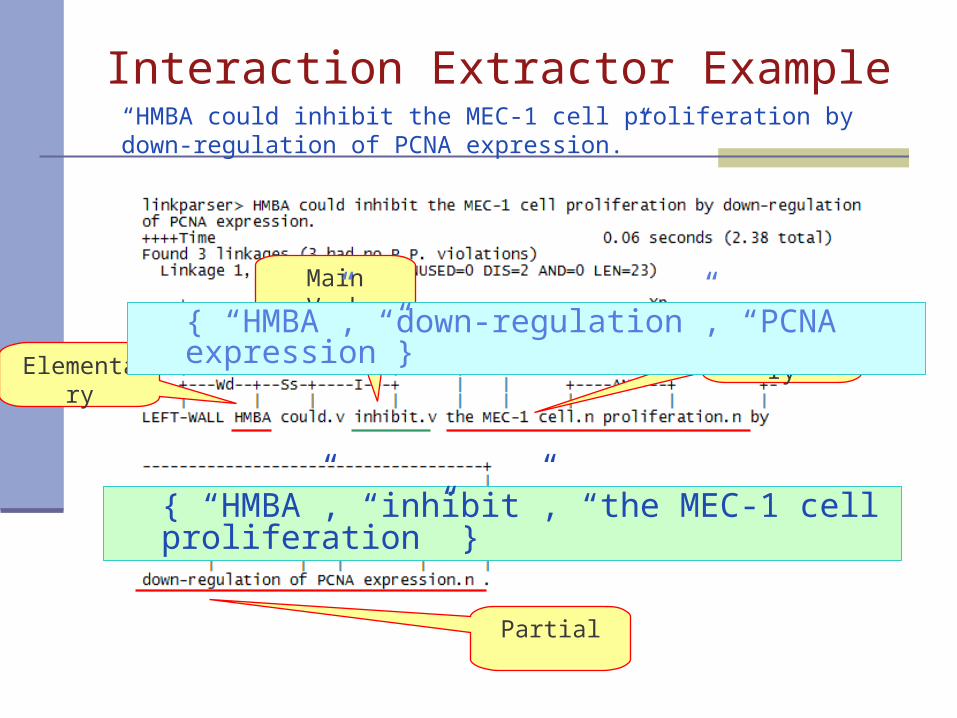
Interaction Extractor Example
ElementaryElementary
Partial
“HMBA could inhibit the MEC-1 cell proliferation by down-regulation of PCNA expression.”
Main Verb
{ “HMBA”, “inhibit”, “the MEC-1 cell proliferation” }
{ “HMBA”, “down-regulation”, “PCNA expression”}

A Detailed Overall Example
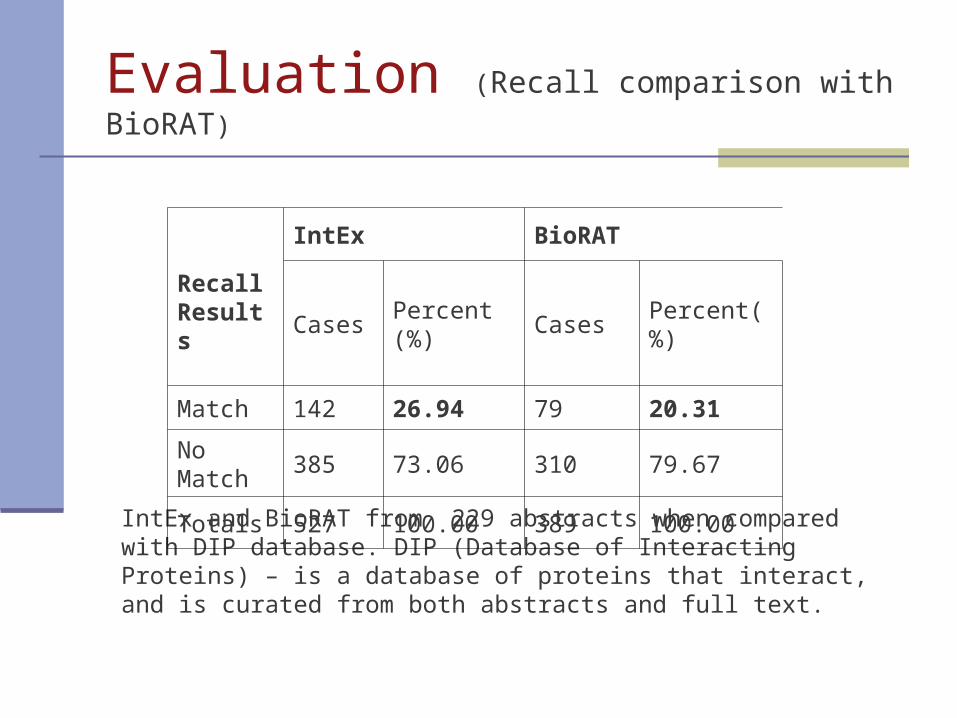
Evaluation (Recall comparison with BioRAT)
IntEx and BioRAT from 229 abstracts when compared with DIP database. DIP (Database of Interacting Proteins) – is a database of proteins that interact, and is curated from both abstracts and full text.
RecallResults
IntEx BioRAT
Cases Percent (%) Cases Percent(%)
Match 142 26.94 79 20.31
No Match 385 73.06 310 79.67
Totals 527 100.00 389 100.00
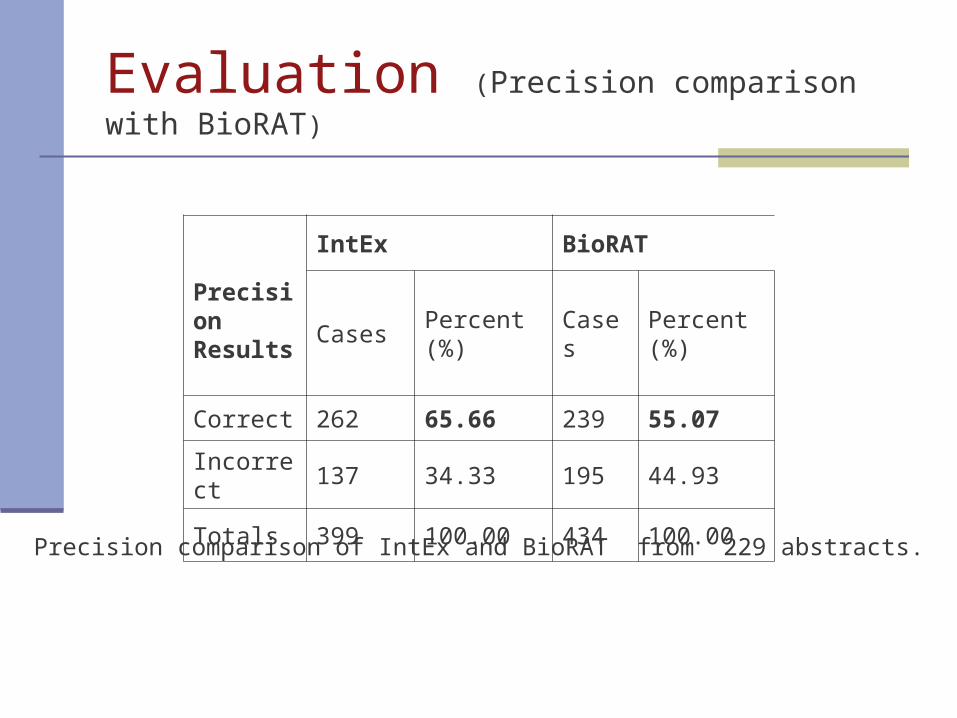
Evaluation (Precision comparison with BioRAT)
Precision Results
IntEx BioRAT
Cases Percent (%) Cases Percent (%)
Correct 262 65.66 239 55.07
Incorrect 137 34.33 195 44.93
Totals 399 100.00 434 100.00
Precision comparison of IntEx and BioRAT from 229 abstracts.
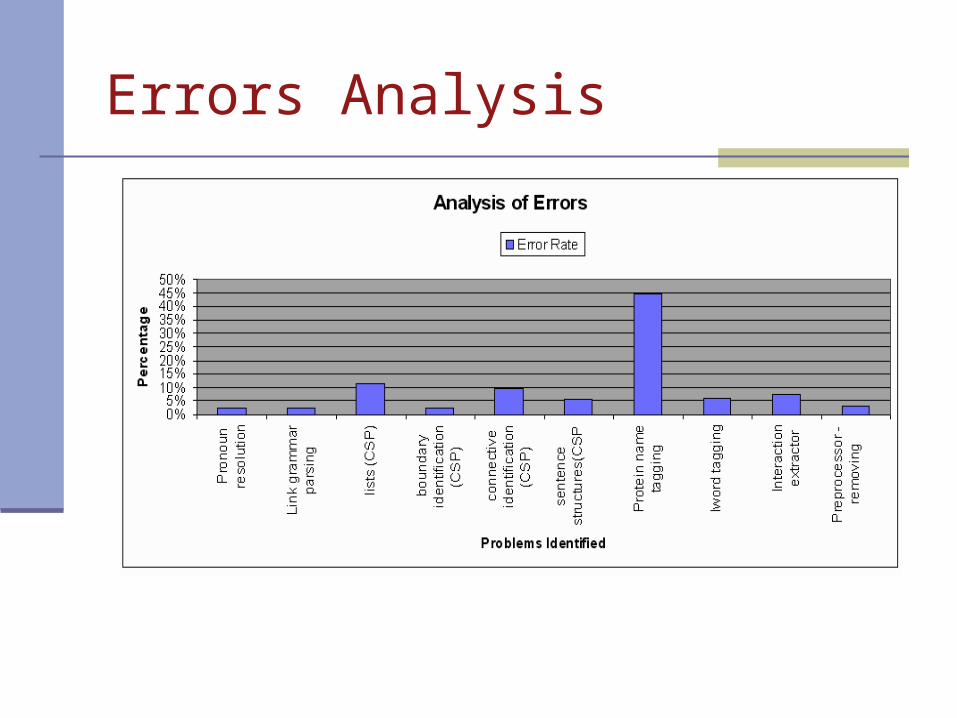
Errors Analysis

Future Work in Interaction Extraction
Handling negations in the sentences (such as “not interact”, “fails to induce”, “does not inhibit”).
Extraction of detailed contextual attributes of interactions (such as bio-chemical context or location) by interpreting modifiers:
Location/Position modifiers (in, at, on, into, up, over…) Agent/Accompaniment modifiers (by, with…) Purpose modifiers( for…) Theme/association modifiers ( of..)
Extraction of relationships between interactions from among multiple sentences within and across abstracts/full text articles. (Protein Interaction Pathways)

A bigger future: combining automated extraction with mass collaboration `Curation’ is expensive. Automated extraction – miles to go Vision: automated extraction with mass
curation The CBioC system: www.cbioc.org

Conclusion
Verb-based approach to extract protein-protein interactions
Handles complex sentences Easy to scale up , and to use in other
domains (we are working on it to use on other domains too).
Protein name tagging needs improvement, and we are working on using other methods.
First release version is almost ready for both Windows and Linux platforms.

References
Link Grammar: http://www.link.cs.cmu.edu/link
LocusLink (Now Entrez Gene):
http://www.ncbi.nlm.nih.gov/LocusLink
UMLS:http://www.nlm.nih.gov/research/umls/umlsmain.html

References (cont.)
Blaschke, C., M. A. Andrade, et al. (1999). "Automatic extraction of biological information from scientific text: Protein-protein interactions." Proceedings of International Symposium on Molecular Biology: 60-67.
Corney, D. P. A., B. F. Buxton, et al. (2004). "BioRAT: extracting biological information from full-length papers." Bioinformatics 20(17): 3206-3213.
Friedman, C., P. Kra, et al. (2001). GENIES: a natural-language processing system for the extraction of molecular pathways from journal articles. Proceedings of the International Confernce on Intelligent Systems for Molecular Biology: 574-82.
Rzhetsky, A., I. Iossifov, et al. (2004). "GeneWays: a system for extracting, analyzing, visualizing, and integrating molecular pathway data." J. of Biomedical Informatics 37(1): 43--53.
Seymore, K., A. McCallum, et al. (1999). Learning hidden markov model structure for information extraction. AAAI 99 Workshop on Machine Learning for Information Extraction
Sleator, D. and D. Temperley (1993). Parsing English with a Link Grammar. Third International Workshop on Parsing Technologies.

Thank you !


















