
Interconnecting Future DoE leadership systems · •Every feature is software controlled •...
53
Rich Graham HPC Advisory Council, Stanford, 2015 Interconnecting Future DoE leadership systems
Transcript of Interconnecting Future DoE leadership systems · •Every feature is software controlled •...

Rich Graham
HPC Advisory Council, Stanford, 2015
Interconnecting Future DoE leadership systems

© 2014 Mellanox Technologies 2 HPC Advisory Council, Europe 2014
HPC The Challenges

© 2014 Mellanox Technologies 3 HPC Advisory Council, Europe 2014
Proud to Accelerate Future DOE Leadership Systems (“CORAL”)
“Summit” System “Sierra” System
5X – 10X Higher Application Performance versus Current Systems
Mellanox EDR 100Gb/s InfiniBand, IBM POWER CPUs, NVIDIA Tesla GPUs
Mellanox EDR 100G Solutions Selected by the DOE for 2017 Leadership Systems
Deliver Superior Performance and Scalability over Current / Future Competition

© 2014 Mellanox Technologies 4 HPC Advisory Council, Europe 2014
Exascale-Class Computer Platforms – Communication Challenges
Challenge Solution focus
Very large functional unit count ~10M Scalable communication capabilities: point-to-
point & collectives
Scalable Network: Adaptive routing
Large on-”node” functional unit count ~500 Scalable HCA architecture
Deeper memory hierarchies Cache aware network access
Smaller amounts of memory per functional unit Low latency, high b/w capabilities
May have functional unit heterogeneity Support for data heterogeneity
Component failures part of “normal” operation Resilient and redundant stack
Data movement is expensive Optimize data movement
Independent remote progress Independent hardware progress
Power costs Power aware hardware

© 2014 Mellanox Technologies 5 HPC Advisory Council, Europe 2014
Standardize your Interconnect
© 2014 Mellanox Technologies 6 HPC Advisory Council, Europe 2014
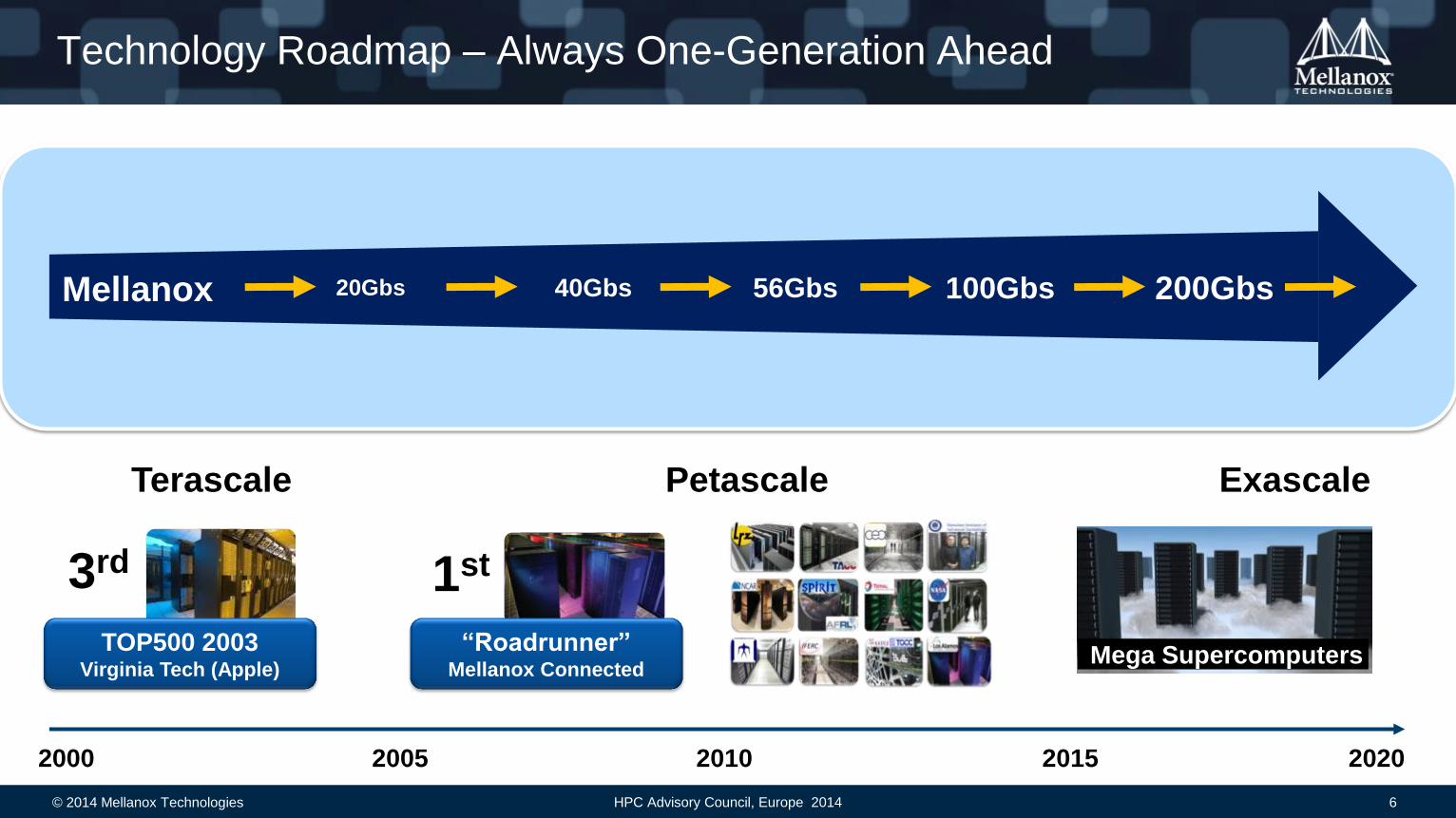
Technology Roadmap – Always One-Generation Ahead
2000 2020 2010 2005
20Gbs 40Gbs 56Gbs 100Gbs
“Roadrunner” Mellanox Connected
1st 3rd
TOP500 2003 Virginia Tech (Apple)
2015
200Gbs
Mega Supercomputers
Terascale Petascale Exascale
Mellanox

© 2014 Mellanox Technologies 7 HPC Advisory Council, Europe 2014
At the Speed of 100Gb/s!
Enter the World of Scalable Performance
The Future is Here

© 2014 Mellanox Technologies 8 HPC Advisory Council, Europe 2014
The Future is Here
Copper (Passive, Active) Optical Cables (VCSEL) Silicon Photonics
36 EDR (100Gb/s) Ports, <90ns Latency
Throughput of 7.2Tb/s
Entering the Era of 100Gb/s
100Gb/s Adapter, 0.7us latency
150 million messages per second
(10 / 25 / 40 / 50 / 56 / 100Gb/s)

© 2014 Mellanox Technologies 9 HPC Advisory Council, Europe 2014
Enter the World of Scalable Performance – 100Gb/s Switch
Store Analyze
7th Generation InfiniBand Switch
36 EDR (100Gb/s) Ports, <90ns Latency
Throughput of 7.2 Tb/s
InfiniBand Router
Adaptive Routing
Switch-IB: Highest Performance Switch in the Market

© 2014 Mellanox Technologies 10 HPC Advisory Council, Europe 2014
Enter the World of Scalable Performance – 100Gb/s Adapter
Connect. Accelerate. Outperform
ConnectX-4: Highest Performance Adapter in the Market
InfiniBand: SDR / DDR / QDR / FDR / EDR
Ethernet: 10 / 25 / 40 / 50 / 56 / 100GbE
100Gb/s, <0.7us latency
150 million messages per second
OpenPOWER CAPI technology
CORE-Direct technology
GPUDirect RDMA
Dynamically Connected Transport (DCT)
Ethernet offloads (HDS, RSS, TSS, LRO, LSOv2)
© 2014 Mellanox Technologies 11 HPC Advisory Council, Europe 2014
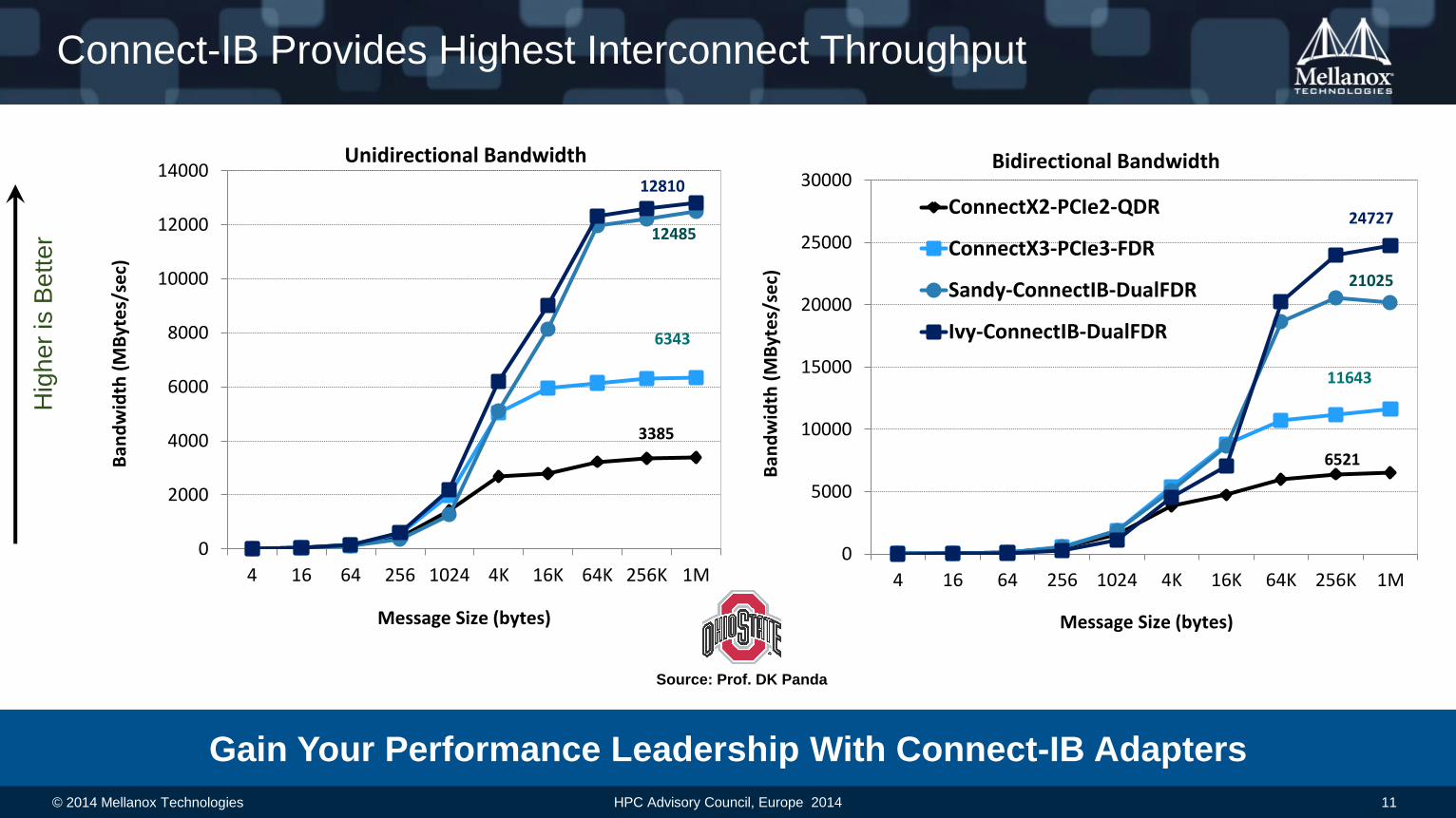
Connect-IB Provides Highest Interconnect Throughput
Source: Prof. DK Panda
Hig
he
r is
Be
tte
r
Gain Your Performance Leadership With Connect-IB Adapters
0
2000
4000
6000
8000
10000
12000
14000
4 16 64 256 1024 4K 16K 64K 256K 1M
Unidirectional Bandwidth
Ban
dw
idth
(M
Byt
es/
sec)
Message Size (bytes)
3385
6343
12485
12810
0
5000
10000
15000
20000
25000
30000
4 16 64 256 1024 4K 16K 64K 256K 1M
ConnectX2-PCIe2-QDR
ConnectX3-PCIe3-FDR
Sandy-ConnectIB-DualFDR
Ivy-ConnectIB-DualFDR
Bidirectional Bandwidth
Ban
dw
idth
(M
Byt
es/
sec)
Message Size (bytes)
11643
6521
21025
24727
© 2014 Mellanox Technologies 12 HPC Advisory Council, Europe 2014
Standard !
Standardized wire protocol
• Mix and match of vertical and horizontal components
• Ecosystem – build together
Open-source, extensible interfaces
• Extend and optimize per applications needs
© 2014 Mellanox Technologies 13 HPC Advisory Council, Europe 2014
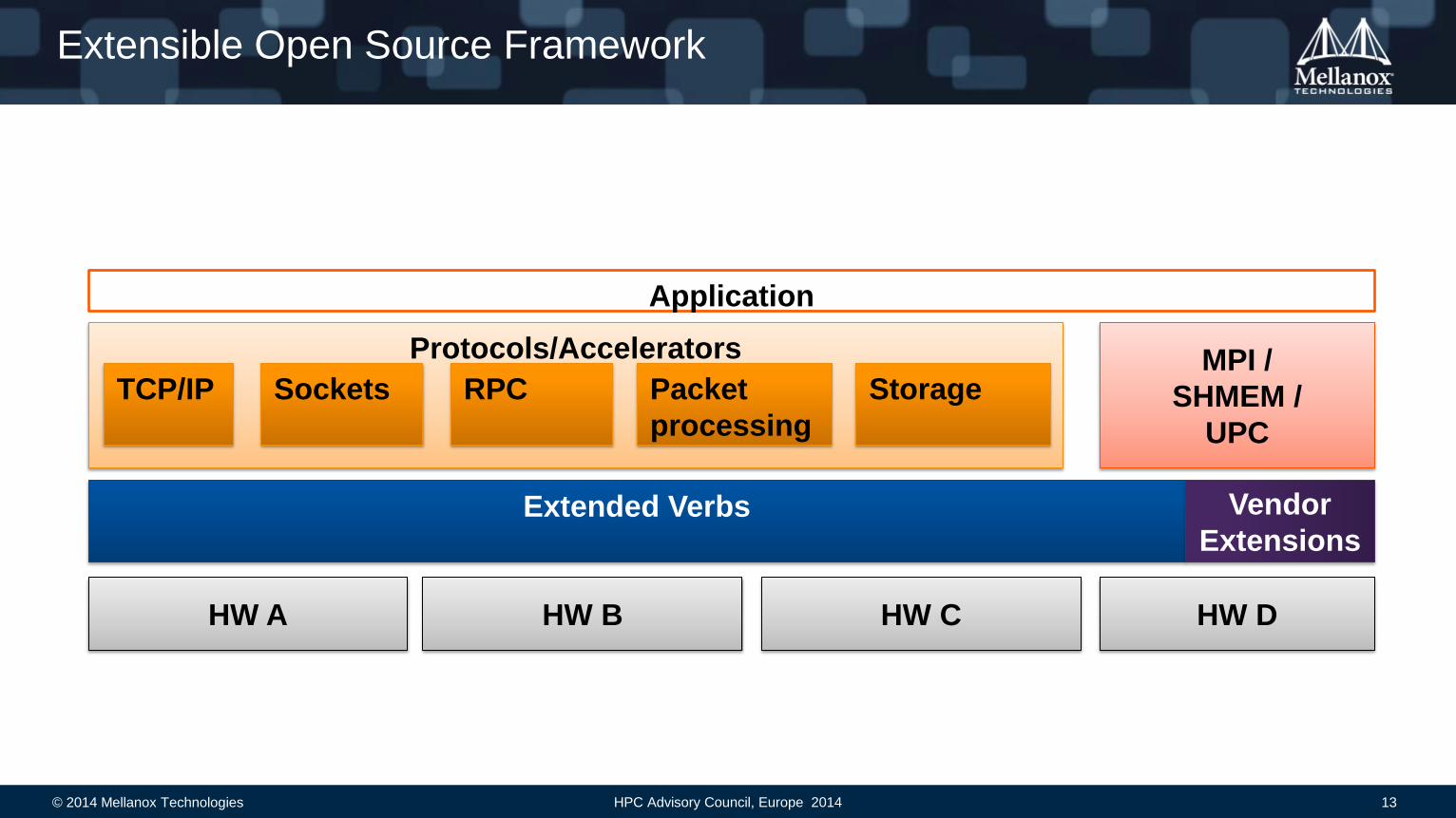
Protocols/Accelerators
Extensible Open Source Framework
HW A HW B HW C
Extended Verbs
TCP/IP Sockets RPC Packet
processing
Storage MPI /
SHMEM /
UPC
HW D
Vendor
Extensions
Application

© 2014 Mellanox Technologies 14 HPC Advisory Council, Europe 2014
Scalability
© 2014 Mellanox Technologies 15 HPC Advisory Council, Europe 2014
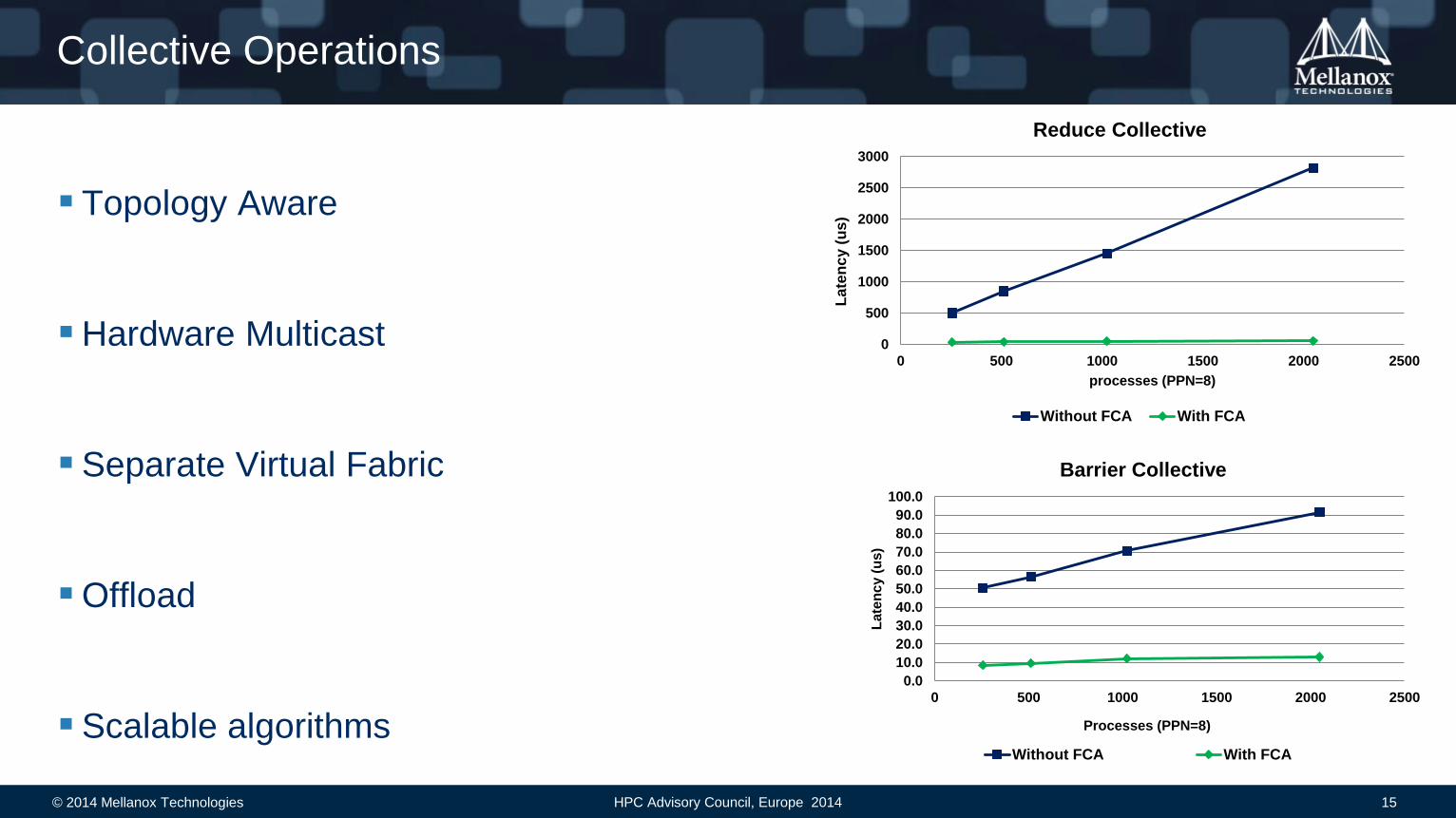
Collective Operations
Topology Aware
Hardware Multicast
Separate Virtual Fabric
Offload
Scalable algorithms
0.0
10.0
20.0
30.0
40.0
50.0
60.0
70.0
80.0
90.0
100.0
0 500 1000 1500 2000 2500
Late
nc
y (
us)
Processes (PPN=8)
Barrier Collective
Without FCA With FCA
0
500
1000
1500
2000
2500
3000
0 500 1000 1500 2000 2500
La
ten
cy (
us
)
processes (PPN=8)
Reduce Collective
Without FCA With FCA

© 2014 Mellanox Technologies 16 HPC Advisory Council, Europe 2014
16
The DC Model
Dynamic Connectivity
Each DC Initiator can be used to reach any remote DC Target
No resources’ sharing between processes
• process controls how many (and can adapt to load)
• process controls usage model (e.g. SQ allocation policy)
• no inter-process dependencies
Resource footprint
• Function of node and HCA capability
• Independent of system size
Fast Communication Setup Time
cs – concurrency of the sender
cr=concurrency of the responder
Pro
ce
ss
0
cs
p*(
cs+
cr)
/2
cr
Pro
ce
ss
1
cs
cr
Pro
ce
ss
p
-1
cs
cr
© 2014 Mellanox Technologies 17 HPC Advisory Council, Europe 2014
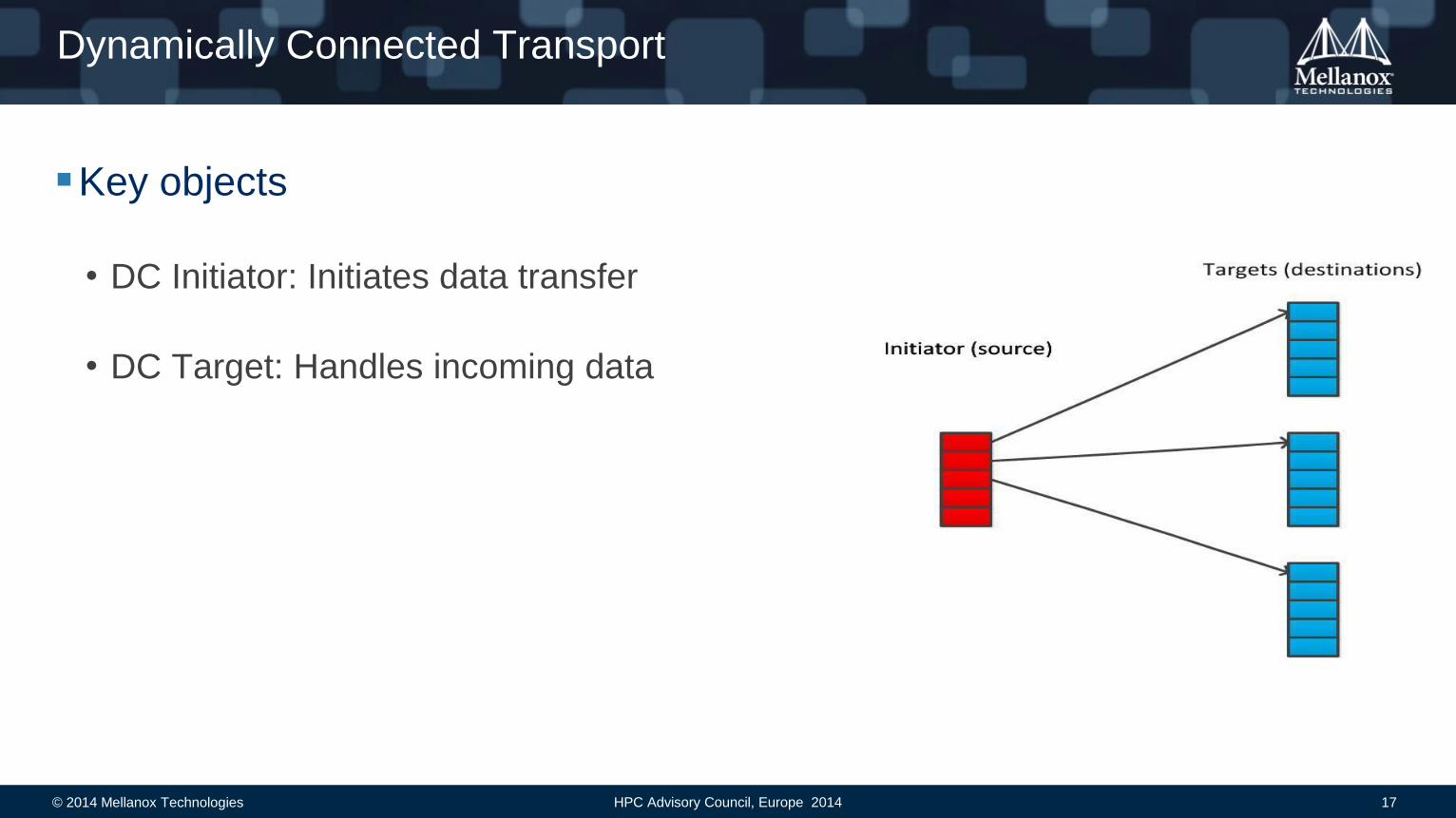
Dynamically Connected Transport
Key objects
• DC Initiator: Initiates data transfer
• DC Target: Handles incoming data
© 2014 Mellanox Technologies 18 HPC Advisory Council, Europe 2014
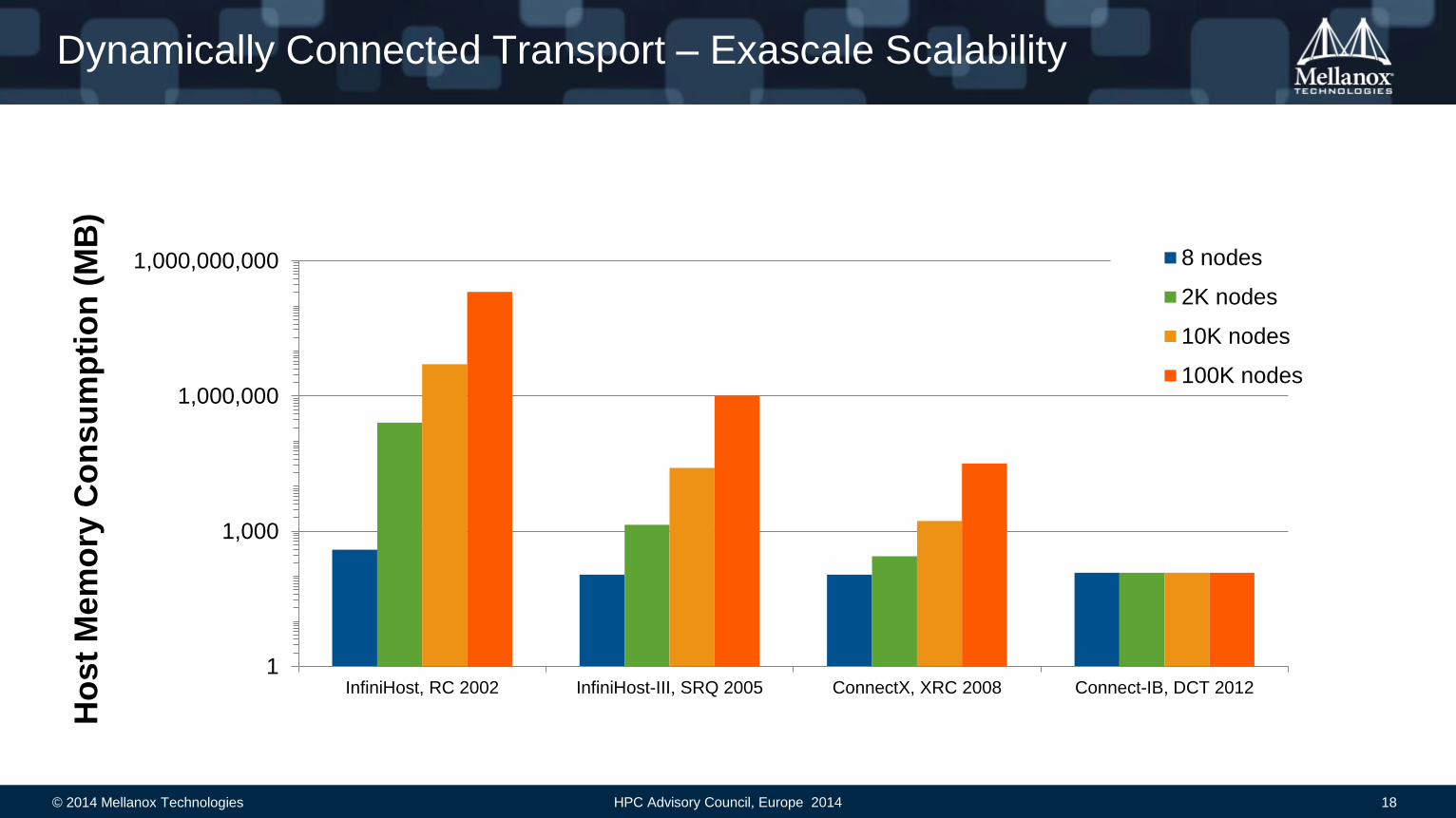
Dynamically Connected Transport – Exascale Scalability
1
1,000
1,000,000
1,000,000,000
InfiniHost, RC 2002 InfiniHost-III, SRQ 2005 ConnectX, XRC 2008 Connect-IB, DCT 2012
8 nodes
2K nodes
10K nodes
100K nodes
Ho
st
Me
mo
ry C
on
su
mp
tio
n (
MB
)
© 2014 Mellanox Technologies 19 HPC Advisory Council, Europe 2014
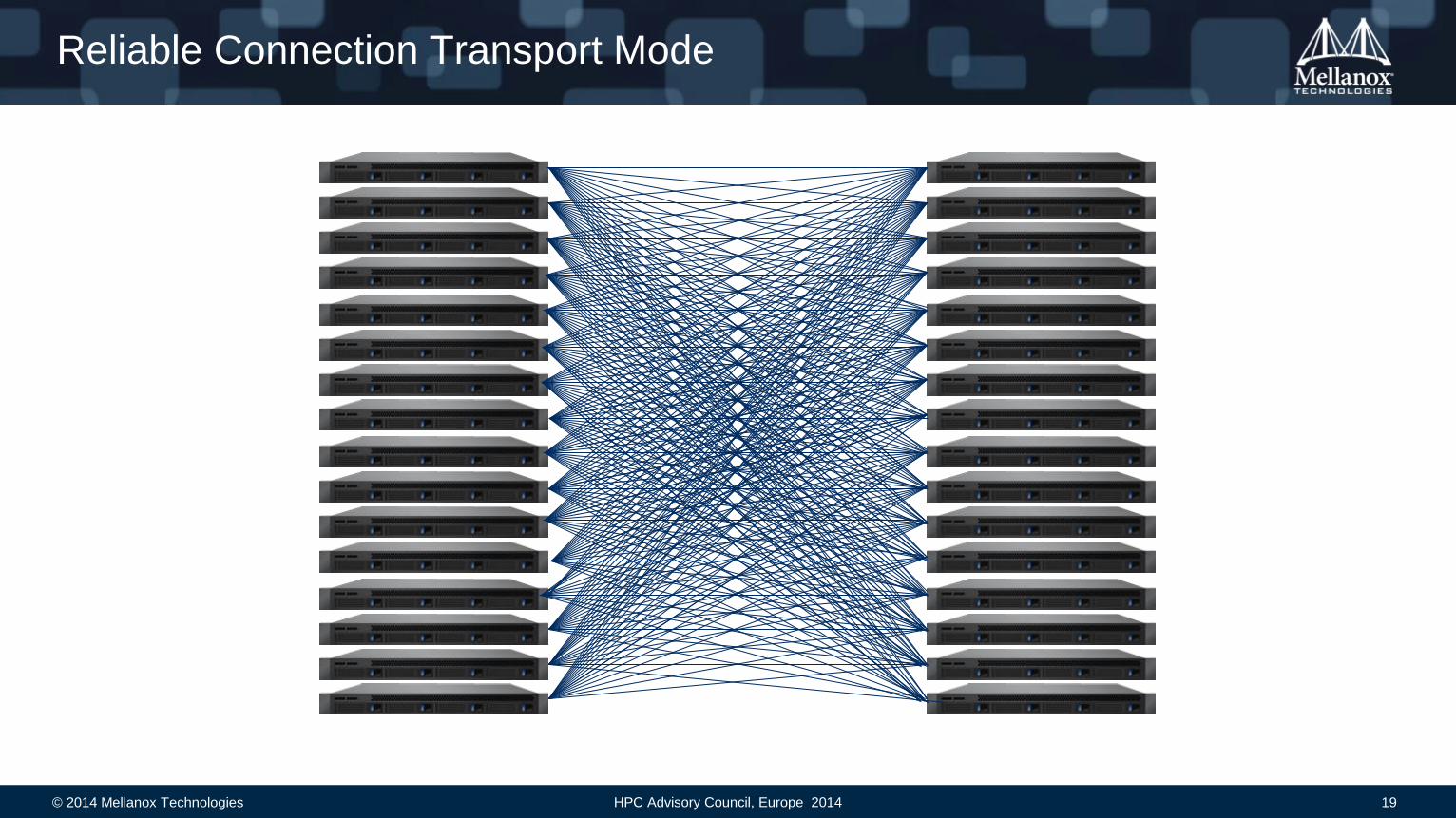
Reliable Connection Transport Mode
© 2014 Mellanox Technologies 20 HPC Advisory Council, Europe 2014
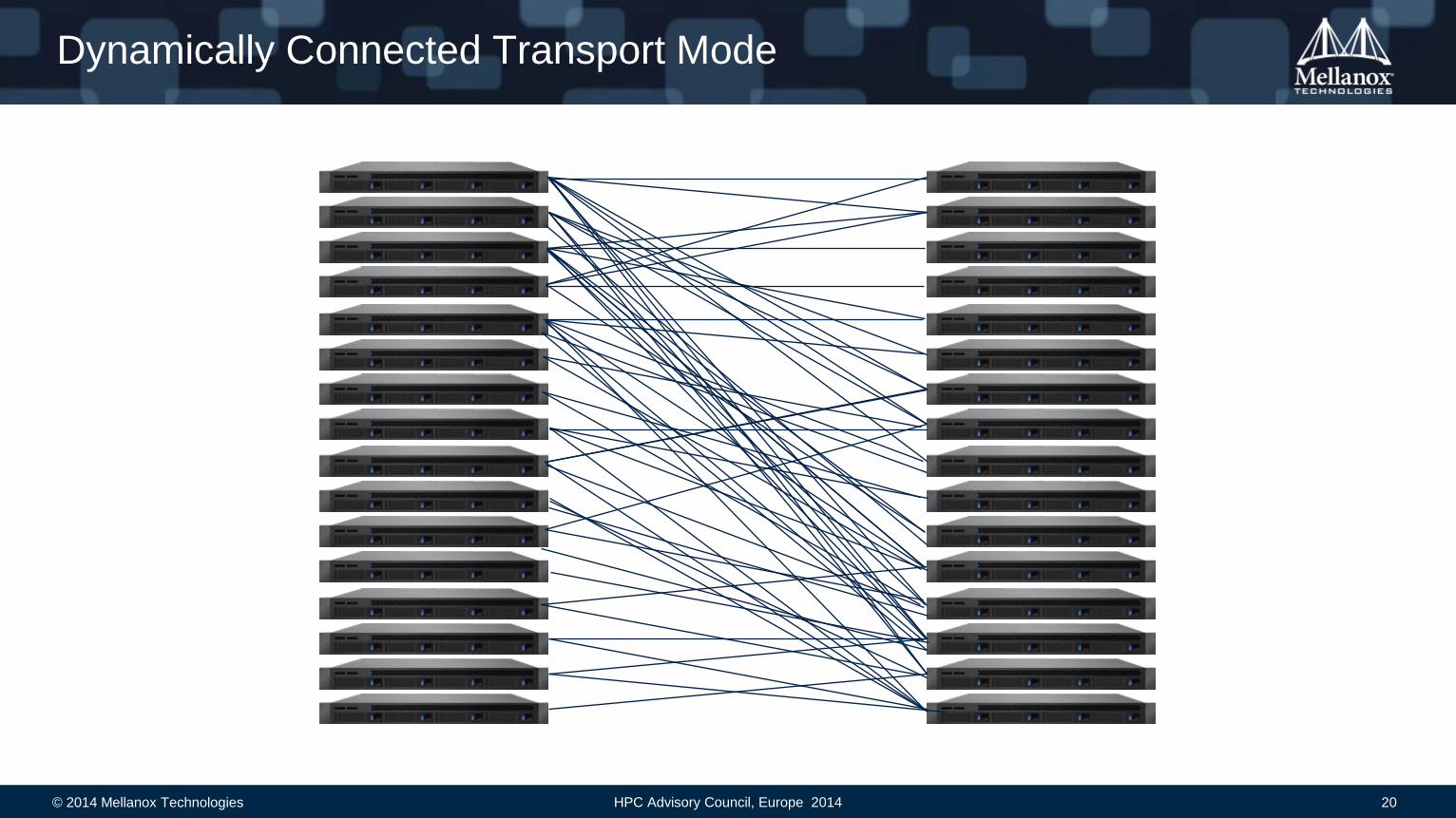
Dynamically Connected Transport Mode
© 2014 Mellanox Technologies 21 HPC Advisory Council, Europe 2014
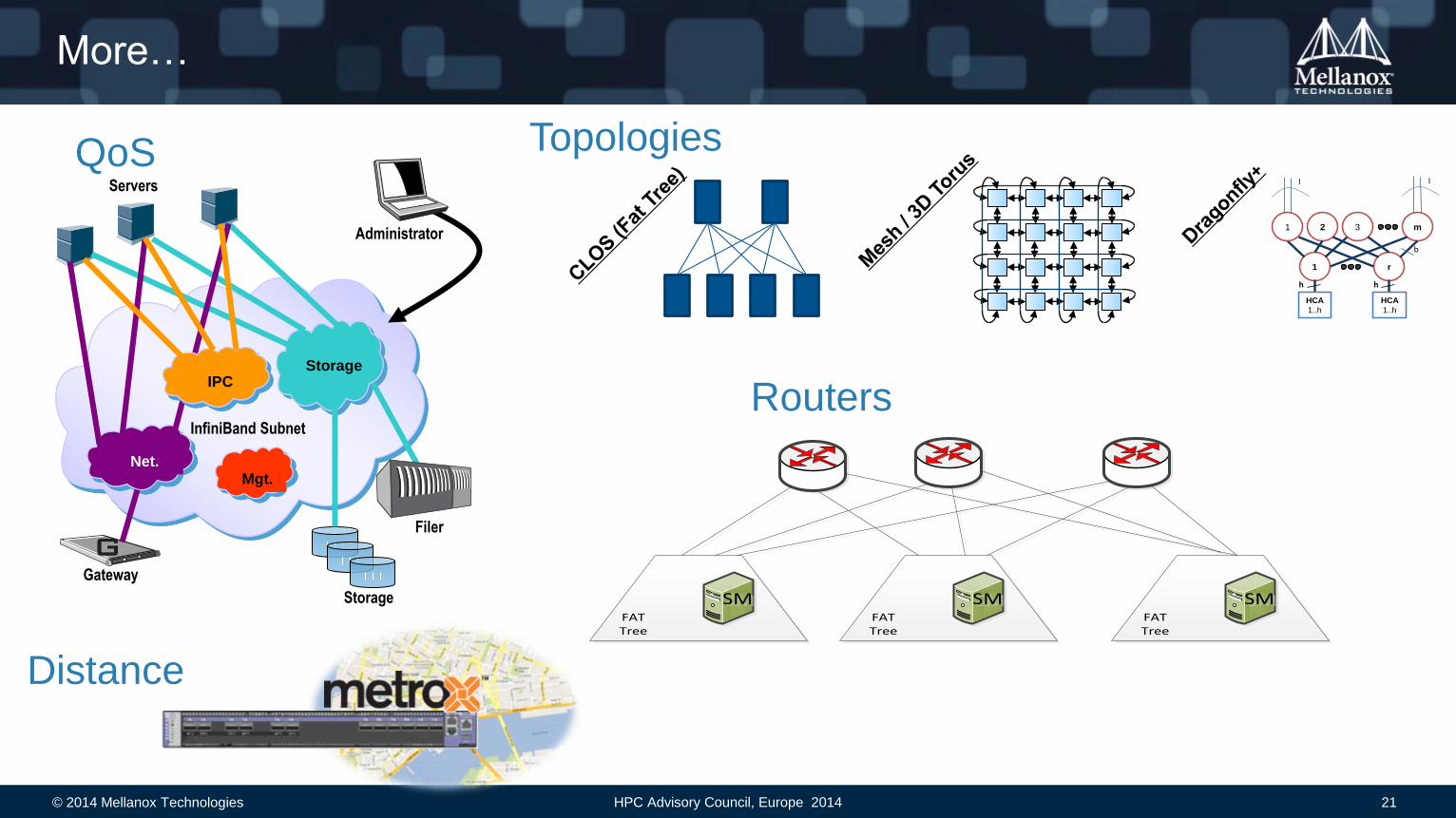
More…
l
r
3
1
2 m1
hh
l
HCA
1..h
HCA
1..h
b
Topologies
FAT Tree
SMSMFAT Tree
SMSMFAT Tree
SMSM
Routers
Administrator
Storage
Net.
IPC
Gateway
Mgt.
Servers
Filer
Storage
InfiniBand Subnet
QoS
Distance

© 2014 Mellanox Technologies 22 HPC Advisory Council, Europe 2014
Scalability Under Load

© 2014 Mellanox Technologies 23 HPC Advisory Council, Europe 2014
Adaptive Routing
Purpose
• Improved Network utilization: choose alternate routes on congestion
• Network resilience: Alternative routes on failure
Supported Hardware
• SwitchX-2
• Switch-IB: Adaptive routing notification added

© 2014 Mellanox Technologies 24 HPC Advisory Council, Europe 2014
Mellanox Adaptive Routing – Hardware Support
For every incoming packet the adaptive routing process has two main stages
• Route Change Decision (to adapt or not to adapt)
• New output port selection
Mellanox hardware is NOT topology specific
• SDN concept separates the configuration plane from the data plane
• Every feature is software controlled
• Fat-Tree, Dragonfly and Dragonfly+ are fully supported
• New hardware features introduced to support Dragonfly and Dragonfly+
© 2014 Mellanox Technologies 25 HPC Advisory Council, Europe 2014
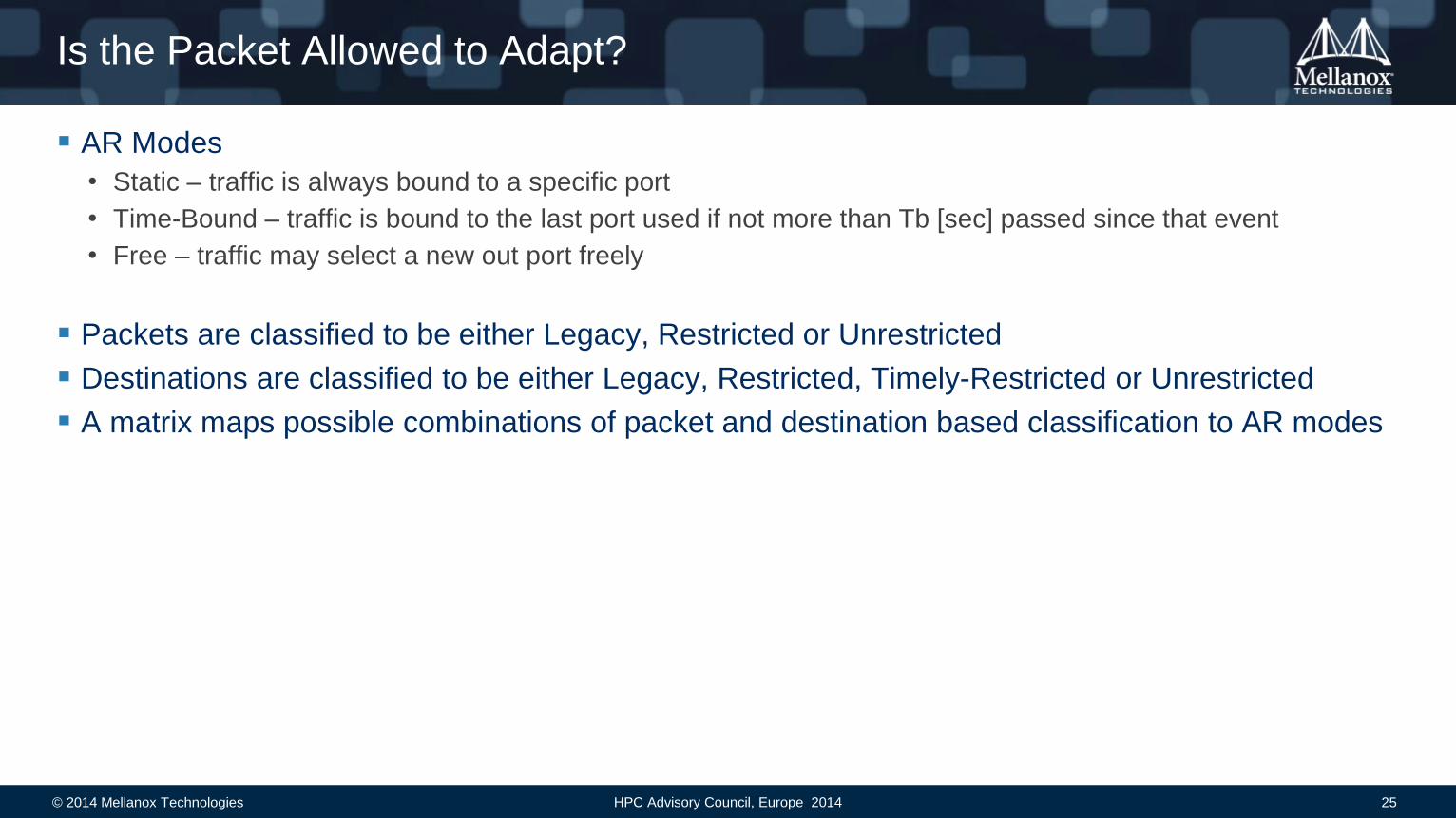
Is the Packet Allowed to Adapt?
AR Modes
• Static – traffic is always bound to a specific port
• Time-Bound – traffic is bound to the last port used if not more than Tb [sec] passed since that event
• Free – traffic may select a new out port freely
Packets are classified to be either Legacy, Restricted or Unrestricted
Destinations are classified to be either Legacy, Restricted, Timely-Restricted or Unrestricted
A matrix maps possible combinations of packet and destination based classification to AR modes
© 2014 Mellanox Technologies 26 HPC Advisory Council, Europe 2014
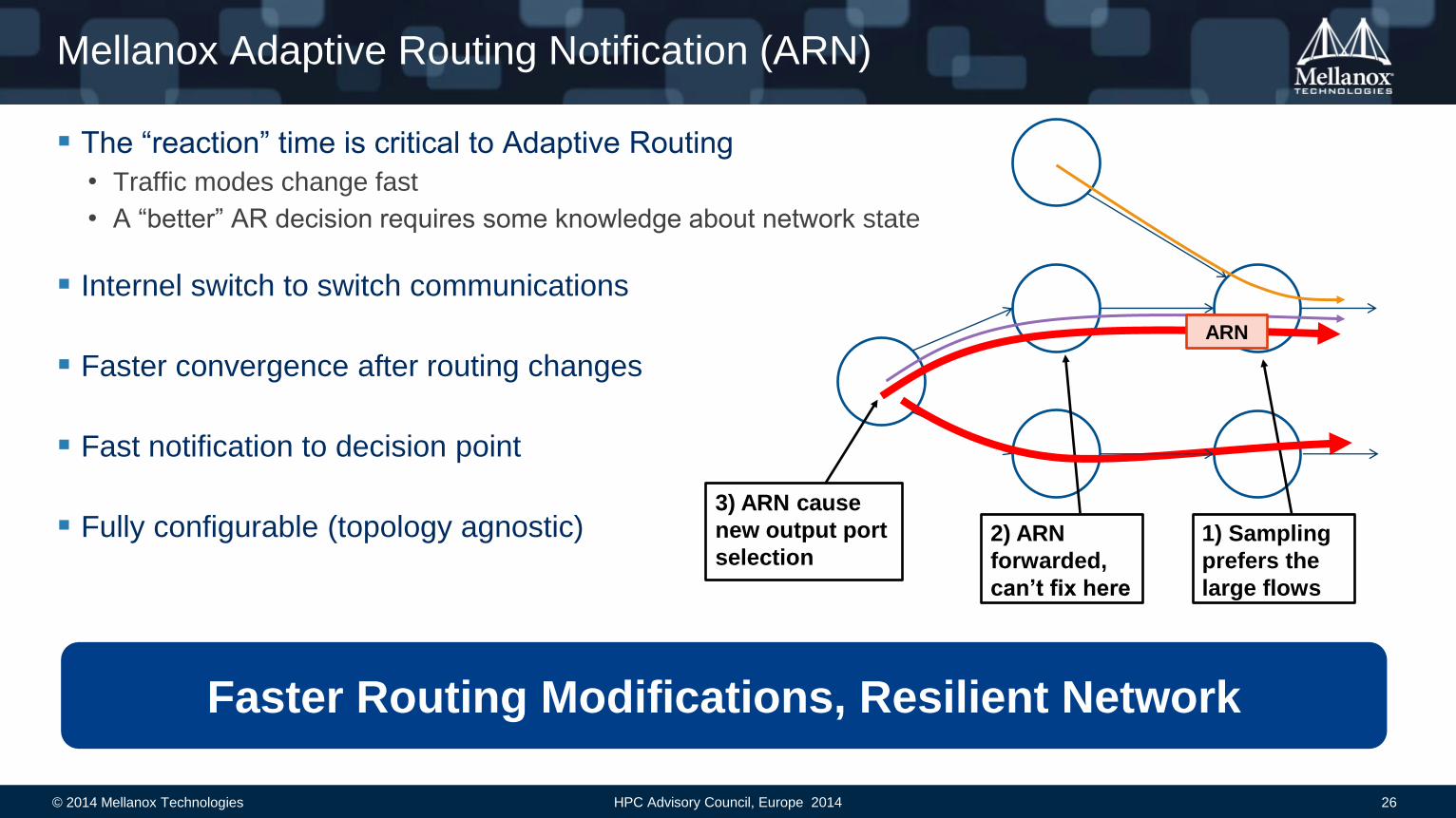
Mellanox Adaptive Routing Notification (ARN)
The “reaction” time is critical to Adaptive Routing
• Traffic modes change fast
• A “better” AR decision requires some knowledge about network state
Internel switch to switch communications
Faster convergence after routing changes
Fast notification to decision point
Fully configurable (topology agnostic) 1) Sampling
prefers the
large flows
ARN
3) ARN cause
new output port
selection 2) ARN
forwarded,
can’t fix here
Faster Routing Modifications, Resilient Network

© 2014 Mellanox Technologies 27 HPC Advisory Council, Europe 2014
Network Offload
© 2014 Mellanox Technologies 28 HPC Advisory Council, Europe 2014
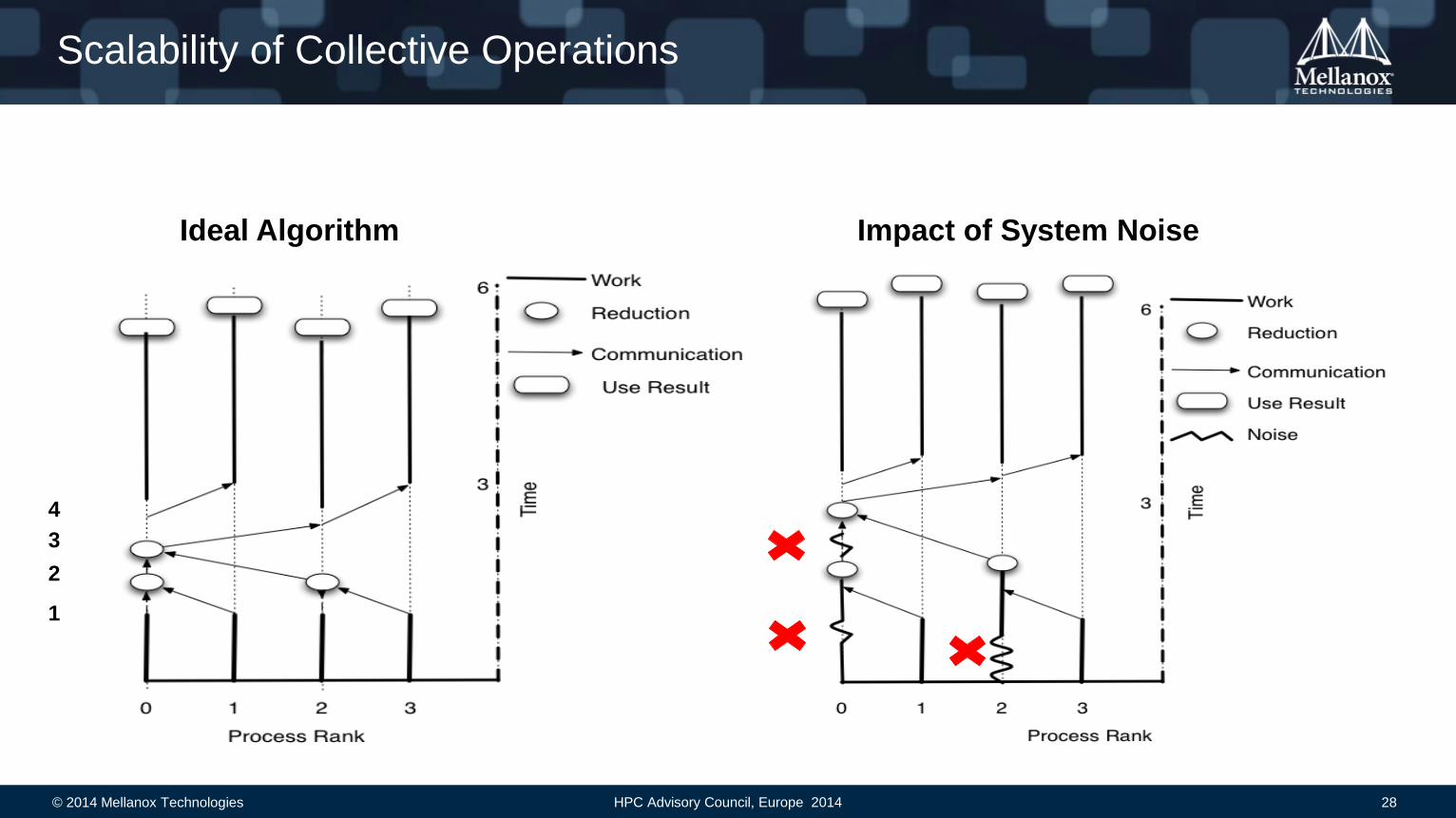
Scalability of Collective Operations
Ideal Algorithm Impact of System Noise
3
1
2
4
© 2014 Mellanox Technologies 29 HPC Advisory Council, Europe 2014
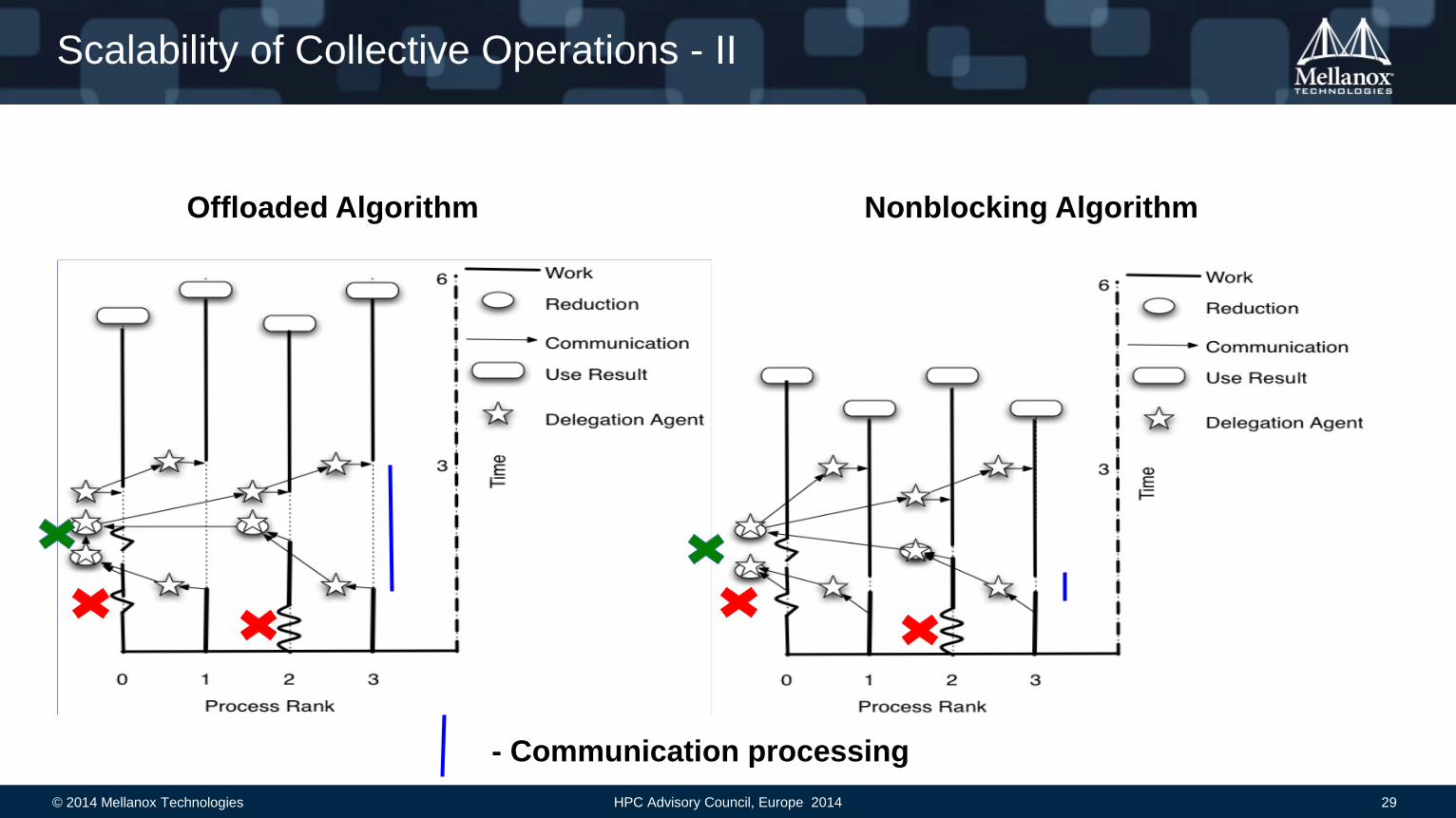
Scalability of Collective Operations - II
Offloaded Algorithm Nonblocking Algorithm
- Communication processing
© 2014 Mellanox Technologies 30 HPC Advisory Council, Europe 2014
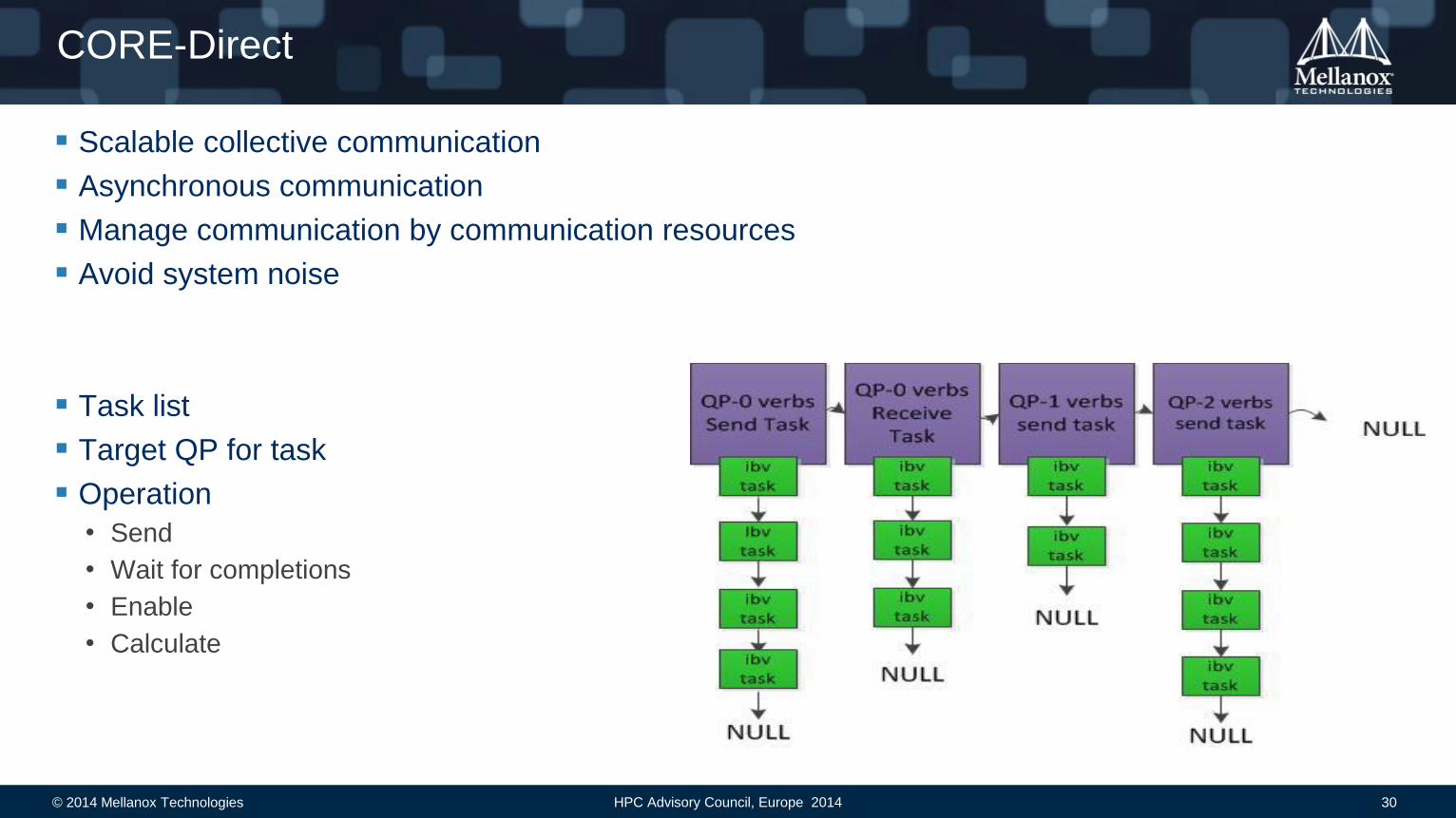
Scalable collective communication
Asynchronous communication
Manage communication by communication resources
Avoid system noise
Task list
Target QP for task
Operation
• Send
• Wait for completions
• Enable
• Calculate
CORE-Direct
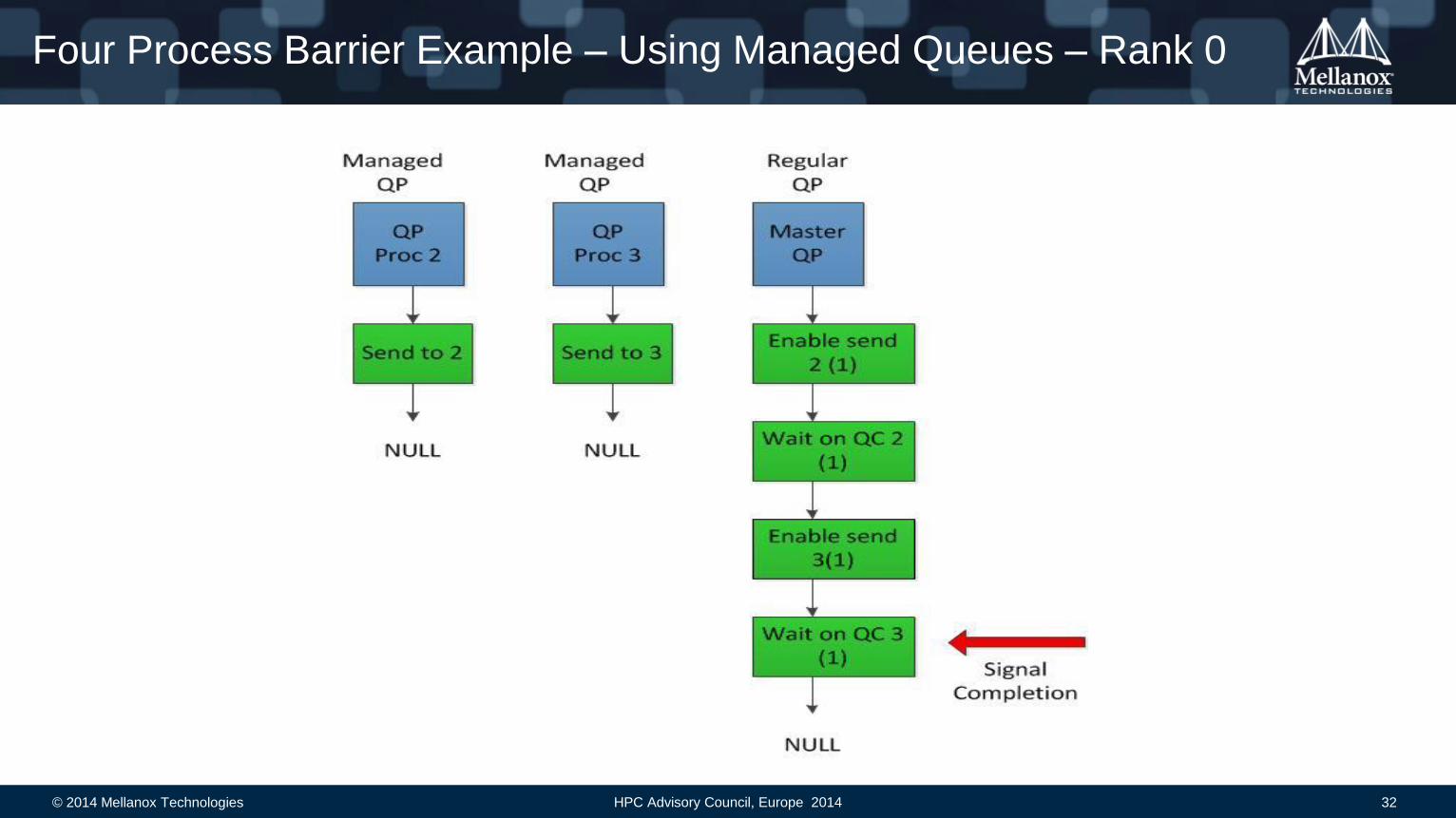
© 2014 Mellanox Technologies 31 HPC Advisory Council, Europe 2014
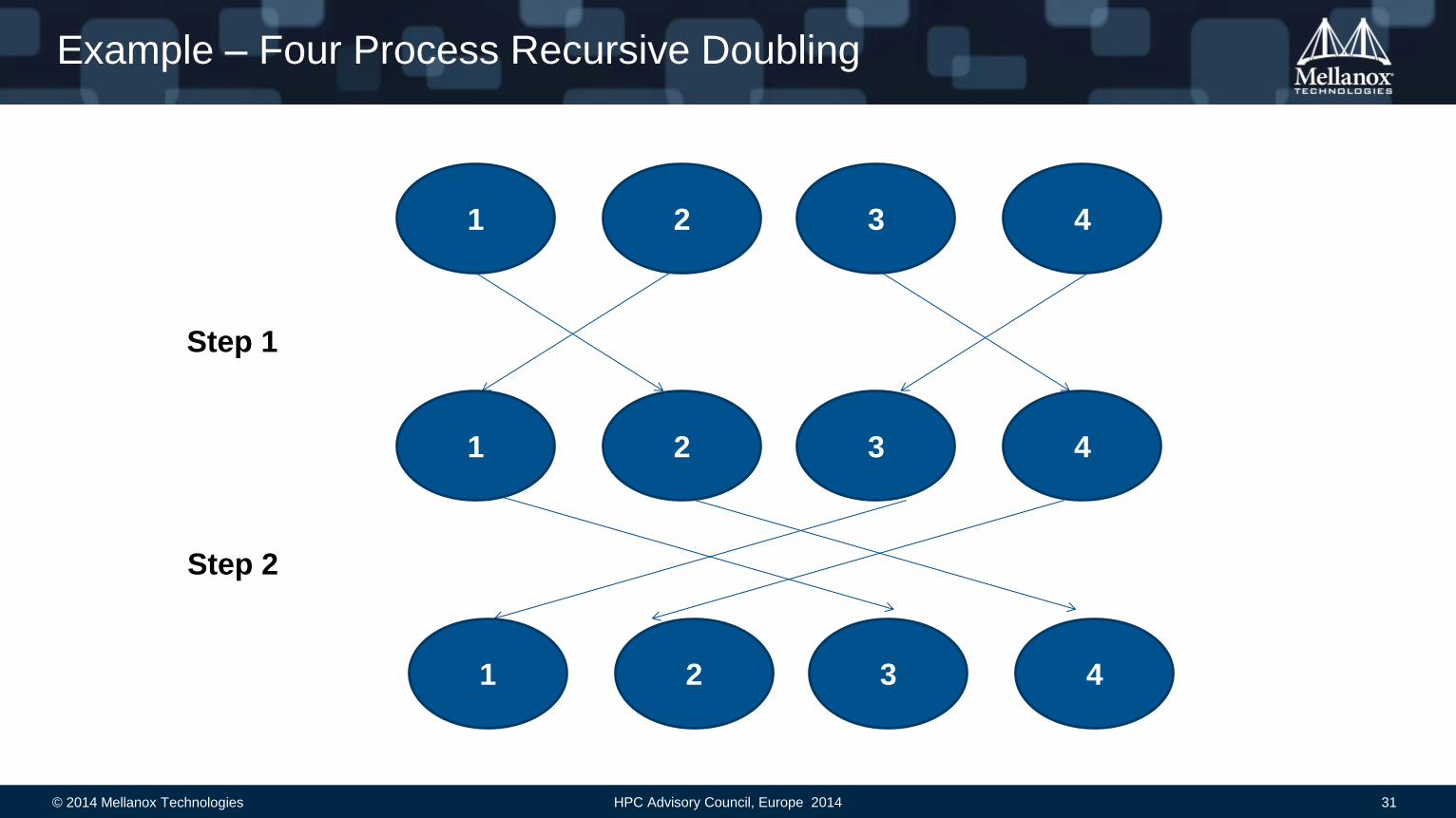
Example – Four Process Recursive Doubling
1 2 3 4
1 2 3 4
1 2 3 4
Step 1
Step 2
© 2014 Mellanox Technologies 32 HPC Advisory Council, Europe 2014
Four Process Barrier Example – Using Managed Queues – Rank 0
© 2014 Mellanox Technologies 33 HPC Advisory Council, Europe 2014
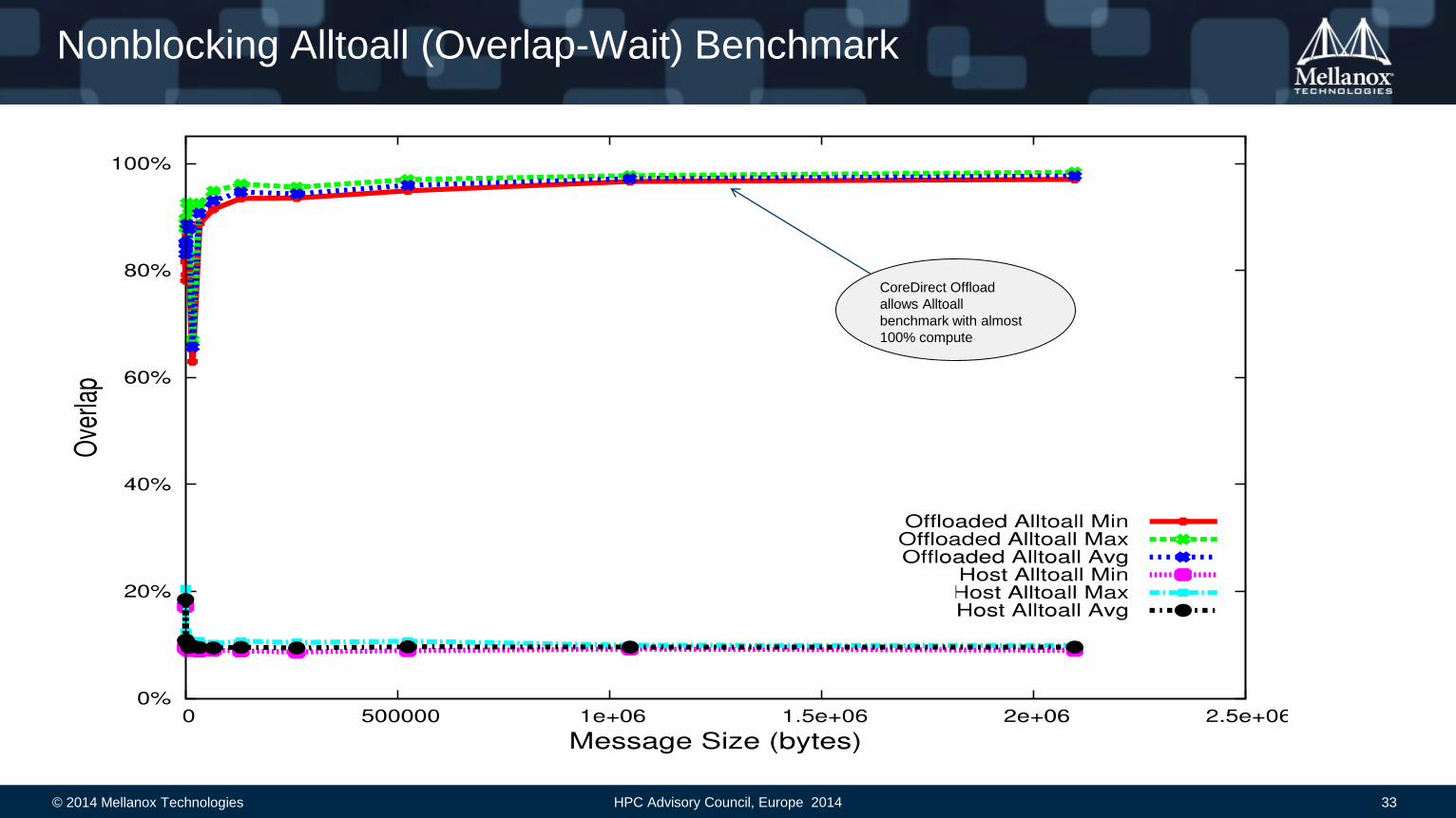
Nonblocking Alltoall (Overlap-Wait) Benchmark
CoreDirect Offload
allows Alltoall
benchmark with almost
100% compute

© 2014 Mellanox Technologies 34 HPC Advisory Council, Europe 2014
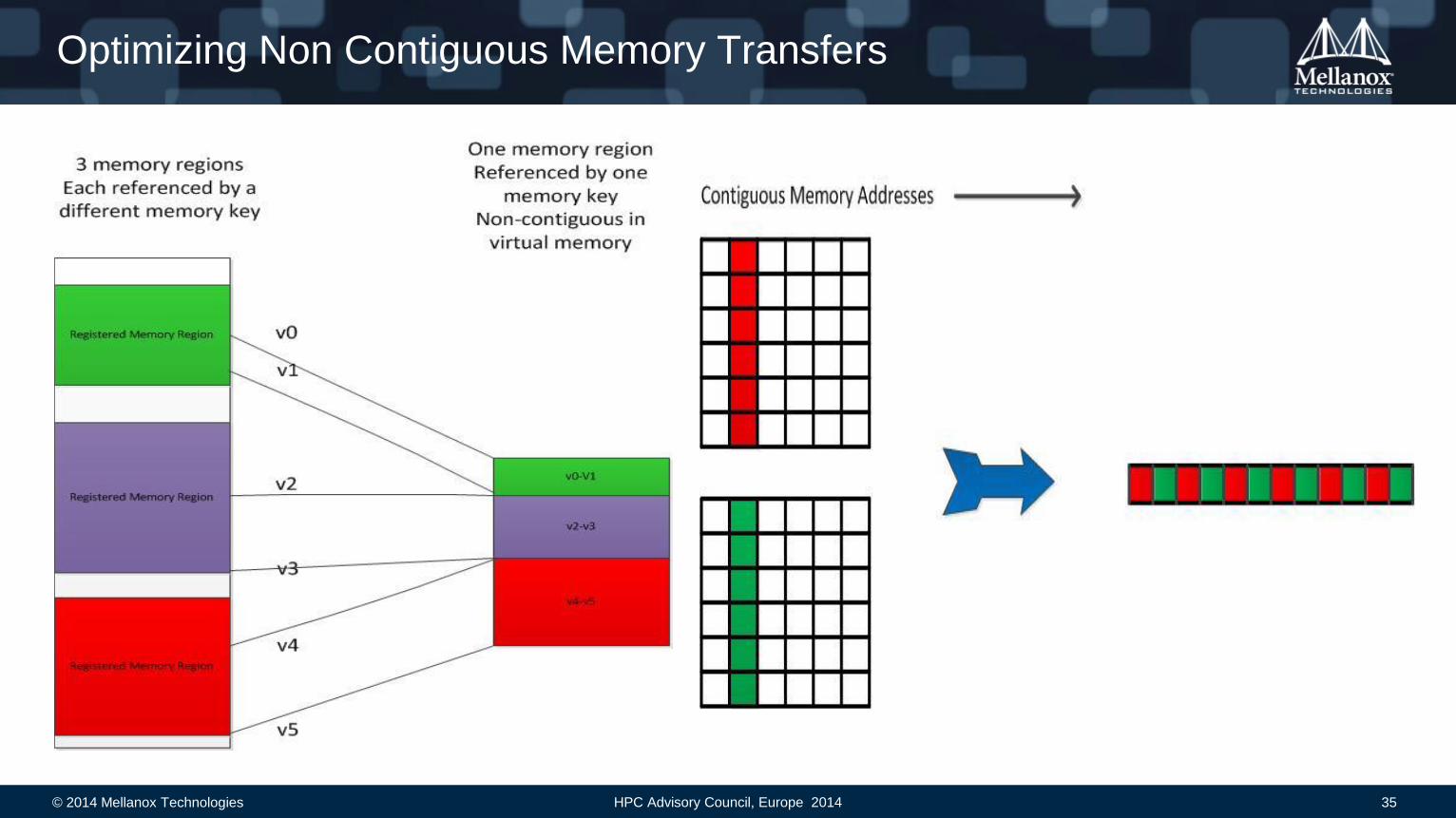
Optimizing Non Contiguous Memory Transfers
Support combining contiguous registered memory regions into a single memory region. H/W treats
them as a single contiguous region (and handles the non-contiguous regions)
For a given memory region, supports non-contiguous access to memory, using a regular structure
representation – base pointer, element length, stride, repeat count.
• Can combine these from multiple different memory keys
Memory descriptors are created by posting WQE’s to fill in the memory key
Supports local and remote non-contiguous memory access
• Eliminates the need for some memory copies
© 2014 Mellanox Technologies 35 HPC Advisory Council, Europe 2014
Optimizing Non Contiguous Memory Transfers

© 2014 Mellanox Technologies 36 HPC Advisory Council, Europe 2014
On Demand Paging
No memory pinning, no memory registration, no registration caches!
Advantages
• Greatly simplified programming
• Unlimited MR sizes
• Physical memory optimized to hold current working set
PFN1
PFN2
PFN3
PFN4
PFN5
PFN6
0x1000
0x2000
0x3000
0x4000
0x5000
0x6000
Address Space
0x1000
0x2000
0x3000
0x4000
0x5000
0x6000
IO Virtual Address
ODP promise:
IO virtual address mapping == Process virtual address mapping

© 2014 Mellanox Technologies 37 HPC Advisory Council, Europe 2014
TODO: x86-> +GPU -> +ARM/POWER
Connecting Compute Elements
© 2014 Mellanox Technologies 38 HPC Advisory Council, Europe 2014
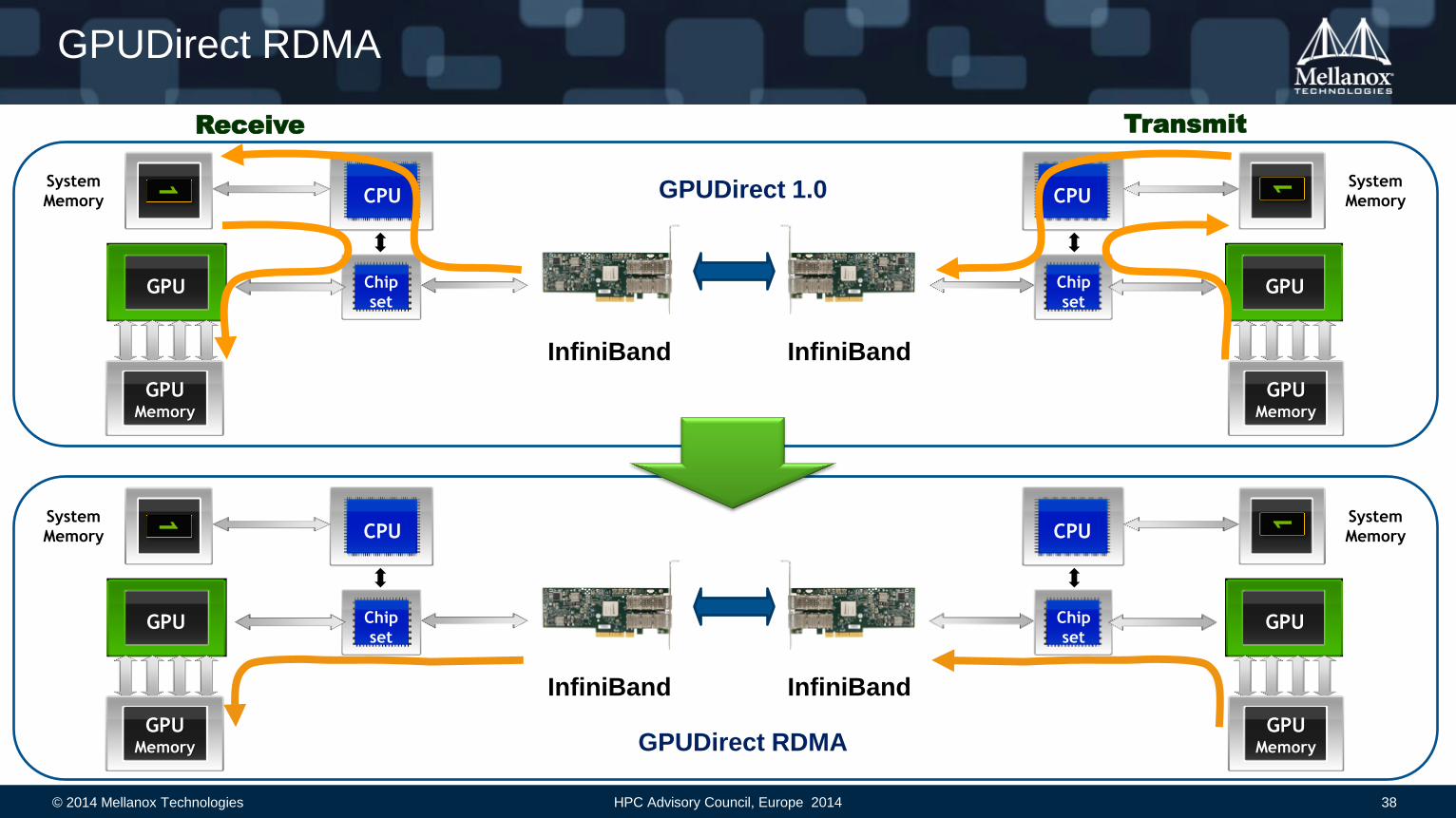
GPUDirect RDMA
Transmit Receive
CPU
GPU Chip
set
GPU Memory
InfiniBand
System
Memory
1
CPU
GPU Chip
set
GPU Memory
InfiniBand
System
Memory
1
GPUDirect RDMA
CPU
GPU Chip
set
GPU Memory
InfiniBand
System
Memory
1
CPU
GPU Chip
set
GPU Memory
InfiniBand
System
Memory
1
GPUDirect 1.0
© 2014 Mellanox Technologies 39 HPC Advisory Council, Europe 2014
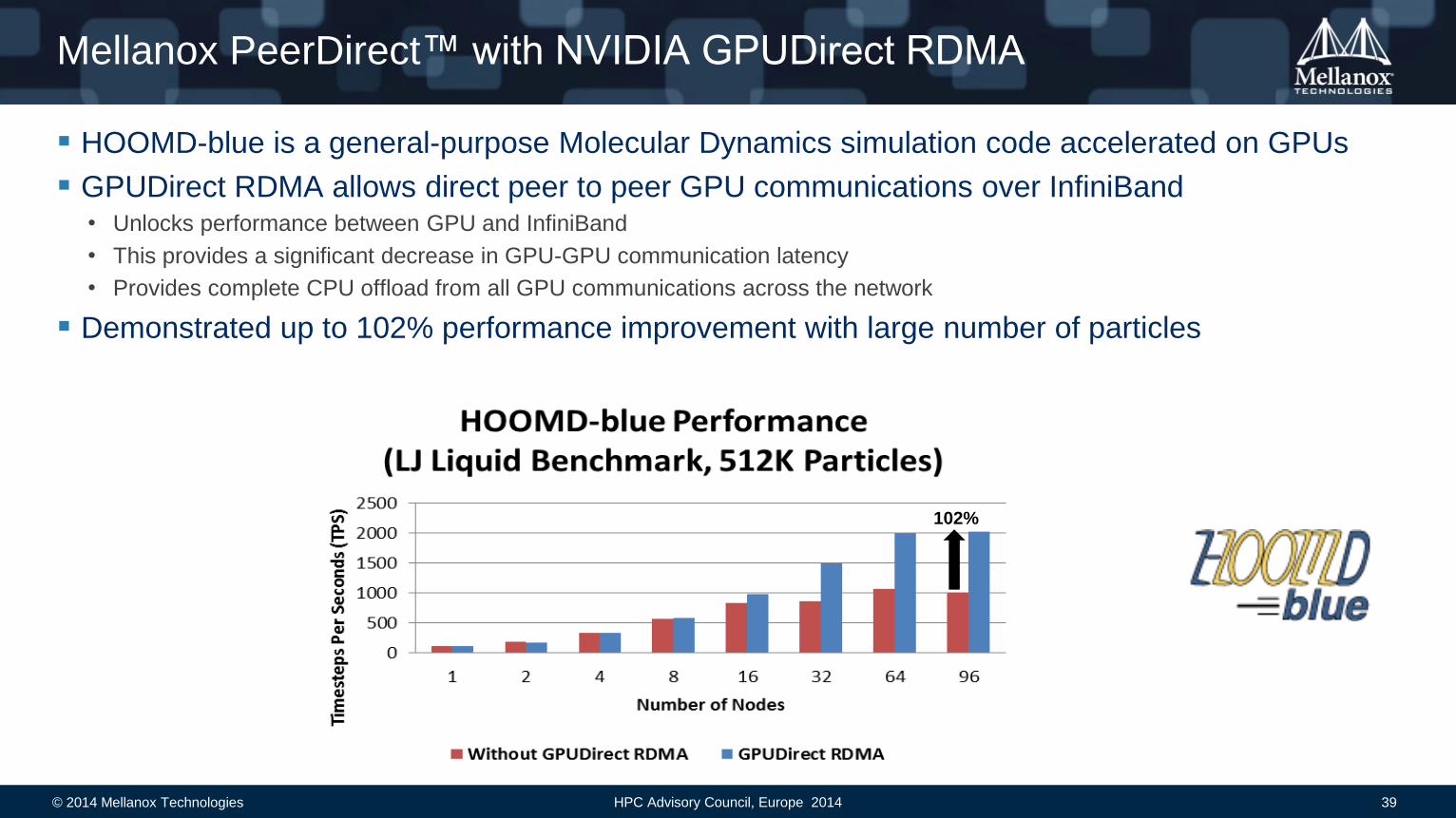
Mellanox PeerDirect™ with NVIDIA GPUDirect RDMA
HOOMD-blue is a general-purpose Molecular Dynamics simulation code accelerated on GPUs
GPUDirect RDMA allows direct peer to peer GPU communications over InfiniBand • Unlocks performance between GPU and InfiniBand
• This provides a significant decrease in GPU-GPU communication latency
• Provides complete CPU offload from all GPU communications across the network
Demonstrated up to 102% performance improvement with large number of particles
102%

© 2014 Mellanox Technologies 40 HPC Advisory Council, Europe 2014
Storage
© 2014 Mellanox Technologies 41 HPC Advisory Council, Europe 2014
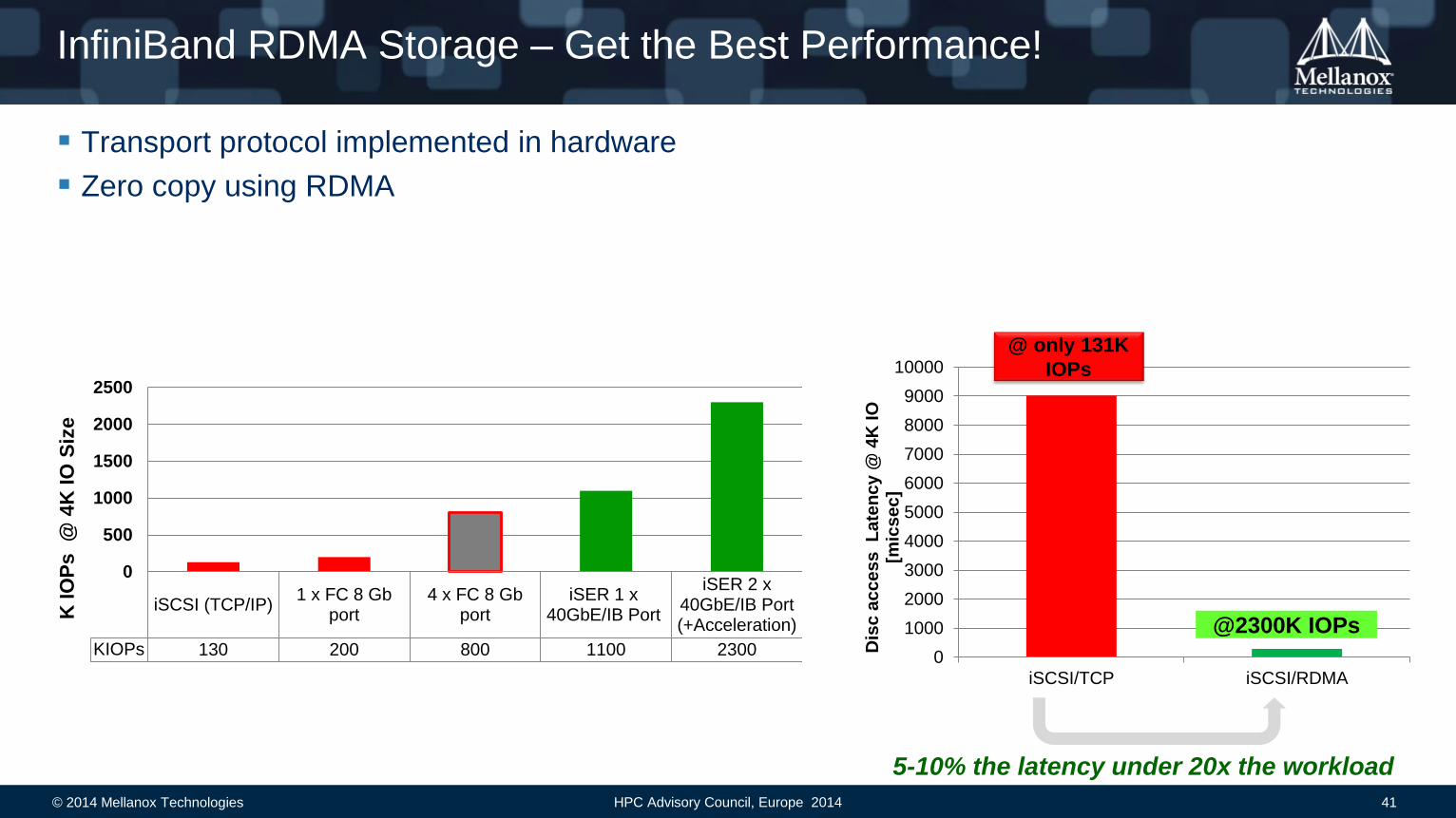
InfiniBand RDMA Storage – Get the Best Performance!
Transport protocol implemented in hardware
Zero copy using RDMA
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
iSCSI/TCP iSCSI/RDMA
Dis
c a
cc
es
s L
ate
nc
y @
4K
IO
[mic
se
c]
iSCSI (TCP/IP)1 x FC 8 Gb
port4 x FC 8 Gb
portiSER 1 x
40GbE/IB Port
iSER 2 x40GbE/IB Port(+Acceleration)
KIOPs 130 200 800 1100 2300
0
500
1000
1500
2000
2500
K IO
Ps
@ 4
K IO
Siz
e
5-10% the latency under 20x the workload
@ only 131K
IOPs
@2300K IOPs
© 2014 Mellanox Technologies 42 HPC Advisory Council, Europe 2014
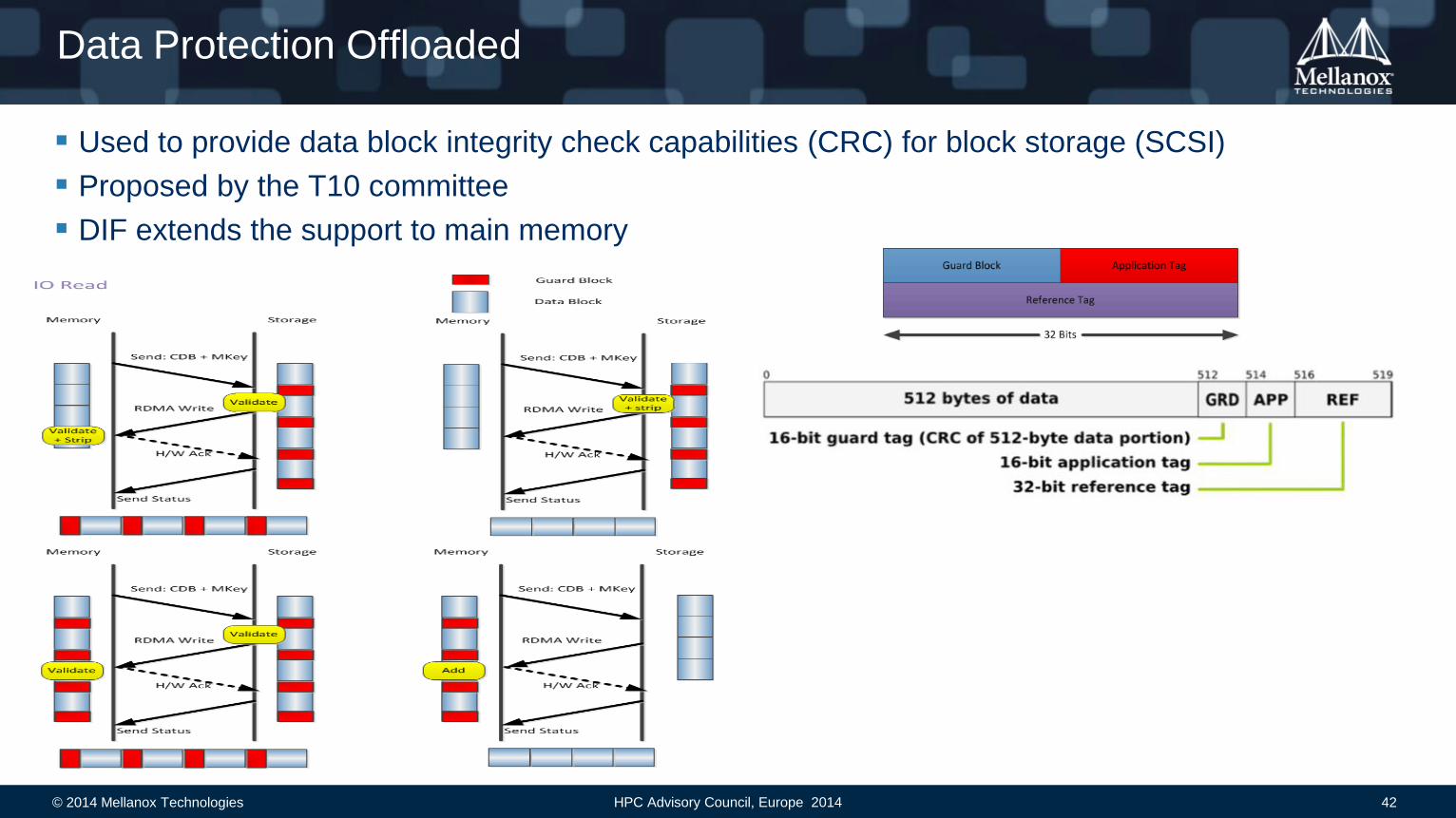
Data Protection Offloaded
Used to provide data block integrity check capabilities (CRC) for block storage (SCSI)
Proposed by the T10 committee
DIF extends the support to main memory

© 2014 Mellanox Technologies 43 HPC Advisory Council, Europe 2014
Power

© 2014 Mellanox Technologies 44 HPC Advisory Council, Europe 2014
Motivation For Power Aware Design
Today networks work at maximum capacity with almost constant dissipation
Low power silicon devices may not suffice to meet future requirements for low-energy networks
The electricity consumption of datacenters is a significant contributor to the total cost of operation
• Cooling costs scale as 1.3X the total energy consumption
Lower power consumption lowers OPEX
• Annual OPEX for 1KW is ~$1000
* According to Global e-Sustainability Initiative (GeSI)
if green network technologies (GNTs) are not adopted

© 2014 Mellanox Technologies 45 HPC Advisory Council, Europe 2014
Increasing Energy Efficiency with Mellanox Switches
Low Energy COnsumption NETworks
ASIC level Voltage/Frequency scaling
Dynamic array power-save
Link level Width/Speed reduction
Energy Efficient Ethernet
Switch Level Port/Module/System shutdown
System Level Energy aware cooling control
Aggregate Power Aware API
FW / MLNX-OS™ / UFM™
© 2014 Mellanox Technologies 46 HPC Advisory Council, Europe 2014
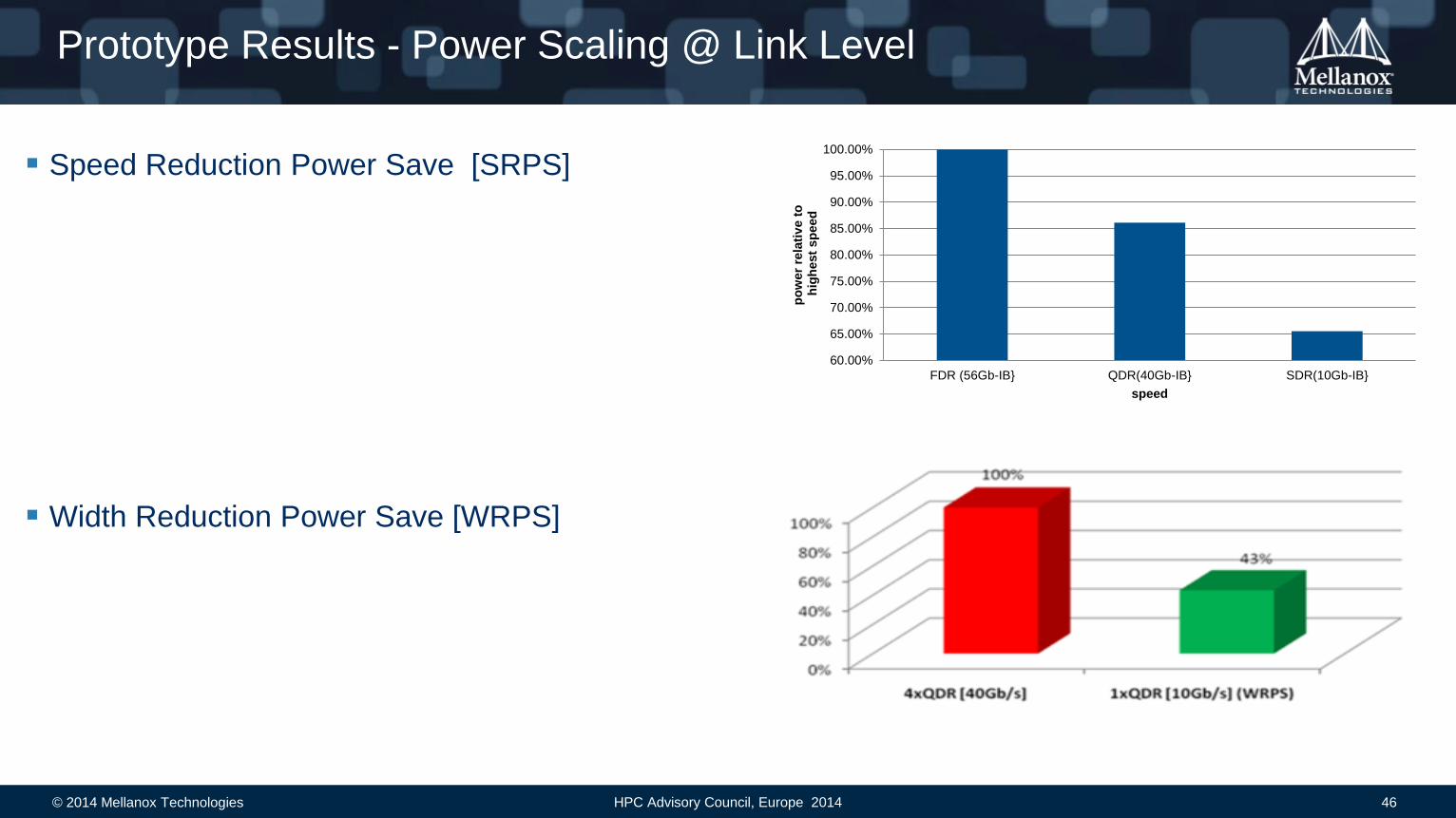
Speed Reduction Power Save [SRPS]
Width Reduction Power Save [WRPS]
Prototype Results - Power Scaling @ Link Level
60.00%
65.00%
70.00%
75.00%
80.00%
85.00%
90.00%
95.00%
100.00%
FDR (56Gb-IB} QDR(40Gb-IB} SDR(10Gb-IB}
po
wer
rela
tiv
e t
o
hig
hest
sp
eed
speed
© 2014 Mellanox Technologies 47 HPC Advisory Council, Europe 2014
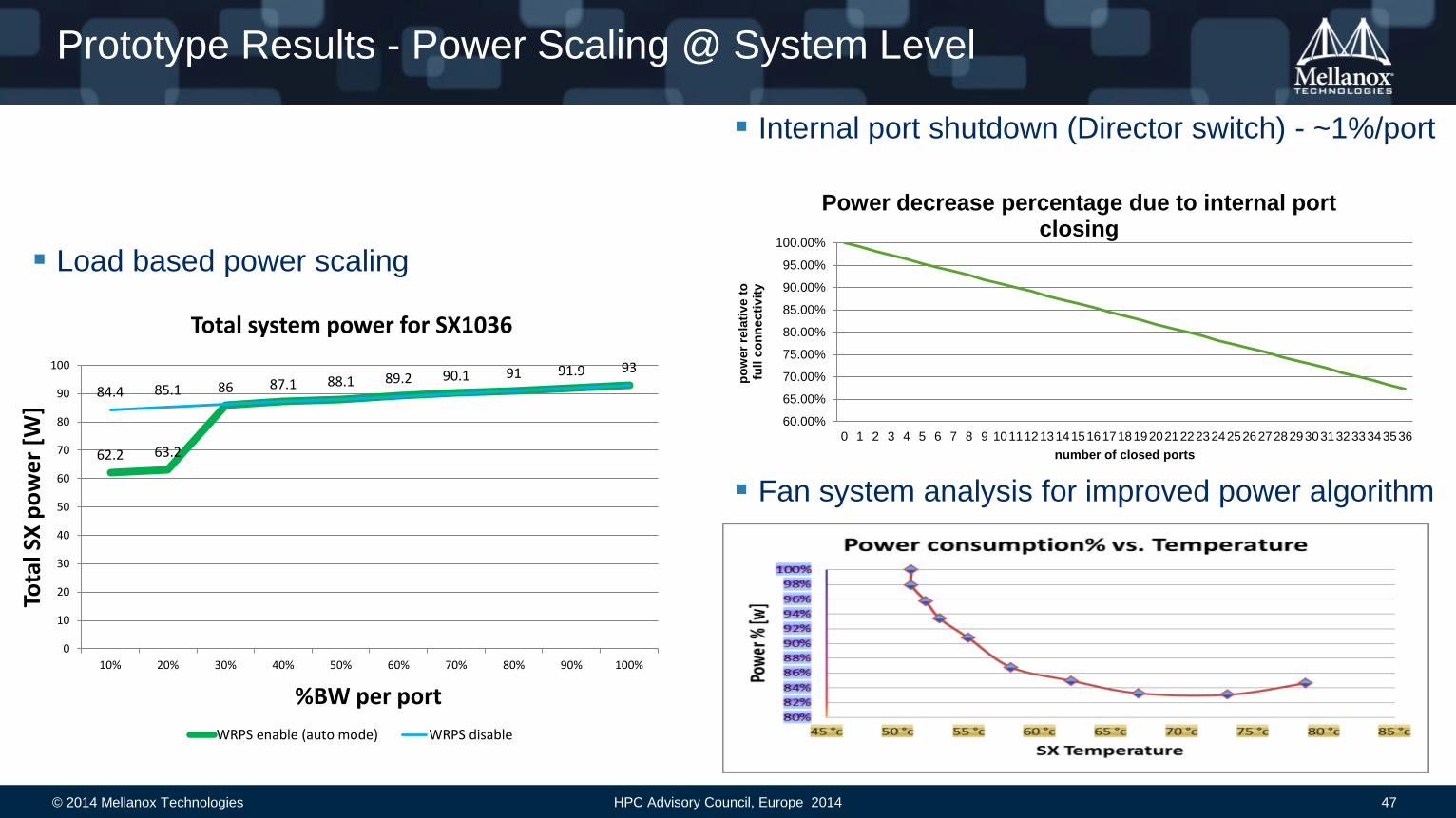
Prototype Results - Power Scaling @ System Level
Internal port shutdown (Director switch) - ~1%/port
Fan system analysis for improved power algorithm
60.00%
65.00%
70.00%
75.00%
80.00%
85.00%
90.00%
95.00%
100.00%
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536
po
wer
rela
tiv
e t
o
fu
ll c
on
necti
vit
y
number of closed ports
Power decrease percentage due to internal port closing
62.2 63.2
86 87.1 88.1 89.2 90.1 91 91.9 93
84.4 85.1
0
10
20
30
40
50
60
70
80
90
100
10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Tota
l SX
po
we
r [W
]
%BW per port
Total system power for SX1036
WRPS enable (auto mode) WRPS disable
Load based power scaling

© 2014 Mellanox Technologies 48 HPC Advisory Council, Europe 2014
Monitoring and Diagnostics
© 2014 Mellanox Technologies 49 HPC Advisory Council, Europe 2014
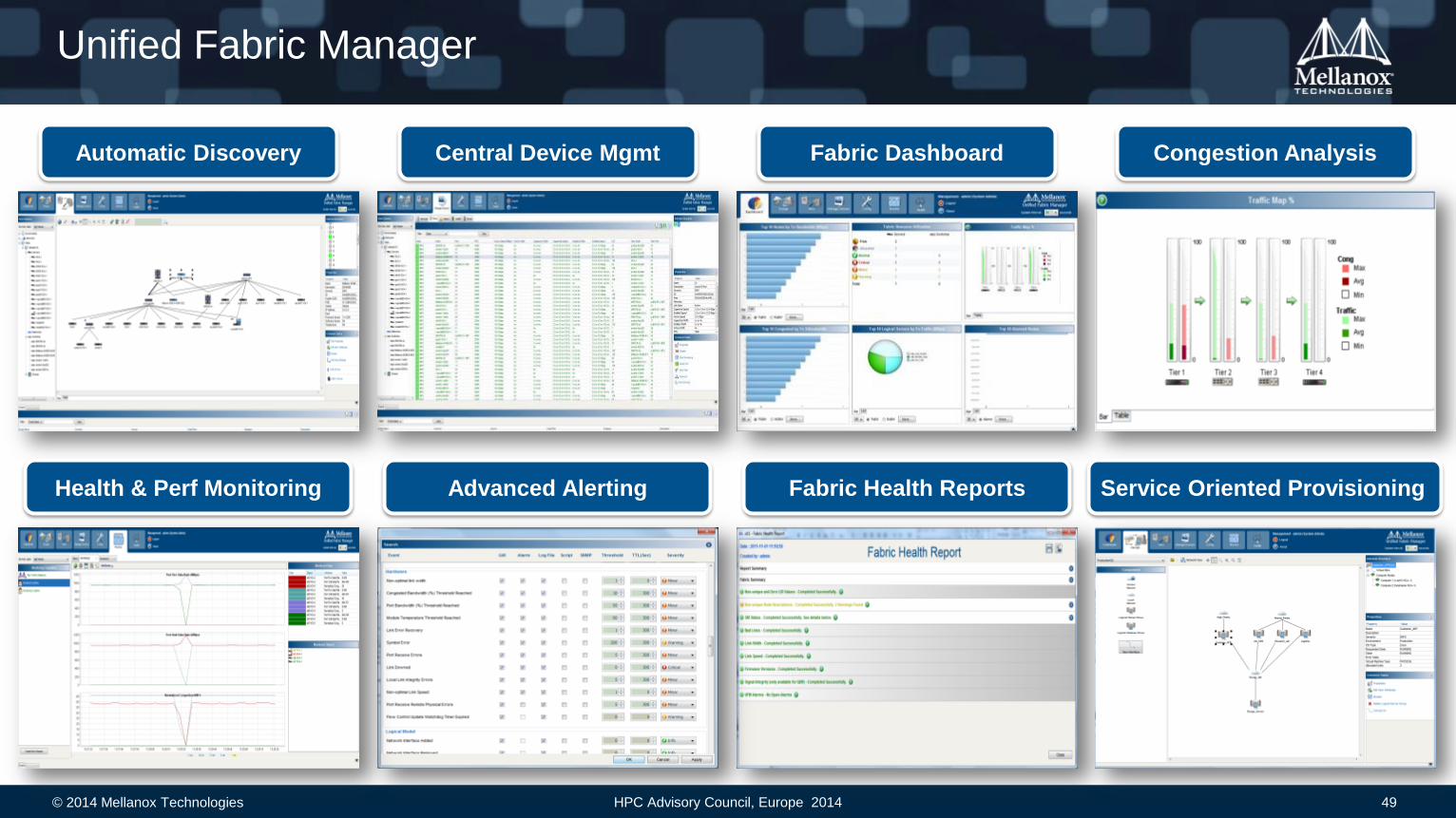
Unified Fabric Manager
Automatic Discovery Central Device Mgmt Fabric Dashboard Congestion Analysis
Health & Perf Monitoring Advanced Alerting Fabric Health Reports Service Oriented Provisioning

© 2014 Mellanox Technologies 50 HPC Advisory Council, Europe 2014
ExaScale !

© 2014 Mellanox Technologies 51 HPC Advisory Council, Europe 2014
Mellanox InfiniBand Connected Petascale Systems
Connecting Half of the World’s Petascale Systems Mellanox Connected Petascale System Examples

© 2014 Mellanox Technologies 52 HPC Advisory Council, Europe 2014
The Only Provider of End-to-End 40/56Gb/s Solutions
From Data Center to Metro and WAN
X86, ARM and Power based Compute and Storage Platforms
The Interconnect Provider For 10Gb/s and Beyond
Host/Fabric Software ICs Switches/Gateways Adapter Cards Cables/Modules
Comprehensive End-to-End InfiniBand and Ethernet Portfolio
Metro / WAN

Thank You


















