
Intelligent Agents Devika Subramanian Comp440 Lecture 1.
53
Intelligent Agents Devika Subramanian Comp440 Lecture 1
-
Upload
valentine-payne -
Category
Documents
-
view
229 -
download
1
Transcript of Intelligent Agents Devika Subramanian Comp440 Lecture 1.

Intelligent Agents
Devika SubramanianComp440Lecture 1

Intelligent Agents
An agent is anything that can be viewed as perceiving its environment through its sensors and acting uponthat environment through its effectors.
environment
agent
sensors
effectors
Objective: design agents that perform well in their environments

Informal agent descriptions Thermostat
Percepts: temperature sensor Actions: open/close valve Performance measure: maintaining user-set
temperature Environment: room/house
Internet Newsweeder Percepts: words, bitmaps Actions: word vector counts, cosine transforms, etc Performance measure: retrieving relevant news posts Environment: Internet newsgroups

Specifying performance measures
How do we measure how well an agent is doing? External performance measure or
self-evaluation? When do we measure performance
of agent? Continuous, periodic or one-shot
evaluation?

Specifying performance measures formally Performance measures are external. The environment provides feedback to
the agent in the form of a function mapping the environment’s state history to a real number.
Performance feedback can be provided after each move, periodically, or at the very end.
*: SV

Example of performance measure for thermostat
s0s1
sn-1 sn
Goal: maximizewith discount factor
The ambient temperature is being sampledat periodic intervals.
otherwise 100-
DESIRED )re( temperatuif 100)(
tt ssV
...)(...)()( 10 nn sVsVsV
10
Statesof theenvironment

Ideal rational agent
An ideal rational agent performs actions that are expected to maximize its performance measure on the basis of the evidence provided by its percept sequence and whatever built-in knowledge the agent has. An ideal rational agent is not omniscient. Doing actions to gather information is part of
rational behavior. Rationality of agents judged using performance
measure, percept sequence, agent’s knowledge, actions it can perform.

Abstract specification of agents
Specifying which action an agent ought to take in response to any given percept sequence provides a design for an ideal rational agent
AP*:f

Example: a thermostat
sensedtemperature
percepts action
A = {no-op,close valve, open valve}
Agent function f: T -> A, where T is set of possible ambient temperatures.
What assumptions about the environment and the deviceare we making with such an agent function?

Agent programs
An implementation of the given agent specification
function thermostat (temperature) If temperature < DESIRED – epsilon
return close valve If temperature > DESIRED + epsilon
return open valve Return no-op
AP*:f

Autonomous agents An agent is autonomous to the extent
that its behavior is determined by its own experience.
Given sufficient time and perceptual information, agent should adapt to new situations and calculate actions appropriate for those situations. Is a thermostat autonomous? Is the GPS route planner in your car
autonomous?

Taxonomy of agent programs Agents with no internal state
Reflex agents or stimulus-response agents Agents with internal state
Agents with fixed policies or reflex agents with state (agents that remember the past)
Agents that compute policies based on goals or general utility functions (agents that remember the past and can project into the future)

Agent program structure
Template for agent programs Function agent (percept) returns
action local state: l
l = update-local-state(l,percept) action = choose-best-action(l) l = update-local-state(l,action) return action

Reflex agents
Current percept
Interpret currentstate
Compute current action by choosing matching condition action rule
Action
conditionactionrules

Template for a reflex agent
Function reflexAgent(percept) static : rules, a set of condition-action
rules s =interpret-input(percept) rule = find-matching-rule(s,rules) action = rule-action(rule) return action
Does not maintain perceptual history!

An example of a reflex agent
10o
(t)
h(t)
Sensors: h(t),(t)
Performance measure: maintain heighth(t) at 3 meters (minimize the sum of (h(t)-3)2 over t in [0..T])
Actions: no-op, turninflow valve to the right, turn inflow valve to left

Condition-action rules
h 0-10 10-15
15-20
20-30
30-60
60-180
0-1.5 right right right right right noop
1.5-2.5 right right right right noop left
2.5-2.8 right right right noop left left
2.8-3.0 right noop left left left left
3.0-3.2 left left left left left left
3.2-4.0 left left left left left left

A reflex agent in nature
If small moving object then activate SNAPIf large moving object then activate AVOID and inhibit SNAP
percept
one of SNAP or AVOID

Ralph: Vision based vehicle steering sampling the image of roadway ahead
of vehicle determining the road curvature assessing the lateral offset of the
vehicle relative to the lane center commanding a steering action
computed on the basis of curvature and lane position estimates
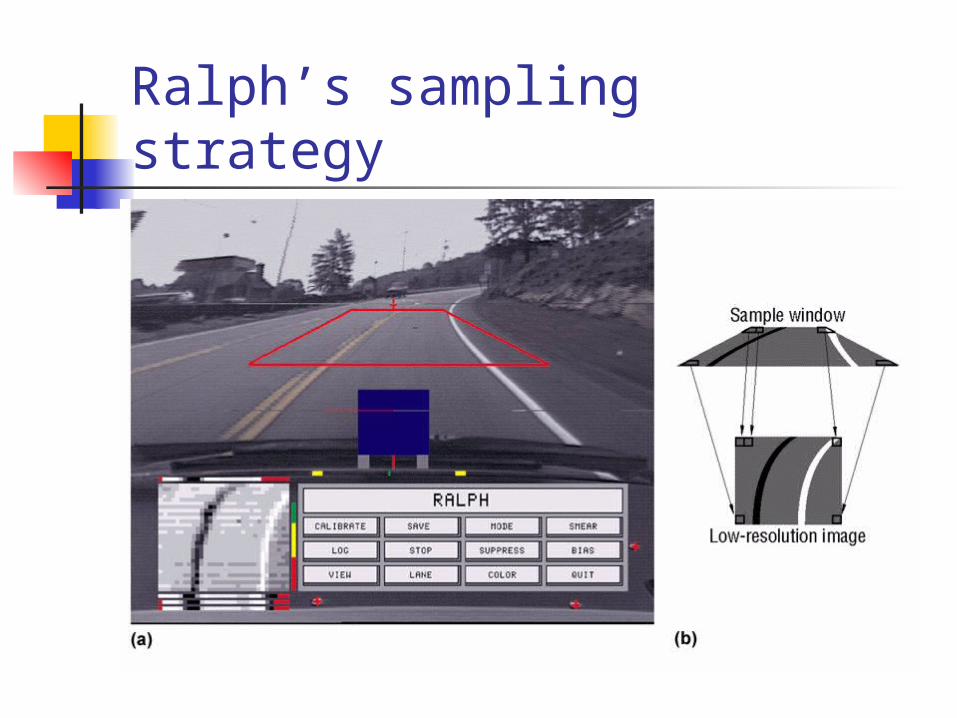
Ralph’s sampling strategy

Curvature hypotheses

Curvature scoring

Lateral offset calculation

No hands across America
2850 mile drive from Washington DC to San Diego, on highways.
Trip challenges: driving at night, during rain storms, on poorly marked roads, through construction areas.
Evaluation metric: percent of total trip distance for which Ralph controlled the steering wheel.
Ralph steered the vehicle for 2796 of the 2850 miles (98.1 percent)
10 mile stretch of new, unpainted highway (no lane markers)
city driving when road markings were either missing or obscured by other vehicles.

Challenging highway driving

Challenging city roads

Want Ralph in your car?
Fixed video camera, forward-looking, mounted on rear-view mirror inside vehicle.
steering actuator (converts output of Ralph to steering command for vehicle).
now commercially available from Assistware Technology Inc. ($1975 from http://www.assistware.com)

Reflex agents with internal state
Current percept
Interpret currentstate
Compute current action by choosing matching condition action rule
Action
InternalState
modelof
actionsandenv

Example of reflex agent with state
An automatic lane changer: need internal state to monitor traffic in lanes unless car has cameras in the front and rear. Internal state allows one to compensate for lack of full observability.

Why internal state is useful
Or, why is remembering the past any good? So, you are not doomed to repeat it
(Santayana). Past + knowledge of actions can help
you reconstruct current state --- helps compensate for lack of, or errors in, sensory information.

Template for reflex agent with state
Function reflex-agent-with-state (percept) returns action
static: state, rules state = update-internal-state(state,percept) rule = rule-match(state,rules) action = rule-action(rule) state = update-internal-state(state,action) return action

The NRL Navigation Task

The NRL Navigation Task

A near-optimal player
A three-rule deterministic controller solves the task!
The only state information required is the last turn made.
A very coarse discretization of the state space is needed: about 1000 states!
Discovering this solution was not easy!

Rule 1: Seek GoalThere is a clear sonar in the direction of the goal.
If the sonar in the direction of the goal is clear, follow it at speed of 20, unless goal is straight ahead, then travelat speed 40.

Rule 2: Avoid Mine
Turn at zero speed to orient with the first clear sonarcounted from the middle outward. If middle sonar is clear, move forward with speed 20.
There is a clear sonar but not in the direction of the goal.

Rule 3: Find Gap
There are no clear sonars.
If the last turn was non-zero, turn again by the sameamount, else initiate a soft turn by summing the rightand left sonars and turning in the direction of thelower sum.

Optimal player in action

Where optimal player loses

Goal-based agents (agents that consider the future)
Current percept
Interpret currentstate
Compute current action by picking one that achieves goals
Action
InternalState
models
project forwardby one action from
current state
goals

Computation performed by a goal-based agent
Current state
a1 a2 a3
a4
next states projected from currentstate and action
Actions a1 and a2 lead to states that do not achieve the goal, and actions a3 and a4 do. Hence, choose one of a3 or a4.

Goal-based agents Do not have fixed policies; they
compute what to do on the fly by assessing whether the action they choose achieves the given (fixed) goals.
Are not restricted to one-step look-ahead.
Are programmed by giving them goals, models of actions, and environment.

Utility-based agents (agents that consider the future)
Current percept
Interpret currentstate
Compute current action by picking one that maximizes utility function
Action
InternalState
models
project forwardby one action from
current state
Utilityfunction

Utility-based agents vs goal-based agents
Goal-based agents are degenerate cases of utility-based agents. The utility function that goal-based agents use is:
U(s0 s1 … … sn) = 1 if sn satisfies goals = 0 otherwise

An extended example: navigation in a Manhattan grid

Case 1 Ideal sensors (robot knows where on
grid it is accurately, at all times) Ideal effectors (commanded motions are
executed perfectly) Environment: all streets two way, no
obstacles. Goal: get from (x1,y1) to (x2,y2) What kind of agent do you need to
achieve this goal?

Solution to case 1
Simple reflex agent suffices. Fixed policy: dead reckoning
Go to (x1,y2) Go to (x2,y2)
No need for sensing at all; above policy can be implemented blindly.

Case 2 Ideal sensors (robot knows where on
grid it is accurately, at all times) Real effectors (commanded motions are
not executed perfectly) Environment: all streets two way, no
obstacles. Goal: get from (x1,y1) to (x2,y2) What kind of agent do you need to
achieve this goal?

Solution to Case 2 A simple reflex agent suffices. Fixed control policy that senses position at
every time step Command motion to (x1,y2) Sense position and issue correcting motion
commands until robot is within epsilon of (x1,y2) Command motion to (x2,y2) Sense position and issue correcting motion
commands until robot is within epsilon of (x2,y2)

Case 3 Ideal sensors (robot knows where on
grid it is accurately, at all times) Ideal effectors (commanded motions are
executed perfectly) Environment: one-way streets and
blocked streets, no map. Goal: get from (x1,y1) to (x2,y2) What kind of agent do you need to
achieve this goal?

Solution to case 3 Need agent with internal state to
remember junctions and options that have already been tried there (so it doesn’t repeat past errors endlessly).
Control algorithm: shorten Manhattan distance to destination whenever possible, backing up only when at a dead end. Back up to last junction with an open choice.

Properties of environments Accessible vs inaccessible: if an agent can sense
every relevant aspect of the environment, the environment is accessible. Simple reflex agents suffice for such environments.
Deterministic vs non-deterministic: if the next state of the environment is completely determined by the current state and the action selected by the agent, the environment is deterministic. Agents with internal state are necessary for non-deterministic environments.
Discrete vs continuous: whether states and actions are continuous are discrete. Chess is discrete, taxi driving is continuous.

Properties of environments (contd.) Episodic vs non-episodic: in an episodic
environment, agent’s experience is divided into episodes. The quality of its action depends just on the episode itself --- subsequent episodes do not depend on what actions occur in previous episodes. Agents that reason about the future are unneeded in episodic environments.
Static vs dynamic: if the environment can change while the agent deliberates, the environment is dynamic for the agent. Time-bounded reasoning needed for dynamic environments.


















