
Intel HPC Technology Overview - ODU · Intel HPC Technology Overview Tom Zahniser ... HEATCODE...
48
1 Intel HPC Technology Overview Tom Zahniser HPC Sales Specialist Email: [email protected] Phone: 610 - 213 - 5536 Q4, 2014
-
Upload
nguyendiep -
Category
Documents
-
view
218 -
download
0
Transcript of Intel HPC Technology Overview - ODU · Intel HPC Technology Overview Tom Zahniser ... HEATCODE...

1
Intel HPC Technology Overview
Tom ZahniserHPC Sales Specialist
Email: [email protected]
Phone: 610-213-5536
Q4, 2014

2
SUPERCOMPUTING1500XMore Performance
4XPower Increase
Top500* (1997 – 2012)
Driven by Moore’s Law
& Architecture Innovation
100XReduction $/FLOP
Source: Intel Analysis / Top500
Intel® Technical Computing
Efficiency Example at Scaledelivering scalable performance – it is a mandate in order to accelerate discovery and insight

3
~9 years #500 to single socket~6 years #1 to #500
Ongoing Exponential Growth in Performance
20152005 2010
**Source: Top500.org and internal Intel estimates
10,000 Tflops
20,000 Tflops
30,000 Tflops
40,000 Tflops
~3+ Teraflops2.4 TeraflopsIntel® XEON®Intel® Pentium® Pro
2.7 Teraflops
Single Socket#1 #500
World’sFastest
Supercomputer
#1 TOP5002000
World’s #500
Supercomputer
#500 Top5002006
= Performance of Top500’s #1 Supercomputer by year
From the biggest, fastest system to a single socket in ~15 years
2000

4
International Super ComputingTop 500 Update
Other brands and names are the property of their respective owners
>28% growth in Intel systems since 2005
Intel® Xeon® processor: • 427 systems (85%)
• 97% of new listings use Intel CPUs
• 100 Ivy Bridge based systems – most of
all CPUs
• InfiniBand outnumbers Ethernet systems
for 1st time
Intel® Xeon Phi™ coprocessor:• Many systems listed!
• #1 System at 34 Petaflops/s: Tianhe 2
- 32,000 Intel Xeon 2600 v2 CPUs
- 48,000 Intel Xeon Phi coprocessors
- with 3.1 Million cores.
(source: www.top500.org November 2013)

5
Intel® Technical Computing for HPCBuilding the Right Tool for the JobBalanced compute, storage, and interconnects based on workload
NETWORKINGSOFTWARE
TOOLSCOMPUTE STORAGE
5
Long-Term Commitment to Enabling HPC Applications and
Solutions
Intel® fabric designed from the ground up for HPC
Intel Confidential

6
Tock
32nm 22nm
Tick Tock
AVX
14nm
Tick Tock
Sandy
Bridge
Ivy
BridgeHaswell Broadwell TBD
AVX2
AVX-INT
Gather
TSX
AVX512
Scatter
Float16
RNG
10nm
Tick Tock
TBD TBD
Consistent and reliable cadence of industry leading architecture, process technology and capacity
Delivering Leadership HPC Performancewith Consistent Technology Development
Knights
Corner
Knights
Landing
Future
Knights
Intel Confidential

7
Intel® Xeon®
processor
64-bit
Intel® Xeon®
processor
5100 series
Intel® Xeon®
processor
5500 series
Intel® Xeon®
processor
5600 series
Intel® Xeon®
processor code-
named Sandy Bridge EP
Intel® Xeon®
processor code-
named
Ivy Bridge EP
Intel® Xeon®
processor code-
named
HaswellEP
Core(s) 1 2 4 6 8 12 18
Threads 2 2 8 12 16 24 36
SIMD Width 128 128 128 128256 AVX
256AVX
256AVX2
How do we attain extremely high compute density for parallel workloadsAND maintain the robust programming models and tools that developers crave?
Intel® Xeon Phi™
coprocessor
Knights Corner
Intel® Xeon Phi™
coprocessor
Knights Landing1
57-61 NDA
228-244 NDA
512 AVX512
More cores More Threads Wider vectors
Performance and Programmability
for Highly-Parallel Processing
Classified
*Product specification for launched and shipped products available on ark.intel.com. 1. Not launched or in planning.

8
• Delivers an agile & efficient solution for HPC centers serving diverse needs.
• Delivers dynamic scalability, greater performance, and
enabling faster time to discovery.
• Delivers performance on highly parallel and vectorized applications.
• Delivers the benefits of a general programming model.
The Processors: Parallelism is the path forwardEfficient, High-performing Applications are the GoalDelivering scalable performance – it is a mandate in order to accelerate discovery and insight

9
Invest in Common Tools and Programming Models
Intel® Xeon® processors
are designed for intelligent
performance and smart
energy efficiency*
Continuing to advance Intel®
Xeon® processor family and
instruction set (e.g., Intel®
AVX, etc.)
Multicore
Intel® Xeon Phi™ architecture
is ideal for highly parallel
computing applications
Software development
platforms ramping now
Manycore
Tomorrow
Use One Software Architecture Today. Scale Forward
Tomorrow.
Code
Today
Use One Software
Architecture
*http://www.intel.com/content/dam/www/public/us/en/documents/product-briefs/xeon-5500-brief.pdf

10
Future Intel® Xeon Phi™ Processor: Knights Landing
• “Knights Landing” code name for the 2nd generation
Intel® Xeon Phi™ product
• Based on Intel’s 14 nanometer manufacturing
process
• Standalone bootable processor (running the host
OS) and a PCIe coprocessor (PCIe end-point
device)
• Integrated on-package high-bandwidth memory
• Flexible memory modes for the on package memory
include: cache, flat, and hybrid
• Support for Intel® Advanced Vector Extensions 512
(Intel® AVX-512)
• 60+ cores, 3+ TeraFLOPS of double-precision peak
performance per single socket node
• Multiple hardware threads per core with improved
single-thread performance over the current
generation Intel® Xeon Phi™ coprocessor
Bootable host
processor…
All products, computer systems, dates and figures specified are preliminary based on current expectations, and are subject to change without notice.
Copyright © 2014 Intel Corporation. All rights reserved

11
Next Generation Supercomputer
“Cori will provide a significant increase in capability for our users and will provide a platform for transitioning our very broad user community to many core architectures.”
Sudip DosanjhNERSC Director
• Mid-2016 timeframe• 5000 users; 700 projects• Enabling extreme-scale science**
• >9300 Knights Landing nodes• >3 Tflops per single socket node• Self-hosting eliminates need to
move data on/off a coprocessor• High-bandwidth in-package
memory for bandwidth constrained workloads
“..a significant step in advancing supercomputing design toward the kinds of computing systems we expect to see in the next decade as we advance to exascale.”
Steve BinkleyAssociate Director of the Office of Advanced Scientific
Computing Research
*DOE--National Energy Research Scientific Computing Center**Per NERSC--developing new energy sources, improving energy efficiency, understanding climate change, developing new materials, analyzing massive data sets
System name: Cori

12
Need for Code Modernization
&
Intel’s Initiatives

13
LEVERAGE INTEL® XEON® PROCESSOR EXPERTISE
Xeon Phi™ Optimization benefits CPU Performance
HEATCODE application case study1
1 Source: Colfax International. Complete details can be found at http://research.colfaxinternational.com/
Application ported quickly from Intel®
Xeon® processors to Intel® Xeon Phi™
coprocessors…
Initial performance is <1/3 of (2) Intel®
Xeon® E5-2600 product family CPUs
After optimization, the new Intel® Xeon
Phi™ coprocessor code:
Runs up to 620x faster than baseline!
Runs up to 125x faster than the Intel®
Xeon® processor baseline!
The new, modern code improves Intel®
Xeon® processor performance over 60x
from baseline
One Intel® Xeon Phi™ coprocessor runs
~2X the speed of two Intel® Xeon®
processor CPUs
Familiar SW programming tools, and code modernization benefits both
CPU and coprocessor performance
Added Intel® Xeon Phi™ coprocessor
INITIAL PERF DROPS BY 1/3 Impact of Intel® Xeon processor
CODE MODERNIZATION
BETTER TOGETHER:
Perf with Intel® Xeon processor and
Intel® Xeon Phi™ coprocessor
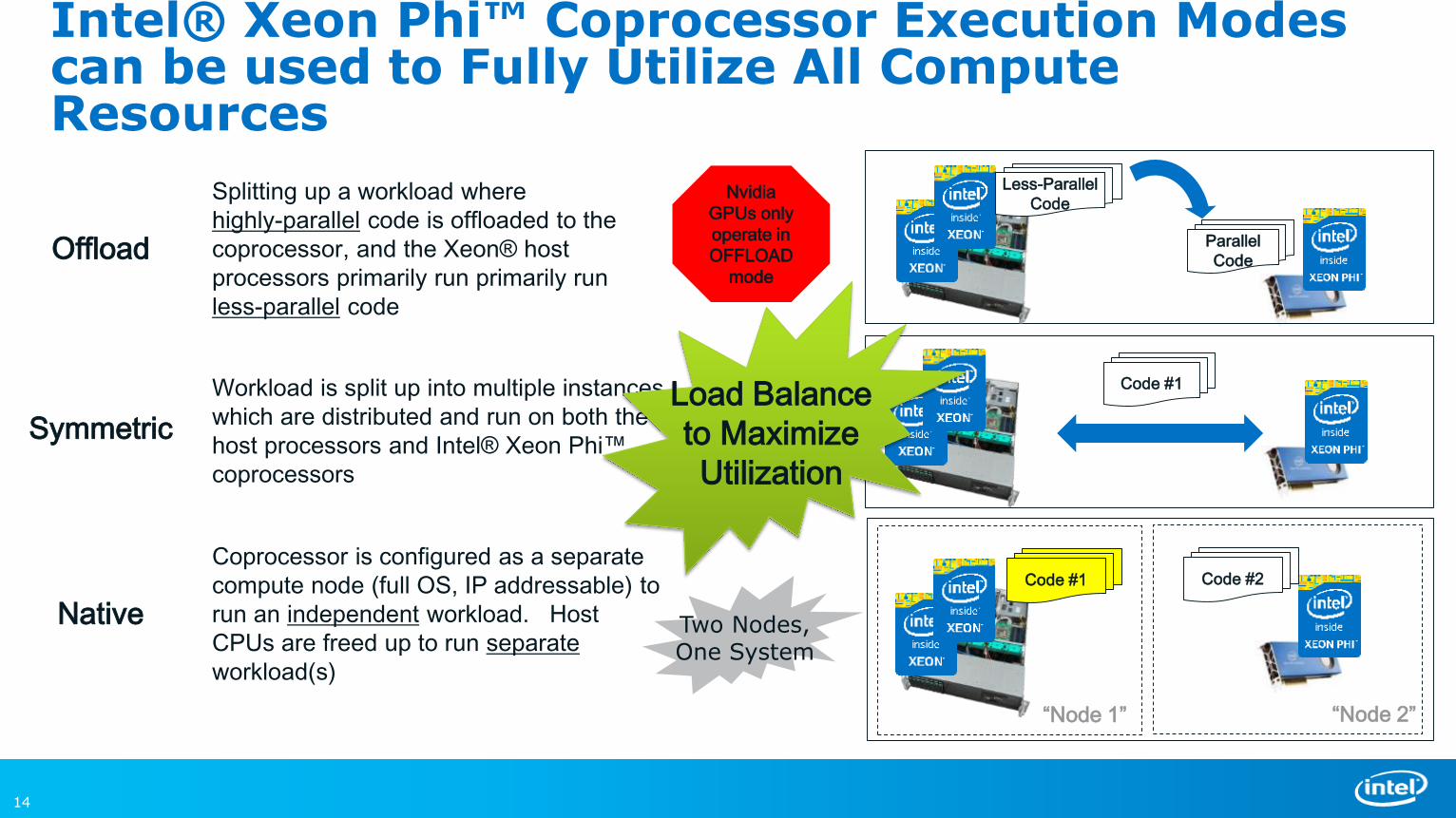
14
Offload
Splitting up a workload where
highly-parallel code is offloaded to the
coprocessor, and the Xeon® host
processors primarily run primarily run
less-parallel code
Symmetric
Workload is split up into multiple instances
which are distributed and run on both the
host processors and Intel® Xeon Phi™
coprocessors
Native
Coprocessor is configured as a separate
compute node (full OS, IP addressable) to
run an independent workload. Host
CPUs are freed up to run separate
workload(s)
Intel® Xeon Phi™ Coprocessor Execution Modes can be used to Fully Utilize All Compute Resources
Code #1
Code #1 Code #2
“Node 1” “Node 2”
Two Nodes,One System
Parallel
Code
Less-Parallel
Code
Load Balance
to Maximize
Utilization
Nvidia
GPUs only
operate in
OFFLOAD
mode

15
620x
1.9x4.4x
125x
Maximize Code Optimization
ONE Parallel Optimization Benefits CPU and Intel® Xeon Phi™
CPU &
Intel
C++ Xeon
Phi
CPU &
Intel
C++
Xeon
Phi
CPU +
Xeon
Phi
+
Xeon
Phi
NON-OPTIMIZED OPTIMIZED
104
103
102
101
Perf
orm
an
ce
(vo
xe
ls/s
eco
nd)
HETERO
HEATCODE BENCHMARKS
1 Source: Colfax International and Stanford University. Complete details can be found at: http://research.colfaxinternational.com/?tag=/HEATCODE

16
Intel® Technical Computing
The Case Study Summary a case study in code modernization
The effort to modernize HEATCODE took about 2 weeks
The majority of the work impacted about 500 lines of critical application code
The runtime for the application decreased from ~19 years on one node to ~16 days.
Copyright © 2014 Intel Corporation. All rights reserved

17
• Intel® Xeon Phi™ delivered the performance expected of a highly parallel processor on highly parallel applications
• Intel® Xeon Phi™ can deliver performance through open standard languages
• The performance of modern code benefits both Intel® Xeon® and Intel® Xeon Phi™ processors
Intel® Technical Computing
Our story – parallel programming is far from easy but,a case study in code modernization
The benefits of established programming languages are more about familiarity, productivity, and utility
Copyright © 2014 Intel Corporation. All rights reserved

18
Intel® Xeon Phi™ Coprocessor: Increases Application Performance up to 7x
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and
MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary.
You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when
combined with other products.
Source: Intel & Customer Measured. Configuration Details: Please reference slide speaker notes. For more information go to http://www.intel.com/performance18
Segment Application/Code Performance vs. 2S Xeon* Code Access
DCCNEC / Video Transcoding
Embree 2.0
Up to 3.0x2
Up to 1.89x1 (native)
NEC Case Study
Intel Developer Zone7
Energy
Seismic Imaging ISO3DFD Proxy 16th order Isotropic kernel RTM
Seismic Imaging 3DFD TTI 3- Proxy 8th order RTM
Petrobras Seismic ISO-3D RTM (2,4 Intel® Xeon Phi™
coprocessors)
Up to 1.45x3
Up to 1.23x3
Up to 3.4x, 5.6x4
Contact Intel representative
Proprietary code
Proprietary code
Financial Services
BlackScholes SP / DP
Monte Carlo European Option SP / DP
Monte Carlo RNG European SP / DP
Binomial Options SP / DP (symmetric)
SP: Up to 2.12x3 ; DP Up to 1.72x3
SP: Up to 7x3 ; DP Up to 3.13x3
SP: Up to 1.58x3 ; DP Up to 1.17x3
SP: Up to 1.85x4 ; DP Up to 1.85x4
Contact Intel representative
Contact Intel representative
Contact Intel representative
Contact Intel representative
Life ScienceBWA/Bio-Informatics
Wayne State University/MPI-Hmmer
GROMACS /Molecular Dynamics
Up to 1.5x4
Up to 1.56x1 (symmetric)
Up to 1.36x1 (symmetric)
Contact Intel representative
Intel Developer Zone7
Contact Intel representative
Manufacturing ANSYS / Mechanical SMP
Sandia Mantevo / miniFE
Up to 1.88x5
Up to 2.3x4
Intel Developer Zone7
Intel Developer Zone7
Physics / AstronomyZIB (Zuse-Institut Berlin) / Ising 3D (Solid State Physics)
ASKAP tHogbomClean (astronomy)
Princeton / GTC-P (Gyrokinetic Torodial) Turbulence Simulation IVB
Up to 3.46x1 (symmetric)
Up to 1.73x3
Up to 1.18x6
Contact Intel representative
Intel Developer Zone7
Intel Developer Zone7
Weather WRF /Code WRF V3.5 1.56x6 Intel Developer Zone7
1. 2S Xeon E5 2670 vs. 2S Xeon* E5 2670 + 1 Xeon Phi* coprocessor
2. 2S Xeon E5 2670 vs. 2S Xeon E5 2670 +2 Xeon Phi™ coprocessor
3. 2S Xeon E5-2697v2 vs. 1 Xeon Phi™ coprocessor (Native Mode)
4. 2S Xeon E5-2697v2 vs. 2S Xeon E5 2697v2 +1 Xeon Phi™ coprocessor (Symmetric Mode) (for Petrobras, 1, 2 3 or 4 Xeon Phi’s in the system)
5. 2S Xeon E5 2670 vs. 2S Xeon* E5 2670 + 1 Xeon Phi* coprocessor (Symmetric) (only 2 Xeon cores used to optimize licensing costs)
6. 4 nodes of 2S E5-2697v2 vs. 4 nodes of E5-2697v2 + 1 Xeon Phi™ coprocessor (Symmetric)
7. Go to http://software.intel.com/XeonPhi, Case Studies Code Recipes or Success Stories
Xeon = Intel® Xeon® processor Xeon Phi = Intel® Xeon Phi™
coprocessor

19
Modernizing Community Codes…Together
AVBP
(Large
Eddy)
Blast
BUDE
CAM-5
CASTEP
Castep
CESM
CFSv2
CIRCAC
AMBER
CliPhi
(COSMOS)COSA
Cosmos
codesDL-MESO DL-Poly ECHAM6 Elmer FrontFlow/blue Code GADGET GAMESS-US GPAW
Gromacs
GS2
GTC
Harmonie
Ls1
MACPO
Mardyn
MPAS
NEMO5
Nemo5 like
NWChemOpenflowOPENMP/
MPI
Optimized
integral
Quantum
EspressoR
ROTOR
SIMSeisSol,
GADGET,
SG++
SG++SU2UTBENCHVASPVISITWRF
Other brands and names are the property of their respective owners.
Intel® Parallel Computing Centers
Plus…User GroupsForming

20
Looking for More Collaborators
• RFP posted
• Rolling review process with responses typically in 60-90 days
• Selected Proposals receive two year grants
• Looking for proposals that:
– Deliver benefits of parallel modern application broadly
– Built on top of Open Standards
– Clear path into primary source tree
– Life Sciences, Energy, and FSI were under represented in prior round
Consider Joining us in this ventureFor More information: http://software.intel.com/ipcc

21

22
Intel® HPC FabricsBalanced Performance that Scales
May 2014

23
Intel® True Scale Fabric – What is it?
•Network Infrastructure• Optimized Price/Performance
interconnect for HPC
Host Architecture• High MPI message rate & low
end-to-end latency
Scalable Switch Solution• Performance & Latency scales
with network

24
Fabric Software Evolution for HPC
Verbs - Retrofitted for HPC• Based on connection-oriented RDMA and Queue Pair programming model
• Poor match to MPI semantics yield inefficiency and large memory footprint

25
Intel® True Scale Fabric: HPC-Optimized Design
HPC Enhanced InfiniBand Architecture
PSM Layer – specifically designed for MPI
• Performance Scaled Messaging: lightweight MPI interface
• High message rate and short message efficiency
Connectionless protocol
• Smaller memory footprint at scale
• Low end-to-end latency at scale
• Designed for high core count processors
Bypasses RDMA Verbs for higher performance
See slide 11 for performance information.

26
Intel® True Scale Architecture Application Performance
Computational Fluid Dynamics
SpecMPI2007
Molecular Dynamics
Weather
QDR
vs.
FDR
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information go to http://www.intel.com/performance. See slide 18 for configuration and testing information.

27
Intel Benchmarking Clusters
“Diamond” Cluster• 1 Head + 32 compute nodes / 512-Cores• Dual Xeon® E5 2680 2.7GHz p/node• 64GB of RAM 1333MHz p/node• RHEL, Compiler, MPI variations available• Intel® Cluster Suite, Intel® Fabric Suite• QDR-40 & QDR-80 Intel® True Scale Fabric
“AtlantisNM” Cluster• 1 Head + 128 compute nodes / 2024-Cores• Dual Xeon® E5 2670 2.6GHz p/node• 64GB of RAM 1600MHz p/node• RHEL, Compiler, MPI variations available• Intel® Cluster Suite, Intel® Fabric Suite• QDR-40 & QDR-80 Intel® True Scale Fabric• Lustre Configuration: 1 MDS, 8 OSS, 87 TB total storage**will soon have 32 Xeon Phi’s (2 cards in 16 nodes) before growing to 64 Xeon Phi’s (2 cards in 32 nodes)
Remote, secured, accessible systems for customers and partners
• “Grizzly 1” & “Grizzly 2” Clusters• 1 Head + 16 compute nodes / 256-Cores
• Dual Xeon® E5 2680 2.7GHz p/node
• 32GB of RAM 1666MHz p/node
• RHEL, Compiler, MPI variations available
• Intel® Cluster Suite, Intel® Fabric Suite
• Grizzly 1: QDR-40 & QDR-80 Intel® True Scale Fabric
• Grizzly 2: Mellanox FDR

28
The Advantages of Fabrics Integration
Fabrics Integration Required to Scale Performance
Intel®
Processor
Today
Fabric
Controller
System IO Interface (PCIe) Fabric Interface
32 GB/sec 10-15 GB/sec
Tomorrow
Intel®
Processor
Fabric Interface
50+ GB/sec
Fabric Controller
Problem:
• Performance Bottleneck – Processor Capacity & Memory Bandwidth Scaling Faster Than System IO Bandwidth
• Higher Cost & Lower Density – More Components On A Server Limit Density and Increase Fabric Cost
• Less Reliability & Higher Power – System IO Interface Adds Additional Componentry & “10s Of Watts” Incremental Power
Solution:
• Better & Balanced Performance - CPU/Fabric Integration Delivers Better Fabric to Compute Balance (Bandwidth & Latency )
• Improved Density & Lower Cost – Integration Provided For Dense Innovative Server Designs at Lower Costs
• Better Reliability & Power - Removing The System IO Interface From The Fabrics Solution Reduces Power and Improves Reliability

29
Intel® OMNI Scale—The Next-Generation Fabric
*OpenFabrics Alliance
Other brands and names are the property of their respective owners
INTEGRATION
Intel® Omni Scale
Intel® Omni Scale
Future 14nm
generation
Knights
Landing
Intel® True Scale
Upgrade Program
Helps Your Transition
Coming in ‘15
PCIe
Adapters√Edge
Switch√Open Software Tools*
√Director
Systems√
INTEL SILICON
PHOTONICS
Designed for Next Generation HPC
Host and Fabric Optimized for HPC
Supports Entry to Extreme Scale
End-to-End Solution

HPC Storage Software: LustreIntel Enterprise Edition for Lustre*
High performance
computing
Cloud Big data

31
Primary File Systems Used for HPC
• Lustre was the only HPC file system that gained usage share – up 10%
• NFS use down ~10% since 2010
• IBM GPFS use remained flat
• Red Hat use grew slightly due to being packaged with Red Hat Linux
• All ‘others’ had less than 3% share each
32
27
11
7
4
22
NFS Lustre GPFS Red Hat Panasas Others
IDC report Evolution of Storage in Technical Computing, #228142,
2013

32
An Intel® Enterprise Edition for Lustre solution
• Speed
• Open platform
• Efficiency
• Storage choice
• Affordable
• Scalable
• Stable and
reliable

33
Why Intel Support - Number of Code Check Ins
Bull 19
CEA 18Cray 4
DDN 2
EMC 39
Fujitsu 2
gentoo 1
GSI 3
Intel 856
IU 1LLNL 67
NASA 1
NRL 5
ORNL
37
S&C 4Suse 5
TACC 13
Ultrascale 1 Xyratex 45

34
Single client performance improvement available in IEEL 2
• Single client, single thread applications are common in the enterprise market
• The client simplification included in IEEL 2 improve the single client performance and also the single stream performance
• Benefit: Improve the I/O performance of enterprise applications
*
0
500
1000
1500
2000
2500
3000
3500
1 2 4 8 16M
B/s
ec
n. threads
IOR benchmark on a single client using QDR infiniband network
Lustre 1.8.x Lustre 2.x IEEL 2

35
Enterprise Edition for Lustre: Stack Chart

36
Intel Enterprise Edition for Lustre*
Open source Lustrecore
Intel® Manager for Lustre*
TechnicalSupport
Partner Program
•Unmatched performance
•Multi-vendor
•Simple administration
•Extensible interfaces
•Global coverage
•Trusted by the most demanding users
•Web-based training
•GTM resources

37
What’s Included with Enterprise Edition for Lustre* 2.0
1. Lustre 2.5.1 foundation2. Support for larger, complex configurations3. Software ‘connector’ to enable Lustre storage with
MapReduce applications4. Software ‘connector’ for resource and job scheduler5. Support for SUSE Enterprise Linux storage servers6. Lustre client for Intel® Xeon Phi™ coprocessors7. IML workflow simplified – now includes tiered
storage
* Some names and brands may be claimed as the property of others.

38
Summary
• Lustre* in good hands:• Solid technical progress: stable, efficient, open• Big investments being made by the community + Intel• Intel committed to open source
– Convergence of HPC & Big Data is underway
– Cloudera Distribution of Hadoop with Intel® Enterprise Edition for Lustre* V2.0 makes this happen
– Performance, Efficiency and Manageability benefit by combining Hadoop with Lustre
3
8
Intel Confidential — Do Not Forward * Some names and brands may be claimed as the property of others.
19

39
IDH to CDHFor Big Data Analytics

40
Intel & Cloudera Strategic Partnership
CDH to be Performance-optimized for Intel Architecture
Support for Intel CPUs, Ethernet, SSD, security & future technologies
Promote CDH as the Hadoop Distribution of choice
Largest strategic shareholder in Cloudera
Joint commitment to open source enabling
Customer benefit: faster insights, dramatic cost efficiency, easy to deploy
Intel Confidential

41
• Commitment to run Hadoop in HPC environments with Lustre
• Intel has developed:
• Hadoop Adapter for Lustre (HAL) to enable Lustre as an alternative to HDFS
• HPC Adapter for MapReduce (HAM) to enable Hadoop to use SLURM/MOAB or others as YARN-compatible
• Intel and Cloudera will collaborate to:
• Enable HPC environments for Cloudera Distribution (CDH)
• Converge on joint roadmap for HPC customers
Collaboration with Cloudera for HPC Solutions

42
HPC Appliances for Life Sciences
Challenge: Experiment processing takes 7 days with current infrastructure. Delays treatment for sick patients
Solution: Active Infrastructure for HPC Life Sciences
Scalable Rack Solution; 9 Teraflops, Lustre File Storage; Intel SW tools
Benefits: RNA-Seq processing reduced to 4 hours
Includes everything you need for NGS - compute, storage, software, networking, infrastructure, installation, deployment, training, service & support
Lustre(up to 360TB)
NFS(up to 180TB)
Infrastructure:
Compute(up to 32 nodes)
2U Plenum
NSS-HA Pair
NSS User Data
HSS Metadata Pair
HSS OSS Pair
HSS User Data
*Other names and brands may be claimed as the property of others.
2X
2X
Speedup
Before: Bowtie2 2.0.0-beta7, TopHat 2.0.4, Cufflinks 2.0.2After: Bowtie2 2.1.0, TopHat 2.0.8b, Cufflinks 2.1.1.2-Intel® Xeon® E5-2687W / 3.1 GHz
Partnership between TGen* & Intel

43
Life Sciences Cluster Sizing Model
Big Data and High Performance Computing
Intel® Architecture is present from sequencers to appliancesto high-performance computing cloud
Sequencer Analytics
Appliance
HPC Pipeline
Cluster
Storage and
Networking
Research
Computing
Precision
Medicine
* Other names and brands may be claimed as the property of others.
32 Sequencers
(128 Xeons
64TB SSDs
256TB SATA)
704 Xeons
(2S/12 core)
1,232 Xeons
(2S/12 core)
~2100-3500
cores per PB-
annual
35PB storage
(14 Xeons)
(32 HTS *
220TB/year
* 5 years)
587 Xeons
(2S/12 core)
~1000 cores
per PB-annual
Intel Technologies:
Intel® Xeon® / Intel® Xeon® Phi™ •
Rack Scale Architecture • Integrated
Fabric • Software Defined Network •
Solid-State Drives • Workload
Optimization
Hadoop* • Lustre* • Cloudbursting •
Virtualization • Encryption • Cloud-based
Analytics
Intel Performance Tools & Compilers
Commercial & Open Source Optimized
Life Sciences Codes
Large Teaching Hospital
32 Sequencers
35PB storage
3,000 Xeon CPUs
37,000 Xeon cores

44
Cray & Intel Partnership
Partners on many technology fronts

45
Thank You.

46
Legal Disclaimer
Copyright © 2014 Intel Corporation. All rights reserved
INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT.
A "Mission Critical Application" is any application in which failure of the Intel Product could result, directly or indirectly, in personal injury or death. SHOULD YOU PURCHASE OR USE INTEL'S PRODUCTS FOR ANY SUCH MISSION CRITICAL APPLICATION, YOU SHALL INDEMNIFY AND HOLD INTEL AND ITS SUBSIDIARIES, SUBCONTRACTORS AND AFFILIATES, AND THE DIRECTORS, OFFICERS, AND EMPLOYEES OF EACH, HARMLESS AGAINST ALL CLAIMS COSTS, DAMAGES, AND EXPENSES ANDREASONABLE ATTORNEYS' FEES ARISING OUT OF, DIRECTLY OR INDIRECTLY, ANY CLAIM OF PRODUCT LIABILITY, PERSONAL INJURY, OR DEATH ARISING IN ANY WAY OUT OF SUCH MISSION CRITICAL APPLICATION, WHETHER OR NOT INTEL OR ITS SUBCONTRACTOR WAS NEGLIGENT IN THE DESIGN, MANUFACTURE, OR WARNING OF THE INTEL PRODUCT OR ANY OF ITS PARTS.
Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined". Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The information here is subject to change without notice. Do not finalize a design with this information.
The products described in this document may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order.
Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be obtained by calling 1-800-548-4725, or go to: http://www.intel.com/design/literature.htm
Any software source code reprinted in this document is furnished under a software license and may only be used or copied in accordance with the terms of that license. {include a copy of the software license, or a hyperlink to its permanent location}
Intel processor numbers are not a measure of performance. Processor numbers differentiate features within each processor family, not across different processor families: Go to: Learn About Intel® Processor Numbers
*Other names and brands may be claimed as the property of others

47
Legal Disclaimers: Performance
Performance tests and ratings are measured using specific computer systems and/or components and reflect the approximate performance of Intel products as measured by those tests. Any difference in system hardware or software design or configuration may affect actual performance. Buyers should consult other sources of information to evaluate the performance of systems or components they are considering purchasing. For more information on performance tests and on the performance of Intel products, Go to: http://www.intel.com/performance/resources/benchmark_limitations.htm.
Intel does not control or audit the design or implementation of third party benchmarks or Web sites referenced in this document. Intel encourages all of its customers to visit the referenced Web sites or others where similar performance benchmarks are reported and confirm whether the referenced benchmarks are accurate and reflect performance of systems available for purchase.
Relative performance is calculated by assigning a baseline value of 1.0 to one benchmark result, and then dividing the actual benchmark result for the baseline platform into each of the specific benchmark results of each of the other platforms, and assigning them a relative performance number that correlates with the performance improvements reported.
SPEC, SPECint, SPECfp, SPECrate. SPECpower, SPECjAppServer, SPECjEnterprise, SPECjbb, SPECompM, SPECompL, and SPEC MPI are trademarks of the Standard Performance Evaluation Corporation. See http://www.spec.org for more information.
TPC Benchmark is a trademark of the Transaction Processing Council. See http://www.tpc.org for more information.
SAP and SAP NetWeaver are the registered trademarks of SAP AG in Germany and in several other countries. See http://www.sap.com/benchmark for more information.
INFORMATION IN THIS DOCUMENT IS PROVIDED “AS IS”. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO THIS INFORMATION INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT.
Performance tests and ratings are measured using specific computer systems and/or components and reflect the approximate performance of Intel products as measured by those tests. Any difference in system hardware or software design or configuration may affect actual performance. Buyers should consult other sources of information to evaluate the performance of systems or components they are considering purchasing. For more information on performance tests and on the performance of Intel products, reference www.intel.com/software/products.

48
Optimization Notice
Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique
to Intel microprocessors. These optimizations include SSE2®, SSE3, and SSSE3 instruction sets and other optimizations. Intel does
not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel.
Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not
specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference
Guides for more information regarding the specific instruction sets covered by this notice.
Notice revision #20110804
Optimization Notice


















