
Drafting Behind Akamai (Travelocity-Based Detouring) Dr. Yingwu Zhu.
date post
21-Dec-2015Category
view
214download
0
Integrating Semantics-Based Integrating Semantics-Based Access Mechanisms with P2P Access Mechanisms with P2P File SystemsFile Systems
Yingwu Zhu, Honghao Wang and Yiming Hu

OutlineOutline
BackgroundSystem DesignRelated WorkConclusions

BackgroundBackground
Current P2P file systems (e.g.,CFS and PAST) Layering FS functionalities on a distribut
ed hash table (DHT), e.g., chord, pastry Do not support semantics-based access
Because DHTs support only exact-match lookups

A problem of DHT-based P2P file systems Support only exact-match lookups given
a file object identifier fileID get(fileID): retrieves the file corresponding to t
he fileID put(fileID, file): stores the file with the fileID a
s a DHT key
MotivationMotivation

MotivationMotivation
A challenge to P2P file systems Provide convenient access to vast
amount of information E.g., provide semantics-based
search capabilities to efficiently locate semantically close files for browsing and purging, etc.

Targeted ApplicationTargeted Application
Semantic search expressed in natural language. Query: “locate files that might contains
k1, k2 and k3” *k1, k2 and k3 are three distinct keywords

Targeted Application Targeted Application (Cont’d)(Cont’d)
Or, a more useful search: Query: “locate files similar to f1” The querys result are materialized via s
emantic directories

System ArchitectureSystem Architecture
Extends a P2P file system to support semantics-based access
Major Components Semantic Extractor Registry Semantic Indexing and Locating Utility

Regular IndexingRegular Indexing
Indexing – key=hash(keywords or contents)– put(key, file-location); get(key)
Will be mapped to different index nodes– A and B have different contents– Traditional hash functions try to be uniform and conflict free
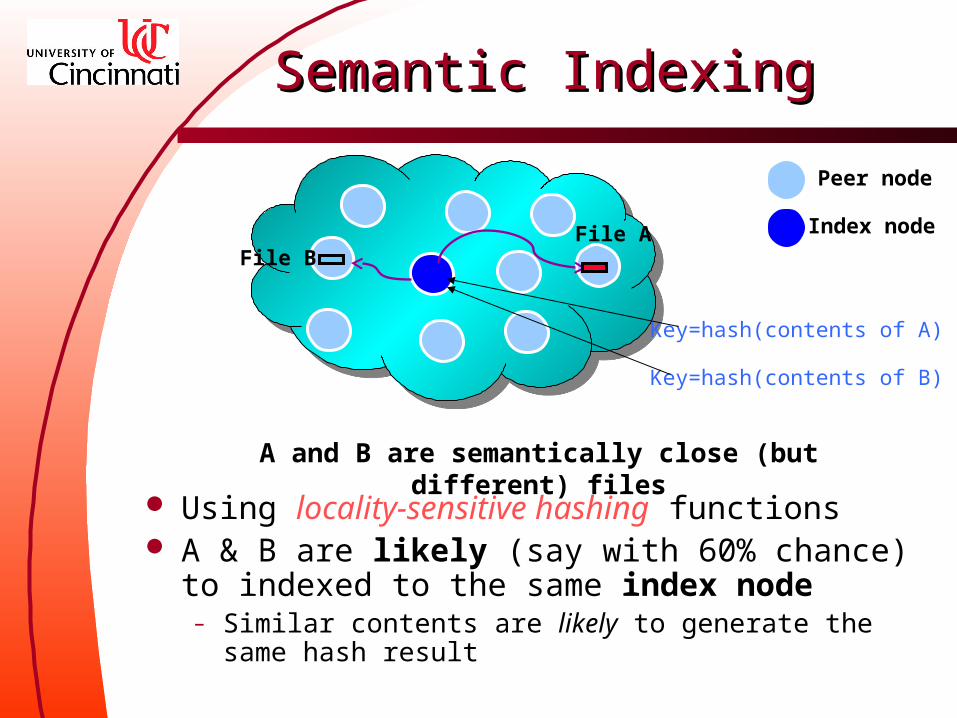
A and B are semantically close (but different) files
Peer node
File AFile B
Index node
Key=hash(contents of B)
Key=hash(contents of A)

Locality Sensitive HashingLocality Sensitive Hashing
A family of hash functions F is locality sensitive if hF operating on two sets A and B, we have:P hF [h(A)=h(B)] = sim(A,B)
Min-wise independent permutations are LSH
Similarity function
Semantic IndexingSemantic Indexing
Using locality-sensitive hashing functions A & B are likely (say with 60% chance) to indexed
to the same index node– Similar contents are likely to generate the same hash result
A and B are semantically close (but different) files
Peer node
File AFile B
Index node
Key=hash(contents of B)
Key=hash(contents of A)

Improving Semantic IndexingImproving Semantic Indexing
How to improve the likelihood that A & B are mapped together?
– Using n (n>1) sets of semantic-hash functions n index nodes
– The more functions we use, the higher the likelihood– Probability of finding the file = 1 – (1-p)n
– n normally is small (e.g., n<20)
A and B are semantically close (but different) files
Peer node
File AFile B
Index node
Key1=hash1(contents of B)
Key1=hash1(contents of A)
Key2=hash2(contents of A)
Key2=hash2(contents of A)

System ArchitectureSystem Architecture
FS
Extractor Registry
Semantic Indexingand
Locating Utility
DHT
Application/User
Major components of the system architecture

Semantic Extractor RegistrySemantic Extractor Registry
A set of semantic extractors Leverage IR algorithms, VSM and LSI Represent a file as a semantic vector (S
V), typcially 200-300 keywords Semantically close files have similar SV
s

Semantic IndexingSemantic Indexing
Given a file’s SV
Step 1: Drive a small number of semantic IDs (semIDs) from the SV using LSH
Step 2: Indexing the file by having these semIDs as the DHT keys If two files are similar, some of their se
mIDs are likely to be the same

Semantic IndexingSemantic Indexing
Using n groups of m hash functions xor hash results within a group
Results: The indice of semantically close files are hashe
d to the same peers with probability 1-(1-pm)n
P is expected to be high for semantically close files, so is the probability
*p=sim(f1,f2), similarity between two files’s SVs

Effects of Effects of nn and and mm
Semantically close files are hashed to the same peers with probability 1-(1-pm)n
A big n would– Increase the probability – Increase the load of indexing / querying
A small m might – Increase the probability– Cluster the indices of dissimilar files to the
same peers, affecting load-balancing

Semantic LocatingSemantic Locating
Given a query’s SV Step 1: Drive a small number of semIDs
from the SV using LSH Step 2: Locating those semantically close
files by having these semIDs as the DHT keys
Goal: answer a query by consulting only a small number of peer nodes

EvaluationEvaluation
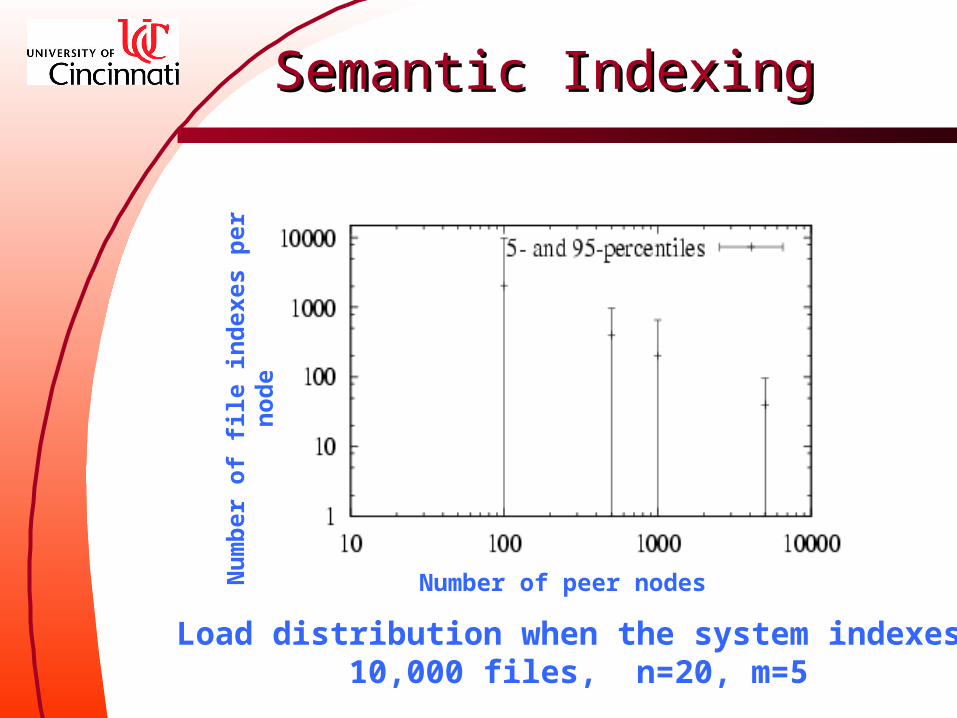
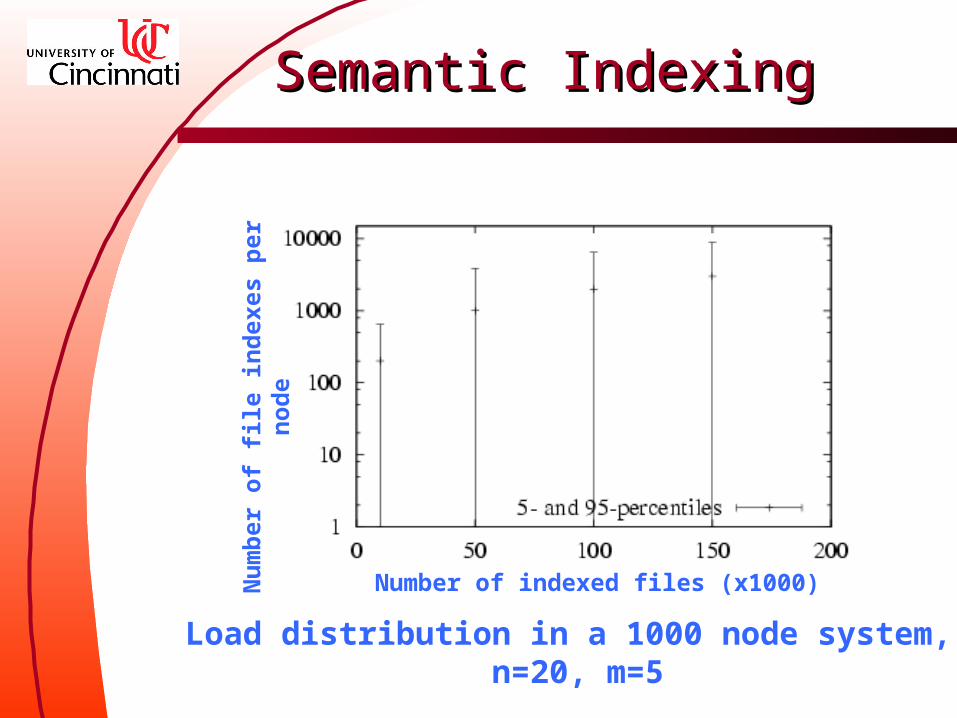
Load distribution of semantic indexing Semantic indices per peer node
Performance of semantic locating Percentage of semantically close files
that can be located
Semantic IndexingSemantic Indexing
Number of peer nodesNu
mb
er o
f fi
le i
nd
exes
per
no
de
Load distribution when the system indexes 10,000 files, n=20, m=5
Semantic IndexingSemantic Indexing
Nu
mb
er o
f fi
le i
nd
exes
per
no
de
Number of indexed files (x1000)
Load distribution in a 1000 node system, n=20, m=5

Perf. of Semantic LocatingPerf. of Semantic Locating
5 10 15 20
5 84% 92% 94% 96%
2 94% 99% 100% 100%
m
npercentage
[1] Apply n groups of m hash functions
[2] Percentage of files located (128-byte fingerprint limit as a SV) [3] m and n determine the performance of semantic locating

ConclusionsConclusions
The first step to support semantics-based access in P2P file systems
LSH-based semantic indexing and locating approach Impose small storage overhead (several MBs) Efficiency: answer a query by consulting a sma
ll number of peers (e.g., 20) Approximate results, but acceptable
Future work: query consistency and refinement, evaluation using IR workloads etc.


















