
Instruction Selection Presented by Huang Kuo-An, Lu Kuo-Chang Subproject 3 A. Aho, M. Lam, R. Sethi,...
134
Instruction Selection Presented by Huang Kuo-An, Lu Kuo-Chang Subproject 3 A. Aho, M. Lam, R. Sethi, J. Ullman, “Instruction Selection by Tree Rewriting.” Compilers: Principles, Techniques & Tools”, 2 nd edition, Pearson Education, Inc, 2007. pp 558-563. “The LLVM Target-Independent Code Generator: Instruction Selection.”
-
Upload
braydon-ozanne -
Category
Documents
-
view
218 -
download
0
Transcript of Instruction Selection Presented by Huang Kuo-An, Lu Kuo-Chang Subproject 3 A. Aho, M. Lam, R. Sethi,...

Instruction Selection Presented byHuang Kuo-An, Lu Kuo-ChangSubproject 3
A. Aho, M. Lam, R. Sethi, J. Ullman, “Instruction Selection by Tree Rewriting.” Compilers: Principles, Techniques & Tools”, 2nd edition, Pearson Education, Inc, 2007. pp 558-563.
“The LLVM Target-Independent Code Generator: Instruction Selection.” http://llvm.org/docs/CodeGenerator.html#instselect

Outline
•Introducing LLVM•Instruction Selection
▫Tree Rewriting•Why we use LLVM?•Progress

Introducing LLVM
•The LLVM compiler infrastructure ▫Provides modular & reusable components.▫Reduces the time & cost to build a
particular compiler.▫Those components shared across different
compiles.

LLVM
IR
The Steps of the LLVM Compiler
Language Front-endLanguage Front-end
C
C++

LLVM
IR
The Steps of the LLVM Compiler
Language Front-endLanguage Front-end
C
C++
either one

LLVM
IR
The Steps of the LLVM Compiler
Language Front-endLanguage Front-end
C
C++
An intermediate representation:Lower than the high level language (simple instructions, no for loops, etc)
Higher than the machine code(no opcodes, no registers, etc)

LLVM
IR
The Steps of the LLVM Compiler
Language Front-endLanguage Front-end
C
C++
An intermediate representation:Lower than the high level language (simple instructions, no for loops, etc)
Higher than the machine code(no opcodes, no registers, etc)
source language
independent
target processor
independent

LLVM
IR
The Steps of the LLVM Compiler
Language Front-endLanguage Front-end
Mid-level OptimizerMid-level Optimizer
LLVM
IR
C
C++

LLVM
IR
The Steps of the LLVM Compiler
Language Front-endLanguage Front-end
Mid-level OptimizerMid-level Optimizer
LLVM
IR
C
C++
Code Generatio
n
Code Generatio
n
.s file
executable

LLVM
IR
The Steps of the LLVM Compiler
Language Front-endLanguage Front-end
Mid-level OptimizerMid-level Optimizer
LLVM
IR
C
C++
Code Generatio
n
Code Generatio
n
.s file
executable
Instruction
Selection
Instruction
Selection
Schedulin
g
Schedulin
g
Register AllocationRegister
Allocation
Machine-specific
Optimizations
Machine-specific
Optimizations
Code Emission
Code Emission
Target Machine Instructions
LLVM IR

Instruction Selection
How does the com-piler translate a C instruction like this:
Into machine code like this:
a[i] = b+1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1ST *R0, R1

Instruction Selection
How does the com-piler translate a C instruction like this:
Into machine code like this:
a[i] = b+1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1ST *R0, R1
First Answer: break it into two steps

Instruction Selection
How does the com-piler translate a C instruction like this:
Into machine code like this:
a[i] = b+1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1ST *R0, R1
The intermediate representation (IR):
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
Ca Rsp
First Answer: break it into two steps

Instruction Selection
Into machine code like this:
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1ST *R0, R1
The intermediate representation (IR):
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
Ca Rsp

Instruction Selection
Into machine code like this:
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1ST *R0, R1
New question: How to go from IR to machine code?
The intermediate representation (IR):
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
Ca Rsp

Instruction Selection
One answer: use tree rewriting
Into machine code like this:
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1ST *R0, R1
The intermediate representation (IR):
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
Ca Rsp

Tree Rewriting
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
Ca Rsp
Ri Ca
Ri Mx
M =
Mx Ri
Ri ind
Ca Rj
+
M =
ind Rj
Ri
Ri
ind
Ca Rj
+
+
Ri
Ri +
Ri Rj
Ri +
Ri C1
{LD Ri, #a}
{LD Ri, x}
{ST x, Ri}
{LD Ri, a(Rj)}
{ST *Ri, Rj}
{ADD Ri, Ri, a(Rj)}
{ADD Ri, Ri, Rj}
{INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
Ca Rsp
Ri Ca
Ri Mx
M =
Mx Ri
Ri ind
Ca Rj
+
M =
ind Rj
Ri
Ri
ind
Ca Rj
+
+
Ri
Ri +
Ri Rj
Ri +
Ri C1
{LD Ri, #a}
{LD Ri, x}
{ST x, Ri}
{LD Ri, a(Rj)}
{ST *Ri, Rj}
{ADD Ri, Ri, a(Rj)}
{ADD Ri, Ri, Rj}
{INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
Ca Rsp
Ri Ca
Ri Mx
M =
Mx Ri
Ri ind
Ca Rj
+
M =
ind Rj
Ri
Ri
ind
Ca Rj
+
+
Ri
Ri +
Ri Rj
Ri +
Ri C1
{LD Ri, #a}
{LD Ri, x}
{ST x, Ri}
{LD Ri, a(Rj)}
{ST *Ri, Rj}
{ADD Ri, Ri, a(Rj)}
{ADD Ri, Ri, Rj}
{INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
R0 Rsp
Ri Ca
Ri Mx
M =
Mx Ri
Ri ind
Ca Rj
+
M =
ind Rj
Ri
Ri
ind
Ca Rj
+
+
Ri
Ri +
Ri Rj
Ri +
Ri C1
{LD Ri, #a}
{LD Ri, x}
{ST x, Ri}
{LD Ri, a(Rj)}
{ST *Ri, Rj}
{ADD Ri, Ri, a(Rj)}
{ADD Ri, Ri, Rj}
{INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
R0 Rsp
Ri Ca
Ri Mx
M =
Mx Ri
Ri ind
Ca Rj
+
M =
ind Rj
Ri
Ri
ind
Ca Rj
+
+
Ri
Ri +
Ri Rj
Ri +
Ri C1
LD R0, #a
{LD Ri, #a}
{LD Ri, x}
{ST x, Ri}
{LD Ri, a(Rj)}
{ST *Ri, Rj}
{ADD Ri, Ri, a(Rj)}
{ADD Ri, Ri, Rj}
{INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
R0 Rsp
Ri Ca
Ri Mx
M =
Mx Ri
Ri ind
Ca Rj
+
M =
ind Rj
Ri
Ri
ind
Ca Rj
+
+
Ri
Ri +
Ri Rj
Ri +
Ri C1
LD R0, #a
{LD Ri, #a}
{LD Ri, x}
{ST x, Ri}
{LD Ri, a(Rj)}
{ST *Ri, Rj}
{ADD Ri, Ri, a(Rj)}
{ADD Ri, Ri, Rj}
{INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1+
ind+
+
Ci Rsp
R0 Rsp
Ri Ca
Ri Mx
M =
Mx Ri
Ri ind
Ca Rj
+
M =
ind Rj
Ri
Ri
ind
Ca Rj
+
+
Ri
Ri +
Ri Rj
Ri +
Ri C1
LD R0, #a
{LD Ri, #a}
{LD Ri, x}
{ST x, Ri}
{LD Ri, a(Rj)}
{ST *Ri, Rj}
{ADD Ri, Ri, a(Rj)}
{ADD Ri, Ri, Rj}
{INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
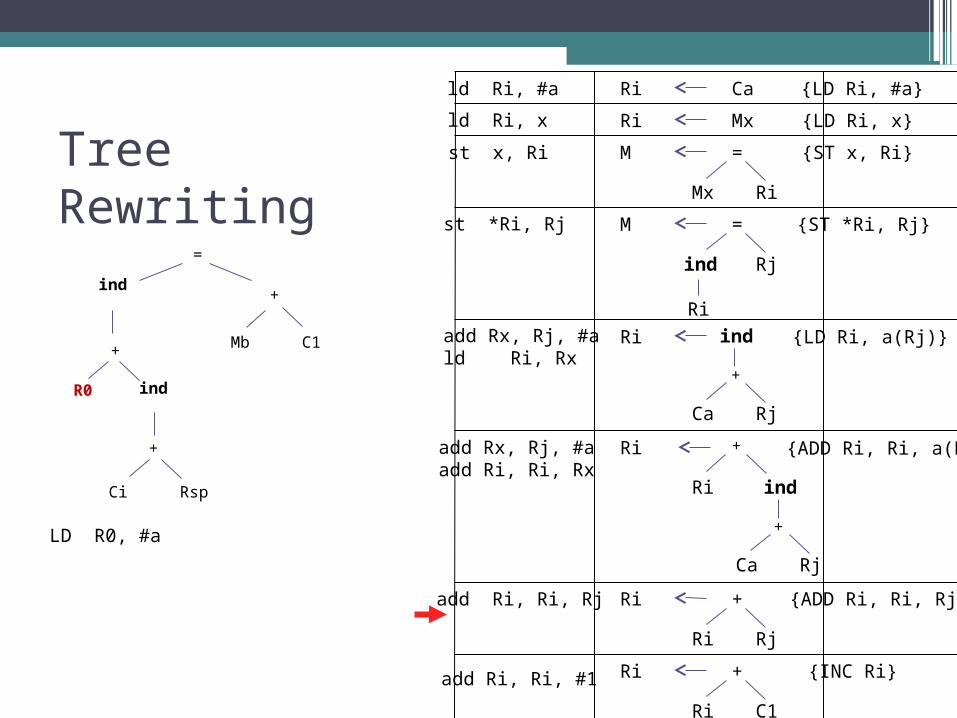
Tree Rewriting
ind
Mb
+
=
C1+
ind
+
Ci Rsp
R0
Ri Ca
Ri Mx
M =
Mx Ri
Ri ind
Ca Rj
+
M =
ind Rj
Ri
Ri
ind
Ca Rj
+
+
Ri
Ri +
Ri Rj
Ri +
Ri C1
LD R0, #a
{LD Ri, #a}
{LD Ri, x}
{ST x, Ri}
{LD Ri, a(Rj)}
{ST *Ri, Rj}
{ADD Ri, Ri, a(Rj)}
{ADD Ri, Ri, Rj}
{INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
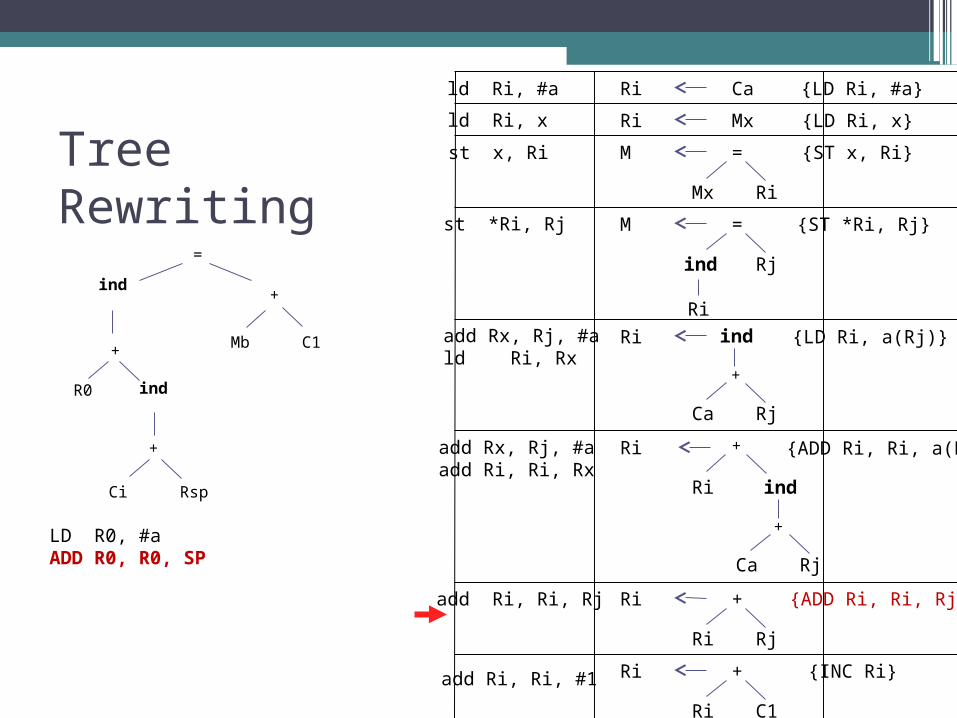
Tree Rewriting
ind
Mb
+
=
C1+
ind
+
Ci Rsp
R0
Ri Ca
Ri Mx
M =
Mx Ri
Ri ind
Ca Rj
+
M =
ind Rj
Ri
Ri
ind
Ca Rj
+
+
Ri
Ri +
Ri Rj
Ri +
Ri C1
LD R0, #aADD R0, R0, SP
{LD Ri, #a}
{LD Ri, x}
{ST x, Ri}
{LD Ri, a(Rj)}
{ST *Ri, Rj}
{ADD Ri, Ri, a(Rj)}
{ADD Ri, Ri, Rj}
{INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1+
ind
+
Ci Rsp
R0
Ri Ca
Ri Mx
M =
Mx Ri
Ri ind
Ca Rj
+
M =
ind Rj
Ri
Ri
ind
Ca Rj
+
+
Ri
Ri +
Ri Rj
Ri +
Ri C1
LD R0, #aADD R0, R0, SP
{LD Ri, #a}
{LD Ri, x}
{ST x, Ri}
{LD Ri, a(Rj)}
{ST *Ri, Rj}
{ADD Ri, Ri, a(Rj)}
{ADD Ri, Ri, Rj}
{INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1+
ind
+
Ci Rsp
R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SP
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1+
ind
+
Ci Rsp
R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SP
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SP
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
Mb
+
=
C1R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
R1
+
=
C1R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
R1
+
=
C1R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, b
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
R1
+
=
C1R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, b
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind
R1
+
=
C1R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, b
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind R1
=
R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, b
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind R1
=
R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind R1
=
R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
ind R1
=
R0
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Tree Rewriting
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
M

Tree Rewriting
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1ST *R0, R1
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
M

Tree Rewriting
Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
Ri C1
LD R0, #aADD R0, R0, SPADD R0, R0, i(SP)LD R1, bINC R1ST *R0, R1
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1

Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
ld Ri, #a
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
Ri C1
But actually, something is missing…
The IR immediate value, #a, does not have a size limit, but the actual machine has a limited number of bits for the immediate value (let’s say, 16 bits)

Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
ld Ri, #a (a≤FFFF)
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
Ri C1
But actually, something is missing…
So we ought to state that this tree rewriting rule only applies when the immediate value can be expressed in 16 bits (ie, a≤FFFF)

Ri Ca {LD Ri, #a}
Ri Mx {LD Ri, x}
M = {ST x, Ri}
Mx Ri
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
ld Ri, #a (a≤FFFF)
ld Ri, x
st x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
Ri C1
But what about if a cannot be expressed in 16 bits ?
Then we need a new rule:
But actually, something is missing…

Ri
Ri {LD Ri, #a}
Ri Mx {LD Ri, x}M = {ST x, Ri}
Mx
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
ld Ri, #a (a≤FFFF)
ld Ri, xst x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
Ri C1
Ca
But what about if a cannot be expressed in 16 bits ?
Then we need a new rule:
But actually, something is missing…

Ri
Ri {LD Ri, #a}
Ri Mx {LD Ri, x}M = {ST x, Ri}
Mx
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
ld Ri, #a (a≤FFFF)
ld Ri, xst x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
Ri C1
ld Ri, #a (a>FFFF)
Ca
But what about if a cannot be expressed in 16 bits ?
Then we need a new rule:
But actually, something is missing…

Ri
Ri {LD Ri, #a}
Ri Mx {LD Ri, x}M = {ST x, Ri}
Mx
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
ld Ri, #a (a≤FFFF)
ld Ri, xst x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
Ri C1
ld Ri, #a (a>FFFF)
Ca
But actually, something is missing…
The problem is the target processor does not have an instruction for 32-bit immediates. Instead, a set of machine instructions is needed. We call this set a pattern.

Ri
Ri
Ca
{LD Ri, #a}
Ri Mx {LD Ri, x}M = {ST x, Ri}
Mx
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
ld Ri, #a (a≤FFFF)
ld Ri, xst x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
Ri C1
Ri {LD Ri, low16(#a) LD Rj, high16(#a)SHR Rj, Rj, #16ADD Ri, Ri, Rj}
ld Ri, #a (a>FFFF)
Ca
But actually, something is missing…
The problem is the target processor does not have an instruction for 32-bit immediates. Instead, a set of machine instructions is needed. We call this set a pattern.

•One-to-One add R1,R1,#1
Kinds of the tree rewriting rules

•One-to-One add R1,R1,#1 INC Ri
Kinds of the tree rewriting rules

•One-to-One add R1,R1,#1 INC Ri
•Many-to-One add Rx,Rj ,#a add Ri ,Ri ,Rx
Kinds of the tree rewriting rules

•One-to-One add R1,R1,#1 INC Ri
•Many-to-One add Rx,Rj ,#a ADD Ri,Ri,a(Rj) add Ri ,Ri ,Rx
Kinds of the tree rewriting rules

•One-to-One add R1,R1,#1 INC Ri
•Many-to-One add Rx,Rj ,#a ADD Ri,Ri,a(Rj) add Ri ,Ri ,Rx
•One-to-Many ld Ri, #a (a>0xFFFF)
Kinds of the tree rewriting rules

•One-to-One add R1,R1,#1 INC Ri
•Many-to-One add Rx,Rj ,#a ADD Ri,Ri,a(Rj) add Ri ,Ri ,Rx
•One-to-Many ld Ri, #a (a>0xFFFF) LD Ri, low16(#a)
LD Rj, high16(#a)SHL Rj, #16ADD Ri, Ri, Rj
Kinds of the tree rewriting rules

So, what’s the point?
To design an instruction selector, you do not need to write a program. Just define a set of rewriting rules.

Ri
Ri
Ca
{LD Ri, #a}
Ri Mx {LD Ri, x}M = {ST x, Ri}
Mx
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
ld Ri, #a (a≤FFFF)
ld Ri, xst x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
Ri C1
Ri {LD Ri, low16(#a) LD Rj, high16(#a)SHR Rj, Rj, #16ADD Ri, Ri, Rj}
ld Ri, #a (a>FFFF)
Ca
So, what’s the point?
To design an instruction selector, you do not need to write a program. Just define a set of rewriting rules.

Ri
Ri
Ca
{LD Ri, #a}
Ri Mx {LD Ri, x}M = {ST x, Ri}
Mx
Ri ind {LD Ri, a(Rj)}
Ca Rj
+
M = {ST *Ri, Rj}
ind Rj
Ri
Ri
ind
{ADD Ri, Ri, a(Rj)}
Ca Rj
+
+
Ri
Ri + {ADD Ri, Ri, Rj}
Ri Rj
Ri + {INC Ri}
ld Ri, #a (a≤FFFF)
ld Ri, xst x, Ri
st *Ri, Rj
add Rx, Rj, #ald Ri, Rx
add Rx, Rj, #aadd Ri, Ri, Rx
add Ri, Ri, Rj
add Ri, Ri, #1
Ri C1
Ri {LD Ri, low16(#a) LD Rj, high16(#a)SHR Rj, Rj, #16ADD Ri, Ri, Rj}
ld Ri, #a (a>FFFF)
Ca
So, what’s the point?
To design an instruction selector, you do not need to write a program. Just define a set of rewriting rules.
Then use an existing instruction selection program to apply your set of rules. The LLVM compiler has such a selector.

Instruction SelectionSuppose you want to use the LLVM compiler to create PowerPC code.The PowerPC has a single-precision floating point add instruction:
FADDS T1, X, YHow can we allow the LLVM compiler to generate FADDS instructions?We need to create a tree rewriting rule in the LLVM format:

Instruction SelectionSuppose you want to use the LLVM compiler to create PowerPC code.The PowerPC has a single-precision floating point add instruction:
FADDS T1, A, BQ:How can we allow the LLVM compiler to generate FADDS instructions?We need to create a tree rewriting rule in the LLVM format:
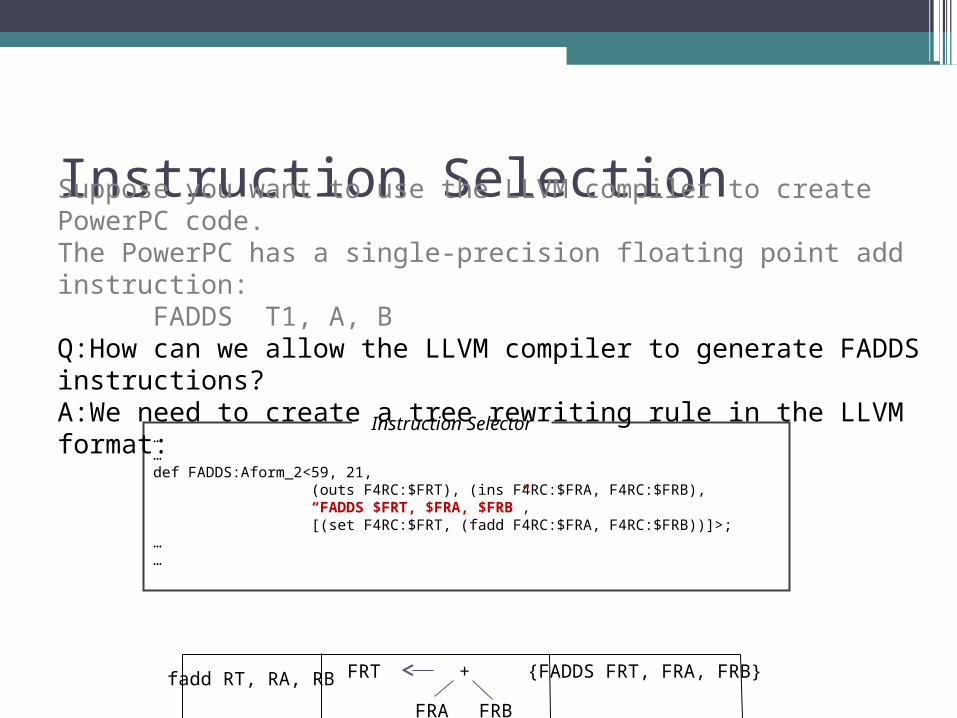
Instruction Selection
……def FADDS:Aform_2<59, 21, (outs F4RC:$FRT), (ins F4RC:$FRA, F4RC:$FRB), “FADDS $FRT, $FRA, $FRB”, [(set F4RC:$FRT, (fadd F4RC:$FRA, F4RC:$FRB))]>;……
Instruction Selector
Suppose you want to use the LLVM compiler to create PowerPC code.The PowerPC has a single-precision floating point add instruction:
FADDS T1, A, BQ:How can we allow the LLVM compiler to generate FADDS instructions?A:We need to create a tree rewriting rule in the LLVM format:
FRA FRB
FRT + {FADDS FRT, FRA, FRB}fadd RT, RA, RB

Instruction SelectionThe PowerPC also has a single-precision floating point multiply instruction:
FMULS T1, X, YSo we need to create a tree rewriting rule for it too:

……def FADDS:Aform_2<59, 21, (outs F4RC:$FRT), (ins F4RC:$FRA, F4RC:$FRB), “FADDS $FRT, $FRA, $FRB”, [(set F4RC:$FRT, (fadd F4RC:$FRA, F4RC:$FRB))]>;def FMULS:Aform_3<59, 25, (outs F4RC:$FRT), (ins F4RC:$FRA, F4RC:$FRB), “FMULS $FRT, $FRA, $FRB”, [(set F4RC:$FRT, (fmul F4RC:$FRA, F4RC:$FRB))]>;……
Instruction Selection
Instruction Selector
The PowerPC also has a single-precision floating point multiply instruction:
FMULS T1, X, YSo we need to create a tree rewriting rule for it too:
FRA FRB
FRT * {FMULS FRT, FRA, FRB}fmul RT, RA, RB
FRT + {FADDS FRT, FRA, FRB}fadd RT, RA, RB
FRA FRA

Instruction SelectionWith these two rules, we could now generate PowerPC code for the following LLVM IR:
FRA FRB
FRT * {FMULS FRT, FRA, FRB}fmul RT, RA, RB
FRT + {FADDS FRT, FRA, FRB}fadd RT, RA, RB
fadd:f32 X, Y FADDS t2, t1, Z
%t1 = mul float %X, %Y%t2 = add float %t1, %Z
fmul:f32 X, Y FMULS t1, X, Y
FRA FRB

Instruction SelectionBut wait! PowerPC has the FMADDS instruction that performs both a multiply and an add. Why didn’t the compiler choose that instruction?
Because no tree rewriting rule was defined for FMADDS.
What are the consequences of not giving a rule for FMADDS? Broken compiler? No. Why not? Because the FMADDS instruction’s function can also be performed by other PowerPC instructions that were defined.
(But, if FADDS was not defined the compiler would be broken.) Bad compiler? Yes. Why? FMADDS will never be used, and its faster than FMULS +FADDS
fadd:f32 X, Y FADDS t2, t1, Z
%t1 = mul float %X, %Y%t2 = add float %t1, %Z
fmul:f32 X, Y FMULS t1, X, Y

Instruction SelectionBut wait! PowerPC has the FMADDS instruction that performs both a multiply and an add. Why didn’t the compiler choose that instruction?
Because no tree rewriting rule was defined for FMADDS.
What are the consequences of not giving a rule for FMADDS? Broken compiler? No. Why not? Because the FMADDS instruction’s function can also be performed by other PowerPC instructions that were defined.
(But, if FADDS was not defined the compiler would be broken.) Bad compiler? Yes. Why? FMADDS will never be used, and its faster than FMULS +FADDS
fadd:f32 X, Y FADDS t2, t1, Z
%t1 = mul float %X, %Y%t2 = add float %t1, %Z
fmul:f32 X, Y FMULS t1, X, Y

Instruction SelectionBut wait! PowerPC has the FMADDS instruction that performs both a multiply and an add. Why didn’t the compiler choose that instruction?
Because no tree rewriting rule was defined for FMADDS.
What are the consequences of not giving a rule for FMADDS? Broken compiler? No. Why not? Because the FMADDS instruction’s function can also be performed by other PowerPC instructions that were defined.
(But, if FADDS was not defined the compiler would be broken.) Bad compiler? Yes. Why? FMADDS will never be used, and its faster than FMULS +FADDS
fadd:f32 X, Y FADDS t2, t1, Z
%t1 = mul float %X, %Y%t2 = add float %t1, %Z
fmul:f32 X, Y FMULS t1, X, Y

Instruction SelectionBut wait! PowerPC has the FMADDS instruction that performs both a multiply and an add. Why didn’t the compiler choose that instruction?
Because no tree rewriting rule was defined for FMADDS.
What are the consequences of not giving a rule for FMADDS? Broken compiler? No. Why not? Because the FMADDS instruction’s function can also be performed by other PowerPC instructions that were defined.
(But, if FADDS was not defined the compiler would be broken.) Bad compiler? Yes. Why? FMADDS will never be used, and its faster than FMULS +FADDS
fadd:f32 X, Y FADDS t2, t1, Z
%t1 = mul float %X, %Y%t2 = add float %t1, %Z
fmul:f32 X, Y FMULS t1, X, Y

Instruction SelectionBut wait! PowerPC has the FMADDS instruction that performs both a multiply and an add. Why didn’t the compiler choose that instruction?
Because no tree rewriting rule was defined for FMADDS.
What are the consequences of not giving a rule for FMADDS? Broken compiler? No. Why not? Because the FMADDS instruction’s function can also be performed by other PowerPC instructions that were defined.
(But, if FADDS was not defined the compiler would be broken.) Bad compiler? Yes. Why? FMADDS will never be used, and its faster than FMULS +FADDS
fadd:f32 X, Y FADDS t2, t1, Z
%t1 = mul float %X, %Y%t2 = add float %t1, %Z
fmul:f32 X, Y FMULS t1, X, Y

Instruction SelectionBut wait! PowerPC has the FMADDS instruction that performs both a multiply and an add. Why didn’t the compiler choose that instruction?
Because no tree rewriting rule was defined for FMADDS.
What are the consequences of not giving a rule for FMADDS? Broken compiler? No. Why not? Because the FMADDS instruction’s function can also be performed by other PowerPC instructions that were defined.
(But, if FADDS was not defined the compiler would be broken.) Bad compiler? Yes. Why? FMADDS will never be used, and its faster than FMULS +FADDS
fadd:f32 X, Y FADDS t2, t1, Z
%t1 = mul float %X, %Y%t2 = add float %t1, %Z
fmul:f32 X, Y FMULS t1, X, Y

Instruction SelectionBut wait! PowerPC has the FMADDS instruction that performs both a multiply and an add. Why didn’t the compiler choose that instruction?
Because no tree rewriting rule was defined for FMADDS.
What are the consequences of not giving a rule for FMADDS? Broken compiler? No. Why not? Because the FMADDS instruction’s function can also be performed by other PowerPC instructions that were defined.
(But, if FADDS was not defined the compiler would be broken.) Bad compiler? Yes. Why? FMADDS will never be used, and its faster than FMULS +FADDS
fadd:f32 X, Y FADDS t2, t1, Z
%t1 = mul float %X, %Y%t2 = add float %t1, %Z
fmul:f32 X, Y FMULS t1, X, Y

Instruction SelectionBut wait! PowerPC has the FMADDS instruction that performs both a multiply and an add. Why didn’t the compiler choose that instruction?
Because no tree rewriting rule was defined for FMADDS.
What are the consequences of not giving a rule for FMADDS? Broken compiler? No. Why not? Because the FMADDS instruction’s function can also be performed by other PowerPC instructions that were defined.
(But, if FADDS was not defined the compiler would be broken.) Bad compiler? Yes. Why? FMADDS will never be used, and its faster than FMULS +FADDS
fadd:f32 X, Y FADDS t2, t1, Z
%t1 = mul float %X, %Y%t2 = add float %t1, %Z
fmul:f32 X, Y FMULS t1, X, Y

Instruction SelectionBut wait! PowerPC has the FMADDS instruction that performs both a multiply and an add. Why didn’t the compiler choose that instruction?
Because no tree rewriting rule was defined for FMADDS.
What are the consequences of not giving a rule for FMADDS? Broken compiler? No. Why not? Because the FMADDS instruction’s function can also be performed by other PowerPC instructions that were defined.
(But, if FADDS was not defined the compiler would be broken.) Bad compiler? Yes. Why? FMADDS will never be used, and its faster than FMULS +FADDS
fadd:f32 X, Y FADDS t2, t1, Z
%t1 = mul float %X, %Y%t2 = add float %t1, %Z
fmul:f32 X, Y FMULS t1, X, Y

……def FADDS:Aform_2<59, 21, (outs F4RC:$FRT), (ins F4RC:$FRA, F4RC:$FRB), “FADDS $FRT, $FRA, $FRB”, [(set F4RC:$FRT, (fadd F4RC:$FRA, F4RC:$FRB))]>;def FMULS:Aform_3<59, 25, (outs F4RC:$FRT), (ins F4RC:$FRA, F4RC:$FRB), “FMULS $FRT, $FRA, $FRB”, [(set F4RC:$FRT, (fmul F4RC:$FRA, F4RC:$FRB))]>;def FMADDS:Aform_1<59, 29, (ops F4RC:$FRT, F4RC:$FRA, F4RC:$FRC, F4RC:$FRB), “FMADDS $FRT, $FRA, $FRC, $FRB”, [(set F4RC:$FRT, (fadd (fmul F4RC:$FRA, F4RC:$FRC), F4RC:$FRB))]>;……
Instruction Selection
Instruction Selector
We can add a new rule for the PowerPC’s multiply and add instruction:
FMADDS T1, A, B, C
FRA FRB
FRT * {FMULS FRT, FRA, FRB}fmul RT, RA, RB
FRT + {FADDS FRT, FRA, FRB}fadd RT, RA, RB
FRA FRC
FRT
*
{FMADDS FRT, FRA, FRB, FRC}fmul RT1, RA, RC
fadd RT2, RT1, RB
+
FRB
FRA FRB

•One-to-One add R1,R1,#1 INC Ri
•Many-to-One add Rx,Rj ,#a ADD Ri,Ri,a(Rj) add Ri ,Ri ,Rx
•One-to-Many ld Ri, #a (a>0xFFFF) LD Ri, low16(#a)
LD Rj, high16(#a)SHL Rj, #16ADD Ri, Ri, Rj
3 Kinds of the tree rewriting rules

•One-to-One add R1,R1,#1 INC Ri
•Many-to-One add Rx,Rj ,#a ADD Ri,Ri,a(Rj) add Ri ,Ri ,Rx
•One-to-Many ld Ri, #a (a>0xFFFF) LD Ri, low16(#a)
LD Rj, high16(#a)SHL Rj, #16ADD Ri, Ri, Rj
3 Kinds of the tree rewriting rules FMADDS is
a Many-to-
One
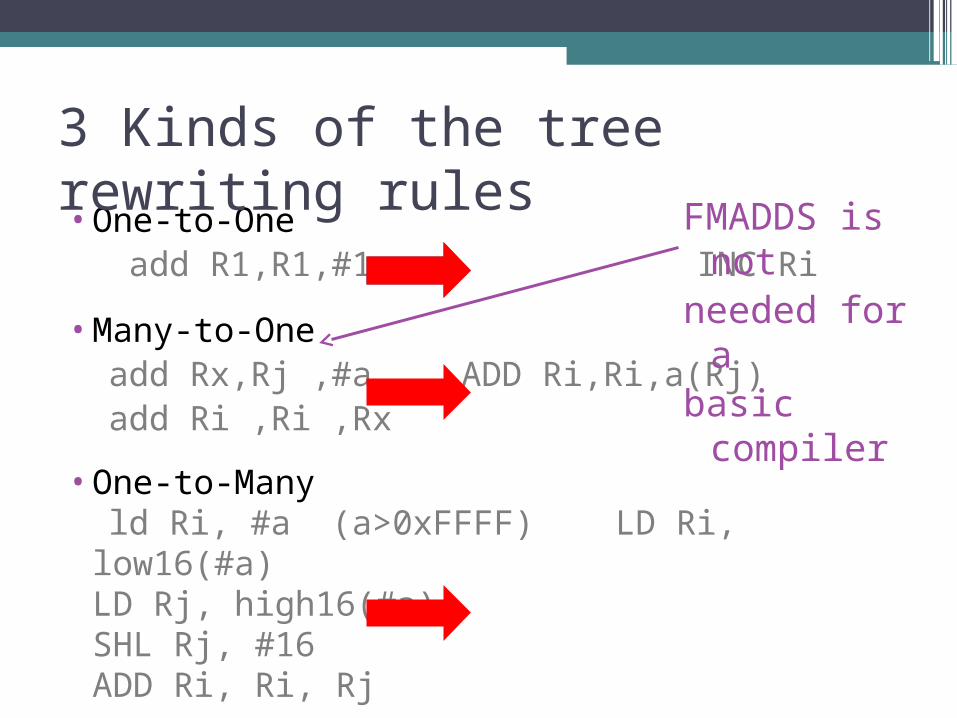
•One-to-One add R1,R1,#1 INC Ri
•Many-to-One add Rx,Rj ,#a ADD Ri,Ri,a(Rj) add Ri ,Ri ,Rx
•One-to-Many ld Ri, #a (a>0xFFFF) LD Ri, low16(#a)
LD Rj, high16(#a)SHL Rj, #16ADD Ri, Ri, Rj
3 Kinds of the tree rewriting rules FMADDS is
not needed for a basic
compiler

•One-to-One add R1,R1,#1 INC Ri
•Many-to-One add Rx,Rj ,#a ADD Ri,Ri,a(Rj) add Ri ,Ri ,Rx
•One-to-Many ld Ri, #a (a>0xFFFF) LD Ri, low16(#a)
LD Rj, high16(#a)SHL Rj, #16ADD Ri, Ri, Rj
3 Kinds of the tree rewriting rules Infact, many-
to-ones can all
be skipped.

•One-to-One add R1,R1,#1 INC Ri
•Many-to-One add Rx,Rj ,#a ADD Ri,Ri,a(Rj) add Ri ,Ri ,Rx
•One-to-Many ld Ri, #a (a>0xFFFF) LD Ri, low16(#a)
LD Rj, high16(#a)SHL Rj, #16ADD Ri, Ri, Rj
3 Kinds of the tree rewriting rules

We will use the LLVM compiler
Because:•It has good optimizations
•It has good documentation
•It is designed to be a little bit easier to retarget to a new processor
•It was the compiler used by subproject 3, year 1 – so there is some infrastructure

But there are some difficulties with the LLVM compiler
Because:•It compiles C, not OpenGL 2.0
•Though it has backends for several processors, none of them are SIMD
•So, the LLVM IR is not SIMD

How we will use the LLVM compiler
Our work is in two parallel paths:•Fast track: uses Subproject 2’s code to
convert OPENGL to C•Slow track: use Subproject 3 year 1’s code
to generate SIMD instructions in the LLVM IR

A quick reminder• OpenGL 2.0 code is stored in a string array.
• It is not compiled until the game is actually running.
• At some point during the running of the game, the game calls glCompileShader, which takes the string array as an input argument and returns an object file.
• Maybe the player entered a new level, and the new level has brick walls. But the previous level did not have brick walls, so the graphics processor does not have a rule for how to render bricks.
• The brick shader must be compiled, linked, and loaded to the graphics processor. • This is accomplished through 3 operating system calls from within the game
• glCompileShader(…)• glLinkProgram(…)• glUseProgram(…)
• Our current work is only on the implementation of glCompileShader.
• glCompileShader is a program that runs on the ARM processor, when called by the ARM’s OS.
• So, our compiler (which is written in C++) is compiled into an ARM executable. But when this compiler executable is run, it generates a shader executable.

iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse +
SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
A sample OpenGL codeHere is some shader code:
shader string array

void AddBrickFragments(GLuint currentProgram) {
GLuint brickFS = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(brickFS, 1, brickStringArray, NULL);
glCompileShader(brickFS);
glAttachShader(currentProgram,brickFS);
glLinkProgram(currentProgram);
glUseProgram(currentProgram);}
A sample compilation triggerAnd here is a function inside of the game that compiles and loads the shader:
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array

void AddBrickFragments(GLuint currentProgram) {
GLuint brickFS = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(brickFS, 1, brickStringArray, NULL);
glCompileShader(brickFS);
glAttachShader(currentProgram,brickFS);
glLinkProgram(currentProgram);
glUseProgram(currentProgram);}
A sample compilation triggerAnd here is a function inside of the game that compiles and loads the shader:
shader string array
game running on ARM
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
void AddBrickFragments(Gluint currentProgram) { GLuint brickFS =glCreateShader( GL_FRAGMENT_SHADER);glShaderSource(brickFS, 1, brickStringArray, NULL);glCompileShader(brickFS);glAttachShader(currentProgram,brickFS); glLinkProgram(currentProgram);glUseProgram(currentProgram);}

The fast track compiler process1. So now, as the game runs, this call
to glCompileShader happens2. Then the ARM processor calls the
LLVM compiler, passing in this code for compilation
3. The LLVM compiler then:1. Runs Proj2Converter to make C code2. Runs the LLVM front end to create IR3. Runs our new LLVM backend to create
shader object file4. Sends the object file back to the game
void AddBrickFragments(Gluint currentProgram) { GLuint brickFS =glCreateShader( GL_FRAGMENT_SHADER);glShaderSource(brickFS, 1, brickStringArray, NULL);glCompileShader(brickFS);glAttachShader(currentProgram,brickFS); glLinkProgram(currentProgram);glUseProgram(currentProgram);}
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
game running on ARM

The fast track compiler process1. So now, as the game runs, this call
to glCompileShader happens2. Then the ARM processor calls the
LLVM compiler, passing in this code for compilation
3. The LLVM compiler then:1. Runs Proj2Converter to make C code2. Runs the LLVM front end to create IR3. Runs our new LLVM backend to create
shader object file4. Sends the object file back to the game
void AddBrickFragments(Gluint currentProgram) { GLuint brickFS =glCreateShader( GL_FRAGMENT_SHADER);glShaderSource(brickFS, 1, brickStringArray, NULL);glCompileShader(brickFS);glAttachShader(currentProgram,brickFS); glLinkProgram(currentProgram);glUseProgram(currentProgram);}
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
game running on ARM

The fast track compiler process1. So now, as the game runs, this call
to glCompileShader happens2. Then the ARM processor calls the
LLVM compiler, passing in this code for compilation
3. The LLVM compiler then:1. Runs Proj2Converter to make C code2. Runs the LLVM front end to create IR3. Runs our new LLVM backend to create
shader object file4. Sends the object file back to the game
void AddBrickFragments(Gluint currentProgram) { GLuint brickFS =glCreateShader( GL_FRAGMENT_SHADER);glShaderSource(brickFS, 1, brickStringArray, NULL);glCompileShader(brickFS);glAttachShader(currentProgram,brickFS); glLinkProgram(currentProgram);glUseProgram(currentProgram);}
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
game running on ARM
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
equivalent C code
Proj2converter

void AddBrickFragments(Gluint currentProgram) { GLuint brickFS =glCreateShader( GL_FRAGMENT_SHADER);glShaderSource(brickFS, 1, brickStringArray, NULL);glCompileShader(brickFS);glAttachShader(currentProgram,brickFS); glLinkProgram(currentProgram);glUseProgram(currentProgram);}
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
game running on ARM
The fast track compiler process1. So now, as the game runs, this call
to glCompileShader happens2. Then the ARM processor calls the
LLVM compiler, passing in this code for compilation
3. The LLVM compiler then:1. Runs Proj2Converter to make C code2. Runs the LLVM front end to create IR3. Runs our new LLVM backend to create
shader object file4. Sends the object file back to the game
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
equivalent C code
Proj2converter

1. So now, as the game runs, this call to glCompileShader happens
2. Then the ARM processor calls the LLVM compiler, passing in this code for compilation
3. The LLVM compiler then:1. Runs Proj2Converter to make C code2. Runs the LLVM front end to create IR3. Runs our new LLVM backend to create
shader object file4. Sends the object file back to the game
void AddBrickFragments(Gluint currentProgram) { GLuint brickFS =glCreateShader( GL_FRAGMENT_SHADER);glShaderSource(brickFS, 1, brickStringArray, NULL);glCompileShader(brickFS);glAttachShader(currentProgram,brickFS); glLinkProgram(currentProgram);glUseProgram(currentProgram);}
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
game running on ARM
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
equivalent C code
Proj2converter
The fast track compiler process
equivalent LLVM IR
LLVMfrontend

1. So now, as the game runs, this call to glCompileShader happens
2. Then the ARM processor calls the LLVM compiler, passing in this code for compilation
3. The LLVM compiler then:1. Runs Proj2Converter to make C code2. Runs the LLVM front end to create IR3. Runs our new LLVM backend to create
shader object file4. Sends the object file back to the game
void AddBrickFragments(Gluint currentProgram) { GLuint brickFS =glCreateShader( GL_FRAGMENT_SHADER);glShaderSource(brickFS, 1, brickStringArray, NULL);glCompileShader(brickFS);glAttachShader(currentProgram,brickFS); glLinkProgram(currentProgram);glUseProgram(currentProgram);}
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
game running on ARM
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
equivalent C code
Proj2converter
equivalent LLVM IR
LLVMfrontend
The fast track compiler process

1. So now, as the game runs, this call to glCompileShader happens
2. Then the ARM processor calls the LLVM compiler, passing in this code for compilation
3. The LLVM compiler then:1. Runs Proj2Converter to make C code2. Runs the LLVM front end to create IR3. Runs our new LLVM backend to create
shader object file4. Sends the object file back to the game
void AddBrickFragments(Gluint currentProgram) { GLuint brickFS =glCreateShader( GL_FRAGMENT_SHADER);glShaderSource(brickFS, 1, brickStringArray, NULL);glCompileShader(brickFS);glAttachShader(currentProgram,brickFS); glLinkProgram(currentProgram);glUseProgram(currentProgram);}
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
game running on ARM
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
equivalent C code
Proj2converter
equivalent LLVM IR
LLVMfrontend
The fast track compiler process
……MUL R1, R2, R3MADD R4,R1,R5……
equivalent shader object file
fast trackbackend

The fast track compiler process
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
equivalent C code
Proj2converter
equivalent LLVM IR
LLVMfrontend
……MUL R1, R2, R3MADD R4,R1,R5……
equivalent shader object file
fast trackbackend

The fast track compiler process iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
equivalent C code
Proj2converter
equivalent LLVM IR
LLVMfrontend
……MUL R1, R2, R3MADD R4,R1,R5……
equivalent shader object file
fast trackbackend

The slow track compiler processIt is not good to use subproject 2’s converter:
•The compiler is run during game execution, so the conversion step adds overhead
•The conversion destroys vectors, so that you can’t create SIMD code
• After all, if C was a good fit for 3D shaders, then we wouldn’t need the OpenGL language!

The slow track compiler processThe subproject 3, year 1 team addressed this problem: •They modified the LLVM frontend to read OpenGL code instead of C code
• To handle the SIMD information expressed in the OpenGL (such as variables declared as “vec4”), they added vectors into the LLVM IR
•The problem is that the LLVM backend was not modified, so their result is a non-standard LLVM IR, that can’t be currently compiled
• The gist of our slow track development process is modifying the backend to understand the augmented IR

The fast track compiler process iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
equivalent C code
Proj2converter
equivalent LLVM IR
LLVMfrontend
……MUL R1, R2, R3MADD R4,R1,R5……
equivalent shader object file
fast trackbackend
The slow track compiler process iform vec3 LightPosition; const float SpecularContribution = 0.3;const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition;
void main(void) { vec3 ecPosition = vec3 (gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); }
shader string array
equivalent, aug-mented LLVM IR
Proj3Y1 LLVM
frontend
……SQRT R1, R2RCP R4,R1……
equivalent shader object file
slow trackbackend

Instruction selection summaryThere are then 3 steps in our instruction selector
1st cut: fast track selection- Backend changed to target the shader processors- Works but has no SIMD operation
2nd cut: slow track selection- Merge in the second backend change to understand the augmented IR- Update instruction selector to make SIMD choices
3rd cut: Create tree rewriting rules for the complex processor instructions, like SQRT and LOG

Progress
SHADER Instructions
LLVM
MOV
LD
ST
MUL
ADD
MAD
MIN
MAX
SLT
SLE
SGT
SGE
SHADER Instructions
LLVM
AND
OR
XOR
DP3
DP4
RCP
RSQ
LOG
EXP
BEQ
JMP
NOP
The following table shows the Shader Instructions. And our goal is map LLVM Instructions into our Shader Instructions.

SHADER Instructions
LLVM
MOV
LD
ST
MUL mul
ADD add
MAD
MIN
MAX
SLT setlt
SLE setle
SGT setgt
SGE setge
SHADER Instructions
LLVM
AND and
OR or
XOR xor
DP3
DP4
RCP
RSQ
LOG
EXP shl
BEQ seteq
JMP
NOP nop
The following table shows the Shader Instructions. And our goal is map LLVM Instructions into our Shader Instructions.There are some LLVM Instructions that can obviously map into our Shader Instructions.
Progress

SHADER Instructions
LLVM
MOV
LD
ST
MUL mul
ADD add
MAD
MIN
MAX
SLT setlt
SLE setle
SGT setgt
SGE setge
SHADER Instructions
LLVM
AND and
OR or
XOR xor
DP3
DP4
RCP
RSQ
LOG
EXP shl
BEQ seteq
JMP
NOP nop
We have map some of them, but there are more LLVM IR. If you have a LLVM IR without a tree rewriting rule for it, then you are not going to get a working compiler.
Progress

SHADER Instructions
LLVM
MOV
LD
ST
MUL mul
ADD add
MAD
MIN
MAX
SLT setlt
SLE setle
SGT setgt
SGE setge
SHADER Instructions
LLVM
AND and
OR or
XOR xor
DP3
DP4
RCP
RSQ
LOG
EXP shl
BEQ seteq
JMP
NOP nop
We have map some of them, but there are more LLVM IR. If you have a LLVM IR without a tree rewriting rule for it, then you are not going to get a working compiler.
These are some harder to map, which means we are going to cover these one by one.
Progress

SHADER Instructions
LLVM
MOV
LD
ST
MUL mul
ADD add
MAD
MIN
MAX
SLT setlt
SLE setle
SGT setgt
SGE setge
SHADER Instructions
LLVM
AND and
OR or
XOR xor
DP3
DP4
RCP
RSQ
LOG
EXP shl
BEQ seteq
JMP
NOP nop
Some are harder to map, which means one of 2 things:• It will require a more complicated mapping• It can be skipped (for now), it’s a many-to-one mapping
Progress

ProgressFor example, here is how we map the SHR instruction, which is easy.

ProgressFor example, here is how we map the SHR instruction, which is easy.
First, we took the MIPS backend to modify, it defines the SHR instruction like this:
def SHR : SetCC_R<0x00, 0x2a, "shr", setlt>;

ProgressFor example, here is how we map the SHR instruction, which is easy.
First, we took the MIPS backend to modify, it defines the SHR instruction like this:
def SHR : SetCC_R<0x00, 0x2a, "shr", setlt>;
Then we turn it into the following code: def SHR : SetCC_R<0x00, 0x2a, "SHR", setlt>;

ProgressFor example, here is how we map the SHR instruction, which is easy.
First, we took the MIPS backend to modify, it defines the SHR instruction like this:
def SHR : SetCC_R<0x00, 0x2a, "shr", setlt>;
Then we turn it into the following code: def SHR : SetCC_R<0x00, 0x2a, "SHR", setlt>;
Because this is a simple mapping, we can just change the the string which we can actually see in the assembly file. For now our target just to get correct assembly, not executables.

ProgressFor example, here is how we map the SHR instruction, which is easy.
First, we took the MIPS backend to modify, it defines the SHR instruction like this:
def SHR : SetCC_R<0x00, 0x2a, "shr", setlt>;
Then we turn it into the following code: def SHR : SetCC_R<0x00, 0x2a, "SHR", setlt>;
Because this is a simple mapping, we can just change the the string which we can actually see in the assembly file. For now our target just to get correct assembly, not executables.
But there are some instruction hard to map, for example, the ASHR instruction.

First, to remind what arithmetic shift right is:• It’s a shift that preserves sign extension.
Consider: if R0 = 10101010101010101010101010101010 then SHR R0,10 = 00000000001010101010101010101010 but ASHR R0,10 = 11111111111010101010101010101010 The shr was easy to make a rule for, because the
shader has an SHR instruction. But it doesn’t have an ASHR.
Q: How then can we make a rule to deal with the LLVM ashr IR instruction?
A: We’ll need to use multiple shader instructions (1 to many)

•But how to define a pattern of shader instructions?
In the example of previous slide, we see that SHR R0,10 = 00000000001010101010101010101010 ASHR R0,10 = 11111111111010101010101010101010

•But how to define a pattern of shader instructions?
In the example of previous slide, we see that SHR R0,10 = 00000000001010101010101010101010 ASHR R0,10 = 11111111111010101010101010101010
This part can be different

•But how to define a pattern of shader instructions?
In the example of previous slide, we see that SHR R0,10 = 00000000001010101010101010101010 ASHR R0,10 = 11111111111010101010101010101010
This part can be different This part is always the same

•But how to define a pattern of shader instructions?
In the example of previous slide, we see that SHR R0,10 = 00000000001010101010101010101010 ASHR R0,10 = 11111111111010101010101010101010
Left Part Right Part

•But how to define a pattern of shader instructions?
In the example of previous slide, we see that SHR R0,10 = 00000000001010101010101010101010 ASHR R0,10 = 11111111111010101010101010101010
Left Part Right PartThis part can be different This part is always the same
These are always the same

•But how to define a pattern of shader instructions?
In the example of previous slide, we see that SHR R0,10 = 00000000001010101010101010101010 ASHR R0,10 = 11111111111010101010101010101010
This number is 1023 = 210 -1, which can be computed as (1<<10) – 1

•But how to define a pattern of shader instructions?
In the example of previous slide, we see that SHR R0,10 = 00000000001010101010101010101010 ASHR R0,10 = 11111111111010101010101010101010
This number is 1023 = 210 -1, which can be computed as (1<<10) – 1

•But how to define a pattern of shader instructions?
In the example of previous slide, we see that SHR R0,10 = 00000000001010101010101010101010 ASHR R0,10 = 11111111111010101010101010101010
This number is 1023 = 210 -1, which can be computed as (1<<10) – 1
So it looks like answer here is to compute the right part with SHR and the left part as: (TopBit << ShiftAmount) - 1

Now we can start to build the ASHR instruction
•First we define a pattern call RED. Recall that shader registers have 4 32-bit fields: Red, Green, Blue, and Alpha. Since we are not using SIMD yet, we will only deal with 1 32-bit register. That is what RED does. Here is the LLVM pattern: def:PAT<(RED Rx),(AND Rx,0xFFFFFFFF)>
•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>

•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>
This strips out everything but the sign bit, which is now in the bottom bit position.

•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>
This strips out everything but the sign bit, which is now in the bottom bit position.
For example 10101010101010101010101010101010

•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>
This strips out everything but the sign bit, which is now in the bottom bit position.
For example 10101010101010101010101010101010After we do the blue part:
00000000000000000000000000000001

•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>
This strips out everything but the sign bit, which is now in the bottom bit position.
For example 10101010101010101010101010101010After we do the blue part:
00000000000000000000000000000001

•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>
This pushes the sign bit up y places. Thus it computes 2y, if the sign bit is 1.

•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>
This pushes the sign bit up y places. Thus it computes 2y, if the sign bit is 1.
For example 10101010101010101010101010101010After we do the blue part:
00000000000000000000000000000001After we do the green part (assuming y =10):

•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>
This pushes the sign bit up y places. Thus it computes 2y, if the sign bit is 1.
For example 10101010101010101010101010101010After we do the blue part:
00000000000000000000000000000001After we do the green part (assuming y =10): 00000000000000000000010000000000

•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB
32,Ry))>
This now computes the left part.
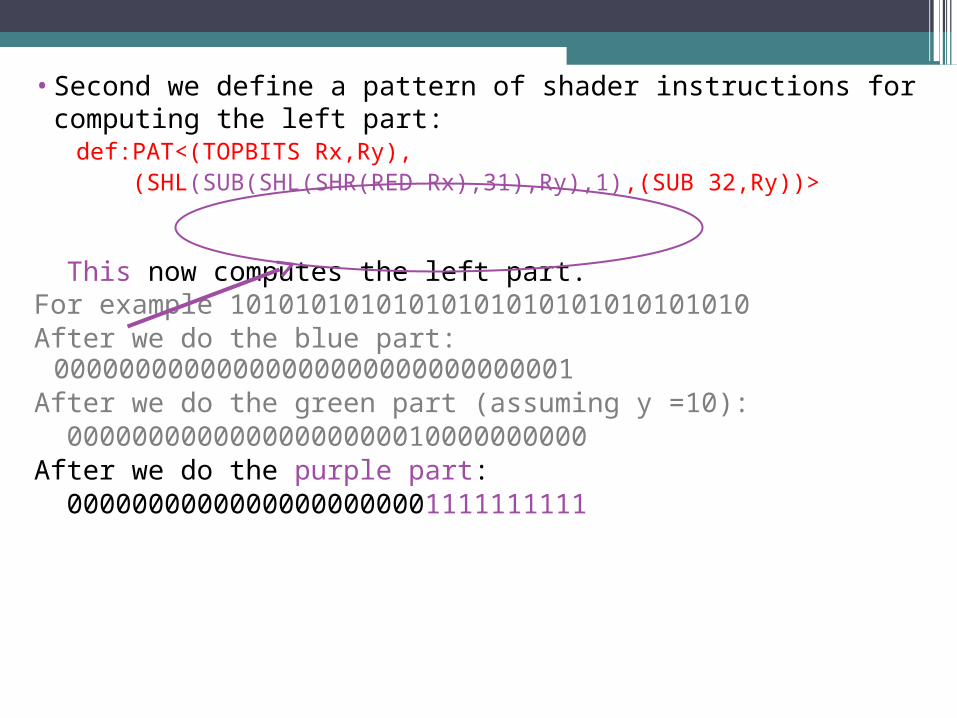
•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>
This now computes the left part.For example 10101010101010101010101010101010After we do the blue part:
00000000000000000000000000000001After we do the green part (assuming y =10): 00000000000000000000010000000000After we do the purple part: 00000000000000000000001111111111

•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB
32,Ry))>
Finally, the sign extension bits shift up to where they go.

•Second we define a pattern of shader instructions for computing the left part:
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>
Finally, the sign extension bits shift up to where they go.For example 10101010101010101010101010101010After we do the blue part:
00000000000000000000000000000001After we do the green part (assuming y =10): 00000000000000000000010000000000After we do the purple part: 00000000000000000000001111111111After we do the red part: 11111111110000000000000000000000

•Third we define a pattern of shader instructions for merging the left and right parts:
def : PAT <(ASHR, Rx), (OR (TOPBITS Rx,Ry), (SHR (RED Rx), y))>
From the previous slide the red part is: 11111111110000000000000000000000
It is clear that the lavender part is: 00000000001010101010101010101010
And a bitwise-OR of the two parts yields: 11111111111010101010101010101010

•So, we defined 3 patterns: def:PAT<(RED Rx),(AND Rx,0xFFFFFFFF)>
def:PAT<(TOPBITS Rx,Ry), (SHL(SUB(SHL(SHR(RED Rx),31),Ry),1),(SUB 32,Ry))>
def : PAT <(ASHR, Rx), (OR (TOPBITS Rx,Ry), (SHR (RED Rx), y))>
•As a result, there is now a rewriting rule for ashr
• Its awkward, but it works▫Besides its unclear how often shaders would do an ashr
•We must similarly build patterns for every LLVM IR instruction that does not naturally map to a shader processor instruction

Future workAll of the above is just for the first-cut compiler
1st cut: fast track selection- Backend changed to target the shader processors- Works but has no SIMD operation
2nd cut: slow track selection- Merge in the second backend change to understand the augmented IR- Update instruction selector to make SIMD choices
3rd cut: Create tree rewriting rules for the complex processor instructions, like SQRT and LOG


















