
Information Retrieval and Web Search - macOS Servermeyer.math.ncsu.edu/Meyer/PS_Files/HLA.pdf ·...
16
63 Information Retrieval and Web Search Amy N. Langville The College of Charleston Carl D. Meyer North Carolina State University 63.1 The Traditional Vector Space Method ............... 63-1 63.2 Latent Semantic Indexing .......................... 63-3 63.3 Nonnegative Matrix Factorizations ................. 63-5 63.4 Web Search ........................................ 63-8 63.5 Google’s PageRank ................................. 63-10 References ................................................ 63-14 Information retrieval is the process of searching within a document collection for information most rel- evant to a user’s query. However, the type of document collection significantly affects the methods and algorithms used to process queries. In this chapter, we distinguish between two types of document collec- tions: traditional and Web collections. Traditional information retrieval is search within small, controlled, nonlinked collections (e.g., a collection of medical or legal documents), whereas Web information retrieval is search within the world’s largest and linked document collection. In spite of the proliferation of the Web, more traditional nonlinked collections still exist, and there is still a place for the older methods of information retrieval. 63.1 The Traditional Vector Space Method Today most search systems that deal with traditional document collections use some form of the vector space method [SB83] developed by Gerard Salton in the early 1960s. Salton’s method transforms textual data into numeric vectors and matrices and employs matrix analysis techniques to discover key features and connections in the document collection. Definitions: For a given collection of documents and for a dictionary of m terms, document i is represented by an m × 1 document vector d i whose j th element is the number of times term j appears in document i . The term-by-document matrix is the m × n matrix A = [ d 1 d 2 ··· d n ] whose columns are the document vectors. 63-1
Transcript of Information Retrieval and Web Search - macOS Servermeyer.math.ncsu.edu/Meyer/PS_Files/HLA.pdf ·...

63Information Retrieval
and Web Search
Amy N. LangvilleThe College of Charleston
Carl D. MeyerNorth Carolina State University
63.1 The Traditional Vector Space Method . . . . . . . . . . . . . . . 63-163.2 Latent Semantic Indexing . . . . . . . . . . . . . . . . . . . . . . . . . . 63-363.3 Nonnegative Matrix Factorizations . . . . . . . . . . . . . . . . . 63-563.4 Web Search . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63-863.5 Google’s PageRank . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63-10References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63-14
Information retrieval is the process of searching within a document collection for information most rel-evant to a user’s query. However, the type of document collection significantly affects the methods andalgorithms used to process queries. In this chapter, we distinguish between two types of document collec-tions: traditional and Web collections. Traditional information retrieval is search within small, controlled,nonlinked collections (e.g., a collection of medical or legal documents), whereas Web information retrievalis search within the world’s largest and linked document collection. In spite of the proliferation of theWeb, more traditional nonlinked collections still exist, and there is still a place for the older methods ofinformation retrieval.
63.1 The Traditional Vector Space Method
Today most search systems that deal with traditional document collections use some form of the vectorspace method [SB83] developed by Gerard Salton in the early 1960s. Salton’s method transforms textualdata into numeric vectors and matrices and employs matrix analysis techniques to discover key featuresand connections in the document collection.
Definitions:
For a given collection of documents and for a dictionary of m terms, document i is represented by anm × 1 document vector di whose j th element is the number of times term j appears in document i .
The term-by-document matrix is the m × n matrix
A = [ d1 d2 · · · dn ]
whose columns are the document vectors.
63-1

63-2 Handbook of Linear Algebra
Recall is a measure of performance that is defined to be
0 ≤ Recall = # relevant docs retrieved
# relevant docs in collection≤ 1.
Precision is another measure of performance defined to be
0 ≤ Precision = # relevant docs retrieved
# docs retrieved≤ 1.
Query processing is the act of retrieving documents from the collection that are most related to a user’squery, and the query vector qm×1 is the binary vector defined by
qi ={
1 if term i is present in the user’s query,0 otherwise.
The relevance of document i to a query q is defined to be
δi = cos θi = qT di /‖q‖2‖di ‖2.
For a selected tolerance τ, the retrieved documents that are returned to the user are the documents forwhich δi > τ.
Facts:
1. The term-by-document matrix A is sparse and nonnegative, but otherwise unstructured.2. [BB05] In practice, weighting schemes other than raw frequency counts are used to construct the
term-by-document matrix because weighted frequencies can improve performance.3. [BB05] Query weighting may also be implemented in practice.4. The tolerance τ is usually tuned to the specific nature of the underlying document collection.5. Tuning can be accomplished with the technique of relevance feedback, which uses a revised query
vector such as q = δ1d1 + δ3d3 + δ7d7, where d1, d3, and d7 are the documents the user judgesmost relevant to a given query q.
6. When the columns of A and q are normalized, as they usually are, the vector δT = qT A providesthe complete picture of how well each document in the collection matches the query.
7. The vector space model is efficient because A is usually very sparse, and qT A can be executed inparallel, if necessary.
8. [BB05] Because of linguistic issues such as polysomes and synonyms, the vector space modelprovides only decent performance on query processing tasks.
9. The underlying basis for the vector space model is the standard basis e1, e2, . . . , em, and the orthog-onality of this basis can impose an unrealistic independence among terms.
10. The vector space model is a good starting place, but variations have been developed that providebetter performance.
Examples:
1. Consider a collection of seven documents and nine terms (taken from [BB05]). Terms not in thesystem’s index are ignored. Suppose further that only the titles of each document are used forindexing. The indexed terms and titles of documents are shown below.

Information Retrieval and Web Search 63-3
Terms Documents
T1: Bab(y,ies,y’s) D1: Infant & Toddler First AidT2: Child(ren’s) D2: Babies and Children’s Room (For Your Home)T3: Guide D3: Child Safety at HomeT4: Health D4: Your Baby’s Health and Safety: From Infant to ToddlerT5: Home D5: Baby Proofing BasicsT6: Infant D6: Your Guide to Easy Rust ProofingT7: Proofing D7: Beanie Babies Collector’s GuideT8: SafetyT9: Toddler
The indexed terms are italicized in the titles. Also, the stems [BB05] of the terms for baby (andits variants) and child (and its variants) are used to save storage and improve performance. Theterm-by-document matrix for this document collection is
A =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣
0 1 0 1 1 0 1
0 1 1 0 0 0 0
0 0 0 0 0 1 1
0 0 0 1 0 0 0
0 1 1 0 0 0 0
1 0 0 1 0 0 0
0 0 0 0 1 1 0
0 0 1 1 0 0 0
1 0 0 1 0 0 0
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦.
For a query on baby health, the query vector is
q = [ 1 0 0 1 0 0 0 0 0 ]T .
To process the user’s query, the cosines
δi = cos θi = qT di
‖q‖2‖di ‖2
are computed. The documents corresponding to the largest elements of δ are most relevant to theuser’s query. For our example,
δ ≈ [ 0 0.40824 0 0.63245 0.5 0 0.5 ],
so document vector 4 is scored most relevant to the query on baby health. To calculate the recalland precision scores, one needs to be working with a small, well-studied document collection. Inthis example, documents d4, d1, and d3 are the three documents in the collection relevant to babyhealth. Consequently, with τ = .1, the recall score is 1/3 and the precision is 1/4.
63.2 Latent Semantic Indexing
In the 1990s, an improved information retrieval system replaced the vector space model. This system iscalled Latent Semantic Indexing (LSI) [Dum91] and was the product of Susan Dumais, then at Bell Labs.LSI simply creates a low rank approximation Ak to the term-by-document matrix A from the vector spacemodel.

63-4 Handbook of Linear Algebra
Facts:
1. [Mey00] If the term-by-document matrix Am×n has the singular value decomposition A =U� V T = ∑r
i=1 σi ui vTi , σ1 ≥ σ2 ≥ · · · ≥ σr > 0, then Ak is created by truncating this
expansion after k terms, where k is a user tunable parameter.2. The recall and precision measures are generally used in conjunction with each other to evaluate
performance.3. A is replaced by Ak = ∑k
i=1 σi ui vTi in the query process so that if q and the columns of Ak have
been normalized, then the angle vector is computed as δT = qT Ak .
4. The truncated SVD approximation to A is optimal in the sense that of all rank-k matrices, thetruncated SVD Ak is the closest to A, and
‖A − Ak‖F = minr ank(B)≤k
‖A − B‖F =√
σ 2k+1 + · · · + σ 2
r .
5. This rank-k approximation reduces the so-called linguistic noise present in the term-by-documentmatrix and, thus, improves information retrieval performance.
6. [Dum91], [BB05], [BR99], [Ber01], [BDJ99] LSI is known to outperform the vector space modelin terms of precision and recall.
7. [BR99], [Ber01], [BB05], [BF96], [BDJ99], [BO98], [Blo99], [BR01], [Dum91], [HB00], [JL00],[JB00], [LB97], [WB98], [ZBR01], [ZMS98] LSI and the truncated singular value decompositiondominated text mining research in the 1990s.
8. A serious drawback to LSI is that while it might appear at first glance that Ak should save storageover the original matrix A, this is often not the case, even when k << r. This is because A isgenerally very sparse, but the singular vectors ui and vT
i are almost always completely dense. Inmany cases, Ak requires more (sometimes much more) storage than A itself requires.
9. A significant problem with LSI is the fact that while A is a nonnegative matrix, the singularvectors are mixed in sign. This loss of important structure means that the truncated singularvalue decomposition provides no textual or semantic interpretation. Consider aparticular document vector, say, column 1 of A. The truncated singular value decompositionrepresents document 1 as
A1 =
⎡⎢⎣...
u1...
⎤⎥⎦ σ1v11 +
⎡⎢⎣...
u2...
⎤⎥⎦ σ2v12 + · · ·
⎡⎢⎣...
uk...
⎤⎥⎦ σkv1k ,
so document 1 is a linear combination of the basis vectors ui with the scalar σi v1i being a weightthat represents the contribution of basis vector i in document 1. What we’d really like to do issay that basis vector i is mostly concerned with some subset of the terms, but any such textualor semantic interpretation is difficult (or impossible) when SVD components are involved. More-over, if there were textual or semantic interpretations, the orthogonality of the singular vectorswould ensure that there is no overlap of terms in the topics in the basis vectors, which is highlyunrealistic.
10. [Ber01], [ZMS98] It is usually a difficult problem to determine the most appropriate value of k fora given dataset because k must be large enough so that Ak can capture the essence of the documentcollection, but small enough to address storage and computational issues. Various heuristics havebeen developed to deal with this issue.

Information Retrieval and Web Search 63-5
Examples:
1. Consider again the 9×7 term-by-document matrix used in section 63.1. The rank-4 approximationto this matrix is
A4 =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣
0.020 1.048 −0.034 0.996 0.975 0.027 0.975
−0.154 0.883 1.067 0.078 0.027 −0.033 0.027
−0.012 −0.019 0.013 0.004 0.509 0.990 0.509
0.395 0.058 0.020 0.756 0.091 −0.087 0.091
−0.154 0.883 1.067 0.078 0.027 −0.033 0.027
0.723 −0.144 0.068 1.152 0.004 −0.012 0.004
−0.012 −0.019 0.013 0.004 0.509 0.990 0.509
0.443 0.334 0.810 0.776 −0.074 0.091 −0.074
0.723 −0.144 0.068 1.152 0.004 −0.012 0.004
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦.
Notice that while A is sparse and nonnegative, A4 is dense and mixed in sign. Of course, as kincreases, Ak looks more and more like A. For a query on baby health, the angle vector is
δ ≈ [ .244 .466 −.006 .564 .619 −.030 .619 ]T .
Thus, the information retrieval system returns documents d5, d7, d4, d2, d1, in order from mostto least relevant. As a result, the recall improves to 2/3, while the precision is 2/5. Adding anothersingular triplet and using the approximation matrix A5 does not change the recall or precisionmeasures, but does give a slightly different angle vector
δ ≈ [ .244 .466 −.006 .564 .535 −.030 .535 ]T ,
which is better than the A4 angle vector because the most relevant document, d4, Your Baby’s Healthand Safety: From Infant to Toddler, gets the highest score.
63.3 Nonnegative Matrix Factorizations
The lack of semantic interpretation due to the mixed signs in the singular vectors is a major obstacle in usingLSI. To circumvent this problem, alternative low rank approximations that maintained the nonnegativestructure of the original term-by-document matrix have been proposed [LS99], [LS00], [PT94], [PT97].
Facts:
1. If Am×n ≥ 0 has rank r, then for a given k < r the goal of a nonnegative matrix factorization (NMF)is to find the nearest rank-k approximation W H to A such that Wm×k ≥ 0 and Hk×n ≥ 0. Oncedetermined, a NMF simply replaces the truncated singular value decomposition in any text miningtask such as clustering documents, classifying documents, or processing queries on documents.
2. A NMF can be formulated as a constrained nonlinear least squares problem by first specifying kand then determining
min ‖A − W H‖2F subject to Wm×k ≥ 0, Hk×n ≥ 0.
The rank of the approximation (i.e., k) becomes the number of topics or clusters in a text miningapplication.

63-6 Handbook of Linear Algebra
3. [LS99] The Lee and Seung algorithm to compute a NMF using MATLAB is as follows.
Algorithm 1: Lee–Seung NMF
W = abs(randn(m, k)) % initialize with random dense matrixH = abs(randn(k, n)) % initialize with random dense matrixfor i = 1 : maxiterH = H. ∗ (WT A)./(WT W H + 10−9) % 10−9 avoids division by 0W = W. ∗ (AH T )./(W H H T + 10−9)end
4. The objective function ‖A − W H‖2F in the Lee and Seung algorithm tends to tail off within 50 to
100 iterations. Faster algorithms exist, but the Lee and Seung algorithm algorithm is guaranteed toconverge to a local minimum in a finite number of steps.
5. [Hoy02], [Hoy04], [SBP04] Other NMF algorithms contain a tunable sparsity parameter thatproduces any desired level of sparseness in W and H . The storage savings of the NMF over thetruncated SVD are substantial.
6. Because A j ≈ ∑ki=1 Wi hi j , and because W and H are nonnegative, each column Wi can be viewed
as a topic vector—if wi j1 , wi j2 , . . . , wi jp are the largest entries in Wi , then terms j1, j2, . . . , j p dictatethe topics that Wi represents. The entries hi j measure the strength to which topic i appears in basisdocument j, and k is the number of topic vectors that one expect to see in a given set of documents.
7. The NMF has some disadvantages. Unlike the SVD, uniqueness and robust computations aremissing in the NMF. There is no unique global minimum for the NMF (the defining constrainedleast squares problem is not convex in W and H), so algorithms can only guarantee convergenceto a local minimum, and many don’t even guarantee that.
8. Not only will different NMF algorithms produce different NMF factors, the same NMF algorithm,run with slightly different parameters, can produce very different NMF factors. For example, theresults can be highly dependent on the initial values.
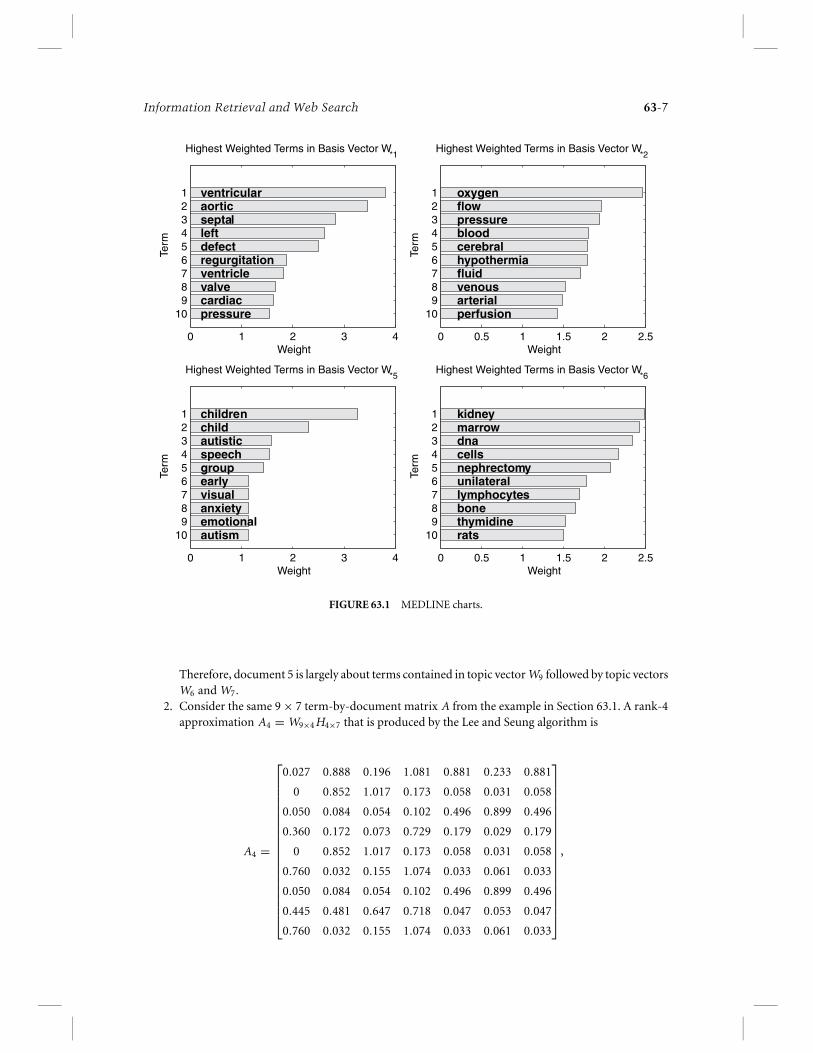
Examples:
1. When the term-by-document matrix of the MEDLINE dataset [Med03] is approximated with aNMF as described above with k = 10, the charts in Figure 63.1 show the highest weighted termsfrom four representative columns of W. For example, this makes it clear that W1 represents heartrelated topics, while W2 concerns blood issues, etc.When document 5 (column A5) from MEDLINE is expressed as an approximate linear combinationof W1, W2, . . . , W10 in order of the size of the entries of H5, which are
h95 = .1646 > h65 = .0103 > h75 = .0045 > · · · ,
we have that
A5 ≈ .1646 W9 + .0103 W6 + .0045 W7 + · · ·
= .1646
⎡⎢⎢⎢⎢⎢⎢⎣
fattyglucose
acidsffa
insulin...
⎤⎥⎥⎥⎥⎥⎥⎦ + .0103
⎡⎢⎢⎢⎢⎢⎢⎣
kidneymarrow
dnacells
nephr....
⎤⎥⎥⎥⎥⎥⎥⎦ + .0045
⎡⎢⎢⎢⎢⎢⎢⎣
hormonegrowth
hghpituitary
mg...
⎤⎥⎥⎥⎥⎥⎥⎦ + · · · .
Information Retrieval and Web Search 63-7
0 1 2 3 4
10987654321 ventricular
aorticseptalleftdefectregurgitationventriclevalvecardiacpressure
Highest Weighted Terms in Basis Vector W*1
Weight
Term
0 0.5 1 1.5 2 2.5
10987654321 oxygen
flowpressurebloodcerebralhypothermiafluidvenousarterialperfusion
Highest Weighted Terms in Basis Vector W*2
Weight
Term
0 1 2 3 4
10987654321 children
childautisticspeechgroupearlyvisualanxietyemotionalautism
Highest Weighted Terms in Basis Vector W*5
Weight
Term
0 0.5 1 1.5 2 2.5
10987654321 kidney
marrowdnacellsnephrectomyunilaterallymphocytesbonethymidinerats
Highest Weighted Terms in Basis Vector W*6
Weight
Term
FIGURE 63.1 MEDLINE charts.
Therefore, document 5 is largely about terms contained in topic vector W9 followed by topic vectorsW6 and W7.
2. Consider the same 9 × 7 term-by-document matrix A from the example in Section 63.1. A rank-4approximation A4 = W9×4 H4×7 that is produced by the Lee and Seung algorithm is
A4 =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣
0.027 0.888 0.196 1.081 0.881 0.233 0.881
0 0.852 1.017 0.173 0.058 0.031 0.058
0.050 0.084 0.054 0.102 0.496 0.899 0.496
0.360 0.172 0.073 0.729 0.179 0.029 0.179
0 0.852 1.017 0.173 0.058 0.031 0.058
0.760 0.032 0.155 1.074 0.033 0.061 0.033
0.050 0.084 0.054 0.102 0.496 0.899 0.496
0.445 0.481 0.647 0.718 0.047 0.053 0.047
0.760 0.032 0.155 1.074 0.033 0.061 0.033
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦,

63-8 Handbook of Linear Algebra
where
W4 =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣
0.202 0.017 0.160 1.357
0 0 0.907 0.104
0.805 0 0 0.008
0 0.415 0 0.321
0 0 0.907 0.104
0 0.875 0 0.060
0.805 0 0 0.008
0 0.513 0.500 0.085
0 0.876 0 0.060
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦,
H4 =
⎡⎢⎢⎢⎣0.062 0.010 0.067 0.119 0.610 1.117 0.610
0.868 0 0.177 1.175 0 0.070 0
0 0.878 1.121 0.105 0 0.034 0
0 0.537 0 0.752 0.559 0 0.559
⎤⎥⎥⎥⎦.
Notice that both A and A4 are nonnegative, and the sparsity of W and H makes the storage savingsapparent. The error in this NMF approximation as measured by ‖A − W H‖2
F is 1.56, while theerror in the best rank-4 approximation from the truncated SVD is 1.42. In other words, the NMFapproximation is not far from the optimal SVD approximation — this is frequently the case inpractice in spite of the fact that W and H can vary with the initial conditions. For a query on babyhealth, the angle vector is
δ ≈ [ .224 .472 .118 .597 .655 .143 .655 ]T .
Thus, the information retrieval system that uses the nonnegative matrix factorization gives the sameranking as a system that uses the truncated singular value decomposition. However, the factors aresparse and nonnegative and can be interpreted.
63.4 Web Search
Only a few years ago, users of Web search engines were accustomed to waiting, for what would now seemto be an eternity, for search engines to return results to their queries. And when a search engine finallyresponded, the returned list was littered with links to information that was either irrelevant, unimportant,or downright useless. Frustration was compounded by the fact that useless links invariably appeared at ornear the top of the list while useful links were deeply buried. Users had to sift through links a long waydown in the list to have a chance of finding something satisfying, and being less than satisfied was notuncommon.
The reason for this is that the Web’s information is not structured like information in the organizeddatabases and document collections that generations of computer scientists had honed their techniques on.The Web is unique in the sense that it is self organized . That is, unlike traditional document collections thatare accumulated, edited, and categorized by trained specialists, the Web has no standards, no reviewers,and no gatekeepers to police content, structure, and format. Information on the Web is volatile andheterogeneous — links and data are rapidly created, changed, and removed, and Web information existsin multiple formats, languages, and alphabets. And there is a multitude of different purposes for Web data,

Information Retrieval and Web Search 63-9
e.g., some Web pages are designed to inform while others try to sell, cheat, steal, or seduce. In addition,the Web’s self organization opens the door for spammers, the nefarious people who want to illicitlycommandeer your attention to sell or advertise something that you probably don’t want. Web spammersare continually devising diabolical schemes to trick search engines into listing their (or their client’s) Webpages near the top of the list of search results. They had an easy time of it when Web search relied ontraditional IR methods based on semantic principles. Spammers could create Web pages that containedthings such as miniscule or hidden text fonts, hidden text with white fonts on a white background,and misleading metatag descriptions designed to influence semantic based search engines. Finally, theenormous size of the Web, currently containing O(109) pages, completely overwhelmed traditional IRtechniques.
By 1997 it was clear that in nearly all respects the database and IR technology of the past wasn’t wellsuited for Web search, so researchers set out to devise new approaches. Two big ideas emerged (almostsimultaneously), and each capitalizes on the link structure of the Web to differentiate between relevantinformation and fluff. One approach, HITS (Hypertext Induced Topic Search), was introduced by JonKleinberg [Kle99], [LM06], and the other, which changed everything, is Google’s PageRank that wasdeveloped by Sergey Brin and Larry Page [BP98], [BPM99], [LM06]. While variations of HITS andPageRank followed (e.g., Lempel’s SALSA [LM00], [LM05], [LM06]), the basic idea of PageRank became the driving force, so the focus is on this concept.
Definitions:
Early in the game, search companies such as YAHOO! employed students to surf the Web and record keyinformation about the pages they visited. This quickly overwhelmed human capability, so today all Websearch engines use Web Crawlers, which is software that continuously scours the Web for information toreturn to a central repository.
Web pages found by the robots are temporarily stored in entirety in a page repository. Pages remainin the repository until they are sent to an indexing module, where their vital information is stripped tocreate a compressed version of the page. Popular pages that are repeatedly requested by users are storedhere longer, perhaps indefinitely.
The indexing module extracts only key words, key phrases, or other vital descriptors, and it creates acompressed description of the page that can be “indexed.” Depending on the popularity of a page, theuncompressed version is either deleted or returned to the page repository.
There are three general kinds of indexes that contain compressed information for each webpage. Thecontent index contains information such as key words or phrases, titles, and anchor text, and this is storedin a compressed form using an inverted file structure, which is simply the electronic version of a bookindex, i.e., each morsel of information points to a list of pages containing it. Information regarding thehyperlink structure of a page is stored in compressed form in the structure index. The crawler modulesometimes accesses the structure index to find uncrawled pages. Finally, there are special-purpose indexessuch as an image index and a pdf index. The crawler, page repository, indexing module, and indexes, alongwith their corresponding data files exist and operate independent of users and their queries.
The query module converts a user’s natural language query into a language that the search engine canunderstand (usually numbers), and consults the various indexes in order to answer the query. For example,the query module consults the content index and its inverted file to find which pages contain the queryterms.
The pertinent pages are the pages that contain query terms. After pertinent pages have been identified,the query module passes control to the ranking module.
The ranking module takes the set of pertinent pages and ranks them according to some criterion, andthis criterion is the heart of the search engine — it is the distinguishing characteristic that differentiates onesearch engine from another. The ranking criterion must somehow discern which Web pages best respondto a user’s query, a daunting task because there might be millions of pertinent pages. Unless a search enginewants to play the part of a censor (which most don’t), the user is given the opportunity of seeing a list oflinks to a large proportion of the pertinent pages, but with less useful links permuted downward.

63-10 Handbook of Linear Algebra
PageRank is Google’s patented ranking system, and some of the details surrounding PageRank arediscussed below.
Facts:
1. Google assigns at least two scores to each Web page. The first is a popularity score and the secondis a content score. Google blends these two scores to determine the final ranking of the results thatare returned in response to a user’s query.
2. [BP98] The rules used to give each pertinent page a content score are trade secrets, but they generallytake into account things such as whether the query terms appear in the title or deep in the bodyof a Web page, the number of times query terms appear in a page, the proximity of multiple querywords to one another, and the appearance of query terms in a page (e.g., headings in bold fontscore higher). The content of neighboring web pages is also taken into account.
3. Google is known to employ over a hundred such metrics in this regard, but the details are proprietary.While these metrics are important, they are secondary to the the popularity score, which is theprimary component of PageRank. The content score is used by Google only to temper the popularityscore.
63.5 Google’s PageRank
The popularity score is where the mathematics lies, so it is the focus of the remainder of this exposition.We will identify the term “PageRank” with just the mathematical component of Google’s PageRank (thepopularity score) with the understanding that PageRank may be tweaked by a content score to produce afinal ranking.
Both PageRank and Google were conceived by Sergey Brin and Larry Page while they were computerscience graduate students at Stanford University, and in 1998 they took a leave of absence to focus ontheir growing business. In a public presentation at the Seventh International World Wide Web conference(WWW98) in Brisbane, Australia, their paper “The PageRank citation ranking: Bringing order to the Web”[BPM99] made small ripples in the information science community that quickly turned into waves.
The original idea was that a page is important if it is pointed to by other important pages. That is, theimportance of your page (its PageRank) is determined by summing the PageRanks of all pages that pointto yours. Brin and Page also reasoned that when an important page points to several places, its weight(PageRank) should be distributed proportionately.
In other words, if YAHOO! points to 99 pages in addition to yours, then you should only get credit for1/100 of YAHOO!’s PageRank. This is the intuitive motivation behind Google’s PageRank concept, butsignificant modifications are required to turn this basic idea into something that works in practice.
For readers who want to know more, the book Google’s PageRank and Beyond: The Science of SearchEngine Rankings [LM06] (Princeton University Press, 2006) contains over 250 pages devoted to link analysisalgorithms along with other ranking schemes such as HITS and SALSA as well as additional backgroundmaterial, examples, code, and chapters dealing with more advanced issues in Web search ranking.
Definitions:
The hyperlink matrix is the matrix Hn×n that represents the link structure of the Web, and its entries aregiven by
hi j ={
1/|Oi | if there is a link from page i to page j,0 otherwise,
where |Oi | is the number of outlinks from page i .

Information Retrieval and Web Search 63-11
Suppose that there are n Web pages, and let ri (0) denote the initial rank of the i th page. If the ranks aresuccessively modified by setting
ri (k + 1) =∑j∈Ii
r j (k)
|O j | , k = 1, 2, 3, . . . ,
where ri (k) is the rank of page i at iteration k and Ii is the set of pages pointing (linking) to page i , thenthe rankings after the kth iteration are
rT (k) = (r1(k), r2(k), . . . , rn(k)) = rT (0)Hk .
The conceptual PageRank of the i th Web page is defined to be
ri = limk→∞
ri (k),
provided that the limit exists. However, this definition is strictly an intuitive concept because the naturalstructure of the Web generally prohibits these limits from existing.
A dangling node is a Web page that contain no out links. Dangling nodes produce zero rows in thehyperlink matrix H, so even if limk→∞ Hk exists, the limiting vector rT = limk→∞ rT (k) would bedependent on the initial vector rT (0), which is not good.
The stochastic hyperlink matrix is produced by perturbing the hyperlink matrix to be stochastic. Inparticular,
S = H + a1T /n, (63.1)
where a is the column in which
ai ={
1 if page i is a dangling node,0 otherwise.
S is a stochastic matrix that is identical to H except that zero rows in H are replaced by 1T /n (1 is a vectorof 1s and n = O(109), so entries in 1T /n are pretty small). The effect is to eliminate dangling nodes. Anyprobability vector pT > 0 can be used in place of the uniform vector.
The Google matrix is defined to be the stochastic matrix
G = αS + (1 − α)E , (63.2)
where E = 1vT in which vT > 0 can be any probability vector. Google originally set α = .85 andvT = 1T /n. The choice of α is discussed later in Facts 12, 13, and 14.
The personalization vector is the vector vT in E = 1vT in Equation 63.2. Manipulating vT givesGoogle the flexibility to make adjustments to PageRanks as well as to personalize them (thus, the name“personalization vector”) [HKJ03], [LM04a].
The PageRank vector is the left Perron vectorπT of the Google matrix G. In particular,πT (I −G) = 0,where πT > 0 and ‖πT ‖1 = 1. The components of this vector constitute Google’s popularity score ofeach webpage.
Facts:
1. [Mey00, Chap. 8] The Google matrix G is a primitive stochastic matrix, so the spectral radiusρ(G) = 1 is a simple eigenvalue, and 1 is the only eigenvalue on the unit circle.
2. The iteration defined by πT (k + 1) = πT (k)G converges, independent of the starting vector, to aunique stationary probability distribution πT , which is the PageRank vector.
3. The irreducible aperiodic Markov chain defined by πT (k + 1) = πT (k)G is a constrained randomwalk on the Web graph. The random walker can be characterized as a Web surfer who, at each step,randomly chooses a link from his current page to click on except that

63-12 Handbook of Linear Algebra
(a) When a dangling node is encountered, the excursion is continued by jumping to another pageselected at random (i.e., with probability 1/n).
(b) At each step, the random Web surfer has a chance (with probability 1 − α) of becoming boredwith following links from the current page, in which case the random Web surfer continuesthe excursion by jumping to page j with probability v j .
4. The random walk defined by rT (k + 1) = rT (k)S will generally not converge because Web’s graphstructure is not strongly connected, which results in a reducible chain with many isolated ergodicclasses.
5. The power method has been Google’s computational method of choice for computing the PageRankvector. If formed explicitly, G is completely dense, and the size of n would make each power iterationextremely costly — billions of flops for each step. But writing the power method as
πT (k + 1) = πT (k)G = απT (k)H + (απT (k)a)1T /n + (1 − α)vT
shows that only extremely sparse vector-matrix multiplications are required. Only the nonzero hij’s
are needed, so G and S are neither formed nor stored.6. When implemented as shown above, each power step requires only nnz(H) flops, where nnz(H)
is the number of nonzeros in H , and, since the average number of nonzeros per column in H issignificantly less than 10, we have O(nnz(H)) ≈ O(n). Furthermore, the inherent parallism iseasily exploited, and the current iterate is the only vector stored at each step.
7. Because the Web has many disconnected components, the hyperlink matrix is highly reducible, andcompensating for the dangling nodes to construct the stochastic matrix S does not significantlyaffect this.
8. [Mey00, p. 695–696] Since S is also reducible, S can be symmetrically permuted to have the form
S ∼
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣
S11 S12 · · · S1r S1,r+1 S1,r+2 · · · S1m
0 S22 · · · S2r S2,r+1 S2,r+2 · · · S2m
.... . .
......
... · · · ...
0 0 · · · Sr r Sr,r+1 Sr,r+2 · · · Sr m
0 0 · · · 0 Sr+1,r+1 0 · · · 0
0 0 · · · 0 0 Sr+2,r+2 · · · 0
...... · · · ...
......
. . ....
0 0 · · · 0 0 0 · · · Smm
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦,
where the following are true.� For each 1 ≤ i ≤ r, Sii is either irreducible or [0]1×1.� For each 1 ≤ i ≤ r, there exists some j > i such that Sij = 0.� ρ(Sii) < 1 for each 1 ≤ i ≤ r.� Sr+1,r+1, Sr+2,r+2, · · · , Sm,m are each stochastic and irreducible.� 1 is an eigenvalue for S that is repeated exactly m − r times.
9. The natural structure of the Web forces the algebraic multiplicity of the eigenvalue 1 to be large.10. [LM04a][LM06][Mey00, Ex 7.1.17, p. 502] If the eigenvalues of Sn×n are
λ(S) = {1, 1, . . . , 1︸ ︷︷ ︸m−r
, µm−r+1, . . . , µn}, 1 > |µm−r+1| ≥ · · · ≥ |µn|,

Information Retrieval and Web Search 63-13
then the eigenvalues of the Google matrix G = αS + (1 − α)E are
λ(G) = {1, α, . . . , α︸ ︷︷ ︸m−r−1
, (αµm−r+1), . . . , (αµn)}. (63.3)
11. [Mey00] The asymptotic rate of convergence of any aperiodic Markov chain is governed by themagnitude of its largest subdominant eigenvalue. In particular, if the distinct eigenvalues λi of anaperiodic chain are ordered λ1 = 1 > |λ2| ≥ |λ3| ≥ · · · ≥ |λn|, then the number of incorrectdigits in each component of πT (k) is eventually going to be reduced by about −log10|λ2| digits periteration.
12. Determining (or even estimating) |λ2| normally requires substantial effort, but Equation 63.3 saysthat λ2 = α for the Google matrix G. This is an extremely happy accident because it means thatGoogle’s engineers can completely control the rate of convergence, regardless of the value of thepersonalization vector vT in E = 1vT .
13. At the last public disclosure Google was setting α = .85, so, at this value, the asymptotic rate ofconvergence of the power method is −log10(.85) ≈ .07, which means that the power method willeventually take about 14 iterations for each significant place of accuracy that is required.
14. [LM04a] Even though they can control the rate of convergence with α, Google’s engineers are forcedto perform a delicate balancing act because while decreasing α increases the rate of convergence,decreasing α also lessens the effect of the true hyperlink structure of the Web, which is Google’sprimary mechanism for measuring Webpage importance. Increasing α more accurately reflects theWeb’s true link structure, but, along with slower convergence, sensitivity issues begin to surface inthe sense that slightly different values for α near 1 can produce significantly different PageRanks.
15. [KHM03a] The power method can be substantially accelerated by a quadratic extrapolation tech-nique similar to Aitken’s 2 method, and there is reason to believe that Google has adopted thisprocedure.
16. [KHM03b], [KHG04] Other improvements to the basic power method include a block algorithmand an adaptive algorithm that monitors the convergence of individual elements of the PageRankvector. As soon as components of the vector have converged to an acceptable tolerance, they areno longer computed. Convergence is faster because the work per iteration decreases as the processevolves.
17. [LM02], [LM04a], [LM04b], [LGZ03] Other methods partition H into two groups according todangling nodes and nondangling nodes. The problem is then aggregated by lumping all of thedangling nodes into one super state to produce a problem that is significantly reduced in size —this is due to the fact that the dangling nodes account for about one-fourth of the Web’s nodes. Themost exciting feature of all these algorithms is that they do not compete with one another. In fact,it is possible to combine some of these algorithms to achieve even greater performance.
18. The accuracy of PageRank computations is an important implementation issue, but we do notknow the accuracy with which Google works. It seems that it must be at least high enough todifferentiate between the often large list of ranked pages that Google usually returns, and sinceπT is a probability vector containing O(109) components, it is reasonable to expect that accuracygiving at least ten significant places is needed to distinguish among the elements.
19. A weakness of PageRank is “topic drift.” The PageRank vector might be mathematically accurate,but this is of little consequence if the results point the user to sites that are off-topic. PageRank is aquery-independent measure that is essentially determined by a popularity contest with everyone onWeb having a vote, and this tends to skew the results in the direction of importance (measured bypopularity) over relevance to the query. This means that PageRank may have trouble distinguishingbetween pages that are authoritative in general and pages that are authoritative more specifically tothe query topic. It is believed that Google engineers devote much effort to mitigate this problem,and this is where the metrics that determine the content score might have an effect.

63-14 Handbook of Linear Algebra
20. In spite of topic drift, Google’s decision to measure importance by means of popularity over rel-evance turned out to be the key to Google’s success and the source of its strength. The querydependent measures employed by Google’s predecessors were major stumbling blocks in main-taining query processing speed as the Web grew. PageRank is query-independent, so at query timeonly a quick lookup into an inverted file storage is required to determine pertinent pages, whichare then returned in order the precomputed PageRanks. The small compromise of topic drift infavor of processing speed won the day.
21. A huge advantage of PageRank is its virtual imperviousness to spamming (artificially gaming thesystem). High PageRank is achieved by having many inlinks from highly ranked pages, and whileit may not be so hard for a page owner to have many of his cronies link to his page, it is difficult togenerate a lot inlinks from important sites that have a high rank.
22. [TM03] Another strength of PageRank concerns the flexibility of the “personalization” (or “inter-vention”) vector vT that Google is free to choose when defining the perturbation term E = 1vT .
The choice of vT affects neither mathematical nor computational aspects, but it does alter the rank-ings in a predictable manner. This can be a terrific advantage if Google wants to intervene to pusha site’s PageRank down or up, perhaps to punish a suspected “link farmer” or to reward a favoredclient. Google has claimed that they do not make a practice of rewarding favored clients, but it isknown that Google is extremely vigilant and sensitive concerning people who try to manipulatePageRank, and such sites are punished. However, the outside world is not privy to the extent towhich either the stick or carrot is employed.
23. [FLM+04], [KH03], [KHG04], [KHM03a], [LM04a], [LM06], [LGZ03], [LM03], [NZJ01] In spiteof the simplicity of the basic concepts, subtle issues such as personalization, practical implementa-tions, sensitivity, and updating lurk just below the surface.
24. We have summarized only the mathematical component of Google’s ranking system, but, as men-tioned earlier, there are a hundred or more nonmathematical content metrics that are also consid-ered when Google responds to a query. The results seen by a user are in fact PageRank tempered bythese other metrics. While Google is secretive about most of their other metrics, they have made itclear that the other metrics are subservient to their mathematical PageRank scores.
Acknowledgment
This work was supported in part by the National Science Foundation under NSF grant CCR-0318575(Carl D. Meyer).
References
[BB05] Michael W. Berry and Murray Browne. Understanding Search Engines: Mathematical Modeling andText Retrieval. SIAM, Philadelphia, 2nd ed., 2005.
[BDJ99] Michael W. Berry, Zlatko Drmac, and Elizabeth R. Jessup. Matrices, vector spaces and informationretrieval. SIAM Rev., 41:335–362, 1999.
[Ber01] Michael W. Berry, Ed. Computational Information Retrieval. SIAM, Philadelphia, 2001.[BF96] Michael W. Berry and R.D. Fierro. Low-rank orthogonal decompositions for information retrieval
applications. J. Num. Lin. Alg. Appl., 1(1):1–27, 1996.[Blo99] Katarina Blom. Information Retrieval Using the Singular Value Decomposition and Krylov Subspaces.
Ph.D. thesis, University of Chalmers, Gotebong, Sweden, January 1999.[BO98] Michael W. Berry and Gavin W. O’Brien. Using linear algebra for intelligent information retrieval.
SIAM Rev., 37:573–595, 1998.[BP98] Sergey Brin and Lawrence Page. The anatomy of a large-scale hypertextual Web search engine.
Comp. Networks ISDN Syst., 33:107–117, 1998.

Information Retrieval and Web Search 63-15
[BPM99] Sergey Brin, Lawrence Page, R. Motwami, and Terry Winograd. The PageRank citation ranking:bringing order to the Web. Technical Report 1999-0120, Computer Science Department, StanfordUniversity, 1999.
[BR01] Katarina Blom and Axel Ruhe. Information retrieval using very short Krylov sequences. In Computational Information Retrieval, pp. 41–56, 2001.[BR99] Ricardo Baeza-Yates and Berthier Ribeiro-Neto. Modern Information Retrieval. ACM Press,
Pearson Education Limited, Essex, England, 1999.[Dum91] Susan T. Dumais. Improving the retrieval of information from external sources. Behav. Res.
Meth., Instru. Comp., 23:229–236, 1991.[FLM+04] Ayman Farahat, Thomas Lofaro, Joel C. Miller, Gregory Rae, and Lesley A. Ward. Existence
and uniqueness of ranking vectors for linear link analysis. SIAM J. Sci. Comp., 27(4):1181-1201, 2006.[GL96] Gene H. Golub and Charles F. Van Loan. Matrix Computations. Johns Hopkins University Press, Baltimore, 1996. [HB00] M.K. Hughey and Michael W. Berry. Improved query matching using kd-trees, a latent semantic
indexing enhancement. Inform. Retri., 2:287–302, 2000.[HKJ03] Taher H. Haveliwala, Sepandar D. Kamvar, and Glen Jeh. An analytical comparison of approaches
to personalizing PageRank. Technical report, Stanford University, 2003.[Hoy02] Patrik O. Hoyer. Non-negative sparse coding. In Neural Networks for Signal Processing XII, Proc.
IEEE Workshop on Neural Networks for Signal Processing, Martigny, Switzerland, 557–565, 2002.[Hoy04] Patrik O. Hoyer. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn.
Res., 5:1457–1469, 2004.[JB00] Eric P. Jiang and Michael W. Berry. Solving total least squares problems in information retrieval.
Lin. Alg. Appl., 316:137–156, 2000.[JL00] Fan Jiang and Michael L. Littman. Approximate dimension equalization in vector-based infor-
mation retrieval. In The Seventeenth International Conference on Machine Learning, Stanford University, pp. 423–430, 2000.
[KH03] Sepandar D. Kamvar and Taher H. Haveliwala. The condition number of the PageRank problem.Technical report, Stanford University, 2003.
[KHG04] Sepandar D. Kamvar, Taher H. Haveliwala, and Gene H. Golub. Adaptive methods for thecomputation of PageRank. Lin. Alg. Appl., 386:51–65, 2004.
[KHM03a] Sepandar D. Kamvar, Taher H. Haveliwala, Christopher D. Manning, and Gene H. Golub.Extrapolation methods for accelerating PageRank computations. In Twelfth International WorldWide Web Conference, New York, 2003. ACM Press.
[KHM03b] Sepandar D. Kamvar, Taher H. Haveliwala, Christopher D. Manning, and Gene H. Golub.Exploiting the block structure of the Web for computing PageRank. Technical Report 2003–17,Stanford University, 2003.
[Kle99] Jon Kleinberg. Authoritative sources in a hyperlinked environment. J. ACM, 46, 1999.[LB97] Todd A. Letsche and Michael W. Berry. Large-scale information retrieval with LSI. Inform. Comp.
Sci., pp. 105–137, 1997.[LGZ03] Chris Pan-Chi Lee, Gene H. Golub, and Stefanos A. Zenios. A fast two-stage algorithm for
computing PageRank and its extensions. Technical Report SCCM-2003-15, Scientific Computationand Computational Mathematics, Stanford University, 2003.
[LM00] Ronny Lempel and Shlomo Moran. The stochastic approach for link-structure analysis (SALSA)and the TKC effect. In The Ninth International World Wide Web Conference, New York, 2000. ACMPress.
[LM02] Amy N. Langville and Carl D. Meyer. Updating the stationary vector of an irreducible Markovchain. Technical Report crsc02-tr33, North Carolina State, Mathematics Dept., CRSC, 2002.
[LM03] Ronny Lempel and Shlomo Moran. Rank-stability and rank-similarity of link-based web rankingalgorithms in authority-connected graphs. In Second Workshop on Algorithms and Models for theWeb-Graph (WAW 2003), Budapest, Hungary, May 2003.

63-16 Handbook of Linear Algebra
[LM04a] Amy N. Langville and Carl D. Meyer. Deeper inside PageRank. Inter. Math. J., 1(3):335-400, 2005. [LM04b] Amy N. Langville and Carl D. Meyer. A reordering for the PageRank problem. SIAM J. Sci. Comp. 27(6):2112-2120, 2006.
[LM05] Amy N. Langville and Carl D. Meyer. A survey of eigenvector methods of web information retrieval. SIAM Rev., 47(1):135–161, 2005.
[LM06] Amy N. Langville and Carl D. Meyer. Google’s PageRank and Beyond: The Science of Search Engine Rankings. Princeton University Press, Princeton, NJ, 2006.
[LS99] Daniel D. Lee and H. Sebastian Seung. Learning the parts of objects by non-negative matrix factorization. Nature, 401:788–791, 1999.
[LS00] Daniel D. Lee and H. Sebastian Seung. Algorithms for the non-negative matrix factorization. Adv. Neur. Inform. Proc., 13:556-562, 2001.
[Med03] Medlars test collection, 2003. http://www.cs.utk.edu/~lsi/ [Mey00] Carl D. Meyer. Matrix Analysis and Applied Linear Algebra. SIAM, Philadelphia, 2000. [NZJ01] Andrew Y. Ng, Alice X. Zheng, and Michael I. Jordan. Link analysis, eigenvectors and stability. In
The Seventh International Joint Conference on Artificial Intelligence, Seattle, WA, 2001. [PT94] Pentti Paatero and U. Tapper. Positive matrix factorization: a non-negative factor model with
optimal utilization of error estimates of data values. Environmetrics, 5:111–126, 1994. [PT97] Pentti Paatero and U. Tapper. Least squares formulation of robust non-negative factor analysis.
Chemomet. Intell. Lab. Sys., 37:23–35, 1997. [SB83] Gerard Salton and Chris Buckley. Introduction to Modern Information Retrieval. McGraw-Hill, New
York, 1983. [SBP04] Farial Shahnaz, Michael W. Berry, V. Paul Pauca, and Robert J. Plemmons. Document clustering
using nonnegative matrix factorization. J. Inform. Proc. Man.,42(2):373-386, 2006. [TM03] Michael Totty and Mylene Mangalindan. As Google becomes web’s gatekeeper, sites fight to get
in. Wall Street Journal, CCXLI(39), 2003. February 26. [WB98] Dian I. Witter and Michael W. Berry. Downdating the latent semantic indexing model for con-
ceptual information retrieval. Comp. J., 41(1):589–601, 1998. [ZBR01] Xiaoyan Zhang, Michael W. Berry, and Padma Raghavan. Level search schemes for information
filtering and retrieval. Inform. Proc. Man., 37:313–334, 2001. [ZMS98] Hongyuan Zha, Osni Marques, and Horst D. Simon. A subspace-based model for information
retrieval with applications in latent semantic indexing. Lect. Notes Comp. Sci., 1457:29–42, 1998.


















