
Information and Coding Theory Transmission over lossless channels. Entropy. Compression codes -...
68
Information and Information and Coding Theory Coding Theory Transmission over lossless channels. Transmission over lossless channels. Entropy. Compression codes - Entropy. Compression codes - Shannon code, Huffman code, Shannon code, Huffman code, arithmetic code. arithmetic code. Juris Viksna, 201
-
Upload
kristopher-hampton -
Category
Documents
-
view
234 -
download
2
Transcript of Information and Coding Theory Transmission over lossless channels. Entropy. Compression codes -...

Information and Information and Coding TheoryCoding Theory
Transmission over lossless channels. Transmission over lossless channels. Entropy. Compression codes -Entropy. Compression codes -Shannon code, Huffman code, Shannon code, Huffman code,
arithmetic code. arithmetic code. Juris Viksna, 2015
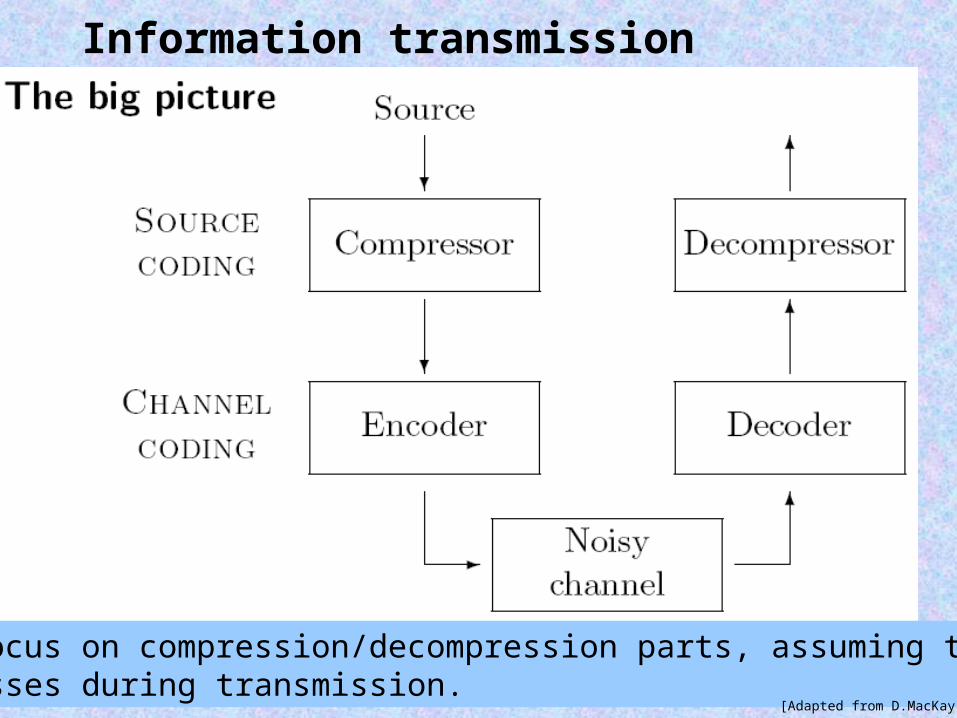
Information transmission
We will focus on compression/decompression parts, assuming that thereare no losses during transmission.
[Adapted from D.MacKay]
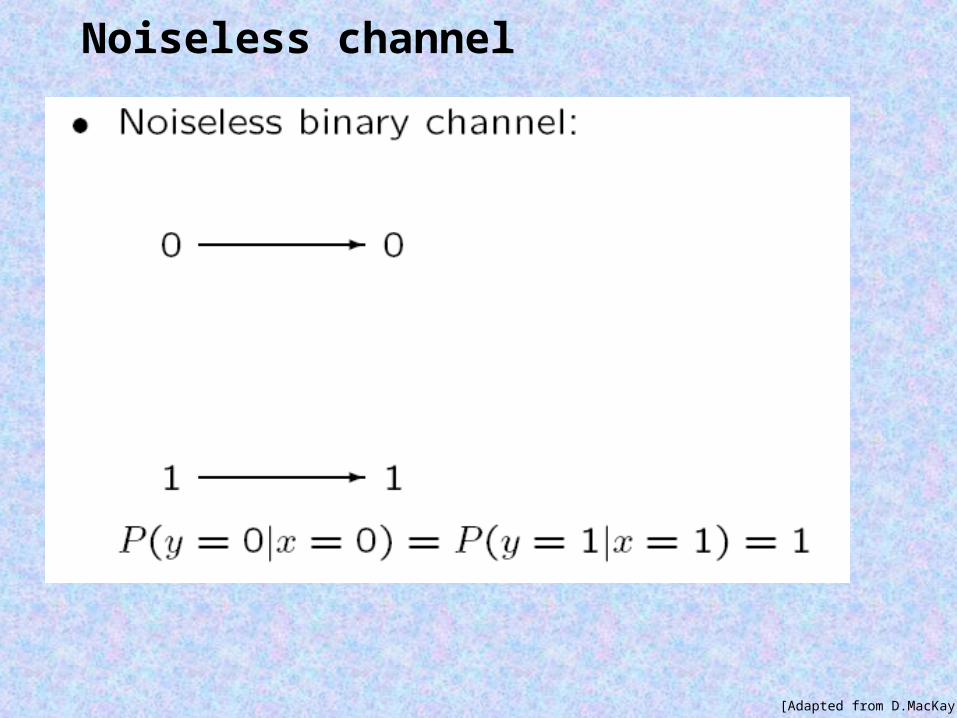
Noiseless channel
[Adapted from D.MacKay]
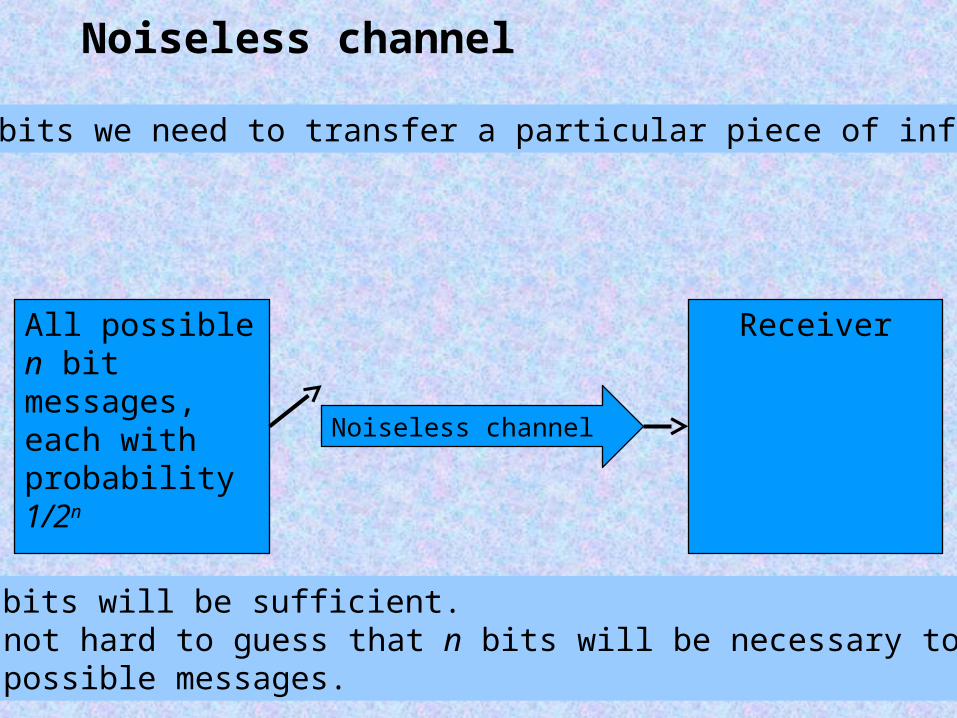
Noiseless channel
How many bits we need to transfer a particular piece of information?
All possible n bit messages, each with probability1/2n Noiseless channel
Receiver
Obviously n bits will be sufficient.Also, it is not hard to guess that n bits will be necessary to distinguishbetween all possible messages.

Noiseless channel
All possible n bit messages.
Msg. Prob.000000... ½111111... ½other 0
Noiseless channel
Receiver
n bits will still be sufficient.However, we can do quite nicely with just 1 bit!
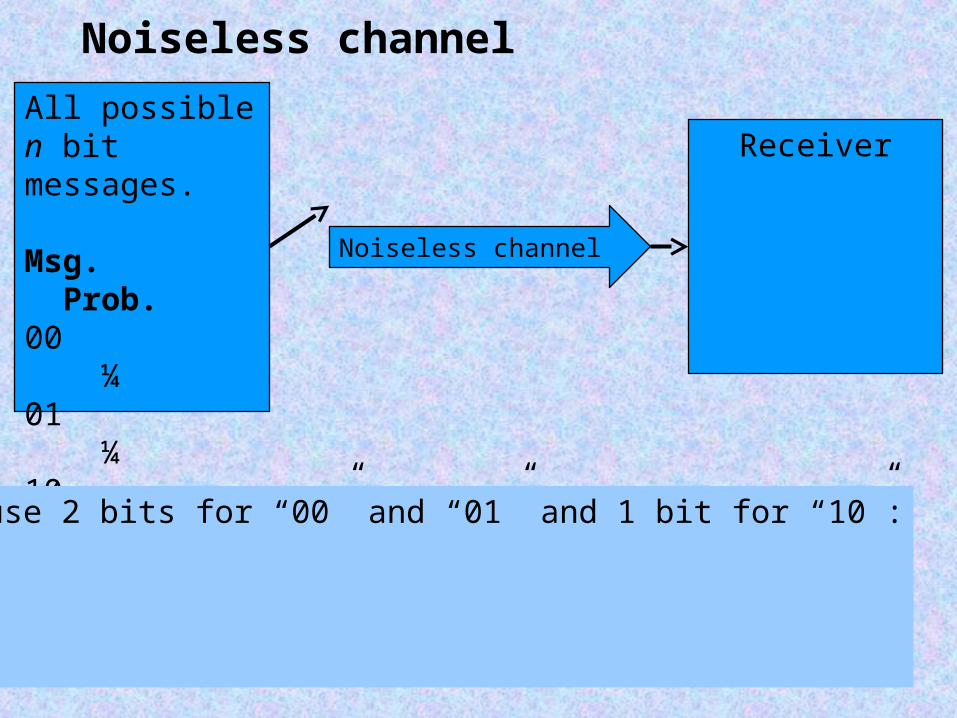
Noiseless channel
All possible n bit messages.
Msg. Prob.00 ¼01 ¼10 ½11 0
Noiseless channel
Receiver
Try to use 2 bits for “00” and “01” and 1 bit for “10”:
00 0001 0110 1

Noiseless channel
All possible n bit messages, the probability of message i being pi.
Noiseless channel
Receiver
We can try to generalize this by defining entropy (the minimal averagenumber of bits we need to distinguish between messages) in thefollowing way:
Derived from the Greek εντροπία "a turning towards" (εν- "in" + τροπή "a turning").

Entropy - The idea
The entropy, H, of a discrete random variable X is a measure of the amount of uncertainty associated with the value of X.
[Adapted from T.Mitchell]

Entropy - The idea
[Adapted from T.Mitchell]

Entropy - Definition
Example[Adapted from D.MacKay]

Entropy - Definition
[Adapted from D.MacKay]
NB!!!If not explicitly stated otherwise, in this course (as well in Computer Science in general)expressions log x denote logarithm of base 2 (i.e. log2 x).

Entropy - Definition
The entropy, H, of a discrete random variable X is a measure of the amount of uncertainty associated with the value of X.
[Adapted from T.Mitchell]

Entropy - Some examples
[Adapted from T.Mitchell]

Entropy - Some examples
[Adapted from T.Mitchell]
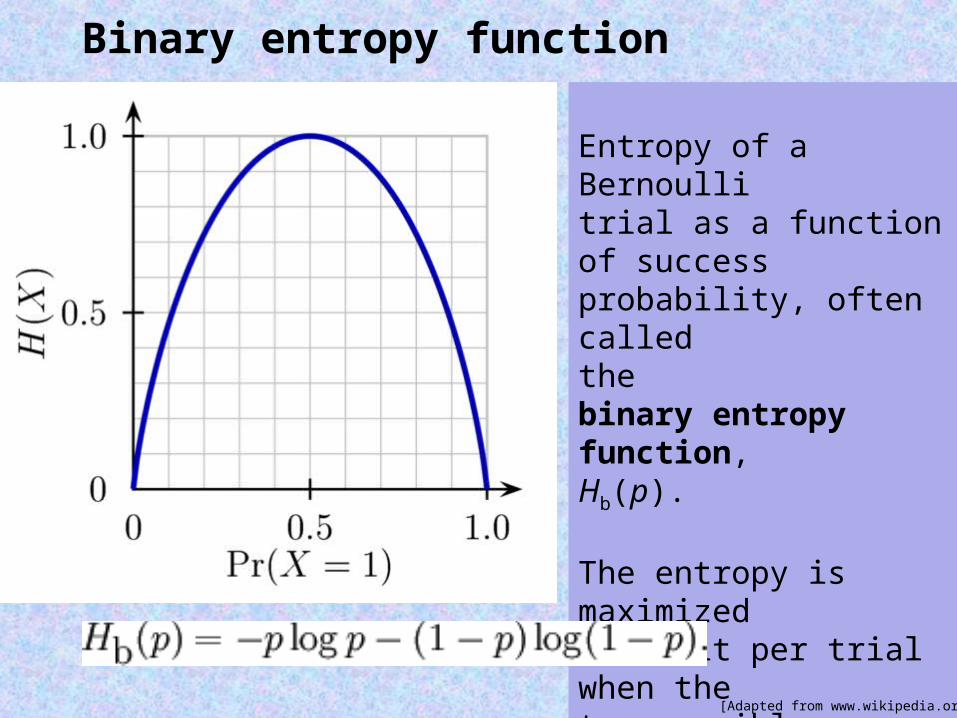
Binary entropy function
Entropy of a Bernoullitrial as a function of success probability, often called the binary entropy function,Hb(p).
The entropy is maximized at 1 bit per trial when the two possible outcomes are equally probable, as in an unbiased coin toss.
[Adapted from www.wikipedia.org]

Entropy - some properties
[Adapted from D.MacKay]

Entropy - some propertiesEntropy is maximized if probability distribution is uniform – i.e. allprobabilities pi are equal.
Sketch of proof:Assume probabilities p and q, then taking both probabilities equal to (p+q)/2 entropy does not decrease.
H(p,q) = – (p log p + q log q) H((p+q)/2, (p+q)/2) = – (p+q) log ((p+q)/2))
– (p+q) log ((p+q)/2)) + (p log p + q log q) – (p+q) log ((pq)1/2) + (p log p + q log q) = – (p/2+q/2) (log p + log q) + (p log p + q log q) = log p (1/2p – 1/2q)+log q (1/2q – 1/2p) = 1/2(p –q)(log p – log q) 0
In addition we need also some continuity assumptions about H.

Joint entropyAssume that we have a set of symbols with known frequenciesof symbol occurrences. We have assumed that on average we will need H() bits to distinguish between symbols.
What about sequences of length n of symbols from (assuming independent occurrence of each symbol with the given frequency)?
The entropy of n will be:
it turns out that H(n) = nH().
Later we will show that (assuming some restrictions) the encoding thatuse nH() bits on average are the best we can get.
sequencesall
anaanan ppppH
_11 )...log(...)(

Joint entropy
The joint entropy of two discrete random variables X and Y is merely the entropy of their pairing: (X,Y). This implies that if X and Y are independent, then their joint entropy is the sum of their individual entropies.
[Adapted from D.MacKay]

Conditional entropy
The conditional entropy of X given random variable Y (also called the equivocation of X about Y) is the average conditional entropy over Y:
[Adapted from D.MacKay]

Conditional entropy
[Adapted from D.MacKay]

Mutual information
Mutual information measures the amount of information that can be obtained about one random variable by observing another.
Mutual information is symmetric:
[Adapted from D.MacKay]

Entropy (summarized)
Relations between entropies, conditional entropies, joint entropy and mutual information.
[Adapted from D.MacKay]

Entropy - example
[Adapted from D.MacKay]

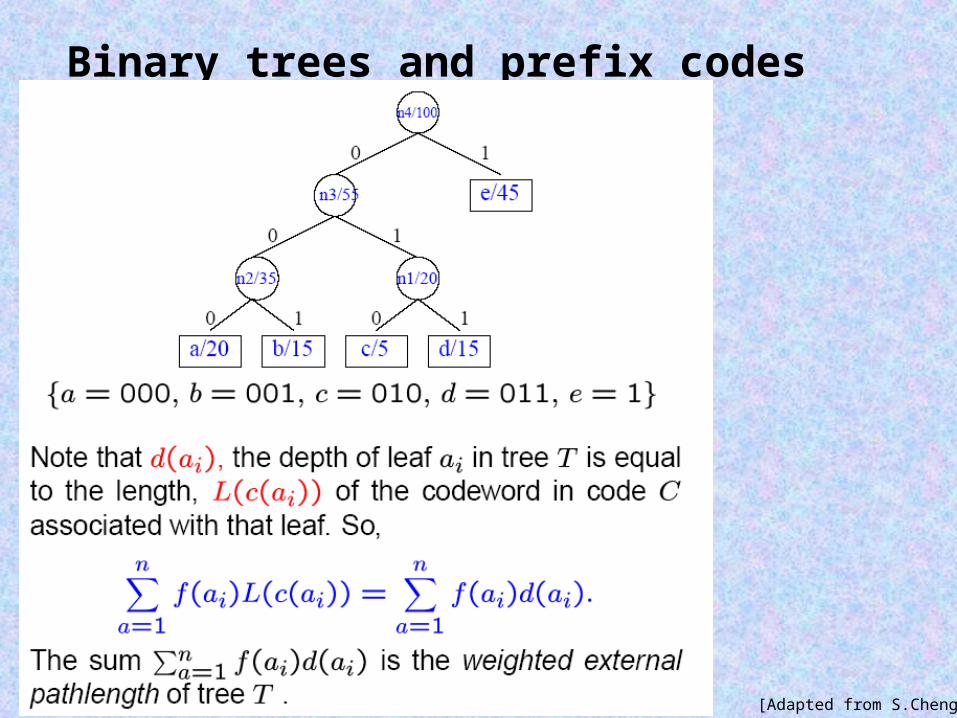
We have some motivation to think that H(X) should represent the minimal number of bits that on average will be needed to transmit a random message xX.
Another property that could be expected from a good compression code is that probabilities of all code words should be as similar as possible.
Entropy and data compression
[Adapted from D.MacKay]

The minimal number of weightings that is needed is three. •can you devise a strategy that uses only three weightings?•can you show that there is no strategy requiring less than 3 weightings?
It turns out that “good” strategy needs to use “most informative” weightings with probabilities of all their outcomes being as similar as possible.
Coin weighting problem
[Adapted from D.MacKay]
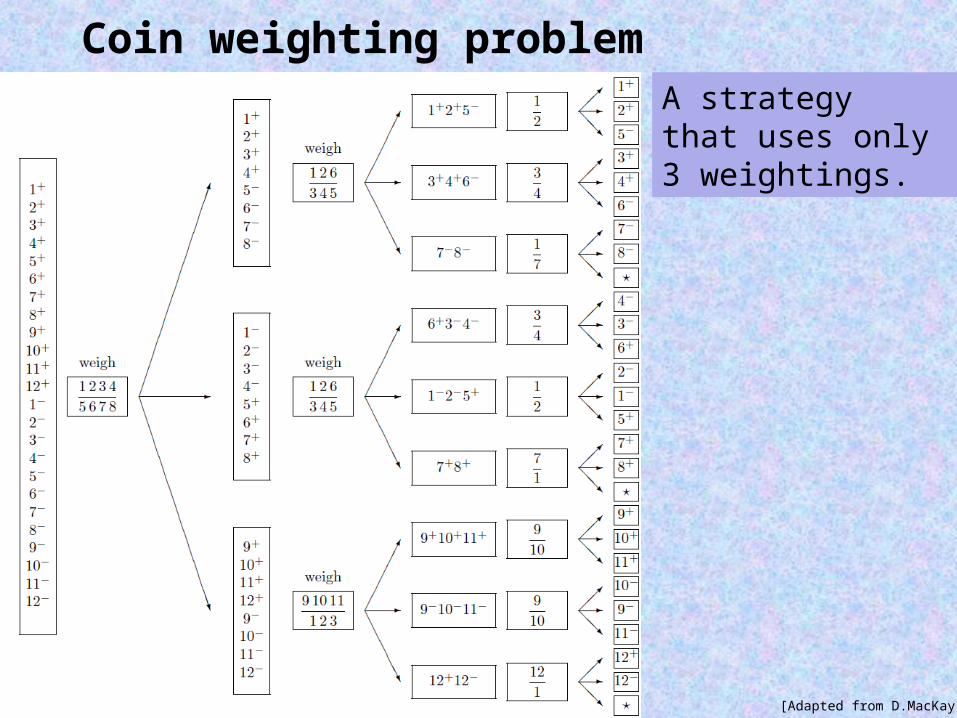
Coin weighting problem
[Adapted from D.MacKay]
A strategy that uses only 3 weightings.
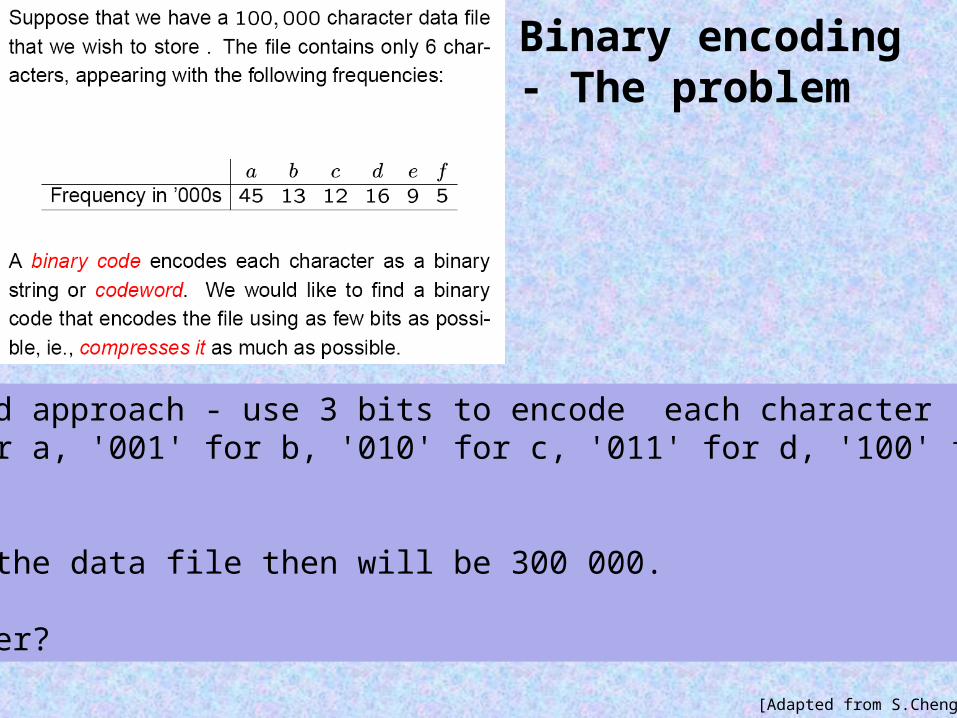
Binary encoding - The problem
Straightforward approach - use 3 bits to encode each character (e.g. '000' for a, '001' for b, '010' for c, '011' for d, '100' for e, '101' for f). The length of the data file then will be 300 000.
Can we do better?
[Adapted from S.Cheng]

Variable length codes
[Adapted from S.Cheng]

Encoding
[Adapted from S.Cheng]

Decoding
[Adapted from S.Cheng]

Prefix codes
[Adapted from S.Cheng]

Prefix codes
[Adapted from S.Cheng]
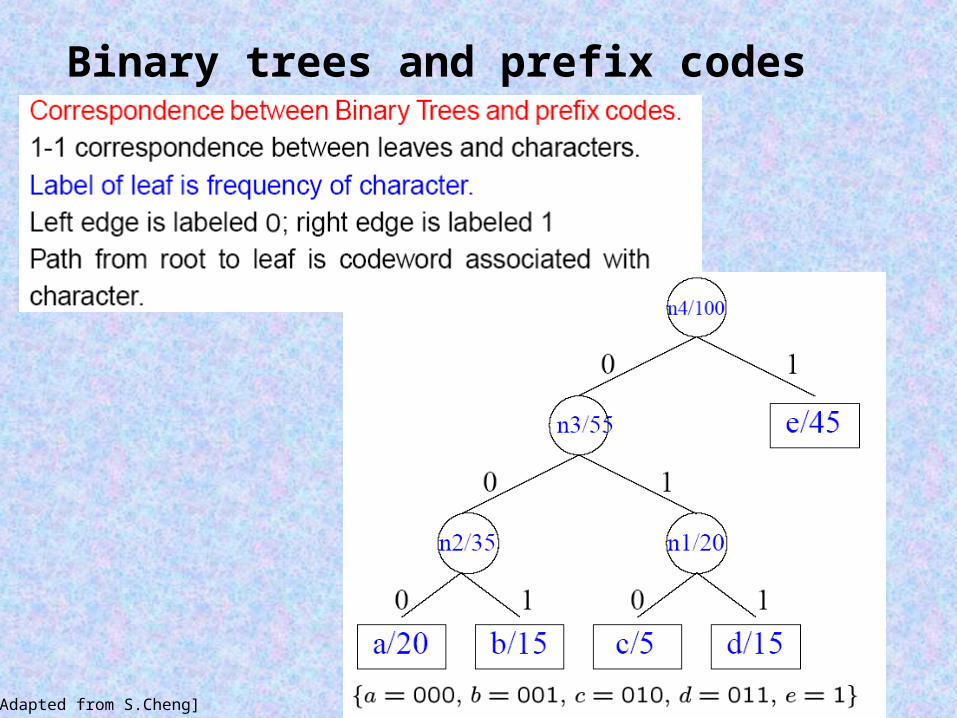
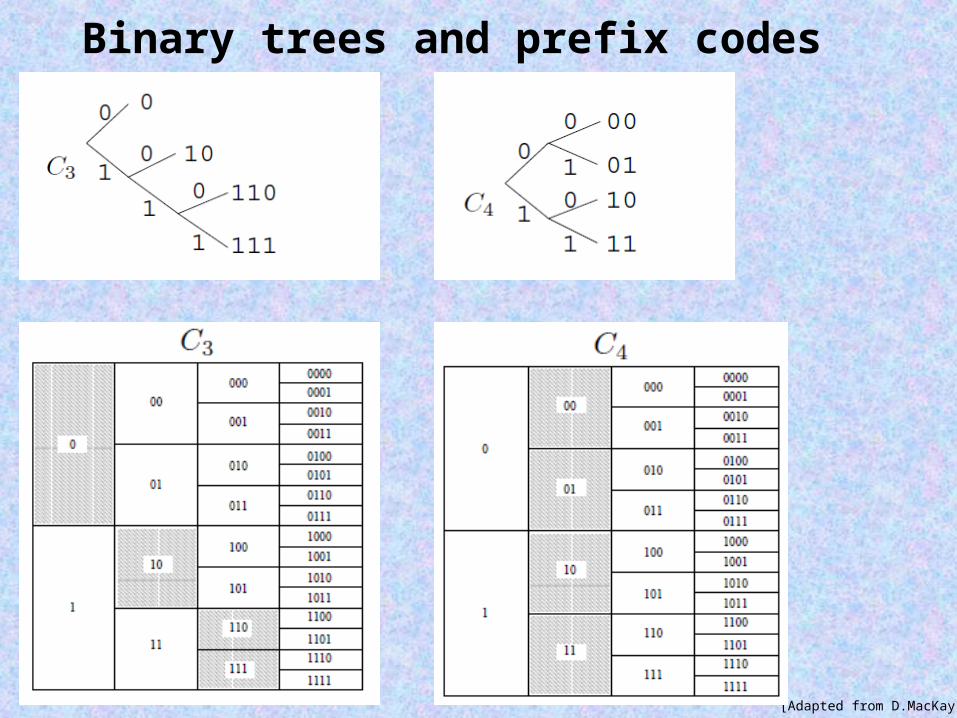
Binary trees and prefix codes
[Adapted from S.Cheng]

Binary trees and prefix codes
[Adapted from D.MacKay]

Binary trees and prefix codes
[Adapted from D.MacKay]
Another requirement for uniquely decodable codes – Kraft inequality:
For any uniquely decodable code the codeword lengths must satisfy:
Binary trees and prefix codes
[Adapted from D.MacKay]
Binary trees and prefix codes
[Adapted from S.Cheng]

Optimal codes
Is this prefix code optimal?[Adapted from S.Cheng]

Optimal codes
[Adapted from S.Cheng]

Shannon encoding
[Adapted from M.Brookes]

Huffman encoding
[Adapted from S.Cheng]
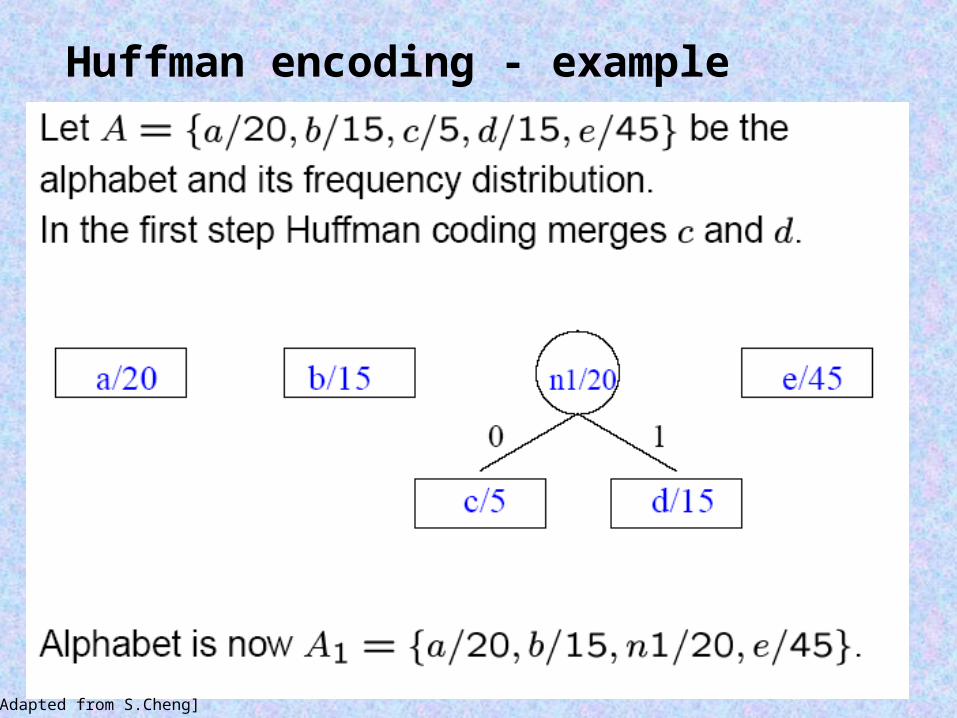
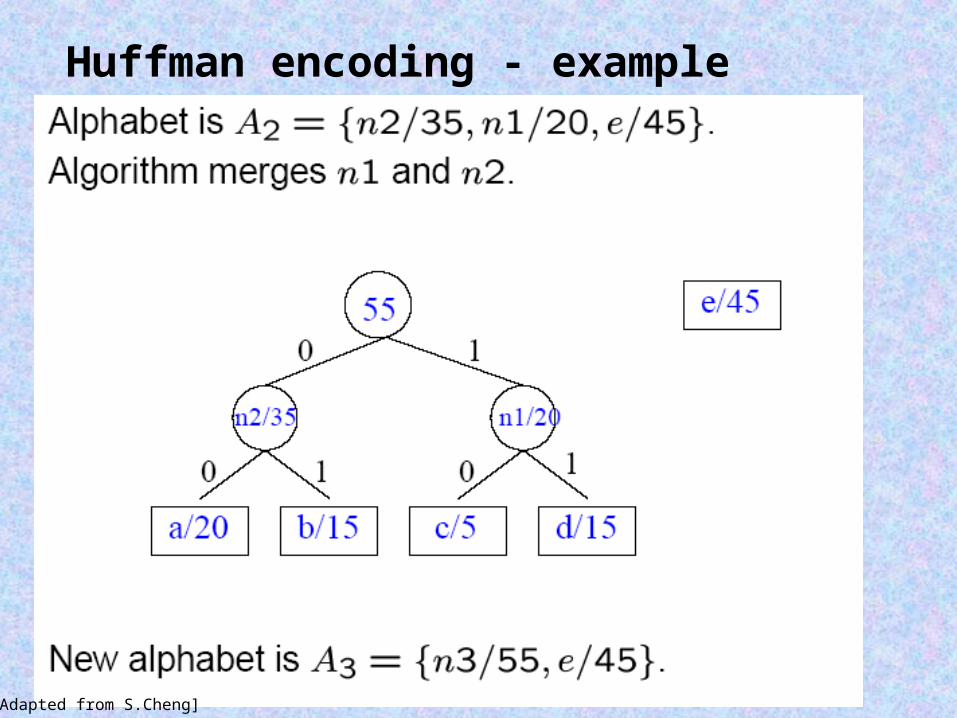
Huffman encoding - example
[Adapted from S.Cheng]
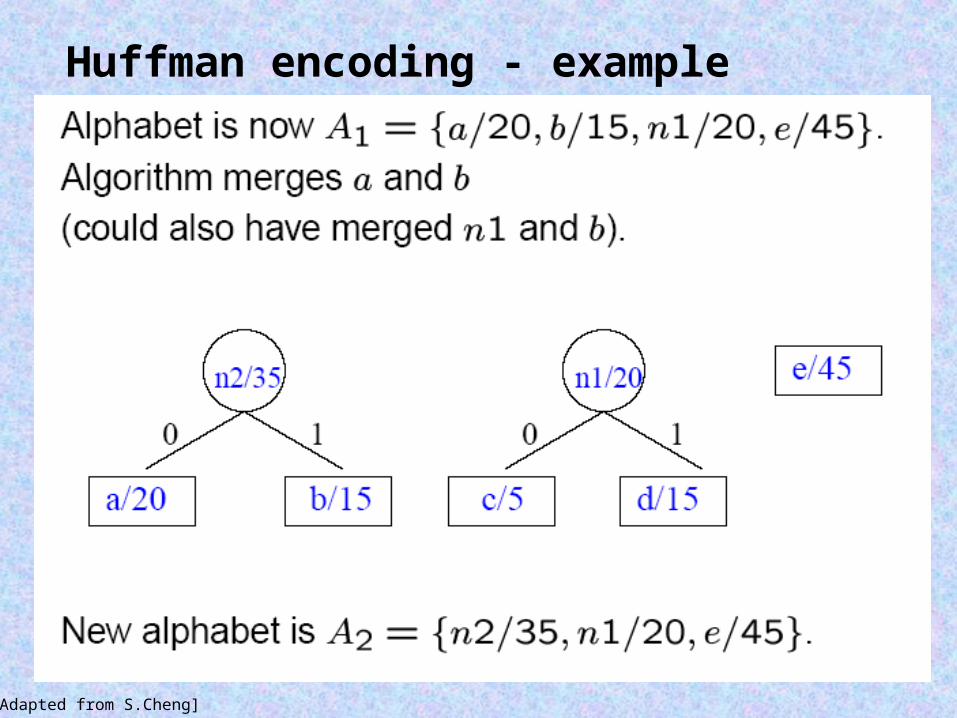
Huffman encoding - example
[Adapted from S.Cheng]
Huffman encoding - example
[Adapted from S.Cheng]
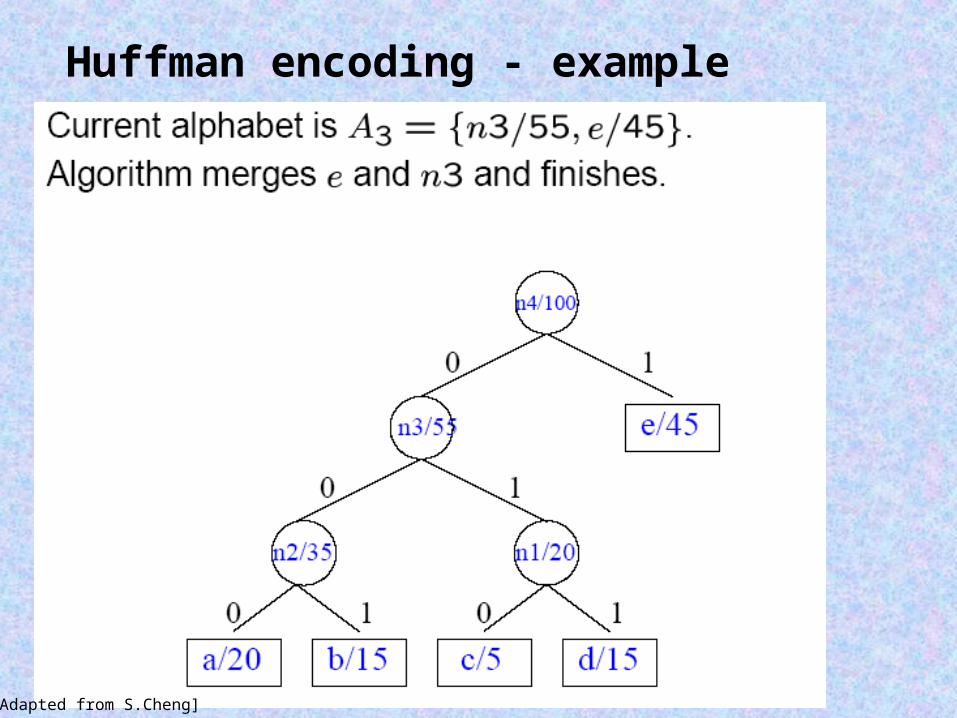
Huffman encoding - example
[Adapted from S.Cheng]
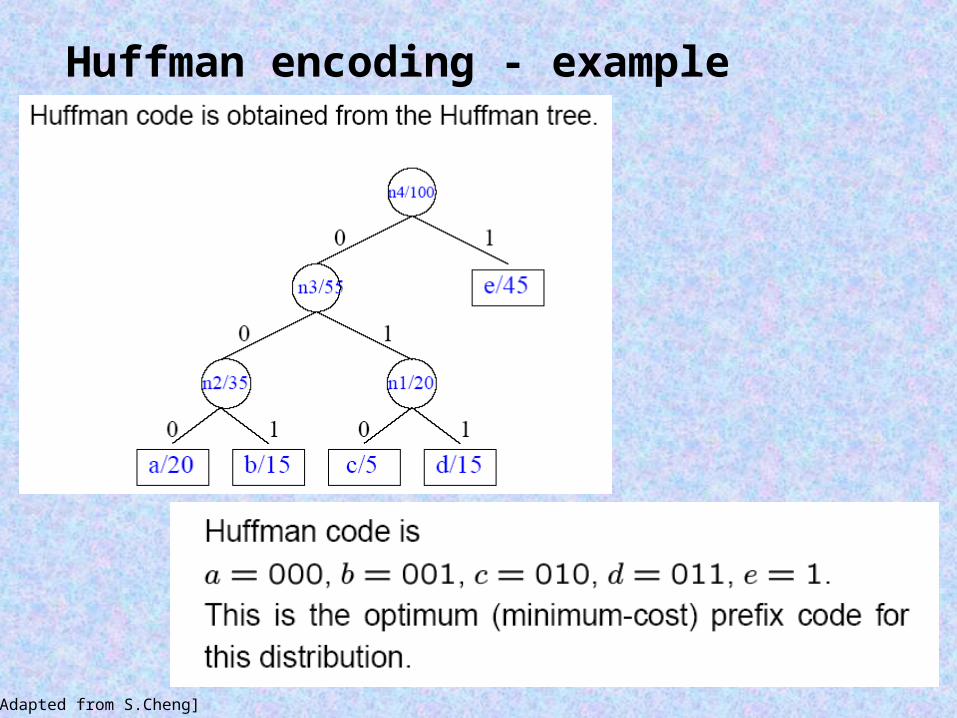
Huffman encoding - example
[Adapted from S.Cheng]

Huffman encoding - example 2
Construct Huffman code for symbols with frequencies:
A 15D 6F 6H 3I 1M 2N 2U 2V 2# 7
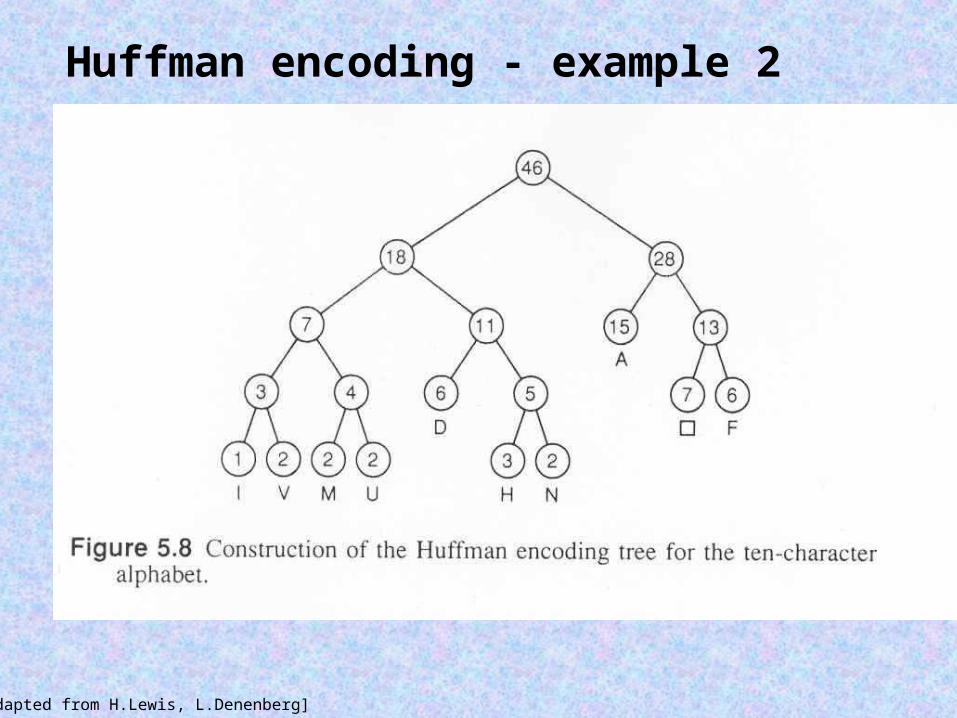
Huffman encoding - example 2
[Adapted from H.Lewis, L.Denenberg]

Huffman encoding - algorithm
[Adapted from D.MacKay]

Huffman encoding - algorithm
[Adapted from S.Cheng]

Huffman code for English alphabet
[Adapted from D.MacKay]

Huffman encoding - optimality
[Adapted from H.Lewis and L.Denenberg]
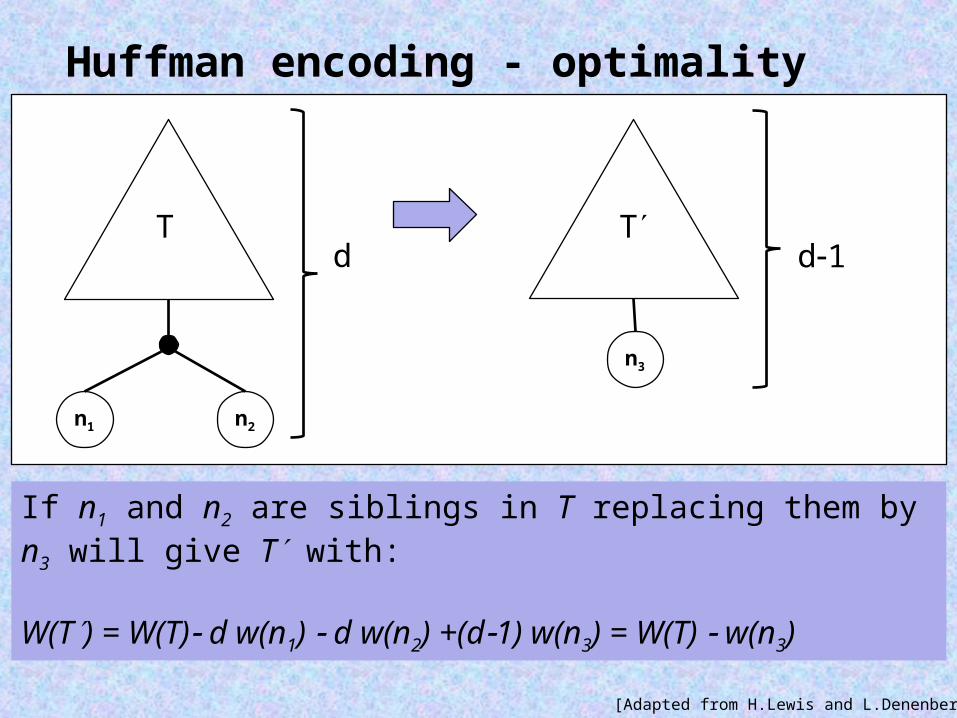
Huffman encoding - optimality
[Adapted from H.Lewis and L.Denenberg]
If n1 and n2 are siblings in T replacing them by n3 will give T with:
W(T) = W(T) d w(n1) d w(n2) +(d1) w(n3) = W(T) w(n3)
n1 n2
n3
d d1T T
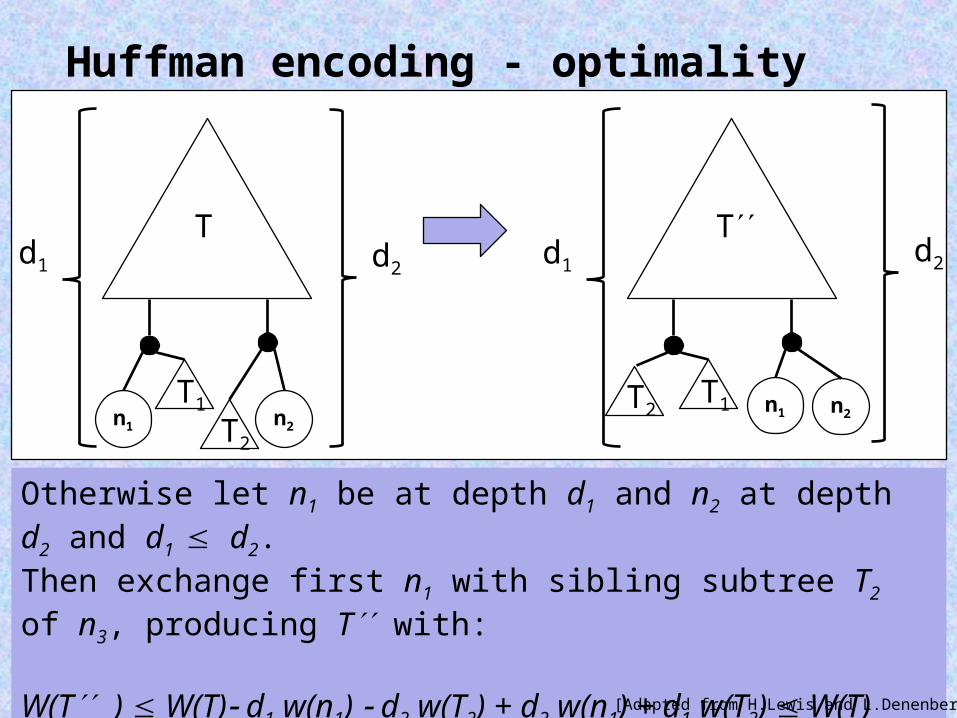
Otherwise let n1 be at depth d1 and n2 at depth d2 and d1 d2.Then exchange first n1 with sibling subtree T2 of n3, producing T with:
W(T ) W(T) d1 w(n1) d2 w(T2) + d2 w(n1) + d1 w(T2) W(T)
Now n1 and n2 are siblings and replace T with T as in previous case.
Huffman encoding - optimality
[Adapted from H.Lewis and L.Denenberg]
n1 n2
d2
Td1
T1
T2
n1 n2
d2
Td1
T1T2

Huffman encoding - optimality
[Adapted from H.Lewis and L.Denenberg]
Proof by induction:
- n = 1 OK
- assume T is obtained by Huffman algorithm and X is an optimal tree. Construct T’ and X’ as described by lemma. Then:
w(T’) w(X’)w(T) = w(T’)+C(n1)+C(n2)w(X) w(X’)+C(n1)+C(n2)w(T) w(X)

Huffman encoding and entropy
W() - average number of bits used by Huffman codeH() - entropy
Then H() W()<H()+1.
Assume all probabilities are in form 1/2k.Then we can prove by induction that H() =W() (we can state that symbol with probability 1/2k. will always be at depth k)
- obvious if ||=1 or ||=2- otherwise there will always be two symbols having smallest probabilities both equal to 1/2k
- these will be joined by Huffman algorithm, thus we reduced the problem to alphabet containing one symbol less.

Huffman encoding and entropy
W() - average number of bits used by Huffman codeH() - entropy
Then W()<H()+1.
Consider symbols a with probabilities 1/2k+1 p(a) < 1/2k
- modify alphabet: for each a reduce its probability to 1/2k+1
- add extra symbols with probabilities in form 1/2k (so that sum of all probabilities is 1)- construct Huffman encoding tree- the depth of initial symbols will be k+1, thus W() < H()+1- we can prune the tree by deleting extra symbols, this procedure certainly will decrease W()

Huffman encoding and entropy
Can we claim that H() W()<H()+1?
In general case symbol with probability 1/2k can be at depth other than k:
Consider two symbols with probabilities 1/2k and 1 1/2k, both of themwill be at depth 1. However changing both probabilities to ½ the entropy will only increase.
By induction we can show that all symbol probabilities can be all changed to have a form 1/2k in such a way that entropy does not decrease and the Huffman tree does not change its structure.
Thus we always will have H() W()<H()+1.

Unlike the variable-length codes described previously, arithmetic coding, generates non-block codes. In arithmetic coding, a one-to-one correspondence between source symbols and code words does not exist. Instead, an entire sequence of source symbols (or message) is assigned a single arithmetic code word.
The code word itself defines an interval of real numbers between 0 and 1. As the number of symbols in the message increases, the interval used to represent it becomes smaller and the number of information units (say, bits) required to represent the interval becomes larger. Each symbol of the message reduces the size of the interval in accordance with the probability of occurrence. It is supposed to approach the limit set by entropy.
Arithmetic coding

Let the message to be encoded be a1a2a3a3a4
Arithmetic coding

0.2
0.4
0.8
0.04
0.08
0.16
0.048
0.056
0.072
0.0592
0.0624
0.0688
0.06368
0.06496
Arithmetic coding

So, any number in the interval [0.06752,0.0688), for example 0.068, can be used to represent the message.
Here 3 decimal digits are used to represent the 5 symbol source message. This translates into 3/5 or 0.6 decimal digits per source symbol and compares favourably with the entropy of
(3x0.2log100.2+2x0.4log100.4) = 0.5786 digits per symbol
As the length of the sequence increases, the resulting arithmetic code approaches the bound set by entropy.
In practice, the length fails to reach the lower bound, because:
• The addition of the end of message indicator that is needed to separate one message from another
• The use of finite precision arithmetic
Arithmetic coding
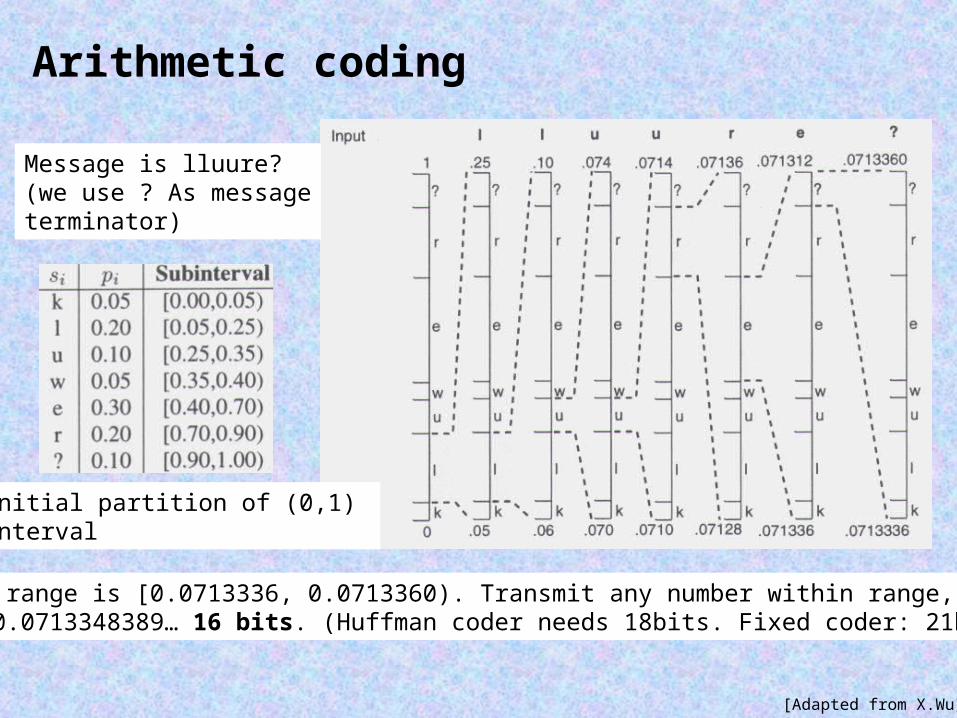
Arithmetic coding
Final range is [0.0713336, 0.0713360). Transmit any number within range, e.g. 0.0713348389… 16 bits. (Huffman coder needs 18bits. Fixed coder: 21bits).
Message is lluure?(we use ? As messageterminator)
Initial partition of (0,1) interval
[Adapted from X.Wu]
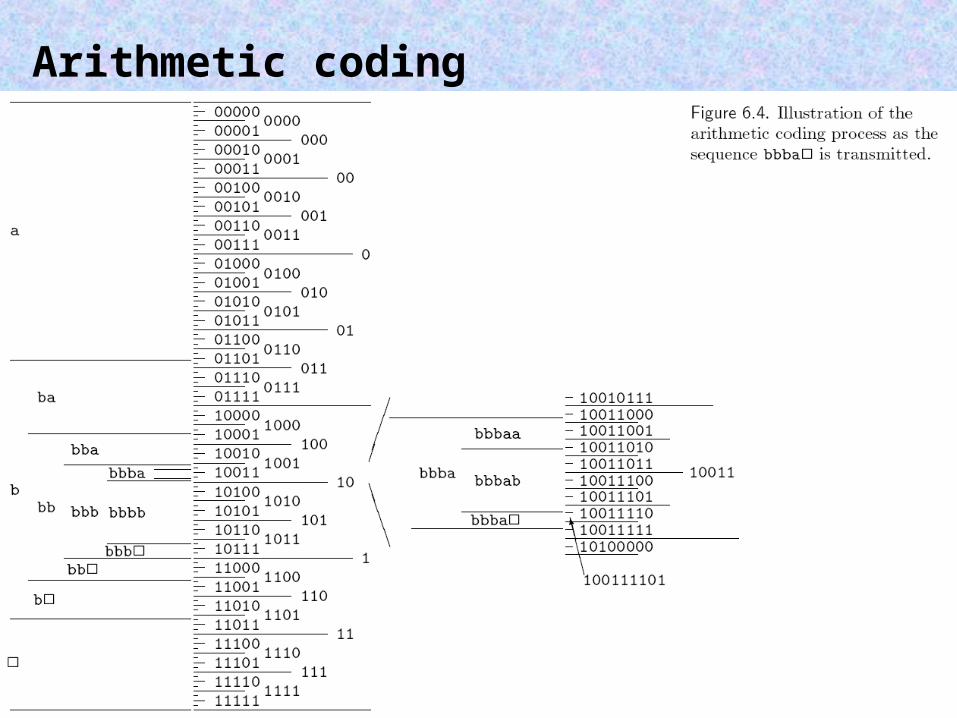
Arithmetic coding

Therefore, the message is:
a3a3a1a2a4
Decoding:
Decode 0.572 (assuming we know that the number of symbols = 5)
Since 0.8> code word > 0.4, the first symbol should be a3.
1.0
0.8
0.4
0.2
0.8
0.72
0.56
0.48
0.40.0
0.72
0.688
0.624
0.592
0.592
0.5856
0.5728
0.5664
0.5728
0.57152
056896
0.56768
0.56 0.56 0.5664
Arithmetic coding

Golomb-Rice codes
[Adapted from X.Wu]
• Golomb code of parameter m for positive integer n is given by coding n div m (quotient) in unary and n mod m (remainder) in binary.
• When m is power of 2, a simple realization also known as Rice code.
Example: n = 22, m = 4.n = 22 = ‘10110’. Shift right n by k = log m (= 2) bits. We get ‘101’.Output 5 (for ‘101’) ‘0’s followed by ‘1’. Then also output the last k bits of n.So, Golomb-Rice code for 22 is ‘00000110’.
Decoding is simple: count up to first 1. This gives us the number 5. Then read the next k (=2) bits - ‘10’ , and n = m 5 + 2 (for ‘10’) = 20 + 2 = 22.

• Golomb code of parameter m for positive integer n is given by coding n div m (quotient) in unary and n mod m (remainder) in binary.
• When m is power of 2, a simple realization also known as Rice code.
What parameters one should chose and why these codes are good?
p = P(X = 0) m = 1/log (1 p)
It turns out that for large m such Golomb codes are quite good and in certain sense equivalent (???) Huffman code (and no need to compute the code – saves time and practically not doable for larger m).
Widely used in audio and image compression (FLAC, MPEG-4)
Golomb-Rice codes
[Adapted from X.Wu]
Well, at least a “popular textbook claim”. What certainly matters is the choice of block length K for code to make any sense K should be larger, but not much larger than m. As it seems the best choice of K sometimes even is determined experimentally...It is also difficult to find the clear statements regarding equivalence to Huffman codes (although there are good experimental demonstrations that with well chosen parameters the performance might approach that of arithmetic coding).


















