

The HathiTrust Research Center: Big Data Analytics in a Secure Data Framework
Upload
liberty-goreCategory
view
217download
1
Information Analysis at Scale:
HathiTrust Research Center
Beth Plale
Director, Data to Insight Center
Co-Director, HathiTrust Research Center
November 12, 2012

2
HathiTrust• Objective: Contribute to the common good by collecting, organizing,
preserving, communicating, and sharing the record of human knowledge.
• Launched in October 2008– University of Michigan– Indiana University
• Expanded to include content from – CIC Member Libraries– UC System Libraries– Internet Archive– Now includes more than 70 partner institutions

3
HathiTrust Research Center • Mission: provision of computational access to comprehensive
body of published works for scholarship and education.
• HTRC is founded as a joint venture between Indiana University and the University of Illinois Urbana-Champaign, aimed at solving the difficult challenges of increasing computational access to the public domain and copyrighted material in HathiTrust.

4
HTRC Long-term goals
• Support innovation in Cyberinfrastructure to deliver optimal access and use of HathiTrust corpus.
• Implement “Non-consumptive” research: a technical and intellectual challenge
• Identify and host existing data analysis, text mining and retrieval tools that are of interest to the community.
• Stimulate development of new analytical methods and tools. We hope that the scale of the HTRC will promote new levels of collaboration in tool development.

5
The HTRC Collection• Public Domain Materials of the HathiTrust
– 2,592,097 Volumes– Data Size
• 2.3 TB in raw OCR’d text• 3.7 TB of managed OCR’d text• 1.85 TB Solr Index
– Monthly Updates• And irregular data delete requests

6
Primary Functions To Support• Data discovery
– Searching – Creating and saving collections
• Service Discovery– Algorithms, analyses, and processes– Parameters and outputs
• Data storage and retrieval• Computational resources• APIs for controlled access to data and services

Experiment: Large Scale Data Analysis on XSEDE

Experimental Environment and Results
• Dataset 2,592,210 volumes, in total 2.1 TB, divided into 1024 partitions of 2GB each• Computation platform
XSEDE Blacklight, 1024-core of each 2.27 GHz, 8192 GB memory. Each core processes one partition• Results
Whole corpus word count finished in 1,454 seconds or 24.23 minutes
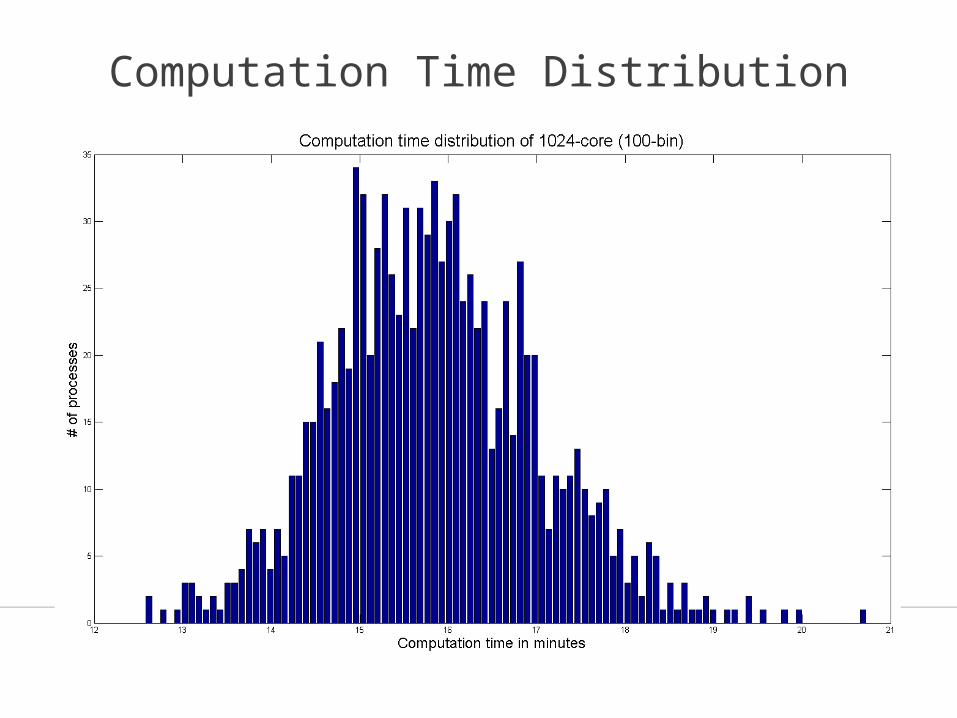
Computation Time Distribution

Word Frequency Distribution

HTRC UnCamp Sept 2012

13

14
Issues in Developing Research Collections
15
16

17
18

19
20

21
Issues in Developing Research Collections
• Search Methods– Known item search via fielded bibliographic data
• Title• Author• Standard number
– Sparsely populated data – Full text access
• All words in OCR’d text• All words in bibliographic data

22
OCR Errors in Public Domain Corpus• Kinds of errors
– Hyphens– Rules and Dictionaries– Pagination– Multiple language texts– Page headers, footers, marginalia – Non-text elements
– Tables and highly structured document elements– Imbedded images– Scientific notations– Book design decorative elements

Automatic Text Correction
• 99,427 human expert verified rules were applied
• 256,000 volumes– 70 million pages– 270 words per page– 19 billion words– 125 million words required correction
• Total percentage of words needing correction was 0.65%. Probability that any volume has one or more errors was 84.9%.
23

Automatic Correction Details
• Average hit rate per page = 1.898
• Average hit rate per word = 0.006
• Total Bytes Read = 121 GB
• Total Execution Time = 3.80 hrs
24

25
Problem Examples
Hyphens:1. Combining words2. Crossing pages3. Page headers

26
Issues with Text
OriginalA D 1817 57°GEO III C xxix 653 the faicl Commifiioners or Truftees orotherPerfons as aforefaid to iffue their Preceptor Precepts to the Sheriff orSheriffs or Bailiff or otherproper Officer of the City Borough or County wherein fuch parochial orother Diftrift hall be fituate
Rules-based CorrectionA D 1817 57°GEO III C xxix 653 the faicl Commifiioners or #trustees# orother#persons# as #aforesaid# to #issue# their Preceptor Precepts to the Sheriffor Sheriffs or Bailiff or otherproper Officer of the City Borough or County wherein #such# parochial orother #district# hall be #situate#

27
HTRC Research Sandbox
• A small subset of the collection– Bibliographic data (in MarcXML)– Images– OCR text
• 250,000 non-Google digitized public domain volumes (or the 35,000 IU digitized public domain collection)
• Image training sets– Clean page images and text– Bad page images and text

28
Metadata as Research Object
• An IU researcher is interested in publishing trends from 1700 – 1899.– Publication dates– Publishers– Publication location
• A research team from UWashington is interested in ontology developments
– Subject headings– Terms in notes and other fields

29
Possible Metadata Research• Using the full text and images to identify
– Content metadata• Topics, keywords, and subjects• Genre • Publication data • Additional characteristics for content identification and author
demographics– Structural component identification
• Chapters (first page of each chapter)• Index• Preface• Table of Contents• Genre as structure

30
Possible Text Research• OCR correction algorithms
– Era based rules • Dictionary • Hyphenation
– Page awareness• Page numbers• Running heading• Cross page hyphenation issues
• New OCR algorithms– Era based rules– Identification of non-text elements – Page awareness

31
[email protected] http://d2i.indiana.edu
• Visit http://www.hathitrust.org/htrc for more information


















