
Informatica Data Quality/Data Explorer Advanced Edition ... · Informatica Data Quality and...
31
Informatica Data Quality/Data Explorer Advanced Edition (Version 9.0.1) System Performance Guidelines
Transcript of Informatica Data Quality/Data Explorer Advanced Edition ... · Informatica Data Quality and...

Informatica Data Quality/Data Explorer Advanced Edition(Version 9.0.1)
System Performance Guidelines

Informatica Data Quality/Data Explorer Advanced Edition System Performance Guidelines
Version 9.0.1January 2011
Copyright (c) 2010 Informatica. All rights reserved.
This software and documentation contain proprietary information of Informatica Corporation and are provided under a license agreement containing restrictions on use anddisclosure and are also protected by copyright law. Reverse engineering of the software is prohibited. No part of this document may be reproduced or transmitted in any form,by any means (electronic, photocopying, recording or otherwise) without prior consent of Informatica Corporation. This Software may be protected by U.S. and/or internationalPatents and other Patents Pending.
Use, duplication, or disclosure of the Software by the U.S. Government is subject to the restrictions set forth in the applicable software license agreement and as provided inDFARS 227.7202-1(a) and 227.7702-3(a) (1995), DFARS 252.227-7013©(1)(ii) (OCT 1988), FAR 12.212(a) (1995), FAR 52.227-19, or FAR 52.227-14 (ALT III), as applicable.
The information in this product or documentation is subject to change without notice. If you find any problems in this product or documentation, please report them to us inwriting.
Informatica, Informatica Platform, Informatica Data Services, PowerCenter, PowerCenterRT, PowerCenter Connect, PowerCenter Data Analyzer, PowerExchange,PowerMart, Metadata Manager, Informatica Data Quality, Informatica Data Explorer, Informatica B2B Data Transformation, Informatica B2B Data Exchange, Informatica OnDemand, Informatica Identity Resolution, Informatica Application Information Lifecycle Management, Informatica Complex Event Processing, Ultra Messaging and InformaticaMaster Data Management are trademarks or registered trademarks of Informatica Corporation in the United States and in jurisdictions throughout the world. All other companyand product names may be trade names or trademarks of their respective owners.
Portions of this software and/or documentation are subject to copyright held by third parties, including without limitation: Copyright DataDirect Technologies. All rightsreserved. Copyright © Sun Microsystems. All rights reserved. Copyright © RSA Security Inc. All Rights Reserved. Copyright © Ordinal Technology Corp. All rightsreserved.Copyright © Aandacht c.v. All rights reserved. Copyright Genivia, Inc. All rights reserved. Copyright 2007 Isomorphic Software. All rights reserved. Copyright © MetaIntegration Technology, Inc. All rights reserved. Copyright © Oracle. All rights reserved. Copyright © Adobe Systems Incorporated. All rights reserved. Copyright © DataArt,Inc. All rights reserved. Copyright © ComponentSource. All rights reserved. Copyright © Microsoft Corporation. All rights reserved. Copyright © Rogue Wave Software, Inc. Allrights reserved. Copyright © Teradata Corporation. All rights reserved. Copyright © Yahoo! Inc. All rights reserved. Copyright © Glyph & Cog, LLC. All rights reserved.Copyright © Thinkmap, Inc. All rights reserved. Copyright © Clearpace Software Limited. All rights reserved. Copyright © Information Builders, Inc. All rights reserved.Copyright © OSS Nokalva, Inc. All rights reserved. Copyright Edifecs, Inc. All rights reserved.
This product includes software developed by the Apache Software Foundation (http://www.apache.org/), and other software which is licensed under the Apache License,Version 2.0 (the "License"). You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0. Unless required by applicable law or agreed to in writing,software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See theLicense for the specific language governing permissions and limitations under the License.
This product includes software which was developed by Mozilla (http://www.mozilla.org/), software copyright The JBoss Group, LLC, all rights reserved; software copyright ©1999-2006 by Bruno Lowagie and Paulo Soares and other software which is licensed under the GNU Lesser General Public License Agreement, which may be found at http://www.gnu.org/licenses/lgpl.html. The materials are provided free of charge by Informatica, "as-is", without warranty of any kind, either express or implied, including but notlimited to the implied warranties of merchantability and fitness for a particular purpose.
The product includes ACE(TM) and TAO(TM) software copyrighted by Douglas C. Schmidt and his research group at Washington University, University of California, Irvine,and Vanderbilt University, Copyright (©) 1993-2006, all rights reserved.
This product includes software developed by the OpenSSL Project for use in the OpenSSL Toolkit (copyright The OpenSSL Project. All Rights Reserved) and redistribution ofthis software is subject to terms available at http://www.openssl.org.
This product includes Curl software which is Copyright 1996-2007, Daniel Stenberg, <[email protected]>. All Rights Reserved. Permissions and limitations regarding thissoftware are subject to terms available at http://curl.haxx.se/docs/copyright.html. Permission to use, copy, modify, and distribute this software for any purpose with or withoutfee is hereby granted, provided that the above copyright notice and this permission notice appear in all copies.
The product includes software copyright 2001-2005 (©) MetaStuff, Ltd. All Rights Reserved. Permissions and limitations regarding this software are subject to terms availableat http://www.dom4j.org/ license.html.
The product includes software copyright © 2004-2007, The Dojo Foundation. All Rights Reserved. Permissions and limitations regarding this software are subject to termsavailable at http:// svn.dojotoolkit.org/dojo/trunk/LICENSE.
This product includes ICU software which is copyright International Business Machines Corporation and others. All rights reserved. Permissions and limitations regarding thissoftware are subject to terms available at http://source.icu-project.org/repos/icu/icu/trunk/license.html.
This product includes software copyright © 1996-2006 Per Bothner. All rights reserved. Your right to use such materials is set forth in the license which may be found at http://www.gnu.org/software/ kawa/Software-License.html.
This product includes OSSP UUID software which is Copyright © 2002 Ralf S. Engelschall, Copyright © 2002 The OSSP Project Copyright © 2002 Cable & WirelessDeutschland. Permissions and limitations regarding this software are subject to terms available at http://www.opensource.org/licenses/mit-license.php.
This product includes software developed by Boost (http://www.boost.org/) or under the Boost software license. Permissions and limitations regarding this software are subjectto terms available at http:/ /www.boost.org/LICENSE_1_0.txt.
This product includes software copyright © 1997-2007 University of Cambridge. Permissions and limitations regarding this software are subject to terms available at http://www.pcre.org/license.txt.
This product includes software copyright © 2007 The Eclipse Foundation. All Rights Reserved. Permissions and limitations regarding this software are subject to termsavailable at http:// www.eclipse.org/org/documents/epl-v10.php.
This product includes software licensed under the terms at http://www.tcl.tk/software/tcltk/license.html, http://www.bosrup.com/web/overlib/?License, http://www.stlport.org/doc/license.html, http://www.asm.ow2.org/license.html, http://www.cryptix.org/LICENSE.TXT, http://hsqldb.org/web/hsqlLicense.html, http://httpunit.sourceforge.net/doc/license.html, http://jung.sourceforge.net/license.txt , http://www.gzip.org/zlib/zlib_license.html, http://www.openldap.org/software/release/license.html, http://www.libssh2.org,http://slf4j.org/license.html, http://www.sente.ch/software/OpenSourceLicense.html, http://fusesource.com/downloads/license-agreements/fuse-message-broker-v-5-3-license-agreement, http://antlr.org/license.html, http://aopalliance.sourceforge.net/, http://www.bouncycastle.org/licence.html, http://www.jgraph.com/jgraphdownload.html, http://www.jgraph.com/jgraphdownload.html, http://www.jcraft.com/jsch/LICENSE.txt and http://jotm.objectweb.org/bsd_license.html.
This product includes software licensed under the Academic Free License (http://www.opensource.org/licenses/afl-3.0.php), the Common Development and DistributionLicense (http://www.opensource.org/licenses/cddl1.php) the Common Public License (http://www.opensource.org/licenses/cpl1.0.php) and the BSD License (http://www.opensource.org/licenses/bsd-license.php).
This product includes software copyright © 2003-2006 Joe WaInes, 2006-2007 XStream Committers. All rights reserved. Permissions and limitations regarding this softwareare subject to terms available at http://xstream.codehaus.org/license.html. This product includes software developed by the Indiana University Extreme! Lab. For furtherinformation please visit http://www.extreme.indiana.edu/.

This Software is protected by U.S. Patent Numbers 5,794,246; 6,014,670; 6,016,501; 6,029,178; 6,032,158; 6,035,307; 6,044,374; 6,092,086; 6,208,990; 6,339,775;6,640,226; 6,789,096; 6,820,077; 6,823,373; 6,850,947; 6,895,471; 7,117,215; 7,162,643; 7,254,590; 7,281,001; 7,421,458; 7,496,588; 7,523,121; 7,584,422; 7,720,842;7,721,270; and 7,774,791, international Patents and other Patents Pending.
DISCLAIMER: Informatica Corporation provides this documentation "as is" without warranty of any kind, either express or implied, including, but not limited to, the impliedwarranties of non-infringement, merchantability, or use for a particular purpose. Informatica Corporation does not warrant that this software or documentation is error free. Theinformation provided in this software or documentation may include technical inaccuracies or typographical errors. The information in this software and documentation issubject to change at any time without notice.
NOTICES
This Informatica product (the “Software”) includes certain drivers (the “DataDirect Drivers”) from DataDirect Technologies, an operating company of Progress SoftwareCorporation (“DataDirect”) which are subject to the following terms and conditions:
1.THE DATADIRECT DRIVERS ARE PROVIDED “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOTLIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NON-INFRINGEMENT.
2. IN NO EVENT WILL DATADIRECT OR ITS THIRD PARTY SUPPLIERS BE LIABLE TO THE END-USER CUSTOMER FOR ANY DIRECT, INDIRECT,INCIDENTAL, SPECIAL, CONSEQUENTIAL OR OTHER DAMAGES ARISING OUT OF THE USE OF THE ODBC DRIVERS, WHETHER OR NOT INFORMED OFTHE POSSIBILITIES OF DAMAGES IN ADVANCE. THESE LIMITATIONS APPLY TO ALL CAUSES OF ACTION, INCLUDING, WITHOUT LIMITATION, BREACHOF CONTRACT, BREACH OF WARRANTY, NEGLIGENCE, STRICT LIABILITY, MISREPRESENTATION AND OTHER TORTS.
Part Number: IDQ-PER-901-0001

Table of Contents
Preface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iiiInformatica Resources. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
Informatica Customer Portal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
Informatica Documentation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
Informatica Web Site. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
Informatica How-To Library. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
Informatica Knowledge Base. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iv
Informatica Multimedia Knowledge Base. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iv
Informatica Global Customer Support. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iv
Chapter 1: System Performance Guidelines for the Profiling Service. . . . . . . . . . . . . . . . 1Overview. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
Profiling Service Architecture. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
Hardware Considerations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
Data Source Paradigms. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Differences Between Relational Database and Flat File Profiling. . . . . . . . . . . . . . . . . . . . . . . . 3
Flat File Paradigm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Relational Database Paradigm. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Paradigm Conclusions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
Memory Requirements for the Data Integration Service. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
Flat File and Mainframe Guidelines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Column Profile Mapping Requirements. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Profile Cache Mapping Requirements. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
Aggregate Profile Mapping Guidelines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
Relational Database Considerations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
Rule and Column Profiling. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
Bandwidth . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
Relational Database Mapping Guidelines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Profiling Service Resource Guidelines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Profile Warehouse Guidelines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Statistical and Bookkeeping Data Guidelines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Value Frequency Calculation Guidelines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Cached Data Guidelines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Other Resource Needs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Data Quality Table Guidelines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Reference Database Tables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Exception Management Tables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
Table of Contents i

Chapter 2: System Performance Guidelines for Mapping Operations. . . . . . . . . . . . . . . 12Overview. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
Basic On-Disk Installation Size. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
General Runtime Memory Size. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Address Validation Reference Data. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Mapping Memory and Disk Size Guidelines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Standard Transformations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
Reference Data-Based Transformations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
Dynamic Transformations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
Appendix A: Disk and Memory Guidelines for United States Customers. . . . . . . . . . . . 17User 1: Matching Mapping. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
User 2: Address Validation Mapping. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
User 3: Standardization Mapping. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
User 4: Association Mapping. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
Additional Memory and Disk Usage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
Appendix B: Address Validation Reference Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19Address Validation Reference Data with On-Disk Size. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
Appendix C: Identity Population Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22Identity Population Data with On-Disk Size. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
ii Table of Contents

PrefaceThe System Performance Guide is written for system administrators and others who must plan the installation ofInformatica Data Quality and Informatica Data Explorer Advanced Edition.
This guide assumes that you understand flat file and database concepts and data quality and profiling concepts.
Informatica Resources
Informatica Customer PortalAs an Informatica customer, you can access the Informatica Customer Portal site at http://mysupport.informatica.com. The site contains product information, user group information, newsletters,access to the Informatica customer support case management system (ATLAS), the Informatica How-To Library,the Informatica Knowledge Base, the Informatica Multimedia Knowledge Base, Informatica ProductDocumentation, and access to the Informatica user community.
Informatica DocumentationThe Informatica Documentation team takes every effort to create accurate, usable documentation. If you havequestions, comments, or ideas about this documentation, contact the Informatica Documentation team throughemail at [email protected]. We will use your feedback to improve our documentation. Let usknow if we can contact you regarding your comments.
The Documentation team updates documentation as needed. To get the latest documentation for your product,navigate to Product Documentation from http://mysupport.informatica.com.
Informatica Web SiteYou can access the Informatica corporate web site at http://www.informatica.com. The site contains informationabout Informatica, its background, upcoming events, and sales offices. You will also find product and partnerinformation. The services area of the site includes important information about technical support, training andeducation, and implementation services.
Informatica How-To LibraryAs an Informatica customer, you can access the Informatica How-To Library at http://mysupport.informatica.com.The How-To Library is a collection of resources to help you learn more about Informatica products and features. Itincludes articles and interactive demonstrations that provide solutions to common problems, compare features andbehaviors, and guide you through performing specific real-world tasks.
iii

Informatica Knowledge BaseAs an Informatica customer, you can access the Informatica Knowledge Base at http://mysupport.informatica.com.Use the Knowledge Base to search for documented solutions to known technical issues about Informaticaproducts. You can also find answers to frequently asked questions, technical white papers, and technical tips. Ifyou have questions, comments, or ideas about the Knowledge Base, contact the Informatica Knowledge Baseteam through email at [email protected].
Informatica Multimedia Knowledge BaseAs an Informatica customer, you can access the Informatica Multimedia Knowledge Base at http://mysupport.informatica.com. The Multimedia Knowledge Base is a collection of instructional multimedia filesthat help you learn about common concepts and guide you through performing specific tasks. If you havequestions, comments, or ideas about the Multimedia Knowledge Base, contact the Informatica Knowledge Baseteam through email at [email protected].
Informatica Global Customer SupportYou can contact a Customer Support Center by telephone or through the Online Support. Online Support requiresa user name and password. You can request a user name and password at http://mysupport.informatica.com.
Use the following telephone numbers to contact Informatica Global Customer Support:
North America / South America Europe / Middle East / Africa Asia / Australia
Toll FreeBrazil: 0800 891 0202Mexico: 001 888 209 8853North America: +1 877 463 2435 Standard RateNorth America: +1 650 653 6332
Toll FreeFrance: 00800 4632 4357Germany: 00800 4632 4357Israel: 00800 4632 4357Italy: 800 915 985Netherlands: 00800 4632 4357Portugal: 800 208 360Spain: 900 813 166Switzerland: 00800 4632 4357 or 0800 463200United Kingdom: 00800 4632 4357 or 0800023 4632 Standard RateFrance: 0805 804632Germany: 01805 702702Netherlands: 030 6022 797
Toll FreeAustralia: 1 800 151 830New Zealand: 1 800 151 830Singapore: 001 800 4632 4357 Standard RateIndia: +91 80 4112 5738
iv Preface

C H A P T E R 1
System Performance Guidelines forthe Profiling Service
This chapter includes the following topics:
¨ Overview, 1
¨ Profiling Service Architecture, 2
¨ Hardware Considerations, 2
¨ Data Source Paradigms, 3
¨ Memory Requirements for the Data Integration Service, 4
¨ Flat File and Mainframe Guidelines, 5
¨ Relational Database Considerations, 6
¨ Profiling Service Resource Guidelines, 7
¨ Profile Warehouse Guidelines, 8
¨ Data Quality Table Guidelines, 9
OverviewThis chapter provides guidelines that you can use to determine system resources for the Profiling Service.
It contains the following information:
¨ Profiling Service requirements related to the Data Integration Service, including memory, disk space, CPUusage, and network bandwidth
¨ Profiling Service requirements related to other Informatica services
¨ Machine resources for the Profiling Service
¨ Database resources for the Profiling Service
The Profiling Service is embedded in the Data Integration Service. This document assumes that the ProfilingService is the only plug-in running in the Data Integration Service.
1

Profiling Service ArchitectureThe Profiling Service interacts with the following components:
Profile Warehouse
The database that contains the profiling results. It can also contain cached source data.
Relational Database Sources
Databases that contain data organized for efficient data processing. Modern relational databases areoptimized to process the data that is stored in them, and the Profiling Service takes advantage of thisoptimization.
Flat File Sources
Files that contain data in delimited or fixed-width form.
Nonrelational Sources
Nonrelational sources of data organized for efficient data processing. The main type of nonrelational databasesource is the mainframe, for example, a DB2 and VSAM database system. The Profiling Service requiresadditional resources to read a nonrelational database source.
Hardware ConsiderationsThe hardware specifications of the Profiling Service machine influence Profiling Service performance.
The Profiling Service runs inside the Data Integration Service, and it inherits the runtime environment of the DataIntegration Service. The Profiling Service also inherits the basic functionality of a multithreaded, high-performancesystem.
The factors that affect profile performance include:
Central Processing Unit (CPU)
The Profiling Service takes advantage of the multithreaded environment of the Data Integration Service.Therefore, the CPU speed is less important than the number of cores in the CPU. To calculate the number ofcycles that the Profiling Service uses each second, add the clock speeds of the cores.
Memory
Profiling operations run faster with more memory. In flat file profiling, the Profiling Service uses memory tosort the value frequency data and to buffer data. The Profiling Service performs multiple read operations tothe same part of a file by reading from the memory buffer, not from the flat file on disk. This also applies torule profiling for flat file and relational sources.
Disk
The Profiling Service uses disk space for temporary storage when there is not enough memory to store theintermediate profile results. The Profiling Service uses multiple temporary directories in a single profiling job,so storage and input/output operations can be spread among multiple disks in parallel.
Profiling speed increases if the temporary directories are located on separate physical disks. Disktechnologies such as rotational speed and on-disk buffering also benefit profiling.
Input/Output
The input/output speeds, for both memory and disk, affect Profiling Service performance. Higher speeds allowthe Profiling Service to access large amounts of data quickly.
2 Chapter 1: System Performance Guidelines for the Profiling Service

Data Source ParadigmsThe types of data source you profile influences the requirements of the Profiling Service machine.
Differences Between Relational Database and Flat File ProfilingWhen you profile the columns in a relational database, the Profiling Service allocates one mapping per column.When you profile the columns in a flat file, the Profiling Service allocates one mapping to five columns.
In addition, the Profiling Service runs five mappings by default on flat file data.
Each mapping divides the work between the relational database and Data Transformation Manager as follows:
¨ The relational database performs value frequency computation.
¨ The Profiling Service performs profile analysis, including pattern analysis. This work is generally light comparedto the value frequency computation.
Flat File ParadigmThe flat file paradigm assumes that the data source cannot execute any logic. It applies to the following types ofdata source:
¨ Flat files
¨ VSAM and other mainframe databases
¨ SAP and other nonrelational databases
Flat Files
The Profiling Service creates temporary mappings that the Data Transformation Manager runs to perform theprofiling functions. These mappings are not exposed to the user.
Mainframe Databases
The flat file paradigm includes mainframe databases because of the financial cost of providing resources formainframe machines.
You can transfer the processing to the Data Transformation Manager to avoid this cost outlay. However, theone-time movement of data from the mainframe to the Data Transformation Manager may incur greaterprocessing overhead than repeated read operations on the mainframe data.
Nonrelational Databases
These databases are included in the flat file paradigm because of the proprietary way that they access data.
Relational Database ParadigmRelational databases can run some types of profiling task on the database machine.
Transferring a profiling task to the database machine delivers higher performance than retrieving the data andprofiling it on the Profiling Service machine. The Profiling Service transfers as much processing as possible.
Data Source Paradigms 3

Paradigm ConclusionsThe flat file paradigm suggests that you allocate hardware resources to the machine that runs the ProfilingService. The relational database paradigm suggests that you allocate hardware resources to the database hostmachine.
In most enterprises, there is a mixture of flat file and relational database data sources. In such a case, divide theresources between the machines.
Note: In addition, the relational database for the Profile Warehouse runs on a separate machine. This machinestores the profiling results and may store cached data. The resources needed for the Profile Warehouse dependon the quantity of data that it may need to store.
Memory Requirements for the Data Integration ServiceThe Data Integration Service runs the Profiling Service, and it has fixed and variable memory requirements.
Fixed Requirements
The amount of memory required to run the Java Virtual Machine that the Data Integration Service uses. Thisis approximately 500 MB.
Variable Requirements
The amount of memory required to run each Data Transformation Manager thread. For relational systems,this is less than 1 CPU per Data Transformation Manager thread. For flat files, this is approximately 2.3 CPUsper Data Transformation Manager thread.
One Data Transformation Manager thread is required to run each mapping that computes part of a profile job.This overhead is approximately 100 MB per Data Transformation Manager thread.
A mapping requires additional memory if it reads address or identity reference data. For example, a profilethat reads the output of an address validation rule may incur an addition of 1 GB in memory to read and cachethe address validation reference data.
Note: When you calculate the number of CPUs you need for Data Transformation Manager operations, roundup the total number to the nearest integer.
Disk space is a one-time cost when the Data Integration Service is installed. CPU overhead is minimal for the DataIntegration Service at rest.
To calculate the amount of memory required by the Data Integration Service, add the following:
¨ 500 MB. This is the fixed cost.
¨ 100 MB • number of concurrent mappings. This is the variable cost.
¨ Additional requirements for address validation reference data, identity population data, or other reference data.
¨ Operating system recommendations.
4 Chapter 1: System Performance Guidelines for the Profiling Service

Flat File and Mainframe GuidelinesWhen you run a profile job on a flat file or mainframe, the Profiling Service divides the job into a number ofmappings that infer the metadata for the columns and virtual columns. Each mapping can run serially, or two ormore mappings can run in parallel.
In addition, a second type of mapping may be generated to cache the source data. This mapping always runs inparallel with the column profiling mappings, because it takes longer than a column profile mapping.
Column Profile Mapping RequirementsThe default column profile mapping profiles five columns at a time. The following requirements are based on fivecolumns.
CPU
Column profiling consumes approximately 2.3 CPUs per mapping. When you calculate the number of CPUsyou need, round up the total to the nearest integer.
Memory for Mappings
The Profiling Service can use two strategies for profile mappings. First, it applies a strategy that requiresapproximately 2 MB of memory per column. If this does not work, it falls back to sorting with a buffer of 64 MB.
The minimum resource required is 10 MB, representing 2 MB • 5. The maximum resource required is 72 MB,representing a 64 MB buffer for one high-cardinality column and 8 MB for the remaining four low-cardinalitycolumns.
Memory for the Flat File Buffer Cache
The Profiling Service caches the flat file as it is read. Profiling speed increases if the flat file can fit intomemory. Otherwise, memory has no effect.
The exception is when two or more mappings read a file concurrently. In this case, add 100 MB of memory.This enables the mappings to share the read operations and increase performance.
Disk
A profile mapping may need disk space to perform profiling computations. The following formula calculatesthe worst-case scenario for a single mapping:
2 • number of columns per mapping • maximum number of rows • ((2 bytes per character • maximum stringsize in characters) + frequency bytes)
where
¨ 2 = two passes (some analyses need two passes)
¨ Number of columns per mapping = 5 (default)
¨ Maximum number of rows = the maximum number of rows in any flat file
¨ 2 bytes per character = the typical number of bytes for a single Unicode character
¨ Maximum string size in characters = the maximum number of characters in any column in any flat file, or255, whichever is less
¨ Frequency bytes = 4 bytes to store the frequency calculation during the analysis
Perform the above calculation and allocate the disk space to one or more physical disks. Use one disk foreach mapping, and use a maximum of four disks.
Flat File and Mainframe Guidelines 5

Operating System
Use a 64-bit operating system if possible, as a 64-bit system can handle memory sizes greater than 4 GB. A32-bit system works if the profiling parameter fits inside the memory limitations of the system.
Note: This example covers the optimal flat file profiling case, which uses five columns per mapping. In somecases, the Profiling Service must profile more than five columns in one mapping, for example, when profilingmainframe data where the financial cost of accessing the data can be high.
Profile Cache Mapping RequirementsA profile cache mapping caches data to the Profiling Warehouse. It has different resource requirements to acolumn profiling mapping.
The cache mapping requirements are as follows:
CPU
The cache mapping requires approximately 1.5 CPUs.
Memory
The cache mapping requires no additional memory beyond the Data Transformation Manager thread memory.
Disk
The cache mapping requires no disk space.
Aggregate Profile Mapping GuidelinesTo compute the total resources required by profiling, add the profile mapping requirements to the cache mappingrequirements.
Use the following formula:
(number of concurrent profile mappings • resources per mapping) + cache mapping resources
Relational Database ConsiderationsThe Profiling Service transfers as much work as it can to the database machine. The division of work between theProfiling Service and the database presents challenges to resource estimation for each machine.
To understand the resource requirements, you must first distinguish rule profiling from column profiling.
Rule and Column ProfilingRules are pushed down to the database or handled internally by the Profiling Service.
If a rule is pushed down to the database, it is treated like a column when it is profiled.
Rules that run inside the Profiling Service are treated like columns profiled from a flat file. The rules are groupedinto mappings of five output columns at a time and then profiled. The flat file calculations apply in this case.
BandwidthThe network between the relational database and the Profiling Service must be able to handle the data transfers.
For large databases, the bandwidth required can be considerable.
6 Chapter 1: System Performance Guidelines for the Profiling Service

Relational Database Mapping GuidelinesThe following guidelines are based on a single mapping that computes the value frequencies for a single column.Multiply these guidelines by the product of the number of profiling jobs and the number of concurrent databaseconnections configured in the Profiling Service.
CPU
Depending on the relational database, at least one CPU processes each query. If the relational databaseprovides a mechanism to increase this, such as the parallel hint in Oracle, the number of threads increasesaccordingly.
Memory
The relational database requires memory in the form of a buffer cache. The greater the buffer cache, thefaster the relational database runs the query. Use at least 512 MB of buffer cache.
Disk
Relational systems use temporary table space. The formula for the maximum amount of temporary tablespace required is:
2 • maximum number of rows • (maximum column size + frequency bytes)
where
¨ 2 = two passes (some analyses need two passes).
¨ Maximum number of rows = the maximum number of rows in any table.
¨ Maximum column size = the number of bytes in any column in a table that is not one of the very large datatypes, for example CLOB, that cannot be profiled. The column size must take into account the characterencoding, such as Unicode or ASCII.
¨ Frequency bytes = 4 or 8 bytes to store the frequency during the analysis. This is the default size that thedatabase uses for COUNT(*).
In many situations less disk space is needed. Perform the disk computation and allocate the temporary tablespace to one or more physical disks. Use one disk for each mapping, and use a maximum of four disks.
Operating System
Use a 64-bit operating system if possible, as a 64-bit system can handle memory sizes greater than 4 GB. A32-bit system works if the profiling parameter fits inside the memory limitations of the system.
Profiling Service Resource GuidelinesThe Profiling Service uses fewer resources to profile a relational data source than a flat file data source.
CPU
The Profiling Service uses less than 1 CPU per column.
Memory
No additional memory is required beyond the minimum needed to run the mapping.
Disk
No disk space is required.
Profiling Service Resource Guidelines 7

Operating System
Use a 64-bit operating system if possible, as a 64-bit system can handle memory sizes greater than 4 GB. A32-bit system works if the profiling parameter fits inside memory limitations of the system.
Profile Warehouse GuidelinesThe Profile Warehouse stores profiling results. The main resource it requires is disk space. More than oneProfiling Service may point to the same Profile Warehouse.
Three types of results are stored in the Profile Warehouse:
¨ Statistical and bookkeeping data
¨ Value frequencies
¨ Staged data
Statistical and Bookkeeping Data GuidelinesEach column contain a set of statistics, such as the minimum and maximum values. It also contains a set of tablesthat store bookkeeping data such as the profile ID. These take up very little space and you can exclude them fromdisk space calculations.
Consider the disk requirement to be effectively zero.
Value Frequency Calculation GuidelinesValue frequencies are a key element in profile results. They list the unique values in a column along with a countof the occurrences of each value.
Low-cardinality columns have very few values, but large-cardinality columns can have millions of values. TheProfiling Service limits the number of unique values it identifies to 16,000 by default. You can change this value.
Use this formula to calculate disk size requirements:
number of columns • number of values • (average value size + 64)
where
¨ Number of columns = the sum of columns and virtual columns profiled.
¨ Number of values = the number of unique values. If you do not use the default of 16,000, use the averagenumber of values in each column.
¨ Average value size includes Unicode encoding of characters.
¨ 64 bytes for each value = 8 bytes for the frequency and 56 bytes for the key.
Cached Data GuidelinesCached data is also known as staged data. It is a copy of the source data that is used for drilldown operations.Depending on the data source, this can use a very large amount of disk space.
Use the following formula to calculate the disk size requirements for cached data:
number of rows • number of columns • (average value size + 24)
Note: 24 is the cache key size.
8 Chapter 1: System Performance Guidelines for the Profiling Service

Sum the results of this calculation for all cached tables.
For example, an 80 column table that contains 100 million rows with an equal mixture of high- and low-cardinalitycolumns may require the following disk space:
Value frequency data 50 MB
Cached data 327,826 MB
Total 327,876 MB
Source data is staged when caching is selected. If you do not cache data for drilldown, the disk space required issignificantly reduced. All profiles store the value frequencies.
Other Resource NeedsThe Profile Warehouse has the following memory and CPU requirements:
Memory
The queries run by the Profiling Service do not use significant amounts of memory. Use the manufacturer'srecommendations based on the table sizes.
CPU
The recommended options are:
¨ 1 CPU for each concurrent profile job. This applies to each relational database or flat file profile job, not toeach profile mapping.
¨ 2 CPUs for each concurrent profile job if the data is cached.
Data Quality Table GuidelinesInformatica Data Quality uses the following types of proprietary database table:
¨ Reference data tables
¨ Exception management tables
Reference Database TablesData quality uses reference tables to enable operations such as standardization, labeling, and parsing. Eachreference data set is carried in a table and has a size in the database equivalent to its on disk size.
Use the following formulas to calculate reference data table size:
Assumption: Columns Have the Same Average Data Size
number of data rows • number of columns • number of characters per column
Assumption: Columns have Different Average Data Sizes
number of data rows • (characters in column 1 + characters in column 2 + … characters in column n)
Data Quality Table Guidelines 9

Exception Management TablesYou can examine database tables for bad-quality or duplicate records in the Analyst tool. The table must containcolumns that are recognized by the Analyst tool.
Some columns contain data that the Analyst tool can use as a filter. Other columns contain values that indicate therecords you want to write back to the source database. The columns must be in place before you import thedatabase table to the staging database.
Some column names are case-sensitive, and you must enter them in uppercase. The names of columns that holdsource data are not case-sensitive.
You must also verify that your source data does not contain columns with reserved names.
Bad Record TableThe Bad Record table contains all potential bad-quality records that a mapping writes to the exception channel.Each row contains the original data size and a set of control columns.
The control column structures are as follows:
¨ ID (numeric)
¨ RECORD_STATUS (varchar, 20)
¨ UPDATED_STATUS (varchar, 20)
¨ ROW_IDENTIFIER (numeric)
¨ COL* (user-defined text)
Issue TableThis table allows multiple issues to be created for a single column. The table contains a row of data for each issuein a column cell.
For the following row in a Bad Record table, the Issue table contains eight rows:
Table 1. Bad Record Table, Row 1
Column 1 Column 2 Column 3
Two issues Four issues One issue
The Issue table format is as follows:
¨ ID (numeric)
¨ ISSUE* (user-defined text)
Duplicate Record TableThe Duplicate Record table contains all potential duplicate records that a mapping writes to the exception channel.Each row contains the original data size and a set of control columns.
The control columns are as follows:
¨ ID (numeric)
¨ CLUSTER_ID (decimal 20,2)
¨ MATCH_SCORE (decimal 20,2)
10 Chapter 1: System Performance Guidelines for the Profiling Service

¨ IS_MASTER (char 1)
¨ UPDATED_STATUS (varchar, 20)
Audit TableAn Audit table is an Informatica system table that is associated with a Bad Record table. It contains a summarytable and a detail table.
When you edit the Bad Record table, the Audit table records the change with a line of detail for each row-levelchange and an issue line for each column change. For example, if you make three changes to a record in the BadRecord table, the Audit table updates the detail table with three rows of data that contain the before and afterstates of the data.
The summary table and detail table are defined as varchars. The size of each detail row depends on the contentsof the old and new column values and the column name. The size of each summary row depends on the usercomments and user name size.
Data Quality Table Guidelines 11

C H A P T E R 2
System Performance Guidelines forMapping Operations
This chapter includes the following topics:
¨ Overview, 12
¨ Basic On-Disk Installation Size, 12
¨ General Runtime Memory Size, 13
¨ Mapping Memory and Disk Size Guidelines, 13
OverviewThis chapter provides system resource recommendations for Informatica Data Quality 9.0.1 mapping operations.
The chapter addresses three areas:
¨ The size of installed elements on the file system
¨ The runtime footprint of general services for all users
¨ The memory and disk overhead when a user runs mappings
The effect of mapping execution on disk and memory usage is the most critical of these factors. It is also the mostdifficult to estimate. When you determine your resource needs, consider the number of concurrent mappingssubmitted to the server, the types of transformation used in each mapping, and the size of the source data sets.
Basic On-Disk Installation SizeA standard installation of server components requires approximately 3.2 GB of disk space. Reference datarequires additional disk space.
The following table describes a standard installation including reference data.
Server platform install size 3.2 GB
Identity reference data 600 MB
12

Address reference data 4 GB
Reference table data 3 GB
Total 11 GB
The installation of additional reference data, or updates to reference data that increase data file sizes, will affectthese figures.
General Runtime Memory SizeThe following table describes a standard installation that is not running disk- or memory-intensive mappings ormappings that load reference data.
Service Name Virtual Set Working Set
Administrator Tool 773 KB 133 KB
Model Repository Service 1288 KB 407 KB
Mapping Service 978 KB 254 KB
Analyst Tool 702 KB 79 KB
The Virtual Set is the total virtual memory used , and the Working Set is the physically resident memory used.
Address Validation Reference DataUse the address reference data file sizes as a guide to memory usage.
The product configuration dictates how the address reference data files are loaded. The data is loaded in thesame way for all users.
The average size in memory of each loaded element is approximately the same as the disk footprint. For example,if a user runs a mapping that uses a 533 MB address reference data file in batch or interactive mode, the processmemory size will grow by approximately 533 MB.
This memory is a one-off cost for the server and for mappings that run in the lifetime of the server. The loadedaddress reference data is not unloaded when there are no current users.
Mapping Memory and Disk Size GuidelinesFrom the point of view of resource usage and performance, data quality transformations can be divided into thefollowing categories:
¨ Standard transformations
¨ Reference data-based transformations
General Runtime Memory Size 13

¨ Dynamic transformations
The standard components do not incur additional costs in memory or disk usage beyond the standard runningsize. Reference data-based transformations can hold reference table lookup structures in memory. Dynamictransformations can use third-party engines, sort space, or b-tree storage.
The dynamic transformations’ use of memory and disk can vary considerably, depending on the data that theyprocess.
Standard TransformationsThe standard transformations are Comparison, Decision, and Merge.
The memory or disk usage of these transformations does not vary with the size of the data processed. Thesecomponents process data rows in small batches and send them to the next component in the mappingimmediately.
Reference Data-Based TransformationsThe following transformations use Informatica reference table data:
¨ Case Converter
¨ Labeller
¨ Parser
¨ Standardizer
These transformations process data immediately, but they have initialization costs that increase memory useaccording to their configuration. While the reference table data is managed in the database, at runtime it is held inmemory for performance reasons. To optimize data throughput, this in-memory storage is designed for speedrather than space efficiency. Each transformation has its own copy of the in-memory reference data.
Multiply the number of bytes in each column of the reference table by the number of lines in the reference table.Then multiply the total by 1.3 to estimate the in-memory footprint.
For example, consider a reference table with the following dimensions:
Rows 10,000
Columns 6
Average byte count 25
The product of 10,000 • 6 • 25 • 1.3 equals approximately 2 MB of runtime memory usage. This runtime memorycost applies to the lifetime of the mapping. All in-memory reference tables are freed when the mapping is finished.
14 Chapter 2: System Performance Guidelines for Mapping Operations

Dynamic TransformationsThe following transformations have dynamic memory and disk usage requirements. These components store largenumbers of rows internally for block processing and have memory and disk requirements that increase with thevolume of input rows and the number of columns per row.
Address Validator TransformationThe following factors affect performance for this transformation. Refer also to the section on General RuntimeMemory Size, as the Address Validator transformation affects all users when an address validation mapping runs.
Preload and Cache Settings
If the memory is available, fully preload all the address reference data files you need. If you use fullpreloading, set the CacheSize value to NONE. Otherwise, accept the default CacheSize value of LARGE.
Concurrent Address Validator Mappings in PowerCenter
Data Quality 9.0.1 creates a single process for all Address Validator mappings it runs, while PowerCentercreates a process for each mapping. Address validation processes do not share memory in PowerCenter. Ifyou specify full preloading in PowerCenter, each address validation mapping needs approximately 6 GB ofmemory at runtime. If this is an issue, use partial preloading for address reference data in PowerCenter.
Memory Usage
Use the amount of data that is used by the Pre-Load setting. The AddressDoctor engine only consumes therequired amount of memory.
Maximum AddressObject Setting
The required AddressObject setting depends on the number of concurrent address validation mappings thatrun. This is a consideration in Data Quality 9.0.1, as all mappings are run in a single process, and it can be aconsideration in PowerCenter if there is more than one Address Validator transformation in a mapping.
Set the AddressObject count to the maximum number of Address Validator transformations that can runconcurrently in a process. If you run two mappings concurrently in Data Quality 9.0.1, with two AddressValidator transformations in each mapping, set the AddressObject count to 4. In the same situation inPowerCenter, set the AddressObject count to 2.
The address validation mapping may fail if the required AddressObjects are not available.
Maximum ThreadCount Setting
The optimal setting for Maximum ThreadCount is the number of processors or cores available for the addressvalidation process. If Maximum ThreadCount is set lower, the mappings will run more slowly.
Association TransformationThis transformation makes extensive use of B-tree file based storage.
Each column that the transformation reads has its own B-tree, and a general B-tree is used to store all the inputdata rows. The Informatica B-tree is space-efficient but not compressed.
Use the following formulas to determine the needs of this transformation:
Association Transformation Column Size
total volume of data for each column • 20 bytes for each input row
On-disk Runtime Cost of the General Storage Cache:
size of input data set • 10 bytes for each row
Mapping Memory and Disk Size Guidelines 15

Maximum Internal Memory Map for Association IDs and Data Rows
number of rows • 20 bytes
Consolidation and Key Generator TransformationsThese transformations use standard Informatica sort transformations. By default they are configured to give thetransformation as much memory as possible without affecting system performance.
You can set a limit on the amount of main memory the sort transformation uses to sort data. This increases on-disk temporary memory use, as the sort transformation must store all data rows.
Match TransformationThe Match transformation can make use of two types of B-tree.
When you configure the transformation with pass through ports and for identity matching, both types of B-tree areused. Assume that B-tree storage will not significantly exceed the space used by the data, if the data residesoutside the B-tree on the file system.
16 Chapter 2: System Performance Guidelines for Mapping Operations

A P P E N D I X A
Disk and Memory Guidelines forUnited States Customers
The variable elements of disk and memory usage increase when multiple users concurrently run mappings withdisk- and memory-intensive transformations.
¨ Base server disk requirement: 12 GB
¨ Base memory requirement: 2 GB
This example assumes that a mapping without disk- or memory-sensitive transformations has no significant impacton calculations. This will not be true for very complex mappings.
User 1: Matching MappingThis user runs a dual-source Identity mapping. Source 1 contains 1 million rows and Source 2 contains 100,000rows.
Each data source has the following structure:
¨ 6 columns with 25 bytes per column
¨ 20 pass-through columns with 25 bytes per column
This mapping has two Sorter transformations from the key generation phase, one B-tree from matching analysis, 1B-tree from identity analysis, and internal memory usage for identity and cluster analysis.
Disk Usage:
¨ Identity B-tree = 1,100,000 • 6 • 25 = 165 MB
¨ Pass-through port B-tree = 1,100,000 • 20 • 25 = 550 MB
Memory Usage:
¨ Internal storage for large number of transformations used for matching = 10 MB
User 2: Address Validation MappingThis user runs a single-source mapping on a data source that contains 1 million rows.
The mapping has minimal transformations and loads all United States address reference data.
17

The following table lists the reference data file sizes:
United States Batch / Interactive 533 MB
United States GeoCoding 422 MB
United States FastCompletion 380 MB
Total disk usage added by this mapping = 0
Memory usage = 533 MB + 422 MB + 380 MB = 1.3 GB
User 3: Standardization MappingThis user runs a standardization mapping on a data source that contains 10 million rows.
The mapping has minimal transformations and loads ten reference tables.
The memory considerations are as follows:
¨ Each reference table has 10,000 rows with five columns and 25 bytes average data per column
¨ Total disk usage added by this mapping = 0
¨ Memory usage per reference table = 10,000 • 5 • 25 • 1.3
¨ Total memory usage = 16 MB
User 4: Association MappingThis user runs a single-source mapping on a data source that contains 10 million rows and uses an Associationtransformation that reads eight groups.
This mapping has no matching transformations. It sources data directly from a table. Each Association key columnhas a 10 byte key, and there are 10 additional columns of row data, each 50 bytes wide.
The memory considerations are as follows:
¨ Each key column B-tree requires 300 MB of memory: 10M • (10 + 20)
¨ General storage requirement = 10M * ((8 • 10) + (10 • 50)) = 5.8 GB
¨ Total disk usage added by this mapping = 300 MB • 8 columns + 5.8 GB = 8.2 GB
¨ Total memory usage = 10M • 20 = 200 MB
Additional Memory and Disk UsageAll users run their mappings concurrently. This has the following impact:
¨ Disk usage = 165 MB + 550 MB + 8,200 MB = 8.7 GB
¨ Memory usage = 10 MB + 1,300 MB + 16 MB + 200 MB = 1.5 GB
18 Appendix A: Disk and Memory Guidelines for United States Customers

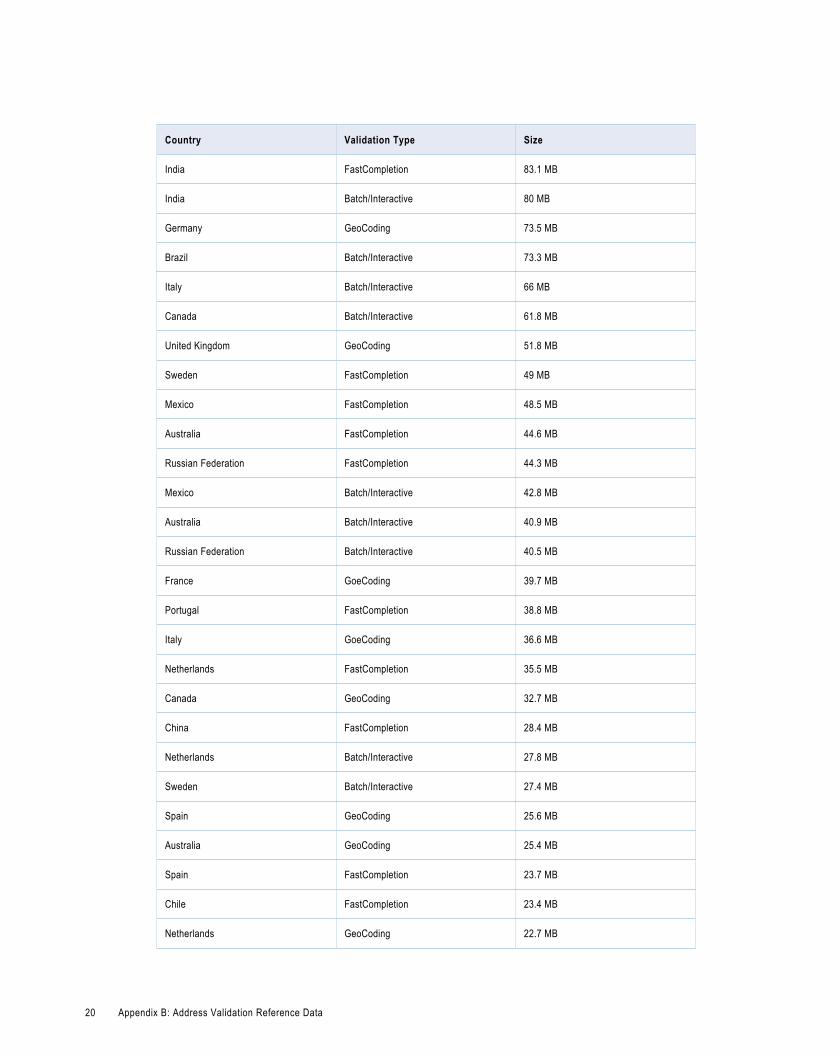
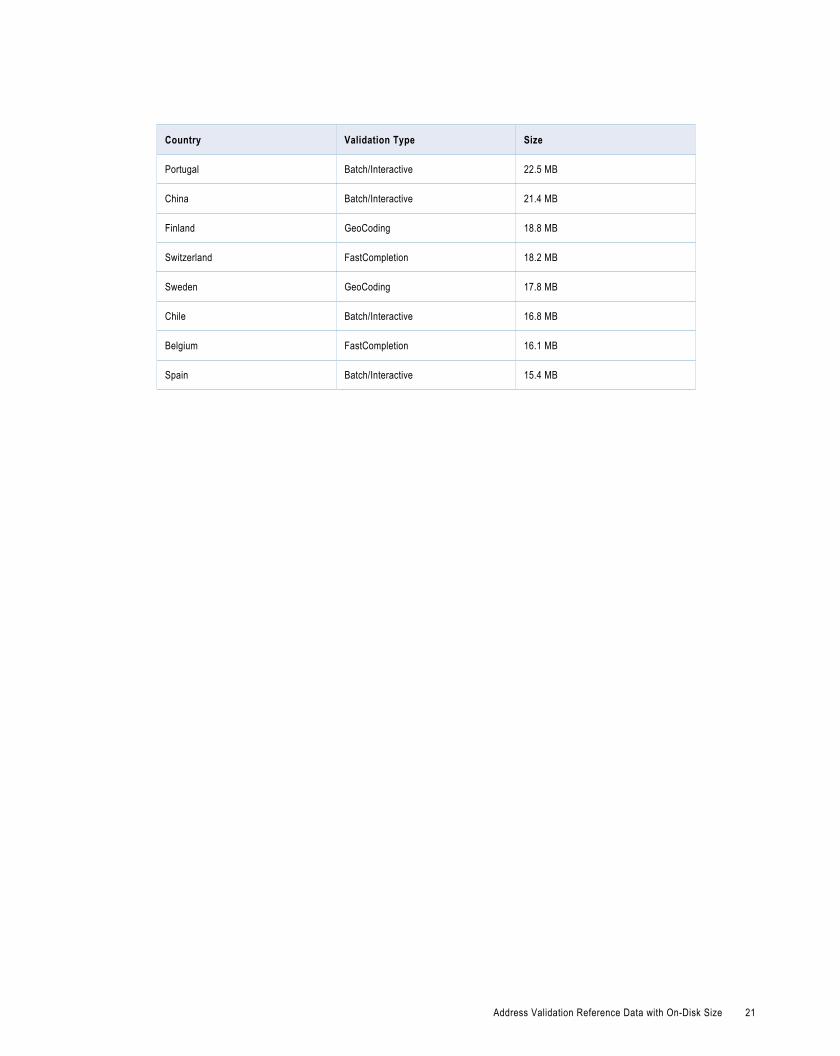
A P P E N D I X B
Address Validation Reference DataThe address validation reference data that you install can take up sizable disk space. This appendix lists thelargest address validation reference data files and their sizes.
Address Validation Reference Data with On-Disk SizeThe following table lists the largest address validation reference data files.
Country Validation Type Size
United States Batch/Interactive 533 MB
United Kingdom FastCompletion 501 MB
United States GeoCoding 422 MB
United States FastCompletion 380 MB
United Kingdom Batch/Interactive 306 MB
France FastCompletion 210 MB
France Batch/Interactive 153 MB
Argentina FastCompletion 120 MB
Brazil FastCompletion 104 MB
Germany FastCompletion 102 MB
Germany Batch/Interactive 99 MB
United Kingdom Supplementary 94.5 MB
Italy FastCompletion 92.9 MB
Argentina Batch/Interactive 90 MB
Canada FastCompletion 83.1 MB
19
Country Validation Type Size
India FastCompletion 83.1 MB
India Batch/Interactive 80 MB
Germany GeoCoding 73.5 MB
Brazil Batch/Interactive 73.3 MB
Italy Batch/Interactive 66 MB
Canada Batch/Interactive 61.8 MB
United Kingdom GeoCoding 51.8 MB
Sweden FastCompletion 49 MB
Mexico FastCompletion 48.5 MB
Australia FastCompletion 44.6 MB
Russian Federation FastCompletion 44.3 MB
Mexico Batch/Interactive 42.8 MB
Australia Batch/Interactive 40.9 MB
Russian Federation Batch/Interactive 40.5 MB
France GoeCoding 39.7 MB
Portugal FastCompletion 38.8 MB
Italy GoeCoding 36.6 MB
Netherlands FastCompletion 35.5 MB
Canada GeoCoding 32.7 MB
China FastCompletion 28.4 MB
Netherlands Batch/Interactive 27.8 MB
Sweden Batch/Interactive 27.4 MB
Spain GeoCoding 25.6 MB
Australia GeoCoding 25.4 MB
Spain FastCompletion 23.7 MB
Chile FastCompletion 23.4 MB
Netherlands GeoCoding 22.7 MB
20 Appendix B: Address Validation Reference Data
Country Validation Type Size
Portugal Batch/Interactive 22.5 MB
China Batch/Interactive 21.4 MB
Finland GeoCoding 18.8 MB
Switzerland FastCompletion 18.2 MB
Sweden GeoCoding 17.8 MB
Chile Batch/Interactive 16.8 MB
Belgium FastCompletion 16.1 MB
Spain Batch/Interactive 15.4 MB
Address Validation Reference Data with On-Disk Size 21

A P P E N D I X C
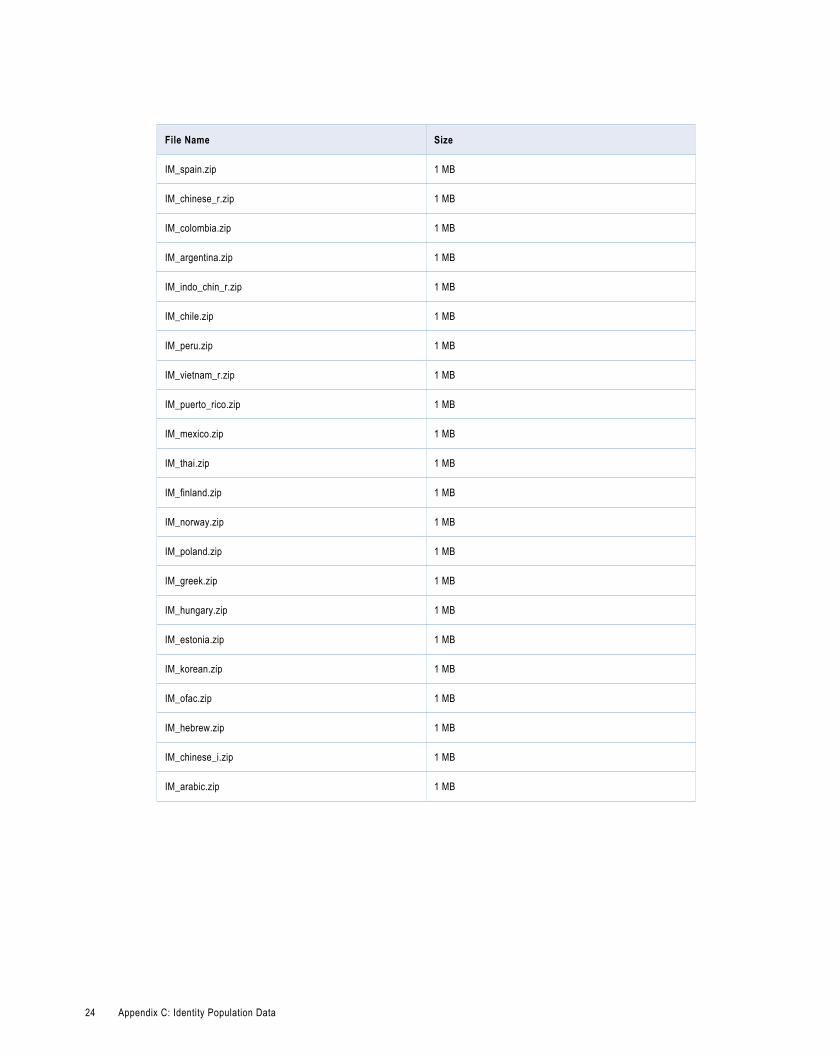
Identity Population DataThis appendix includes the following topic:
¨ Identity Population Data with On-Disk Size, 22
Identity Population Data with On-Disk SizeThe following table lists the largest address validation reference data files.
File Name Size
IM_japan_i.zip 82 MB
IM_japan.zip 82 MB
IM_japan_r.zip 15 MB
IM_gaelic.zip 9 MB
IM_canada.zip 9 MB
IM_international.zip 5 MB
IM_chinese_s.zip 5 MB
IM_south_africa.zip 4 MB
IM_uk.zip 4 MB
IM_ireland.zip 4 MB
IM_new_zealand.zip 4 MB
IM_australia.zip 4 MB
IM_usa.zip 4 MB
IM_arabic_m.zip 4 MB
IM_indonesia.zip 3 MB
22

File Name Size
IM_cyrillic.zip 3 MB
IM_arabic_r.zip 3 MB
IM_singapore.zip 2 MB
IM_india.zip 2 MB
IM_chinese_t.zip 2 MB
IM_aml.zip 2 MB
IM_greek_l.zip 2 MB
IM_switzerland.zip 2 MB
IM_france.zip 2 MB
IM_philippines.zip 2 MB
IM_luxembourg.zip 2 MB
IM_belgium.zip 2 MB
IM_germany.zip 2 MB
IM_brasil.zip 2 MB
IM_portugal.zip 2 MB
IM_korean_r.zip 2 MB
IM_italy.zip 1 MB
IM_turkey.zip 1 MB
IM_hk_r.zip 1 MB
IM_sweden.zip 1 MB
IM_czech.zip 1 MB
IM_netherlands.zip 1 MB
IM_taiwan_r.zip 1 MB
IM_denmark.zip 1 MB
IM_slovakia.zip 1 MB
IM_malaysia.zip 1 MB
IM_thai_r.zip 1 MB
Identity Population Data with On-Disk Size 23
File Name Size
IM_spain.zip 1 MB
IM_chinese_r.zip 1 MB
IM_colombia.zip 1 MB
IM_argentina.zip 1 MB
IM_indo_chin_r.zip 1 MB
IM_chile.zip 1 MB
IM_peru.zip 1 MB
IM_vietnam_r.zip 1 MB
IM_puerto_rico.zip 1 MB
IM_mexico.zip 1 MB
IM_thai.zip 1 MB
IM_finland.zip 1 MB
IM_norway.zip 1 MB
IM_poland.zip 1 MB
IM_greek.zip 1 MB
IM_hungary.zip 1 MB
IM_estonia.zip 1 MB
IM_korean.zip 1 MB
IM_ofac.zip 1 MB
IM_hebrew.zip 1 MB
IM_chinese_i.zip 1 MB
IM_arabic.zip 1 MB
24 Appendix C: Identity Population Data


















