
Information Visualization: Ten Years in Review Xia Lin Drexel University.
Upload
adriana-garneyCategory
view
215download
0
INFO624 - Week 2
Models of Information Retrieval
Dr. Xia LinDr. Xia LinAssociate ProfessorAssociate Professor
College of Information Science and TechnologyCollege of Information Science and Technology
Drexel UniversityDrexel University

Reviews of Last Week Challenges of Information RetrievalChallenges of Information Retrieval
Translate user’s information needs to Translate user’s information needs to queries.queries.
Match queries to stored information.Match queries to stored information. Evaluate if the query results match the Evaluate if the query results match the
user’s information needsuser’s information needs Differences between Differences between
Data, information, and knowledgeData, information, and knowledge Data retrieval and information retrievalData retrieval and information retrieval

Assignment 1
Some of my favorite Search Software PackagesSome of my favorite Search Software Packages IBM’ Content Management (high-cost)IBM’ Content Management (high-cost) AOL PLS Search Engine (free)AOL PLS Search Engine (free) GreenStone Digital Library Software (open-GreenStone Digital Library Software (open-
source)source) SWISH (open source)SWISH (open source) mnoGoSearch (free)mnoGoSearch (free) Apache Lucene (open source components) Apache Lucene (open source components)

Documents
Documents are logical units of textDocuments are logical units of text Units of records (text & other components)Units of records (text & other components) Units that can be stored, retrieved, and Units that can be stored, retrieved, and
displayed as an unique entitydisplayed as an unique entity Units of semantic entityUnits of semantic entity
units of text grouped together for a purposeunits of text grouped together for a purpose Units of unformatted textUnits of unformatted text
Text as written by authors of documents.Text as written by authors of documents.

Document Models
Documents need to be processed and represented Documents need to be processed and represented in a concise and identifiable formats/structures.in a concise and identifiable formats/structures. Documents are full of text.Documents are full of text. Not every words of the text are meaningful for Not every words of the text are meaningful for
searching/retrieval.searching/retrieval. Documents themselves do not have identifiable Documents themselves do not have identifiable
attributes such as authors and titles.attributes such as authors and titles.

Figure 1.2: Logical view of a document: from full text to a set of index terms.

Document Representation
Documents should be represented to help users Documents should be represented to help users identify and receive information from the system.identify and receive information from the system.
to identify authors and titlesto identify authors and titlesto identify subjectsto identify subjectsto provide summaries/abstractsto provide summaries/abstractsto classify subject categoriesto classify subject categories

Document Surrogates Each document should have one or more short and Each document should have one or more short and
descriptive labels/attributesdescriptive labels/attributes Level 1:Level 1:
Title: Title: Author:Author:Keywords:Keywords:
Level 2:Level 2:Level 1 +Abstract:Level 1 +Abstract:
Level 3:Level 3:Level 2 + full textLevel 2 + full text

A Formal IR Models An information retrieval model is a quadruple An information retrieval model is a quadruple
(D, Q, F, R(qi, dj)) where(D, Q, F, R(qi, dj)) where D is a set composed of logical views (or representations) D is a set composed of logical views (or representations)
for the documents in the collection.for the documents in the collection. Q is a set composed of logical views (or representations) Q is a set composed of logical views (or representations)
for the information needs. Such representations are called for the information needs. Such representations are called queries.queries.
F is a framework for modeling document representations, F is a framework for modeling document representations, queries, and their relationshipsqueries, and their relationships
R(qi, dj) is a ranking function which associated a real R(qi, dj) is a ranking function which associated a real number with a queryqi and a document representation dj. number with a queryqi and a document representation dj. Scuh ranking defines an ordering among the documents Scuh ranking defines an ordering among the documents with regard to the query qi. with regard to the query qi.

Computerized Indexing
Title indexing:Title indexing: Sort all the titles alphabeticallySort all the titles alphabetically
Not consider the beginning “a” or “the”Not consider the beginning “a” or “the”Convert all letters to uppercases.Convert all letters to uppercases.
Matching always starts from the beginning Matching always starts from the beginning of the title (not individual words).of the title (not individual words).
Most early IR systems (such as library Most early IR systems (such as library catalogs) used title indexingcatalogs) used title indexing

Word indexing Parsing every individual words from documentsParsing every individual words from documents
First decision: What is a word?First decision: What is a word?Are digits words?Are digits words?
• How about the letter and digit combination: How about the letter and digit combination: B6, B12 B6, B12
• Is F-16 one word or two words?Is F-16 one word or two words?HyphensHyphens
• Online, on-line, on line ?Online, on-line, on line ?• F-16 F-16
Singular or plural ?Singular or plural ? List all the words alphabetically with points back to List all the words alphabetically with points back to
documents – inverted indexing.documents – inverted indexing.

Inverted Indexing
Inverted indexing consists of an ordered list Inverted indexing consists of an ordered list of indexing terms, each indexing term is of indexing terms, each indexing term is associated with some document associated with some document identification numbers. identification numbers.
Retrieval is done by first searching in the Retrieval is done by first searching in the ordered list to find the indexing term, then ordered list to find the indexing term, then using the document identification numbers using the document identification numbers to locate documentsto locate documents

Example: Create an inverted indexing for the following:
Document Number Document Number TermsTerms
001001 T3, T4, T6, T12, T15T3, T4, T6, T12, T15
002002 T1, T3, T4, T7, T9, T13T1, T3, T4, T7, T9, T13
003003 T5, T12, T15,T5, T12, T15,
004004 T11, T12, T15, T15T11, T12, T15, T15
005005 T2, T3, T5, T7, T8, T12T2, T3, T5, T7, T8, T12
006006 T1, T4, T5T1, T4, T5
007007 T3, T5, T6, T7T3, T5, T6, T7
008008 T1, T2, T7, T9, T12T1, T2, T7, T9, T12

Boolean Logic Logical operators defined on setsLogical operators defined on sets
True and false: True and false: A set is a collection of items with certain common A set is a collection of items with certain common
characteristics.characteristics. Any item either belongs to the set (true) or not belong to Any item either belongs to the set (true) or not belong to
the set (false)the set (false) AND AND
combine two sets, A and B, to create a combine two sets, A and B, to create a smallersmaller (or at (or at least not larger) set C.least not larger) set C.
any items in C must be in BOTH set A and set B.any items in C must be in BOTH set A and set B. OROR
Union of two sets, A and B, to create Union of two sets, A and B, to create a largera larger set C. set C. any item in C must be either in set A or in set B.any item in C must be either in set A or in set B.
NotNot to exclude items in a set.to exclude items in a set.
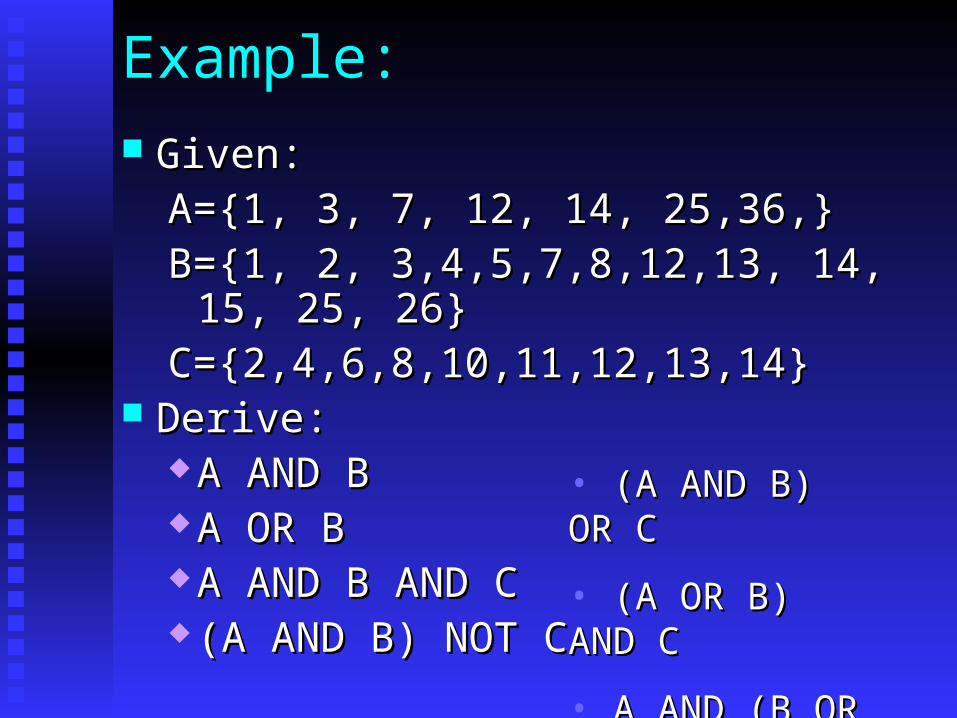
Example:
Given:Given:A={1, 3, 7, 12, 14, 25,36,}A={1, 3, 7, 12, 14, 25,36,}B={1, 2, 3,4,5,7,8,12,13, 14, 15, 25, 26}B={1, 2, 3,4,5,7,8,12,13, 14, 15, 25, 26}C={2,4,6,8,10,11,12,13,14}C={2,4,6,8,10,11,12,13,14}
Derive:Derive: A AND BA AND B A OR BA OR B A AND B AND CA AND B AND C (A AND B) NOT C(A AND B) NOT C
• (A AND B) OR C(A AND B) OR C
• (A OR B) AND C(A OR B) AND C
• A AND (B OR C)A AND (B OR C)

Boolean Logic
Venn DiagramVenn Diagram graphical representation of Boolean logicgraphical representation of Boolean logic
A and (B or C)A and (B or C)A and B or (C and D)A and B or (C and D)

Boolean Query Terms connected by Boolean operatorsTerms connected by Boolean operators The system retrieves a set of documents The system retrieves a set of documents
based on the Boolean logic of the query.based on the Boolean logic of the query. Examples:Examples:
(network or networks or structured or (network or networks or structured or system or systems) and (information or system or systems) and (information or retrieval)retrieval)

Advantages of Boolean Search
Simple and specificSimple and specific EffectiveEffective
AND reduces the number of hits very AND reduces the number of hits very quicklyquickly
OR expands search scopeOR expands search scope Strong logic-basedStrong logic-based
proved mathematical foundationsproved mathematical foundations

Problems of Boolean Search:
Boolean search is an exact searchBoolean search is an exact search either retrieving or not retrieving a either retrieving or not retrieving a
document.document. Requesting “computer” would not find Requesting “computer” would not find
“computing” unless more programming is “computing” unless more programming is donedone
No weighting can be done on termsNo weighting can be done on terms in query, A and B, you can’t specify A is in query, A and B, you can’t specify A is
more important than B.more important than B.

No Ranking No Ranking Retrieved sets can not be ordered based on Retrieved sets can not be ordered based on
the Boolean logic.the Boolean logic. Every retrieved document are treated Every retrieved document are treated
equally.equally. Possible order confusionPossible order confusion
A AND B OR CA AND B OR C

Vectors A numerical representation for a point in a A numerical representation for a point in a
multi-dimensional space.multi-dimensional space.(x(x11, x, x22, … … x, … … xnn))
Dimensions of the space need to be Dimensions of the space need to be defineddefined
A measure of the space needs to be A measure of the space needs to be defined.defined.
n
1k
2jkikji
jnj2j1j
ini2i1i
)x(x)x,d(x
Distance
)x,......,x,(xx
)x,......,x,(xx

Vector Representation of Document Space
Each indexing term is a dimension Each document is a vector
Di = (ti1, ti2, ti3, ti4, ... tin)
Dj = (tj1, tj2, dj3, tj4, ..., tjn) Document similarity is defined as
n
1k
n
1k
2jk
2ik
n
1kjkik
ji
t*t
t*t) D,(D Similarity

Example: A document Space is defined by three terms:A document Space is defined by three terms:
hardware, software, userhardware, software, user A set of documents are defined as:A set of documents are defined as:
A1=(1, 0, 0),A1=(1, 0, 0), A2=(0, 1, 0), A2=(0, 1, 0), A3=(0, 0, 1)A3=(0, 0, 1) A4=(1, 1, 0),A4=(1, 1, 0), A5=(1, 0, 1), A5=(1, 0, 1), A6=(0, 1, 1)A6=(0, 1, 1) A7=(1, 1, 1)A7=(1, 1, 1) A8=(1, 0, 1).A8=(1, 0, 1). A9=(0, 1, 1)A9=(0, 1, 1)
If the Query is “hardware and software”If the Query is “hardware and software” what documents should be retrieved?what documents should be retrieved?

In Boolean query matching:In Boolean query matching: document A4, A7 will be retrieved by “ANDing” the document A4, A7 will be retrieved by “ANDing” the
two query termstwo query terms retrieved:A1, A2, A4, A5, A6, A7, A8, A9 if two retrieved:A1, A2, A4, A5, A6, A7, A8, A9 if two
query terms are “ORed” together.query terms are “ORed” together. In Vector query matching:In Vector query matching:
q=(1, 1, 0)q=(1, 1, 0) S(q, A1)=0.71, S(q, A1)=0.71, S(q, A2)=0.71,S(q, A2)=0.71, S(q, A3)=0S(q, A3)=0 S(q, A4)=1,S(q, A4)=1, S(q, A5)=0.5, S(q, A5)=0.5, S(q, A6)=0.5S(q, A6)=0.5 S(q, A7)=0.82, S(q, A7)=0.82, S(q, A8)=0.5, S(q, A8)=0.5, S(q, A9)=0.5S(q, A9)=0.5 Document retrieved set (with order)=Document retrieved set (with order)=
{A4, A7, A1, A2, A5, A6, A8, A9}{A4, A7, A1, A2, A5, A6, A8, A9}

Weights in the Vector Space A main advantage of Vector representation is that A main advantage of Vector representation is that
items in vectors don’t have to be just 0 or 1 (true or items in vectors don’t have to be just 0 or 1 (true or false).false). A1=(0.7, 0.5, 0.3)A1=(0.7, 0.5, 0.3) A2=(0.5, 0.2, 0.7)A2=(0.5, 0.2, 0.7) A3=(0.3, 0.6, 0.9)A3=(0.3, 0.6, 0.9) A4=(0.7, 0.9, 1.0)A4=(0.7, 0.9, 1.0)
Queries may also be weighted:Queries may also be weighted: Q=(0.7, 0.3, 0)Q=(0.7, 0.3, 0)

TF and IDF TF – term frequencyTF – term frequency
number of times a term occurs in a number of times a term occurs in a documentdocument
DF –Document frequency DF –Document frequency Number of documents that contain the term. Number of documents that contain the term.
IDF – inversed document frequencyIDF – inversed document frequency =log(N/n=log(N/nii)) N –the total number of documents N –the total number of documents nnii – number of documents that contains – number of documents that contains
term i. term i.

Salton’s Vector Space A document is represented as a vector:A document is represented as a vector:
(W(W11, W, W22, … … , W, … … , Wnn)) Binary:Binary:
WWii= 1 if the corresponding term is in the = 1 if the corresponding term is in the documentdocument
WWii= 0 if the term is not in the document= 0 if the term is not in the document TF: (Term Frequency)TF: (Term Frequency)
WWii= tf= tfii where tf where tfii is the number of times the term is the number of times the term occurred in the document occurred in the document
TF*IDF: (Inverse Document Frequency)TF*IDF: (Inverse Document Frequency) WWii =tf =tfii*idf*idfii=tf=tfii*(1+log(N/df*(1+log(N/dfii)))) where dfwhere dfii is the is the
number of documents contains the term i, and N number of documents contains the term i, and N the total number of documents in the collection.the total number of documents in the collection.

In vector space, documents and queries are treated In vector space, documents and queries are treated the same.the same. It is easier to do similarity search:It is easier to do similarity search:
““find documents like this one”find documents like this one” It is easier to do document clusters:It is easier to do document clusters:
““group documents into categories and group documents into categories and subcategories”subcategories”
It’s easier to display search results graphicallyIt’s easier to display search results graphically““Giving meaning to place or location in the Giving meaning to place or location in the
multi-dimensional space”multi-dimensional space”

Web Indexing
Most web indexing is Vector-based indexing, with Most web indexing is Vector-based indexing, with variances: variances: robot indexing software keeps traverse the web robot indexing software keeps traverse the web
to collect more pages and termsto collect more pages and terms Servers establish a huge inverted indexing and Servers establish a huge inverted indexing and
vector indexing databasevector indexing database Search engines conduct different types of vector Search engines conduct different types of vector
query matchingquery matchingonly a few search engines implement truly only a few search engines implement truly
Boolean query matchingBoolean query matching

The real differences among different search The real differences among different search engines are engines are their indexing weight schemestheir indexing weight schemes their query process methodstheir query process methods their ranking algorithmstheir ranking algorithms None of these are published by any of the None of these are published by any of the
search engines firms.search engines firms.

Alternative IR Models Probabilistic ModelProbabilistic Model
Given a document d, how likely would the user Given a document d, how likely would the user consider it relevant? consider it relevant?
How likely would the user consider it no How likely would the user consider it no relevant?relevant?
If these two are known, Similarity of document d If these two are known, Similarity of document d and query q can be defined as:and query q can be defined as:
S(d, q) = probability of d is relevant to q S(d, q) = probability of d is relevant to q
probability of d is not relevant to qprobability of d is not relevant to q

Examples:
If a document is 80% likely to be relevant If a document is 80% likely to be relevant to query q, what is its (probabilistic) to query q, what is its (probabilistic) similarity?similarity?
If a document is only 30% likely to be If a document is only 30% likely to be relevant, what is the similarity?relevant, what is the similarity?

If there are 100 documents, 10 are relevant to a If there are 100 documents, 10 are relevant to a query, query, what is the probability of relevance for a what is the probability of relevance for a
randomly select document?randomly select document? What is the similarity of this document to the What is the similarity of this document to the
query?query? Any retrieve systems must do must better than Any retrieve systems must do must better than
that.that. In general, retrieval systems should retrieve In general, retrieval systems should retrieve
those S>1 those S>1

Advantages of the Probabilistic modelAdvantages of the Probabilistic model Documents can be ranked by its relevance Documents can be ranked by its relevance
probability.probability. Relevance probability can be improved through Relevance probability can be improved through
the interaction process.the interaction process. Good mathematic modelGood mathematic model
Disadvantages:Disadvantages: Involved many assumptionsInvolved many assumptions Not very practicalNot very practical

Fuzzy Set Model Fuzzy Set Theory Fuzzy Set Theory
Extension of Boolean set theoryExtension of Boolean set theoryInstead of a binary membership Instead of a binary membership
definition, fuzzy set Membership is definition, fuzzy set Membership is continuously defined between 0 and 1.continuously defined between 0 and 1.
Example: Example: • { Male students in our class}{ Male students in our class}• {tall students in our class}{tall students in our class}• One is Boolean set and one is fuzzy One is Boolean set and one is fuzzy
set.set.

The set of retrieved documents should be The set of retrieved documents should be considered as a fuzzy set.considered as a fuzzy set. Documents are not just relevant or not-Documents are not just relevant or not-
relevant.relevant. Documents can be somehow relevant.Documents can be somehow relevant. Documents can be 80% likely to be Documents can be 80% likely to be
relevant.relevant. Good Mathematical Models but not widely Good Mathematical Models but not widely
implemented and tested. implemented and tested.

Latent Semantic Indexing Model
Map documents from a high-dimensional Map documents from a high-dimensional space to a lower dimensional space, while space to a lower dimensional space, while maintaining document relationships.maintaining document relationships. For clusteringFor clustering For visualizationFor visualization
It’s a popular advanced retrieval technique.It’s a popular advanced retrieval technique. It’s computationally expensive. It’s computationally expensive.

Neural Network Model
Organize the document collection as a semantic Organize the document collection as a semantic network through learningnetwork through learning Use known queries/relevant documents to to Use known queries/relevant documents to to
train the network, and later allow the network to train the network, and later allow the network to predict relevance for new queries. (supervised predict relevance for new queries. (supervised learning)learning)
Use document-document relationships to “self-Use document-document relationships to “self-organize” the network and move relevant organize” the network and move relevant documents close to each other. (un-supervised documents close to each other. (un-supervised learning). learning).

The Fusion Model Retrieve documents based on text indexing Retrieve documents based on text indexing
(Boolean model or Vector Space Model, etc.)(Boolean model or Vector Space Model, etc.) Retrieve documents based on link models Retrieve documents based on link models
(Citations, Google’s PageLink, etc.)\(Citations, Google’s PageLink, etc.)\ Retrieve documents based on classification models Retrieve documents based on classification models
(The classification schemes, thesauri, Yahoo (The classification schemes, thesauri, Yahoo categories, etc).categories, etc).
““Fusion” results together before response to the Fusion” results together before response to the useruser

Models for Browsing
Flat ModelFlat Model No particular organizations of materialsNo particular organizations of materials
Hierarchical modelHierarchical model Assign documents into a hierarchical Assign documents into a hierarchical
structure.structure. Hypertext ModelHypertext Model
Define appropriate links among related Define appropriate links among related documents.documents.
![Jianting Zhou *, Xiaogang Li, Runchuan Xia, Jun Yang and ... · For example, in Japan, the Akashi Kaikyo Bridge [6] has a main span of 1991 m. ... Drexel University in America completed](https://static.fdocuments.in/doc/165x107/5b480f817f8b9aa4148d43d8/jianting-zhou-xiaogang-li-runchuan-xia-jun-yang-and-for-example-in.jpg)

















