Congestion Control Principles Floyd, S., RFC 2914: Congestion Control Principles. , 2000
Upload
sierra-connerCategory
view
20download
0description

1
INF 2914Information Retrieval and Web
Search
Lecture 7: Query ProcessingThese slides are adapted from
Stanford’s class CS276 / LING 286Information Retrieval and Web
Mining

2
Query processing: AND
Consider processing the query:Brutus AND Caesar Locate Brutus in the Dictionary;
Retrieve its postings. Locate Caesar in the Dictionary;
Retrieve its postings. “Merge” the two postings:
128
34
2 4 8 16 32 64
1 2 3 5 8 13
21
Brutus
Caesar

3
34
1282 4 8 16 32 64
1 2 3 5 8 13 21
The merge
Walk through the two postings simultaneously, in time linear in the total number of postings entries
128
34
2 4 8 16 32 64
1 2 3 5 8 13 21
Brutus
Caesar2 8
If the list lengths are x and y, the merge takes O(x+y)operations.Crucial: postings sorted by docID.

4
Boolean queries: Exact match
The Boolean Retrieval model is being able to ask a query that is a Boolean expression: Boolean Queries are queries using AND, OR
and NOT to join query terms Views each document as a set of words Is precise: document matches condition or not.
Primary commercial retrieval tool for 3 decades.
Professional searchers (e.g., lawyers) still like Boolean queries: You know exactly what you’re getting.

5
Boolean queries: More general merges
Exercise: Adapt the merge for the queries:Brutus AND NOT CaesarBrutus OR NOT Caesar
Can we still run through the merge in time O(x+y) or what can we achieve?

6
Merging
What about an arbitrary Boolean formula?(Brutus OR Caesar) AND NOT(Antony OR Cleopatra) Can we always merge in “linear” time?
Linear in what? Can we do better?

7
Query optimization
What is the best order for query processing?
Consider a query that is an AND of t terms. For each of the t terms, get its postings,
then AND them together.Brutus
Calpurnia
Caesar
1 2 3 5 8 16 21 34
2 4 8 16 32 64 128
13 16
Query: Brutus AND Calpurnia AND Caesar

8
Query optimization example
Process in order of increasing freq: start with smallest set, then keep cutting
further.
Brutus
Calpurnia
Caesar
1 2 3 5 8 13 21 34
2 4 8 16 32 64 128
13 16
This is why we keptfreq in dictionary
Execute the query as (Caesar AND Brutus) AND Calpurnia.

9
More general optimization
e.g., (madding OR crowd) AND (ignoble OR strife)
Get freq’s for all terms. Estimate the size of each OR by the
sum of its freq’s (conservative). Process in increasing order of OR
sizes.

10
Query processing exercises
If the query is friends AND romans AND (NOT countrymen), how could we use the freq of countrymen?
Exercise: Extend the merge to an arbitrary Boolean query. Can we always guarantee execution in time linear in the total postings size?

11
Faster postings merges:Skip pointers

12
Recall basic merge
Walk through the two postings simultaneously, in time linear in the total number of postings entries
128
31
2 4 8 16 32 64
1 2 3 5 8 17 21
Brutus
Caesar2 8
If the list lengths are m and n, the merge takes O(m+n)operations.
Can we do better?Yes,if we have pointers…
13
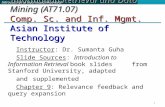
Augment postings with skip pointers (at indexing time)
Why? To skip postings that will not figure in the
search results. How? Where do we place skip pointers?
1282 4 8 16 32 64
311 2 3 5 8 17 21318
16 128

14
Query processing with skip pointers
1282 4 8 16 32 64
311 2 3 5 8 17 21318
16 128
Suppose we’ve stepped through the lists until we process 8 on each list.
When we get to 16 on the top list, we see that itssuccessor is 32.
But the skip successor of 8 on the lower list is 31, sowe can skip ahead past the intervening postings.

15
Where do we place skips?
Tradeoff: More skips shorter skip spans more
likely to skip. But lots of comparisons to skip pointers.
Fewer skips few pointer comparison, but then long skip spans few successful skips.

16
B-Trees
Use B-Trees, instead of skip pointers Handle large posting lists
Top levels of the B-Tree always in memory for most used posting lists Better caching performance
Read-only B-Trees Simple implementation No internal fragmentation

17
Zig-zag join
Join all lists at the same time Self-optimized
Heuristic: when a result is found, move list with the smallest residual term frequency Want to move the list which will skip the
most number of entriesBrutus
Calpurnia
Caesar
1 2 3 5 8 13 21 34
2 4 8 16 32 64 128
13 16
No need to execute the query (Caesar AND Brutus) AND Calpurnia.

18
Zig-zag example
Brutus
Calpurnia
Caesar
1 2 3 5 8 13 21 34
2 4 8 16 32 64 128
13 16
Handle OR’s and NOT’s More about Zig-zag join in the XML class

19
Phrase queries

20
Phrase queries
Want to answer queries such as “stanford university” – as a phrase
Thus the sentence “I went to university at Stanford” is not a match. The concept of phrase queries has proven
easily understood by users; about 10% of web queries are phrase queries
No longer suffices to store only <term : docs> entries

21
Positional indexes
Store, for each term, entries of the form:<number of docs containing term;doc1: position1, position2 … ;doc2: position1, position2 … ;etc.>

22
Positional index example
Can compress position values/offsets Nevertheless, this expands postings
storage substantially
<be: 993427;1: 7, 18, 33, 72, 86, 231;2: 3, 149;4: 17, 191, 291, 430, 434;5: 363, 367, …>
Which of docs 1,2,4,5could contain “to be
or not to be”?

23
Processing a phrase query
Extract inverted index entries for each distinct term: to, be, or, not.
Merge their doc:position lists to enumerate all positions with “to be or not to be”. to:
2:1,17,74,222,551; 4:8,16,190,429,433; 7:13,23,191; ...
be: 1:17,19; 4:17,191,291,430,434;
5:14,19,101; ...
Same general method for proximity searches

24
Positional index size
You can compress position values/offsets Nevertheless, a positional index expands
postings storage substantially It is now vastly used because of the power
and usefulness of phrase and proximity queries … whether used explicitly or implicitly in a ranking retrieval system.

25
Rules of thumb
A positional index is 2–4 as large as a non-positional index
Positional index size 35–50% of volume of original text
Caveat: all of this holds for “English-like” languages

26
Combination schemes
Biword an positional indexes can be profitably combined For particular phrases (“Michael Jackson”,
“Britney Spears”) it is inefficient to keep on merging positional postings lists
Even more so for phrases like “The Who”
Williams et al. (2004) evaluate a more sophisticated mixed indexing scheme A typical web query mixture was executed
in ¼ of the time of using just a positional index
It required 26% more space than having a positional index alone

27
Wild-card queries

28
Exercise: from this, how can we enumerate all termsmeeting the wild-card query pro*cent ?
Wild-card queries: *
mon*: find all docs containing any word beginning “mon”.
Easy with binary tree (or B-tree) lexicon: retrieve all words in range: mon ≤ w < moo
*mon: find words ending in “mon”: harder Maintain an additional B-tree for terms
backwards

29
Query processing
At this point, we have an enumeration of all terms in the dictionary that match the wild-card query
We still have to look up the postings for each enumerated term
E.g., consider the query: se*ate AND fil*er This may result in the execution of many
Boolean AND queries

30
B-trees handle *’s at the end of a query term
How can we handle *’s in the middle of query term? (Especially multiple *’s)
The solution: transform every wild-card query so that the *’s occur at the end
This gives rise to the Permuterm Index.

31
Query = hel*oX=hel, Y=o
Lookup o$hel*
Permuterm index
For term hello index under: hello$, ello$h, llo$he, lo$hel, o$hell where $ is a special symbol.
Queries: X lookup on X$ X* lookup on X*$ *X lookup on X$* *X* lookup on
X* X*Y lookup on Y$X* X*Y*Z ??? Exercise!

32
Empirical observation for English.
Permuterm query processing
Rotate query wild-card to the right Now use B-tree lookup as before. Permuterm problem: ≈ quadruples lexicon
size

33
$a,ap,pr,ri,il,l$,$i,is,s$,$t,th,he,e$,$c,cr,ru,ue,el,le,es,st,t$, $m,mo,on,nt,h$
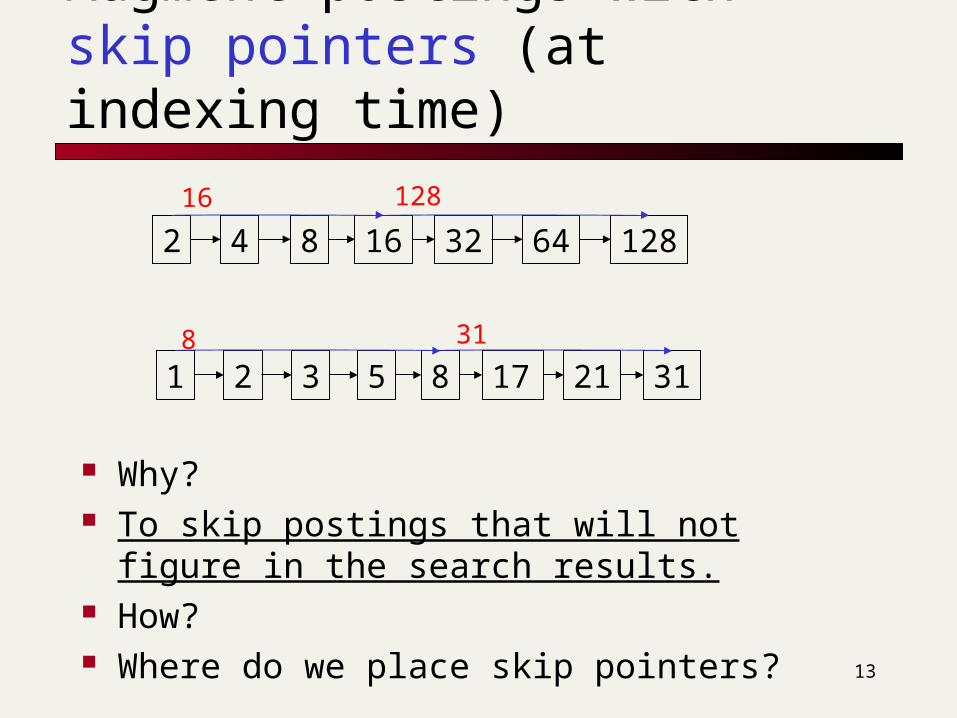
Bigram indexes
Enumerate all k-grams (sequence of k chars) occurring in any term
e.g., from text “April is the cruelest month” we get the 2-grams (bigrams)
$ is a special word boundary symbol Maintain an “inverted” index from bigrams
to dictionary terms that match each bigram.
34
mo
on
among
$m mace
among
amortize
madden
around
Bigram index example

35
Processing n-gram wild-cards
Query mon* can now be run as $m AND mo AND on
Fast, space efficient. Gets terms that match AND version of our
wildcard query. But we’d enumerate moon. Must post-filter these terms against query. Surviving enumerated terms are then
looked up in the term-document inverted index.

36
Search
Type your search terms, use ‘*’ if you need to.E.g., Alex* will match Alexander.
Processing wild-card queries
As before, we must execute a Boolean query for each enumerated, filtered term.
Wild-cards can result in expensive query execution

37
Spelling correction

38
Spell correction
Two principal uses Correcting document(s) being indexed Retrieve matching documents when query
contains a spelling error Two main flavors:
Isolated word Check each word on its own for misspelling Will not catch typos resulting in correctly spelled
words e.g., from form Context-sensitive
Look at surrounding words, e.g., I flew form Heathrow to Narita.

39
Document correction
Primarily for OCR’ed documents Correction algorithms tuned for this
Goal: the index (dictionary) contains fewer OCR-induced misspellings
Can use domain-specific knowledge E.g., OCR can confuse O and D more often
than it would confuse O and I (adjacent on the keyboard, so more likely interchanged in typing).

40
Query mis-spellings
Our principal focus here E.g., the query Alanis Morisett
We can either Retrieve documents indexed by the correct
spelling, OR Return several suggested alternative
queries with the correct spelling Did you mean Alanis Morissette?

41
Isolated word correction
Fundamental premise – there is a lexicon from which the correct spellings come
Two basic choices for this A standard lexicon such as
Webster’s English Dictionary An “industry-specific” lexicon – hand-maintained
The lexicon of the indexed corpus E.g., all words on the web All names, acronyms etc. (Including the mis-spellings)

42
Isolated word correction
Given a lexicon and a character sequence Q, return the words in the lexicon closest to Q
What’s “closest”? We’ll study several alternatives
Edit distance Weighted edit distance n-gram overlap

43
Edit distance
Given two strings S1 and S2, the minimum number of basic operations to covert one to the other
Basic operations are typically character-level Insert Delete Replace
E.g., the edit distance from cat to dog is 3. Generally found by dynamic programming.

44
Edit distance
Also called “Levenshtein distance” See http://www.merriampark.com/ld.htm
for a nice example plus an applet to try on your own

45
Weighted edit distance
As above, but the weight of an operation depends on the character(s) involved Meant to capture keyboard errors, e.g. m
more likely to be mis-typed as n than as q Therefore, replacing m by n is a smaller edit
distance than by q (Same ideas usable for OCR, but with
different weights) Require weight matrix as input Modify dynamic programming to handle
weights

46
Using edit distances
Given query, first enumerate all dictionary terms within a preset (weighted) edit distance
(Some literature formulates weighted edit distance as a probability of the error)
Then look up enumerated dictionary terms in the term-document inverted index Slow but no real fix Tries help
Better implementations – see Kukich, Zobel/Dart references.

47
Edit distance to all dictionary terms?
Given a (mis-spelled) query – do we compute its edit distance to every dictionary term? Expensive and slow
How do we cut the set of candidate dictionary terms?
Here we use n-gram overlap for this

48
n-gram overlap
Enumerate all the n-grams in the query string as well as in the lexicon
Use the n-gram index to retrieve all lexicon terms matching any of the query n-grams
Threshold by number of matching n-grams Variants – weight by keyboard layout, etc.

49
Example with trigrams
Suppose the text is november Trigrams are nov, ove, vem, emb, mbe, ber.
The query is december Trigrams are dec, ece, cem, emb, mbe, ber.
So 3 trigrams overlap (of 6 in each term) How can we turn this into a normalized
measure of overlap?

50
YXYX /
One option – Jaccard coefficient
A commonly-used measure of overlap (remember dup detection)
Let X and Y be two sets; then the J.C. is
Equals 1 when X and Y have the same elements and zero when they are disjoint
X and Y don’t have to be of the same size Always assigns a number between 0 and 1
Now threshold to decide if you have a match
E.g., if J.C. > 0.8, declare a match
51
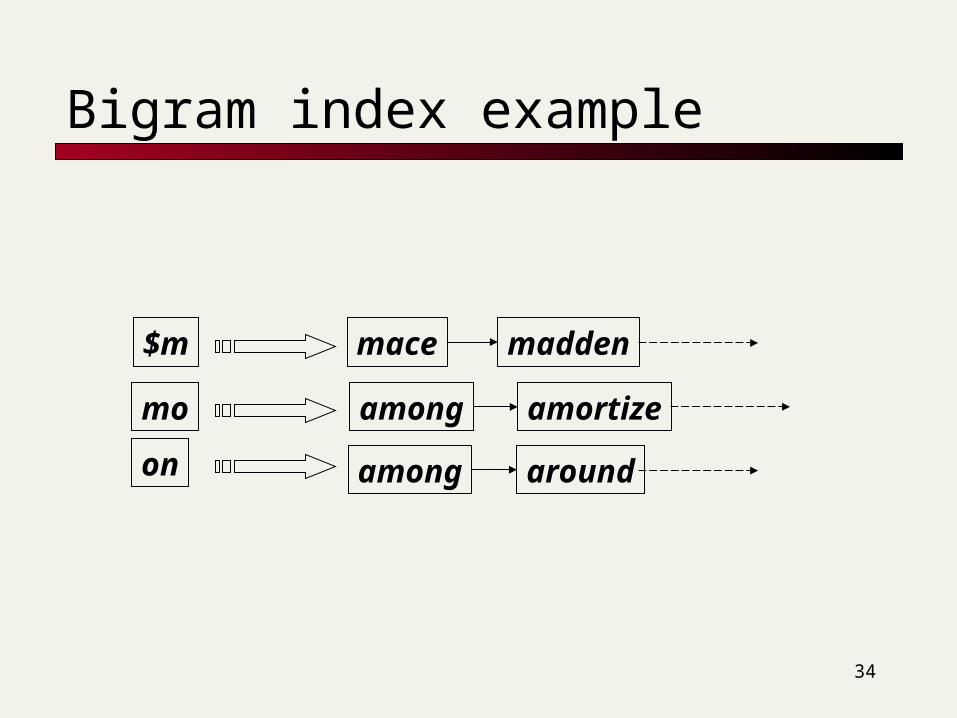
lo
or
rd
alone lord
sloth
lord
morbid
border card
border
ardent
Standard postings “merge” will enumerate …
Adapt this to using Jaccard (or another) measure.
Matching n-grams
Consider the query lord – we wish to identify words matching 2 of its 3 bigrams (lo, or, rd)

52
Caveat
Even for isolated-word correction, the notion of an index token is critical – what’s the unit we’re trying to correct?
In Chinese/Japanese, the notions of spell-correction and wildcards are poorly formulated/understood

53
Context-sensitive spell correction
Text: I flew from Heathrow to Narita. Consider the phrase query “flew form
Heathrow” We’d like to respond Did you mean “flew from Heathrow”? because no docs matched the query
phrase.

54
Context-sensitive correction
Need surrounding context to catch this NLP too heavyweight for this.
First idea: retrieve dictionary terms close (in weighted edit distance) to each query term
Now try all possible resulting phrases with one word “fixed” at a time
flew from heathrow fled form heathrow flea form heathrow etc.
Suggest the alternative that has lots of hits?

55
Exercise
Suppose that for “flew form Heathrow” we have 7 alternatives for flew, 19 for form and 3 for heathrow.
How many “corrected” phrases will we enumerate in this scheme?

56
Another approach
Break phrase query into a conjunction of biwords
Look for biwords that need only one term corrected.
Enumerate phrase matches and … rank them!

57
General issue in spell correction
Will enumerate multiple alternatives for “Did you mean”
Need to figure out which one (or small number) to present to the user
Use heuristics The alternative hitting most docs Query log analysis + tweaking
For especially popular, topical queries

58
Computational cost
Spell-correction is computationally expensive
Avoid running routinely on every query? Run only on queries that matched few docs

59
Thesauri
Thesaurus: language-specific list of synonyms for terms likely to be queried car automobile, etc.
Machine learning methods can assist Can be viewed as hand-made alternative
to edit-distance, etc.

60
Query expansion
Usually do query expansion rather than index expansion No index blowup Query processing slowed down
Docs frequently contain equivalences May retrieve more junk
puma jaguar retrieves documents on cars instead of on sneakers.

61
Resources for today’s lecture
IIR 2 MG 3.6, 4.3; MIR 7.2 Skip Lists theory: Pugh (1990)
Multilevel skip lists give same O(log n) efficiency as trees
H.E. Williams, J. Zobel, and D. Bahle. 2004. “Fast Phrase Querying with Combined Indexes”, ACM Transactions on Information Systems.
http://www.seg.rmit.edu.au/research/research.php?author=4, D. Bahle, H. Williams, and J. Zobel. Efficient phrase querying with an auxiliary index. SIGIR 2002, pp. 215-221.

62
Resources
MG 4.2 Efficient spell retrieval:
K. Kukich. Techniques for automatically correcting words in text. ACM Computing Surveys 24(4), Dec 1992.
J. Zobel and P. Dart. Finding approximate matches in large lexicons. Software - practice and experience 25(3), March 1995. http://citeseer.ist.psu.edu/zobel95finding.html
Nice, easy reading on spell correction: Mikael Tillenius: Efficient Generation and Ranking
of Spelling Error Corrections. Master’s thesis at Sweden’s Royal Institute of Technology. http://citeseer.ist.psu.edu/179155.html