
Increasing and Detecting Memory Address Congruence Sam Larsen Emmett Witchel Saman Amarasinghe...
43
Increasing and Detecting Memory Address Congruence Sam Larsen Emmett Witchel Saman Amarasinghe Laboratory for Computer Science Massachusetts Institute of Technology
-
Upload
della-griselda-mcbride -
Category
Documents
-
view
218 -
download
0
Transcript of Increasing and Detecting Memory Address Congruence Sam Larsen Emmett Witchel Saman Amarasinghe...

Increasing and Detecting Memory Address Congruence
Sam LarsenEmmett Witchel
Saman Amarasinghe
Laboratory for Computer ScienceMassachusetts Institute of Technology

The Congruence Property
int a[M], b[n];for (i=0; i<n; i++) { a[b[i]*8] = 0;}
0 4 8 …
i=0

The Congruence Property
int a[M], b[n];for (i=0; i<n; i++) { a[b[i]*8] = 0;}
0 4 8 …
i=0i=1

The Congruence Property
int a[M], b[n];for (i=0; i<n; i++) { a[b[i]*8] = 0;}
0 4 8 …
i=0i=1i=2

The Congruence Property
int a[M], b[n];for (i=0; i<n; i++) { a[b[i]*8] = 0;}
0 4 8 …

The Congruence Property
int a[M], b[n];for (i=0; i<n; i++) { a[b[i]*8] = 0;}
0 4 8 12 16 20 24 28
Congruentwith offset of 0

The Congruence Property
int a[M];for (i=0; i<n; i++) { a[16*i+2] = 0;}
0 4 8 12 16 20 24 28
Congruentwith offset of 8

The Congruence Property
int a[M];for (i=0; i<n; i++) { a[15*i+3] = 0;}
0 4 8 12 16 20 24 28
NotCongruent(32-byte line)

Outline
• Uses of congruence information• Congruence detection algorithm• Congruence-increasing transformations• Results• Related work

SIMD Compilation [PLDI ’00]
• Multimedia extensions offer wide mem ops– Motorola’s AltiVec– Intel’s MMX/SSE
• Automatic SIMD parallelization– Multiple mem ops single wide mem op
• 128-bit lds/strs must be 128-bit aligned– SSE: 6-9 cycle penalty for unaligned accesses– AltiVec: All wide mem ops have to be aligned

Energy Savings [Micro ’01]
• Skip tag checks in a set-associative cache
• Add special loads/stores to ISA– First mem op memoizes the cache way– Second mem op uses this to skip the check
• Compiler analysis determines when data occupy the same line– Need congruence information

Banked Memory Architectures
• Offset specifies the memory bank– Place data close to computation– Access banks in parallel
regfile
memory
0
regfile
memory
4
regfile
memory
8
regfile
memory
12

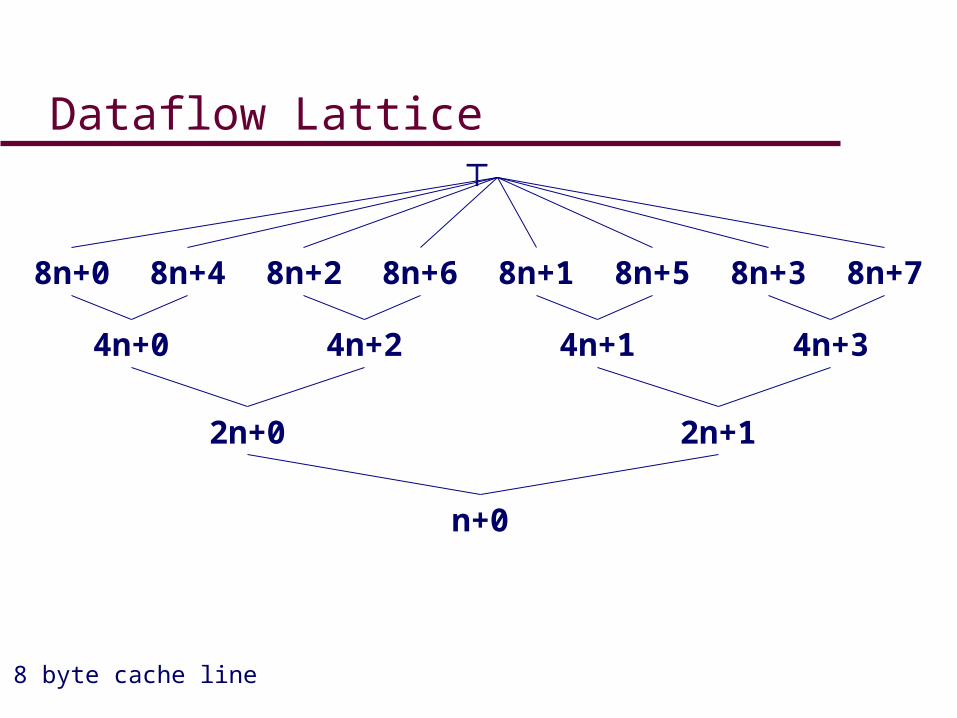
Congruence Recognition
• Iterative dataflow analysis– Low-level IR
• Lattice elements of the form an+b– For pointers, memory locations accessed
• If a = cache line size then b = offset– 32n+8 accesses offset 8 in a 32-byte line
0 4 8 12 16 20 2824
Dataflow Lattice
8 byte cache line
2n+0 2n+1
4n+0 4n+2 4n+1 4n+3
8n+0 8n+4 8n+2 8n+6 8n+1 8n+5 8n+3 8n+7
n+0

Dataflow Lattice
2n+0 2n+1
4n+0 4n+2 4n+1 4n+3
8n+0 8n+4 8n+2 8n+6 8n+1 8n+5 8n+3 8n+7
8n+04n+2
2n+0
n+0

Transfer Functions
a = gcd(a1, a2, |b1-b2|)b = b1 % a
Meet

Transfer Functions
a = gcd(a1, a2, |b1-b2|)b = b1 % a
a = gcd(a1, a2)b = (b1+b2) % a
a = gcd(a1, a2)b = (b1 – b2) % a
a = gcd(a1a2, a1b2, a2b1, C)b = (b1b2) % a
Meet
Add
Subtract
Multiply

The Bad News
• Most mem ops are not congruent– 32 byte cache line
0102030405060708090
100
% c
ong
rue
nt

Congruence Conventions (Padding)
• Allocate arrays/structs on a line boundary– Congruent accesses to arrays for a given
index– Congruent accesses to struct fields
• Requires that we:– Allocate stack frames on cache line boundary– Modify malloc to return aligned data

Unrolling
• Unrolling creates congruent references
int a[100];
for (i=0; i<n; i+=8) { a[i+0] = 0; a[i+1] = 0; … a[i+7] = 0;}
a[0]a[8]a[16]…
0 4 8 12 16 20 24 28

Unrolling
• Unrolling creates congruent references
int a[100];
for (i=0; i<n; i+=8) { a[i+0] = 0; a[i+1] = 0; … a[i+7] = 0;}
a[1]a[9]a[17]…
0 4 8 12 16 20 24 28

Congruence with Parameters
void init(int* a){ for (i=0; i<n; i+=8) { a[i+0] = 0; a[i+1] = 0; … a[i+7] = 0; }}
void main(){ int a[100]; init(&a[2]); init(&a[3]);}
0 4 8 12 16 20 24 28

Congruence with Parameters
void init(int* a){ for (i=0; i<n; i+=8) { a[i+0] = 0; a[i+1] = 0; … a[i+7] = 0; }}
void main(){ int a[100]; init(&a[2]); init(&a[3]);}
0 4 8 12 16 20 24 28

Pre-loop
• Add a pre-loop to enforce congruence
for (i=0; i<n; i++) { if ((int)&a[i] % 32 == 0) break; a[i] = 0;}for (; i<n; i+=8) { a[i+0] = 0; a[i+1] = 0; … a[i+7] = 0;} 0 4 8 12 16 20 24 28

Pre-loop
• Add a pre-loop to enforce congruence• Mem ops congruent in the unrolled body• Pre-loop has few iterations
– Most dynamic mem ops are congruent

Finding the Break Condition
• Can we choose arbitrarily?
void init(int *x) { int i; for (i=0; i<100; i+=2) { if ((int)&x[i] % 32 == 0) break; x[i] = 0; } ...}
int main() { int x[200]; init(&x[1]);}
i &x[i]%32
0 4
2 12
4 20
6 28
8 4
NO!

Finding the Break Condition
void copy(int *x, int *y) { int i; for (i=0; i<100; i++) { if ((int)&x[i] % 32 == 0 && (int)&y[i] % 32 == 0) break; x[i] = y[i]; } ...}
int main() { int x[200], y[200]; copy(&x[0], &y[0]); copy(&x[0], &y[1]);}
i &x[i]%32
&y[i]%32
0 0 0
1 4 4
… … …
8 0 0
i &x[i]%32
&y[i]%32
0 0 4
1 4 8
… … …
8 0 4
first call
second call

Finding the Break Condition
void copy(int *x, int *y) { int i; for (i=0; i<100; i++) { if ((int)&x[i] % 32 == 0 && (int)&y[i] % 32 == 0) break; x[i] = y[i]; } ...}
int main() { int x[200], y[200]; copy(&x[0], &y[0]); copy(&x[0], &y[1]);}
i &x[i]%32
&y[i]%32
0 0 0
1 4 4
… … …
8 0 0
i &x[i]%32
&y[i]%32
0 0 4
1 4 8
… … …
8 0 4
first call
second call

Finding the Break Condition
void copy(int *x, int *y) { int i; for (i=0; i<100; i++) { if ((int)&x[i] % 32 == 0 && (int)&y[i] % 32 == 4) break; x[i] = y[i]; } ...}
int main() { int x[200], y[200]; copy(&x[0], &y[0]); copy(&x[0], &y[1]);}
i &x[i]%32
&y[i]%32
0 0 0
1 4 4
… … …
8 0 0
i &x[i]%32
&y[i]%32
0 0 4
1 4 8
… … …
8 0 4
first call
second call

Finding the Break Condition
void copy(int *x, int *y) { int i; for (i=0; i<100; i++) { if ((int)&x[i] % 32 == 0) break; x[i] = y[i]; } ...}
int main() { int x[200], y[200]; copy(&x[0], &y[0]); copy(&x[0], &y[1]);}
i &x[i]%32
&y[i]%32
0 0 0
1 4 4
… … …
8 0 0
i &x[i]%32
&y[i]%32
0 0 4
1 4 8
… … …
8 0 4
first call
second call

Finding the Break Condition
• Use profiling to observe runtime addresses• Find best break condition for the profile• Exhaustive search:
– Consider all possible break conditions– Compute iterations in unrolled loop– Multiply by # of mem ops with known offset– Break condition with highest value is the best
• Results vary little with profile data set– Insignificant on all but one benchmark

Congruence Results (SPECfp95)
0
10
20
30
40
50
60
70
80
90
100
% d
ynam
ic r
efs
OriginalCongruent

Congruence Results (SPECfp95)
0
10
20
30
40
50
60
70
80
90
100
% d
ynam
ic r
efs
OriginalCongruentDetected

Congruence Results (MediaBench)
0
10
20
30
40
50
60
70
80
90
100
% d
yn
am
ic r
efs
OriginalCongruentDetected
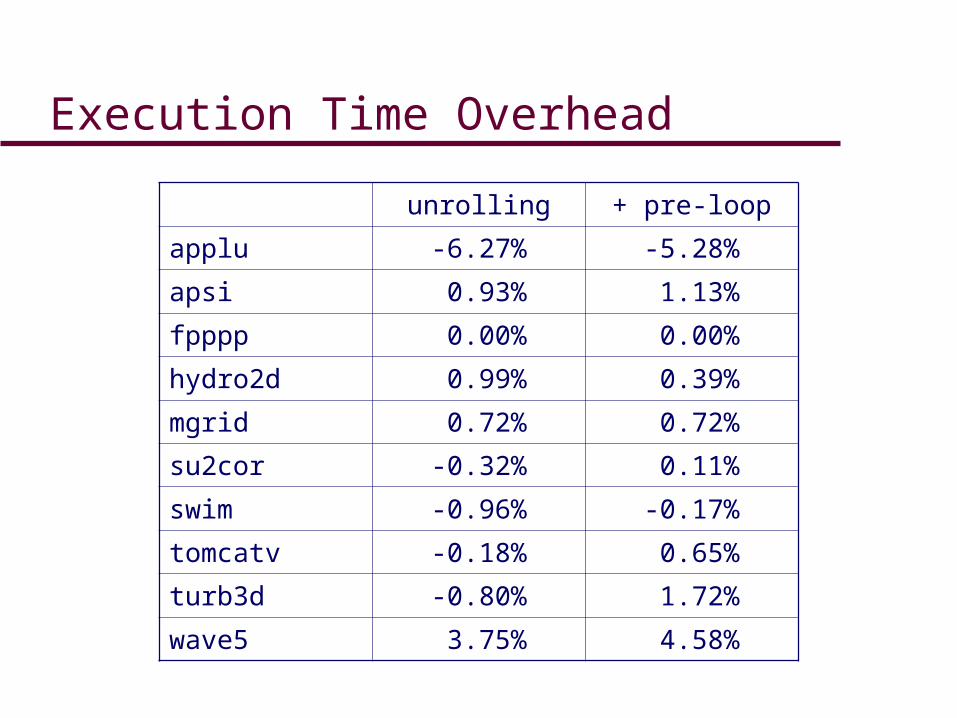
Execution Time Overhead
unrolling + pre-loop
applu -6.27% -5.28%
apsi 0.93% 1.13%
fpppp 0.00% 0.00%
hydro2d 0.99% 0.39%
mgrid 0.72% 0.72%
su2cor -0.32% 0.11%
swim -0.96% -0.17%
tomcatv -0.18% 0.65%
turb3d -0.80% 1.72%
wave5 3.75% 4.58%

DCache Energy Savings [Micro ’01]
0
5
10
15
20
25
30
35
40
% e
nerg
y s
ave
d
withwithout

Related Work
• Fisher and Ellis – Bulldog Compiler– Memory bank disambiguation– Loop unrolling
• Barua et al. – Raw Compiler– Modulo unrolling
• Davidson et al. – Mem Access Coalescing– Loop Unrolling– Alignment checks at runtime

Conclusions
• Increased number of congruent refs by 5x• Analysis detected 95%• Results are good
– MediaBench – 65% congruent, 60% detected– SpecFP95 – 84% congruent, 82% detected
• Many uses of congruence information– Wide accesses in multimedia extensions– Energy savings by tag check elimination– Bank disambiguation in clustered
architectures

Increasing and Detecting Memory Address Congruence
Sam LarsenEmmett Witchel
Saman Amarasinghe
Laboratory for Computer ScienceMassachusetts Institute of Technology

r0 = i+7r1 = r0*4r2 = r1+a*r2 = 0i = i+8
i < n
i = 0
Example
int a[100];
for (i=0; i<n; i+=8) { a[i+0] = 0; a[i+1] = 0; … a[i+7] = 0;}

Example
i: 32n+0
r0: 32n+0 + 32n+7 = 32n+7r1: 32n+7 * 32n+4 = 32n+28r2: 32n+28 + 32n+0 = 32n+28
i: 32n+0 + 32n+8 = 32n+8
r0 = i+7r1 = r0*4r2 = r1+a*r2 = 0i = i+8
i < n
i = 0

i: 32n+0
r0: 32n+0 + 32n+7 = 32n+7r1: 32n+7 * 32n+4 = 32n+28r2: 32n+28 + 32n+0 = 32n+28
i: 32n+0 + 32n+8 = 32n+8
Example
i: 32n+0
r0: 8n+0 + 32n+7 = 8n+7 r1: 8n+7 * 32n+4 = 32n+28 r2: 32n+28 + 32n+0 = 32n+28
i: 8n+0 + 32n+8 = 8n+0
i: 32n+0 32n+8 = 8n+0
*r2: offset is 28
r0 = i+7r1 = r0*4r2 = r1+a*r2 = 0i = i+8
i < n
i = 0

Multimedia Compilation
• PowerMAC G4 with AltiVec• Commercial vectorizing compiler
– Alignment pragmas
datatype Vector length
Speedup (unaligned
)
Speedup (aligned)
Improve-ment
float 4 3.25 4.75 46%
int 4 2.15 2.93 36%
short 8 2.98 5.87 97%
char 16 5.21 11.53 121%


















