
In-silico study of ToxCast GPCR assays by quantitative structure-activity relationships (QSARs)...
19
Office of Research and Development In-silico study of ToxCast GPCR assays by quantitative structure- activity relationships (QSARs) modeling Kamel Mansouri ORISE postdoctoral fellow National Center for Computational Toxicology, U.S. EPA The views expressed in this presentation are those of the author and do not necessarily reflect the views or policies of the U.S. EPA ACS 2014 11 August 2014, San Francisco
-
Upload
kamel-mansouri -
Category
Science
-
view
64 -
download
0
Transcript of In-silico study of ToxCast GPCR assays by quantitative structure-activity relationships (QSARs)...
Office of Research and Development
In-silico study of ToxCast GPCR assays by quantitative structure-activity relationships (QSARs) modeling
Kamel MansouriORISE postdoctoral fellow National Center for Computational Toxicology, U.S. EPA
The views expressed in this presentation are those of the author and do not
necessarily reflect the views or policies of the U.S. EPA
ACS 2014
11 August 2014, San Francisco

Office of Research and DevelopmentNational Center for Computational Toxicology
Outline
• ToxCast
–High-throughput Screening Data Generation
–Available data with lots of gaps to fill
–Time, cost, ethics
• GPCR assays
– Importance
–Classification models
–Regression models
–Predictions
• Future Plans
–Model other assays and extend the prediction list
2

Office of Research and DevelopmentNational Center for Computational Toxicology
Problem Statement
3
Too many chemicals to test with standard
animal-based methods
–Cost, time, animal welfare
Alternative

Office of Research and DevelopmentNational Center for Computational Toxicology
ToxCast / Tox21 Overall Strategy
• Identify targets or pathways linked to toxicity
• Develop high throughput assays for these targets or pathways
• Develop predictive systems models
– in vitro → in vivo
–in vitro → in silico
• Use predictive models (qualitative):
–Prioritize chemicals for targeted testing
• High Throughput Risk Assessments (quantitative)
• High Throughput Exposure Predictions
4
Office of Research and DevelopmentNational Center for Computational Toxicology 5
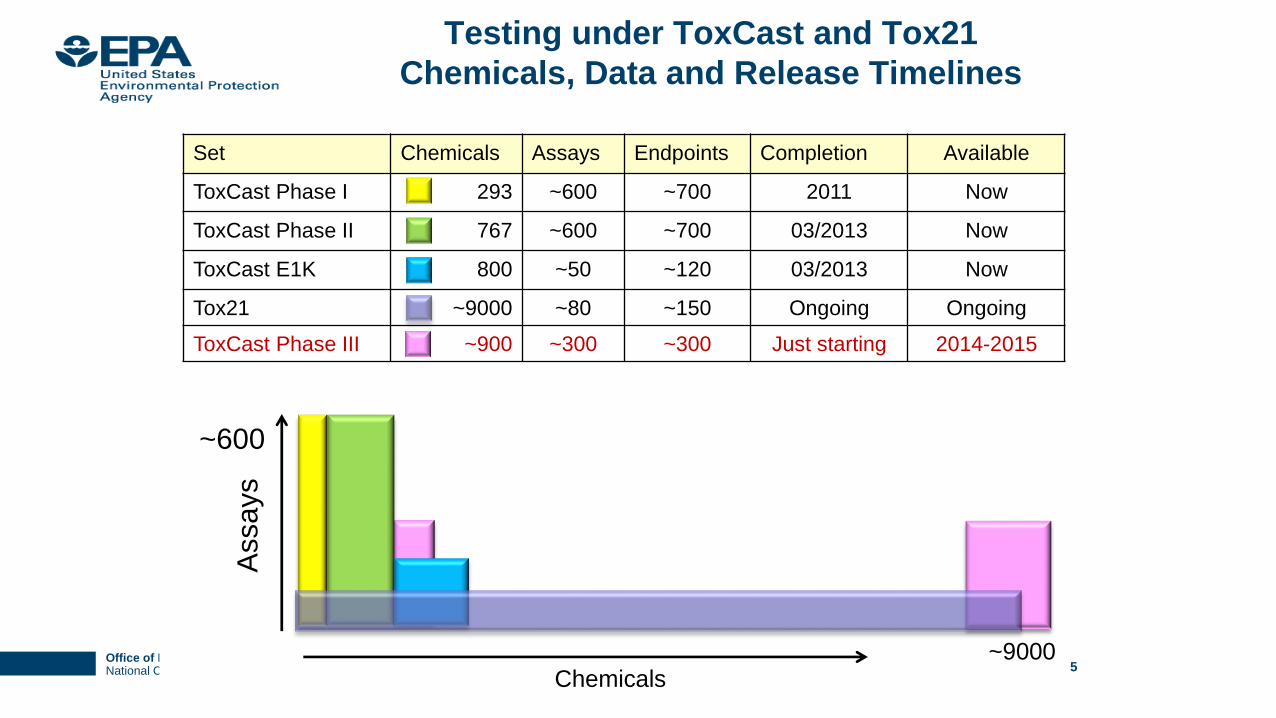
Testing under ToxCast and Tox21
Chemicals, Data and Release Timelines
Set Chemicals Assays Endpoints Completion Available
ToxCast Phase I 293 ~600 ~700 2011 Now
ToxCast Phase II 767 ~600 ~700 03/2013 Now
ToxCast E1K 800 ~50 ~120 03/2013 Now
Tox21 ~9000 ~80 ~150 Ongoing Ongoing
ToxCast Phase III ~900 ~300 ~300 Just starting 2014-2015
Chemicals
Assays
~600
~9000

Office of Research and DevelopmentNational Center for Computational Toxicology
QSAR for ToxCast targets: GPCRs
• G-Protein coupled receptors
• Common drug targets
• Chemicals are often promiscuous across GPCRs, leading to
off-target side effects
• ToxCast includes a large number of ~1000 diverse chemicals
6

Office of Research and DevelopmentNational Center for Computational Toxicology
1 1 1 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 0 1 0 0 1 1 1 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0
1 1 1 0 1 1 1 1 1 1 1 1 1 0 1 1 1 0 0 0 0 0 0 1 0 1 0 0 0 0 1 0 0 0 1 0 0 1 0 1
0 0 0 1 1 1 1 1 0 0 1 0 1 0 0 1 1 0 0 0 0 1 0 1 0 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 1 1 0 0
0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 1 1 1 1
0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 1 1 0 1 1 1 1 0 0 0 0 1 1 1 1 1
0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 1 1 0 1 1 1 1 0 0 0 0 1 1 1 1 1
1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 0 1 1 1 1 0 0 0 1 0 1 1 1 1
1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 1 1 0 1 1 1 1 0 0 0 1 0 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 0 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1
0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 1 1 1 0 1 1 0 1 0 0 0 0 1 1 1 1 1
0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 1 1 1 0 1 1 1 1 0 0 0 0 1 1 1 1 1
0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1
0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1
0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 1 1 0 1 1 1 1 1
0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1
0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0
0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 1
0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 1 0 0 0 1 0 1 1 0 0
0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1
0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 1 0 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 0 0 1 1 1 0 1 0 1 1 1 1 1 0 0 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1
0 0 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 0 0 1 0 1 1
0 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 1 1 1
0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 1 1 0 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 0
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 0 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 1 0 0 0 0 1 1 0 1 1 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 1 1 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1
0 0 0 1 1 1 1 1 0 0 1 1 1 1 1 1 1 0 0 0 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1
GPCR_gOpiateK 4 76
GPCR_rOpiate_NonSelectiveNa 2 47
GPCR_rOpiate_NonSelective 1 67
GPCR_p5HT2C 7 68
GPCR_bDR_NonSelective 3 26
GPCR_r5HT_NonSelective 2 36
GPCR_rAdra1A 3 37
GPCR_h5HT2A 4 38
IC_rNaCh_site2 13 91
IC_rCaBTZCHL 3 62
GPCR_gH2 5 59
GPCR_rAdra1_NonSelective 4 40
GPCR_rmAdra2B 5 66
GPCR_hAdra2A 3 50
GPCR_rAdra2_NonSelective 3 54
GPCR_rAdra1B 6 43
GPCR_hH1 7 43
TR_gDAT 4 98
TR_hDAT 7 120
GPCR_hNK2 6 60
IC_rCaDHPRCh_L 1 50
GPCR_h5HT6 6 57
TR_hNET 12 137
GPCR_g5HT4 1 72
GPCR_hM2 8 58
GPCR_gMPeripheral_NonSelective 3 48
GPCR_hAdrb2 4 32
GPCR_hM4 5 66
GPCR_hM1 2 49
GPCR_hM3 6 57
GPCR_hM5 6 60
GPCR_hOpiate_D1 1 10
GPCR_hAdrb1 4 50
GPCR_h5HT5A 2 70
GPCR_hOpiate_mu 5 99
GPCR_hDRD4.4 6 54
GPCR_hDRD2s 10 66
GPCR_hDRD1 9 90
GPCR_hAdra2C 8 66
GPCR_h5HT7 13 101
1 0.6 0.6 0.3 0.4 0.4 0.5 0.4 0.5 0.5 0.6 0.4 0.4 0.4 0.4 0.5 0.3 0.4 0.3 0.3 0.3 0.3 0.4 0.4 0.5 0.5 0.3 0.5 0.4 0.4 0.4 0.2 0.3 0.3 0.4 0.3 0.3 0.4 0.3 0.4
0.6 1 0.8 0.4 0.5 0.5 0.5 0.5 0.6 0.6 0.6 0.4 0.4 0.4 0.4 0.5 0.4 0.4 0.4 0.4 0.5 0.4 0.4 0.5 0.5 0.5 0.3 0.5 0.4 0.4 0.5 0.4 0.3 0.4 0.6 0.4 0.4 0.4 0.4 0.5
0.6 0.8 1 0.4 0.6 0.6 0.6 0.6 0.6 0.6 0.6 0.5 0.5 0.5 0.5 0.6 0.5 0.4 0.4 0.4 0.5 0.4 0.5 0.5 0.5 0.5 0.4 0.5 0.5 0.5 0.5 0.4 0.3 0.4 0.6 0.4 0.5 0.5 0.4 0.5
0.3 0.4 0.4 1 0.5 0.6 0.5 0.6 0.5 0.5 0.5 0.4 0.5 0.4 0.5 0.5 0.5 0.4 0.4 0.4 0.4 0.5 0.4 0.5 0.4 0.5 0.4 0.5 0.4 0.4 0.5 0.3 0.4 0.5 0.4 0.5 0.6 0.5 0.5 0.5
0.4 0.5 0.6 0.5 1 0.7 0.7 0.7 0.5 0.6 0.6 0.5 0.5 0.5 0.5 0.6 0.6 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.5 0.6 0.5 0.5 0.5 0.4 0.5 0.3 0.4 0.4 0.4 0.6 0.6 0.5 0.5 0.5
0.4 0.5 0.6 0.6 0.7 1 0.8 0.8 0.5 0.6 0.6 0.6 0.6 0.6 0.6 0.7 0.7 0.5 0.4 0.4 0.4 0.5 0.4 0.4 0.4 0.5 0.5 0.5 0.4 0.4 0.5 0.4 0.4 0.4 0.4 0.6 0.6 0.6 0.5 0.6
0.5 0.5 0.6 0.5 0.7 0.8 1 0.8 0.6 0.6 0.7 0.7 0.7 0.7 0.7 0.8 0.7 0.4 0.4 0.3 0.4 0.4 0.5 0.5 0.5 0.6 0.4 0.6 0.5 0.5 0.6 0.3 0.4 0.4 0.4 0.6 0.5 0.6 0.6 0.6
0.4 0.5 0.6 0.6 0.7 0.8 0.8 1 0.6 0.7 0.7 0.6 0.7 0.6 0.6 0.7 0.7 0.4 0.4 0.4 0.5 0.4 0.5 0.5 0.6 0.6 0.5 0.6 0.6 0.5 0.6 0.4 0.4 0.5 0.5 0.6 0.6 0.6 0.5 0.6
0.5 0.6 0.6 0.5 0.5 0.5 0.6 0.6 1 0.8 0.8 0.5 0.6 0.5 0.6 0.6 0.5 0.5 0.5 0.4 0.6 0.4 0.6 0.6 0.6 0.7 0.4 0.7 0.5 0.5 0.6 0.4 0.4 0.4 0.5 0.4 0.5 0.5 0.5 0.5
0.5 0.6 0.6 0.5 0.6 0.6 0.6 0.7 0.8 1 0.8 0.5 0.6 0.5 0.6 0.6 0.5 0.5 0.5 0.5 0.6 0.4 0.5 0.6 0.6 0.7 0.5 0.6 0.6 0.5 0.6 0.4 0.4 0.4 0.5 0.5 0.5 0.6 0.5 0.5
0.6 0.6 0.6 0.5 0.6 0.6 0.7 0.7 0.8 0.8 1 0.6 0.6 0.6 0.6 0.7 0.6 0.5 0.5 0.5 0.6 0.5 0.6 0.6 0.7 0.7 0.5 0.7 0.6 0.6 0.7 0.5 0.5 0.5 0.6 0.6 0.6 0.6 0.6 0.6
0.4 0.4 0.5 0.4 0.5 0.6 0.7 0.6 0.5 0.5 0.6 1 0.6 0.6 0.7 0.8 0.6 0.4 0.4 0.3 0.5 0.4 0.5 0.5 0.5 0.5 0.4 0.5 0.5 0.5 0.5 0.4 0.4 0.4 0.4 0.6 0.5 0.6 0.6 0.6
0.4 0.4 0.5 0.5 0.5 0.6 0.7 0.7 0.6 0.6 0.6 0.6 1 0.8 0.8 0.7 0.7 0.5 0.4 0.3 0.4 0.5 0.5 0.6 0.6 0.6 0.5 0.6 0.6 0.6 0.6 0.4 0.4 0.5 0.5 0.6 0.6 0.6 0.6 0.6
0.4 0.4 0.5 0.4 0.5 0.6 0.7 0.6 0.5 0.5 0.6 0.6 0.8 1 0.8 0.7 0.7 0.4 0.4 0.3 0.4 0.4 0.5 0.5 0.6 0.6 0.5 0.6 0.6 0.6 0.6 0.4 0.4 0.5 0.4 0.6 0.5 0.6 0.6 0.6
0.4 0.4 0.5 0.5 0.5 0.6 0.7 0.6 0.6 0.6 0.6 0.7 0.8 0.8 1 0.7 0.7 0.5 0.4 0.3 0.4 0.4 0.5 0.6 0.6 0.6 0.5 0.6 0.6 0.6 0.6 0.4 0.4 0.5 0.4 0.6 0.6 0.6 0.6 0.6
0.5 0.5 0.6 0.5 0.6 0.7 0.8 0.7 0.6 0.6 0.7 0.8 0.7 0.7 0.7 1 0.8 0.5 0.5 0.4 0.5 0.5 0.6 0.6 0.6 0.7 0.6 0.6 0.6 0.6 0.6 0.5 0.5 0.5 0.5 0.7 0.6 0.7 0.7 0.7
0.3 0.4 0.5 0.5 0.6 0.7 0.7 0.7 0.5 0.5 0.6 0.6 0.7 0.7 0.7 0.8 1 0.4 0.5 0.4 0.5 0.5 0.5 0.5 0.6 0.7 0.6 0.7 0.7 0.7 0.7 0.6 0.6 0.6 0.5 0.7 0.7 0.7 0.7 0.6
0.4 0.4 0.4 0.4 0.4 0.5 0.4 0.4 0.5 0.5 0.5 0.4 0.5 0.4 0.5 0.5 0.4 1 0.7 0.3 0.4 0.4 0.5 0.5 0.4 0.4 0.4 0.5 0.4 0.4 0.5 0.4 0.4 0.4 0.4 0.4 0.4 0.5 0.5 0.5
0.3 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.5 0.5 0.5 0.4 0.4 0.4 0.4 0.5 0.5 0.7 1 0.5 0.4 0.5 0.6 0.5 0.4 0.5 0.4 0.5 0.4 0.5 0.5 0.4 0.4 0.5 0.5 0.4 0.5 0.5 0.5 0.5
0.3 0.4 0.4 0.4 0.4 0.4 0.3 0.4 0.4 0.5 0.5 0.3 0.3 0.3 0.3 0.4 0.4 0.3 0.5 1 0.5 0.5 0.5 0.4 0.4 0.5 0.5 0.5 0.4 0.4 0.5 0.5 0.5 0.5 0.5 0.4 0.5 0.5 0.4 0.5
0.3 0.5 0.5 0.4 0.4 0.4 0.4 0.5 0.6 0.6 0.6 0.5 0.4 0.4 0.4 0.5 0.5 0.4 0.4 0.5 1 0.5 0.5 0.5 0.5 0.4 0.5 0.5 0.4 0.4 0.6 0.5 0.5 0.5 0.5 0.5 0.6 0.6 0.5 0.5
0.3 0.4 0.4 0.5 0.4 0.5 0.4 0.4 0.4 0.4 0.5 0.4 0.5 0.4 0.4 0.5 0.5 0.4 0.5 0.5 0.5 1 0.5 0.6 0.4 0.4 0.5 0.5 0.5 0.5 0.6 0.5 0.5 0.6 0.5 0.6 0.7 0.6 0.6 0.6
0.4 0.4 0.5 0.4 0.4 0.4 0.5 0.5 0.6 0.5 0.6 0.5 0.5 0.5 0.5 0.6 0.5 0.5 0.6 0.5 0.5 0.5 1 0.6 0.5 0.5 0.5 0.6 0.6 0.6 0.6 0.5 0.6 0.5 0.6 0.5 0.6 0.6 0.6 0.6
0.4 0.5 0.5 0.5 0.4 0.4 0.5 0.5 0.6 0.6 0.6 0.5 0.6 0.5 0.6 0.6 0.5 0.5 0.5 0.4 0.5 0.6 0.6 1 0.5 0.6 0.5 0.5 0.6 0.6 0.6 0.5 0.5 0.5 0.5 0.5 0.6 0.6 0.6 0.6
0.5 0.5 0.5 0.4 0.5 0.4 0.5 0.6 0.6 0.6 0.7 0.5 0.6 0.6 0.6 0.6 0.6 0.4 0.4 0.4 0.5 0.4 0.5 0.5 1 0.8 0.5 0.9 0.7 0.8 0.8 0.4 0.4 0.4 0.4 0.5 0.6 0.5 0.6 0.5
0.5 0.5 0.5 0.5 0.6 0.5 0.6 0.6 0.7 0.7 0.7 0.5 0.6 0.6 0.6 0.7 0.7 0.4 0.5 0.5 0.4 0.4 0.5 0.6 0.8 1 0.6 0.8 0.7 0.8 0.8 0.5 0.5 0.4 0.5 0.5 0.6 0.5 0.6 0.5
0.3 0.3 0.4 0.4 0.5 0.5 0.4 0.5 0.4 0.5 0.5 0.4 0.5 0.5 0.5 0.6 0.6 0.4 0.4 0.5 0.5 0.5 0.5 0.5 0.5 0.6 1 0.6 0.7 0.7 0.6 0.6 0.7 0.5 0.5 0.6 0.7 0.6 0.6 0.5
0.5 0.5 0.5 0.5 0.5 0.5 0.6 0.6 0.7 0.6 0.7 0.5 0.6 0.6 0.6 0.6 0.7 0.5 0.5 0.5 0.5 0.5 0.6 0.5 0.9 0.8 0.6 1 0.8 0.9 0.8 0.5 0.6 0.5 0.5 0.5 0.6 0.6 0.6 0.6
0.4 0.4 0.5 0.4 0.5 0.4 0.5 0.6 0.5 0.6 0.6 0.5 0.6 0.6 0.6 0.6 0.7 0.4 0.4 0.4 0.4 0.5 0.6 0.6 0.7 0.7 0.7 0.8 1 0.8 0.8 0.5 0.6 0.5 0.5 0.6 0.6 0.6 0.6 0.6
0.4 0.4 0.5 0.4 0.4 0.4 0.5 0.5 0.5 0.5 0.6 0.5 0.6 0.6 0.6 0.6 0.7 0.4 0.5 0.4 0.4 0.5 0.6 0.6 0.8 0.8 0.7 0.9 0.8 1 0.8 0.6 0.6 0.6 0.5 0.6 0.6 0.6 0.6 0.6
0.4 0.5 0.5 0.5 0.5 0.5 0.6 0.6 0.6 0.6 0.7 0.5 0.6 0.6 0.6 0.6 0.7 0.5 0.5 0.5 0.6 0.6 0.6 0.6 0.8 0.8 0.6 0.8 0.8 0.8 1 0.6 0.6 0.6 0.6 0.6 0.7 0.7 0.8 0.7
0.2 0.4 0.4 0.3 0.3 0.4 0.3 0.4 0.4 0.4 0.5 0.4 0.4 0.4 0.4 0.5 0.6 0.4 0.4 0.5 0.5 0.5 0.5 0.5 0.4 0.5 0.6 0.5 0.5 0.6 0.6 1 0.7 0.6 0.6 0.6 0.6 0.6 0.7 0.6
0.3 0.3 0.3 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.5 0.4 0.4 0.4 0.4 0.5 0.6 0.4 0.4 0.5 0.5 0.5 0.6 0.5 0.4 0.5 0.7 0.6 0.6 0.6 0.6 0.7 1 0.7 0.6 0.7 0.7 0.7 0.7 0.6
0.3 0.4 0.4 0.5 0.4 0.4 0.4 0.5 0.4 0.4 0.5 0.4 0.5 0.5 0.5 0.5 0.6 0.4 0.5 0.5 0.5 0.6 0.5 0.5 0.4 0.4 0.5 0.5 0.5 0.6 0.6 0.6 0.7 1 0.6 0.7 0.7 0.7 0.8 0.7
0.4 0.6 0.6 0.4 0.4 0.4 0.4 0.5 0.5 0.5 0.6 0.4 0.5 0.4 0.4 0.5 0.5 0.4 0.5 0.5 0.5 0.5 0.6 0.5 0.4 0.5 0.5 0.5 0.5 0.5 0.6 0.6 0.6 0.6 1 0.5 0.6 0.7 0.6 0.7
0.3 0.4 0.4 0.5 0.6 0.6 0.6 0.6 0.4 0.5 0.6 0.6 0.6 0.6 0.6 0.7 0.7 0.4 0.4 0.4 0.5 0.6 0.5 0.5 0.5 0.5 0.6 0.5 0.6 0.6 0.6 0.6 0.7 0.7 0.5 1 0.8 0.7 0.7 0.7
0.3 0.4 0.5 0.6 0.6 0.6 0.5 0.6 0.5 0.5 0.6 0.5 0.6 0.5 0.6 0.6 0.7 0.4 0.5 0.5 0.6 0.7 0.6 0.6 0.6 0.6 0.7 0.6 0.6 0.6 0.7 0.6 0.7 0.7 0.6 0.8 1 0.7 0.7 0.7
0.4 0.4 0.5 0.5 0.5 0.6 0.6 0.6 0.5 0.6 0.6 0.6 0.6 0.6 0.6 0.7 0.7 0.5 0.5 0.5 0.6 0.6 0.6 0.6 0.5 0.5 0.6 0.6 0.6 0.6 0.7 0.6 0.7 0.7 0.7 0.7 0.7 1 0.8 0.8
0.3 0.4 0.4 0.5 0.5 0.5 0.6 0.5 0.5 0.5 0.6 0.6 0.6 0.6 0.6 0.7 0.7 0.5 0.5 0.4 0.5 0.6 0.6 0.6 0.6 0.6 0.6 0.6 0.6 0.6 0.8 0.7 0.7 0.8 0.6 0.7 0.7 0.8 1 0.7
0.4 0.5 0.5 0.5 0.5 0.6 0.6 0.6 0.5 0.5 0.6 0.6 0.6 0.6 0.6 0.7 0.6 0.5 0.5 0.5 0.5 0.6 0.6 0.6 0.5 0.5 0.5 0.6 0.6 0.6 0.7 0.6 0.6 0.7 0.7 0.7 0.7 0.8 0.7 1
Dopaminergic, Serotonin, Adrenergic
Adrenergic
Muscarinic
Histamine
Histamine
GPCR assays – Cluster analysis
GPCR Aminergic assays with >=65% similarity
7
Office of Research and DevelopmentNational Center for Computational Toxicology
http://dx.doi.org/10.1016/j.str.2011.05.012
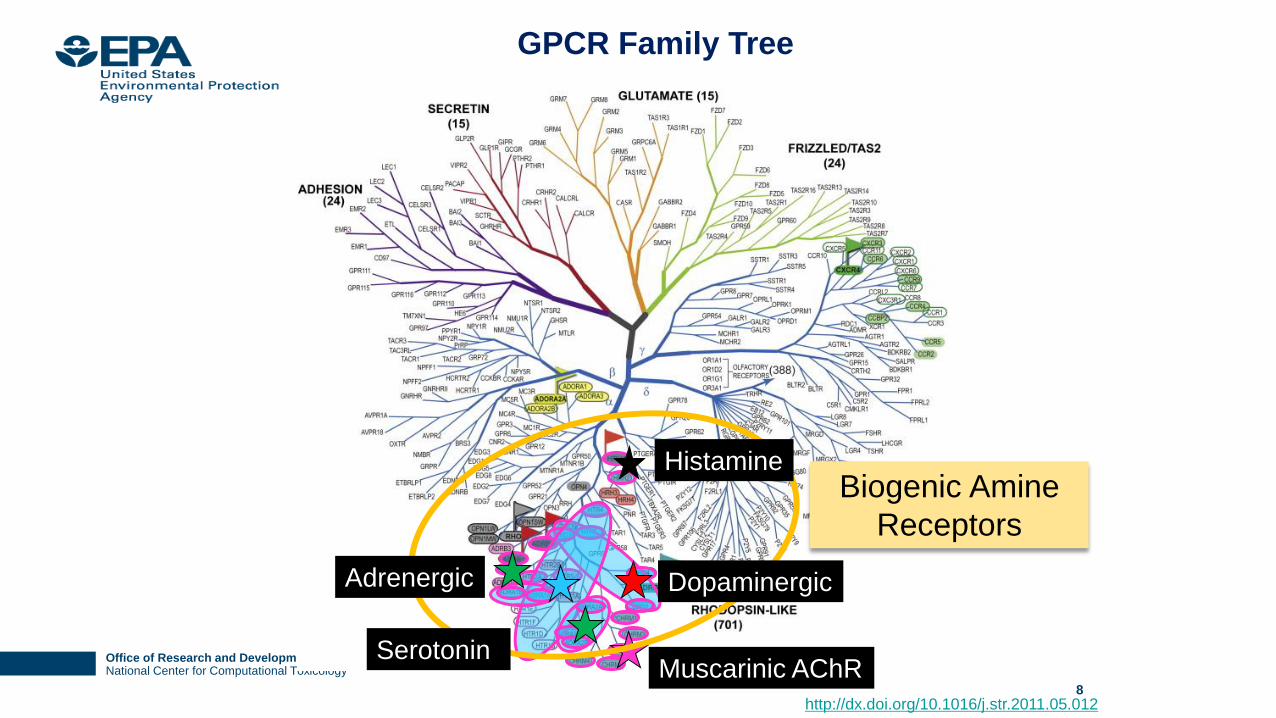
Muscarinic AChR
GPCR Family Tree
8
Biogenic Amine
Receptors
Dopaminergic
Histamine
Serotonin
Adrenergic
Office of Research and DevelopmentNational Center for Computational Toxicology
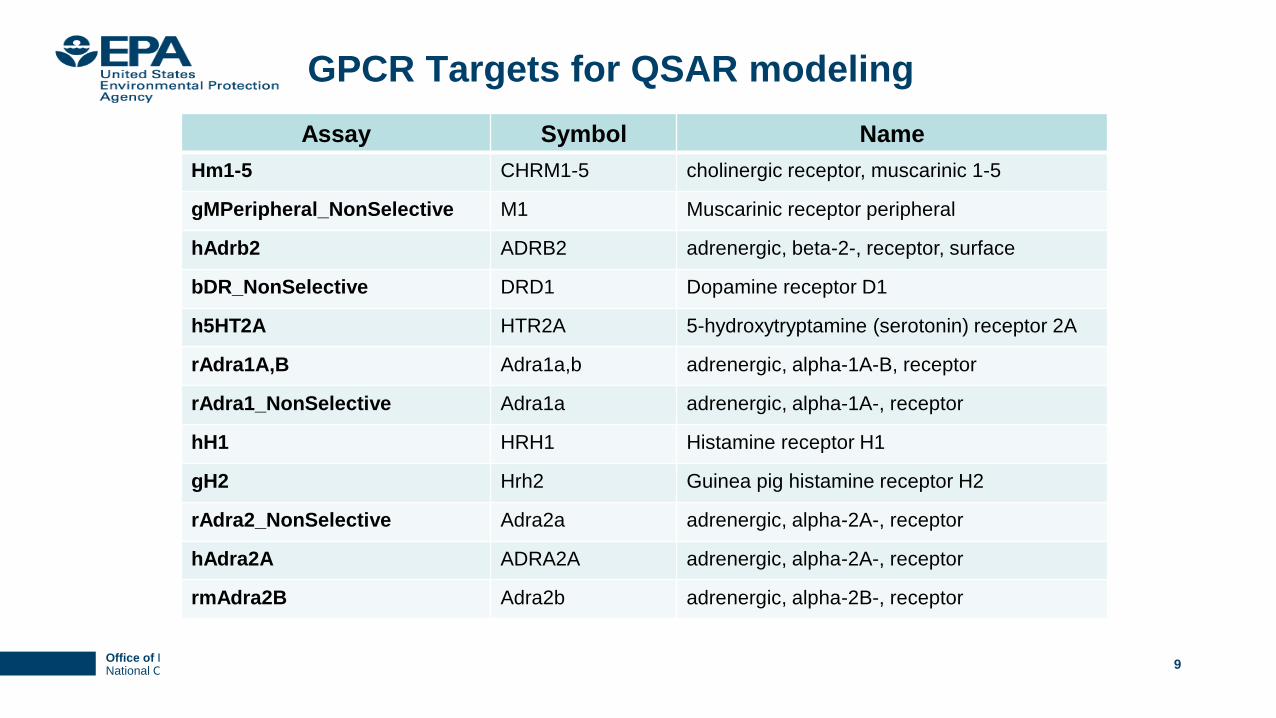
GPCR Targets for QSAR modeling
9
Assay Symbol Name
Hm1-5 CHRM1-5 cholinergic receptor, muscarinic 1-5
gMPeripheral_NonSelective M1 Muscarinic receptor peripheral
hAdrb2 ADRB2 adrenergic, beta-2-, receptor, surface
bDR_NonSelective DRD1 Dopamine receptor D1
h5HT2A HTR2A 5-hydroxytryptamine (serotonin) receptor 2A
rAdra1A,B Adra1a,b adrenergic, alpha-1A-B, receptor
rAdra1_NonSelective Adra1a adrenergic, alpha-1A-, receptor
hH1 HRH1 Histamine receptor H1
gH2 Hrh2 Guinea pig histamine receptor H2
rAdra2_NonSelective Adra2a adrenergic, alpha-2A-, receptor
hAdra2A ADRA2A adrenergic, alpha-2A-, receptor
rmAdra2B Adra2b adrenergic, alpha-2B-, receptor
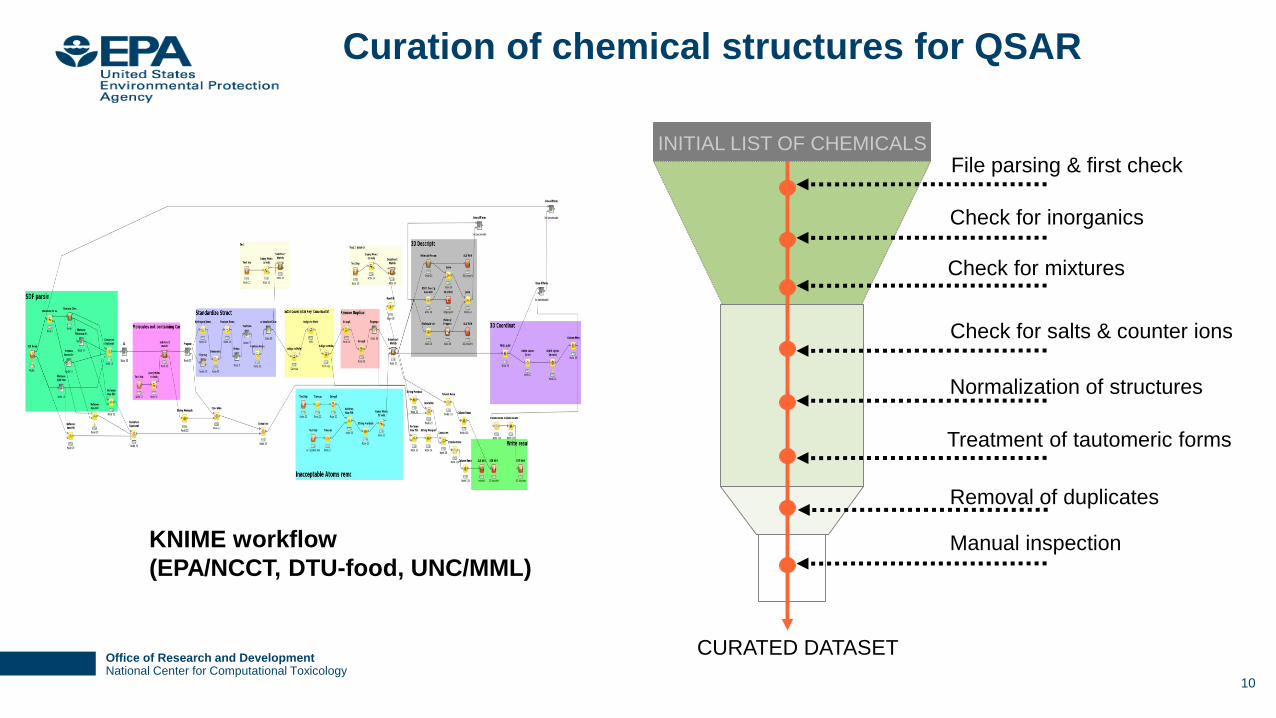
Office of Research and DevelopmentNational Center for Computational Toxicology
10
INITIAL LIST OF CHEMICALSFile parsing & first check
Check for mixtures
Check for salts & counter ions
Normalization of structures
Manual inspection
Removal of duplicates
Treatment of tautomeric forms
CURATED DATASET
Check for inorganics
Curation of chemical structures for QSAR
KNIME workflow
(EPA/NCCT, DTU-food, UNC/MML)

Office of Research and DevelopmentNational Center for Computational Toxicology
11
Training & prediction sets:
• Training set (ToxCast):
• 1005 Chemicals with data 18 Endpoints
• Binary classes (qualitative models)
• AC50 (quantitative models)
• Prediction Set (Human Exposure Universe):
• 32464 Chemicals to be predicted
Molecular descriptors calculation:
• 1022 molecular descriptors 2D chemical structures.
• Software: Indigo, RDKit, CDK and MOE.
• Reduce collinearity,
• correlation threshold of 0.96 was applied Constant
& near constant removed
• Descriptors with missing values removed.
• The remaining set consisted of 470 descriptors.
QSAR-ready data
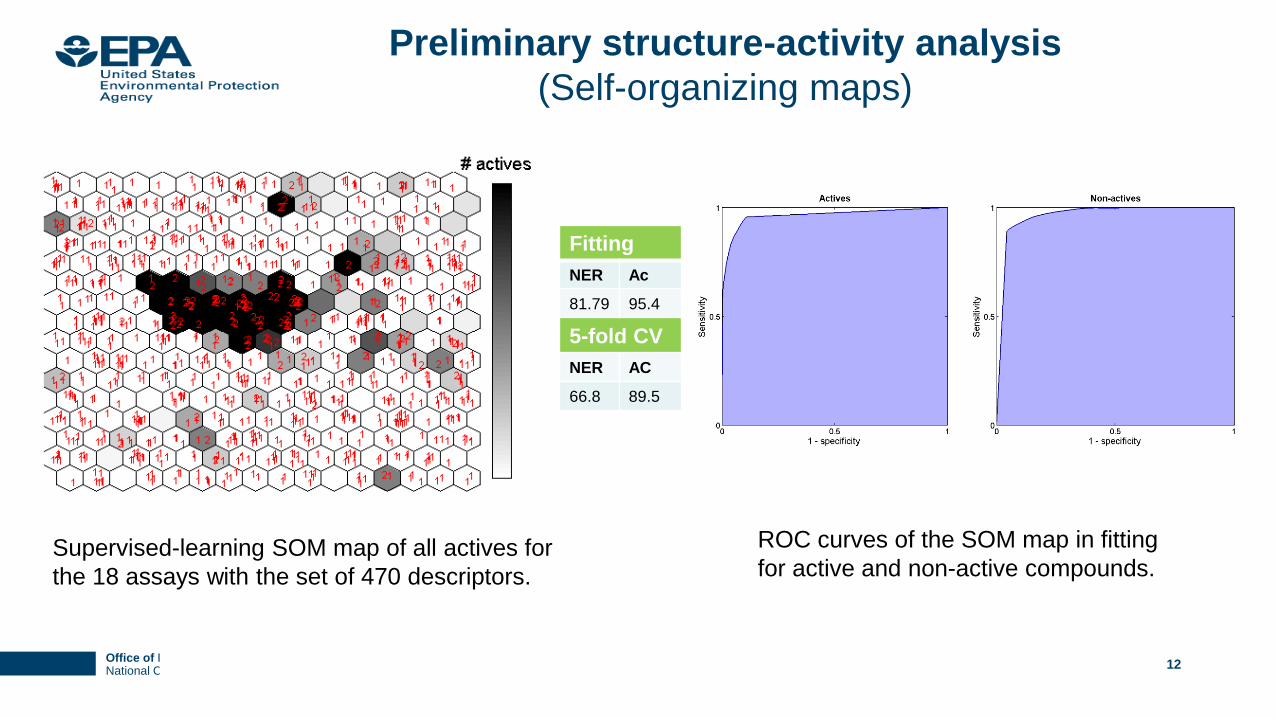
Office of Research and DevelopmentNational Center for Computational Toxicology
Preliminary structure-activity analysis
(Self-organizing maps)
12
Supervised-learning SOM map of all actives for
the 18 assays with the set of 470 descriptors.
Fitting
NER Ac
81.79 95.4
5-fold CV
NER AC
66.8 89.5
ROC curves of the SOM map in fitting
for active and non-active compounds.
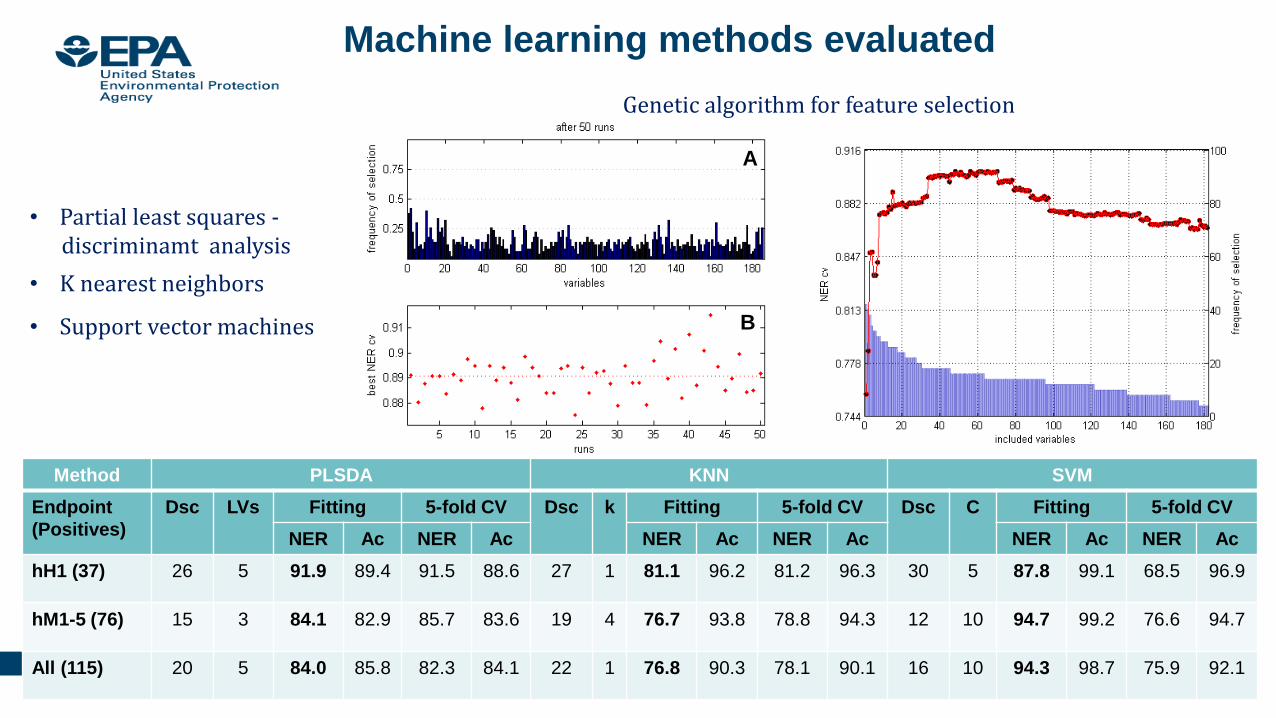
Office of Research and DevelopmentNational Center for Computational Toxicology
13
A
B
Method PLSDA KNN SVM
Endpoint
(Positives)
Dsc LVs Fitting 5-fold CV Dsc k Fitting 5-fold CV Dsc C Fitting 5-fold CV
NER Ac NER Ac NER Ac NER Ac NER Ac NER Ac
hH1 (37) 26 5 91.9 89.4 91.5 88.6 27 1 81.1 96.2 81.2 96.3 30 5 87.8 99.1 68.5 96.9
hM1-5 (76) 15 3 84.1 82.9 85.7 83.6 19 4 76.7 93.8 78.8 94.3 12 10 94.7 99.2 76.6 94.7
All (115) 20 5 84.0 85.8 82.3 84.1 22 1 76.8 90.3 78.1 90.1 16 10 94.3 98.7 75.9 92.1
• Partial least squares -discriminamt analysis
• K nearest neighbors
• Support vector machines
Machine learning methods evaluated
Genetic algorithm for feature selection
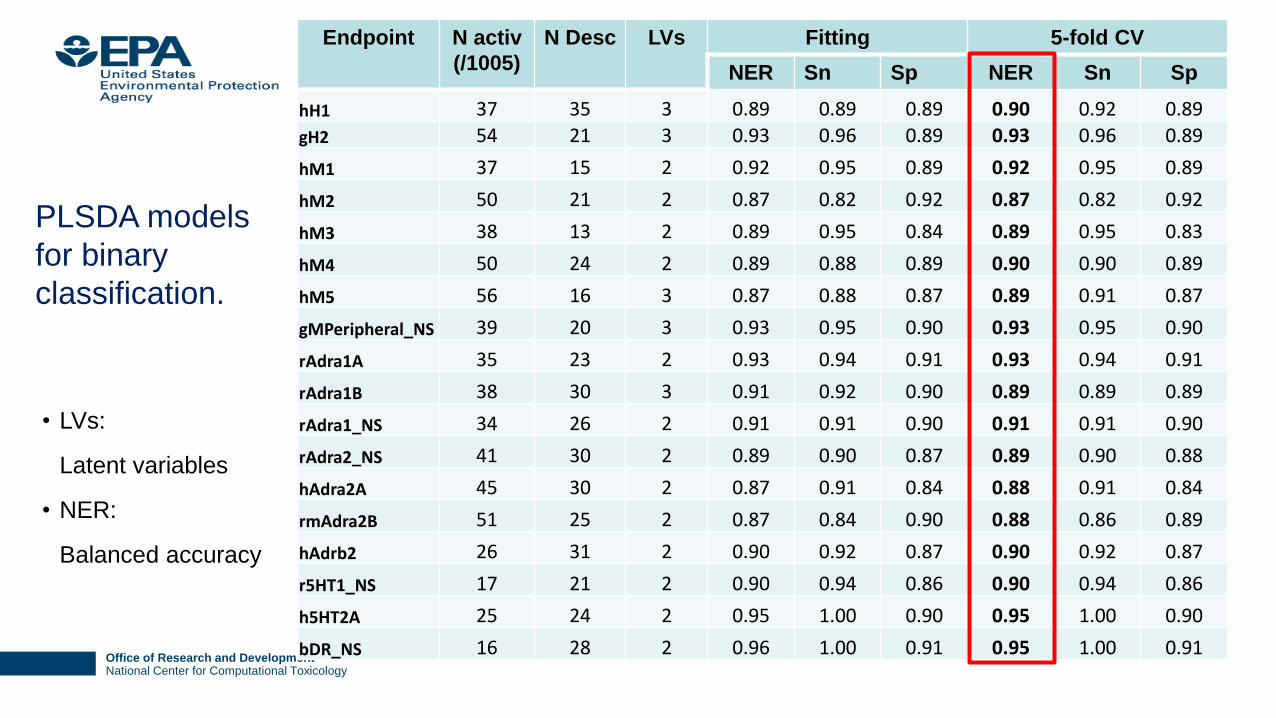
Office of Research and DevelopmentNational Center for Computational Toxicology
Endpoint N activ
(/1005)
N Desc LVs Fitting 5-fold CV
NER Sn Sp NER Sn Sp
hH1 37 35 3 0.89 0.89 0.89 0.90 0.92 0.89
gH2 54 21 3 0.93 0.96 0.89 0.93 0.96 0.89
hM1 37 15 2 0.92 0.95 0.89 0.92 0.95 0.89
hM2 50 21 2 0.87 0.82 0.92 0.87 0.82 0.92
hM3 38 13 2 0.89 0.95 0.84 0.89 0.95 0.83
hM4 50 24 2 0.89 0.88 0.89 0.90 0.90 0.89
hM5 56 16 3 0.87 0.88 0.87 0.89 0.91 0.87
gMPeripheral_NS 39 20 3 0.93 0.95 0.90 0.93 0.95 0.90
rAdra1A 35 23 2 0.93 0.94 0.91 0.93 0.94 0.91
rAdra1B 38 30 3 0.91 0.92 0.90 0.89 0.89 0.89
rAdra1_NS 34 26 2 0.91 0.91 0.90 0.91 0.91 0.90
rAdra2_NS 41 30 2 0.89 0.90 0.87 0.89 0.90 0.88
hAdra2A 45 30 2 0.87 0.91 0.84 0.88 0.91 0.84
rmAdra2B 51 25 2 0.87 0.84 0.90 0.88 0.86 0.89
hAdrb2 26 31 2 0.90 0.92 0.87 0.90 0.92 0.87
r5HT1_NS 17 21 2 0.90 0.94 0.86 0.90 0.94 0.86
h5HT2A 25 24 2 0.95 1.00 0.90 0.95 1.00 0.90
bDR_NS 16 28 2 0.96 1.00 0.91 0.95 1.00 0.91
PLSDA models
for binary
classification.
• LVs:
Latent variables
• NER:
Balanced accuracy
Office of Research and DevelopmentNational Center for Computational Toxicology
15
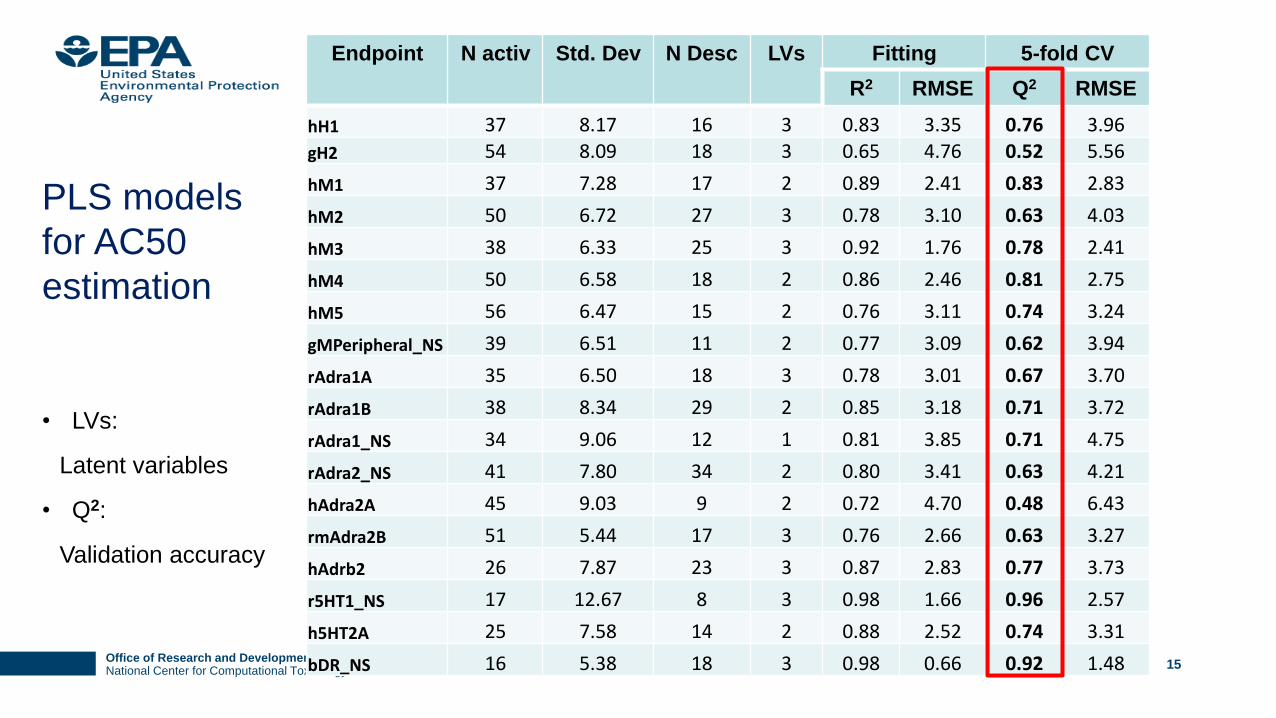
Endpoint N activ Std. Dev N Desc LVs Fitting 5-fold CV
R2 RMSE Q2 RMSE
hH1 37 8.17 16 3 0.83 3.35 0.76 3.96
gH2 54 8.09 18 3 0.65 4.76 0.52 5.56
hM1 37 7.28 17 2 0.89 2.41 0.83 2.83
hM2 50 6.72 27 3 0.78 3.10 0.63 4.03
hM3 38 6.33 25 3 0.92 1.76 0.78 2.41
hM4 50 6.58 18 2 0.86 2.46 0.81 2.75
hM5 56 6.47 15 2 0.76 3.11 0.74 3.24
gMPeripheral_NS 39 6.51 11 2 0.77 3.09 0.62 3.94
rAdra1A 35 6.50 18 3 0.78 3.01 0.67 3.70
rAdra1B 38 8.34 29 2 0.85 3.18 0.71 3.72
rAdra1_NS 34 9.06 12 1 0.81 3.85 0.71 4.75
rAdra2_NS 41 7.80 34 2 0.80 3.41 0.63 4.21
hAdra2A 45 9.03 9 2 0.72 4.70 0.48 6.43
rmAdra2B 51 5.44 17 3 0.76 2.66 0.63 3.27
hAdrb2 26 7.87 23 3 0.87 2.83 0.77 3.73
r5HT1_NS 17 12.67 8 3 0.98 1.66 0.96 2.57
h5HT2A 25 7.58 14 2 0.88 2.52 0.74 3.31
bDR_NS 16 5.38 18 3 0.98 0.66 0.92 1.48
PLS models
for AC50
estimation
• LVs:
Latent variables
• Q2:
Validation accuracy
Office of Research and DevelopmentNational Center for Computational Toxicology
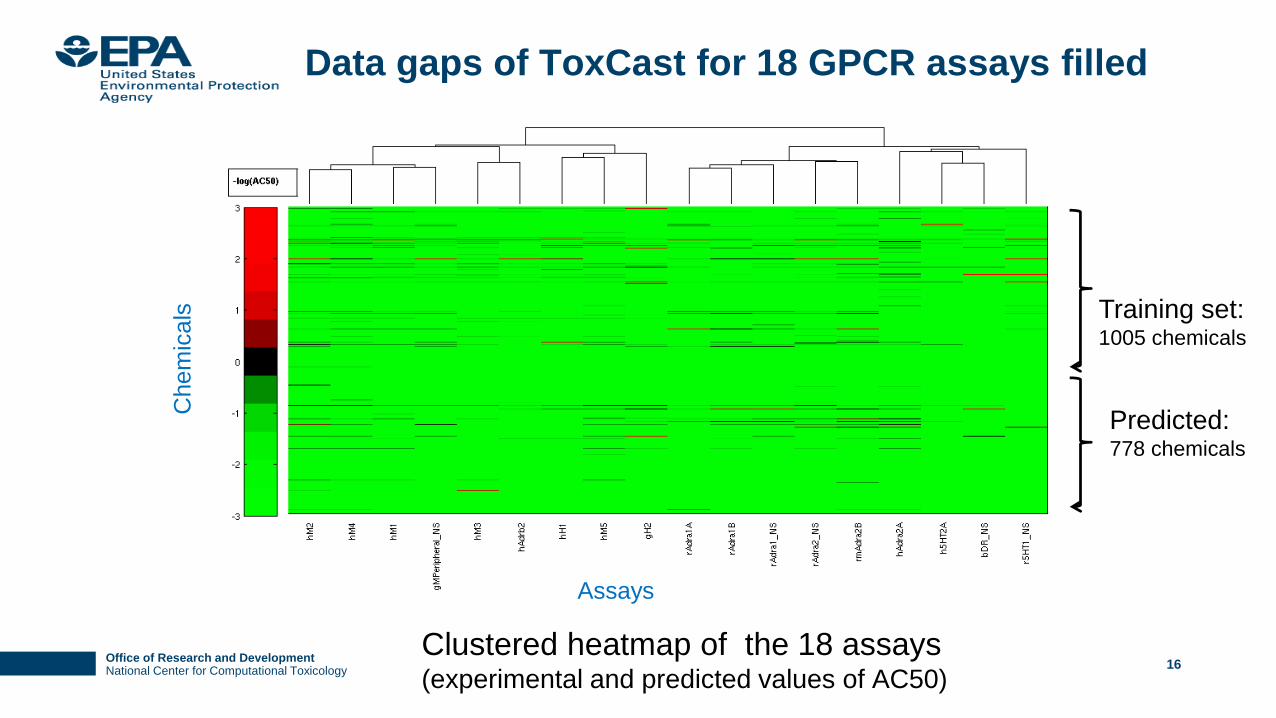
Clustered heatmap of the 18 assays (experimental and predicted values of AC50)
16
Training set: 1005 chemicals
Predicted: 778 chemicals
Chem
icals
Assays
Data gaps of ToxCast for 18 GPCR assays filled
Office of Research and DevelopmentNational Center for Computational Toxicology
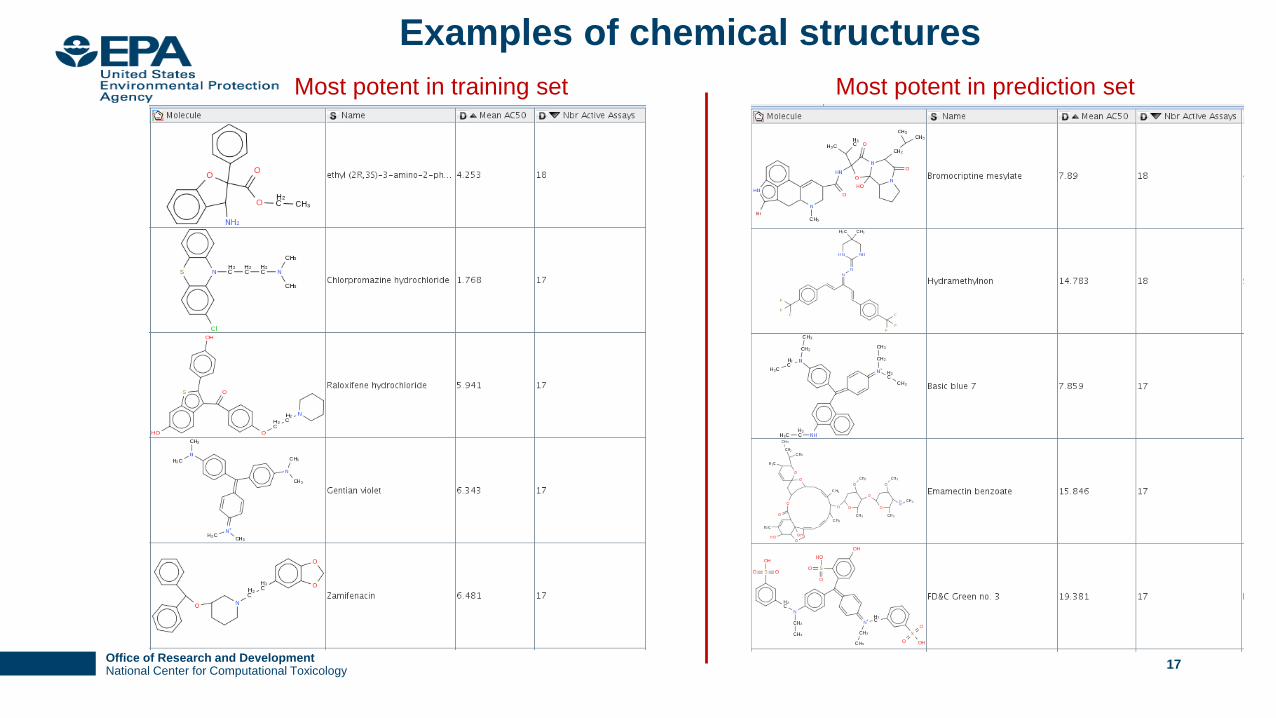
Examples of chemical structures
17
Most potent in training set Most potent in prediction set

Office of Research and DevelopmentNational Center for Computational Toxicology
Summary and future directions
• High accuracy classification & regression models were built on quality data
• ToxCast data gaps filled with:
1. Qualitative predictions: active/ inactive
2. Quantitative predictions for active chemicals: estimation of AC50
• ToxCast is providing large data sets ready for building new QSAR models
–300 gene targets
–1000-8000 chemicals
• Forms the basis for predicting other inventories
– Validate with external test sets
– Apply all models on a list of 32,000 chemicals: Human Exposure Universe
– Use QSAR predictions to help regulators in the prioritization procedures 18

Office of Research and DevelopmentNational Center for Computational Toxicology
Acknowledgements
EPA NCCT
Rusty Thomas
Kevin Crofton
Keith Houck
Ann Richard
Richard Judson
Tom Knudsen
Matt Martin
Woody Setzer
John Wambaugh
Monica Linnenbrink
Jim Rabinowitz
Steve Little
Agnes Forgacs
Jill Franzosa
Chantel Nicolas
Bhavesh Ahir
Nisha Sipes
Lisa Truong
Max Leung
Kamel Mansouri
Eric Watt
Corey Strope
EPA NCCT
Nancy Baker
Jeff Edwards
Dayne Filer
Jayaram Kancherla
Parth Kothiya
Jimmy Phuong
Jessica Liu
Doris Smith
Jamey Vail
Hao Truong
Sean Watford
Indira Thillainadarajah
Christina Baghdikian
Contributors:
Nisha Sipes
Richard Judson
www.epa.gov/ncct/
US EPA National Center for Computational Toxicology


















