
II-SDV 2016 Srinivasan Parthiban - KOL Analytics from Biomedical Literature
39
KOL Analytics from Biomedical Literature II-SDV Conference Nice, France 18 - 19 April 2016 Srinivasan Parthiban Thava Alagu New York, USA
-
Upload
dr-haxel-congress-and-event-management-gmbh -
Category
Internet
-
view
771 -
download
0
Transcript of II-SDV 2016 Srinivasan Parthiban - KOL Analytics from Biomedical Literature

KOL Analytics from Biomedical Literature
II-SDV Conference Nice, France
18 - 19 April 2016
Srinivasan Parthiban
Thava Alagu
New York, USA

• Working with pharmaceutical Medical
Affairs, Clinical, R&D, and commercial
organizations since 2005
• Working with more than half of the Top 50
Companies, 16 of the top 25 (17, and 18
contracting now!)
• The only completely integrated Scientific
Information Solution
Provides timely insights and facilitates strategic decision making
from the vast amount of publicly available scientific information
Medmeme
Meme(noun) - An idea or behavior that spreads in a manner analogous to the biological
transmission of genes.

Bottom Up vs. Top Down
• As each scientific dissemination is captured it is normalized and disambiguated prior to being placed into the master data warehouse
• Matching, tagging and synonyms are added at this stage
• Data is mapped to all relevant areas of interest:• People
• Places
• Institutions & Companies
• Drugs
• Keywords: Mechanism of Action, treatment paradigms, etc.
Building the Scientific Data Warehouse

Grants
Over 1,128,000
Data Sources
Patents
Over 800,000
ClinicalTrials
Over 280,000
Publications
Over 8,930,000
Abstracts from 5760 journals
Meetings
Over 11,870,000
AbstractsMonitoring 14,000+
meetings/year
Treatment GuidelinesOver 36,480
Rolling 10 years Continuously Updated Scientifically Credible Sources
Aligned to the Scientific Discovery Process – from Grants to Guidelines

Impactmeme: The ultimate tool for constantly keeping on top of who is saying what, where. It captures all available scientific dissemination regardless of source
Profilememe: Complete, detailed profiles of virtually all significant publishing and presenting activities for up to 10 years – at one’s fingertips and continuously updated
Insightmeme: A virtual medical librarian on a desktop, allows a user to search on almost any dimension, the entirety of medical journal contents and congress outputs for the past 10 years up to the past month – all normalize and indexed
Conferencememe: The most comprehensive database of medical congress output available anywhere available to users everywhere. See trends in content, as well as where the opinion leaders of interest are presenting
Medmeme Products

• An Industry term and acronym: KOL = Key Opinion Leader
• KOLs are influential doctors, physicians and members of
the medical community who’s opinions are highly regarded
and who influence other doctor’s and physicians.
• KOLs advise companies as to where unmet medical needs lie,
choose drug targets, help to define potential product profiles
and shape clinical programs, run clinical trials, and may be
involved in a drug’s regulatory or reimbursement review
process.
• Peer-to-peer relationships with KOLs are maintained by
Medical Science Liaisons (MSL) from Pharma and healthcare
companies. MSLs are therapeutic specialists (e.g., oncology,
cardiology, neurology)
What is a KOL?

Therapeutic Areas

Geographic Influence
Does the physician have to lead clinical research studies?
Is the physician an early adopter of new drugs?
Education Level
Level of Annual Advising Services Funding
Level of Annual Grant Funding
Tier 1 Global Yes Yes Medical Doctor
$25,000 to $50,000
$100,000 to $250,000
Tier 2 National (US) Yes Yes Medical Doctor
$10,000 to $25,000
Less Than $100,000
Tier 3 Regional No Yes Medical doctor
Less Than $10,000
Less Than $100,000
Tier 4 Local No Notnecessarily
Medical doctor
Less Than $10,000
Less Than $100,000
Tier 5 Local or National (non-USA)
No No PharmD Less Than $10,000
Less Than $100,000
Different Levels of KOLs

Average Number of Publications per Year by
Thought Leader Tier
8,2
5,7
4,8
2,9
1,7
0
1
2
3
4
5
6
7
8
9
Tier-1 Tier-2 Tier-3 Tier-4 Tier-5
Nu
mb
er
of
Pu
blic
atio
ns
pe
r Ye
ar
Thought Leader Tier

Average Years of Clinical Experience by
Thought Leader Tier
12,9
9
7,4 7,3
5,2
0
2
4
6
8
10
12
14
Tier-1 Tier-2 Tier-3 Tier-4 Tier-5
Clin
ical
Exp
eri
ence
in Y
ears
Thought Leader Tier

Average Number of Promotional Speeches per
Year by Thought Leader Tier
9,2
6
3,63,9
2,2
0
1
2
3
4
5
6
7
8
9
10
Tier-1 Tier-2 Tier-3 Tier-4 Tier-5
Spe
ech
es
Thought Leader Tier

KOL Profiling

1,85
2,32
7,17
6,79
6,69
20,65
7,38
5,52
2,17
0 5 10 15 20 25
Delivering a Promotional Speech
Delivering a Scientific Speech
Leading an Advisory Panel (Chair)
Moderating an Advisory Panel
Participating in an Advisory Panel
Authoring a manuscript
Authoring an Abstract
Thought Leader Training (General)
Compilance Training
Hours
Average Amount of Hours Spent per
Thought Leader Activity

Growth in PubMed

Three Challenges 1. Synonymy - A single individual may publish under multiple names—this includes a) orthographic and spelling variants, b) spelling errors, c) name changes over time as may occur with marriage, religious conversion or gender re-assignment, and d) the use of pen names.
2. Homonymy - Many different individuals have the same name – in fact, common names may comprise several thousand individuals.
3. The necessary metadata are often incomplete or lacking entirely – for example, some publishers and bibliographic databases did not record authors’ first names, their geographical locations, or identifying information such as their degrees or their positions.
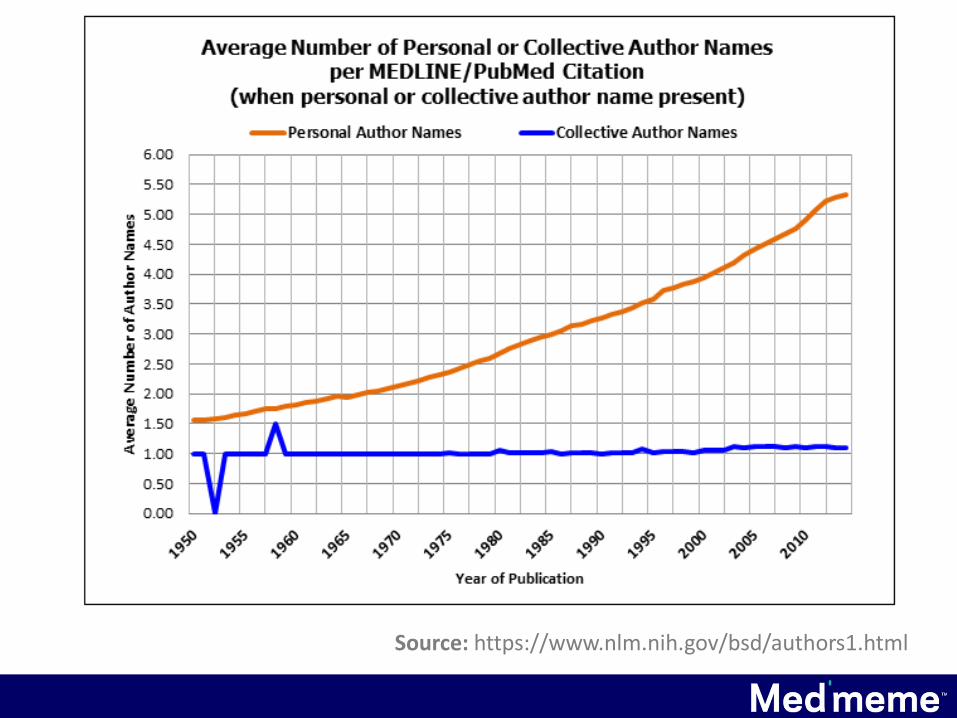
Source: https://www.nlm.nih.gov/bsd/authors1.html

…mistaken identity has resulted in the wrong person being invited to work on a project […] or to undertake the peer review of an article

Type I errorFalse Positive: Identify different author instances as same single author entity. Results in bigger clusters than what it should be.
Type II errorFalse Negative: Not able to identify different author instances of same author. Results in too many small clusters.
What Can Go Wrong?

Percentage of author names in Medline that includes full first name instead of an initial
0,0
10,0
20,0
30,0
40,0
50,0
60,0
70,0
80,0
90,0
1995 2000 2005 2010 2015
per
cen
tage
(%
)
Year
72,0
74,0
76,0
78,0
80,0
82,0
84,0
86,0
2000 2002 2004 2006 2008 2010 2012
per
cen
tage
(%
)Year
• Full names work much better than initials
• Only 5% of the author names on your institution’s articles are people in your instance of Profiles. The rest are former faculty or external collaborators that you have never heard about.

Can never be 100% accurate
85% is considered quite good
Further manual disambiguation
is optionalClose enough

Who is John Smith and what is he talking about ?
Retrieve all clusters with the same author name
What Do You Want to Know?
Who is this John Smith, the author of Article X?
Retrieve other PubMed ids of the same cluster

Give me top 10 KOLs in the field of Cancer!
DISA Platform retrieves top 10 Unique-Author-IDs.
Each UAID is associated with one cluster (of articles) and associated Identity information. (Affiliations and E-mails).
DISA uses the keywords associated with articles to pre-index the authors with associated keywords.
What Do You Want to Know?

• High Precision and Recall is the goal.
• Precision• Accuracy Ratio – Be correct in grouping.• precision = #of correctly clustered pairs / #of
clustered pairs• Stricter the condition, higher the precision
• Recall• Efficiency Ratio - Do not miss the matches.• recall = #of correctly clustered pairs / #of
true positive pairs• More liberal condition, higher the recall
Disambiguation Goal

• Total Manual Disambiguation is infeasible
• Automation is great, but can’t be 100%
• Manual process is hard, uncertain, subjective
• Manual after Automation is Pragmatic
Manual Vs Automated Disambiguation

• Group all publications into author clusters
• Match person to clusters
Clustering Methods
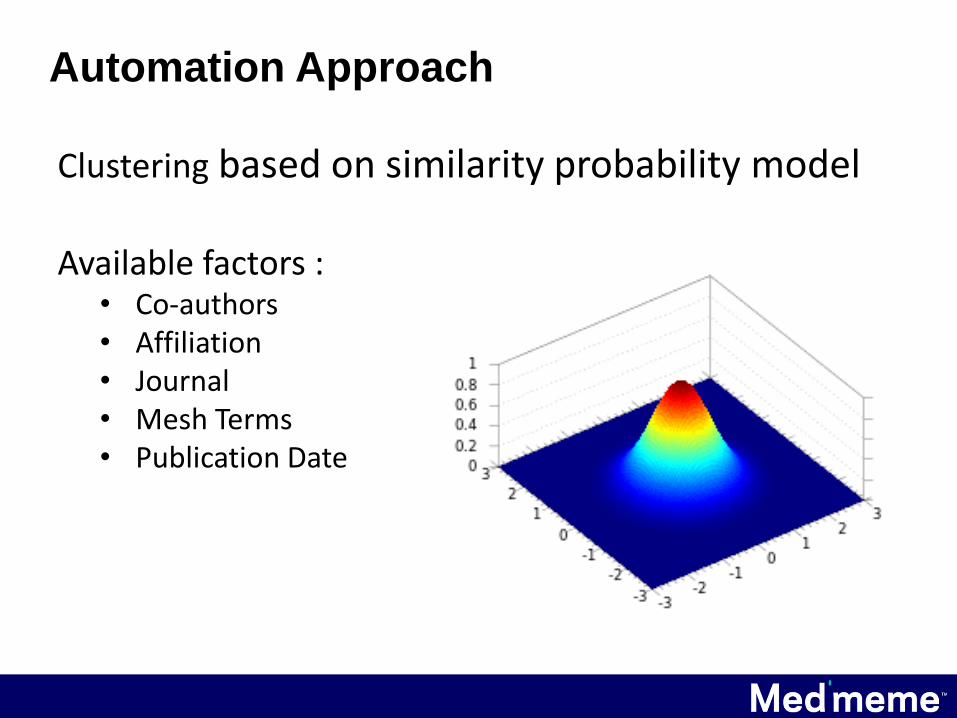
Clustering based on similarity probability model
Available factors :• Co-authors• Affiliation• Journal• Mesh Terms• Publication Date
Automation Approach

• Self learning system possible – Learns from Gold Set
• Creating proper training set is the biggest challenge
• Manual creation of proper training set is costly
• Higher the complexity, vulnerable to bugs
• Main goal is to find relative importance of
the criteria
• Co-author Vs Affiliation Vs MeshTerms Vs Journal etc.
Machine Learning

• Extensive affiliation disambiguation is more
challenging
• Affiliation normalization helps in author
disambiguation
• Involves recognizing countries, cities and address
normalization into canonical form.
• Fuzzy matching possible after normalization – for
smaller buckets only.
Affiliation Disambiguation

• Remember – It is costly operation !
• Scalability Hazard !
• Algorithms:
• Monger-Elkan, Jaro-Winkler, Levenstein
based on edit distance.
• Jaccard, TF-IDF based on token based
multi-sets. (Order of words are not important)
• Some hybrid techniques are also common.
.
Fuzzy Matching

Article-1 Authors : X, Y
Article-2 Authors : X, Z (1 and 2 seems disconnected)
Article-3 Authors : X, Y, Z (Likely that X is same author
for all 3 articles)
Note: Clustering algorithm recognizes and handles this appropriately.
Transitivity Fixing

Introducing DISA
• DISA stands for Disambiguation Automated Platform.
• DISA provides powerful core kernel software system
backed by the author database.
• DISA enables applications to be developed on this
platform to explore the KOLs based on Pubmed and
Conferences information.
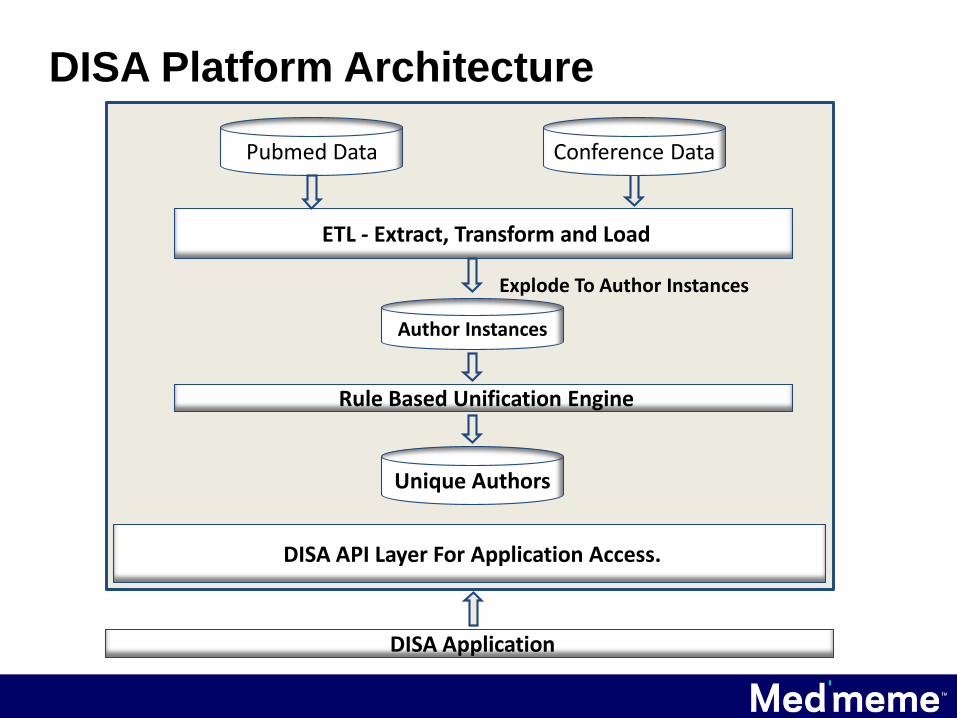
ETL - Extract, Transform and Load
Pubmed Data
Explode To Author Instances
Unique Authors
Rule Based Unification Engine
Author Instances
DISA API Layer For Application Access.
Conference Data
DISA Application
DISA Platform Architecture

DISA Technology Stack

• Disambiguation restricted to same
last name authors.
• This “Blocking” mechanism prevents
combinatorial explosion.
• Still poses problems for common
names
• Fuzzy algorithms are very expensive
on large buckets/blocks.
Scalability Issues

• Relatively less researched so far.
• Need faster updates for delta addition.
• Reconstruct clusters of given name spaces.
• Use incremental clustering
• Embedded database to store and retrieve the
disambiguated author data.
Incremental Disambiguation

• We need both higher precision and
recall.
• But precision is more important.
• Precision errors are more permanent
and harder to fix.
• Recall misses may be fixed in future or
by manual disambiguation.
Being Conservative : Precision Vs Recall

Can not Fix Impossible Situations
Not possible to identify these without author’s voluntary disclosures.
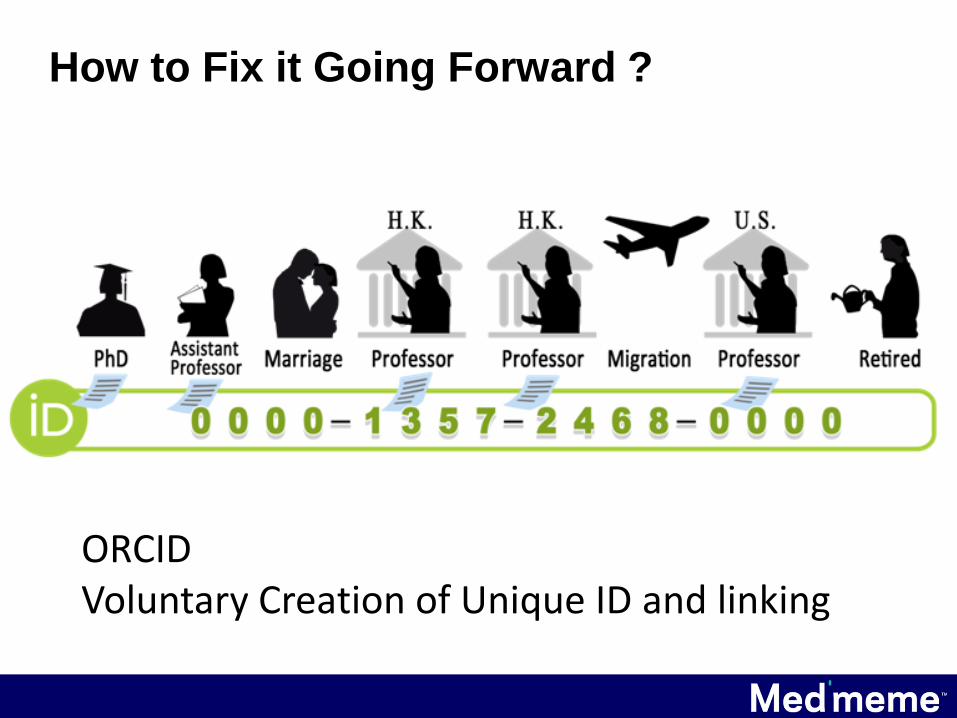
ORCIDVoluntary Creation of Unique ID and linking
How to Fix it Going Forward ?

501 7th Avenue, Suite 508New York, NY, 10018 (USA)
Tel.: 212-725-5992Fax: 212-725-5993
www.medmeme.com
Thank You


















